Компания NVIDIA представляет новые графические процессоры на архитектуре Fermi
Графический процессор на базе архитектуры Fermi
Слухи о новых графических процессорах NVIDIA на базе архитектуры Fermi уже давно ходят в Интернете. Видеокарты на процессорах Fermi действительно можно назвать долгожданными. И вот наконец свершилось. В ночь с 27 на 28 марта были официально объявлены новые графические процессоры NVIDIA GeForce GTX 480 и GTX 470 на базе архитектуры Fermi.
В течение последних нескольких лет компанию NVIDIA упорно обвиняли в том, что вместо разработки действительно новых процессоров она, мягко говоря, занимается перемаркировкой старых чипов. Конечно, в последнее время репутация компании была немного подмочена, тем более что на фоне предпринимаемых ею попыток выжать из старой архитектуры графических процессоров всё до последний капли конкурент NVIDIA — компания AMD создавала по-настоящему инновационные продукты, постепенно увеличивая свою долю рынка. А потому новая архитектура графических процессоров, известная под кодовым названием Fermi (так же называются и сами графические процессоры), действительно была долгожданной. Фанаты NVIDIA возлагали на нее большие надежды, полагая, что видеокарты на базе новых процессоров Fermi наконецто станут лидерами по производительности, оставив далеко позади своих конкурентов.
Итак, давайте поближе познакомимся с особенностями новой архитектуры графических процессоров Fermi.
На базе архитектуры Fermi будут выпускаться как графические процессоры серии GeForce для игровых видеокарт, так и графические процессоры для профессиональных видеокарт серии Quadro, а также процессоры серии Tesla для карт, используемых в суперкомпьютерах. Естественно, что нас в первую очередь интересуют графические процессоры серии GeForce, однако поскольку основу этих процессоров составляет та же архитектура Fermi, логично вначале рассмотреть особенности самой архитектуры.
Особенности архитектуры Fermi
Описание новых графических процессоров на базе архитектуры Fermi можно было бы начать с перечисления их технических характеристик (количество потоковых (шейдерных) процессоров, размер кэша и т.д. и т.п.). Цифры выглядят действительно впечатляюще, однако, на наш взгляд, выдающиеся технические характеристики графического процессора Fermi — это не самое главное.
Ключевая особенность Fermi заключается в том, что существенной переработке подверглась сама архитектура графического процессора, которая ориентирована на повышение эффективности параллельных вычислений и подразумевает концептуально новый подход к созданию графических процессоров. Собственно, архитектура Fermi во многом напоминает архитектуру процессора общего назначения, и можно даже сказать, что Fermi разрабатывалась именно как архитектура процессора общего назначения с возможностью ее использования для создания игровых графических процессоров. Фактически Fermi воплощает в себе очередную попытку компании NVIDIA поменять акценты между графическим и центральным процессором. То есть сегодня графический процессор во многих приложениях можно рассматривать как сопроцессор для центрального процессора, однако компания NVIDIA пытается сделать так, чтобы главенствующая роль отводилась графическому процессору, а центральный процессор выполнял функцию сопроцессора для графического процессора. Конечно, до воплощения в жизнь этих амбициозных планов NVIDIA еще далеко, да и не факт, что им вообще суждено сбыться, однако попытки наделить графический процессор функциональностью процессора общего назначения компанией NVIDIA предпринимаются, и архитектура Fermi — тому пример. Создание специализированных суперкомпьютеров на базе процессоров Tesla демонстрирует тот факт, что для специализированных приложений применение вычислительной мощности графического процессора в ряде случаев оказывается более эффективным.
По всей видимости, архитектура Fermi изначально разрабатывалась для процессоров Tesla, а возможность ее использования для создания игровых (серии GeForce) и профессиональных (серии Quadro) графических процессоров — это своего рода дополнительная возможность. Впрочем, это вовсе не означает, что процессоры серии GeForce не смогут успешно конкурировать с решениями ATI.
Увы, из-за особенностей таможни тестирование видеокарт на базе новых графических процессоров GeForce откладывается (этих карт на момент написания статьи просто не было у нас в стране), однако, по некоторым данным, эти видеокарты опережают по производительности в играх видеокарту AMD Radeon HD 5870, но несколько уступают двухпроцессорной видеокарте AMD Radeon HD 5950. Справедливости ради отметим, что видеокарты AMD Radeon HD 5950 в России также нет.
Итак, после того как акценты расставлены, перейдем к более подробному рассмотрению архитектуры Fermi.
Графический процессор на базе архитектуры Fermi
Графический процессор на основе архитектуры Fermi имеет кодовое название GF100. Отметим, что ранее он назывался GT300 (как продолжение предыдущего чипа GT200), однако существенные изменения в архитектуре процессора, видимо, побудили разработчиков изменить кодовое наименование, дабы не было ассоциации с чипом GT200.
Отметим, что чип GF100 — это первый графический процессор NVIDIA, который изготавливается по 40-нм техпроцессу. Напомним, что компания AMD уже давно перешла на этот техпроцесс. Кстати, все графические процессоры NVIDIA и AMD изготавливаются компанией TSMC.
Итак, если говорить языком цифр, то GF100 — это:
- 3 млрд транзисторов;
- 512 ядер CUDA;
- 16 геометрических блоков;
- четыре блока растеризации;
- 64 текстурных блока;
- шесть блоков ROP (по восемь модулей ROP в каждом блоке);
- шесть 64-битных контроллеров памяти GDDR5 (384-битный интерфейс памяти);
- кэш L1 размером 16 или 48 Кбайт;
- унифицированный кэш L2 размером 768 Кбайт;
- поддержка DirectX 11;
- поддержка кода C++;
- поддержка памяти ECC.
Графический кластер GPC
В основе Fermi лежит масштабируемая архитектура на основе графических кластеров GPC (Graphic Processing Cluster). Каждый GPC-кластер наделен собственным движком растеризации и фактически представляет собой отдельный графический процессор, за тем лишь исключением, что не имеет выделенного доступа к памяти и выделенных блоков ROP. В чипе GF100 насчитывается четыре отдельных кластера GPC (рис. 1). Все они совместно используют шесть контроллеров памяти, шесть модулей ROP (по восемь ROP-блоков в каждом модуле) и унифицированный L2-кэш размером 768 Кбайт, который обслуживает все запросы по загрузке и сохранению данных, а также текстурные выборки. Унифицированный кэш L2 в GF100 заменяет собой текстурный кэш, кэш ROP, а также различные буферы. Кэш L2 GF100 используется как для записи, так и для чтения данных.
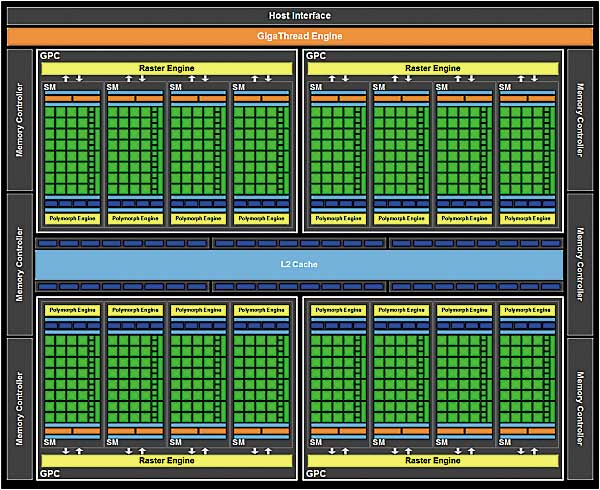
Рис. 1. Кластерная структура архитектуры Fermi
Планировщик GigaThread Engine
Для того чтобы загрузить все GPC-кластеры инструкциями, применяется планировщик GigaThread Engine. Забегая вперед, скажем, что каждый отдельный GPC-кластер состоит из четырех потоковых мультипроцессоров SM, то есть всего в чипе GF100 насчитывается 16 SM-процессоров. Так вот, планировщик GigaThread Engine как раз и отвечает за загрузку всех SM-процессоров.
Планировщик GigaThread запрашивает нужные данные из системной памяти и копирует их в локальную память, а кроме того, он создает группы из 32 потоков, которые получили название варпы (warps), и распределяет варпы по разным SM-процессорам.
Важно отметить, что планировщик GigaThread Engine способен организовывать варпы параллельно, что позволяет максимально загрузить все исполнительные блоки графического процессора.
Потоковый мультипроцессор SM
Каждый отдельный кластер GPC представляет собой совокупность четырех потоковых мультипроцессоров (Streaming Multiprocessor, SM) вместе со всеми блоками текстурирования и геометрической обработки данных (рис. 2). Отдельный потоковый мультипроцессор SM включает двойной планировщик варпов, 32 процессорных ядра CUDA, которые совместно используют память и кэш L1, четыре текстурных модуля и блок PolyMorph Engine (рис. 3). Впрочем, о различных модулях мы еще подробно расскажем, а пока обратим внимание на тот факт, что почти такая же структура была и в графическом процессоре предыдущего поколения — чипе GT200. Напомним, что понятие потокового мультипроцессора SM использовалось еще и в чипе GT200. Правда, в GT200 один потоковый мультипроцессор объединял в себе восемь потоковых процессоров (Streaming Processor, SP). В чипе GF100 в один потоковый мультипроцессор объединяются уже 32 потоковых процессора, и называется он потоковым мультипроцессором третьего поколения. Теперь унифицированные потоковые процессоры получили название процессорных ядер CUDA, но сути это не меняет.
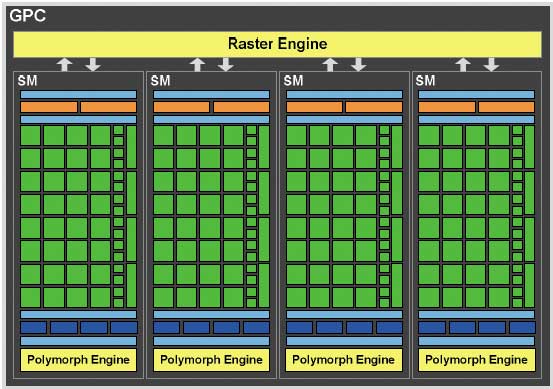
Рис. 2. Структура графического кластера GPC
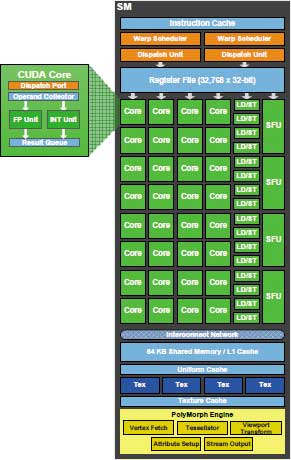
Рис. 3. Структурная схема
потокового мультипроцессора
Если учесть, что в одном кластере насчитывается четыре потоковых мультипроцессора, а всего в чипе GF100 имеется четыре кластера, то получим 512 процессорных ядер CUDA в чипе GF100.
Кроме процессорных ядер CUDA в состав каждого SM входят 16 блоков загрузки и временного хранения данных (Load/Store Unit, LSU), которые могут определить адреса данных в кэше или памяти для 16 потоков за каждый такт.
Каждый потоковый мультипроцессор SM также включает четыре специальных блока SFU (Special Function Unit), которые используются для математических расчетов. Эти блоки способны выполнять такие математические операции, как синус, косинус, квадратный корень и т.п. Каждый SFU-блок способен выполнять одну математическую операцию на поток за такт.
Теперь рассмотрим отдельные модули потокового мультипроцессора более детально.
Планировщик варпов
Как уже отмечалось, глобальный планировщик GigaThread Engine создает варпы из 32 потоков и распределяет их по разным SM-процессорам. В каждом SM-мультипроцессоре имеются два планировщика варпов (Warp Scheduler) и два диспетчера инструкций (Instruction Dispatch Unit).
Два планировщика работают параллельно, что позволяет выбирать одновременно два варпа для выполнения на SM-мультипроцессоре.
Планировщики передают по одной инструкции от каждого варпа группе из 16 ядер CUDA, 16 блоков LSU или четырех SFU.
Процессорное ядро CUDA
Процессорное ядро CUDA, или, если угодно, унифицированный потоковый процессор, представляет собой скалярный процессор общего назначения для обработки целочисленных данных и данных с плавающей запятой. Этот процессор включает блок для работы с целочисленными операндами (INT Unit) и блок для работы с операндами с плавающей запятой (FP Unit). Важно отметить, что CUDA-процессоры работают на удвоенной частоте графического процессора. Поэтому, говоря о современных графических процессорах, различают частоту ядра и частоту шейдерного домена, что равносильно частоте CUDA-процессоров.
Напомним, что унифицированные потоковые или шейдерные процессоры используются в архитектуре графических процессоров уже не первый год. Унифицированным такой процессор является в том смысле, что он способен выполнять как вершинные, так и пиксельные шейдеры, а также геометрические и физические расчеты.
Традиционно в процессорах существует два типа математики: векторная и скалярная. В случае векторной математики данные (операнды) представляются в виде n-мерных векторов, при этом над большим массивом данных проводится всего одна операция. Самый простой пример — задание цвета пиксела в виде четырехмерного вектора с координатами R, G, B, A, где первые три координаты (R, G, B) задают цвет пиксела, а последняя — его прозрачность. В качестве простого примера векторной операции можно рассмотреть сложение цвета двух пикселов. При этом одна операция осуществляется одновременно над восемью операндами (двумя четырехмерными векторами). В скалярной математике операции осуществляются над парой чисел. Понятно, что векторная обработка увеличивает скорость и эффективность обработки за счет того, что обработка целого набора (вектора) данных выполняется одной командой.
В то же время традиционная векторная архитектура менее эффективно использует вычислительные ресурсы, нежели скалярный дизайн процессорных модулей, особенно в случае обработки сложных смешанных шейдеров, сочетающих векторные и скалярные инструкции. Кроме того, довольно сложно добиться эффективной обработки скалярных вычислений с помощью векторных исполнительных модулей. Именно поэтому в унифицированных процессорах используются скалярные исполнительные блоки.
Текстурные блоки TMU
В состав каждого SM-мультипроцессора входят четыре текстурных TMU-блока и текстурный кэш. Каждый текстурный блок выбирает до четырех текстурных семплов за такт, а результат может быть выдан как в неотфильтрованном виде, так и с билинейной, трилинейной и анизотропной фильтрацией.
Конфигурируемая память
Каждый SM-мультипроцессор имеет доступ к 64 Кбайт памяти, которая может быть разделена на кэшпамять первого уровня (L1) и разделяемую общую память, причем разделена она может быть двумя способами: 48 и 16 Кбайт, либо наоборот — 16 и 48 Кбайт.
Для игровых приложений реализуется вариант с кэшпамятью L1 16 Кбайт и общей памятью 48 Кбайт. В этом случае кэшпамять работает как регистровый буфер.
В вычислительных приложениях реализуется второй вариант, то есть размер кэшпамяти составляет 48 Кбайт, а размер общей памяти — 16 Кбайт.
Блок PolyMorph Engine
Как уже отмечалось, в состав SM-процессора входит специальный блок PolyMorph Engine. Это новый в архитектуре графических процессоров NVIDIA блок, отвечающий за аппаратную реализацию тесселяции.
Отметим, что Fermi — это первый графический процессор NVIDIA, поддерживающий тесселяцию (равно как и DirectX 11).
Напомним, что технология тесселяции позволяет выбирать оптимальный уровень детализации объектов в зависимости от их удаленности в сцене. Традиционно в играх для удаленных в сцене объектов и объектов, расположенных на переднем крае сцены, применяются различные трехмерные модели (с разным уровнем детализации). Понятно, что чем дальше расположен объект от точки обзора, тем он может быть менее детализирован, поскольку его сложно рассмотреть, но по мере его приближения число полигонов в трехмерной модели этого объекта должно увеличиваться с тем, чтобы он выглядел более реалистично.
Учитывая, что каждый объект в сцене передается в графический процессор заново для каждого кадра, требуются достаточно сложные алгоритмы для использования модели с оптимальным в данный момент уровнем детализации. Причем существенное ограничение налагает не только предельная производительность графического процессора при обработке геометрической информации, но и пропускная способность шины PCI Express.
Идея тесселяции заключается в том, что в зависимости от удаленности объекта в сцене изменяется и количество полигонов в его трехмерной модели. То есть первоначально создается простая модель, а затем, в зависимости от расположения объекта, автоматически увеличивается количество полигонов в трехмерной модели с применением кривых Безье. При этом каждый полигон модели разбивается на заданное число связанных полигонов, которые выстраиваются в соответствии с общим направлением поверхности модели.
Технология тесселяции основана на картах смещения, которые представляют собой монохромные текстуры, используемые для задания геометрических свойств объекта. Яркость каждой точки на этой текстуре определяет высоту (смещение) этой точки над исходной поверхностью.
Преимущество карт смещения заключается в том, что они позволяют создать универсальную модель, уровень детализации которой определяется лишь применяемой картой смещения.
В графическом процессоре GF100 технология тесселяции реализована следующим образом. Первоначально вершина выбирается из глобального буфера, после чего она направляется в SM-процессор (в блок PolyMorph Engine), где ее координаты преобразуются в координаты сцены и определяется уровень тесселяции (рис. 4). Затем вершина передается на аппаратный тесселятор, который разбивает полигон на несколько более мелких, а по карте смещения определяются их координаты. Полученные новые вершины вновь обрабатываются в SM-процессоре.

Рис. 4. Структурная схема блока PolyMorph Engine
Блок Raster Engine
Raster Engine, которым наделен каждый GPC-кластер, — это блок растеризации. В этом блоке отфильтровываются невидимые поверхности, а геометрические данные преобразуются в экранные точки, которые также фильтруются по глубине (Z-координата), то есть происходит отсечение невидимых точек.
Когда рассчитывается новый пиксел, его глубина сравнивается со значениями глубин уже рассчитанных пикселов с теми же координатами Х и Y. Если новый пиксел имеет значение глубины больше какого-либо значения в Z-буфере, то новый пиксел не записывается в буфер для отображения (если меньше — то записывается).
Каждый GPC-кластер оснащен одним блоком растеризации, обрабатывающим до восьми точек за такт, то есть суммарная производительность растеризатора GF100 составляет 32 точки за такт.
Блоки ROP
Если блоком Raster Engine наделен каждый GPC-кластер, то блоки ROP (Raster Operation), то есть блоки растровых операций, используются совместно всеми GPS-кластерами. Несмотря на схожесть названия, блоки Raster Engine и ROP выполняют различные функции. Блок ROP выполняет операции блендинга, то есть задает прозрачность объектов, а также реализует операции сглаживания.
В процессоре GF100 имеется 48 блоков ROP, объединенных в четыре модуля по шесть блоков в каждом. Каждый модуль ROP связан с отдельным 64-битным контроллером памяти (напомним, что всего в GF100 имеется шесть контроллеров памяти). Ну и, кроме того, каждый ROP-модуль связан с L2-кэшем графического процессора.
Каждый блок ROP может за такт обрабатывать один пиксел с целочисленным 32-битным значением, либо один пиксел FP16 за два такта, либо один пиксел FP32 за четыре такта. Таким образом, максимальная производительность ROP составляет 48 целочисленных 32-битных пикселов, либо 24 FP16-пикселов, либо 12 FP32-пикселов.
Согласно данным компании NVIDIA, благодаря увеличенному количеству блоков ROP и улучшенным алгоритмам сжатия, возрастает и скорость сглаживания 4x и 8x MSAA. В сравнении с GT200 скорость выполнения сглаживания 4x и 8x MSAA выше в 1,6 и 2,3 раза соответственно.
Кроме того, в графическом процессоре GF100 реализован новый тип сглаживания 32x CSAA (Coverage Sample Antialiasing)
Заключение
В заключение нашего обзора архитектуры Fermi графического процессора GF100 отметим те особенности архитектуры, которые до сих пор оставались за кадром.
Как уже отмечалось, архитектура Fermi поддерживает унифицированную 64-битную адресацию памяти. Это позволяет не только адресовать большие объемы памяти (до 1 Тбайт), но и реализовать поддержку языка С++. Кроме того, важно подчеркнуть, что архитектура Fermi поддерживает память с коррекцией ошибок ECC. Конечно, для игровых видеокарт это абсолютно неважно (важнее, что поддерживается память GDDR5), а вот для процессоров Tesla последнее обстоятельство играет весьма значимую роль.
Нужно отметить, что спектр задач, которые позволяет решить GF100, гораздо шире, чем у традиционного графического процессора, однако в настоящее время разработчики игр еще не готовы использовать весь арсенал этого процессора. С использованием процессора на базе архитектуры Fermi можно эффективно реализовать различные физические эффекты PhysX, рендеринг методом трассировки лучей и, возможно, даже искусственный интеллект в играх, который сегодня обеспечивается средствами центрального процессора.
Сегодня компания NVIDIA анонсировала две референсные видеокарты на базе графических процессоров GF100: GeForce GTX 480 и GTX 470 (см. таблицу). Напомним, что GF100 — это кодовое наименование процессора, ну а его официальное название — графический процессор серии GeForce GTX 400.

Референсная видеокарта GeForce GTX 480 в исполнении ZOTAC

Референсная видеокарта GeForce GTX 470 в исполнении ZOTAC
Важно отметить, что характеристики процессоров GeForce GTX 480 и GTX 470 несколько отличаются от характеристик, заявленных для архитектуры Fermi.
Вообще, традиционно вначале анонсируется топовый графический процессор, а уж потом на его основе создаются урезанные варианты. Однако c чипом GF100 всё несколько иначе. Сначала были анонсированы урезанные варианты графического процессора, а когда будет анонсирован флагман — пока не ясно. Тот факт, что сейчас анонсированы лишь урезанные версии чипа GF100, по всей видимости, свидетельствует о том, что с полностью годными чипами GF100 пока еще не всё в порядке. Не стоит забывать, что GF100 выпускается по новому техпроцессу 40-нм, а сам чип содержит 3 млрд транзисторов, что является своего рода рекордом. А потому приходится урезать и количество CUDA-процессоров, и количество текстурных блоков, и даже количество SM-мультипроцессоров. К примеру, графический процессор GeForce GTX 480 имеет всего 480 (вместо 512) CUDA-процессоров, то есть на 32 процессора меньше, чем предусмотрено в GF100. Кром того, в этом процессоре только 60 (вместо 64 текстурных блоков), а вот количество ROP-блоков максимально, то есть 48.
Учитывая, что в GeForce GTX 480 недостает четырех текстурных блоков и 32 CUDA-процессоров (ровно столько текстурных блоков и CUDA-процессоров приходится на один SM-мультипроцессор), можно предположить, что в GeForce GTX 480 вообще отключен один из SM-мультипроцессоров в какомто из GPC-кластеров.
В процессоре GeForce GTX 470 имеется всего 448 CUDA-процессоров, 56 текстурных блоков и 40 блоков ROP. То есть в этом процессоре недостает 64 CUDA-процессоров, восьми текстурных модулей и восьми блоков ROP. Таким образом, можно предположить, что в GeForce GTX 470 отключены два SM-мультипроцессора и один модуль ROP (каждый модуль ROP включает восемь ROP-блоков). Кроме того, в GeForce GTX 470 используется 320-битная, а не 384-битная шина памяти, то есть отключен один из шести 64-битных контроллеров памяти. Остальные различия между референсными графическими картами GeForce GTX 480 и GeForce GTX 470 заключаются в тактовых частотах ядра, CUDA-процессоров и памяти, а также в объеме графической памяти и энергопотреблении.








