Революция в мире графических процессоров
Графический процессор NVIDIA GeForce 8800
Принцип работы классического графического процессора
Вершинный процессор (Vertex Pipeline)
Пиксельный процессор (Pixel Pipeline)
Недостатки классического графического конвейера
Архитектура GPU NVIDIA GeForce 8800 в деталях
Унифицированный потоковый процессор
Архитектура ядра GPU NVIDIA GeForce 8800
Технологии, поддерживаемые графическим процессором GeForce 8800
Новые режимы анизотропной фильтрации
Поддержка геометрических шейдеров
Технология расчета физических эффектов NVIDIA Quantum Effects
Режим Extreme High Definition Gaming
Семейство процессоров GeForce 8800
8 ноября текущего года компания NVIDIA анонсировала новый графический процессор NVIDIA GeForce 8800 (кодовое название чипа G80) и новый чипсет для материнских плат — медиакоммуникационный процессор NVIDIA nForce 680i SLI, поддерживающий процессоры семейства Intel Core 2 Duo и Intel Core 2 Quad. Правда, сама NVIDIA не придала особого значения этому событию. Так, российское представительство компании не сочло нужным организовать даже пресс-конференцию, посвященную выходу новых продуктов. Возможно, на раскрутку просто не хватило денег или в компании сочли, что новые продукты настолько хороши, что в рекламе не нуждаются. Впрочем, то, что новые продукты действительно хороши, — сомнений не вызывает. Ведь речь идет не о банальном выпуске очередной версии графического процессора (к этим регулярным событиям все давно привыкли), а о выпуске кардинально новой архитектуры графического процессора. По своей значимости это событие можно сравнить разве что с разработкой новой процессорной микроархитектуры Intel Core, которая до этого оставалась главным событием года на IT-рынке. В любом случае, трудно сказать, чем руководствовались маркетологи компании NVIDIA, принимая решение произвести революцию в области графических процессоров «по-тихому», однако факт остается фактом — революция свершилась, и теперь остается лишь пожинать ее плоды.
В настоящей статье мы в деталях рассмотрим преимущества новой архитектуры графических процессоров, которые в буквальном смысле открывают новые горизонты возможностей в области 3D-игр как для разработчиков, так и для пользователей ПК.
Коротко о главном
Итак, прежде чем перейти к подробному рассмотрению нового графического процессора GeForce 8800, вкратце расскажем о возможностях нового графического процессора и медиакоммуникационного процессора NVIDIA nForce 680i SLI.
Прежде всего, эти два новых семейства продуктов вкупе с процессором семейства Intel Core 2 Duo или Intel Core 2 Quad представляют собой аппаратную основу мощнейшей на сегодня платформы для компьютерных игр и видео высокой четкости.
Графические процессоры GeForce 8800 первыми в мире получили поддержку API Microsoft DirectX 10, который будет представлен вместе с грядущей операционной системой Microsoft Vista. Графические процессоры GeForce 8800 воплощают в себе следующие технологии:
- новая революционная унифицированная шейдерная архитектура, состоящая из 128 параллельных потоковых процессоров, которые функционируют на частоте 1,35 ГГц;
- технология обработки физики NVIDIA Quantum Effects, знаменующая приход нового поколения визуальных эффектов и графического реализма;
- одновременное 16x сглаживание и 128-битное освещение в широком динамическом диапазоне (HDR).
«Одна производительность и визуальные эффекты нового GeForce 8800 GTX сведут вас с ума, — сказал Пэт Гелсингер (Pat Gelsinger), старший вице-президент и генеральный директор Digital Enterprise Group в Intel. — Intel Core 2 Quad и Core 2 Duo вкупе с GeForce 8800 GTX и технологией SLI обеспечивают самые лучшие впечатления от изображений в мире».
В ходе разработки графического процессора GeForce 8800 компания NVIDIA тесно сотрудничала с ведущими мировыми разработчиками игр с целью создания игр нового поколения для DirectX 10 на базе графических процессоров NVIDIA , позволяя им полностью задействовать их потенциал производительности и возможностей.
«NVIDIA передала ведущие графические процессоры с поддержкой DirectX 10 в руки лучших разработчиков игр, что является важной вехой в истории разработки игр для DirectX 10, — сказал Питер Мур (Peter Moore), вице-президент по решениям для интерактивных развлечений отделения Entertainment and Devices в Microsoft. — Серия GeForce 8 в сочетании с несравненными графическими возможностями DirectX 10 и Windows Vista, созданных с нуля для игр, предоставляет разработчикам игр практически неограниченные возможности для реализации своих идей».
Другой частью ведущей игровой платформы является новый MCP-процессор NVIDIA nForce 680i SLI, созданный для обеспечения высочайшей производительности ПК на базе Intel Core 2 Quad и Core 2 Duo. Нацеленный на энтузиастов MCP-процессор NVIDIA nForce 680i SLI предоставляет расширенную поддержку новейших технологий, включая усовершенствованную поддержку многопроцессорной графической технологии NVIDIA SLI. С двумя портами Gigabit Ethernet и передовыми функциями хранения данных NVIDIA nForce 680i SLI MCP способен менее чем за секунду переслать 30-минутную телепередачу с одного ПК на другой и хранить сотни фильмов высокой четкости. Чипсет также поддерживает высокопроизводительные SLI-Ready-модули памяти DIMM и третий слот PCI Express x16 для расширенных многоэкранных окружений и будущей обработки физики.
Помимо решения для ведущих производителей материнских плат NVIDIA также объявила о начале разработки и производства собственной линейки материнских плат на базе NVIDIA nForce 680i SLI для энтузиастов, которые предлагаются как завершенное решение некоторым партнерам по каналу. Программа «Разработано NVIDIA» позволяет партнерам компании, включая EVGA и других, вывести на рынок платы на базе NVIDIA nForce 680i SLI быстрее, чем когда-либо, и информирует потребителей, что платы, которые они покупают, полностью оснащены всеми программными и аппаратными функциями, поддерживаемыми в NVIDIA nForce 680i SLI MCP.
Графический процессор NVIDIA GeForce 8800
Итак, после краткого перечисления основных особенностей новой платформы NVIDIA самое время ознакомиться с новинками более детально. Основное внимание мы сосредоточим именно на рассмотрении новой архитектуры графического процессора NVIDIA GeForce 8800, которая, как уже отмечалось, является революционной архитектурой и знаменует собой новую веху в развитии графических процессоров — переход к унифицированным потоковым шейдерным процессорам. Впрочем, прежде чем разобраться во всем многообразии терминов, с которыми поневоле придется столкнуться при описании особенностей нового графического процессора, и понять, чем унифицированные шейдерные процессоры отличаются от классических вершинных и пиксельных, нам придется сделать небольшое отступление — дабы разобраться с классической архитектурой графического процессора и поближе ознакомиться с таким важным понятием, как API DirectX.
Принцип работы классического графического процессора
На заре развития персональных компьютеров видеокарты выполняли функцию кадрового буфера. То есть изображение формировалось центральным процессором компьютера и программным обеспечением, а карта отвечала лишь за его хранение (в буфере памяти) и вывод с определенной частотой отдельных кадров на монитор. По мере возрастания требований к качеству и реалистичности формируемого изображения, а также к скорости рендеринга отдельных кадров, пришло понимание того факта, что центральный процессор ПК, то есть процессор общего назначения, не в состоянии эффективно решать специфические задачи формирования трехмерного изображения и для этих целей требуется специализированный графический процессор (GPU), который бы занимался исключительно расчетом трехмерного изображения. Собственно, современные графические процессоры по сложности не уступают центральным процессорам (процессорам общего назначения), и разница заключается лишь в их специализации, благодаря чему они могут более эффективно справляться с задачей формирования изображения, выводимого на экран монитора.
Как и центральные, графические процессоры характеризуются такими параметрами, как микроархитектура, тактовая частота работы графического ядра и технологический процесс производства. Для графических процессоров есть и специфические характеристики, которые обычно приводятся в технической документации. К примеру, к важнейшим характеристикам графического процессора относится число вершинных (Vertex Pipelines) и пиксельных (Pixel Pipelines) конвейеров.
Забегая вперед, скажем, что для построения трехмерного изображения необходимо выполнить целый ряд операций: принять решение, какие объекты вообще должны присутствовать в сцене (видимые и невидимые объекты), определить местоположение вершин, которые задают каждый из этих объектов, построить по этим вершинам грани, заполнить получившиеся полигоны текстурами в соответствии с освещением, степенью детализации и учетом перспективных искажений и т.д. Чем тщательнее делаются все эти расчеты, тем реалистичнее получается трехмерное изображение. Повысить производительность этих рутинных операций можно за счет разбивки их по стадиям (конвейеризации) и распараллеливания. Именно эти вопросы и решают графические процессоры.
Для того чтобы лучше представить себе структуру современного графического процессора, рассмотрим более детально классический процесс конвейерного расчета трехмерного изображения (рис. 1).

Рис. 1. Классический процесс конвейерного
расчета трехмерного изображения
Вершинный процессор (Vertex Pipeline)
На первом этапе графический процессор получает от центрального процессора данные об объекте, который необходимо построить. Эти данные обрабатываются в вершинном процессоре или блоке (Vertex Pipeline), который является частью общего конвейера обработки данных. На основании полученных данных вершинный процессор занимается расчетом геометрии сцены и рассчитывает положение вершин, которые при соединении образуют каркасную модель трехмерного объекта. Кроме того, в вершинном процессоре производятся дополнительные операции над вершинами — преобразование и освещение (Transform & Lighting, T&L).
Обработка данных в вершинном процессоре происходит под управлением специализированной программы, называемой вершинным шейдером (Vertex Shader). Вершинные шейдеры производят математические операции с вершинами, то есть предоставляют возможность выполнять программируемые алгоритмы по изменению параметров вершин и их освещению (T&L). Каждая вершина в 3D-модели определяется тремя координатами — X, Y и Z. Вершины также могут быть описаны характеристиками цвета, текстурными координатами и т.п. Вершинные шейдеры, в зависимости от алгоритмов, изменяют эти данные в процессе своей работы, например вычисляя и записывая новые координаты и цвет. Входными данными вершинного процессора являются данные об одной вершине геометрической модели, которая в данный момент обрабатывается. Это могут быть координаты в пространстве, нормаль, компоненты цвета и текстурные координаты.
При помощи вершинных шейдеров вершинный процессор может выполнять такие операции, как, например, деформация и анимация объектов, имитация ткани и многое другое.
Сборка
На следующем этапе конвейера (Triangle) происходит сборка (Setup) трехмерной модели в полигоны. На этом этапе вершины соединяются между собой линиями, образуя каркасную модель. При соединении вершин друг с другом образуются полигоны (треугольники).
Пиксельный процессор (Pixel Pipeline)
После этапа сборки данные поступают в пиксельный процессор (Pixel Pipeline), который определяет конечные пикселы, которые будут выведены в кадровый буфер. Пиксельный процессор в итоге своей работы выдает конечное значение цвета пиксела и Z-значение для последующего этапа конвейера. Пиксельный процессор работает под управлением специальной программы, называемой пиксельным шейдером (Pixel Shader). Пиксельные шейдеры — это программы, выполняемые пиксельными процессорами во время растеризации для каждого пиксела изображения. Дабы данное определение не показалось слишком заумным, поясним, что подразумевается под понятием «растеризация». Это процесс разбиения объекта на отдельные точки — пикселы. Поскольку пиксельные шейдеры реализуют различные операции над отдельными пикселами, такие как затенение или освещение, текстурирование (операцию выполняет блок наложения текстур TMU), присвоение цвета, данных о прозрачности и т.п., то можно говорить, что пиксельный процессор работает на этапе растеризации.
Пиксельные шейдеры реализуют такие функции, как мультитекстурирование (наложение нескольких слоев текстуры), попиксельное освещение, создание процедурных текстур, постобработка кадра и т.д.
ROP
После обработки данных в пиксельном процессоре с помощью пиксельных шейдеров данные обрабатываются блоком растровых операций ROP (Raster Operations). На данном этапе с использованием буфера глубины (Z-буфера) определяются и отбрасываются те пикселы, которые будут не видны пользователю. Когда рассчитывается новый пиксел, его глубина сравнивается со значениями глубин уже рассчитанных пикселов с теми же координатами Х и Y. Если новый пиксел имеет значение глубины больше какого-либо значения в Z-буфере, новый пиксел не записывается в буфер для отображения (если меньше — то записывается).
Кроме буфера глубины, позволяющего отсекать невидимые поверхности, при создании реалистичных трехмерных изображений необходимо учитывать, что объекты могут быть полупрозрачными. Эффект полупрозрачности создается путем объединения цвета исходного пиксела с пикселом, уже находящимся в буфере. В результате цвет точки является комбинацией цветов переднего и заднего плана. Для учета прозрачности объектов используется так называемый alpha-коэффициент прозрачности, который имеет значение от 0 до 1 (для каждого цветового пиксела).
Недостатки классического графического конвейера
Описанная нами классическая архитектура графического конвейера дает наглядное представление об основных этапах формирования изображения видеокартой. При этом нужно отметить, что в графическом процессоре используется не один, а несколько конвейеров, работающих параллельно; чем больше в графическом процессоре таких конвейеров, тем она производительнее. Действительно, если, к примеру, в графическом процессоре реализовано 16 конвейеров, то первый из них обрабатывает 1-й, затем 17-й, потом 33-й пиксел и т.д.; второй — 2-й, 18-й и 34-й соответственно.
История развития графических процессоров до сих пор шла в одном направлении — увеличивалось число конвейеров. Понятие «конвейер» является устойчивым, но его нельзя считать строгим техническим термином. Дело в том, что в графическом процессоре используются разные конвейеры, которые выполняют отличающиеся друг от друга функции. В этом смысле более правильно говорить о вершинных или пиксельных конвейерах, но не о конвейерах вообще. Раньше под конвейером понимали пиксельный процессор, который был подключен к своему блоку наложения текстур (TMU). Например, если у графического процессора (GPU) используется восемь пиксельных процессоров, каждый из которых подключен к своему блоку TMU, то говорят, что у GPU восемь конвейеров. В то же время отождествлять число конвейеров с числом пиксельных процессоров не совсем корректно, поскольку конвейерная обработка подразумевает работу не только с пикселами, но и с вершинами, а значит, необходимо учитывать и число вершинных процессоров. Поэтому число конвейеров может выступать в качестве корректной характеристики графического процессора только в том случае, если количество конвейеров совпадает с числом пиксельных и вершинных процессоров и блоков TMU, то есть когда каждый конвейер включает по одному вершинному и пиксельному процессору, а также по одному блоку TMU. В то же время этот подход к архитектуре графического процессора нельзя признать оптимальным. Дело в том, что такая линейная организация конвейера подразумевает равномерное распределение нагрузки между отдельными стадиями конвейера. В то же время в реальных приложениях нагрузка на отдельные блоки графического процессора может быть различной. Отчасти решить проблему оптимизации нагрузки графического процессора позволяет такая архитектура, при которой количество пиксельных процессоров не совпадает с количеством вершинных процессоров. При этом разработчикам приходится искать золотую середину между количеством вершинных и пиксельных процессоров, поскольку необходимо не переборщить с геометрическими характеристиками и в то же время не урезать красоты, получаемые мультитекстурированием и сложными пиксельными шейдерами.
Понятно, что в подобном случае говорить о классическом конвейере не вполне корректно.
К примеру, в графическом процессоре NVIDIA GeForce 6800 (рис. 2) используется шесть вершинных процессоров и 16 пиксельных процессоров. Каждый из 16 пиксельных процессоров имеет два блока пиксельных программ и один текстурный модуль TMU. Если первый блок пиксельных программ на каждом конвейере может выполнять как арифметические операции, так и чтение текстур и нормализацию, то второй блок ограничен только арифметикой. Другими словами, первый блок связан с текстурами. Если блок не занимается текстурированием, то он может выполнять (в данный проход) пиксельное затенение. Второй всегда доступен для пиксельного затенения.
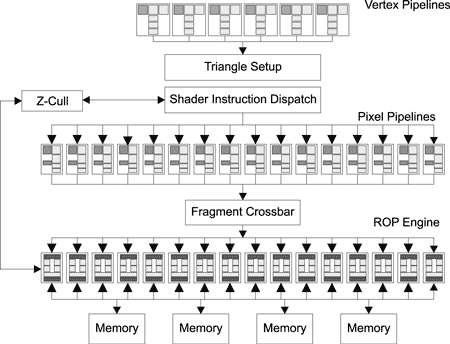
Рис. 2. Схема графического процессора NVIDIA GeForce 6800
Как мы уже отмечали, исторически под числом конвейеров в графическом процессоре принято понимать число пиксельных процессоров (хотя это и не вполне корректно). Для рассмотренной архитектуры NVIDIA GeForce 6800, как и для многих других графических процессоров, такой подход вполне приемлем, однако подобная организация лишь отчасти решает проблему сбалансированности нагрузки на GPU. Следующий шаг в этом направлении предложила компания ATI, перейдя на модульную, фрагментированную архитектуру в графических процессорах семейства ATI Radeon X1000.
Рассмотрим, к примеру, процесс формирования изображения в графическом процессоре ATI Radeon X1800 (рис. 3).
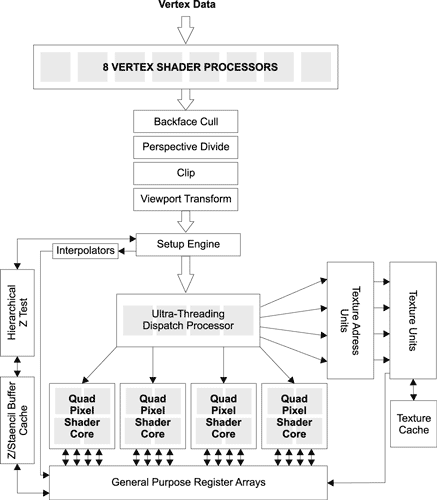
Рис. 3. Схема графического процессора ATI Radeon X1800
Первый этап вполне традиционен — это обработка данных вершинными процессорами, которые вычисляют геометрию трехмерного изображения. На этом этапе данные (Vertex Data) обрабатываются восемью вершинными процессорами (Vertex Shader Processor).
После расчета геометрии вершин, отсечения скрытых поверхностей, обрезки и т.д. данные поступают в блок сборки (setup engine), содержащий блок растеризации геометрии, потом — в процессор распределения данных Ultra-Threading Dispatch Processor. Именно этот новый блок распределения позволяет говорить о мультипоточной концепции архитектуры графического процессора. Процессор распределения Ultra-Threading Dispatch Processor способен распараллеливать шейдерный код на сотни потоков (до 512 потоков), увеличивая эффективность выполнения пиксельных шейдеров.
После прохождения процессора распределения потоки поступают в пиксельные блоки (Quad Pixel Shader Cores). Каждый такой блок (всего в графическом процессоре их четыре) состоит из четырех объединенных вместе пиксельных процессоров, каждый из которых в состоянии обработать шейдер для блока 2x2 пикселов за такт. Соответственно пиксельный блок может обрабатывать шейдер для блока 4x4 пикселов за такт.
Понятно, что в данной архитектуре термин «конвейер», равно как и «пиксельный конвейер», уже утратил свое значение.
В то же время, несмотря на некорректность использования термина «число конвейеров» в архитектуре графических процессоров семейства ATI Radeon X1000, необходимо отметить, что конвейерный способ построения изображения, применение отдельных вершинных и пиксельных процессоров остался неизменным. И хотя проблема оптимального распределения нагрузки между отдельными блоками GPU в архитектуре процессора ATI Radeon X1000 решена (хотя и не кардинально), данная архитектура не позволяет избавиться от еще одного недостатка конвейерной архитектуры GPU. Нередко возникает ситуация, когда уже частично обработанные данные необходимо изменить. Для этого приходится дожидаться завершения всего процесса конвейерной обработки данных, при котором конвейер работает впустую, обрабатывая данные, которые все равно придется изменять и обрабатывать повторно.
Недостатки конвейерной обработки данных в графических процессорах можно было бы решить, перейдя к архитектуре унифицированных процессоров, то есть когда не существует отдельных вершинных или пиксельных процессоров, а есть процессоры общего назначения, способные исполнять как вершинные, так и пиксельные шейдеры. Естественно, что для унифицированных процессоров потребуются и новые программы обработки, то есть шейдеры (Shader Model, SM). Унифицированные процессоры поддерживаются в API DirectX 10, однако, прежде чем переходить к детальному рассмотрению унифицированных процессоров, рассмотрим вкратце понятия DirectX и Shader Model.
Microsoft DirectX
DirectX (как и OpenGL) — это графический интерфейс прикладного программирования (Application Programming Interface, API). До появления API каждый производитель графических процессоров использовал собственный механизм общения с играми, и разработчикам игр приходилось писать отдельный код для каждого графического процессора, который они хотели поддержать. Поэтому для каждой игры указывалось, какие именно видеокарты она поддерживает. Чтобы решить эту проблему, которая являлась серьезным тормозом для игровой индустрии, был разработан API, что позволило устранить зависимость между игрой и конкретным графическим процессором. Графические процессоры поддерживали определенные версии API, а разработчики игр писали коды под определенную версию API.
Исторически существует два типа API: Microsoft DirectX и OpenGL. При этом нужно отметить, что большинство игр ориентировано именно на Microsoft DirectX.
Стандарт DirectX включает API для звука, музыки, устройств ввода и т.д. За 3D-графику в DirectX отвечает API Direct3D, и когда говорят о видеокартах, то имеют в виду именно его (поэтому понятия DirectX и Direct3D взаимозаменяемы).
Стандарт DirectX постоянно обновляется. В настоящее время большинство игр поддерживает DirectX 7.0, DirectX 8.0 и DirectX 9.0. Последняя версия DirectX — это DirectX 9.0с, а с выходом операционной системы Windows Vista появится и DirectX 10.
Каждая версия DirectX поддерживает определенные версии шейдеров (программ обработки вершин (Vertex Shader) и пикселов (Pixel Shader). Эти версии шейдеров называются Shader Model. К примеру, DirectX 8 поддерживает Pixel Shader от 1.0 до 1.3 и Vertex Shader 1.0, а DirectX 8.1 — Pixel Shader 1.4 и Vertex Shader 1.1.
В DirectX 9 поддерживаются Pixel Shader 2.0 и Vertex Shader 2.0, а в DirectX 9.0c — Pixel Shader 3.0.
Как уже отмечалось, первый графический процессор с поддержкой API DirectX 10 — это NVIDIA GeForce 8800. Основные характеристики DirectX 10 и его сравнение с предыдущими версиями DirectX представлены в табл. 1.
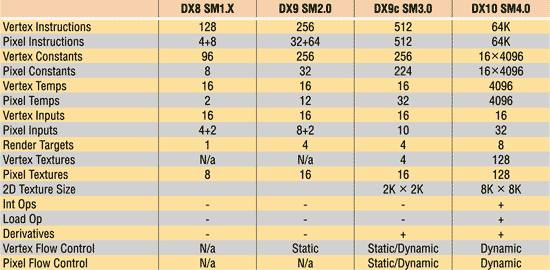
Таблица 1. Сравнение различных версий API DirectX
Архитектура GPU NVIDIA GeForce 8800 в деталях
Как уже отмечалось, одно из центральных мест в архитектуре графического процессора NVIDIA GeForce 8800 занимает унифицированный процессор, что позволяет избежать главного недостатка классической архитектуры — невозможности достижения сбалансированной нагрузки вершинных и пиксельных шейдеров. Прежде чем переходить к рассмотрению архитектуры ядра графического процессора, поясним, в чем заключается сущность унифицированного процессора, реализованного компанией NVIDIA .
Унифицированный потоковый процессор
Компания NVIDIA обосновывает необходимость перехода к унифицированным процессорам следующим образом. Предположим, что в воображаемом графическом процессоре с классической архитектурой присутствуют четыре вершинных и восемь пиксельных процессоров (рис. 4). Если, к примеру, в игре используются преимущественно вершинные шейдеры (трехмерные модели с насыщенной геометрией), то может возникнуть ситуация, что будут заняты все четыре вершинных процессора и только один пиксельный процессор, а оставшиеся семь пиксельных процессоров будут бездействовать. В этом случае производительность всего графического процессора определяется производительностью и количеством вершинных процессоров. В случае если в игре используются преимущественно пиксельные шейдеры (трехмерные модели с насыщенными пиксельными эффектами), то может возникнуть обратная ситуация, когда будут заняты только один вершинный процессор и все семь пиксельных процессоров. В этом случае производительность всего графического процессора определяется производительностью и количеством пиксельных процессоров.

Рис. 4. Проблема сбалансированной нагрузки при использовании
вершинных и пиксельных конвейеров
Данной проблемы можно избежать, если вместо четырех вершинных и восьми пиксельных процессоров (в сумме 12) использовать 12 унифицированных процессоров, которые могли бы выполнять как вершинные, так и пиксельные шейдеры (рис. 5).
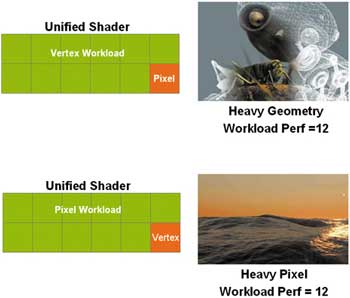
Рис. 5. Решение проблемы сбалансированной нагрузки
при использовании унифицированных процессоров
Впрочем, говорить, что главная особенность унифицированных процессоров NVIDIA заключается только в том, что они способны выполнять как вершинные, так и пиксельные шейдеры, было бы не вполне корректно. Унифицированные процессоры способны выполнять геометрические (Geometry) и физические (Physics) расчеты, чего вообще не было предусмотрено в графических процессорах предыдущих поколений (рис. 6).
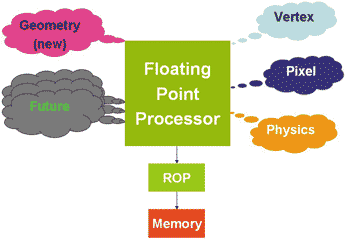
Рис. 6. Задачи, решаемые унифицированными процессорами
Унифицированные процессоры NVIDIA называются унифицированными потоковыми процессорами (Unified Streaming Processors, SP) и представляют собой скалярные процессоры общего назначения для обработки данных с плавающей запятой. Напомним, что традиционно в процессорах существует два типа математики: векторная и скалярная. В случае векторной математики данные (операнды) представляются в виде n-мерных векторов, при этом над большим массивом данных проводится всего одна операция. Самый простой пример — задание цвета пиксела в виде четырехмерного вектора с координатами R, G, B, A, где первые три координаты (R, G, B) задают цвет пиксела, а последняя — его прозрачность. В качестве простого примера векторной операции можно рассмотреть сложение цвета двух пикселов. При этом одна операция осуществляется одновременно над восемью операндами (двумя 4-мерными векторами). В скалярной математике операции осуществляются над парой чисел. Понятно, что векторная обработка увеличивает скорость и эффективность обработки за счет того, что обработка целого набора (вектора) данных выполняется одной командой. Рассмотрим в качестве примера программный цикл:
Do i = 1, n
A(i) = B(i)+C(i)
End Do
В скалярном режиме потребуется сгенерировать целую последовательность команд: прочитать элемент B(i), прочитать элемент C(i), выполнить операцию сложения, записать результат в A(i), увеличить параметр цикла, проверить условие цикла и т.д. В векторном режиме массивы элементов B(i) и С(i) можно рассматривать как n-мерные векторы. В таком случае этот фрагмент кода преобразуется в следующую последовательность: загрузить массив B, загрузить массив C, реализовать операцию векторного сложения и запись результата в массив A.
Впрочем, мы несколько отвлеклись от основной темы. Итак, как уже отмечалось, в графическом процессоре NVIDIA GeForce 8800 реализованы унифицированные скалярные процессоры, а не векторные. Дело в том, что векторная архитектура является в какой-то степени традиционной для графических процессоров по причине преобладающего количества операций с векторными данными, такими как компонентная R-G-B-A-обработка в пиксельных шейдерах или геометрическое преобразование 4x4-матриц в вершинных шейдерах.
К примеру, в графических процессорах NVIDIA предыдущего поколения, а также в графических процессорах ATI используется векторная архитектура исполнительных блоков. В результате векторные исполнительные блоки в последних версиях графических процессоров ATI способны выполнять одну векторную операцию за такт для четырехэлементных (4-мерных) векторов или одну векторную операцию для трехэлементных векторов плюс одну скалярную операцию (схема «3+1»). Векторные исполнительные блоки в графических процессорах NVIDIA GeForce 6x и GeForce 7x работают по схеме «2+2», то есть способны выполнять одновременно две векторные операции для двухэлементных векторов или одну векторную операцию для четырехэлементных векторов.
В последнее время наблюдается переход от векторных к скалярным вычислениям. Так, проанализировав сотни шейдерных программ, разработчики NVIDIA пришли к выводу, что традиционная векторная архитектура менее эффективно использует вычислительные ресурсы, нежели скалярный дизайн процессорных модулей, особенно в случае обработки сложных смешанных шейдеров, сочетающих векторные и скалярные инструкции. Кроме того, достаточно сложно добиться эффективной обработки скалярных вычислений с помощью векторных исполнительных модулей. Поэтому в унифицированных процессорах NVIDIA применяются скалярные исполнительные блоки. При этом векторный шейдерный программный код преобразуется в скалярные операции непосредственно графическим процессором GeForce 8800.
Забегая вперед, отметим, что в графическом процессоре NVIDIA GeForce 8800 используются 128 скалярных унифицированных процессоров. Причем разработчики компании NVIDIA подсчитали, что применение такого количества скалярных процессоров дает двукратный прирост производительности в сравнении с 32 векторными процессорами, функционирующими по схеме «3+1».
Архитектура ядра GPU NVIDIA GeForce 8800
После рассмотрения особенностей унифицированных процессоров, используемых в GPU NVIDIA GeForce 8800, изучим более детально архитектуру самого ядра GPU.
В графическом процессоре NVIDIA GeForce 8800 применяются 128 потоковых унифицированных процессоров, каждый их которых работает на тактовой частоте 1,35 ГГц. Структурная схема GPU NVIDIA GeForce 8800 представлена на рис. 7.
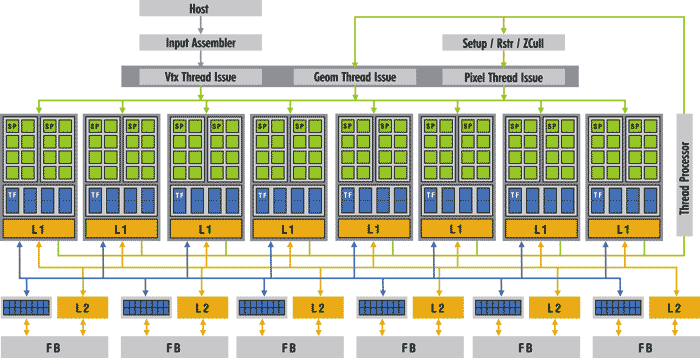
Рис. 7. Структурная схема графического процессора NVIDIA GeForce 8800
Потоковые процессоры сгруппированы в восемь блоков по 16 штук, каждый из которых оснащен четырьмя текстурными модулями и общим L1-кэшем.
Каждый блок представляет собой два шейдерных процессора (состоящих из восьми потоковых процессоров каждый), при этом все восемь блоков имеют доступ к любому из шести L2-кэшей и к любому из шести массивов регистров общего назначения. Таким образом, обработанные одним шейдерным процессором данные могут быть использованы другим шейдерным процессором.
На каждые четыре потоковых процессора приходится один текстурный блок, включающий один блок адресации текстур (Texture Address Unit, TA) и два блока фильтрации текстур (Texture Filtering Unit, TF) (рис. 8). При этом отметим, что текстурные блоки и кэш работают на частоте 575 МГц.
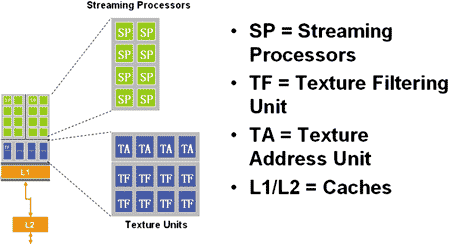
Рис. 8. Организация блоков унифицированных потоковых процессоров
Графический процессор GeForce 8800 GTX обладает шестью разделами растровых операций (ROP). Каждый раздел ROP способен обрабатывать четыре пиксела за такт с общей производительностью 24 пиксела за такт с обработкой цвета и Z-обработкой.
Блоки растровых операций поддерживают мультисэмплированный, суперсэмплированный и прозрачный адаптивный антиалиасинг. Важно отметить, что добавлены и новые режимы антиалиасинга — 8x, 8xQ, 16x и 16xQ. Более подробно об этих режимах мы расскажем чуть позже, а пока лишь отметим, что новый графический процессор поддерживает сглаживание как в формате FP16, так и в формате FP32, так что проблема, свойственная архитектурам GeForce 6х и GeForce 7х, заключавшаяся в невозможности одновременного использования полноэкранного сглаживания и режима HDR, в GeForce 8800 полностью решена.
Еще одной ключевой особенностью архитектуры графического процессора GeForce 8800 является возможность потоковой циклической обработки данных, что позволяет устранить уже упоминавшийся недостаток классической конвейерной схемы графического процессора — неоптимальное использование ресурсов в случае повторной обработки данных.
В архитектуре GeForce 8800 входящие данные (input stream) поступают на вход одного унифицированного процессора, обрабатываются им, по выходе (output stream) записываются в регистры, а затем вновь подаются на вход другого процессора для исполнения следующей операции обработки.
Возможность такой циклической потоковой обработки данных одновременно с унифицированными процессорами позволяет решить проблему их повторной обработки, довольно часто встречающуюся в современных играх. К примеру, унифицированный процессор под управлением вершинного шейдера создает куб, который передается для дальнейшей обработки (подвергается текстурированию), одновременно данные поступают на вход другого унифицированного процессора, который создает из этого куба пирамиду или другую трехмерную фигуру. В случае традиционной линейной архитектуры процессора при такой операции пришлось бы дождаться полного формирования изображения и повторно считывать данные из кадрового буфера.
На рис. 9 показана схема организации потоковой циклической обработки данных в процессоре GeForce 8800.
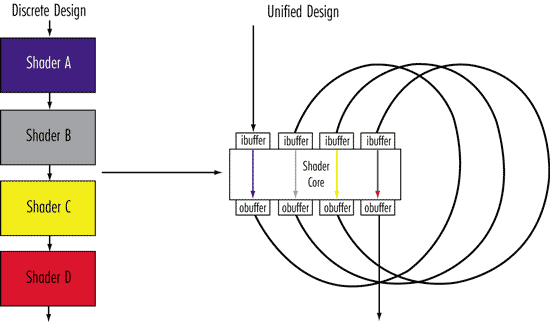
Рис. 9. Организация потоковой циклической обработки данных в процессоре GeForce 8800
Потоковая обработка данных, реализованная в GPU GeForce 8800, является составной частью API DirectX 10. Такая архитектура позволяет отправлять в буфер памяти данные, обработанные вершинным или геометрическим шейдером, а затем вновь использовать их либо для последующей, либо для повторной обработки. Схема потоковой обработки данных для DirectX 10 показана на рис. 10.
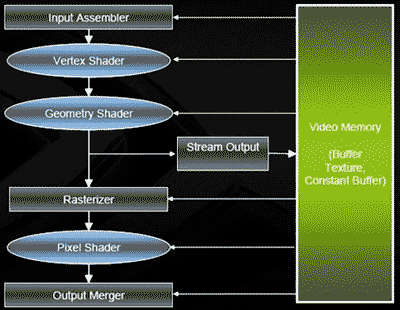
Рис. 10. Схема потоковой обработки данных
Технологии, поддерживаемые графическим процессором GeForce 8800
Как уже отмечалось, новый графический процессор поддерживает множество новых функций и технологий, среди которых:
- новые режимы антиалиасинга и анизотропной фильтрации;
- поддержка геометрических шейдеров, реализованных в DirectX 10;
- режим HDR;
- технология расчета физических эффектов NVIDIA Quantum Effects;
- поддержка режима Extreme High Definition Gaming;
- технология PureVideo и PureVideo HD.
Рассмотрим эти технологии и режимы более подробно.
Новые режимы анизотропной фильтрации
В графическом процессоре GeForce 8800 реализованы, по заявлениям разработчиков, новые и очень высококачественные режимы полноэкранного сглаживания (антиалиасинга) (AA) и анизотропной фильтрации (AF).
Новая технология антиалиасинга основана на так называемых coverage samples и получила название Coverage Sampling Antialiasing (CSAA). При этом поддерживаются четыре новых режима CSAA: 8x, 8xQ, 16x и 16xQ.
Технология CSAA обеспечивает более высокое качество сглаживания, чем технологии, реализованные в предыдущих версиях графических процессоров NVIDIA.
Каждый из новых режимов AA активизируется из панели управления драйвера NVIDIA, при этом необходимо выбрать опцию с названием Enhance the Application Setting.
Новая технология сглаживания CSAA позволяет снизить требования к размеру и пропускной способности памяти в сравнении с традиционным методом MSAA. По заявлению специалистов компании NVIDIA , производительность в режиме CSAA 16x лишь на 10-20% ниже, чем в режиме MSAA 4x.
Что касается анизотропной фильтрации, то в графическом процессоре GeForce 8800 реализован алгоритм, в котором качество фильтрации не зависит от угла наклона плоскости текстуры, что позволяет добиться большей четкости и резкости различных объектов, расположенных под острым углом или уходящих в перспективу.
Поддержка геометрических шейдеров
Как уже неоднократно упоминалось, одной из ключевых особенностей нового графического процессора NVIDIA GeForce 8800 являются унифицированные процессоры, а также поддержка API DirectX 10. Эти унифицированные процессоры поддерживают не только вершинные и пиксельные шейдеры, но и геометрические шейдеры (Geometry shaders), что является неотъемлемой частью DirectX 10.
Геометрические шейдеры — это программы, позволяющие обрабатывать данные не на уровне отдельных вершин, как в вершинных шейдерах, а на уровне примитивов, то есть наборов вершин, например линий, полосок, треугольников и т.д.
Геометрические шейдеры позволяют существенно повысить эффективность преобразования сложных трехмерных объектов. В качестве примера одного из возможных вариантов использования геометрических шейдеров можно привести процесс создания и анимации реалистичных волос. В случае использования API DirectX 9 этот процесс реализовывался преимущественно с применением центрального процессора системы (CPU). В частности, интерполяция и тесселяция контрольных точек, сохранение в памяти осуществлялись средствами CPU. При использовании DirectX 10 весь процесс моделирования волос возлагается на графический процессор с применением геометрических шейдеров (табл. 2).

Таблица 2. Сравнение возможностей DirectX 9 и DirectX 10
Режим HDR
Режим HDR — это режим рендеринга в широком динамическом диапазоне (High Dynamic Range).
Стандартной моделью описания цвета является модель RGB, когда любой цвет получается при смешении трех базовых цветов (красного, зеленого и синего), а интенсивность каждого компонентного цвета задается в виде градаций от 0 до 255. При этом для описания каждого компонентного цвета используется 8 бит, что позволяет описать 256 цветовых оттенков, а всего можно описать 16 777 216 цветов (224).
Отношение максимальной интенсивности к минимальной называется динамическим диапазоном. Так, динамический диапазон модели RGB составляет 256:1. Эту модель описания цвета и интенсивности принято называть Low Dynamic Range (LDR).
В то же время человеческий глаз способен видеть гораздо больший диапазон, особенно при малой интенсивности света.
Динамический диапазон зрения человека — от 10-6 до 108. Естественно, что увидеть одновременно весь динамический диапазон человеческий глаз не в состоянии, но диапазон, видимый глазом в каждый момент времени, примерно равен 10 000. Как известно, человеческое зрение способно постепенно приспосабливаться к условиям освещенности, то есть перестраиваться с одного динамического диапазона на другой. К примеру, если в темной комнате погасить свет, то первые несколько минут человек ничего не видит. Но постепенно зрение адаптируется под новые условия освещенности, и в темноте начинают появляться силуэты.
Понятно, что модель RGB с ее низким динамическим диапазоном плохо соответствует реальным возможностям человеческого зрения.
Идея режима HDR заключается в том, чтобы для описания цветовых компонентов и интенсивности использовать числа с плавающей точкой с большой точностью (например, 16 или 32 бита). Это снимет ограничения модели RGB, а динамический диапазон изображения серьезно увеличится.
У режима HDR есть множество и других возможностей, которые можно задействовать для повышения реалистичности изображения. К примеру, режим HDR дает возможность имитировать эффект адаптации человеческого зрения к меняющимся условиям освещения. Кроме того, данный режим является эффективным для применения постобработки и позволяет более качественно реализовывать такие эффекты, как цветокоррекция, гамма-коррекция, glare (эффект блеска), flares (эффект вспышки), bloom (освещение мягким светом) и motion blur (эффект движения).
Графические процессоры серии GeForce 8800 поддерживают процесс рендеринга HDR (High Dynamic Range) с 128-битной точностью не только в режиме FP16 (64-битный цвет), но и FP32 (128-битный цвет), которые могут обрабатываться одновременно с процессом антиалиасинга. Это позволяет добиться реалистичных эффектов освещения и наложения теней, при этом обеспечиваются высокая динамика и детализация самых затемненных и самых светлых объектов. Правда, нужно отметить, что существующие сегодня мониторы не способны выводить изображение в широком динамическом диапазоне. Поэтому даже в случае использования режима HDR при ренедеринге для вывода изображения на экран монитора все равно будет использоваться стандартная модель RGB. В связи с этим сегодня режим HDR можно рассматривать только как эффективное средство для создания различных визуальных эффектов.
Технология расчета физических эффектов NVIDIA Quantum Effects
NVIDIA Quantum Effects — это технология расчета физических эффектов (расчет физики) средствами графического процессора. С помощью графического процессора GeForce 8800 технология NVIDIA Quantum Effects позволяет имитировать и рендерить множество новых физических эффектов, таких как имитация огня, дыма, взрывов, движущихся волос, воды и т.д. Разумеется, самые интересные игровые эффекты с эмуляцией физических явлений можно будет наблюдать после выхода DirectX 10-игр.
Режим Extreme High Definition Gaming
Новые графические процессоры семейства GeForce 8800 и соответственно все видеокарты на базе этих процессоров поддерживают игровые установки Extreme High Definition (XHD), при которых игры могут запускаться в широкоформатных режимах вплоть до 2560x1600, что в семь раз превышает качество картинки HD телевизора формата 1080i и в два раза — формата 1080p.
Технология PureVideo HD
Технология NVIDIA PureVideo HD хорошо известна, поскольку реализована во всех современных видеокартах NVIDIA. Естественно, что данная технология реализована в видеокартах на базе графических процессоров GeForce 8800. Напомним, что данная технология обеспечивает высокое качество и плавное воспроизведение HD Video-контента с носителей HD DVD и Blu-ray при минимальном задействовании ресурсов центрального процессора. Технология PureVideo HD является комплексным программно-аппаратным решением с поддержкой HDV-форматов H.264, VC-1, WMV/WMV-HD и MPEG-2 HD. Помимо этого чипы GeForce 8800 поддерживают технологию PureVideo для работы со стандартными форматами WMV и MPEG-2. Защищенный AACS-контент с носителей Blu-ray или HD DVD может воспроизводиться системами на базе GeForce 8800 с использованием AACS-совместимых плееров (CyberLink, InterVideo, Nero). Все карты GeForce 8800 обладают поддержкой системы защиты HDCP для дисков Blu-ray Disc и HD DVD, позволяя воспроизводить защищенное видео на ПК при использовании HDCP-совместимых дисплеев.
Семейство процессоров GeForce 8800
Итак, в состав семейства GeForce 8800 вошли два процессора: GeForce 8800 GTX и урезанный вариант GeForce 8800 GTS. При этом особенно подчеркнем, что все видеокарты на основе этих графических процессоров, которые можно будет встретить на рынке под логотипами разных компаний, на самом деле являются референсными видеокартами NVIDIA и ничем (кроме коробки и, возможно, комплектации) не отличаются друг от друга.
Рекомендованная стоимость видеокарты на GPU NVIDIA GeForce 8800 GTX составляет 599 долл., а видеокарты на GPU NVIDIA GeForce 8800 GTS — 499 долл.
Графические процессоры семейства GeForce 8800 выполнены по 90-нанометровому техпроцессу. При этом топовая модель NVIDIA GeForce 8800 GTX имеет 681 млн транзисторов. Все процессоры семейства GeForce 8800 производятся компанией TSMC.
Разница между процессорами GeForce 8800 GTX и GeForce 8800 GTS заключается в числе унифицированных потоковых процессоров (SP), тактовой частоте работы SP и графического ядра, а также в разрядности шины памяти, частоте работы памяти и объеме поддерживаемой памяти. Так, GPU GeForce 8800 GTX имеет 128 унифицированных потоковых процессоров, а GeForce 8800 GTX — только 96. При этом тактовая частота SP в GeForce 8800 GTX составляет 1350 МГц, а в GeForce 8800 GTS — 1200 МГц. Тактовая частота остальных блоков (кэш, модули текстурирования и т.д.) процессора GeForce 8800 GTX равна 575 МГц, а процессора GeForce 8800 GTS — 500 МГц.
Референсная видеокарта на базе процессора GeForce 8800 GTX имеет 768 Мбайт видеопамяти GDDR3. При этом ширина шины памяти составляет 384 бит, а частота работы памяти — 1800 МГц. Соответственно пиковая пропускная способность шины памяти равна 86,4 Гбайт/с.
Референсная видеокарта на базе процессора GeForce 8800 GTS имеет 640 Мбайт видеопамяти GDDR3. При этом ширина шины памяти составляет 320 бит, а частота работы памяти — 1600 МГц. Соответственно, пиковая пропускная способность шины памяти равна 64 Гбайт/с.
Все остальные технические характеристики и функциональные возможности видеокарт на процессорах GeForce 8800 GTX и GeForce 8800 GTS совпадают.
Заключение
Несомненно, графические процессоры семейства GeForce 8800 являются на сегодня самыми производительными игровыми графическими процессорами. Но далеко не все их потенциальные возможности можно сегодня реализовать. Так, эти процессоры поддерживают спецификацию API DirectX 10, которая еще официально не объявлена (DirectX 10 будет составной частью Windows Vista). Кроме того, нет и игр, совместимых с DirectX 10. Ну а поскольку раскрыть все потенциальные возможности видеокарт на базе процессоров семейства GeForce 8800 можно будет только при использовании приложений DirectX 10, то понятно, что эти карты ориентированы на будущее.
В то же время ориентация графических карт на базе процессоров нового поколения на приложения DirectX 10 вовсе не означает, что они не совместимы с приложениями DirectX 9 и вообще с любыми играми. Причем, как показывают результаты тестирования, проведенного специалистами компании NVIDIA, даже на современных играх, не поддерживающих DirectX10, видеокарта на графическом процессоре GeForce 8800 GTX позволяет получить рекордный уровень производительности, недоступный для видеокарт на базе процессоров ATI и для видеокарт на базе процессоров NVIDIA предыдущего поколения.








