Каким будет поиск в будущем
Улучшение существующих поисковых машин
Использование систем вертикального поиска
Количество информации, которую создает мировое сообщество, растет с каждым годом. И в век высоких технологий ее большая часть попадает во Всемирную сеть. Открытость информационного поля обеспечивает доступ к знаниям каждому человеку независимо от того, в какой стране он живет. И даже российские образовательные учреждения и библиотеки обращают все больше внимания на электронные копии, в которые переводятся многие редкие книги. Если раньше ученые и студенты были вынуждены стоять в очереди на ту или иную книгу и пользоваться ею только в читальном зале, то сегодня ее можно скачать на свой компьютер и изучать в любом месте.
Однако у такой всеобщей доступности есть и обратная сторона — чтобы получить информацию, ее нужно сначала найти, а это становится очень сложной задачей.
Сегодня все наиболее популярные поисковые системы работают по горизонтальному принципу: стремятся обработать максимальное количество данных и выдать наиболее релевантные результаты пользователю. Сложность заключается в том, что пользователь не может описать системе признаки искомого объекта, поскольку принцип поиска таких компаний, как Яndex и Google, базируется на тексте и ключевых словах. Фактически пользователь не может найти те данные, о которых он не имеет представления, а для того, чтобы получить нужную информацию, человеку необходимо ввести в строку запроса как можно больше слов, содержащихся в ответе. Таким образом, чтобы получить ответ, мы уже должны его знать.
Если раньше поиск не вызывал особых трудностей из-за небольшого объема индексированных страниц, то сегодня пользователи вынуждены перекопать целые горы поискового мусора, чтобы найти действительно важную информацию. Справедливости ради нужно добавить, что поисковые системы стараются помочь пользователям в этом, ведь от качества поиска напрямую зависит количество приверженцев того или иного сервиса, а значит и объемы финансовой прибыли, большую часть которой составляют рекламные отчисления.
Разумеется, единого рецепта улучшения качества поиска не существует. Предлагается несколько разработок, каждая из которых решает те или иные задачи. Их мы и рассмотрим в настоящей статье.
Улучшение существующих поисковых машин
Первый принцип систематизации данных заключается в улучшении выдачи поисковых систем. Причем для этого не нужно создавать собственный индекс — большинство сервисов сегодня имеют удобные интерфейсы для экспорта результатов запросов. Все, что для этого нужно, — принимать запросы от пользователей, передавать их системе типа Google, получать от нее результат и обрабатывать его перед выдачей клиенту.
Данная идея не нова, еще на заре Интернета наряду с поисковыми машинами появились сервисы метапоиска, которые объединяли на странице результаты выдачи нескольких поисковых систем. В то время как разные поисковики зачастую индексировали различные сегменты Сети, подобные системы решали проблему недостаточности объема информации, до которой может «дотянуться» один поисковый сервис.
Сегодня такая задача не стоит. Скорее наоборот — из тысяч страниц выдачи пользователю нужно отобрать одну — единственно верную и содержащую интересующие его данные.
Попытки улучшить поиск предпринимают и сами поисковые системы, например Google реализует проект searchmash.com, на котором испытывает свои новые разработки. Здесь, когда пользователь что-то ищет, ему предлагают также результаты поиска по картинкам, блогам, видеофайлам и энциклопедии «Википедия».
![]()
Проект searchmash.com создан
компанией Google для тестирования собственных
поисковых инноваций
Компания Microsoft поддерживает сервис live.com, который, как ни странно, становится все больше похож на Google, при том что призван помочь корпорации бороться с этим поисковым гигантом.
Интерес представляет независимая разработка Snap.com, которая объединяет сразу несколько небольших улучшений интерфейса. Основная инновация сервиса — изображения сайтов в результатах поиска, которые динамически подгружаются в правой части страницы. Пользователь сразу может оценить полезность найденного материала и сэкономить некоторое количество времени. Система использует поисковую выдачу сервиса ask.com, позволяя посетителям оценивать ее и влиять на дальнейшее положение того или иного сайта в результатах поиска.
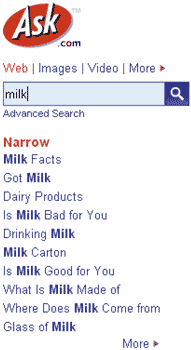
При запросе «молоко» сервис ask.com,
помимо непосредственных ссылок, выдает
«соседствующие» и связанные с ним
по смыслу понятия — производство молока,
потребление молока и т.п.,
группируя сайты в кластеры
Интересно, что и сам сервис ask.com является в какой-то мере попыткой понять, что же именно хочет найти пользователь. Эта система разбивает выдачу на кластеры, в которые помещает тематически схожие ответы, давая таким образом пользователю возможность самому указать на объект поиска. В России вот уже несколько лет развивается сервис Nigma.ru, которым занимаются аспиранты и студенты МГУ. Правда, практическая ценность такого поиска пока видна не всем. Возможно, потому, что кластеризация далека от идеала и разработчикам еще есть над чем поработать.
Использование систем вертикального поиска
Еще одним направлением работы поисковых машин является создание вертикальных систем, которые направлены на обработку и выдачу данных по определенной тематике или по группе тем. Такой подход оправдан, поскольку каждая тема включает разные типы объектов с различной структурой. Например, если пользователь осуществляет поиск по базе вакансий, то ему интересно название компании, должностные обязанности, уровень заработной платы и отзывы сотрудников об этом работодателе. В то же время если вы ищете фильм по базе, то вас интересуют уже другие данные — название, режиссер, год выпуска и задействованные актеры (хорошим примером является сайт imdb.com). Очевидно, что найти всю эту информацию можно и с помощью Google, но эффективность и удобство представления данных при этом будут ниже, чем у специально ориентированных поисковиков.
Семантическая паутина
Описывая специализированные поисковые машины, мы упоминали такой термин, как объект. Данные системы работают именно с объектами, а не с фрагментами текста, а следовательно, подобный подход позволяет осуществлять более эффективный поиск. Однако слабость методики заключается в том, что сейчас практически вся информация в Интернете представляет собой как раз текст, и, чтобы столь же эффективно решать задачи глобального поиска, нужно научиться из текста выделять объекты. Такой подход и носит название семантической паутины, или, как его уже успели окрестить, Web 3.0.
Более 30% всех поисковых запросов в Интернете — информация о персонах или компаниях, которую довольно трудно выделять из текстов. Но первые попытки уже делаются: если вы зайдете в поиск «Яндекса» по новостям, то увидите колонку с фамилиями людей, которые были найдены в новостных лентах. И там же сможете ознакомиться с их высказываниями, которые были включены в новости.
Концепция семантической паутины имеет два противоположных подхода. Первый подразумевает определение типов данных и связей между объектами самими авторами веб-страниц. Такую концепцию еще в 2001 году предложил не кто иной, как Тим Бернерс-Ли — создатель Всемирной паутины, человек, сделавший Интернет интересным для массового пользователя и обеспечивший каждому возможность работать в Сети практически без специальной подготовки. В журнале Scientific American он опубликовал статью, в которой рассказывает о будущем созданной им Паутины, где роботы смогут так же просто воспринимать информацию с сайтов, как это сегодня делают люди. Поисковые роботы смогут понимать не только написание слов, но и их значение, им можно будет объяснить, в каком случае Paris Hilton — это название отеля, а в каком — имя его хозяйки.
Согласно Wikipedia, cемантическая паутина (англ. Semantic web) — новая концепция развития Всемирной паутины и сети Интернет, принятая и продвигаемая Консорциумом Всемирной паутины. Иногда она также называется семантический веб. Cемантическая паутина — это надстройка над существующей Всемирной паутиной, которая призвана сделать размещенную в сети информацию более понятной для компьютеров. Известно, что почти вся информация в Интернете находится в текстовой форме. Не секрет также, что прогресс в области обработки иностранных языков (Natural Language Processing) идет очень медленно. Компьютеры не могут воспринять и осмыслить словесную информацию, размещенную в Интернете, и в ближайшее время, видимо, ничего не изменится. Тогда встает вопрос: как же научить компьютеры понимать смысл размещенной в Сети информации и пользоваться ею? На него и призвана ответить концепция семантической паутины. Слово «семантическая» в данном случае означает «осмысленная», «понятная». |
Правда, для того чтобы роботы научились воспринимать информацию, люди должны хорошо потрудиться и описать все значения и отношения между объектами в специальном микроязыке. Прошло шесть лет, и сообщество смогло договориться о спецификации этих языков — так появился стандарт описания ресурсов (Resource description framework, RDF) и онтологический язык (Ontology markup language, OWL). Сегодня мы имеем возможность переписать все данные в Сети так, чтобы поисковые машины могли хорошо их понимать, но для этого у нас совершенно нет ресурсов. Количество информации в Интернете столь огромно, что нет такой силы, которая могла бы в одночасье модернизировать всю Сеть. В то же время уровень проникновения Интернета растет и появляются все новые пользователи, которые создают контент в свое свободное время и вряд ли захотят заниматься описанием объектов на новом языке.
Тем не менее прикладное использование стандартов уже началось. Кулинарный портал Yahoo! Food уже сейчас демонстрирует, насколько более комфортной становится жизнь пользователя, если роботы видят связи между объектами. Возможность определять связи появилась и во многих системах публикации данных open-source, вопрос лишь в том, будут ли создатели сайтов ею пользоваться.
Существует и противоположный подход к концепции семантической паутины. Разработчики строят системы, которые самостоятельно анализируют содержание Интернета и переводят его из текстового представления в объектное. Это непростая задача, ведь нужно создать онтологию каждого процесса, а для этого необходимо знать структуру взаимоотношений объектов, правила их существования и интерпретации.
Например, семья.
Структура: родители, дети и т.п.
Правила действия: дети родили и стали родителями, мамы стали бабушками и т.д.
Возможные интерпретации: шведская семья, мусульманская семья, семья Ельцина — и соответствующие правила наследования имущества, проживания и устройства.
Плагин для браузера BlueOrganiser компании Adaptive Blue пытается понять смысл сайта, который вы посещаете, и выдает список ссылок по данной теме. Авторы программы говорят, что страницы уже содержат всю необходимую размеченную информацию, и если человек может ее воспринимать, то возможно создать и робота, которому это будет под силу. Правда, пока такие попытки выглядят довольно примитивно и практически ничем не отличаются от помощника на Amazon.com или в подобных интернет-магазинах.

Компания Hakia создала одноименный
сервис под громким лозунгом: «Ищем смысл»
Поиск производится не по текстовому индексу, а по базе, уже разбитой на вопросы и ответы, которые робот выделяет из текстовой информации на сайтах. Конечно, задавать вопрос в Hakia тоже необходимо на обычном человеческом языке. К сожалению, пока компания не может похвастаться адекватностью поисковой выдачи, а тем более строительством онтологий. Сейчас представлена только предварительная альфа-версия сервиса, хотя коммерческое использование технологии планируется начать уже в этом году. На разработку проекта компания собрала около 30 млн долл., в основном от частных европейских инвесторов. В дополнение к собственной технологии сервис позволяет роботу обучаться и более эффективно искать ответы на задаваемые вопросы. Пользователи могут оценить результат и дать рекомендацию роботу. Правда, здесь кроется множество опасностей — от злоумышленной накрутки сайтов до отсутствия в выдаче непопулярных запросов. Например, при запросе Queen мне ни разу не удалось выйти на информацию о королевской семье.
Запросы на натуральном языке многие называют панацеей для поисковых систем будущего. Не совсем понятно, почему пользователь должен стараться сделать запрос удобным для машины, а не наоборот. В этом направлении тоже ведутся разработки, которые пока ограничиваются простым переводом человеческого языка на язык запросов.
Интересен старт-ап-проект Powerset — в режиме закрытого тестирования он собрал более 12 млн долл. на разработку. Авторы обещают инновационный подход к поиску данных. Язык натуральных запросов для них — это четкий язык поисковых терминов. Powerset учитывает при обработке запроса слова, которые обычно не рассматриваются (стоп-слова). В первую очередь речь идет о предлогах, которые на самом деле содержат основную управляющую нагрузку. То есть для Powerset фразы «Одежда из Испании» и «Одежда для Испании» будут иметь столь же разную смысловую нагрузку, как и для нас с вами. В списке инвесторов-«ангелов», опубликованном на сайте powerset.com, можно найти имена Питера Тиля (Peter Thiel) — основателя PayPal, Эрика Тинелиуса (Eric Tinelius) — основателя answers.com и других предпринимателей, уже рисковавших деньгами ради инноваций и оказавшихся в выигрыше.

Расшифровать человеческий язык
и превратить его в точный механизм определения
отношений в словосочетаниях,
а в последующем и всего смысла высказывания —
задача сложная, но предельно важная.
Именно ее поставили перед собой
разработчики старт-ап-проекта Powerset
Социализация поисковых систем, наверное, будет неизбежной. Некоторые из существующих систем уже отслеживают предпочтения своих пользователей и предоставляют им отобранную информацию. К таким проектам относятся в первую очередь del.icio.us и российский аналог «БобрДобр».
Нет сомнений, что рано или поздно поиск в «коллективном разуме» превратится в особое направление. Помимо крупных игроков, на этом рынке появляются новые старт-апы, например компания Collarity из Пало-Альто. Данный сервис обладает удобным интерфейсом и возможностями настройки поиска по всему Интернету в рамках личных настроек или в комьюнити пользователей. Пока поисковик плохо проходит тест на Paris Hilton, но с увеличением числа пользователей, возможно, поиск станет более эффективным. Надо сказать, что практически все сервисы закладок, такие как популярнейший del.icio.us, уже являются социальными поисковиками. Пользуясь тэговой разметкой, вы можете найти наиболее популярные сайты по теме и выбрать из них нужные. Не вызывает сомнений тот факт, что Yahoo! приобрела сервис для развития собственной поисковой системы.
Медиапоиск
Если речь идет о поиске текстовой информации, то все более-менее понятно и мы можем сегодня рассчитывать на адекватный поиск с помощью Google и подобных ей поисковых машин. Все возникающие проблемы и вопросы так или иначе находятся в поле текстовой информации. Но что происходит, когда нам нужно найти музыкальный файл, видеоролик или изображение? Мы вынуждены пытаться дать поисковой системе описание изображения или звука в текстовом виде. Люди, которые когда-либо писали рецензии на кинофильмы и музыкальные альбомы, поймут, что сделать это крайне сложно, — ведь даже в процессе общения люди зачастую не могут передать словами то, что не хранится в текстовом виде. Что же говорить о поиске, когда даже с текстом возникает множество серьезных проблем?!
Когда мы собираемся найти медиафайл и вводим его описание, то каким бы четким и однозначным оно ни было, Google не может сопоставить фразу «Портрет Ренуара» с конкретным изображением. Все, на что она способна, — это поиск описаний, подписей к фотографиям и текстового окружения картинок на странице. Очевидно, что все это может серьезно исказить результаты поиска. Мы вынуждены слепо доверять авторам сайтов, которые, хочется надеяться, обладают достаточной квалификацией и желанием, чтобы описать те файлы, которые они помещают на своих страницах.
Единственный выход из ситуации — искать медиафайлы с помощью других медиафайлов. Если нам нужно изображение, то мы должны показать поисковой системе эскиз, похожий на то, что мы ищем. Если мы хотим найти музыку, то проще всего дать роботу файл, в котором будут содержаться подобные звуки. Сегодня существует три сервиса медиапоиска, которые должны упростить нашу дальнейшую жизнь, причем один из них уже нашел свое прикладное применение.
Нынешней весной компания Ojos выпустила новый сервис Riya, который позволяет размещать фотографии в публичном доступе. Этот сервис, казалось бы, ничем не отличается от традиционных фотохостингов: в нем также есть возможность установить тэги на фотографии, создать папки и осуществлять поиск. Его особенность заключается в том, что программа не просто запоминает тэг на фотографии — она сопоставляет с ним не файл, а его содержание! Строго говоря, если вы закачаете семейные фотографии и проставите в тэгах имена своих родственников, то в дальнейшем Riya будет автоматически распознавать их и подписывать на фотографиях. Идея для сервиса удачная и очень интересная, но сам модуль распознавания изображений хорошо подойдет для поиска по медиафайлам. Пока такой поисковой системы нет, но в Ojos уже задумались над ее созданием.
Сегодня мы можем посмотреть на реализацию подобного проекта с говорящим названием Like.com. Он отвечает на вопрос из любимой комедии: «А нет ли такого же, но с перламутровыми пуговицами?» Система поиска по товарам дополнена модулем, который предлагает покупателям ознакомиться с товарами, похожими на те, что они выбрали. Это позволяет найти подобные вещи, не занимаясь тотальным просмотром всех фотографий в интернет-магазинах.
Музыкальный поиск тоже начинает работать по новой концепции. Недавно был запущен сервис Pandora, который чем-то напоминает популярнейший last.fm, — он отслеживает прослушиваемые композиции и предлагает плейлист с не известными пользователю, но похожими песнями. Отличие данного сервиса в том, что last.fm ориентируется на тэги, заданные пользователями, а Pandora анализирует звуковые файлы и сама расставляет метки. Разработчики сервиса называют себя «любящими музыку техническими специалистами», они начали работу над сервисом в 2000 году, и с тех пор в их базу попало более 10 тыс. треков, которые были обработаны и для каждого было построено дерево внутренней структуры.
Заглянем в будущее
На дворе 2007 год, и мы видим массу интересных сервисов, которые создают как молодые старт-апы, так и известные поисковые гиганты. И конечно, впечатляет количество миллионов долларов, вкладываемых в развитие новых поисковых систем. Успехи, которые уже делаются разработчиками, дают основания полагать, что мы движемся к новой эре, когда популярными станут поисковые системы, способные обеспечить максимальное удобство для пользователей.
Предсказания будущего очень противоречивы и далеко не всегда сбываются. Например, многие футурологи прошлого века верили, что в наши дни будет повсеместно развит космический туризм, но при этом никто не угадал глобального распространения персональных компьютеров. |
Сегодня сложно сказать, какая из перечисленных концепций получит наибольшее распространение. Наверное, никакая — ведь, как и в любой революционной идее, здесь главное начать двигаться в нужном направлении и вовремя объединить в своем продукте удачные решения всех участников прогресса.








