Аналитические службы Microsoft SQL Server 2005
Некоторые особенности практического применения
Проблемы построения таблиц фактов
Применение агрегированных значений
Коротко о возможностях языка MDX
В течение почти года мы публиковали цикл статей «Средства бизнес-анализа в SQL Server 2005», посвященный разнообразным возможностям аналитических служб, входящих в состав некоторых редакций последней версии корпоративной СУБД от Microsoft. По завершении этого цикла мы предлагаем вашему вниманию статью о практическом применении рассмотренных в нем технологий, написанную обладателем подобного опыта.
В настоящей публикации рассматриваются дополнительные возможности по аналитической обработке данных, предоставляемые службой Analysis Server, которая входит в состав Microsoft SQL Server 2005.
Проблемы построения таблиц фактов
Как известно читателям, OLAP-анализ базируется на построении аналитических кубов. Кратко напомним, в чем заключается основная идея. В оперативной (OLTP) базе данных выбирается либо специально создается таблица, которая хранит данные, подлежащие анализу, — таблица фактов. С ней связываются таблицы измерений, содержащие условия отбора — атрибуты измерений. После этого производится вычисление хранимых в кубе агрегатных данных («процессинг» куба) и размещение куба на OLAP-сервере.
При проектировании OLAP-кубов следует учитывать множество факторов, в том числе ограничивающих возможности работы. Рассмотрим один из них, вызывающий серьезные трудности в ходе эксплуатации.
Таблица фактов, как правило, составляется таким образом, чтобы она содержала сведения об одной категории субъектов предметной области. Сами субъекты при этом могут описываться целым набором различных характеристик — мер. Так, аналитический куб по сотрудникам торговой организации может содержать самые разнообразные сведения о специалистах: возраст, должность, оклад, объем полученных подотчетных средств и т.п. Допустим, нас интересует еще один показатель — величина продаж каждого менеджера. Понятно, что продажи относятся уже к другой части предметной области — к товарам. Как можно получить такую специфическую информацию о менеджерах?
Один из способов решения данной задачи заключается в присоединении к таблице фактов нового столбца — месячного объема продаж (суммы счетов, которые выставил клиентам каждый менеджер). Такое действие называется денормализацией таблиц. Реализация бизнес-логики за счет добавления к базовым данным избыточной информации — очень распространенная операция. Однако она решает проблему получения нужного показателя лишь частично. В процессе работы может потребоваться разделение продаж на группы товаров — тогда одного сводного показателя будет уже недостаточно.
Если продолжать двигаться в направлении увеличения избыточности, то итогом станет таблица фактов, в которой объединены данные двух таблиц: сведений о сотрудниках и сведений о продажах. Размер сводной таблицы при этом будет расти в геометрической прогрессии — ведь добавление каждого нового признака о втором субъекте будет кратно увеличивать число строк базовой таблицы. При небольшом количестве и малом размере исходных таблиц такое построение оправданно, но что делать, когда речь заходит о значительных объемах информации?
Применение агрегированных значений
Ответ на поставленный выше вопрос очевиден: нужно идти другим путем. Действительно, зачем объединять большие объемы «сырых» данных на уровне OLTP-систем, когда можно работать с их агрегированными значениями, содержащимися в OLAP-кубах?
Обратимся к теории. Одним из основных средств обработки информации в реляционных базах данных являются представления (Views). Они позволяют создавать различные наборы данных предметной области путем комбинирования исходных данных. При построении запросов, на основе которых создаются представления, обычно задаются связи (посредством оператора JOIN), однако иногда запросы могут объединять в себе и независимые таблицы. Типичный пример — классическая операция «перемножения» таблиц, при которой выбираются столбцы из двух таблиц без указания условий связанности.
В аналитических вычислениях тоже есть аналог запросов. В версии Analysis Server 2000 их роль выполняют так называемые виртуальные кубы (Virtual Cubes), позволяющие объединить в одну структуру несколько обычных кубов. Благодаря виртуальным кубам можно анализировать информацию, собранную из нескольких источников. В составе объединяемых кубов могут быть одинаковые измерения, точнее одно и то же измерение из множества Shared Dimensions. Оно выступает в качестве инструкции Where оператора Select и является единым фильтром для обоих наборов данных. Заметим, что такого измерения может и не быть — несколько кубов объединяются в один виртуальный, причем каждый со своим набором измерений.
Как уже отмечалось, по сути виртуальные кубы в Analysis Server 2000 играют роль запросов. В то же время они обладают врожденным недостатком — связи между источниками данных устанавливаются автоматически на этапе создания, после чего их нельзя редактировать и просматривать. Понятно, что такое положение дел в корне отличается от привычного для всех режима работы с запросами в реляционных СУБД, что очень неудобно в плане практического применения. Видимо, поэтому концепция виртуальных кубов в последней версии аналитического сервера получила свое логическое развитие.
В Microsoft Analysis Server 2005 появилась новая структура данных, которая называется Measure group. Она представляет собой таблицу фактов с набором связанных с ней измерений. Условно говоря, Measure group является обычным кубом, если говорить о нем в категориях Analysis Server 2000.
Новшество последней версии аналитических служб заключается в возможности добавления в один куб нескольких Measure group одновременно. Иными словами, любой куб может содержать больше одной таблицы фактов. По существу, это означает, что теперь функциональность виртуальных кубов поддерживается на уровне обычных.
При объединении нескольких аналитических кубов в рамках одного представления возникает проблема технического плана. Допустим, кубы содержат собственные системы измерений. Тогда в случае их объединения у кубов появятся внешние измерения — измерения других кубов. Какие же данные будут отображаться при выборе таких измерений? Если измерения относятся к другой таблице фактов, аналитический сервер показывает данные для атрибута All_Member. Это логично, однако совместный анализ данных становится невозможным. К счастью, ситуацию можно легко исправить — достаточно запрограммировать необходимые вычисления на языке MDX.
Коротко о возможностях языка MDX
Рассмотрим кратко возможности языка MDX. Отметим, что в области аналитической обработки данный язык выступает аналогом языка SQL в среде реляционных БД. Язык MDX можно использовать при решении следующих задач:
- навигации внутри куба;
- расчете вычисляемых членов (Calculated Members);
- собственно выполнении MDX-запросов.
Базовая функция языка MDX — это навигация внутри куба. Измерения куба (Dimensions) являются его внутренней системой координат, а набор MDX-функций предоставляет пользователю возможность по перемещению внутри нее. Смещаться можно как по уровням измерений (функции Level), так и между самими атрибутами (функции Members). Существует также вырожденный случай — переключение между иерархиями (например, между обычными и фискальными календарями).
В MDX поддерживается целый набор функций, отражающий различные степени родства между атрибутами измерений. Так, находясь в определенной точке куба (вычислив агрегатное значение), можно определить аналогичные значения для атрибута, расположенного на одном уровне с базовым (Sibling), а также более высокого уровня (Parent) либо имеющего общего предка (Cousin) и т.п. При необходимости запросы можно вызывать рекурсивно — например вычислять предка от предка выбранного атрибута. Такие вычисления удобные (запрос пишется в одну строку) и мощные одновременно. Выборка данных с подобными условиями посредством языка SQL является на порядок более сложной.
Отдельную группу образуют функции для работы с временными измерениями. Они имеют собственный синтаксис и учитывают, что для таких измерений уже задано отношение порядка (можно выделить больший и меньший элементы). В частности, функция OpeningPeriod ищет самого младшего члена среди потомков заданного уровня. Понятно, что в общем случае такая функция работать не будет, поскольку для обычных измерений младший (первый) атрибут определяется на этапе расчета структуры агрегаций, что никак не связано с семантикой данных.
Наиболее ценными функциями для размерностей типа «Дата» являются функции расчета накопительного итога — PeriodsToDate. Они считают количество элементов размерности (дней, месяцев, кварталов и т.п.), предшествующих выбранному атрибуту. Для стандартных временных интервалов (год, квартал, месяц, неделя) существует сокращенное написание PeriodsToDate: YTD(), QTD(), MTD(), WTD().
Главным достоинством функций навигации является возможность их использования при создании вычисляемых членов. На специальную ось Measures, где хранятся меры куба, можно добавить новый член — Calculated Member. Атрибуты, применяемые для его расчета, могут быть связаны с текущими элементами измерения (Current Member) отношениями, заданными при помощи функций MDX. Причем атрибуты можно выбирать из нескольких измерений (точнее, для нескольких измерений одновременно можно указывать значения, отличные от All Members). В частности, можно рассчитывать долю чего-либо в общей сумме, где общая сумма — значение элемента Parent от текущего значения (CurrentMember.Parent). В этом случае удельная доля будет вычисляться в зависимости от текущего значения атрибута. Например, если выбран месяц, то выводится доля месяца в году (квартале), а если выбрана его детализация — доля отдельного дня.
Необходимо сделать общее замечание, что такая функциональность не поддерживается обычными сводными таблицами. Как правило, в них реализована только возможность комбинирования различных членов оси Measures (вычисляемые поля) либо атрибутов, взятых из одного измерения (вычисляемые ячейки).
Практический пример
Постановка задачи
Приведем пример практического применения вышеизложенных идей. В произвольной СУБД создадим две не связанные между собой таблицы.
Первая — «Сотрудники» — содержит данные о работниках организации (табл. 1).
Таблица 1. Сотрудники
Код сотрудника |
Дирекция |
Сотрудник |
Должностной оклад, руб. |
1 |
Московская дирекция |
Изобенко Станислав |
10 000 |
2 |
Московская дирекция |
Фролова Ольга |
3000 |
3 |
Региональная дирекция |
Укродыженко Любовь |
3000 |
4 |
Региональная дирекция |
Богус Виталий |
10 000 |
5 |
Региональная дирекция |
Мешечкин Олег |
3000 |
Вторая — «План» — хранит информацию о плане продаж (табл. 2).
Таблица 2. План
Код товара |
Название товара |
План продаж, руб. |
1 |
Фитинги |
100 000 |
2 |
Трубы |
65 000 |
3 |
Котлы |
50 000 |
Наша задача будет состоять в распределении бюджета (Budget Allocation). Иными словами, общую сумму плана между сотрудниками необходимо разделить пропорционально окладу. В качестве дополнительного условия потребуем, чтобы план для каждого сотрудника формировался с детализацией по типам товаров.
Создание представлений источников данных
Решение начнем с создания новой аналитической базы данных в среде аналитических служб SQL Server 2005. В качестве источника данных выберем оперативную СУБД, в которой хранятся исходные данные. Создадим новое представление источников данных Data Source View и добавим в него таблицы. Названиям таблиц можно присвоить псевдонимы, под которыми они будут видны в кубах, — для этого достаточно заполнить свойство FriendlyName. Поэтому если таблицы данных имеют имена, отличные от «План» и «Сотрудники», то их следует снабдить соответствующими псевдонимами.
Создадим на базе таблицы «План» одноименное измерение. Для этого определим столбец «Код товара» как содержащий ключевые значения измерений, а «Название товара» — имена атрибутов.
Сформируем второе измерение — на этот раз на базе таблицы «Сотрудники». Сделаем его двухуровневым. Верхний уровень назовем «Отдел», основой для него выберем столбец «Дирекция». Ключевой нижний уровень — «Сотрудники» — построим на базе столбца «Код сотрудника», при этом имена атрибутов будем выбирать из столбца «Сотрудник». Уровни следует объединить в иерархию «Сотрудники», как показано на рис. 1.
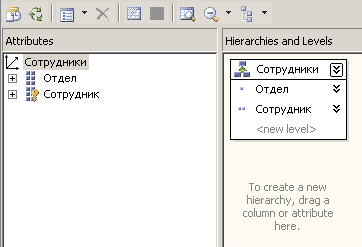
Рис. 1
Если все сделано правильно, измерение станет доступным для просмотра после выполнения процедуры расчета (рис. 2).

Рис. 2
Создание OLAP-куба
Создадим куб «Бюджет» и добавим в него таблицы «Сотрудники» и «План», причем каждую из них назначим одновременно таблицей фактов и измерений. В итоге в кубе будут сразу две группы мер. Формально каждая из них содержит как таблицу фактов, так и таблицу измерений, хотя физически все данные хранятся в одном месте.
Добавим в куб измерения, созданные на предыдущем этапе. Затем определим две новые меры: на столбце «Должностной оклад» таблицы «Сотрудники» — «Оклад», а на столбце «План продаж» таблицы «План» — «План».
Посмотрим на результат нашей работы на рис. 3.

Рис. 3
Данный рисунок иллюстрирует некоторые важные свойства сводной таблицы:
- она объединяет информацию из двух источников данных. Несмотря на то что измерения находятся в разных Measure group, в отчете можно выбрать обе координатные оси;
- получившееся распределение является результатом «перемножения» исходных таблиц. Если не считать строки с итоговыми значениями, общее количество строк отчета — 15 (5x3). Как мы помним, измерение «Сотрудники» содержит пять атрибутов, а измерение «План» — три;
- любая точка куба определяется теперь парой значений: [Имя сотрудника] и [Название товара]. В действительности внешние измерения при расчете мер не учитываются. Например, план для точки с координатами ([Изобенко Станислав], [Котлы]) составляет 50 000. Такой принцип расчета проще всего пояснить при помощи пространственной аналогии. С точки зрения геометрии куб является двумерным пространством — ведь значение меры определяется двумя координатами. Однако по умолчанию значения мер вычисляются для проекций пространства на ту координатную ось, которая ассоциирована с выбранной мерой.
Создание вычисляемых мер
Последнее замечание во многом обесценивает приложенные усилия по созданию общего источника данных. Да, мы создали куб, в котором доступна информация из обеих таблиц сразу, но сами данные так и остались не связанными друг с другом. Однако, как уже говорилось, ситуацию можно легко исправить при помощи вычисляемых мер.
Теперь перейдем в раздел Calculations куба и создадим в нем новый вычисляемый член (Calculated Member), который назовем «Доля_Оклада». Пользовательские вычисляемые элементы можно размещать на любых измерениях, а также на оси, где хранятся меры куба. Мы поместим ячейку именно на эту ось, чтобы в дальнейшем использовать ее при расчетах. Для этого просто выберем в списке Parent hierarchy значение Measures.
В окне Expressions напишем следующее MDX-выражение:
([Measures].[Оклад])/([Сотрудники]. [Структура].[All],[Measures].[Оклад])
Формула вычисляет долю оклада текущего элемента в общем фонде оплаты труда (знаменатель дроби — элемент All измерения «Сотрудники»).
Новый элемент можно оформить по собственному усмотрению, например задать формат отображения данных «Процентный» и изменить цвет фоновой заливки (рис. 4).

Рис. 4
Создадим еще один вычисляемый член — «Личный план» — с формулой расчета:
[Measures].[Доля_Оклада]*[Measures].[План].
Добавим обе ячейки в сводный отчет (рис. 5).

Рис. 5
Из рисунка видно, что значение ячейки «Личный план» в точке ([Изобенко Станислав], [Фитинги]) — 34 482, что составляет 34,48% от плана по данной категории товаров, равного 100 000 руб.
Уберем детализацию штатной структуры по сотрудникам. Получится новое распределение плана — на этот раз между дирекциями (рис. 6).

Рис. 6
Таким образом, мы убедились, что созданная нами мера корректно справляется с поставленной задачей. Причем для создания этого нетривиального распределения понадобилось написать всего два простых выражения на языке MDX.
***
В заключение хотелось бы еще раз отметить: аналитические кубы являются мощным средством для работы с данными. С помощью языка MDX обработку информации можно вывести на качественно новый уровень — нужно только научиться ориентироваться в многомерном пространстве.








