Средства бизнес-анализа в SQL Server 2005
Часть 3. Модификация структуры многомерных баз данных
Развертывание аналитических решений
Действия после тестового развертывания
Создание ключевых показателей производительности
Добавление вычисляемых значений
Книги о новых версиях продуктов и о новых технологиях..
Во второй части этой статьи (см. КомпьютерПресс № 3’2005) мы обсудили средства создания OLAP-кубов в аналитических службах SQL Server 2005. Сегодня мы подробнее остановимся на некоторых новых возможностях, доступных авторам решений на основе аналитических служб данной СУБД.
Развертывание аналитических решений
 ернувшись к примеру создания OLAP-куба, рассмотренному во второй части данной статьи, отметим несколько особенностей развертывания подобных решений. До выбора опции Deploy из контекстного меню проекта аналитического решения в Business Intelligence Development Studio все манипуляции со структурой будущего куба приводят к созданию описания структуры измерений и самого куба в виде XML-файлов на компьютере, используемом для разработки (напомним, что созданный таким образом набор кубов и измерений, определенных в SQL Server 2005, называется универсальной моделью измерений (Unified Dimensional Model, UDM)). По существу, на этапе создания UDM разработчику даже не требуется доступ к серверу аналитических служб — первое обращение к нему происходит только на этапе развертывания.
ернувшись к примеру создания OLAP-куба, рассмотренному во второй части данной статьи, отметим несколько особенностей развертывания подобных решений. До выбора опции Deploy из контекстного меню проекта аналитического решения в Business Intelligence Development Studio все манипуляции со структурой будущего куба приводят к созданию описания структуры измерений и самого куба в виде XML-файлов на компьютере, используемом для разработки (напомним, что созданный таким образом набор кубов и измерений, определенных в SQL Server 2005, называется универсальной моделью измерений (Unified Dimensional Model, UDM)). По существу, на этапе создания UDM разработчику даже не требуется доступ к серверу аналитических служб — первое обращение к нему происходит только на этапе развертывания.
Управление процессом развертывания проекта на целевом сервере аналитических служб подразумевает выбор целевого сервера для развертывания — можно создать несколько конфигураций для разных типов развертывания, например для тестового сервера или для промышленной эксплуатации готового решения. При этом при развертывании можно воспользоваться инструментами отладки, такими как браузер кубов, отладчик MDX (О языке MDX (MultiDimensional Expressions) рассказывается в статье «Введение в OLAP», опубликованной несколько лет назад в нашем журнале. Вы сможете найти эти материалы на прилагающемся к журналу компакт-диске) -скриптов или браузер ключевых показателей производительности (рис. 1).
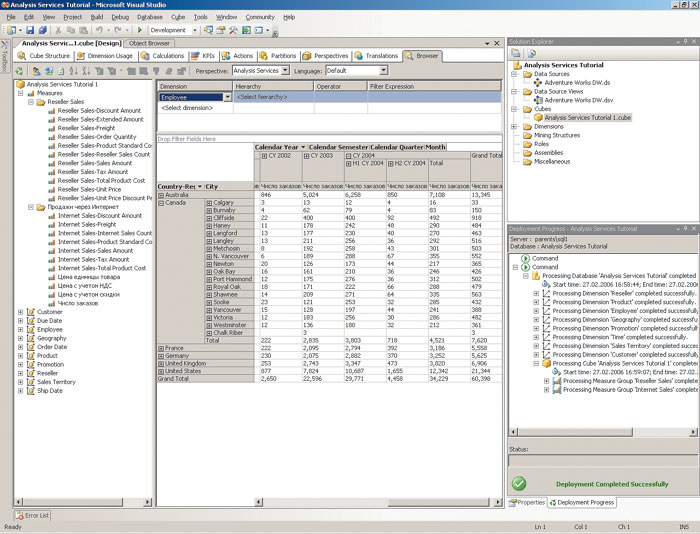
Рис. 1. Результат тестового развертывания
Во второй части статьи мы рассмотрели создание многомерной базы данных на основе уже имеющегося реляционного хранилища. Такой способ характерен для предыдущей версии аналитических служб, а также для других OLAP-платформ. Отметим, что аналитические службы SQL Server 2005 позволяют создавать кубы и альтернативным методом — с помощью опции Design BI model without data source мастера Cube Wizard. В данном случае мастер сгенерирует описание структуры измерений и кубов на основе шаблона для выбранной предметной области (шаблоны могут быть поставлены как компанией Microsoft, так и другими разработчиками программного обеспечения), а при необходимости — реляционную структуру данных и пакеты служб интеграции. Кроме того, можно комбинировать указанные подходы, например использовать готовые шаблоны для создания только некоторых измерений (в частности, измерений, содержащих данные о дате и времени).
Действия после тестового развертывания
 осле тестового развертывания и проверки соответствия полученных результатов ожидаемым (например, на небольшом тестовом наборе данных) обычно производятся дальнейшие модификации проекта. В частности, на этом этапе можно осуществить модификацию структуры куба, например определить связи между атрибутами (это нередко требуется при использовании исходного хранилища данных, спроектированного с применением схемы «снежинка»), произвести измерения на основе данных, содержащихся в таблице фактов (такие измерения часто нужны для группировки данных), определить при необходимости соотношение «многие ко многим» между измерениями и группами мер, гранулярность для групп измерений (типичный пример — определение гранулярности сумм продаж за месяц из-за наличия ежемесячной или ежеквартальной нормы продаж и отсутствия ежедневной).
осле тестового развертывания и проверки соответствия полученных результатов ожидаемым (например, на небольшом тестовом наборе данных) обычно производятся дальнейшие модификации проекта. В частности, на этом этапе можно осуществить модификацию структуры куба, например определить связи между атрибутами (это нередко требуется при использовании исходного хранилища данных, спроектированного с применением схемы «снежинка»), произвести измерения на основе данных, содержащихся в таблице фактов (такие измерения часто нужны для группировки данных), определить при необходимости соотношение «многие ко многим» между измерениями и группами мер, гранулярность для групп измерений (типичный пример — определение гранулярности сумм продаж за месяц из-за наличия ежемесячной или ежеквартальной нормы продаж и отсутствия ежедневной).
|
Книги о новых версиях продуктов и о новых технологиях (особенно хорошие) обычно выпускаются не сразу после их появления, а спустя некоторое время. Следовательно, не стоит рассчитывать на быструю доступность хороших книг о новой версии SQL Server. Но во многих случаях при создании решений на базе этой СУБД может пригодиться издание, посвященное предыдущей версии, например выпущенная издательством «Вильямс» книга «Профессиональное руководcтво по SQL Server. Структура и реализация» Кена Хендерсона (опытные разработчики, возможно, помнят великолепные книги этого автора, посвященные резработке приложений с базами данных с помощью Delphi). Отметим, что в этом издании уделяется много внимания не столько применению SQL Server, сколько его архитектуре, внутренней организации, недокументированным средствам, а также технологиям, на которых основана работа этой СУБД и ее составных частей. Своей фундаментальностью подхода и глубиной рассмотрения функционирования SQL Server данная книга заметно отличается от многочиcленных (хотя, безусловно, тоже нужных) пособий для администраторов и разработчиков приложений и является, похоже, единственной из существующих книг подобного содержания, переведенной на русский язык. Правда, лично я все же не рискнула бы называть SQL Server «программой», но это уже вопрос совпадения моих субъективных взглядов со взглядами редактора русского перевода. |
||

На этом же этапе в проект добавляются ключевые показатели производительности (Key Performance Indicators), действия при наступлении каких-либо событий (Actions), вычисляемые значения (Calculations), различные проекции OLAP-данных для разных групп пользователей (Perspectives) и локализованные имена объектов (Translations) для пользователей, применяющих разные языковые настройки и типы валют. Помимо перечисленных составляющих, связанных с предметной областью, на этом же этапе принимаются решения о физических характеристиках, влияющих на производительность обработки данных, таких как разбиение многомерной БД на разделы и выбор режима упреждающего кэширования.
Ниже мы рассмотрим некоторые примеры подобных модификаций проекта решения на базе аналитических служб.
Создание ключевых показателей производительности
Ключевые показатели производительности (Key Performance Indicator, KPI) — это описания проводимых сервером вычислений, требующихся для оценки эффективности бизнеса. Эти показатели можно отображать в отчетах или в приложениях.
В аналитических службах SQL Server 2005 показатели производительности обладают следующими характеристиками:
- значение — можно использовать меру куба или вычисляемое значение на основе мер;
- целевое значение, которого следует достичь, — можно применять численное значение или выражение MDX;
- состояние — используется выражение MDX, результатом которого является величина в диапазоне от –1 (очень плохо) до +1 (очень хорошо);
- тенденция — применяется выражение MDX для оценки текущей динамики изменения значения.
В качестве простейшего примера рассмотрим добавление ключевого показателя производительности к готовому кубу о продажах различных товаров, содержащемуся в одном из примеров в комплекте поставки SQL Server (соответствующий проект можно найти в каталоге Microsoft SQL Server\90\Samples\Analysis Services\Tutorials\Lesson7). Предположим, достижение объема Интернет-продаж (соответствующая мера называется [Internet Sales-Sales Amount]) в 40 млн. долл. является отличным показателем, а в 20 млн. долл. — удовлетворительным. Для создания соответствующего показателя производительности, отражающего состояние объема Интернет-продаж, нам следует открыть закладку KPIs, перенести название меры в поле Value Expression (Значение), выбрать тип индикатора для определения состояния показателя из списка Status Indicator (к примеру, Traffic Light) и добавить код на языке MDX в поле Status Expression для определения состояния индикатора при различных значениях объема Интернет-продаж (рис. 2), например:
Case
When [Measures].[Internet Sales-Sales Amount] > 40000000 Then 1
When [Measures].[Internet Sales-Sales Amount] > 20000000 and
[Measures].[Internet Sales-Sales Amount] <=40000000 Then 0
Else -1
End
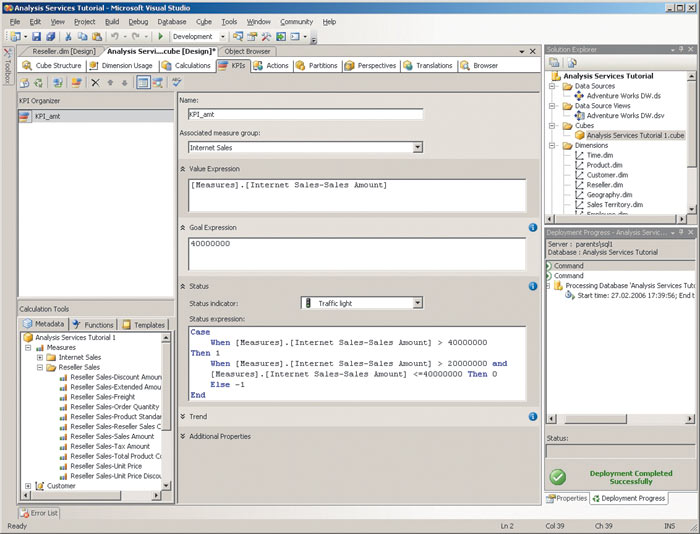
Рис. 2. Создание показателя производительности
Далее следует повторно перенести куб на сервер аналитических служб, заново осуществить соединение с кубом и переключиться на отображение ключевых показателей производительности с помощью кнопки Browser View на закладке KPIs (рис. 3).
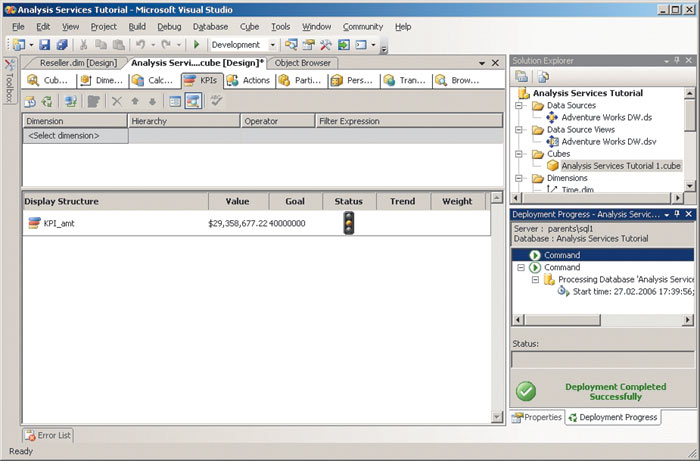
Рис. 3. Отображение показателя производительности
Созданный нами показатель производительности вполне корректно отображает тот факт, что объем Интернет-продаж уже превысил 20 млн. долл., но пока не достиг 40 млн. долл.
Добавление вычисляемых значений
Значения, вычисляемые на основе имеющихся данных куба, могут быть добавлены и к мерам, и к измерениям. В кубах хранятся правила вычисления этих значений, но не сами значения, хотя последние в настоящей версии аналитических служб кэшируются на сервере, что позволяет не вычислять их повторно в случае, если они потребуются нескольким пользователям.
В качестве простейшего примера создания вычисляемого значения рассмотрим нахождение суммы продаж реселлеров и Интернет-продаж. Для этого следует перейти на закладку Calculations и нажать кнопку New Calculated Member, что приведет к появлению формы для описания вычисляемого значения.
При заполнении данной формы следует указать имя вычисляемого значения (пусть это будет «[Общая сумма продаж]»), выражение для его вычисления (при конструировании выражения можно перетаскивать мышью в соответствующее поле имена имеющихся объектов структуры куба), формат для отображения в браузере, цвет шрифта и фона ячеек (в данном случае это будет синий текст на желтом фоне), гарнитуру и размер шрифта. Кроме того, в поле Non-empty behavior можно указать, при отсутствии каких значений измерений для данной ячейки вычисляемое выражение должно быть пустым (рис. 4).
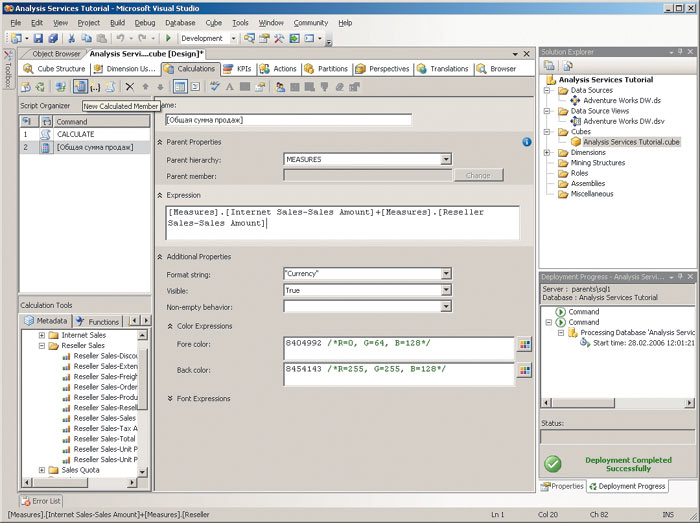
Рис. 4. Добавление вычисляемого значения
С помощью кнопки Script View той же формы можно просмотреть полученный MDX-скрипт (рис. 5).
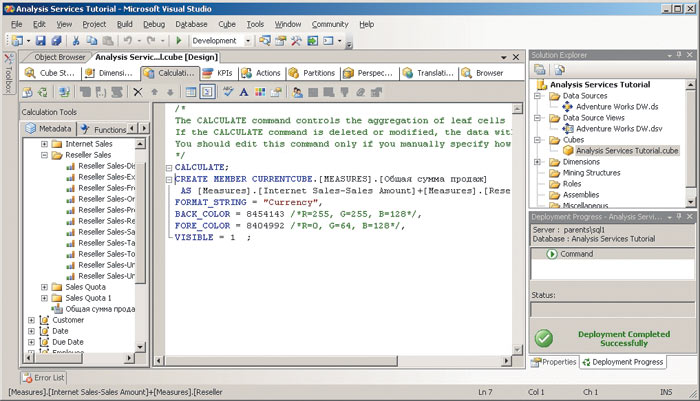
Рис. 5. Просмотр MDX-скрипта
После повторного развертывания и соединения с кубом можно отобразить в браузере вычисляемое значение (рис. 6).
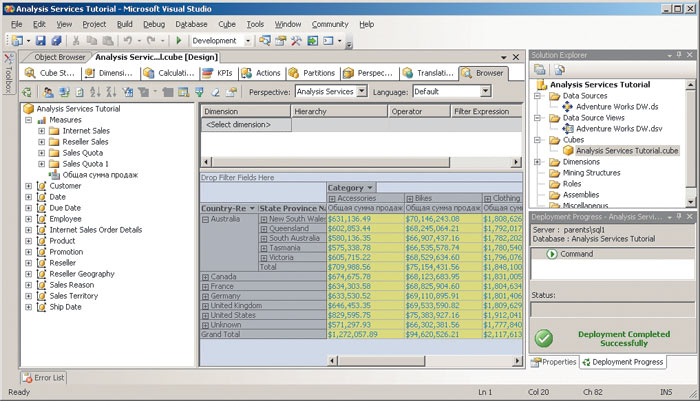
Рис. 6. Отображение вычисляемого значения
Вычисления с помощью аналитических служб не ограничиваются простыми случаями, подобными рассмотренному выше. Например, в текущей версии аналитических служб возможно применение более сложных концепций вычислений, таких как меры с частичным суммированием (типичный пример — остаток товара на складе за месяц, который вычисляется отнюдь не суммированием остатков по всем дням месяца), меры для вычисления количества значений, основанные не на числовых, а на строковых данных, вычисления для сравнения некоторых периодов с предыдущими периодами (например, I квартал 2006 года и I квартал 2005 года) и ряд других.
Язык MultiDimensional Expressions (MDX), предназначенный для произведения вычислений и выполнения запросов из клиентских приложений, был доступен и в предыдущей версии аналитических служб. В то же время MDX-скрипты, появившиеся в последней версии, являются частью структуры куба и используются для таких серверных объектов, как вычисляемые члены и агрегатные данные, и могут содержать выражения для ограничения областей видимости (например, для осуществления вычислений только для определенной области куба), формулы, определения вычисляемых значений и именованных наборов данных. Скрипты можно отлаживать, а результаты вычислений — кэшировать на диске сервера. Кроме того, в базах данных аналитических служб SQL Server 2005 можно создавать хранимые процедуры на любом из .NET-совместимых языков.
Создание проекций
Современные задачи бизнес-анализа, как правило, связаны с манипуляцией большим количеством разнообразных многомерных данных (в том числе основанных на нескольких таблицах фактов), а также с удобным представлением этих данных разным категориям пользователей с целью предоставления им только той информации, которая требуется для выполнения их служебных обязанностей. Некоторые производители OLAP-средств предлагают создавать для этой цели так называемые витрины данных — хранилища меньшего объема, содержащие ту часть данных, которая требуется для решения конкретной задачи.
Пользователям аналитических служб предыдущей версии SQL Server был доступен такой способ решения этой задачи, как создание виртуальных OLAP-кубов на основе нескольких реальных кубов. При решении подобной задачи с помощью аналитических служб SQL Server 2005 рекомендуется создать один физический куб, содержащий одну (или более) группу мер, и ряд проекций этого куба для различных групп пользователей (например, роль доступа может быть связана с определенным набором проекций).
Для создания проекции достаточно перейти на вкладку Perspectives, нажать кнопку New Perspective, ввести имя проекции в поле Perspective Name (в данном примере — «Интернет-продажи») и отметить, какие меры, измерения, иерархии, члены и атрибуты следует отобразить в создаваемой проекции (рис. 7).
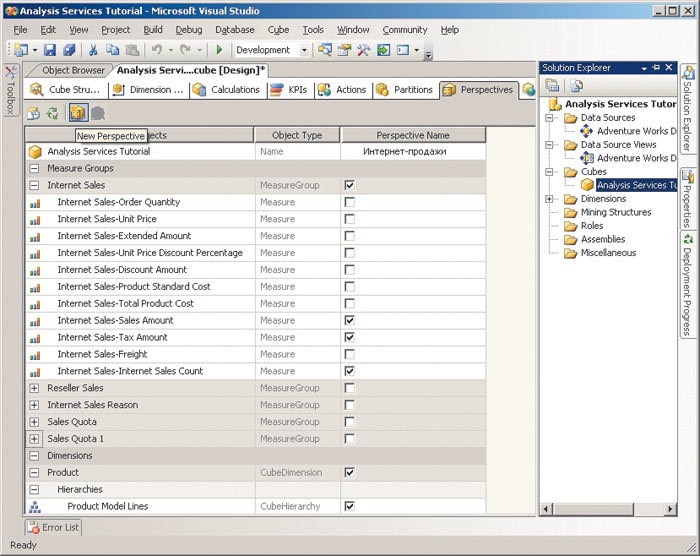
Рис. 7. Создание проекции куба
После повторного развертывания куба можно выбрать созданную проекцию в выпадающем списке Perspectives и убедиться в том, что в этом случае пользователю доступны только данные, выбранные при создании проекции (рис. 8).
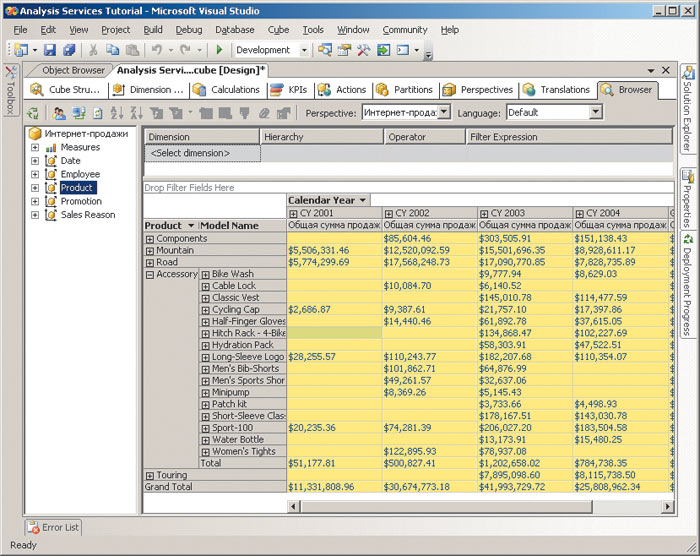
Рис. 8. Отображение проекции куба
Таким образом, мы буквально за несколько минут описали способ отображения данных, предназначенных для решения конкретной задачи, что намного проще, чем создание виртуальных кубов, и намного эффективнее в плане сопровождения готового решения, нежели создание дополнительных хранилищ.
Локализация имен объектов
В аналитических службах SQL Server 2005 можно использовать локализованные имена таких объектов, как меры, группы мер, измерения, показатели производительности и вычисляемые величины. Язык, применяемый для отображения OLAP-данных в клиентских приложениях, определяется языковыми настройками клиента и передается аналитическим службам вместе с запросами к ним.
Для создания набора локализованных названий на вкладке Translations, содержащей список локализуемых имен объектов на языке, принятом по умолчанию, следует нажать кнопку New Translation и выбрать из появившегося окна со списком возможных языков нужный язык. После этого к списку добавится новая колонка, в которой следует ввести локализованные версии имен объектов на данном языке (рис. 9).
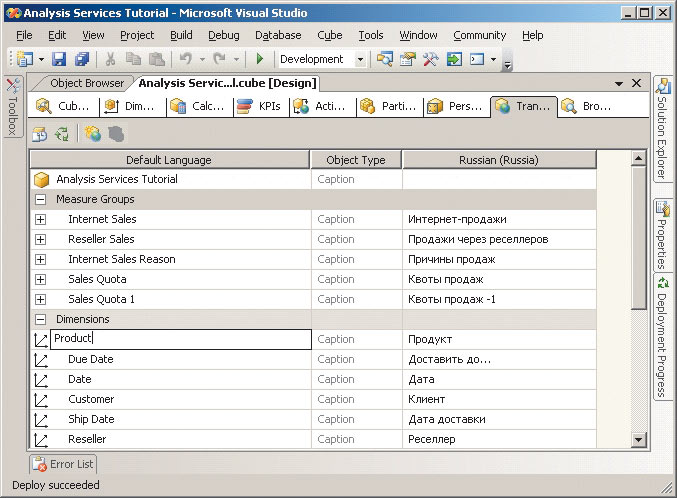
Рис. 9. Создание русскоязычного набора локализованных названий
Отметим, что при отсутствии в структуре куба локализованных наименований для языковой настройки конкретного клиента аналитическими службами используются наименования, принятые по умолчанию.
Заключение
 егодня мы еще раз убедились в том, что аналитические службы SQL Server 2005 предоставляют разработчикам и бизнес-пользователям немало новых интересных возможностей — это, например, создание и применение таких наглядных объектов, как ключевые показатели производительности; предоставление пользователям проекций, фактически выполняющих функции витрин данных, возможность создания локализованных представлений данных. Впрочем, возможности новой версии аналитических служб этим не ограничиваются, поэтому мы продолжим знакомиться с ними в следующем номере.
егодня мы еще раз убедились в том, что аналитические службы SQL Server 2005 предоставляют разработчикам и бизнес-пользователям немало новых интересных возможностей — это, например, создание и применение таких наглядных объектов, как ключевые показатели производительности; предоставление пользователям проекций, фактически выполняющих функции витрин данных, возможность создания локализованных представлений данных. Впрочем, возможности новой версии аналитических служб этим не ограничиваются, поэтому мы продолжим знакомиться с ними в следующем номере.








