В тестовой лаборатории «КомпьютерПресс» проведено тестирование управляемых и неуправляемых коммутаторов второго уровня Ethernet 10/100 Мбит/с. Среди управляемых коммутаторов тестировались: 3Com SuperStack II Switch 3300; HP ProCurve Switch 2424M; D-Link DES-3624i; Nortel Networks BayStack 450-24T; SMC TigerSwitch 10/100 SMC6924M; CNet CNSH-800i; Intel Express 460T Standalone Switch.
Среди неуправляемых коммутаторов тестировались: Compex 16-Port 10/100 Ethernet Switch SXP1216; D-Link DES-1016; Intel inBusiness 16-Port 10/100 Switch; PRIME 16-port smart switch PS-1016e; 3Com OfficeConnect DualSpeed Switch 16; 3Com SuperStack II Baseline 10/100 Switch; CNet PowerSwitch CNSH-1600.
Коммутаторы
Коммутаторы — новый уровень производительности
Методика тестирования коммутаторов
3Com SuperStack II Switch 3300
SMC TigerSwitch 10/100 SMC6924M
Hewllet Packard ProCurve Switch 2424M
Nortel Networks BayStack 450-24T
3Com OfficeConnect Dual Speed Switch 16
3Com SuperStack II Baseline 10/100 Switches
Compex 16-Port 10/100 Ethernet Switch SXP1216
Intel inBusiness 16-Port 10/100 Switch
В условиях развивающейся инфраструктуры малого и среднего бизнеса все большее значение приобретает построение локальных сетей начального уровня, рассчитанных на небольшой офис с поддержкой нескольких десятков клиентов, или предприятие, в котором насчитывается несколько сот клиентских компьютеров. На сегодняшний день самыми популярными локальными сетями в России являются сети Ethernet. Основным недостатком таких сетей является сам принцип их построения — в результате коллективного доступа к среде передачи данных увеличение числа пользователей сети становится проблематичным. Так, сеть, построенная на основе концентратора и объединяющая в себе несколько десятков клиентов, может оказаться недееспособной в том смысле, что скорость передачи данных в такой сети будет неприемлемо низкой или некоторым клиентам вообще будет отказано в доступе к сетевым ресурсам. Известно, что работа в сетях Ethernet может быть эффективной при коэффициенте загруженности сети до 40%. Повысить производительность сети можно за счет перехода на более скоростные протоколы передачи данных. Однако это не решает проблемы масштабируемости сети, так как увеличение скорости передачи данных не изменяет принципа функционирования сети, если только эта сеть не построена на базе коммутатора. Коммутатор, как это будет показано далее, фактически изменяет принцип коллективного доступа к среде передачи данных, что с успехом позволяет решать проблему масштабируемости сети и повышения ее производительности.
Несмотря на то что данная статья ориентирована в основном на читателей, знакомых с основами сетевых технологий, вначале напомним основные положения технологии Ethernet, с которыми нам придется столкнуться при обсуждении методики тестирования и анализа результатов. Итак, обо всем по порядку…
Что такое Ethernet
Ethernet как стандарт для построения локальных сетей был разработан в 1970-х годах и окончательно утвердился после принятия спецификации IEEE 802.3 в 1980 году. На сегодняшний день Ethernet является самым распространенным стандартом локальных сетей. В зависимости от типа физической среды передачи данных стандарт Ethernet имеет множество различных модификаций: 10Base-5, 10Base-2, 10Base-T, 10Base-FB, 10Base-FL и т.д. В 1995 году был принят новый стандарт — Fast Ethernet, описанный в разделе IEEE 802.3u. Стандарт Fast Ethernet во многом не является самостоятельным стандартом, поскольку использует аналогичную Ethernet технологию. В 1998 году был принят стандарт Gigabit Ethernet, описанный в разделе IEEE 802.3z. Все стандарты Ethernet имеют много общего.
В настоящее время термин Ethernet используется для описания всех локальных сетей, использующих режим коллективного доступа к среде передачи данных с опознанием несущей и обнаружением коллизий. Этот метод используется в сетях, построенных по логической топологии с общей шиной. При такой топологии все компьютеры локальной сети имеют непосредственный доступ к физической среде передачи данных (общая шина), поэтому она может быть использована для обмена данными между двумя любыми узлами сети. Одновременно (с учетом задержки распространения сигнала по физической среде) все компьютеры сети имеют возможность получать данные, которые любой из компьютеров начал передавать на общую шину. Кабель, к которому подключены все компьютеры, работает в режиме коллективного доступа. В конкретный момент времени передавать данные на общую шину может только один компьютер в сети. При этом все компьютеры сети обладают равными правами доступа к среде. Чтобы упорядочить доступ компьютеров к общей шине, используется метод коллективного доступа с опознанием несущей и обнаружением коллизий (carrier-sense-multiply-access with collision detection, CSMA/CD). Метод состоит из двух частей. Первая часть — Carrier Sense Multiply Access определяет, каким образом компьютер получает доступ к среде. Для того чтобы передать данные на общую шину, компьютер сначала слушает сеть, чтобы определить, не передаются ли в данный момент какие-либо данные. В стандарте Ethernet признаком свободной линии является «тишина», то естьто есть отсутствие несущей. Если рабочая станция обнаруживает несущий сигнал, то для нее это является признаком занятости шины и передача данных откладывается, то есть станция переходит в режим ожидания. В стандарте Fast Ethernet признаком свободного состояния среды является не отсутствие сигналов на шине, а передача по ней специального Idle-символа соответствующего избыточного кода.
Когда в сети наступает молчание, станция начинает передачу. Все данные, передаваемые по сети, формируются в кадрах определенной структуры. Каждый кадр снабжается уникальным адресом станции назначения и станции отправителя. Кроме того, каждый кадр сопровождается 8-байтовой преамбулой — определенным сигналом, необходимым для синхронизации приемника и передатчика. Все станции, подключенные к общей шине, определяют факт передачи кадра, но только та станция, которая узнает свой адрес в заголовках кадра, записывает его содержимое в свой внутренний буфер, а затем посылает по кабелю кадр-ответ. Адрес станции-отправителя содержится в исходном кадре, поэтому станция-получатель знает, кому нужно послать ответ.
По окончании передачи кадра все узлы сети обязаны выдержать паузу, называемую межкадровым интервалом (Inter Packet Gap, IPG). Эта пауза необходима для обеспечения равных прав всем станциям на передачу данных, то естьто есть для предотвращения монопольного захвата одной станцией общей шины и для приведения сетевых адаптеров в исходное состояние. По окончании паузы станции сети определяют среду как свободную и могут начать передачу данных. Длительность межкадрового интервала для 10-мегабитного Ethernet составляет 9,6 мкс, а для 100-мегабитного Fast Ethernet — в 10 раз меньше, то есть 0,96 мкс. Межкадровый интервал в точности равен времени, необходимому для передачи 12 байт или 96 бит. Если определить в качестве единицы измерения временного интервала время, необходимое для передачи одного бита — битовый интервал (bt), то межкадровый интервал равен 96 bt. Такой способ определения временных интервалов не зависит от скорости передачи данных и часто используется в стандарте Ethernet.
При описанном способе коллективного доступа к среде передачи данных возможна ситуация, когда несколько станций одновременно решат, что шина является свободной, и начнут передавать по ней свои данные. Такая ситуация называется коллизией (collision). При этом содержимое кадров сталкивается на общей шине и происходит искажение информации. В принципе, коллизия — это нормальная и неизбежная ситуация в сетях Ethernet. Коллизия возникает не только в том случае, когда две или больше станций начинают абсолютно одновременно передавать кадр на общую шину, что практически нереально, но и когда одна станция начинает передачу кадра, а до другой станции этот кадр еще не успел распространиться, и, решив, что шина свободна, другая станция также начинает передачу. Коллизия — это следствие распределенного характера сети. Чем больше диаметр сети, то есть расстояние между двумя наиболее удаленными друг от друга станциями, тем больше вероятность возникновения коллизии в такой сети (рис. 1).
Вторая часть метода CSMA/CD — Collision Detection служит для разрешения конфликтных ситуаций, возникающих при коллизиях. Все узлы сети должны быть способны распознать возникающую коллизию.
Четкое распознавание коллизий всеми станциями сети является необходимым условием корректной работы сети Ethernet. Если какая-либо передающая станция не распознает коллизию и решит, что кадр данных передан ею верно, то этот кадр данных будет утерян. Из-за наложения сигналов при коллизии информация кадра исказится и он будет отбракован принимающей станцией (возможно, из-за несовпадения контрольной суммы). Скорее всего, искаженная информация будет повторно передана каким-либо протоколом верхнего уровня, например транспортным или прикладным, работающим с установлением соединения. Но повторная передача сообщения протоколами верхних уровней произойдет через значительно более длительный интервал времени по сравнению с микросекундными интервалами, которыми оперирует протокол Ethernet. Поэтому если коллизии не будут надежно распознаваться узлами сети Ethernet, то это приведет к заметному снижению полезной пропускной способности данной сети.
Для того чтобы иметь возможность распознать коллизию, каждая станция прослушивает сеть во время и после передачи пакета. Обнаружение коллизии основано на сравнении посылаемого станцией сигнала и регистрируемого сигнала. Если регистрируемый сигнал отличается от передаваемого, то станция определяет эту ситуацию как коллизию. При обнаружении коллизии передающей станцией она прерывает процесс передачи кадра и посылает в сеть специальный 32-битный сигнал, называемый jam-последовательностью. Назначение этой последовательности — сообщить всем узлам сети о наличии коллизии.
После возникновения коллизии станция, ее обнаружившая, делает паузу, после
которой предпринимает следующую попытку передать кадр. Пауза ![]() после коллизии является случайной и выбирается по следующему правилу:
после коллизии является случайной и выбирается по следующему правилу:
![]()
где t — интервал отсрочки равный 512 bt, что при скорости 100 Мбит/с
составит 5,12 мкс; L — целое случайное число, выбранное из диапазона ![]() ,
где N — номер повторной попытки передачи данного кадра.
,
где N — номер повторной попытки передачи данного кадра.
После первой попытки пауза может либо отсутствовать, либо составлять один или два интервала отсрочки. После второй попытки пауза может либо отсутствовать, либо быть равной одному, двум, трем или четырем интервалам отсрочки. После 10-й попытки интервал, из которого выбирается пауза, не увеличивается. Таким образом, после десятой попытки передачи кадра случайная пауза может принимать значения от 0 до 1024´ 512 bt = 524 288 bt. Для стандарта Fast Ethernet это соответствует временному диапазону от 0 до 5,24 мс.
Передатчик предпринимает всего 16 последовательных попыток передачи кадра. Если все попытки завершились неудачно, вызвав коллизию, то передатчик прекращает попытки передать данный кадр.
Для надежного распознания коллизий необходимо, чтобы коллизия была обнаружена в процессе передачи кадра. В худшем варианте в конфликт могут вступить две наиболее удаленные друг от друга станции. Пусть первая станция, решив, что шина свободна, начинает передачу кадра. До самой удаленной от нее станции этот кадр дойдет не мгновенно, а через некоторый промежуток времени t. Если в этот момент времени удаленная станция, также решив, что шина свободна, начинает передачу своего кадра, то возникает коллизия. Искаженная информация дойдет до первой станции также через время t. Поэтому коллизия будет обнаружена первой станцией через время 2t после начала передачи ею кадра. К моменту обнаружения коллизии станция не должна закончить передачу кадра. Отсюда получается простое соотношение между временем, необходимым для передачи кадра минимальной длины и задержкой сигнала при распространении в сети:
![]()
где t — время распространения сигнала по сети Ethernet. Удвоенное время распространения сигнала называют временем двойного оборота (Path Delay Value, PDV). Время двойного оборота в сети определяется максимальной длиной сети, а также устройствами (концентраторами, повторителями), вносящими задержку в распространение сигнала. Минимальное время, необходимое для передачи кадра Ethernet, зависит от скорости передачи и длины кадра. Все параметры протокола Ethernet подобраны таким образом, чтобы при нормальной работе узлов сети коллизии всегда четко распознавались. Так, для сетей Fast Ethernet, построенных на витой паре и концентраторе, максимальное расстояние между станцией и концентратором не должно превосходить 100 м, а между любыми двумя станциями сети должно быть не более четырех концентраторов (правило четырех хабов).
Из описания метода коллективного доступа к общей шине и механизма реагирования на коллизии видно, что вероятность того, что станция может получить в свое распоряжение общую шину для передачи данных, зависит от загруженности сети, то есть от того, насколько часто возникает потребность у станций в передаче кадров. При значительной загруженности сети возрастает вероятность возникновения коллизий, и полезная пропускная способность сети Ethernet падает из-за повторных попыток передачи одних и тех же кадров. Следует отметить, что метод доступа CSMA/CD вообще не гарантирует станции, что она когда-либо сможет получить доступ к среде. Конечно, при небольшом сетевом трафике вероятность такого поворота событий невелика, но если сетевой трафик приближается к максимальной пропускной способности сети, подобное становится очень вероятным. Для характеристики загруженности сети вводят понятие коэффициента загруженности (использования) сети. Коэффициент загруженности сети определяется как отношение трафика, передаваемого по сети, к ее максимальной пропускной способности. Для сетей Fast Ethernet максимальная пропускная способность равна 100 Мбит/с (200 Мбит/с в полнодуплексном режиме), а трафик, передаваемый по сети, равен сумме интенсивностей трафиков, генерируемых каждым клиентом сети.
Говоря о максимальной пропускной способности сети, следует различать полезную и полную пропускную способность. Под полезной пропускной способностью понимается скорость передачи полезной информации, объем которой всегда несколько меньше полной передаваемой информации, так как каждый передаваемый кадр содержит служебную информацию, гарантирующую его правильную доставку адресату. Отличие полезной пропускной способности от полной пропускной способности зависит от длины кадра. Так как доля служебной информации всегда одна и та же, то, чем меньше общий размер кадра, тем выше «накладные расходы». Служебная информация в кадрах Ethernet составляет 18 байт (без преамбулы), а размер поля данных кадра меняется от 46 до 1500 байт. Сам размер кадра меняется от 46 + 18 = 64 байт до 1500 + 18 = 1518 байт. Поэтому для кадра минимальной длины полезная информация составляет всего лишь 46/64 = 0,72 от общей передаваемой информации, а для кадра максимальной длины 1500/1518 = 0,99 от общей информации. Чтобы рассчитать полезную пропускную способность сети для кадров максимального и минимального размера, необходимо учесть различную частоту следования кадров. Естественно, что, чем меньше размер кадров, тем больше таких кадров будет проходить по сети за единицу времени, перенося с собой большее количество служебной информации (рис. 2).
Так, для передачи кадра минимального размера, который вместе с преамбулой имеет длину 72 байта, или 576 бит, потребуется время, равное 576 bt, а если учесть межкадровый интервал в 96 bt, то получим, что период следования кадров составит 672 bt. При скорости передачи в 100 Мбит/с это соответствует времени 6,72 мкс. Тогда частота следования кадров, то есть количество кадров, проходящих по сети за 1 секунду, составит 1/6,72 мкс = 148 809 кадр/с.
При передаче кадра максимального размера, который вместе с преамбулой имеет длину 1526 байт или 12208 бит, период следования составляет 12 208 bt + 96 bt = 12 304 bt, а частота кадров при скорости передачи 100 Мбит/с составит 1/123,04 мкс = 8127 кадр/с.
Зная частоту следования кадров и размер полезной информации, переносимой каждым кадром, нетрудно рассчитать полезную пропускную способность сети. Для кадра минимальной длины полезная пропускная способность равна 46 байт/кадр´ 148 809 кадр/с = 54,76 Мбит/с, что составляет лишь немногим больше половины от общей максимальной пропускной способности сети. Для кадра максимального размера полезная пропускная способность сети равна 1500 байт/кадр´ 8127 кадр/с = 97,52 Мбит/с.
Таким образом, в сети Fast Ethernet полезная пропускная способность может меняться в зависимости от размера передаваемых кадров от 54,76 до 97,52 Мбит/с, а частота следования кадров изменяется в диапазоне от 8127 до 148 809 кадр/с.
Говоря о различных размерах кадров, принятых в стандарте Ethernet, отметим, откуда берутся ограничения, накладываемые на размер кадров. Действительно, если при большем размере кадра увеличивается полезная пропускная способность сети, то почему не сделать все кадры одинакового размера, установив этот размер как можно большим? Максимальный размер кадра ограничивается несколькими обстоятельствами. Во-первых, чем больше размер кадра, тем больше времени требуется для его обработки, и, кроме того, необходимо повышать емкость буфера сетевого адаптера. Кроме того, если такой кадр будет утерян или испорчен и потребуется его повторная передача, то это приведет к менее эффективному использованию сети. Делать же все кадры одинакового размера, равного, например 1518 байт, при котором достигается высокая полезная пропускная способность сети, было бы также не рационально, поскольку не всегда компьютеры обмениваются большими объемами полезной информации. К примеру, пересылка файла от одного компьютера к другому сопровождается постоянной пересылкой «квитанций в получении» от компьютера-адресата к компьютеру-поставщику. Такие квитанции оформляются в специальные служебные кадры. Объем переносимой при этом информации невелик и вполне укладывается в поле данных минимального по размерам кадра. Если же использовать для таких квитанций кадры максимального размера, то это приведет к заметному уменьшению эффективности использования сети, так как накладные расходы (служебная информация, содержащаяся в заголовке кадра) значительно превысят объем полезной информации. Объем полезной информации, переносимой кадром, может оказаться и меньше поля данных минимального кадра, то есть меньше 46 байтов. При этом незаполненное полезной информацией поле данных автоматически заполняется нулями до размера в 46 байт. Для чего это нужно? Почему нельзя установить минимальный размер кадра равным размеру служебной информации (18 байтов) и необходимому размеру для передачи полезной информации? Минимальный размер кадра устанавливается из условия надежного распознания коллизий. Вспомним, что время двойного оборота кадра по сети должно быть меньше времени, необходимого для передачи этого кадра.
Приведенный выше расчет максимальной полезной пропускной способности сети Ethernet относится к идеальной ситуации, когда одна станция имеет монопольный доступ к общей шине. В такой ситуации нет коллективного доступа и коллизий, приводящих к уменьшению полезной пропускной способности сети, не возникает. Такая ситуация реализуется, например, при копировании файла с сервера на несколько клиентских компьютеров.
При наличии нескольких клиентов, общающихся друг с другом, происходит множественный доступ к общей шине. При этом попытка клиента передать кадр на общую шину может иметь три исхода: успешная передача, переход в режим ожидания или передача с возникновением коллизии. В идеальной ситуации, когда все кадры передаются с успешным результатом, в сети, состоящей из N узлов, на долю каждого узла приходится пропускная способность равная С/N Мбит/с, где C — максимальная пропускная способность сети. Однако вероятность передачи кадров с переходом в режим ожидания или с возникновением коллизии возрастает экспоненциально с ростом числа узлов в сети и интенсивности передачи трафика каждым узлом. К примеру, если в сети Fast Ethernet, состоящей из 20 узлов, каждый компьютер попытается генерировать в сеть трафик со скоростью 5 Мбит/с, то за счет возникающих коллизий и переходов в режим ожидания сеть вообще перестанет передавать полезную информацию и будет работать «вхолостую», обрабатывая возникающие коллизии. Влияние задержек и коллизий на полезную пропускную способность сети отражает график, представленный на рис. 3.
Из рис. 3 видно, что при некотором критическом значении коэффициента загруженности сети полезная пропускная способность сети перестает увеличиваться. Дальнейшее увеличение коэффициента загруженности сети приводит к снижению полезной пропускной способности, делая работу в такой сети практически невозможной. Количество узлов, при котором значение коэффициента загруженности сети принимает критическое значение, зависит от типа функционирующих в сети приложений и реально ограничивается несколькими десятками узлов, что значительно меньше того максимального количества узлов, которое можно объединять в сеть по стандарту Ethernet (в стандарте Ethernet предусмотрено максимальное количество узлов в сети, равное 1024). Поэтому сети Ethernet рекомендуется загружать так, чтобы значение коэффициента использования не превышало 30-40%.
Но как быть, если сеть необходимо расширить, что, естественно, будет сопровождаться увеличением ее загруженности? Ограничения, возникающие из-за использования общей разделяемой среды, можно преодолеть, разбив ее на несколько более мелких сетей и соединив такие сегменты между собой с помощью коммутатора.
|
|
Коммутаторы — новый уровень производительности
В отличие от концентраторов, которые полностью воплощают в себе идеологию общей разделяемой среды и превращают сеть в единый домен коллизий, коммутаторы — это более интеллектуальные устройства, способные анализировать адрес назначения кадра и передавать его не всем станциям сети, а только адресату.
До появления коммутаторов задача разбиения сети на сегменты решалась с помощью мостов, которые в настоящее время практически не используются. Основной же принцип действия мостов и коммутаторов остался неизменным. Именно поэтому коммутаторы иногда называют многопортовыми мостами.
Технология конфигурационной коммутации сегментов Ethernet была предложена фирмой Kalpana в 1990 году. Эта технология основана на отказе от использования разделяемой среды передачи данных, что позволяет передавать пакеты одновременно между всеми парами портов коммутатора.
Конструктивно коммутатор представляет собой многопортовое устройство, предназначенное для деления сети на множество сегментов. В сетях Ethernet коммутаторы используют в своей работе алгоритм прозрачного моста (transparent bridge), регламентированного в стандарте IEEE 802.1D. Алгоритм прозрачного моста подразумевает, что коммутатор «обучается» в процессе своей работы. Коммутатор строит свою адресную таблицу на основании пассивного наблюдения за трафиком, циркулирующего в сети. В начальный момент времени коммутатор ничего не знает об адресах подключенных к его портам компьютеров или сегментах сети. По мере того как подключенные к портам коммутатора узлы начинают проявлять активность, коммутатор анализирует содержимое адресов отправителя кадров, что позволяет делать вывод о принадлежности того или иного узла к тому или иному порту коммутатора. Адреса отправителей кадров заносятся в таблицу MAC-адресов коммутатора (рис. 4).
В начальный момент времени коммутатор работает в неразборчивом режиме, передавая полученные кадры на все порты. Построив таблицу MAC-адресов, коммутатор может передавать полученные кадры не на все порты, а только по адресу назначения. Если на порт коммутатора поступает кадр с адресом назначения, приписанным к другому порту коммутатора, то кадр передается между портами. Такой процесс называется продвижением кадра (forwarding). Если же коммутатор определяет, что адрес назначения приписан к тому порту, на который поступил данный кадр, то кадр отбрасывается или отфильтровывается, то есть удаляется из буфера порта. Такой процесс называется фильтрацией (filtering).
При обсуждении технологии Ethernet мы отмечали, что использование коммутаторов может значительно увеличить производительность сети за счет отказа от принципа разделяемой среды. Рассмотрим, как это происходит. Пусть к каждому из восьми портов 8-портового коммутатора подключен компьютер (микросегментация сети). В идеальном случае можно установить четыре пары соединений между компьютерами, как показано на рис. 5.
При таком соединении каждая пара компьютеров может общаться друг с другом, как если бы других компьютеров в сети вообще не было. Поскольку при таком соединении нет общей разделяемой среды (в полнодуплексном режиме работы), то возникновение коллизий невозможно и все кадры передаются в сеть с положительным исходом. В этом случае компьютеры могут общаться друг с другом с максимальной протокольной скоростью. Говорят, что коммутатор предоставляет каждому узлу выделенную пропускную способность протокола. Производительность коммутатора, имеющего N портов и позволяющего установить N/2 соединений, составляет (N/2)*С, где С — протокольная пропускная способность.
Однако рассмотренная ситуация является идеальной. Более вероятно, когда два или более компьютеров в сети пытаются установить соединение с одним компьютером (рис. 6).
Учитывая, что выходной порт может в один момент времени устанавливать соединение только с одним входным портом, нельзя не понимать, что в этом случае коммутатор не способен выделить каждому компьютеру пропускную способность протокола. Так, если 4 компьютера пытаются установить соединение с одним компьютером по протоколу Fast Ethernet, то коммутатор может выделить каждой станции лишь полосу пропускания в 25 Мбит/с, так как выходной порт коммутатора может передавать данные с максимальной скоростью в 100 Мбит/с.
Практически все современные коммутаторы сетей Ethernet способны работать в двух режимах: 10 Мбит/с по стандарту Ethernet и 100 Мбит/с по стандарту Fast Ethernet. При этом, поддерживается как полудуплексный, так и полнодуплексный режим работы.
В полудуплексном режиме работы прием и передача кадров осуществляется по одной витой паре, поэтому даже в случае, когда к каждому порту коммутатора подключено по одному компьютеру, возможно возникновение коллизий. При этом доменом коллизий являются сам порт коммутатора, порт сетевого адаптера и собственно кабель. Коллизия в этих условиях может возникнуть, если сетевой адаптер и порт коммутатора одновременно или почти одновременно начинают передачу кадров, решив, что кабель не занят.
В полнодуплексном режиме работы такая ситуация не считается коллизией, поскольку полнодуплексный режим предусматривает одновременную передачу данных в обоих направлениях. Таким образом, если сеть микросегментирована, то есть к каждому порту коммутатора подключено по одному компьютеру, то коллизии в принципе не могут возникать. Фактически при этом меняется способ доступа узла к среде передачи данных, что позволяет ликвидировать основной недостаток сетей Ethernet. Узлу разрешается отправлять кадры в коммутатор, когда бы ему это ни потребовалось. Однако при этом отсутствует механизм регулирования потока от каждого узла. Действительно, ведь при разделении среды передачи данных всеми узлами сети трафик саморегулировался тем, что с повышением интенсивности генерации трафика некоторыми узлами, повышалась и вероятность перехода этих узлов в режим ожидания. При этом интенсивность реального трафика, который направляется такими узлами в сеть, может оказаться значительно меньше той интенсивности, которая требуется этими узлами.
В полнодуплексном режиме работы нет механизма саморегулирования трафика, поэтому, если дополнительно не предусмотреть средств регулирования потока кадров, коммутаторы могут столкнуться с перегрузками. Рассмотрим, к примеру, ситуацию, когда несколько портов коммутатора направляют свой трафик на один порт. Такая ситуация возникает при одновременном копировании файлов на файловый сервер со стороны нескольких клиентов. Если считать, что каждый отдельный компьютер способен копировать файлы со скоростью 25 Мбит/с, а в полнодуплексном режиме компьютер в сети ведет себя так, как если бы он был один (то есть не чувствует влияния других компьютеров), то при наличии уже пяти таких компьютеров, одновременно производящих копирование файлов, выходной порт коммутатора неизбежно столкнется с перегрузками. Действительно, суммарный трафик, создаваемый пятью компьютерами составит 125 Мбит/с, но выходной порт может передавать кадры лишь со скоростью 100 Мбит/с, что ограничено протокольной пропускной способностью. В результате нагрузка на выходной порт составит 125% и коммутатор неизбежно столкнется с перегрузкой. Если такая перегрузка длится в течение очень короткого промежутка времени, то проблема может быть решена за счет использования буфера выходного порта. Но при долговременной перегрузке буфер переполнится, что приведет к потере кадров. Поэтому в полнодуплексном режиме работы необходимо предусмотреть механизм управления потоком кадров.
Для регулирования потока кадров используется технология Advanced Flow Control, описанная в стандарте IEEE 802.3х. Эта технология использует для контроля потока кадров со стороны коммутатора команды «Приостановить передачу» и «Возобновить передачу». Сетевой адаптер или порт коммутатора, поддерживающий стандарт IEEE 802.3x, получив команду «Приостановить передачу», прекращает передавать кадры до получения команды «Возобновить передачу».
При работе в полудуплексном режимекоммутатор также может сталкиваться с перегрузками, когда сумма входящих трафиков превышает сумму выходящих. Однако при полудуплексном режиме технология Advanced Flow Control неприемлема, так как передача и прием кадров осуществляются по одной витой паре. В этом случае для управления потоком кадров коммутатор может использовать два метода, основанных на том, что коммутатор, в отличие от конечных узлов, может нарушать некоторые правила доступа к среде передачи данных.
Первый метод называется методом обратного давления (backpressure). В случае когда коммутатору необходимо «подавить» активность какого-либо порта, он искусственно генерирует коллизии на этот порт, посылая ему jam-последовательности.
Второй метод основан на агрессивном поведении порта коммутатора. Агрессивность поведения порта коммутатора заключается в том, что для доступа к среде передачи данных порт не выдерживает технологической паузы между кадрами в 9,6 bt, а делает эту паузу равной 9,1 bt. В этом случае порт коммутатора монопольно захватывает шину, направляя конечному узлу только свои кадры. Естественно, что сам конечный узел прекращает генерацию кадров, что дает возможность порту коммутатора разгрузить свой внутренний буфер. Для монопольного захвата шины после коллизии коммутатор выдерживает интервал отсрочки, равный 500 bt, а конечный узел, как и определено стандартом, выдерживает интервал отсрочки в 512 bt. Это также приводит к тому, что конечный узел прекращает генерацию кадров в порт коммутатора.
|
|
Какими они бывают
На сегодняшний день наиболее часто используются три типа функциональной структуры коммутаторов:
- с коммутационной матрицей;
- с общей шиной;
- с разделяемой многовходовой памятью.
Кроме того, упомянутые схемы часто комбинируются в схеме одного коммутатора, так как каждая схема имеет свои достоинства и недостатки.
Первый коммутатор EtherSwitch фирмы Kalpana был построен на основе коммутационной матрицы. Каждый порт такого коммутатора обслуживается отдельным процессором кадров (Ethernet Packet Processor, EPP). Работу всех процессоров координирует системный модуль, который содержит адресную таблицу коммутатора и обеспечивает управление коммутатором по протоколу SNMP. При поступлении кадра в порт коммутатора процессор EPP буферизует служебные байты кадра, для того чтобы прочитать адрес назначения. После того, как адрес назначения установлен, процессор, не дожидаясь прихода остальных байтов кадра, принимает решение о продвижении или фильтрации кадра. Для этого он просматривает таблицу MAC адресов в своем собственном кэше или, если там нет нужного адреса, обращается к системному модулю. Если процессор, на основе анализа адресной таблицы, принимает решение о продвижении кадра, коммутационная матрица устанавливает соединение между портом приема и портом назначения. Однако установление соединения в коммутационной матрице возможно только в том случае, если порт назначения свободен, то есть не соединен с другим портом. Если же порт назначения занят, то установить соединение невозможно. В этом случае кадр полностью буферизуется портом, оставаясь там до тех пор, пока не будет возможно установить соединение. После установления соединения байты кадра поступают на выходной порт коммутатора, где могут быть буферизованы процессором выходного порта. Процессор выходного порта передает немедленно (без буферизации) поступающие байты подключенному к порту сегменту Ethernet или же буферизует их, если разделяемая среда сегмента в данный момент занята.
Коммутаторы с коммутационной матрицей обеспечивают самый быстрый способ коммутации портов. Однако число портов в таких коммутаторах ограничено, так как сложность схемы возрастает пропорционально квадрату числа портов. Конструктивно матрица может быть выполнена на основе различных комбинационных схем, реализованных в виде ASIC-микросхем, но независимо от способа реализации в ее основе лежит физическая коммутация каналов связи. На рис. 7 показана топология связей коммутационной матрицы (рис. 7).
Основным недостатком данной технологии является невозможность буферизации кадров в самой коммутационной матрице. Из приведенного выше примера ясно, что основным фактором, определяющим пропускную способность такого коммутатора, является буферизация кадров, без которой кадры могут быть просто потеряны. Однако увеличение объема буфера порта приводит к большей задержке передачи кадра, что противоречит основной цели коммутаторов — повышению производительности.
В коммутаторах с общей шиной (рис. 8) процессоры портов связываются между собой высокоскоростной шиной. Связь портов через такую шину происходит в режиме разделения времени. Для того чтобы такой коммутатор мог работать в неблокирующем режиме, производительность общей шины, то есть ее пропускная способность, должна быть не ниже совокупной производительности всех портов коммутатора.
Передача данных по такой шине происходит не кадрами, а более мелкими порциями, размер которых зависит от производителя. Для этого процессор передающего порта разбивает кадр на более мелкие порции, прибавляя к каждой из них адрес порта назначения (тэг адреса). Процессоры выходных портов содержат фильтры тэгов, что позволяет им выбирать предназначенные им данные. В схемы с общей шиной, так же как и в схеме с коммутационной матрицей, невозможно осуществить промежуточную буферизацию кадров.
В коммутаторах с разделяемой памятью процессоры портов связаны через специальный переключатель с разделяемой памятью. Работой переключателей и памяти управляет специальный блок управления портами. Этот блок организует в памяти очередь данных для каждого выходного порта. Когда какому-либо порту необходимо передать данные, процессор этого порта делает запрос блоку управления, который связывает данный порт с разделяемой памятью, что дает возможность записать данные в очередь нужного выходного порта (рис. 9).
Параллельно с записью данных в очереди выходных портов блок управления поочередно подключает процессоры выходных портов к соответствующим очередям, в результате чего данные из очереди переписываются в выходной буфер процессора. Применение общей буферной памяти, распределяемой блоком управления между отдельными портами, снижает требования к размеру буферной памяти процессора порта.
Независимо от способа конструктивной реализации коммутатора все коммутаторы характеризуются некоторыми общими параметрами, определяющими их производительность. Наиболее важные среди них — это:
- скорость продвижений (forwarding);
- скорость фильтрации (filtering);
- пропускная способность коммутатора (throughput);
- время задержки передачи кадра;
- тип коммутации;
- размер адресной таблицы;
- размер буферной памяти.
Скорость продвижения, измеряемая в количестве кадров в секунду, определяет скорость, с которой происходит передача кадра между входным и выходным портами. Сам процесс передачи кадра включает в себя несколько этапов. Первый этап — это процесс буферизации либо всего кадра в целом, либо первых байтов кадра, содержащих адрес назначения. После определения адреса назначения кадра происходит процесс поиска искомого выходного порта в адресной таблице, которая может быть расположена либо в локальном кэше порта, либо в общей адресной таблице. После определения нужного выходного порта процессор принимает решение о продвижении кадра и посылает запрос на доступ к выходному порту. Установление необходимой связи между выходным и входным портами сопровождается передачей кадра в сеть через выходной порт.
Скорость фильтрации, так же как и скорость продвижения, измеряется в количестве кадров в секунду и характеризует скорость, с которой порт фильтрует, то есть отбрасывает ненужные для передачи кадры. Первый этап процесса фильтрации — это буферизация либо всего кадра, либо только первых адресных байтов кадра. После этого процессор просматривает адресную таблицу на предмет установления необходимого выходного порта. Определив, что адрес выходного порта совпадает с адресом входного порта, процессор принимает решение о фильтрации кадра и очищает свой буфер.
Скорость фильтрации и скорость продвижения зависят как от производительности процессоров портов, так и от режима работы коммутатора, о чем будет сказано далее. Наибольшего значения скоростей можно достигнуть при наименьшем размере кадров, так как в этом случае скорость их поступления максимальна. Как правило, скорость фильтрации является неблокирующей, то есть обработка кадров может происходить со скоростью их поступления.
Пропускная способность коммутатора, измеряемая в мегабитах в секунду (Мбит/с), определяет какое количество пользовательских данных можно передать через коммутатор за единицу времени. Максимальное значение пропускной способности достигается на кадрах максимальной длины, поскольку в этом случае доля накладных расходов на служебную информацию в каждом кадре мала.
Время задержки передачи кадра определяется как время, прошедшее с момента поступления первого байта кадра на входной порт коммутатора до момента появления этого байта на его выходном порте. Время задержки, так же как и скорость фильтрации и продвижения, зависит от типа коммутации, поэтому принято указывать лишь минимально возможное время задержки, которое составляет от единиц до десятков микросекунд.
Типы коммутации, определяют не производительность коммутатора, а режим его работы. Однако от типа коммутации зависит скорость продвижения и фильтрации и время задержки передачи кадров. Поэтому тип коммутации косвенно влияет на производительность коммутатора. Различают четыре типа коммутации:
- сквозная коммутация (cut-through);
- коммутация с буферизацией (store-and-forward switching);
- бесфрагментная коммутация (fragment-free switching);
- адаптивная коммутация (intelligent).
При сквозной коммутации в буфер входного порта поступают лишь несколько первых байтов кадра, что необходимо для считывания адреса назначения. После установления адреса назначения, параллельно с приемом остальных байтов кадра, происходит коммутация необходимого маршрута, по кадр передается к выходному порту. Сквозная коммутация возможна лишь в том случае, если выходной порт не занят в момент поступления кадра. В противном случае весь кадр поступает в буфер входного порта.
Сквозная коммутация обеспечивает самую высокую скорость коммутации, что дает значительный выигрыш в производительности. Однако наряду с ростом производительности снижается надежность. Действительно, если не происходит полной буферизации кадра, то и невозможно осуществить анализ этого кадра. Как следствие — могут быть пропущены кадры с ошибками. Таким образом, сквозная коммутация не поддерживает защиты от плохих кадров.
При коммутации с буферизацией кадр поступает в буфер входного процессора, где по контрольной сумме проверяется на наличие ошибок. Если ошибки не обнаружены, пакет передается на выходной порт. Этот способ коммутации гарантирует фильтрацию от ошибочных кадров, однако за счет снижения пропускной способности коммутатора по сравнению со сквозной коммутацией.
При безфрагментной коммутации в буфер входного порта поступает не весь кадр, а только первые 64 байта. Для кадра минимального размера это соответствует полной буферизации, а для кадров, размер которых больше 64 байтов, это соответствует сквозной коммутации. Таким образом, при безфрагментной буферизации проверке подлежат только кадры минимального размера.
В зависимости от конкретных условий работы предпочтителен тот или иной способ коммутации. Так, если передача происходит с большим количеством ошибок, то более предпочтительна коммутация с буферизацией, а если передача происходит без ошибок, то для повышения производительности предпочтительна сквозная коммутация. Поскольку условия передачи могут меняться в зависимости от времени и для каждого порта интенсивность появления ошибок может быть индивидуальной, полезно иметь возможность адаптивной подстройки под конкретные условия передачи. Такая технология получила названия адаптивной коммутации. При адаптивной коммутации коммутатор сам выбирает для каждого порта оптимальный режим работы. Вначале все порты устанавливаются в режим сквозной коммутации, потом те порты, на которых возникает много ошибок, переводятся в режим безфрагментной коммутации. Если и при этом количество ошибок остается неприемлемо большим, то порт переводится в режим коммутации с буферизацией, что гарантирует полную фильтрацию от ошибочных кадров.
Размер адресной таблицы определяет то максимальное количество MAC-адресов, которое может хранить коммутатор. Обычно размер адресной таблицы приводится в расчете на один порт. Размер адресной таблицы зависит от области применения коммутаторов. Так, при использовании коммутатора в рабочей группе при микросегментации сети достаточно всего несколько десятков адресов. Коммутаторы отделов должны поддерживать несколько сот адресов, а коммутаторы магистралей сетей — до нескольких тысяч адресов.
Размер адресной таблицы сказывается на производительности коммутатора только в том случае, если требуется больше адресов, чем может разместиться в таблице. Если адресная таблица порта коммутатора полностью заполнена и встречается кадр с адресом, которого нет в таблице, то процессор размещает этот адрес в таблице, вытесняя при этом какой-либо старый адрес. Эта операция отнимает у процессора порта часть времени, что снижает производительность коммутатора. Кроме того, если после этого порт получает кадр с адресом назначения, который пришлось предварительно удалить из таблицы, по процессор порта передает этот кадр на все остальные порты, так как не может определить адрес назначения. Это в значительной степени отнимает процессорное время у процессоров всех портов и создает излишний трафик в сети, что еще больше снижает производительность коммутатора.
Размер буферной памяти также оказывает непосредственное влияние на производительность коммутатора. Буферная память используется для временного хранения кадров в случае если их невозможности немедленной передачи на выходной порт. Основное назначение буферной памяти заключается в сглаживании кратковременных пиковых пульсаций трафика. Такие ситуации могут возникать в случае, если на все порты коммутатора одновременно предаются кадры и у коммутатора нет возможности передавать принимаемые кадры на порты назначения. Чем больше объем буферной памяти, тем ниже вероятность потери кадров при перегрузках.
Размер буферной памяти может указываться как общий, так и в расчете на порт. Для повышения эффективности использования буферной памяти в некоторых моделях коммутаторов память может перераспределяться между портами, так как перегрузки на всех портах маловероятны.
Кроме рассмотренных выше характеристик коммутаторов, определяющих их производительность, многие модели коммутаторов способны выполнять ряд дополнительных функций. Такие коммутаторы принято называть управляемыми. Управление или настройка коммутаторов может происходить или по последовательному интерфейсу через терминальную программу, или на основе Web. Кроме того, некоторые коммутаторы поддерживают функцию настройки и мониторинга через специальное программное обеспечение. В числе основных дополнительных функций управляемых коммутаторов наиболее важными являются следующие:
- трансляция протоколов канального уровня;
- фильтрация трафика;
- приоритетная обработка кадров;
- поддержка протокола Spanning Tree Protocol (STP);
- поддержка виртуальных сетей;
- поддержка протокола SMNP;
- поддержка протокола RMON.
Трансляция протоколов канального уровня подразумевает, что коммутатор может преобразовывать кадры различных форматов друг в друга: например кадры формата Fast Ethernet в кадры формата FDDI. Такая функция коммутатора дает возможность объединять в пределах одной локальной сети сегменты, построенные по различным технологиям. Трансляция кадров происходит в соответствии со спецификациями IEEE 802.1H и RFC 1042, определяющими правила преобразования служебных полей кадров различных протоколов. Естественно, что при выполнении трансляции протоколов канального уровня коммутатор должен обеспечивать коммутацию с буферизацией, так как для преобразования кадров необходима их полная буферизация.
Возможность дополнительной фильтрации трафика позволяет создавать пользовательские фильтры, которые ограничивают доступ заданных заранее групп пользователей к определенным службам сети. Фактически фильтрация трафика — это сервис, повышающий уровень сетевой безопасности.
Приоритетная обработка кадров подразумевает возможность обрабатывать входящие кадры не по принципу First Input First Output (FIFO), когда каждый кадр обрабатывается в соответствии с очередью их поступления, а в соответствии с указанным приоритетом кадра. Для каждого порта можно устанавливать по несколько очередей, причем каждой очереди может быть присвоен определенный уровень приоритета. При таком подходе кадры с высоким уровнем приоритета могут обрабатываться в 10 раз чаще, чем кадры с низким уровнем приоритета.
Самый простой способ осуществлять приоритетную обработку кадров — назначать уровни приоритета непосредственно самим портам. Однако у такого способа есть существенный недостаток — если к порту подключается не один компьютер, а сетевой сегмент, то соответствующим уровнем приоритета будут пользоваться все компьютеры этого сегмента, что может быть нежелательно.
Более гибкой является схема назначения уровня приоритета самим кадрам. Такой механизм реализован в спецификации IEEE 802.1p. Согласно этой спецификации в кадр Ethernet добавляется дополнительно служебное двухбайтовое поле, в котором указывается уровень приоритета кадра. Для того чтобы могла осуществляться приоритетная обработка кадров по спецификации IEEE 802.1p, ее должен поддерживать не только коммутатор, но и сетевые адаптеры конечных узлов.
Поддержка протокола Spanning Tree Protocol, то есть алгоритма покрывающего дерева определяет корректную работу коммутатора в случае, когда между конечными узлами сети существует несколько логических или физических маршрутов, в состав которых входят коммутаторы. При существовании нескольких дублирующих друг друга путей, называемых петлями, возникают явления, которые способны парализовать работу всей сети, если только коммутатор не придерживается определенных правил. Такие дублирующие пути могут прокладываться специально для повышения отказоустойчивости сети.
Протокол STP описан в документе IEEE 802.1D и определяет правила поведения коммутатора в случае обнаружения им петель. В соответствии с протоколом STP для корректной работы коммутатора необходимо, чтобы между любыми двумя конечными узлами сети существовал один и только один маршрут. Если коммутатор обнаруживает несколько дублирующих маршрутов, то начинается процесс определения оптимального маршрута и блокировка всех остальных. Естественно, что для реализации протокола STP необходимо, чтобы все коммутаторы сети обеспечивали его поддержку. Все коммутаторы сети, поддерживающие данный протокол, обмениваются друг с другом специальными служебными кадрами BPDU (Bridge Protocol Data Unit). В этих кадрах заложены два параметра: идентификатор коммутатора и стоимость портов. Идентификатор коммутатора должен назначаться сетевым администратором, а стоимость портов устанавливается по умолчанию либо задается вручную. Обмен BPDU-пакетами позволяет коммутаторам определить корневой коммутатор, которому соответствует наибольшее значение идентификатора и, кроме того, вычислить стоимость пути от конечных узлов до портов корневого коммутатора. На основе сравнения коммутатор с наибольшей стоимостью пути до корня переводит свой порт в заблокированное состояние. Соответственно порт с наименьшей стоимостью пути становится назначенным и осуществляет передачу кадров.
Поддержка виртуальных сетей (Virtual LAN,VLAN) позволяет с помощью коммутатора создавать изолированные друг от друга локальные сети. В отличие от использования пользовательских фильтров, виртуальные сети поддерживают защиту от широковещательного трафика. Поэтому говорят, что виртуальная сеть образует домен широковещательного трафика (broadcast domain). Изоляция виртуальных сетей друг от друга происходит на канальном уровне. Это означает, что передача кадров между различными виртуальными сетями на основании адреса канального уровня (MAC-адреса) невозможна.
Конечно, построить несколько изолированных друг от друга сетей можно, использовав нескольких коммутаторов, но использование одного коммутатора не только снижает стоимость таких сетей, но и позволяет более гибко и рационально использовать порта коммутатора. К примеру, одна локальная сеть может быть построена из двух сегментов, подключенных к двум портам коммутатора, а другая сеть может состоять из пяти сегментов, для чего потребуется пять портов коммутатора. При использовании для этих сетей двух различных коммутаторов несколько портов останутся неиспользованными.
Поскольку узлы различных виртуальных сетей изолированы друг от друга на канальном уровне, для объединения таких сетей в единую сеть требуется привлечение сетевого, или 3-го уровня. Понятие 3-го уровня соответствует градации уровней сетевой модели OSI. Для обеспечения таких связей могут быть использованы маршрутизаторы либо коммутаторы, обеспечивающие функции маршрутизатора. Такие коммутаторы получили название коммутаторов 3-го уровня. По аналогии — коммутаторы, работающие только на канальном уровне, иногда называются коммутаторами 2-го уровня.
Технология образования виртуальных сетей определяется в спецификации IEEE 802.1Q. В соответствии с этой спецификацией в каждый кадр встраивается служебное поле, в котором записывается идентификатор виртуальной сети. Кроме указанной технологии, коммутаторы могут поддерживать способ образования виртуальных сетей по группировке портов. Для этого каждый порт коммутатора приписывается той или иной виртуальной сети. Однако такой способ может применяться только в случае создания виртуальных сетей на базе одного коммутатора.
Поддержка протокола SNMP (Simple Network Management Protocol) определяет возможность управления коммутатором. Протокол сетевого администрирования SNMP очень широко используется в настоящее время и входит в стек протоколов TCP/IP. Протокол SNMP используется для получения от коммутатора информации о его статусе, производительности и других характеристиках, которые хранятся в базе данных коммутатора. Процесс управления коммутатором и получения нужной информации о его состоянии происходит по схеме менеджер-агент. Агент является посредником между коммутатором и основной программой-менеджером. Основная задача агента — предоставление необходимой информации менеджеру. Например, агент коммутатора может предоставлять менеджеру такие характеристики, как количество портов, их статус, текущую скорость передачи данных, таблицу фильтрации и т.д. На основе полученной от агента информации менеджер принимает решение по управлению или обобщает предоставленную информацию для отображения ее в нужном виде.
Поскольку задача агента — предоставление информации, его называют базой данных управляющей информации — Management Information Base, MIB. В настоящее время существует несколько моделей MIB.
Поддержка протокола RMON (Remote Monitoring) определяет возможность удаленного мониторинга и управления коммутатором. Фактически RMON является расширением протокола SNMP, обеспечивая удаленное взаимодействие с базой данных MIB. До появления протокола RMON управление коммутатором могло происходить только локально, например при подключении коммутатора через последовательный порт к компьютеру и использовании терминальной программы. Использование RMON позволяет управлять и следить за состоянием коммутатора с удаленного компьютера с возможностью передачи требуемых данных по сети. Объекты RMON MIB включают в себя дополнительные счетчики об ошибках, более гибкие средства анализа статистики, средства фильтрации и т.д. Агенты RMON MIB более интеллектуальны по сравнению с агентами MIB-I и MIB-II так как позволяют выполнять часть работы по обработке информации вместо менеджеров. Эти агенты могут быть расположены как внутри коммутатора, так и вне их в виде программных модулей на компьютере. В протоколе RMON выделяют 9 групп:
- Statistic — группа сбора текущих статистических данных о трафике, характеристиках пакетов, ошибках и т.д.
- History — группа сбора статистических данных, которые сохраняются через определенные промежутки времени для последующего анализа.
- Alarms — группа сбора пороговых значений показателей, при превышении которых посылается соответствующее сообщение.
- Hosts — группа сбора статистических данных о конечных узлах.
- Hosts Top N — группа сбора данных по конечным узлам с возможностью сортировки.
- Matrix — группа сбора данных о трафике между каждой парой узлов сети.
- Filter — группа сбора данных об условиях фильтрации пакетов.
- Capture — группа сбора данных об условиях захвата пакетов.
- Event — группа сбора данных об условиях регистрации и генерации событий.
Кроме перечисленных дополнительных возможностей, предоставляемых управляемыми коммутаторами, стоит отметить, что многие модели предусматривают возможность масштабирования.
Для неуправляемых коммутаторов эта функция реализуется в большинстве случаев через специальный порт Uplink, позволяющий связывать коммутатор с коммутатором или концентратором. Наличие такого порта — хотя и удобное, но не единственное решение. Два коммутатора можно связать друг с другом и через обычные порты, но с применением кроссированного кабеля.
Для управляемых коммутаторов возможность масштабирования решается с использованием либо транковых соединений, либо специальных высокоскоростных портов, что позволяет объединять несколько коммутаторов в стек (стековые коммутаторы).
Транковые соединения представляют собой объединения нескольких портов друг с другом так, что с точки зрения коммутатора они видятся как один порт. В результате пропускная способность транкового соединения возрастает пропорционально количеству объединенных портов. К примеру, пропускная способность транкового соединения из четырех портов FastEthernet 100 Mбит/с составит 800 Мбит/c в полнодуплексном режиме работы. Такие соединения используются для соединения коммутаторов друг с другом или для соединения коммутатора с сервером при наличии соответствующего количества объединенных сетевых карт на сервере.
Использование высокоскоростных портов для объединения коммутаторов в стек позволяет объединять несколько коммутаторов в общую систему, работающую как единый коммутатор. Как правило, использование высокоскоростного интерфейса позволяет объединять только коммутаторы одного производителя.
|
|
Методика тестирования коммутаторов
Тестирование проводилось для управляемых и неуправляемых коммутаторов Ethernet 10/100 MBps. Подробные технические характеристики коммутаторов представлены в табл. 1.
Тестирование коммутаторов проводилось в два этапа. На первом этапе оценивалась интегральная производительность коммутатора при работе в реальной сети, на втором этапе, который условно можно назвать функциональным тестированием, проводилось сравнение наиболее важных, влияющих на их производительность и функциональные возможности характеристик коммутаторов.
Методика тестирования любого сетевого устройства основана на создании таких условий, при которых именно тестируемое устройство является узким местом в сети. При таком подходе производительность всей сети будет определяться именно производительностью тестируемого устройства и получаемые результаты будут корректны. Так, например, если при тестировании серверов коммутатор или концентратор окажется узким местом сети, ограничивающим сетевой трафик, то максимальная производительность сервера просто не будет достигнута.
Между тем создать такие условия, при которых получаемые результаты целиком бы зависели от тестируемого устройства, в принципе невозможно. Результаты неизбежно будут определяться производительностью всех сетевых компонентов, то есть производительностью рабочих станций и серверов, производительностью концентраторов и коммутаторов, физической топологией сети и т.д. Это означает, что результаты тестирования будут меняться при изменении конфигурации самой сети и для возможности сравнения тестируемых устройств необходимо локализовать конфигурацию всей сети, изменяя в ней только тестируемое устройство.
Все выше сказанное в полной мере относится и к коммутаторам. Первая проблема, возникающая при тестировании коммутаторов — это создание таких условий, при которых именно коммутатор был бы узким местом сети. Производительность самого коммутатора заведомо выше производительности компьютера, и в этом смысле загрузить коммутатор не так-то просто. Поэтому часто при тестировании коммутаторов используют не компьютеры, создающие трафик в сети, а специализированные генераторы трафика, как например Smartbits Advanced SMB100. Производительность таких программируемых генераторов выше производительности коммутаторов, и, следовательно, они позволяют создать экстремальные условия для работы коммутаторов. Именно с их помощью можно измерять такие важные характеристики коммутаторов, как время задержки, скорость продвижения и фильтрации а также пропускная способность коммутатора.
При использовании в качестве оконечной нагрузки коммутатора компьютеров измерить какие-либо характеристики коммутатора принципиально невозможно. С другой стороны, представить себе сеть с загрузкой, хотя бы приближающейся к той, что создается с помощью специализированных генераторов трафика, тоже трудно. Поэтому, на наш взгляд, более интересным представляется сравнение коммутаторов не в условиях, которые заведомо не могут быть достигнуты в реальных сетях, а в условиях, максимально приближенных к реальным. Исследуя работу коммутатора в реальной сети, можно попытаться получить некоторую интегральную оценку производительности не столько самого коммутатора, сколько производительности сети, построенной на конкретном коммутаторе. Именно этот принцип и был положен нами в основу проведения сравнительных испытаний коммутаторов.
Для проведения тестирования разворачивалась локальная сеть Fast Ethernet, состоящая из 8 рабочих станций с операционной системой Microsoft® Windows® 2000 Professional SP1 и коммутатора. Использование кабеля категории CAT5 позволило создать сеть 100Base-TX c полнодуплексным режимом работы. Все компьютеры сети имели одинаковую конфигурацию:
- материнская плата ASUS P3B-F;
- процессор Intel Pentium III 500 MHz;
- оперативная память 128 МВ PC-100 non ECC;
- жесткий диск 10200 MB IDE;
- сетевой адаптер 3Com Fast EtherLink XL PCI-10/100 Base-TX.
Параметры сетевых адаптеров на всех компьютерах были выставлены по умолчанию, а именно:
- поддержка протокола 802.1p (приоритетная обработка кадров) — запрещена (Disable);
- управление потоком 802.3x (Flow Control) — разрешено (Enable);
- режим работы (Duplex Mode) — определяется оборудованием (Hardware default);
- тип среды передачи данных (Media Type) — определяется оборудованием (Hardware default).
Конфигурация используемой локальной сети показана на рис. 10.
Характерно, что в используемой нами сети нет сервера. Действительно, можно, используя несколько компьютеров, создать мощный трафик, направив его на один порт коммутатора, к которому подключен сервер. Казалось бы, в этих условиях можно оценить пропускную способность порта коммутатора и производительность коммутатора по обслуживанию выходных очередей. Однако пропускная способность коммутатора ограничена не его производительностью, а протокольными соотношениями и для сети Fast Ethernet не может превосходить 100 Мбит/с, а производительности процессора выходного порта коммутатора вполне достаточно для обслуживания всех выходных очередей при потоке в 100 Мбит/с. Кроме того, при таком подходе узким местом в сети является не коммутатор, а канал связи коммутатор-сервер. То есть производительность сети будет определяться производительностью сетевой подсистемы самого сервера. В доказательство сказанного можно отметить, что производительность сети в рассмотренном примере не будет меняться не только при замене одного коммутатора на другой, но и при замене коммутатора на концентратор. Действительно, с одной стороны, использование концентратора вместо коммутатора сохраняет классический подход к рассмотрению множественного доступа, определяя в качестве домена коллизий всю локальную сеть. С другой стороны, механизм саморегулирования потока за счет перехода клиентов в режим ожидания в сети, построенной на концентраторе, и механизм сдерживания потока, основанный на технологии Advanced Flow Control, принципиально приводят к одинаковому результату: если линия (порт) занята, то передача кадра откладывается.
Именно поэтому для проведения тестовых испытаний мы использовали одноранговую локальную сеть. Для создания максимальной нагрузки на коммутатор каждый компьютер сети одновременно в псевдопараллельном режиме общался со всеми остальными компьютерами сети, то есть общение между компьютерами данной сети основывалась на принципе «многие-ко-многим» (рис. 11).
В реальных условиях при микросегментации сети трудно представить себе ситуацию, когда один компьютер сети одновременно общается со всеми остальными. Однако ситуация кардинально меняется, если к каждому порту коммутатора подключается не отдельный компьютер, а концентратор или другой коммутатор. В этих условиях каждый порт коммутатора представляет отдельный сегмент сети и общение между компьютерами, принадлежащим различным сегментам, создает трафик, подобный тому, как если бы каждый сегмент сети был представлен отдельным компьютером, общающимся со всеми остальными компьютерами сети. (рис. 12).
При достаточно интенсивном трафике узким местом сети становится сам коммутатор, и производительность всей сети определяется интегральной производительностью коммутатора. Действительно, если трафик, поступающий на каждый порт, близок к предельному и пакеты в непредсказуемом порядке адресуются всем остальным компьютерам сети, то скорость передачи информации через коммутатор будет интегрально зависеть от скорости продвижения кадров и времени задержки передачи.
Для создания интенсивного трафика мы использовали утилиту Iometer, разработанную компанией Intel®. При использовании утилиты необходимо, чтобы на всех компьютерах сети была бы установлена операционная система Windows NT4 или выше. Именно поэтому мы использовали на всех компьютерах ОС Windows 2000 Professional SP1. Утилита предназначена для измерения производительности сетевых устройств и состоит из двух программ: Dynamo и Iometer. Программа Dynamo осуществляет функцию генератора трафика и устанавливается на всех компьютерах сети, с которых предполагается генерировать трафик. Программа Iometer осуществляет функцию контроллера и руководит работой программы Dynamo. С помощью графического интерфейса программы Iometer задаются программа теста, последовательность выполняемых операций, интенсивность трафика и осуществляется отображение результатов теста. Программа Iometer устанавливается только на одном компьютере сети. Согласно терминологии утилиты Iometer любая пара компьютеров сети, между которыми производится генерация трафика, представляют собой пару «клиент-сервер». Причем компьютер, на который производится генерация трафика, называется сервером, а компьютер, с которого осуществляется генерация трафика, называется клиентом. При этом под парой «клиент-сервер» понимают не физические компьютеры сети, а логическую задачу, выполняемую на паре компьютеров. Утилита Iometer позволяет организовывать работу в многозадачном режиме, поэтому между любыми двумя физическими компьютерами могут одновременно выполняться несколько логических задач, каждая из которых требует свей собственной пары «клиент-сервер». Для того чтобы организовать равноправный обмен данными между двумя физическими компьютерами, на каждом из них устанавливается как сервер, так и клиент. Если же необходимо осуществить равноправное взаимодействие между всеми восемью компьютерами сети, то на каждом из них устанавливается по восемь серверов и восемь клиентов. Утилита Iometer позволяет контролировать интенсивность генерируемого трафика, однако такой контроль осуществляется не непосредственно, а через дополнительные параметры настройки выполняемой задачи. Такими настройками являются: размер данных, над которыми выполняются файловые операции ввода-вывода (Transfer Request Size), тип выполняемой операции — последовательное чтение, выборочное чтение, последовательная запись, выборочная запись, а также смесь этих операций в процентном соотношении, время задержки между выполнением указанных задач. В нашем тестировании для получения максимально интенсивного трафика мы использовали операции последовательно чтения с размером данных в 64 Кбайт при нулевом времени задержки. В этих условиях утилизация процессора каждой рабочей станции составляет не более 15%, что позволяет утверждать, что процессорная подсистема рабочих станций не является узким местом сети.
В указанных условиях трафик, создаваемы между одной парой компьютеров, то есть без учета влияния всех остальных компьютеров сети равен, 90 Мбит/с. При этом речь идет не о полезном, а о полном трафике, то есть с учетом «накладных расходов», когда переносимая информация определяется размером кадра.
Для оценки интегральной производительности коммутатора количество компьютеров в сети, взаимодействующих по принципу «многие-ко-многим» увеличивается от двух до восьми и с добавлением каждого нового компьютера рассчитывается как предлагаемая нагрузка на сеть, так и реально наблюдаемая нагрузка.
Под реальной нагрузкой на сеть, измеряемой в мегабайтах в секунду (MBps) или в мегабитах в секунду (Mbps) понимается количество данных, переносимых по сети в единицу времени.
Под предполагаемой нагрузкой на сеть понимается то количество данных, которое можно передать по сети за единицу времени в «идеальных условиях», то есть в случае, когда компьютеры передают данные по сети, не влияя друг на друга. Для расчета предполагаемой нагрузки сначала определяется трафик в случае, когда один компьютер сети, подключенный, например, к первому порту коммутатора, передает данные одновременно всем остальным компьютерам сети. После этого аналогичный трафик определяется для компьютера, подключенного ко второму порту, и т.д. для всех компьютеров сети. Если трафик, идущий от i-го порта к j-му порту обозначить через Cij, то предлагаемая нагрузка рассчитывается по формуле:
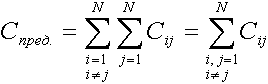
где N — количество задействованных портов коммутатора.
Учитывая, что все порты коммутатора имеют одинаковую производительность, а конфигурация всех компьютеров одинакова, полученную формулу можно упростить:
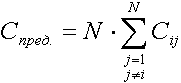 .
.
Если бы коммутатор был способен обеспечить такую передачу данных, при который компьютеры сети не «тормозили» бы друг друга, то предлагаемая нагрузка совпала бы с наблюдаемой. Однако в реальных условиях всегда имеет место взаимное влияние компьютеров друг на друга, и наблюдаемая нагрузка на сеть всегда меньше предлагаемой. Величину, показывающую во сколько раз наблюдаемая нагрузка меньше предлагаемой, мы будем называть интегральной производительностью коммутатора.
Интегральная производительность коммутатора определяется в относительных единицах как отношение реально наблюдаемой нагрузки в сети к предполагаемой нагрузке, то есть по формуле:
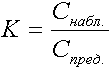
Измерение интегральной производительности коммутатора в относительных единицах более удобно тем, что получаемые величины наделены конкретным физическим смыслом. Действительно, при таком определении интегральная производительность показывает, насколько близок данный коммутатор к «идеальному». При этом «идеальному» коммутатору соответствует значение интегральной производительности, равное единице, а для реальных коммутаторов — оно всегда меньше единицы.
При расчете интегральной производительности коммутатора было зафиксировано, что предлагаемая нагрузка на сеть у всех коммутаторов одинакова. Фактически это означает, что в условиях отсутствия взаимного влияния компьютеров друг на друга, все коммутаторы работают одинаково. С ростом числа клиентов, то есть компьютеров, участвующих в процессе обмена данными, предлагаемая нагрузка увеличивается линейно (рис. 13) и может быть рассчитана по формуле:
![]()
где N — количество активных клиентов, к — коэффициент пропорциональности, определяемый экспериментально. В нашем случае он оказался равен 11,25 МБайт/с=90 Мбит/с. Таким образом, при подключении всех восьми компьютеров предлагаемая нагрузка составляла 720 Мбит/с.
Согласно нашим измерениям, наблюдаемая нагрузка менялась для различных моделей коммутаторов от 0,52 до 0,97. При этом, наблюдаемая нагрузка, так же как и предлагаемая, линейно возрастала с ростом числа клиентов. При линейной зависимости наблюдаемой нагрузки для расчета интегральной производительности коммутатора, в принципе, достаточно и трех клиентов, так как отношение наблюдаемой нагрузки к предлагаемой не зависит от числа клиентов, если только их больше трех. Тогда возникает вопрос: для чего нужно использовать так много клиентов, если можно обойтись всего тремя? Цель, которая преследовалась увеличением числа используемых клиентов — загрузить коммутатор как можно больше. Естественно, что при максимальной нагрузке в 720 Мбит/с коммутатор не нагружается даже на 50% от своей пропускной способности, и в этом смысле говорить о загрузке коммутатора бессмысленно. Речь идет о том, насколько «сбалансировано» коммутатор обслуживает свои порты в случае, когда все компьютеры одновременно начинают запрашивать доступ к среде передачи данных. Как известно, коммутатор должен предоставлять равные права всем компьютерам к среде передачи данных. Однако «должен» — не значит «умеет». В процессе тестирования у нас возникло подозрение, что не все коммутаторы знают о своих обязанностях. Так, была выявлена модель коммутатора, которая отказывалась работать со столь большим числом клиентов одновременно. По всей видимости, коммутатор не обеспечивал сбалансированное обслуживание своих портов и те компьютеры, которые не могли в течение положенного срока начать передачу данных, приводили к сбою в работе программы.
В завершение описания методики измерения производительности коммутатора отметим, что каждый замер наблюдаемой нагрузки производился по пять раз, а по результатам измерений рассчитывалось среднее значение и среднеквадратичное отклонение. Зная среднеквадратичное отклонение, мы рассчитывали погрешность измерения при доверительной вероятности 80% (коэффициент Стъюдента равен 0,267). В наших измерениях погрешность не превышала 1%.
Учитывая, что проведенного нами исследования работоспособности коммутаторов недостаточно для получения объективной оценки качества, на втором этапе мы сравнивали наиболее важные, на наш взгляд, характеристики коммутаторов. Из них мы выбрали следующие: интегральную производительность коммутатора по результатам проведенного тестирования, цену за порт, размер таблицы MAC-адресов, количество портов UpLink, максимальное количество портов в транковом объединении, максимальное количество коммутаторов, объединяемых в стек, количество дополнительных слотов в коммутаторе, экспертную оценку дополнительных возможностей коммутатора и экспертную оценку эффективности управления коммутатором (табл. 2). Естественно, что приведенный перечень характеристик коммутатора далеко не полный, но, во-первых, сравнивать все характеристики коммутаторов было бы крайне сложно, а во-вторых, далеко не все характеристики коммутатора можно выяснить по его паспортным данным. Так, например, выяснить пропускную способность, время задержки и объем буферной памяти для многих моделей коммутаторов оказалось невозможно.
В приведенном перечне оцениваемых характеристик поясним, что мы понимаем под «экспертной оценкой дополнительных возможностей коммутатора» и «экспертной оценкой эффективности управления коммутатором».
Эффективность управления означает, насколько легко выбирать требуемую конфигурацию продукта и управлять им. Кроме того, учитывается и функциональность управления, то есть количество опций, доступных для настройки. Управление через Web-браузер или специализированный софт — большой плюс, но оно должно быть быстрым, простым в навигации и охватывать большинство, если не все важные функции устройства.
При оценке дополнительных возможностей коммутатора учитывался весь спектр дополнительных функций и возможностей. К примеру, возможность выбирать режим коммутации — большой плюс. Кроме того, учитывались возможности по созданию виртуальных сетей, фильтрации трафика, обеспечению сетевой безопасности и т.д.
Часть из указанных характеристик учитывается по факту наличия, то есть либо «есть» либо «нет» часть характеристик рассчитывается субъективно по 10-бальной шкале.
Для каждой характеристики вычисляется ее показатель качества. Необходимость введения этого абстрактного понятия вызвана стремлением сравнить коммутаторы между собой. Ведь конечная цель тестирования заключается именно в сравнении коммутаторов между собой и не только по отдельным характеристикам, но и в целом. Такое сравнение было бы простой задачей, если бы у нас имелся какой-либо обобщенный (интегральный) показатель производительности или качества коммутатора. Для определения такого интегрального показателя качества сначала вычисляется показатель качества каждой отдельной характеристики, после чего они складываются с соответствующими весовыми коэффициентами.
Итак, первая проблема, с которой приходится сталкиваться, это вычисление показателя качества для каждой отдельной характеристики. Понятно, что сама по себе характеристика в «чистом» виде не может быть своим же качеством. Действительно, как можно, например, складывать максимальное количество коммутаторов, объединяемых в стек, и удобство управления коммутатором? Поэтому показатель качества каждой характеристики должен быть безразмерной величиной. Более того, показатель качества должен отражать действительное положение вещей, то есть если характеристика одного коммутатора хуже аналогичной характеристики другого коммутатора, то и соотношение показателей качества этих характеристик должно быть аналогичным. Формулы, позволяющие вычислить показатель качества каждой характеристики, приведены в табл. 2.
После того как определены показатели качества каждой характеристики, можно вычислить качество самого коммутатора. Однако просто сложить показатели качества для каждой характеристики недостаточно. Ведь разные характеристики имеют различную значимость. Естественно, что показатель качества интегральной производительности коммутатора по результатам тестирования куда более важен, чем показатель качества удобства управления коммутатором. Поэтому для каждой характеристики необходимо определить ее весовой коэффициент, являющийся показателем значимости данной характеристики. Весовые коэффициенты выражаются в процентах или в долевых частях, но так, чтобы сумма всех весовых коэффициентов была равна 100%, или соответственно 1. Тогда интегральный показатель качества коммутатора вычисляется как сумма произведений показателей качества отдельных характеристик и соответствующих весовых коэффициентов. Учитывая, что в тестировании мы использовали как управляемые, так и неуправляемые коммутаторы, а сравнивать их друг с другом нельзя хотя бы потому, что эти коммутаторы предназначены для различных целей, весовые коэффициенты характеристик различны для управляемых и неуправляемых коммутаторов.
Определение весового коэффициента каждой характеристики является, пожалуй, наиболее слабым местом в методике сравнения коммутаторов, так как весовые коэффициенты — параметр субъективный. Как говорится, на вкус и цвет товарищей нет. Для повышения объективности методики вычисления качества коммутатора мы провели опрос экспертов в области сетевых технологий, в ходе которого просили их высказать свою точку зрения о важности той или иной характеристики коммутатора и заполнить таблицу с весовыми коэффициентами характеристик. Результаты приведены в табл. 2.
Рассчитанные по описанной выше методике интегральные показатели качества коммутатора использовались при выборе самого качественного коммутатора. Чем выше интегральный показатель качества, тем лучше. Для удобства сравнения и анализа для каждой характеристики коммутатора приводится как абсолютное значение, так и нормированное. Все характеристики, кроме «цены за порт», нормируются на максимальное значение. Цена за порт, наоборот, нормируется на минимальное значение, поскольку чем ниже этот показатель, тем выше интегральный показатель качества. Результаты оценки характеристик и интегральный показатель качества для управляемых коммутаторов представлены в табл. 3, а для неуправляемых коммутаторов — в табл. 4.
|
|
![]()








