Энциклопедия современной памяти
Основные характеристики памяти
Соотношения между таймингами памяти
Проблема терминирования сигналов
Графическая память: названия схожие, но суть разная
Все современные компьютеры в настоящее время оснащаются памятью DDR2, которая практически вытеснила память DDR, однако уже в начале следующего года будет внедрена в массовую эксплуатацию новая память — память стандарта DDR3. Практически все ведущие производители модулей памяти уже продемонстрировали свою готовность к массовому производству нового типа памяти, анонсировав модули памяти стандарта DDR3. В этой статье мы расскажем о новом типе памяти и рассмотрим основные различия между памятью DDR3 и DDR2.
Немного истории
Традиционно производители памяти внедряют новую архитектуру с периодичностью в 4-5 лет. Помимо архитектуры памяти, каждые год-два изменяется и техпроцесс производства чипов памяти.
Синхронная память SDRAM появилась в середине 1990-х годов. Именно тогда в массовое производство была внедрена синхронная память SDR SDRAM PC66, которая вскоре была заменена на память PC100, а затем и PC133.
В 2000 году на смену памяти SDR SDRAM пришла память DDR SDRAM, отличающаяся большей пропускной способностью при меньшем энергопотреблении.
Вслед за памятью DDR была внедрена память DDR2, которая в настоящий момент является наиболее распространенной. Первоначально существовала только память DDR2-400, на смену которой довольно быстро пришла память DDR2-533. Затем появилась память DDR2-667, DDR2-800 и даже DDR2-1066. А в будущем году нас ждет постепенный переход на память стандарта DDR3. Первоначально память DDR3 будет внедрена только в платформы на базе процессоров компании Intel, но позднее, в 2008 году, когда память DDR3 станет массовой и дешевой, ее также начнут использовать и в системах на базе процессоров AMD.
Итак, что представляет собой новый тип памяти и чем он кардинально отличается от памяти DDR2? Чтобы ответить на этот вопрос, нам прежде всего придется разобраться с тем, как вообще функционирует синхронная память и в чем отличие памяти SDR от DDR.
Основные понятия
Оперативная память, или RAM-память (Random Access Memory), — это память с произвольным доступом.
Поскольку элементарной единицей информации является бит, оперативную память можно рассматривать как некий набор элементарных ячеек, каждая из которых способна хранить один информационный бит.
Элементарная ячейка оперативной памяти представляет собой конденсатор, способный в течение короткого промежутка времени сохранять электрический заряд, наличие которого можно ассоциировать с информационным битом. Проще говоря, при записи логической единицы в ячейку памяти конденсатор заряжается, при записи нуля — разряжается.
Поскольку элементарной единицей информации для современных компьютеров является байт (8 бит), то для простоты можно считать, что элементарная ячейка памяти, которая может адресоваться, хранит не бит, а байт информации. Таким образом, доступ к памяти производится не побитно, а побайтно.
Логическая организация памяти
Микросхемы памяти организованы в виде матрицы, напоминающей лист бумаги в клетку, причем пересечение столбца и строки матрицы создает одну из элементарных ячеек. Понятно, что количество строк и столбцов в матрице памяти определяет ее объем в битах или байтах.
Кроме того, современные чипы памяти имеют несколько банков, каждый из которых можно рассматривать как отдельную матрицу со своими столбцами и строками.
На рис. 1 показана упрощенная схема чипа памяти, в котором имеется четыре банка, каждый из которых содержит 8192 строки и 1024 столбца. Таким образом, емкость каждого банка составляет: 8192x1024 = 8192 Кбайт = 8 Мбайт.
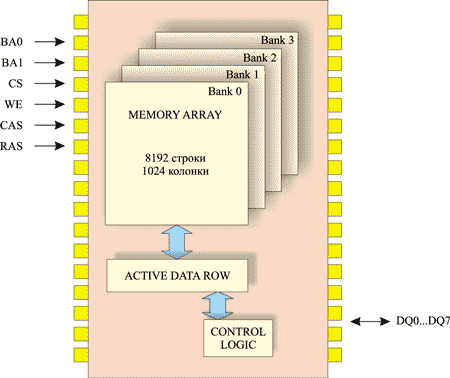
Рис. 1. Упрощенная схема чипа памяти с шириной шины данных 8 бит
С учетом того, что чип содержит четыре банка, получается, что полная емкость чипа равна 32 Мбайт.
Кроме емкости и количества банков, каждая микросхема (чип) памяти характеризуется шириной шины данных, то есть количеством линий для передачи данных (DQ0, DQ1 и т.д.). Подчеркнем, что здесь речь идет не о модуле памяти, а об отдельном чипе памяти, из которых состоят модули. Ширина шины данных современных чипов памяти может составлять 4, 8, 16 или 32 линии, и именно этот параметр определяет логическую структуру чипа памяти. К примеру, чип емкостью 1024 Мбит при ширине шины данных 8 бит может быть составлен как 128 М x 8, то есть может рассматриваться и как 128 М логических 8-битных элементов. Тот же чип 1024 Мбит можно составить и как 64 М x 16 или 32 М x 32. В записи 64 М x 16, определяющей логическую структуру чипа памяти, первая цифра называется глубиной чипа памяти, а вторая — шириной.
Если говорить не об отдельном чипе памяти, а о модуле памяти, который включает несколько чипов памяти, то, кроме емкости, выражаемой в мегабайтах (Мбайт) или в гигабайтах (Гбайт), он характеризуется шириной или разрядностью интерфейса шины данных. Для всей современной памяти ширина шины данных составляет 64 бита. Ширина шины данных модуля памяти (64 бит) больше, чем ширина шины данных отдельного чипа памяти (4, 8, 16 или 32 бит). Для того чтобы согласовать передачу данных, используется простое слияние шин данных отдельных чипов памяти в шину данных модуля памяти.
Такое «заполнение» шины данных памяти принято называть составлением физического банка памяти. К примеру, для составления одного физического банка 64-разрядного модуля памяти SDRAM необходимо наличие 16 чипов шириной x4, или 8 чипов шириной x8, или 4 чипов шириной x16.
Как и отдельный чип памяти, модуль памяти характеризуется глубиной, которая определяется как емкость модуля, выраженная в битах, деленная на разрядность шины данных (64 бит). Соответственно произведение ширины на глубину дает полную емкость модуля и определяет его организацию. Так, для модуля памяти емкостью 1024 Мбайт справедлива запись 128 М x 64.
Адресация памяти
При обращении к той или иной ячейке памяти следует задать адрес нужных строки и столбца.
С учетом того, что в модуле памяти используется несколько чипов памяти, а в каждом чипе — несколько банков памяти, прежде всего необходимо указать, в каком чипе и банке находится ячейка. Для этого применяются специальные сигналы: CS, BA0 и BA1.
Сигнал CS (Chip Select) позволяет выбрать требуемый чип памяти. Когда сигнал активен, возможен доступ к чипу памяти, то есть чип активируется. В противном случае чип памяти недоступен.
Сигналы BA0 и BA1 (Bank Active) позволяют адресовать один из четырех банков памяти. Учитывая, что каждый сигнал может принимать одно из двух значений: 0 или 1, — комбинации 00, 01, 10 и 11 позволяют задать адрес четырех банков памяти.
Когда выбраны чип и банк памяти, можно получить доступ к требуемой ячейке памяти, задав адрес столбца и строки. Исходя из соображений минимизации размера упаковки микросхемы и сокращения количества выводов, адреса строк и столбцов передаются по одним и тем же адресным линиям, образующим мультиплексированную адресную шину (Multiplexed Address, MA). То есть первоначально передается адрес строки, а затем, через некоторый промежуток времени, по той же шине передается адрес столбца. Ширина мультиплексированной шины адреса составляет 14 линий (A0, A1 … A13), однако, в зависимости от логической организации чипа памяти, часть линий может не использоваться. Кроме того, некоторые линии зарезервированы для служебных нужд.
Команды доступа к памяти
Для считывания адреса строки на входы матрицы памяти подается специальный стробирующий импульс RAS (Row Address Strobe). Этот импульс представляет собой изменение уровня сигнала с высокого на низкий, то есть при переходе сигнала RAS с высокого уровня на низкий возможно считывание адреса строки.
При этом отметим, что само считывание адреса строки происходит не в момент изменения RAS-сигнала, а синхронно с положительным фронтом тактирующего импульса.
Аналогичным образом считывание адреса столбца происходит при изменении уровня сигнала (стробирующего импульса) CAS (Column Address Strobe) с высокого значения на низкое и синхронно с положительным фронтом тактирующего импульса.
Кстати заметим, что, поскольку все события памяти (считывание адреса строки и столбца, выдача или запись данных) синхронизованы с фронтами тактирующего импульса, память называется синхронной.
Импульсы RAS# и CAS# подаются последовательно друг за другом, причем импульс CAS# всегда следует за импульсом RAS#, то есть сначала происходит выбор строки, а затем — выбор столбца.
После считывания адресов строки и столбца ячейки памяти к ней возможен доступ для чтения или записи информации. Эти операции подобны друг другу, но для записи используется специальный разрешающий сигнал (стробирующий импульс) WE# (Write Enable). Если сигнал по напряжению меняется с высокого уровня на низкий, то в выбранную ячейку происходит запись информации. Если же сигнал WE# остается высоким, то происходит считывание информации с выбранной ячейки.
После того как все данные записаны или считаны с ячеек активной сроки, необходимо выполнить команду Precharge, которая закрывает активную строку и позволяет активировать следующую строку.
В совокупности сигналы CS#, RAS#, CAS#, WE# позволяют сформировать все команды, необходимые для работы с памятью, то есть команды активации строки и чипа памяти (ACTIVE), команду чтения (READ), команду записи (WRITE) и команду деактивации строки (PRECHARGE) (существуют и другие специфические команды, но для понимания сути процесса они не нужны). Состояние сигналов CS#, RAS#, CAS#, WE# и соответствующие им команды отображены в таблице.
Состояние сигналов CS#, RAS#, CAS#, WE# и соответствующие им команды
|
Состояние сигналов |
||||
|
Команда |
CS# |
RAS# |
CAS# |
WE# |
|
No Operation (NOP) |
Low |
High |
High |
High |
|
ACTIVE (ACT) |
Low |
Low |
High |
High |
|
READ |
Low |
High |
Low |
High |
|
WRITE |
Low |
High |
Low |
Low |
|
PRECHARGE (PRE) |
Low |
Low |
High |
Low |
Для упрощения на временных диаграммах работы памяти часто вместо состояния сигналов CS#, RAS#, CAS#, WE# изображают соответствующие им команды. Упрощенная временная диаграмма соответствия команд и сигналов приведена на рис. 2.
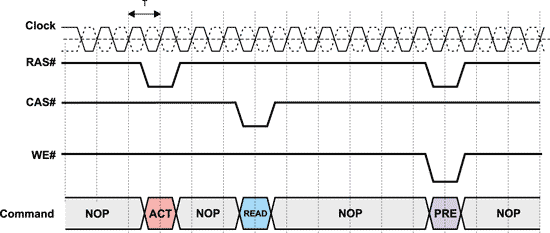
Рис. 2. Диаграмма команд памяти
Основные характеристики памяти
Пропускная способность
Как известно, главной характеристикой памяти является ее пропускная способность, то есть максимальное количество данных, которое можно считать из памяти или записать в память в единицу времени. Именно эта характеристика прямо или косвенно отражается в названии типа памяти. Пропускная способность памяти зависит от ширины шины данных и частоты работы памяти. Ширина шины данных определяет количество бит, передаваемых за один такт, а частота работы памяти — количество тактов в единицу времени. Поэтому для того, чтобы определить пропускную способность памяти, нужно умножить частоту системной шины на ширину шины данных. Память SDRAM имеет 64-битную (8-байтную) шину данных.
К примеру, память DDR400, функционирующая на эффективной частоте 400 МГц, имеет пропускную способность 400 МГц x 8 байт = 3,2 Гбайт/с, а память DDR2-800, функционирующая на эффективной частоте 800 МГц, — 800 МГц x 8 байт = 6,4 Гбайт/с.
Кроме того, необходимо учесть, что синхронная память DDR и DDR2 может функционировать в двухканальном режиме и в этом случае максимальная пропускная способность удваивается.
Тайминги памяти
Кроме максимальной пропускной способности, память характеризуется латентностью. Причем во многих случаях латентность памяти оказывает большее влияние на производительность всей системы в целом, нежели тактовая частота работы памяти.
Под латентностью принято понимать задержку между поступлением команды и ее реализацией. Латентность памяти определяется ее таймингами, то есть задержками, измеряемыми в количествах тактов, между отдельными командами. Принято различать несколько разных таймингов памяти, соответствующих задержкам между различным командами. Для того чтобы разобраться с разными таймингами, рассмотрим последовательность команд при чтении или записи данных в память.
RAS-to-CAS Delay (tRCD)
Первоначально происходит активация нужной строки памяти (команда ACTIVE), для чего сигнал RAS переводится в низкий уровень и происходит считывание адреса строки и адреса банка. Далее следует команда записи (WRITE) или чтения (READ) данных, для чего сигнал CAS переводится в низкий уровень и в надлежащий уровень устанавливается сигнал WE. При установке CAS в низкий уровень после прихода положительного фронта тактирующего импульса происходит выборка адреса столбца, наличествующего в данный момент на шине адреса, и открывается доступ к нужному столбцу матрицы памяти. Однако команда чтения или записи не может следовать непосредственно за командой активации — требуется, чтобы между этими командами, то есть между импульсами RAS и CAS, существовал некий промежуток времени — RAS-to-CAS Delay (задержка сигнала CAS относительно сигнала RAS). Эту задержку, измеряемую в тактах системной шины, принято обозначать tRCD. Учитывая, что импульс RAS эквивалентен выполнению команды активации строки (ACTIVE), а импульс CAS — команде READ, под задержкой RAS-to-CAS Delay можно понимать время между командами ACTIVE и READ (рис. 3).
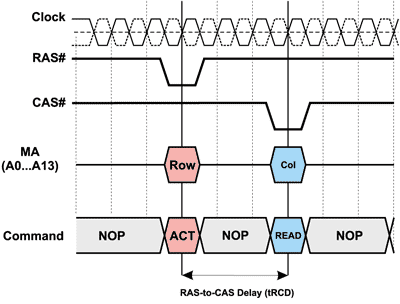
Рис. 3. Задержка RAS-to-CAS Delay (tRCD)
CAS Latency (tCL)
От команды чтения (записи) данных и до выдачи первого элемента данных на шину (записи данных в ячейку памяти) проходит промежуток времени, который называется CAS Latency (рис. 4). Эта задержка измеряется в тактах системной шины и обозначается tCL. Каждый последующий элемент данных появляется на шине данных в очередном такте.
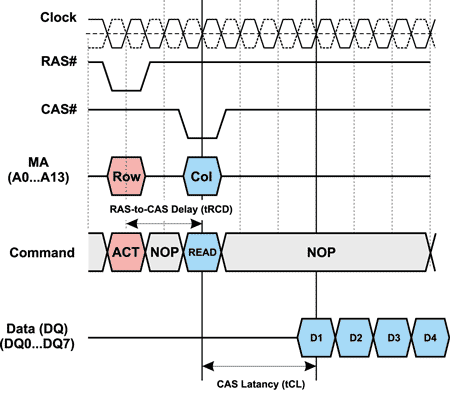
Рис. 4. Задержка CAS Latency (tCL)
Active-to-precharge delay (tRAS)
Еще один тип задержки, называемый Active-to-precharge delay, — это минимальный промежуток времени, который должен пройти с момента подачи команды активации строки до команды PRECHARGE (рис. 5). Эта задержка обозначается tRAS и измеряется в тактах системной шины.
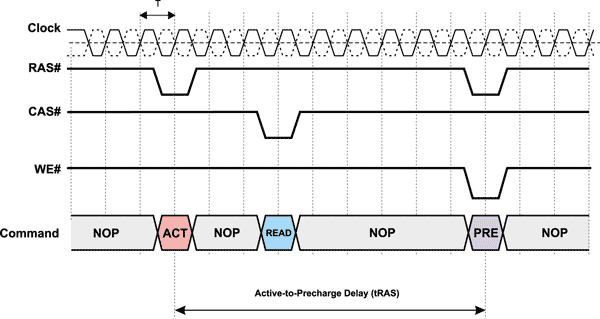
Рис. 5. Задержка Active-to-precharge (tRAS)
RAS Precharge (tRP)
Завершение цикла обращения к банку памяти осуществляется подачей команды PRECHARGE, приводящей к закрытию строки памяти. От команды PRECHARGE и до поступления новой команды активации строки памяти должен пройти промежуток времени (tRP), называемый RAS Precharge (рис. 6).
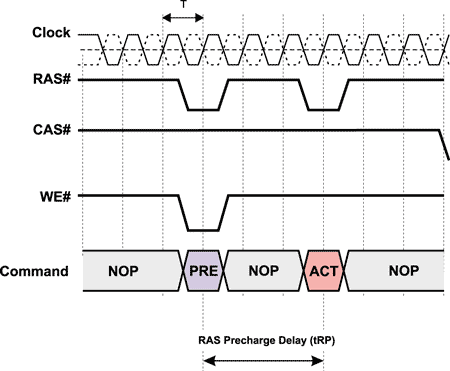
Рис. 6. Задержка RAS Precharge (tRP)
Command Rate
Следующий тип задержки, о котором необходимо сказать, — это скорость выполнения команд (Command Rate), представляющая собой задержку в тактах системной шины между командой CS# выбора чипа и командой активации строки (рис. 7). Как правило, задержка Command Rate составляет один или два такта (1T или 2T).
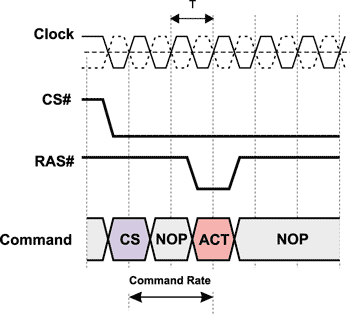
Рис. 7. Задержка Command Rate
Соотношения между таймингами памяти
Естественно, для каждого типа памяти значения различных задержек не могут быть произвольными и выбираются из допустимых значений. Кроме того, между разными таймингами должны соблюдаться вполне определенные соотношения. Далее мы рассмотрим несколько соотношений между таймингами на примере типичных операций чтения данных.
В простейшем случае для чтения данных из памяти необходимо выполнить последовательность следующих операций:
- активировать строку в банке памяти (команда ACTIVE);
- подать команду чтения данных (команда READ);
- считать данные, поступающие на внешнюю шину данных;
- закрыть активированную строку (команда PRECHARGE);
- активировать строку в банке памяти (команда ACTIVE).
Временной промежуток между активацией строки и командой чтения определяется как tRCD, а временной промежуток между командой чтения и появлением данных на шине — как tCL. Временной промежуток между началом считывания данных и закрытием активной строки (tRAS) зависит от длины передаваемого пакета, причем должно выполняться соотношение tRAS > tRCD+tCL.
Минимальное значение tRAS должно быть больше суммы tRCD и tCL на столько, на сколько велика длительность третьей операции, определяемая длиной передаваемого пакета. В качестве примера рассмотрим память типа SDR с величинами задержек tCL = 2 и tRCD = 2 (tRAS > 4). При длине пакета BL = 2 необходимо затратить не менее 2 тактов для передачи всего пакета, поэтому минимальное значение tRAS должно быть равным 6.
Запись таймингов памяти
Описанные задержки — RAS-to-CAS Delay (tRCD), CAS Latency (tCL), RAS Precharge (tRP), Active-to-precharge delay (tRAS) и Command Rate — определяют тайминги памяти, обычно записываемые в виде последовательности tCL-tRCD-tRP-tRAS-Command Rate. К примеру, для модуля DDR400 (PC3200) тайминги могут быть следующими: 2-3-4-5-(1T). Это означает, что для данного модуля CAS Latency (tCL) составляет 2 такта, RAS to CAS Delay (tRCD) — 3 такта, RAS Precharge (tRP) — 4 такта, ACTIVE-to- precharge delay (tRAS) — 5 тактов и Command Rate — 1 такт.
Память SDR
Разобравшись с такими важными характеристиками памяти, как ее тайминги, можно перейти непосредственно к рассмотрению принципов работы памяти. Начнем с синхронной SDRAM-памяти типа SDR (Single Data Rate), как с наиболее простой.
В SDR SDRAM-памяти обеспечивается синхронизация всех входных и выходных сигналов с положительными фронтами импульсов тактового генератора. Весь массив памяти SDRAM-модуля разделен на два независимых банка. Такое решение позволяет совмещать выборку данных из одного банка с установкой адреса в другом банке, то есть одновременно иметь две открытые страницы. Доступ к этим страницам чередуется (bank interleaving), и соответственно устраняются задержки, что обеспечивает создание непрерывного потока данных.
Наиболее распространенными типами SDRAM-памяти являлись PC100 и PC133. Цифры 100 и 133 определяют частоту системной шины в мегагерцах (МГц), которую поддерживает эта память. По внутренней архитектуре, способам управления и внешнему дизайну модули памяти PC100 и PC133 полностью идентичны.
В SDRAM-памяти организована пакетная обработка данных, что позволяет производить обращение по новому адресу столбца ячейки памяти на каждом тактовом цикле. Смысл пакетной обработки заключается в том, при активированной строке задание адреса одного столбца позволяет получить доступ сразу к последовательности нескольких столбцов (пакету столбцов) без дополнительного указания их адресов. В микросхеме SDRAM имеется счетчик для наращивания адресов столбцов ячеек памяти, чтобы обеспечить к ним быстрый доступ. Количество адресуемых таким образом столбцов называется длиной пакета (Burst Length, BL).
В SDRAM-памяти ядро и буферы обмена работают в синхронном режиме на одной и той же частоте (100 или 133 МГц). Передача каждого бита из буфера происходит с каждым тактом работы ядра памяти.
Временная диаграмма работы памяти SDR SDRAM при длине пакета BL = 4 и таймингах tRCD = 2 и tCL = 2 показана на рис. 8.
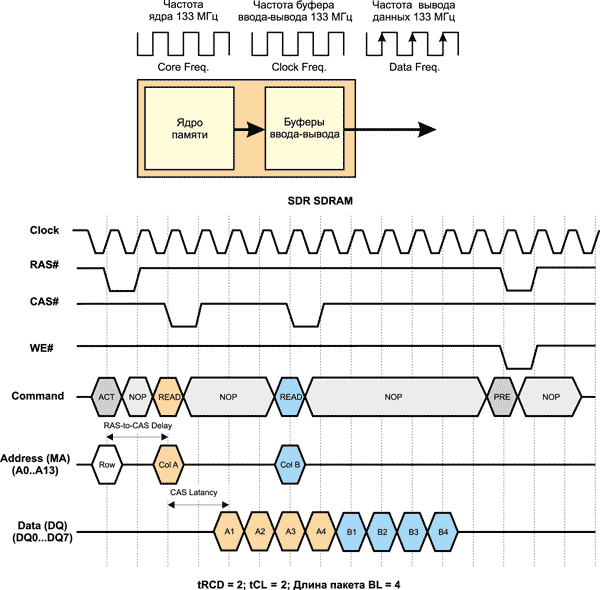
Рис. 8. Упрощенная временная диаграмма работы SDR SDRAM-памяти
Память DDR
Память DDR SDRAM, которая пришла на смену памяти SDR, обеспечивает вдвое большую пропускную способность. Аббревиатура DDR (Double Data Rate) в названии памяти означает удвоенную скорость передачи данных. В DDR-памяти каждый буфер ввода-вывода на каждой из 64 линий шины данных передает два бита за один такт, то есть фактически работает на удвоенной тактовой частоте, оставаясь при этом полностью синхронизированным с ядром памяти. Такой режим работы возможен в случае, если эти два бита доступны буферу ввода-вывода на каждом такте работы памяти. Для этого требуется, чтобы каждая команда чтения приводила к передаче из ядра памяти в буфер ввода-вывода сразу 2n бит. С этой целью используются две независимые линии передачи от ядра памяти к буферам ввода-вывода шириной n бит каждая, откуда биты поступают на шину данных в требуемом порядке (рис. 9 и 10).
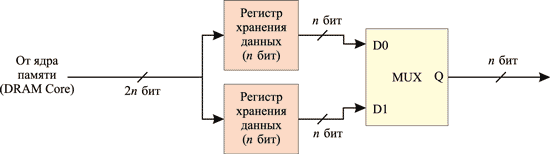
Рис. 9. Реализация технологии 2n-Prefetch при операции чтения данных
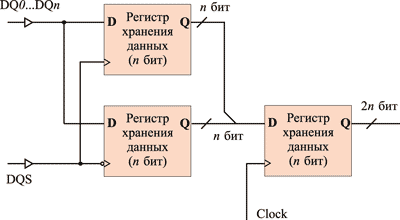
Рис. 10. Реализация технологии 2n-Prefetch при операции записи данных
Поскольку при таком способе организации работы памяти происходит предвыборка 2n бит перед передачей их на шину данных, его также называют 2n Prefetch (предвыборка 2n бит). В этой архитектуре доступ к данным осуществляется «попарно» — каждая одиночная команда чтения данных приводит к отправке по внешней шине данных двух элементов (разрядность которых, как и в SDR SDRAM, равна разрядности внешней шины данных). Аналогично каждая команда записи данных ожидает поступления двух элементов по внешней шине данных. Именно поэтому длина пакета (Burst Length, BL) при передаче данных в устройствах DDR SDRAM не может быть меньше 2.
Для того чтобы осуществить синхронизацию работы ядра памяти и буферов ввода-вывода, используется одна и та же тактовая частота (одни и те же тактирующие импульсы). Только если в самом ядре памяти синхронизация осуществляется по положительному фронту тактирующего импульса, то в буфере ввода-вывода, выполняющем функцию мультиплексора, для синхронизации используется как положительный, так и отрицательный фронт тактирующего импульса. Таким образом, передача 2n бит в буфер ввода-вывода по двум раздельным линиям осуществляется по положительному фронту тактирующего импульса, а их выдача на шину данных происходит как по положительному, так и по отрицательному фронту тактирующего импульса. Это обеспечивает вдвое более высокую скорость работы буфера и соответственно вдвое большую пропускную способность памяти.
Отличительной особенностью DDR-памяти является реализация четырех логических банков.
Рассмотрим упрощенную схему работы DDR-памяти на примере операции чтения (рис. 11). Пусть имеется четыре банка памяти (Bank0…Bank3), длина пакета (Burst Length) равна 4, tCAS = 2 и tRCD = 3. Первоначально необходимо активировать каждый из четырех банков и получить доступ к строке в этом банке. Задержка между активацией двух банков определяется как tRRD (Row-to Row Delay) и обычно составляет 2 такта. Таким образом, через каждые два такта активизируется новый банк, а через каждые три такта после активации банка следует команда чтения данных из него.
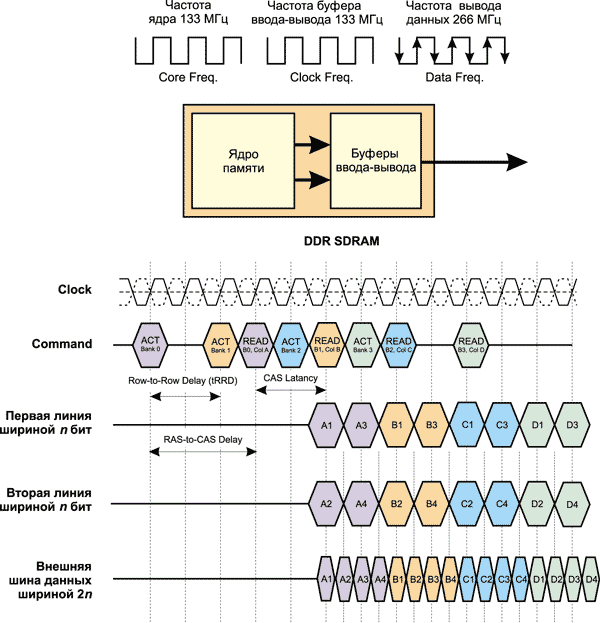
Рис. 11. Упрощенная временная диаграмма работы DDR SDRAM-памяти
Поскольку задержка CAS Delay составляет 2 такта, то через 2 такта после команды чтения данные могут быть считаны с шины данных. Напомним, что у нас имеется две шины данных (линии) шириной n бит каждая и передача данных может происходить параллельно по каждой из этих линий. К примеру, первое слово (n бит), соответствующее первому банку (Bank0) и первому столбцу в этом банке (A1), может быть передано по первой линии, а второе слово (A2) одновременно с первым словом — по второй линии. Далее, одновременно с передачей по первой линии слова A3, по первой линии данных может быть передано слово A4. Таким образом, по первой линии передаются данные A1, A3, B1, B3 и т.д., а по второй линии одновременно с ними — данные A2, A4, B2, B4 и т.д.
Затем эти данные передаются в мультиплексор синхронно с положительным фронтом тактового импульса и выводятся по шине шириной n бит синхронно с положительным и отрицательным фронтами.
Память DDR2
Если следовать терминологии SDR (Single Data Rate), DDR (Double Data Rate), то память DDR2 было бы логично назвать QDR (Quadra Data Rate), поскольку этот стандарт подразумевает в четыре раза большую скорость передачи, то есть в стандарте DDR2 при пакетном режиме доступа данные передаются четыре раза за один такт. Для организации данного режима работы памяти необходимо, чтобы буфер ввода-вывода (мультиплексор) работал на учетверенной частоте по сравнению с частотой ядра памяти. Достигается это следующим образом: ядро памяти, как и прежде, синхронизируется по положительному фронту тактирующих импульсов, а с приходом каждого положительного фронта по четырем независимым линиям в буфер ввода-вывода (мультиплексор) передаются 4n бита информации (выборка 4n битов за такт, 4n-Prefetch). Сам буфер ввода-вывода тактируется на удвоенной частоте ядра памяти и синхронизируется как по положительному, так и по отрицательному фронту этой частоты. Иными словами, с приходом положительного и отрицательного фронтов происходит передача битов в мультиплексном режиме на шину данных (рис. 12 и 13). Это позволяет за каждый такт работы ядра памяти передавать четыре слова на шину данных, то есть вчетверо повысить пропускную способность памяти.
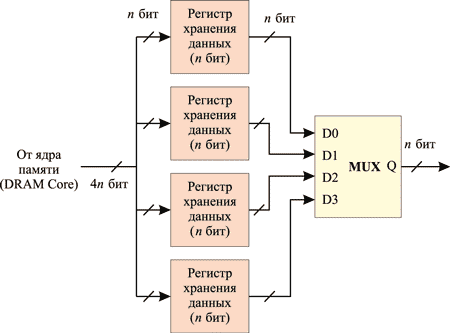
Рис. 12. Реализация технологии 4n-Prefetch при операции чтения данных
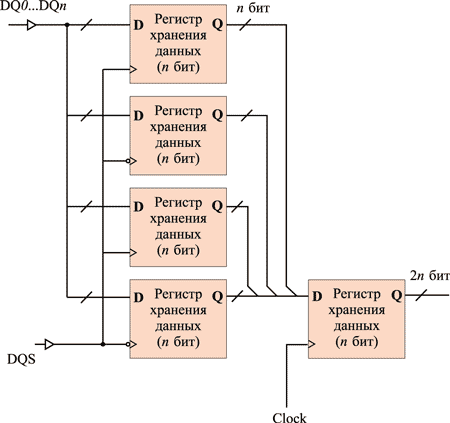
Рис. 13. Реализация технологии 4n-Prefetch при операции записи данных
По сравнению с памятью DDR память DDR2 позволяет обеспечить ту же пропускную способность, но при вдвое меньшей частоте ядра. К примеру, в памяти DDR400 ядро функционирует на частоте 200 МГц, а в памяти DDR2-400 — на частоте 100 МГц. В этом смысле память DDR2 имеет значительно большие потенциальные возможности для увеличения пропускной способности по сравнению с памятью DDR.
В памяти DDR2 реализована схема разбиения массива памяти на четыре логических банка, а для модулей емкостью 1 и 2 Гбайт — на восемь логических банков.
Рассмотрим упрощенную схему работы DDR2-памяти на примере операции чтения (рис. 14). Пусть имеются два банка памяти (Bank0, Bank1), длина пакета (Burst Length) равна 4, tCAS = 2 и tRCD = 3, tRRD = 2. Первоначально необходимо активировать оба банка и получить доступ к строке в этом банке. Тогда через каждые 2 такта активируется новый банк, а через каждые три такта после активации банка следует команда чтения данных из этого банка.
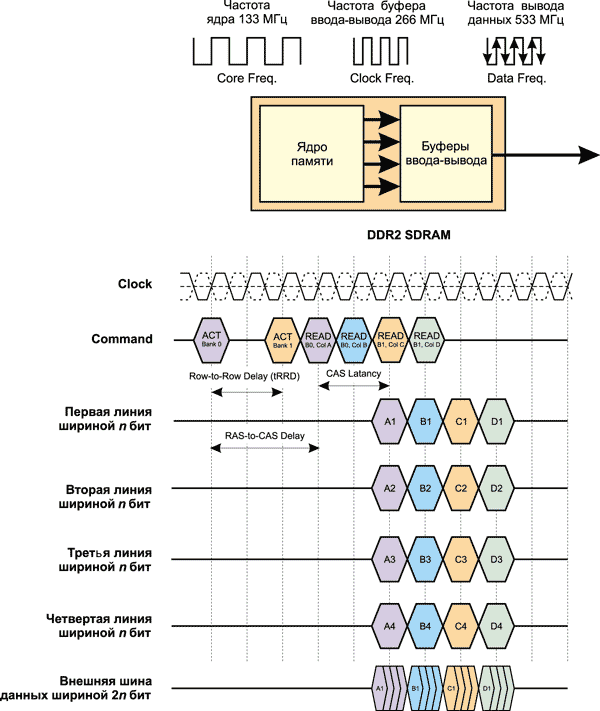
Рис. 14. Упрощенная временная диаграмма работы SDRAM-памяти DDR2
Поскольку задержка CAS Delay составляет два такта, то через два такта после команды чтения данные могут быть считаны с шины данных. Напомним, что у нас имеется четыре шины данных (линии) шириной n бит каждая и передача данных может происходить параллельно по каждой из этих линий. В нашем упрощенном примере можно считать, что слова A1-A4, соответствующие первому банку, одновременно (в течение одного такта) передаются по четырем линиям. На следующем такте по четырем линиям одновременно передаются слова B1-B4 и т.д.
Далее эти данные передаются в мультиплексор синхронно с положительным фронтом тактового импульса. Поскольку мультиплексор работает на удвоенной частоте и выводит данные по шине шириной n бит синхронно с положительным и отрицательным фронтами, за один такт работы ядра памяти осуществляется вывод на шину данных 4n бит (4 слова).
Понятно, что в случае реализации архитектуры 4n-Prefetch длина пакета (Burst Length) данных не может быть менее 4. Поэтому для памяти DDR2 минимальная длина пакета составляет 4.
Одна из главных задач в технологии 4n-Prefetch — обеспечить наличие непрерывного потока данных на каждой из четырех линий шириной n бит. С учетом того, что команды тактируются на частоте работы ядра памяти и в один момент времени на шине может присутствовать только одна команда, эта задача не такая простая, как кажется.
Рассмотрим в качестве гипотетического примера ситуацию с тремя банками памяти. Активация каждого следующего банка может происходить только после промежутка времени Row-to-Row Delay (tRRD). Типичным является случай, когда tRRD составляет два такта. Кроме того, для каждого отдельного банка после его активации команда на чтение (выбор столбца в пределах активированной строки) поступает с задержкой, определяемой RAS-to-CAS Delay (tRCD). И если tRCD = 4T, то команда на чтение первого банка совпадет с активацией третьего банка. Для того чтобы избежать конфликта команд, команду активации третьего банка приходится смещать на целый цикл, что, естественно, приводит и к смещению всех последующих команд для этого банка. В результате такого сдвига на шине данных образуется пропуск или пузырь (Bubble), что приводит к снижению пропускной способности памяти (рис. 15).
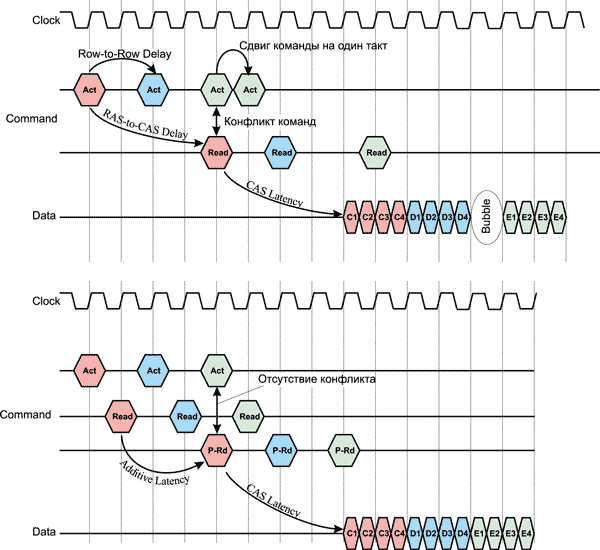
Рис. 15. Возникновение пропусков данных
Отложенная операция CAS
Для того чтобы избежать пропусков данных, в DDR2-памяти используются отложенные операции CAS. Суть заключается в том, что операции активации банка и команда на выбор столбца (CAS) следуют непосредственно друг за другом с разницей в один цикл. Это позволяет избежать конфликта команд, поскольку команда CAS уже не совпадает с командой активации банка. Команда CAS поступает в буфер команд и хранится там требуемое количество циклов в зависимости от значения tRCD. После этого она считывается, но шина команд остается незанятой и может быть использована для команды активации очередного банка. В результате достигается непрерывный поток данных на шине и увеличивается пропускная способность памяти.
Хранение команды CAS в буфере эквивалентно введению дополнительной задержки (Additive Latency, AL), поэтому данный способ известен также как Additive Latency или как способ отложенного чтения (Posted CAS).
OCD-калибровка сигнала
Одной из серьезных проблем, связанных с DDR-памятью, является потребление энергии. К примеру, системы, оснащенные 4 Гбайт DDR-памяти, при чтении всего объема памяти потребляют 35-40 Вт электроэнергии. Снижение номинального напряжения памяти приведет к уменьшению потребления электроэнергии и, кроме того, позволит увеличить тактовую частоту работы памяти.
Однако не все так просто. Действительно, снижение перепадов напряжения позволяет увеличивать тактовую частоту, но после определенного значения напряжения пилообразное изменение формы импульсов напряжения будет искажаться. Это искажение можно уменьшить, увеличив крутизну фронта импульса, но и это имеет свои негативные последствия: в результате на положительном и отрицательном фронтах импульса возникнут выбросы (всплески) напряжения.
Еще одна проблема, связанная с высокой тактирующей частотой, заключается в том, что с ростом частоты следования импульсов начинают сказываться явления задержки, что может приводить к рассинхронизации сигналов. К примеру, в результате таких задержек опорные тактовые импульсы, с которыми синхронизируются все команды, могут быть рассинхронизированы с импульсами DQS (Data Queue Strobe), передний и задний фронты которых используются для стробирования приема/передачи данных в буферы ввода-вывода.
Для того чтобы решить проблему эффекта задержки в DDR-памяти, используется метод компенсации этих задержек, то есть тактирующие импульсы подаются с некоторым опережением.
Рассинхронизация может возникать и по другой причине. В DDR-памяти точкой синхронизации является пересечение переднего или заднего фронтов стробирующего сигнала с опорным напряжением, условно принимаемым за ноль. То есть, как только значение стробирующего сигнала достигает значения опорного напряжения, наступает момент синхронизации (срабатывания). При таком подходе возникают определенные проблемы: и опорное напряжение (ноль), и стробирующий сигнал могут «плавать», что неизбежно приводит к тому, что точка синхронизации тоже «плавает».
Для решения проблемы синхронизации в DDR2-памяти операции ввода-вывода в буфер синхронизируются не по одному стробирующему сигналу, а по двум: DQS (Data Queue Strobe) и инверсному к нему сигналу ![]() . Эти стробирующие сигналы являются дифференциальными, то есть уровни сигналов
. Эти стробирующие сигналы являются дифференциальными, то есть уровни сигналов ![]() измеряются друг относительно друга, а не относительно некоторого опорного напряжения, как в DDR-памяти. Соответственно точкой синхронизации является пересечение самих стробирующих сигналов DQS и
измеряются друг относительно друга, а не относительно некоторого опорного напряжения, как в DDR-памяти. Соответственно точкой синхронизации является пересечение самих стробирующих сигналов DQS и ![]() .
.
Теоретически сигналы DQS и ![]() должны быть зеркально симметричны друг относительно друга, но на практике эта симметрия не всегда достижима. Всегда возникают индуцированные искажения и расфазировка сигналов. В результате точка пересечения между DQS- и
должны быть зеркально симметричны друг относительно друга, но на практике эта симметрия не всегда достижима. Всегда возникают индуцированные искажения и расфазировка сигналов. В результате точка пересечения между DQS- и ![]() -сигналами, используемая как точка синхронизации, может «плавать» и не совпадать с точкой пересечения сигнала DQ (Data Queue) (сигнал на выдачу данных) с опорным напряжением. Это явление известно как DQ-DQS-сдвиг.
-сигналами, используемая как точка синхронизации, может «плавать» и не совпадать с точкой пересечения сигнала DQ (Data Queue) (сигнал на выдачу данных) с опорным напряжением. Это явление известно как DQ-DQS-сдвиг.
Помимо всего прочего необходимо учитывать, что входные импедансы буферов ввода-вывода могут слегка отличаться друг от друга. Это в еще большей степени препятствует компенсации DQ-DQS-сдвига.
Для решения данной проблемы в DDR2-памяти используется (Off-Chip Driver) OCD-калибровка. При такой калибровке DQS и ![]() стробовые сигналы калибруются друг относительно друга и относительно сигнала DQ. В результате такой калибровки исчезает DQ-DQS-сдвиг (рис. 16).
стробовые сигналы калибруются друг относительно друга и относительно сигнала DQ. В результате такой калибровки исчезает DQ-DQS-сдвиг (рис. 16).
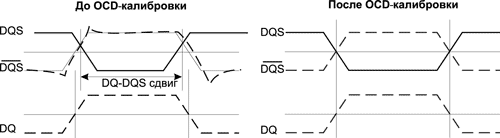
Рис. 16. OCD-калибровка сигнала
Проблема терминирования сигналов
Распространение любого сигнала вдоль шины неизбежно приводит к его частичному отражению от любых неоднородностей вдоль пути его распространения. Для того чтобы такого отражения сигнала не происходило, необходимо, во-первых, чтобы на пути распространения сигнала не было неоднородностей, а во-вторых, чтобы сам путь был бесконечным. Понятно, что на практике такие условия нереализуемы и отражение сигнала всегда присутствует. Отраженный сигнал интерферирует с основным сигналом, что приводит к искажению последнего. Поэтому одной из основных задач является уменьшение отраженного сигнала.
Одно из решений, используемых для предотвращения отражения сигнала, заключается во введении шунтирующих сопротивлений, образующих заглушку, или терминатор. Шунтирующее сопротивление устанавливается на конце шины, по которой распространяется сигнал и заземляется. Такая заглушка полностью поглощает сигнал и предотвращает его отражение. В случае DDR-памяти терминальные сопротивления устанавливаются на самой материнской плате. Такой подход позволяет устранить отражения, которые могли бы возникнуть на конце самой шины, однако не решает проблемы возникновения отражений от неоднородностей, связанных с наличием нескольких слотов для установки модулей памяти.
В случае памяти DDR2 используется принципиально иной метод терминирования сигналов, получивший название ODT (On-Die-Termination). В данном случае терминальные сопротивления устанавливаются непосредственно на самих модулях памяти, а для того, чтобы предотвратить поглощение сигнала в активном модуле памяти, используется технология отключения терминальных сопротивлений от активных модулей.
Память DDR3
Память стандарта DDR3 можно рассматривать как логическое развитие стандарта DDR2. Стандарт DDR3 еще не принят, что, впрочем, не мешает производителям модулей памяти уже сейчас анонсировать память DDR3.
Ожидается, что массовое распространение DDR3-память получит к концу будущего года, а в 2009-м станет основным типом памяти на рынке.
Эффективная частота работы DDR3-памяти будет составлять от 800 до 1600 МГц. Кроме увеличенной пропускной способности, память DDR3 будет также выгодно отличаться и уменьшенным энергопотреблением. Так, если модули DDR-памяти работают при напряжении питания 2,5 В, а модули памяти DDR2 — при 1,8 В, то модули DDR3-памяти работают при напряжении питания 1,5 В (на 16,5% меньше, чем для памяти DDR2). Снижение напряжения питания достигается за счет использования 90-нм техпроцесса производства микросхем памяти и применения транзисторов с двойным затвором (Dual-gate), что способствует снижению токов утечки.
Ожидается, что первоначально емкость модулей памяти DDR3 составит 1 Гбайт, а впоследствии появятся модули памяти емкостью 2 и 4 Гбайт.
Для памяти DDR3 будет реализована 8-банковая логическая структура, а размер страницы составит 1 Кбайт для чипов с шиной х4 и х8 и 2 Кбайт для чипов с шиной х16.
Принципиальное отличие памяти DDR3 от памяти DDR2 заключается в реализации механизма 8n-Prefetch вместо 4n-Prefetch.
Для организации данного режима работы памяти необходимо, чтобы буфер ввода-вывода (мультиплексор) работал на частоте в 8 раз большей по сравнению с частотой ядра памяти. Достигается это следующим образом: ядро памяти, как и прежде, синхронизируется по положительному фронту тактирующих импульсов, а с приходом каждого положительного фронта по восьми независимым линиям в буфер ввода-вывода (мультиплексор) передаются 8n бита информации (выборка 8n битов за такт). Сам буфер ввода-вывода тактируется на учетверенной частоте ядра памяти и синхронизируется как по положительному, так и по отрицательному фронту данной частоты. Это позволяет за каждый такт работы ядра памяти передавать восемь слов на шину данных, то есть в восемь раз повысить пропускную способность памяти.
По сравнению с памятью DDR2, DDR3-память позволяет обеспечить ту же пропускную способность при вдвое меньшей частоте ядра. К примеру, в памяти DDR2-800 ядро функционирует на частоте 200 МГц, а в памяти DDR3-800 — на частоте 100 МГц (рис. 17).
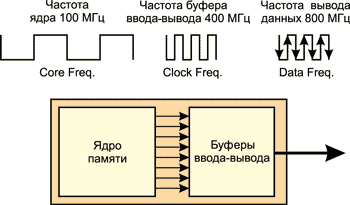
Рис. 17. Реализация метода 8n-Prefetch
Понятно, что в случае реализации архитектуры 8n-Prefetch длина пакета (Burst Length) данных не может быть менее 8. Поэтому для памяти DDR2 минимальная длина пакета составляет 8.
Упрощенная временная диаграмма работы DDR3-памяти для BL = 8, tRRD = 2, tRCD = 3 и tCL = 2 показана на рис. 18.
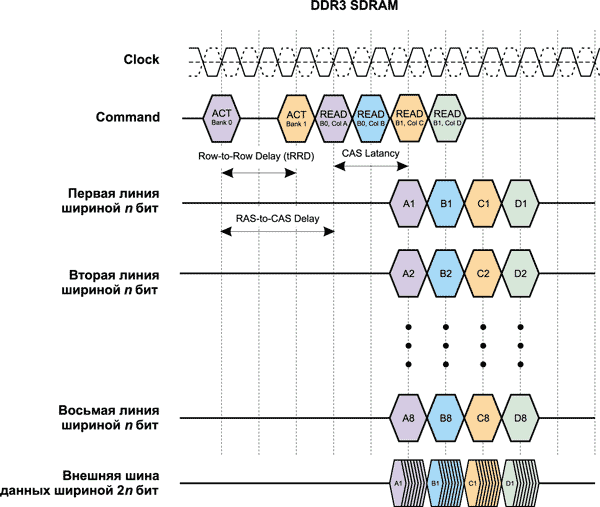
Рис. 18. Упрощенная временная диаграмма работы памяти DDR3
Конечно, реализация механизма 8n-Prefetch вместо 4n-Prefetch — это не единственное различие между памятью DDR3 и DDR2. Другими нововведениями, реализованными в памяти DDR3, являются технология динамического терминирования сигналов (dynamic On-Die Termination (ODT)) и новая технология калибровки сигналов.
Технология динамического терминирования сигналов позволяет гибко оптимизировать значения терминальных сопротивлений в зависимости от условий загрузки памяти.
Графическая память: названия схожие, но суть разная
Как известно, оперативная память применяется для нужд не только центрального процессора, но и графического процессора. В современных графических видеокартах используется так называемая графическая память, микросхемы которой распаиваются на плате графической карты. Аналогично тому, что существуют различные типы оперативной памяти (SDR, DDR, DDR2 и DDR3), графическая память тоже бывает разной. Для того чтобы отличать оперативную память от графической памяти, последнюю снабжают обозначением «G». Так, бывает память GDDR2, GDDR3 и GDDR4. Несмотря на схожие названия (GDDR2 и DDR2, GDDR3 и DDR3), графическая память существенно отличается от оперативной памяти.
Отметим, что впервые графическая память GDDR2 (Graphics Double Data Rate, version 2) была использована компанией NVIDIA в видеокарте на базе процессора GeForce FX 5800. В то же время по принципу действия графическая память GDDR2 не имеет ничего общего с памятью DDR2 и в этом смысле более схожа с памятью DDR. В частности, в памяти GDDR2 не используется технология 4n-Prefetch, когда буфер ввода-вывода данных работает на удвоенной частоте. От обычной DDR-памяти память GDDR2 отличается более высокими тактовыми частотами, требованиями к напряжению и способами терминирования сигналов.
Память GDDR3 (Graphics Double Data Rate, version 3) была разработана компанией ATI, однако впервые использовалась на видеокартах с графическим процессором NVIDIA GeForce FX 5700 Ultra.
Эта память также не имеет никакого отношения к памяти DDR3 и по принципу действия более схожа с памятью DDR2, отличаясь от нее тактовыми частотами, требованиями к напряжению и способами терминирования сигналов. В памяти GDDR3, так же как и в памяти DDR2, используется технология 4n-Prefetch.
Память GDDR4 (Graphics Double Data Rate, version 4) сегодня применяется только в видеокарте с процессором ATI Radeon X1950XTX, анонсированном компанией 21 июля текущего года. Эта память является своеобразным аналогом памяти DDR3 в том смысле, что в ней реализован механизм 8n-Prefetch.








