Голос времени
Игорь Вениаминович Жарков — руководитель проекта «Речевые технологии» НПФ «Беркут» (www.bercut.ru), кандидат филологических наук (e-mail: Igor.Zharkov@bercut.ru).
Павел Анатольевич Скрелин — профессор кафедры фонетики филологического факультета СПбГУ, заведующий лабораторией экспериментальной фонетики им. Л.В.Щербы, доктор филологических наук (e-mail: Skrelin@phonetics.pu.ru).
Михаил Николаевич Гусев — ведущий инженер-программист НПФ «Беркут», кандидат технических наук (e-mail: Michael.Gusev@bercut.ru).
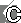 овременная цивилизация, как ни крути, является цивилизацией технологической. Выяснили это фантасты. Подумали-порассуждали, расписали, какой она вообще бывает, построили классификацию, и не одну, — и пришли к выводу, что двинулось человечество, оказывается, по технологическому пути развития. Ну что теперь делать, технологический путь — так технологический. Не возвращаться же с полдороги. Да и достоверных данных о том, что после грехопадения у нас остались какие-то другие варианты, не поступало. Так что давайте принимать это как данность.
овременная цивилизация, как ни крути, является цивилизацией технологической. Выяснили это фантасты. Подумали-порассуждали, расписали, какой она вообще бывает, построили классификацию, и не одну, — и пришли к выводу, что двинулось человечество, оказывается, по технологическому пути развития. Ну что теперь делать, технологический путь — так технологический. Не возвращаться же с полдороги. Да и достоверных данных о том, что после грехопадения у нас остались какие-то другие варианты, не поступало. Так что давайте принимать это как данность.
Эти самые фантасты очень любят, кстати, будущее описывать — как светлое, так и темное. (Кто не может или не хочет — те в параллельные миры или в альтернативное настоящее ударились, но эти нас интересуют мало.) А повествуя о нашем технологическом будущем, они непременно всевозможные устройства там размещают, по большей части изрядно способные к вычислениям и, что нам особенно интересно, изысканно и остроумно мыслящие и изъясняющиеся.
Звуковая коммуникация, как известно, для человеческих существ долгое время оставалась пусть и не единственным, но во всяком случае таким способом общения, который был вне всякой конкуренции. При речевом общении человек меньше устает и делает меньше ошибок, быстрее реагирует, в результате чего скорость и эффективность обмена информацией оказываются выше, чем при использовании других способов — визуального, тактильного (тактильный язык общения в свое время был специально разработан для слепоглухонемых людей), тонально-звукового. Ситуация, возможно, слегка изменилась в последние десять лет, когда использование разнообразных электронных средств переписки стало по-настоящему массовым, хотя это, пожалуй, явление временное, ибо с ростом пропускной способности средств связи и удешевлением трафика, с развитием и удешевлением оконечного оборудования на линиях, с появлением все новых наворотов «за те же деньги» сообщения SMS, общение в среде ICQ и электронная почта будут если и не полностью вытеснены с рынка (читай — из жизни), как в свое время текстовые версии квестов, то, как минимум, весьма основательно ущемлены в своих правах механизмами пересылки видеоданных (для начала, разумеется). Это что касается коммуникации «один на один».
Что уж тут говорить о том, чтобы не на экран выдать интересующую читателя газетную статью или справку о наличии билетов в Крым, а прочитать ее вслух. Разумеется, мы отдаем себе отчет в том, что отправлять письменность на свалку элементарно глупо и уж во всяком случае настолько преждевременно, что пока даже нельзя представить себе эпоху, когда подобный шаг преждевременным быть перестанет. Но факт остается фактом: человеку, идущему по улице, уже сегодня иной раз хочется иметь при себе компьютер/наладонник/коммуникатор и что-нибудь эдакое с ним в этот момент делать — и даже не что-нибудь, а всё, что только можно делать с оным устройством дома или на работе. При этом «иметь при себе» можно уже сейчас — были бы лишние деньги, а вот чтобы использовать на ходу, да еще на всю катушку, всеми возможными способами — с этим пока есть проблемы. По-настоящему удобная клавиатура, например, крайне неудобна в переноске (Мнение субъективное и основанное исключительно на личных представлениях авторов об удобствах), а необходимость смотреть на экран, скажем так, значительно ограничивает свободу передвижения. Выход один: наушник в ухо, микрофон ко рту — и вперед!
Вы скажете, что на свете и так есть много вещей, без которых можно прожить, — и будете абсолютно правы. В философском плане, например. Или в религиозно-аскетическом. Но давайте вспомним, что цивилизация у нас все-таки технологическая. Так что искомая маленькая штучка с гарнитурой рано или поздно обязательно появится. А жалеть денег на то, без чего можно прожить, в современном обществе как-то не принято… Хорошо это или плохо, решать не нам. Но можно смело ставить десять к одному, что, однажды появившись, подобная вещица непременно приживется. И наступит эпоха расцвета речевых технологий.
Под термином «речевые технологии» чаще всего разумеют любые попытки решения нескольких тесно связанных между собой проблем, имеющих отношение к обработке звуковых данных, которые называются человеческой речью на естественном языке. Область речевых технологий — это синтез и распознавание речи, идентификация диктора по голосу, изменение тембра и т.п. Сегодня мы расскажем вам о первой задаче из этого списка.
Так уж сложилось, что для авторов настоящей статьи проблемы синтеза русской речи чужими никак не назовешь, хотя бы уже потому, что они имеют непосредственное отношение к разработке трех семейств программных продуктов, обеспечивающих синтез русской речи по тексту (всего таких семейств пять). Разумеется, в сложившихся условиях требовать от авторов безусловной объективности нереально. В то же время у нас никак не получится писать только о тех разработках, которые знакомы нам исключительно со стороны, — картина будет явно неполной. Но постараемся быть предельно объективными и по возможности избегать чисто оценочных суждений.
Многоликий синтез
 сновные области применения синтетической речи — это телекоммуникации, специализированное оборудование и ПО для слабовидящих, системы оповещения, говорящая бытовая техника. Чтобы у вас не сложилось превратного впечатления о принципиальной закрытости списка возможных сфер приложения синтеза, приведем ряд ярких примеров его использования (особенно плодовитой в этом отношении оказалась Япония (Возможно, причина в том, что именно в этой стране с начала 1980-х годов реализуется государственная программа по созданию компьютеров пятого поколения. Напомним, что один из важных признаков, которыми наделены эти гипотетические устройства, — естественно-языковой интерфейс, где без речевых и лингвистических технологий обойтись невозможно)):
сновные области применения синтетической речи — это телекоммуникации, специализированное оборудование и ПО для слабовидящих, системы оповещения, говорящая бытовая техника. Чтобы у вас не сложилось превратного впечатления о принципиальной закрытости списка возможных сфер приложения синтеза, приведем ряд ярких примеров его использования (особенно плодовитой в этом отношении оказалась Япония (Возможно, причина в том, что именно в этой стране с начала 1980-х годов реализуется государственная программа по созданию компьютеров пятого поколения. Напомним, что один из важных признаков, которыми наделены эти гипотетические устройства, — естественно-языковой интерфейс, где без речевых и лингвистических технологий обойтись невозможно)):
- выпускаются швейные машинки, которые выдают хозяину инструкции по собственной эксплуатации в устной форме;
- производятся калькуляторы, сообщающие результат вычислений голосом;
- объявления об остановках в токийском метро с конца 1970-х годов делает синтезатор;
- во многих лифтах, в гостиницах, аэропортах и магазинах установлены информаторы с использованием синтеза речи — с их помощью транслируются различные объявления и осуществляется аварийное оповещение.
Но синтез речи активно используется, причем зачастую самым неожиданным образом, не только в Японии:
- синтетическая речь применяется при озвучивании персонажей некоторых англоязычных компьютерных игр;
- синтез речи используется в некоторых навигационных системах для автомобилей;
- на бомбардировщиках B-52, состоящих на вооружении ВВС США, установлена система речевого оповещения о возникновении аварийных ситуаций.
Впрочем, очень интересные и неожиданные применения синтеза можно найти и гораздо ближе. Влад Креймер, музыкант из Донецка, который сейчас живет и работает в России, больше года назад впервые в мире выпустил целый альбом электронной музыки (14 дорожек), где весь вокал является чисто синтетическим. «Девушку» зовут Ula. Поет она, к сожалению, только по-английски. При записи диска, по заявлению самого Креймера, живые голоса вообще не использовались. Надо сказать, временами звучит просто здорово. Понятно, что в этот проект вложено огромное количество ручного труда, но какие здесь открываются возможности!
Разумеется, многоликость синтеза проявляется не только в способах его использования. Речевые технологии во всех случаях являются областью наукоемкой, но если говорить о синтетической речи, то результат обычно напрямую зависит от произведенных затрат. Разные разработчики могут применять различные алгоритмы модификации звука, использовать более-менее сложные процедуры обработки текста — но у всех этих алгоритмов и процедур есть свои недостатки, так что количество проблем в итоге оказывается примерно одинаковым. Разумеется, чересчур упрощать технологию не стоит — просто смешно получится. А усложнение, конечно, дает свой эффект, только вот количество никак не желает переходить в качество. Все равно сохраняются большие проблемы с естественностью и осмысленностью звучания в целом.

Обложка диска Just an engine
Но если, например, в плане осмысленности выбора интонации прорыва ждать придется еще очень долго, ибо задача эта является частным случаем классической вечной темы — создания искусственного интеллекта, то в смысле естественности звучания этот самый качественный прорыв, пожалуй, уже достигнут, причем не за счет усложнения технологии, а путем почти механического наращивания объема материала, из которого «лепится» выходной поток речи…
Немного чистой теории. Технологии синтеза речи делятся на две большие группы: синтез формантный, при котором звук формируется «из ничего», складывается из элементарных гармонических колебаний на разных частотах, и синтез компилятивный, при котором используется заранее записанная и тщательно обработанная вручную звуковая база, представляющая собой набор фрагментов живой речи диктора-человека (Иногда синтезом речи называют также макросинтез, заключающийся в простой склейке целых слов и фраз. Макросинтез сегодня используется, например, при передаче стандартных сообщений абонентам сотовой связи («На вашем счете…»), в объявлениях о прибытии и отправлении поездов на многих вокзалах и т.п. В данной статье макросинтез не рассматривается). Эти фрагменты используются в компилятивном синтезе как кирпичики, из которых после соответствующей обработки и скрупулезной стыковки строится выходной звуковой поток.

Виртуальный телевизионный диктор Ananova (разработка агентства PA News Media)
Формантный синтез в лучших своих проявлениях пока что дает качество, которое лишь с определенной натяжкой можно назвать удовлетворительным. В большинстве реально используемых систем применяется синтез компилятивный. Объем звуковой базы (количество фрагментов) может быть самым разным. Существует целый ряд различных методов построения звуковой базы для компилятивного синтеза. В одних моделях используются целые звуки с учетом окружающего контекста — аллофоны (ударный звук «а» в словах «сад», «мать» и «мять», например, должен звучать и действительно звучит совершенно по-разному, то есть в этих словах используются разные аллофоны «а»), в других — половинки звуков (субаллофоны); есть и другие модели. При этом с точки зрения качества синтетической речи между 800 звуковыми фрагментами в субаллофонной модели синтеза и 2500 фрагментами в модели аллофонной (Цифры приблизительные и могут меняться в зависимости от особенностей технологии) нет практически никакой разницы.
Историческая справкаОставляя в стороне не вполне научные и абсолютно недостоверные гипотезы, относящиеся к временам доисторическим, то есть называя своими именами всяческие мифы и легенды (например, об Атлантиде), можно утверждать, что отсчет истории технологий синтеза речи следует начинать с конца XVIII века — с первых попыток сооружения механических устройств, подражающих звукам речевого аппарата человека. Общим для всех этих конструкций было наличие резонаторной камеры, снабженной механизмами, служащими для изменения ее формы с целью имитации резонаторов речевого тракта, постоянно меняющих свою форму в процессе фонации при артикуляции языком, губами и челюстями. В эту камеру тем или иным способом направлялся воздушный поток; работу голосовых связок имитировали струны или упругие язычки. Первые механические машины являлись скорее музыкальными инструментами, чем сложными техническими системами. Можно сказать, почти одновременно (по тем временам десять лет — не срок, поскольку на все мало-мальски сложные технические проекты обычно затрачивалось значительно больше времени) появились система резонаторов Христиана Кратценштейна и говорящий автомат Вольфганга фон Кемпелена. Член Петербургской академии наук Христиан Кратценштейн в 1779 году сконструировал резонаторы, воспроизводящие форму человеческой гортани, которые наглядно демонстрировали физиологические различия между пятью гласными, задающими так называемый треугольник гласных и выполняющими смыслоразличительную функцию в большинстве языков мира (рис. 1).
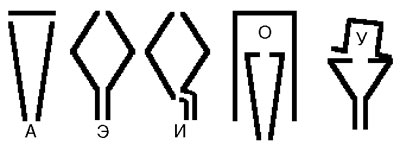
Рис. 1. Акустические резонаторы Кратценштейна Система акустических резонаторов была дополнена вибрирующими язычками, колеблющимися под действием воздушного потока, и представляла собой действующую модель речеобразования, позволявшую получить звук, приближенный к человеческой речи. Создатель знаменитой шахматной машины «Турок», вошедшей в историю как яркий пример технического мошенничества, Вольфганг фон Кемпелен был, однако, если разобраться, не только жуликом и шарлатаном — в числе менее известных его изобретений есть чрезвычайно интересный синтезатор речи, автомат, который способен был выдавать «на гора» целые предложения (рис. 2).
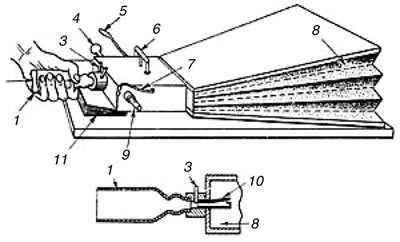
Рис. 2. Устройство говорящей машины Кемпелена: Резонатором служила гибкая кожаная трубка, которой управлял оператор. К числу интересных особенностей аппарата следует отнести наличие отверстий, эмулирующих носовые полости, и свистков, которые имитировали щелевые звуки (прежде всего свистящие и шипящие). Машина эта могла воспроизводить не только гласные, но и девятнадцать согласных звуков. Впрочем, хватит о совсем уж седой древности. Отметим лишь, что история европейской, а впоследствии и американской технической мысли в области речевых технологий с этих изобретений только началась. Всё более новые и всё более сложные механические синтезаторы регулярно появлялись примерно до середины XX века. Безусловно, с точки зрения современного человека, единственным достоинством этих механических кунштюков можно признать разве что свойство устойчиво работать в условиях аварии на электрической подстанции. Однако опасность аварий и катастроф никогда не становилась достаточной сдерживающей силой на пути технического прогресса. В 1920-х годах начались первые опыты по синтезу речи электронными средствами. Сотрудник Bell Labs Хумер Дадли в 1928 году изобрел водер — первую электронную систему, способную синтезировать понятные предложения. Водер состоит из двух независимых генераторов (рис. 3), один из которых обеспечивает гармонические колебания для гласных и звонких согласных, а другой создает шум за счет имитации процессов турбулентности в речевом тракте. Водер позволял получать довольно качественную речь с высоким уровнем разборчивости.
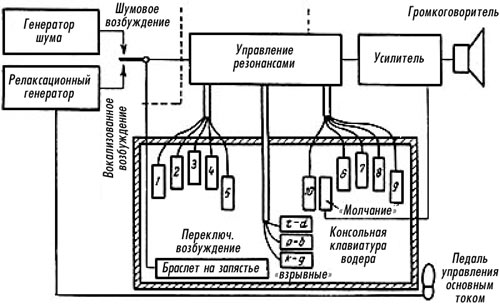
Рис. 3. Водер Дадли Отметим, что не стояла на месте со времен Кратценштейна и отечественная научная мысль. Достаточно упомянуть синтезатор звуков АНС, который был создан Е.А.Мурзиным в 1938 году. В этом устройстве речь генерировалась с помощью рядов Фурье как сумма гармоник — элементарных спектральных составляющих, то есть чистых тонов. Банк тонов был записан на покрытый фотоэмульсией стеклянный диск. Схема синтезатора Мурзина изображена на рис. 4.
Рис. 4. Синтезатор АНС Е.А.Мурзина: Следующий исторический шаг был сделан в 1978 году компанией Texas Instruments. Синтезатор, сконструированный в стенах этой фирмы, открыл в синтезе речи цифровую эпоху. Это устройство позволяло генерировать около 200 слов. При генерации выходного сигнала использовалось преобразование на основе коэффициентов линейного предсказания. Примерно то же самое время, конец 70-х годов, можно считать отправной точкой современного этапа исследований в области синтеза речи на кафедре фонетики филологического факультета ЛГУ. В конце 80-х годов на основе накопленного опыта стало возможным развитие проекта системы автоматического синтеза речи по произвольному русскому тексту. В 1989 году был изготовлен первый образец компилятивного синтеза. В 1990-х годах работы в области синтеза речи по тексту проводились в СПбГУ чрезвычайно активно, дав жизнь трем проектам компилятивного синтеза русской речи. |
||
А вот дальше разница появляется — дальше работает закономерность, которую можно сформулировать следующим образом: чем больше фрагментов в базе, тем каждый из них будет в среднем меньше уродоваться в процессе модификации и тем больше в выходном звуке останется от звука исходного — от голоса живого человека.
Необходимо учитывать, что подготовка звуковой базы — это процесс, который выполняется прежде всего вручную (по крайней мере частично). Соответственно затраты на изготовление базы растут в обычной арифметической прогрессии. Чем больше денег вложено, тем лучше результат. Наверное, всем доводилось слышать «говорящие головы» — виртуальных дикторов (во всяком случае, все знают об их существовании), которые ведут назначенные им речи настолько хорошо и гладко, что им даже выпуски новостей на ТВ доверяют. Так вот: объем звуковых баз, которые используются в этих проектах, составляет несколько миллионов (!) сегментов.
В России (и в целом для русского языка) подобных проектов, насколько нам известно, пока нет.
Да и вообще в России пока много чего нет. Нет, например, такого поселка, какой построила в Бельгии компания L&H. Там живут и работают несколько тысяч человек, которые ничем другим, кроме речевых технологий, не занимаются; там исправно функционируют лифты с голосовым управлением (Справедливости ради следует отметить, что одна наша знакомая все же имеет опыт застревания в таком лифте; ее русский акцент оказался непреодолимым препятствием для системы распознавания команд), установлены голосовые пароли на вход в служебные помещения и т.п. Это своего рода уголок будущего, призванный продемонстрировать огромный потенциал отрасли.
Спрос — двигатель прогресса
 ачем современному обществу в целом и отдельному человеку в частности может понадобиться синтез речи? Или, иными словами, есть ли на него спрос? Постараемся ответить на этот вопрос, не ограничиваясь кратким «конечно, есть».
ачем современному обществу в целом и отдельному человеку в частности может понадобиться синтез речи? Или, иными словами, есть ли на него спрос? Постараемся ответить на этот вопрос, не ограничиваясь кратким «конечно, есть».
Россия в последние годы резво движется по весьма своеобразному пути — от социалистического прошлого к развитому капиталистическому будущему, хотя нам вряд ли удалось миновать на этой дороге фактический статус страны третьего мира. Особенно бодрым выглядит это движение в периоды высокого уровня цен на энергоносители, а сейчас именно такой период.
А жизнь в развитом обществе — это как у классика, утверждавшего, что все счастливые семьи похожи друг на друга. Ни в чем не отставать от соседа — это сегодня стало не только бытовым, но и геополитическим принципом. Если в США, например, «заговорил» холодильник, следует ожидать, что скоро эти полезные устройства обретут дар речи повсюду, за исключением тех слаборазвитых регионов, где они до сих пор встречаются крайне редко и считаются элементом роскоши. Соответственно, чтобы выяснить, какая участь в ближайшем будущем ожидает речевые технологии в России, нужно прежде всего ознакомиться с западным опытом.
В развитых странах синтезом речи сегодня никого не удивишь (ниже мы более подробно остановимся на основных и наиболее распространенных областях его применения). Способы приложения речевых технологий давно уже стихийно не формируются. Слишком серьезные деньги вкладываются в отрасль, чтобы пустить все на самотек. В этом плане особый интерес вызывает ежегодная лондонская конференция, специализирующаяся на речевых разработках ведущих мировых производителей, которая называется Voice World. Это совершенно особое мероприятие представляет собой отнюдь не научную конференцию, не совещание разработчиков по техническим вопросам и не отраслевую выставку достижений (хотя выставка в рамках Voice World тоже есть). Это — конференция для специалистов по маркетингу, где обсуждаются основные стратегические пути развития отрасли в ближайшей перспективе, и если называть вещи своими именами, нужно сказать, что именно здесь можно узнать, какие новые потребности будут создаваться и активно навязываться обществу. Резюме — крайне поучительное мероприятие во всех смыслах.
Телекоммуникации
Услуги, предоставляемые синтетическим голосом по телефону, отличаются большим разнообразием — здесь и прогноз погоды, и расписание авиарейсов, и курсы валют, и чтение голосом электронной корреспонденции… Даже службу секса по телефону кое-кто пытался организовать, правда без особого успеха, — но, может, потому и не вышло, что не стали владельцы скрывать синтетическую природу своей «барышни».
На 90% запросов к любым информационно-справочным системам в той или иной форме способен отвечать компьютер. Это и различная справочная информация, и сведения о состоянии счета, курсах валют, погоде, и целые статьи из энциклопедий. Список этот можно продолжать до бесконечности. Здесь важно подчеркнуть, что с особенной полнотой достоинства систем, использующих синтез речи, проявляются в тех ситуациях, когда информация периодически обновляется (еженедельно, ежедневно, ежечасно). Например, для услуги, подразумевающей чтение абоненту сказок, тостов, анекдотов, гороскопов и пр. или получение им информации, связанной с его местоположением, необходимо оперативно изменять либо модифицировать предоставляемые данные. Такие услуги могут быть интересны потребителям лишь в случае безусловной актуальности информации и ее новизны. Поэтому в подобных случаях синтетическая речь является наиболее естественным и удобным интерфейсом.
В России на данный момент положение дел с применением синтеза речи в телефонии намного более скромное. Тем не менее такое применение уже существует и появляются всё новые и новые. Пожалуй, самый масштабный проект такого рода — доступ, организованный некоторыми операторами, для абонентов сотовой связи к своим почтовым ящикам на сервере @mail.ru. Человек, находящийся вдали от своего компьютера, всегда может послушать, что ему прислали на электронный адрес, и ему для этого ничего не понадобится, кроме обычного сотового телефона и символической суммы денег на счете.
Есть и другие интересные телекоммуникационные проекты. Скажем, уже два года в столичных сотовых сетях функционирует служба рассылки синтетических звуковых сообщений для абонентов под названием «Телега», позволяющая озвучить набранный пользователем произвольный текст. При этом можно выбрать один из четырех голосов. Круг операторов, предоставляющих доступ к этой службе, хотя и не быстро, но неуклонно расширяется.
Следует также упомянуть специализированные голосовые порталы в Сети, центры обработки звонков со встроенной поддержкой русского синтеза, другие продукты, поддерживающие синтез в рамках концепции Unified Messaging… Все это в России уже есть и работает!
Проекты социальной значимости
Один из значимых отличительных признаков цивилизованного общества — забота о людях с физическими недостатками. На программы реабилитации инвалидов в развитых странах выделяются огромные деньги. Государственными и негосударственными благотворительными фондами хорошо финансируются в числе прочих и проекты, направленные на социальную адаптацию слепых и немых людей, а это, как нетрудно догадаться, прежде всего касается разработок в области речевых технологий. Подход «сколько же есть на свете вещей, без которых можно прожить» к данному случаю отношения не имеет.
Особенно активно проводятся работы по созданию читающих машин для слепых и слабовидящих. Как правило, эта функциональность дополняется соответствующими устройствами ввода данных (специальной клавиатурой, сканером со специализированным ПО для распознавания текста и т.п.) и программным обеспечением распознавания речи, которое заменяет собой привычный графический интерфейс и обеспечивает наиболее удобную для слепых и слабовидящих форму интерактивности. В результате получается полноценное автоматизированное рабочее место.
Для общения немых с обычными людьми предназначены портативные устройства синтеза речи, в которых сообщение набирается на клавиатуре. В Финляндии первый образец такого устройства был создан уже в 1977 году.
Сегодня устройства для слепых (слабовидящих) и немых, обладающие самой разнообразной функциональностью, пользуются большой популярностью во всех развитых странах. Одно из последних нововведений подобного рода — говорящие банкоматы Northern Bank.
Разработки для слабовидящих существуют и в России, их очень любят показывать по федеральным телевизионным каналам, но здесь есть две больших проблемы. Во-первых, качество отечественных программно-аппаратных комплексов для слепых и слабовидящих значительно уступает западным стандартам, а во-вторых, региональные организации ВОС отнюдь не купаются в деньгах и не имеют возможности обеспечить оборудованием, о котором идет речь, сколь-нибудь значительный процент тех, кто в нем нуждается.

Урок информатики в интернате для слепых детей. Компьютеры оснащены брайлевскими дисплеями и специальным программным обеспечением
Для решения указанных проблем в современных российских условиях требуется активная помощь государства, и прежде всего финансовая, в двух основных направлениях:
- Развитие исследований, направленных на повышение качества собственно синтеза речи и интеллектуальной обработки текстовой информации. Содержание соответствующих научных проектов можно определить как фундаментальное с непосредственным выходом в прикладную сферу. Но, увы, хотя некоторые сдвиги в финансировании фундаментальных исследований у нас сегодня и наметились, радикальными их не назовешь — больше подошел бы эпитет «символические». Гомеопатическими инъекциями науку не спасешь.
- Целевые бюджетные расходы на социальную реабилитацию слепых (слабовидящих) и немых. Соответствующие федеральные программы в России есть, но и здесь критичен прежде всего объем их финансирования.
Не стоит забывать также и о том, что русский язык — не единственный в России. Разработки в области речевых технологий могут быть очень привлекательными для тех, кто заинтересован в сохранении и развитии культуры народов России. Работы по синтезу речи для татарского языка ведутся в Казани уже несколько лет. Полагаем, что и представители других национально-культурных автономий со временем заинтересуются открывающимися в этой сфере возможностями. «Локализовать» русскую систему синтеза для языка коми, разумеется, непросто, но на разработку с нуля это никак не похоже. Основными производителями речевых технологий для языков народов России будут выступать те же самые российские компании, которые занимаются синтезом и распознаванием речи на материале русского языка.
Еще одно интересное направление использования синтезаторов речи связано с обучением языку. Еще в конце 1970-х годов в США было выпущено устройство «Speak and Spell» для маленьких детей, обучающихся грамоте. Устройство это умело произносить слова и оценивать правильность их буквенного написания ребенком. Сегодня разработано великое множество функционально схожих с ним устройств, предназначенных как для преподавания взрослым практической фонетики иностранного языка, так и для обучения детей родной речи. Если вспомнить о несчетном количестве малокомплектных сельских школ в России, то проблема разработки и внедрения подобных обучающих средств сразу приобретает социальное звучание.
Еще раз подчеркнем, что список возможных применений синтеза речи потенциально бесконечен: начинается он с наиболее очевидных пунктов (телекоммуникации, социальная сфера), которым мы уделили в нашей статье основное внимание, но вряд ли заканчивается даже такой экзотикой, как виртуальный вокал. Завершая этот краткий обзор, можно сделать вывод о том, что в общем случае синтез речи может применяться во всех ситуациях, когда получателем информации является человек и предоставить ему вербальную (то есть выражаемую словами) информацию целесообразно в устной форме, причем каждому типу приложений, по-видимому, соответствует конкретный приемлемый уровень качества.
Предложение
 ассмотрев спрос (пусть пока во многом латентный, но это дело времени) на русскоязычные системы синтеза речи, было бы нелогично оставить за рамками предложение, фактически существующее сегодня на рынке.
ассмотрев спрос (пусть пока во многом латентный, но это дело времени) на русскоязычные системы синтеза речи, было бы нелогично оставить за рамками предложение, фактически существующее сегодня на рынке.
Восток—Запад
Здесь все достаточно просто. Более или менее серьезные разработки синтеза русской речи можно пересчитать по пальцам: если не одной, то двух рук точно хватит. Прежде всего системы русского синтеза следует разделить по критерию «страна происхождения». На рынке представлены две категории производителей: крупные западные фирмы, специализирующиеся в области речевых технологий, для которых русский язык является «одним из», и фирмы отечественные или почти отечественные, которые занимаются прежде всего русским языком. (Сразу оговоримся, что западных компаний, которые представлены на рынке полновесными русскоязычными продуктами, включенными в прейскуранты, а не только декларациями и наличием доступных образцов синтеза — чисто практическая разница здесь немалая, — с уверенностью можно назвать всего две.)
Разумеется, если сравнить общую картину разработок и исследований в сфере речевых технологий, наблюдаемую сегодня в России, с аналогичной картиной (для английского языка), скажем, в США, оптимизма неизбежно поубавится. В Америке соответствующие лаборатории и группы существуют практически в каждом университете — в итоге созданы несколько сот разработок, причем у всех имеются какие-то действующие модели. И естественно, есть десятки фирм, продвигающих свои продукты на рынке.
А у нас в России — три-четыре университетские лаборатории да пяток компаний, хоть каким-то боком причастных к речевым технологиям. Продуктов в области синтеза речи и того меньше.
Но, как ни парадоксально это звучит, сравнение разработок и перспектив в целом получается явно в пользу производителя отечественного. Здесь прежде всего следует рассмотреть три фактора:
- Приоритетность поддержки русского языка. Хотя технологии синтеза речи постепенно приближаются к той стадии развития, когда сама технология станет универсальной и не будет зависеть от языка, фактически мы еще далеки от этой цели, причем унификация программного обеспечения здесь возможна и достижима уже сегодня, но вот в том, что касается подготовки данных (звуковые базы, представление фонетического строя конкретного языка, грамматика, словарь и т.д.), ни о какой серьезной независимости от языка пока говорить не приходится — а это объем работ и затрат, сопоставимый, как минимум, с разработкой ПО. И если для российских разработчиков русский язык имеет наивысший приоритет, а поддержка других языков носит вторичный характер, то для западных производителей русский язык фактически имеет статус второстепенного. К примеру, для продуктов ScanSoft, безусловного мирового лидера по части затрат и по размаху деятельности в области речевых технологий, хронологический порядковый номер русского языка — 46-й, и это находит свое выражение в целом ряде негативных обстоятельств, например в большой задержке выпуска русских версий продуктов по сравнению с версиями на других языках.
- Априорное ценовое преимущество. Объясняется оно очень просто — намного более низким уровнем расходов на производство, в основном за счет, мягко говоря, значительной разницы в оплате труда. При этом речевые разработки, как в высшей степени наукоемкое направление, практически не подпадают под действие общего механизма сокращения затрат на производство за счет его переноса в страны с дешевой рабочей силой, применяемого европейскими и американскими компаниями. Показательна позиция все той же компании ScanSoft: руководство этой фирмы никак не желает устанавливать особые цены для российского рынка. Судя по всему, установка эта принципиальная. В результате цены «кусаются» — можете проверить сами.
- Отечественная научная школа. Не последнюю роль в этом вопросе играют и серьезные научные традиции, огромный опыт, накопленный в Советском Союзе в области экспериментальной фонетики (прежде всего речь идет о ленинградской и московской фонетических школах), который с точки зрения интересующих нас вопросов можно рассматривать как очень серьезный задел. Конечно, после развала СССР темпы накопления научных знаний основательно снизились, но, смеем вас заверить, в области фонетики у нас пока все не так плохо, как во многих других научных сферах.
В дополнение можно вспомнить о нашем непосредственном участии в разработке русской версии синтезатора Digalo. В 1994-96 годах совместно с CNET (France Telecom) и Центром цифровой обработки сигналов университета телекоммуникаций им. Бонч-Бруевича была создана система синтеза русской речи RusVox, на основе которой чуть позже была разработана русская версия синтезатора русской речи по тексту Digalo — самого известного и весьма качественного даже по современным меркам продукта из имеющих отношение к русскому языку. Если вы когда-нибудь интересовались русским синтезом речи, вам вряд ли незнаком голос Digalo (виртуального диктора зовут Николай). Да и в компании L&H (ее преемником в настоящее время выступает ScanSoft) русским языком занимались в основном «наши люди», получившие образование и некоторое время работавшие в СПбГУ.
Пророки в своем отечестве
Предложение по системам синтеза речи на внутреннем рынке представлено разработками компаний «Сакрамент» (Белоруссия, www.sakrament.com), НПФ «Беркут» (Санкт-Петербург, www.bercut.ru), «Центр речевых технологий» (Санкт-Петербург, www.speechpro.ru) (Под вопросом включение в этот список производителей московского Клуба голосовых технологий (на научной базе МГУ), который несколько лет назад выпустил продукт «Говорящая мышь». Однако на данный момент этот продукт отсутствует на рынке.).
Явного лидера здесь нет. А потому стоит вспомнить один из приведенных выше тезисов о том, что различные по алгоритмам обработки звука и процедурам подготовки данных технологии синтеза дают сегодня вполне сопоставимые, близкие по качеству результаты. Поле для конкуренции лежит главным образом в сфере специализации продуктов, то есть их «заточки» под определенное применение, в наборе дополнительных сервисных функций, а также в более-менее интеллектуальной работе с текстом, обеспечивающей расстановку пауз и правильное интонирование выходного речевого потока.
Принимая во внимание малую насыщенность рынка подобными продуктами, с одной стороны, и обилие областей их возможного применения — с другой, нельзя не сделать вывод о том, что конкуренция между производителями систем синтеза русской речи в настоящий момент скорее миф, чем реальность.
Звуковой поток, заранее рассчитанный на передачу по телефонным каналам, будет заведомо более приемлемым и разборчивым в телефонной трубке, чем более чистый и плавный голос, сформированный в расчете на передачу по каналу коммуникации с частотой дискретизации 32 кГц (это лучше, чем FM-радио, но хуже по качеству звука, чем аудио-CD; в телефонном сигнале частота дискретизации в четыре раза ниже) — и наоборот.
А если принять во внимание то обстоятельство, что каждый тип устройств обладает своими уникальными характеристиками канала (частота дискретизации — лишь одна из них, причем далеко не самая важная), то очевидно, что для каждого типа устройств желательно иметь особую версию системы синтеза, даже если все отличия этой версии сведутся лишь к наложению «правильных» частотных фильтров. С учетом сопоставимого качества выходного сигнала в разных системах синтеза получается, что лучшая система синтеза в каждом конкретном случае — это та, что наиболее удачно специализирована для данного применения.
Опираясь на собственный опыт, мы можем определенно утверждать, что специализация синтезатора речи — процесс неизбежный, если вы хотите получить качественный коммерческий продукт. Скажем, разработка НПФ «Беркут» под рабочим названием EyesFree, которая должна появиться на рынке телекоммуникаций до конца текущего года в составе ряда продуктов компании, специализирована для применения в телефонных каналах связи с учетом особенностей GSM-кодирования сигнала; для других, «внетелефонных», применений будут выпускаться отдельные версии EyesFree. К похожим выводам, судя по всему, пришли и специалисты ScanSoft, выделившие синтезаторы речи для использования в телефонии в отдельную ветку продуктов. О сильных и слабых местах синтеза в системе EyesFree можно будет уверенно говорить лишь после начала ее эксплуатации в реальных условиях.
Чуть более подробно остановимся на двух отечественных разработках, уже имеющих опыт такой эксплуатации. Очень активно ведет себя на рынке белорусская компания «Сакрамент», которая уже выпустила целый ряд версий своей системы синтеза, предназначенных для различных применений: для PC, для обычной (не GSM-) телефонии, для платформы Symbian, для PDA. Кроме того, следует отметить, что «Сакрамент» очень активно развивается в сторону расширения сервисной функциональности своей продукции. В частности, пользователю предлагается выбор из десяти разных голосов (правда, на наш взгляд, три голоса из десяти звучат намного лучше остальных). Существует также утилита, позволяющая пользователю записать звуковую базу для синтеза на основе собственного голоса, но следует предупредить: затея эта довольно рискованная, поскольку времени требует много, а результат предсказуемым никак не назовешь, коль скоро среди «стандартных» голосов больше половины «проблемных»… Впрочем, есть к «Сакраменту» и другие вопросы. Методы модификации речевого сигнала, которые применяются в синтезаторах этой фирмы, построены на идеях и представлениях конца 1960-х годов. Пожалуй, их следует признать морально устаревшими, и это местами очень хорошо слышно даже неспециалисту. Будет ли что-нибудь меняться в этом смысле в дальнейшем, сказать сложно. По крайней мере заметных сдвигов в последней версии (3.0) на первый взгляд не наблюдается ни в сравнении с предыдущей версией 2.5, ни даже с версией 1.5.
Синтезатор «Оратор» (разработка «Центра речевых технологий») позиционируется как специализированный для решения трех задач: для использования в системах оповещения, в игрушках и в ПО для чтения электронных текстов. Образцы синтеза, представленные на сайте ЦРТ, следует признать вполне удачными. В системе «Оратор» функционирует также довольно приличный модуль обработки текста. Скромно заметим, что его разработка велась с использованием акцентно-интонационного транскриптора Udar, к которому имеют самое прямое отношение некоторые из авторов настоящей статьи. При работе над «Оратором» за основу была взята версия 1995 года, более поздняя по сравнению с той, что была использована в работе над RusVox (прообраз русской версии Digalo).
Что касается перспектив технологий синтеза речи в России, то на говорящую по-русски анимационную голову на телеэкране в обозримом будущем рассчитывать не стоит, какими бы непрофессиональными ни выглядели в последнее время обычные («биологические») дикторы.
Хочется, конечно, всего и сразу. Но надо понимать, что так не бывает. Любая система синтеза речи сама по себе — полуфабрикат, который нуждается в хорошей приправе и в технологически выдержанном разогреве, а там и до подачи на стол не далеко. Рынок сейчас явно оживился. Рискнем предположить, что в ближайшем будущем следует ожидать прорыва готовых разработок к широким потребительским кругам. Мы называем эти разработки готовыми, поскольку их качество достаточно высокое для того, чтобы начать ими пользоваться. Скорее всего, нас ожидает появление говорящей бытовой техники, синтетических телефонных автоответчиков и информаторов, информационно-развлекательных телефонных служб и т.п. «Догнать и перегнать Америку» мы в очередной раз не сумели — пока не сумели. Что ж, пойдем следом за нею.








