Переводчик с искусственным интеллектом
До наступления эры компьютеров слово «переводчик» однозначно ассоциировалось с человеком. Кто же еще может перевести текст с одного языка на другой, как не человек? Однако компьютеры изменили этот стереотип — теперь они с помощью программ-переводчиков тоже умеют переводить.
Перевод текста — задача интеллектуальная, поэтому скепсис в отношении возможности использования компьютера для перевода вполне закономерен. Однако разработчикам удалось, что называется, наделить разумом свои разработки, и сейчас машинный перевод относят к классу технологий искусственного интеллекта.
Сегодня в мире существует два подхода к построению технологии машинного перевода: традиционный, который предполагает построение системы перевода на основе лингвистических правил (rule-based machine translation), и статистический (statistical-based machine translation), полагающийся на математические модели при обработке текста. В данной статье мы обсудим возможности этих технологий и на конкретных примерах сравним качество перевода, которое выдают разные переводчики.
Математический подход
Ремесло переводчика всегда считалось гуманитарной областью, поскольку для выполнения профессионального перевода требуется не только знание иностранного языка, но и умение хорошо излагать мысли на родном языке. Однако рост мощности компьютеров позволил взглянуть на этот вопрос с другой точки зрения. Разработчики статистической модели перевода рискнули и разложили таинство перевода на сухие математические формулы. В результате при выполнении перевода компьютер не оперирует лингвистическими алгоритмами, а вычисляет вероятность применения того или иного слова или выражения. Слово или последовательность слов, имеющие оптимальную вероятность, считаются наиболее соответствующими переводу исходного текста и подставляются компьютером в получаемый в результате текст.
Безусловно, весь мощный математический аппарат бессилен без исходных данных — базы параллельных текстов. Анализируя параллельные тексты (в этих базах попарно хранятся фразы и выражения на исходном языке и их переводы) на основе определенных алгоритмов, компьютер вычисляет наиболее вероятные последовательности слов выходного языка.
В результате для работы статистической системы необходимо наличие больших и очень больших баз параллельных текстов, которые содержали бы фразы из различных областей человеческой деятельности. Причем эти параллельные тексты должны быть переведены в электронный вид и быть легкодоступны, что тоже немаловажно. Очевидно, что все эти требования выполняются в Интернете, где количество многоязычной информации возрастает с каждым днем. Ничего удивительного, что одной из наиболее известных систем статистического перевода располагает сегодня поисковая система Google.
Важным достоинством статистической технологии можно считать ее универсальность. Фактически для перевода с одного языка на другой используется единый математический аппарат, а направление перевода можно менять, подключая к системе базы параллельных текстов для различных языков.
С одной стороны, отсутствие привязки системы перевода к языку снижает стоимость ее разработки, но с другой — программа-переводчик всецело зависит от объема подключаемой базы параллельных текстов и качества содержащихся в ней переводов.
Также следует заметить, что игнорирование грамматических правил как входного, так и выходного языков разработчиками статистического перевода во многих случаях приводит к появлению на выходе программы абсолютно несогласованных предложений с разрушенной структурой.
Лингвистика прежде всего
В основе традиционной технологии машинного перевода также лежит применение алгоритмов, в которых запрограммированы лингвистические правила. Эта технология существует уже более полувека и поэтому имеет полное право называться традиционной. Здесь надо отметить, что на заре компьютерной эпохи просто физически отсутствовали базы параллельных текстов в электронном виде. Да и возможности первых компьютеров были не столь велики, чтобы оперативно анализировать большие массивы текстов.
Лингвистическая технология перевода используется в системах таких производителей, как Systran, PROMT, Linguatec и многих других разработчиков. Для тестирования нам нужна англо-русская система перевода, поэтому возьмем наиболее доступную из них — PROMT 8.0, разработанную российской компанией ПРОМТ.
Схематично принцип работы лингвистической технологии можно описать следующим образом. Сначала система анализирует исходный текст, то есть проводит морфологический анализ слов в предложении: для каждого слова определяется его род, число, лицо и другие морфологические характеристики. Затем выполняется синтаксический анализ: система определяет члены предложения (подлежащее, сказуемое, дополнение, обстоятельства). На заключительном этапе выполняется синтез предложений в переведенном тексте.
Очевидно, что при таком подходе для каждого языка необходимо разрабатывать отдельный набор алгоритмов, что требует немалых ресурсов компании-разработчика. Вместе с тем качество перевода не зависит от баз параллельных текстов, а кроме того, в системе имеется ряд возможностей для повышения качества перевода (например, подключение специализированных словарей).
Google и PROMT на тест-драйве
Для тестирования качества перевода PROMT и Google были использованы тексты по различным тематикам, полученные из Интернета. Процесс тестирования был разбит на три этапа: «первое знакомство» (табл. 1), «усложняем задачу» (табл. 2) и «проверяем мастерство» (табл. 3).
Первое знакомство
Для начала мы взяли два английских текста: первый — фрагмент из новости, посвященной судебному процессу, второй — отрывок из официального разъяснения о правилах получения кредита.
Результат работы PROMT можно оценить как весьма добротный машинный перевод: точно передан смысл исходного текста, все предложения имеют целостную структуру и легко читаются. Конечно, не обошлось без пары неудачных формулировок («за судебные издержки», «чтобы собраться на примечании»), но это не мешает легко воспринимать текст.
Перевод Google содержит довольно много языковых конструкций, смысл которых совершенно непонятен. Например, «Положение на адвоката гонорар», «суд даст стороной» и т.д. Таким образом, в некоторых предложениях смысл исходного текста можно лишь угадать, но и для этого потребуется несколько раз перечитать полученный перевод.
При переводе второго англоязычного текста (заявление на получение кредита) PROMT и Google достойно справились со своей задачей. Google даже отличился и перевел выражение “at no charge” стилистически более точно: «на безвозмездной основе».
Здесь также стоит отметить возможность интерактивного взаимодействия с разработчиками Google. В окне с переводом имеется ссылка «Предложить лучший вариант перевода», которая позволяет отослать разработчикам улучшенную версию перевода. Как показали наши наблюдения, Google периодически обновляет свою систему (возможно, благодаря обратной реакции пользователей). Так, в табл. 1 показаны два варианта перевода от Google, полученные в декабре 2007-го и в феврале 2008 года. Изменения налицо, хотя не всегда в лучшую сторону (это особенно заметно при переводе первого фрагмента). Однако сам факт постоянной работы над улучшением качества перевода можно только приветствовать.
Усложняем задачу
На втором этапе тестирования мы расширили количество тематик и протестировали переводчики на коротких текстах по различным тематикам (см. табл. 2): техника, финансы, юриспруденция.
Перевод, сделанный PROMT, нам понравился. Смысл во всех текстах передан правильно, предложения выходного текста имеют правильную структуру. В качестве недостатка можно отметить, что в некоторых случаях PROMT выбрал не совсем корректный перевод терминов (например, «the rate» переводится во втором отрывке именно как «курс», а «enclosure» правильнее переводить как «приложение»). К сожалению, одно слово из исходного текста — «dues» (в данном контексте переводится на русский язык как «сборы, пошлины») — PROMT вообще «забыл» перевести. Возможно, система не распознала, что это множественное число слова «due».
Однако такие огрехи не мешают быстро улавливать суть текста, а для качественного перевода тематических текстов разработчики рекомендуют подключать специализированные словари (в данном случае подошел бы словарь «Финансы»).
Перевод, полученный с помощью Google, производит двойственное впечатление. С одной стороны, при переводе технического текста система выдала бессвязный набор слов, который правильнее будет назвать подстрочником («В зонда также изучает ли фирма «незаконно отрезаны от конкурентов, каналов распределения»). С другой — при переводе текста по финансовой тематике и отрывка из текста контракта Google выдал практически идеальный машинный перевод («Стороны признают, что общие условия, Приложение № 2, являются неотъемлемой частью настоящего Договора».). Возможно, что такой результат объясняется слишком малым размером используемой Google базы текстов по технической тематике.
Момент истины
На финальном этапе тестирования мы усложнили задачу и отобрали для теста более сложные тексты (содержащие лексику из разных областей), а также увеличили их объем, чтобы случайные ошибки были менее заметны. Результаты представлены в табл. 3.
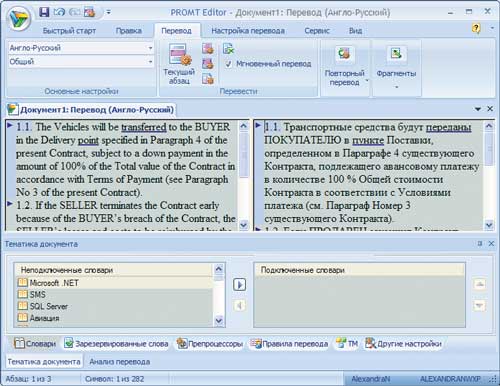
PROMT остался верен себе: на выходе система выдала хорошо читаемый перевод, который позволяет сразу же понять смысл исходного текста. Перевод, конечно, нуждается в стилистической правке (например, фразу «в количестве 100 % Общей стоимости Контракта» правильнее будет исправить на «в размере 100% от полной стоимости контракта»). Однако с таким текстом легко работать и незначительный объем правки позволит довести его до финального варианта.
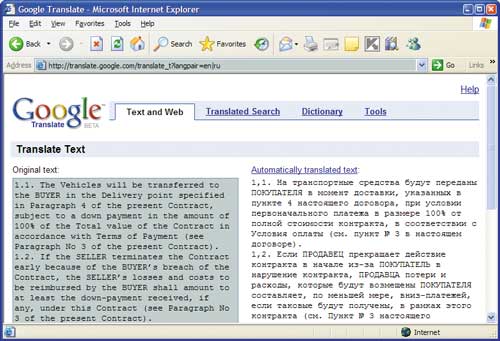
Момент истины наступил и для Google. Несмотря на весьма удачный перевод фраз из договора на втором этапе, контракт на поставку автомобилей оказался для Google более сложной задачей. В первой же фразе Google выдал откровенно искаженный перевод (фраза “The Vehicles will be transferred” однозначно переводится как «Транспортные средства будут переданы»). Затем во втором абзаце вместо связного перевода получилось мешанина из слов («Если ПРОДАВЕЦ прекращает действие контракта в начале из-за ПОКУПАТЕЛЬ в нарушение контракта, ПРОДАВЦА потери и расходы, которые будут возмещены ПОКУПАТЕЛЯ составляет по меньшей мере, вниз-платежей...»).
При этом надо отметить, что некоторые выражения в этом тексте (например, «если таковые будут получены, в рамках этого контракта») переведены абсолютно корректно и вообще не требуют никакой правки.
Причина такой нестабильности качества перевода Google, очевидно, кроется в особенностях статистического перевода. Идеально переведенные фразы и выражения — это готовые переводы, которые система просто подставила из базы. Судя по нашим результатам, наиболее полной у Google является база, содержащая параллельные тексты по финансовой и юридической тематикам (контракты, образцы заявлений и т.д.). Но даже малейшее отклонение исходного текста от фрагмента, находящегося в базе, приводит к тому, что Google начинает путаться и выдает подстрочник.
Напротив, качество перевода PROMT не зависит от тематики (мы специально не применяли никаких настроек для чистоты теста). Все переводы читаются хорошо, хотя подчас и требуют стилистической правки. Таким образом, PROMT можно уверенно использовать в качестве помощника, который позволяет быстро понять смысл любого текста. Хотя объем редакторской правки не столь велик, чтобы довести перевод до финального состояния.
Подведем итоги
В заключение нашего теста можно сделать главный вывод: машинный перевод действительно позволяет оперативно решить проблему языкового барьера. Мы тестировали системы перевода на разных текстах по различным тематикам и в большинстве случаев смысл исходного текста легко улавливался. На сложных текстах Google давал сбои и переходил на подстрочник. PROMT не всегда был точен в формулировках при переводе юридических и финансовых текстов.
Также надо отметить, что сервис Google предоставляется бесплатно, а за коробку PROMT 8.0 надо платить. Но если перевод PROMT вам понравился больше, можно пользоваться бесплатным сервисом на сайте Translate.ru, который компания-разработчик предоставляет для демонстрации.








