Блеск и нищета сводных таблиц
Часть 13
Срезы данных и сводные таблицы
Первый материал из настоящего цикла статей был опубликован еще в начале 2011 года, когда самой распространенной версией офисного пакета был Microsoft Office 2007, а Microsoft Office 2010 только начинал свое победное шествие по планете. Сегодня новейшая версия Microsoft Office занимает существенный сегмент рынка офисных приложений, и обсуждение ее возможностей может быть полезно для широкого круга читателей. С позиций прикладного бизнес-анализа последний офисный пакет от компании Microsoft интересен в первую очередь расширением спектра доступных методов работы с OLAP-источниками, часть из которых имеет непосредственное отношение к семейству функций КУБ(). В настоящей статье мы начнем рассматривать новведения, касающиеся построения и обработки аналитических отчетов.
Срезы данных и сводные таблицы
Значимым компонентом сводной таблицы является раздел фильтров отчета. Как известно, фильтры позволяют выбрать нужные пользователю значения элементов из измерений, которые не показываются на осях отчета. На листе электронной таблицы фильтр графически представляется одной ячейкой. Он может явным образом отобразить установленное пользователем условие фильтрации в единственном случае — когда выбирается один элемент измерения. На практике больше распространена обратная ситуация, при которой требуется одновременно выбрать несколько элементов из одного измерения. Такая операция называется множественным выбором (MultiSelect). Следует отметить, что OLAP-клиент, встроенный в Microsoft Excel, ее поддерживает. Для перехода в режим MultiSelect в окне фильтра следует включить опцию Выделить несколько элементов. Но при использовании в работе множественного выбора неизбежно возникают проблемы с наглядностью отображения набора, по которому осуществляется фильтрация данных в отчете. Поскольку в одной ячейке невозможно одновременно показать сразу несколько значений, вместо них выводится сообщение«заглушка»: Несколько элементов (рис. 1).
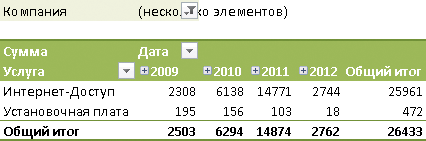
Рис. 1. Множественный выбор в фильтре
сводной таблицы
Такое сообщение сложно назвать информативным, ведь открытым остается важный вопрос: какие именно элементы были отобраны? Для получения подробных сведений приходится каждый раз обращаться к раскрывающемуся списку в отдельном модальном окне. Работа со списком элементов в случае больших измерений сопряжена с рядом неудобств. Часто набор, используемый в фильтре, представляет собой «разреженную» выборку элементов, для перехода между которыми приходится использовать прокрутку списка на экране. Кроме того, в текущем ракурсе куба значительное количество элементов может иметь нулевые значения. В принципе, их можно вообще не показывать в списке, сделав его таким образом более компактным. Ведь добавление или удаление нулевого элемента не изменит итоговых значений в сводном отчете.
Для устранения перечисленных недостатков в Microsoft Excel были добавлены новые функциональные компоненты, получившие название срезов данных. Их основное назначение — облегчить работу с фильтрами в отчетах сводных таблиц. Фактически срез данных — это измерение куба, показанное в отдельном окне. Причем, в зависимости от потребностей пользователя, отобразить его можно различными способами.
На основе имеющейся сводной таблицы новый срез данных добавляется при помощи команды Вставить срез, размещенной в группе Сортировка и фильтр вкладки Параметры. В открывшемся диалоговом окне Вставка срезов следует установить флажок напротив требуемого измерения.
После выполнения указанных операций новый срез будет добавлен на лист Microsoft Excel 2010 (рис. 2).
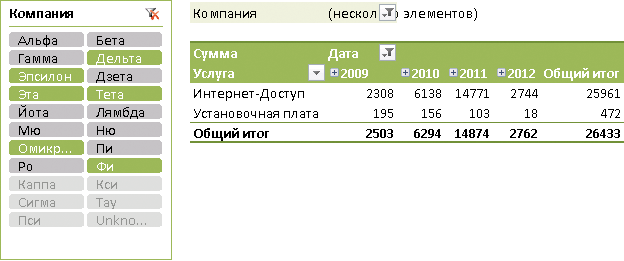
Рис. 2. Фильтр в виде среза данных
На рис. 2 представлен срез, созданный на базе измерения «Компания». Окно формы среза показывает все элементы этого измерения. Как видно из рисунка, в зависимости от своего текущего статуса они имеют различное цветовое оформление. Те из них, которые добавлены в фильтр отчета, выделены зеленым цветом. Когда срез данных связан с определенной сводной таблицы, он синхронно отображает все происходящие с ней изменения. В частности, если изменить условия фильтрации (добавить/исключить элементы), то соответствующие элементы в окне среза поменяют свое форматирование. Таким образом, срез позволяет значительно повысить наглядность и упростить понимание данных аналитического отчета. Реальную ценность имеет обратная операция — выделение тех или иных элементов в окне среза автоматически меняет состав фильтрующего набора в сводной таблице.
Работать со срезами данных, по сравнению с обычными фильтрами, удобнее сразу по ряду причин. Окно среза размещается прямо на листе Microsoft Excel, что позволяет получить непосредственный доступ к элементам измерения. В тех же ситуациях, когда приходится иметь дело с измерениями, содержащими большое количество элементов, линейные размеры окна можно увеличить. Здесь функциональность формы срезов аналогична по своим возможностям модальному окну настройки фильтров. Однако, кроме изменения геометрических размеров окна, срезы данных позволяют увеличить количество видимых пользователю элементов измерения и другими способами, которых нет в «классических» сводных таблицах. Такие настройки выполняются на специальной вкладке Параметры, которая активируется при выборе конкретного среза данных. В группе Кнопки можно указать желаемые линейные размеры кнопок, представляющих отдельные элементы измерения, а также количество столбцов в окне среза. Например, срез данных по измерению «Компания», показанный на рис. 2, состоит из двух столбцов.
При внимательном рассмотрении невыделенных ячеек в срезе на рис. 2 видно, что они несколько отличаются по тональности серого цвета. Ячейки, размещенные в конце списка, имеют более светлый оттенок. Подобным образом в срезе данных выделяются «пустые» элементы. Пустым считается всякий элемент, для которого все ассоциированные с ним ячейки не имеют значений в текущей проекции куба. Поэтому состав и взаимное расположение полей в форме среза может динамически меняться при совершении какихлибо операций с другими измерениями куба. В англоязычной литературе такое свойство обычно обозначают термином Cross-Filtering.
В рассматриваемом примере компания «Альфа» имела доход только в 2011 и 2012 годах. Она не добавлена в фильтр отчета, но в то же время сам элемент непустой. Поэтому кнопка, соответствующая данной компании, расположена в самом начале списка как первый элемент измерения «Компания» и имеет насыщенный серый цвет. Теперь изменим макет отчета. Оставим на оси Дата единственный период — 2009 год. Во вновь определенном ракурсе многомерного пространства с компанией «Альфа» уже не связано никаких доходов. Это означает, что добавление данной компании в фильтрующий набор не повлияет на итоговые значения сводного отчета. Иными словами, компанию «Альфа» можно не показывать пользователю. В данной ситуации Microsoft Excel считает элемент пустым, перемещает его в конец списка и перекрашивает в более светлый серый цвет (рис. 3).
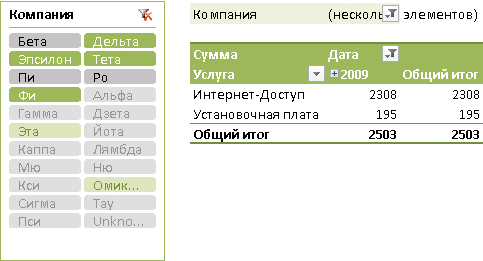
Рис. 3. Связь среза с другими измерениями — Cross-Filtering
Подобный режим работы удобен на практике, так как обеспечивает приоритетное размещение и соответственно более высокую доступность тем элементам, которые могут понадобиться пользователю в текущем контексте. Опции цветового выделения и ранжирования включаются в диалоговом окне Настройка среза путем выставления флагов Выделять пустые элементы и Отображать пустые элементы последними (рис. 4).
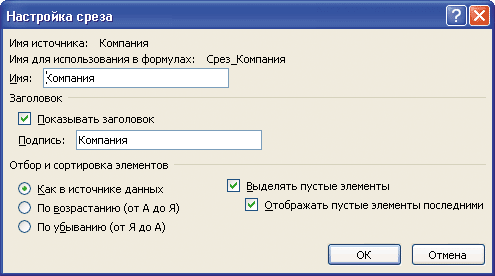
Рис. 4. Настройка среза
Для срезов данных предусмотрено два основных режима использования: автономный и подключение к существующей сводной таблице. Автономный режим мы обсудим несколько позже, а сейчас скажем несколько слов о способах подключения срезов к обычным сводным таблицам. Объединение среза со сводной таблицей производится путем нажатия кнопки Подключения к сводной таблице, размещенной на вкладке Параметры в группе Срез. В открывающемся диалоговом окне следует выбрать из списка те таблицы, к которым должно быть организовано соединение. Допускается выбор как одной, так и многих таблиц одновременно. Последний вариант позволяет, наконец, выполнить операцию, которой так не хватало в предыдущих версиях Microsoft Excel, — синхронизировать работу двух и более многомерных отчетов. Если один срез связан с несколькими сводными отчетами, он выступает для них в роли общего фильтра. В свою очередь, все сводные таблицы совместно определяют его структуру. В частности, множество пустых элементов среза рассчитывается как пересечение пустых множеств из всех связанных с ним таблиц. Кроме того, следует учитывать, что связывание сразу нескольких сводных таблиц и срезов между собой приводит к установлению транзитивных зависимостей между объектами со всеми вытекающими отсюда последствиями. На рис. 5 показана одна из таких возможных ситуаций. Выставление определенного фильтра в срезе 1 приводит к изменению состава элементов в сводной таблице 1, которая ассоциирована со срезом 2. Данный срез, кроме сводной таблицы 1, подключен к сводной таблице 2, на которую настроен и срез 3. В итоге модификация среза 1 влечет за собой каскадное изменение целого ряда объектов, включая срез 3, с которым у исходного объекта нет никаких прямых связей.
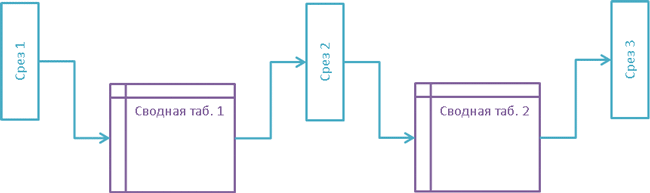
Рис. 5. Транзитивные зависимости между срезами
Срезы данных и функции КУБ()
Альтернативной формой функционирования среза является так называемый автономный режим, при котором он выполняет единственную операцию — формирует фильтрующий набор. При работе со сводными таблицами такая опция представляется избыточной. Однако любой фильтр, созданный посредством среза данных, всегда определяет некоторый набор элементов одного из измерений куба. Такие наборы, как мы помним, выступают в роли тех «строительных кирпичиков», из которых составляются многомерные отчеты, в том числе с помощью семейства функций КУБ(). Оказывается, в функциях КУБ() срезы данных выступают полным аналогом оператора КУБМНОЖ().
В книгу Microsoft Excel автономные срезы добавляются командой Срез, расположенной на вкладке Вставка в группе Фильтр. Каждому добавленному в книгу срезу соответствует именованный диапазон Срез_ХХХ, где ХХХ — название самого среза данных (в англоязычной версии Microsoft Office имя диапазона начинается с префикса Slice_). Посмотреть на название диапазона можно в Диспетчере имен, находящемся на вкладке Формулы в группе Определенные имена (рис. 6), либо в окне настройки свойств среза, в разделе Имя для использования в формулах (см. рис. 4).
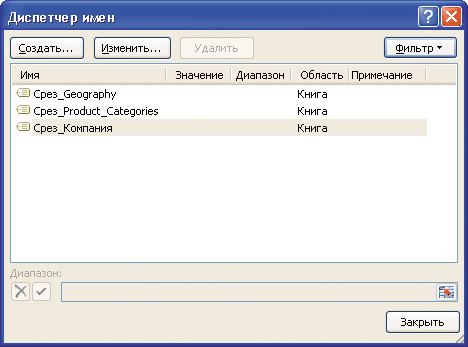
Рис. 6. Срезы данных в Диспетчере имен
Из рис. 4 видно, что, в отличие от других параметров, пользователь не имеет возможности изменить свойство объекта Имя для использования в формулах. Несмотря на то что срез данных явно присутствует в Диспетчере имен, соответствующего ему диапазона ячеек в книге Microsoft Excel нет. Фактически к срезу можно обратиться по имени только внутри функций КУБ(), используя его вместо вызова оператора КУБМНОЖ().
Работа со срезами, представляющими одноуровневые измерения, не сопряжена с серьезными трудностями. Однако процесс обработки измерений со сложной структурой иерархий требует некоторых дополнительных пояснений. Дело в том, что срез, созданный на основе иерархии, графически отображается в виде целого набора отдельных окон — слоев, число которых равно количеству уровней в выбранном измерении.
На рис. 7 для примера показано, как выглядит срез, сформированный на базе трехуровневого измерения Product_Categories из стандартной учебной базы Adventure Works. Из рисунка видно, что элементы указанного измерения разнесены сразу по трем отдельным окнам. Все слои связаны между собой отношением Auto-Select, при котором задание условий фильтрации в любом из слоев автоматически меняет множество активных элементов во всех прочих слоях.

Рис. 7. Слои измерения Product_Categories
С подобным представлением многоуровневого измерения очень удобно работать на практике. Выбор родительского элемента всегда приводит к синхронному выделению его потомков на нижестоящих уровнях. Так, при активации элемента Clothing на уровне Category автоматически выделяются все подчиненные ему подкатегории, а также отдельные товарные позиции, относящиеся к номенклатурной группе «Одежда». Свойство Auto-Select работает также и в обратном режиме — «снизу вверх»: выбор любого товара на уровне Product сопровождается выделением всех его прямых предков.
Слои одного измерения связаны между собой на уровне данных, но при этом они представляют собой самостоятельные управляющие элементы Microsoft Excel. Слои можно произвольным образом располагать на листе, а также независимым образом менять их геометрические размеры. Кроме того, допускается создание произвольного количества копий любого слоя, а также размещение отдельных слоев не только в произвольных местах одного листа, но даже на нескольких различных листах одновременно. Подобные возможности открывают новые перспективы в области визуализации данных из OLAP-кубов.
В случае многоуровневых измерений следует учитывать одно важное обстоятельство: набор связанных со срезом элементов, пригодный для использования в операторах КУБ(), и набор элементов, выделенных во всех слоях среза на листе Microsoft Excel, часто не совпадают между собой. Чтобы выяснить, почему так происходит, повторно обратимся к примеру, приведенному на рис. 7. На рисунке видно, что категория Clothing состоит из восьми товарных групп (см. Набор 1).
Набор 1
{
[Bib-Shorts];
[Caps];
[Gloves];
[Jerseys];
[Shorts];
[Socks];
[Tights];
[Vests]
}
При фильтрации по измерению Product_Categories набор, содержащий единственный элемент {[Clothing]}, и набор 1 определяют одну и ту же область многомерного пространства, но различаются при этом уровнем детализации данных.
При составлении итогового фильтрующего набора не нужно перечислять оба эти множества одновременно — достаточно указать любое из них. Предпочтителен более экономный по записи вариант — {[Clothing]}. Поэтому если в срезе данных выбраны все потомки какого-либо элемента, то в итоговом наборе будет представлен только он сам. Практическую реализацию данной идеи мы и наблюдаем на рисунке. Подкатегории товаров [Bib-Shorts] на уровне [Product] соответствует набор 2 из трех элементов.
Набор 2
{
[Men’s Bib-Shorts, L],
[Men’s Bib-Shorts, M],
[Men’s Bib-Shorts, S]
}
Все элементы из набора 2 на рис. 7 находятся в выделенном состоянии, поэтому в наборе среза Срез_ Product_Categories они представлены в качестве единственного элемента подгруппы [Bib-Shorts].
Подкатегории [Vest] соответствует набор, также содержащий три элемента (набор 3).
Набор 3
{
[Classic Vest, L],
[Classic Vest, M],
[Classic Vest, S]
}
Но в данном случае на уровне [Product] выбраны не все, а только два элемента. Элемент [Classic Vest, L] оставлен невыделенным. Соответственно в набор среза Срез_ Product_Categories вместо подгруппы [Vest] добавлены конкретные товарные позиции с листового уровня измерения (строки 9-я и 10-я списка).
Рассмотрим теперь один существенный аспект совместного использования срезов и функций КУБ(). Как известно, элементы любого измерения могут присутствовать только на одной оси многомерного отчета. Безусловно, в процессе составления MDX-выражения допускается формирование нескольких наборов из одного измерения, но в конечном счете все они должны использоваться в составе MDX-функций либо объединяться в один итоговый набор. Срез данных — это инструмент для составления наборов. При желании со сводной таблицей можно связать несколько срезов, собранных из одного измерения. Но подобные наборы нельзя объединить в один, их также не получится использовать в качестве аргументов MDX-операторов внутри приложения Microsoft Excel. Видимо, поэтому срезы, относящиеся к одному измерению, при подключении к сводной таблице всегда связываются с одним именованным диапазоном Срез_Наименование_Измерения (переименование ассоциированного со срезом диапазона происходит автоматически). Такой подход гарантированно исключает коллизии при формировании многомерных отчетов. Хотя сами срезы при этом должны иметь собственные уникальные имена и могут также различаться заголовками. Создание автономного среза приводит к аналогичной ситуации: сколько бы срезов ни добавлялось в книгу, все они будут связываться с единственным диапазоном Срез_Наименование_Измерения. В большинстве случаев подобный подход оправдан. Однако, в отличие от отчетов сводных таблиц, формулы КУБЗНАЧЕНИЕ() позволяют обращаться к ячейкам куба индивидуальным образом. Учитывая вышесказанное, возникает естественное желание обойти исходные ограничения и научиться добавлять в книгу Microsoft Excel срезы одного измерения, связанные с разными именованными диапазонами. В действительности выполнить такую операцию довольно просто — достаточно вставить в книгу несколько сводных таблиц, использующих один OLAP-источник. Затем в каждой из сводных таблиц создать по срезу данных. Только в этом случае каждый из срезов связывается с собственным именованным диапазоном, который представляется в Диспетчере имен уникальным именем (рис. 8).
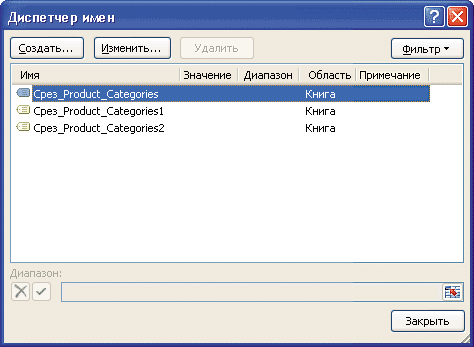
Рис. 8. Несколько срезов одного измерения в Диспетчере имен
Повторимся еще раз: срезы данных являются самостоятельными объектами. Они могут существовать независимо от сводных таблиц, на базе которых были созданы. Поэтому после вставки необходимых пользователю срезов промежуточные таблицы можно безболезненно удалить из книги.
Дальнейшая настройка отчетов сводится к указанию добавленных на первом шаге именованных диапазонов в аргументах функции КУБЗНАЧЕНИЕ(). На рис. 9 приведен пример одного из таких отчетов. В представленной таблице есть общая часть — измерение Customer Geography, а также три не зависящих друг от друга набора элементов из измерения Product_Categories.
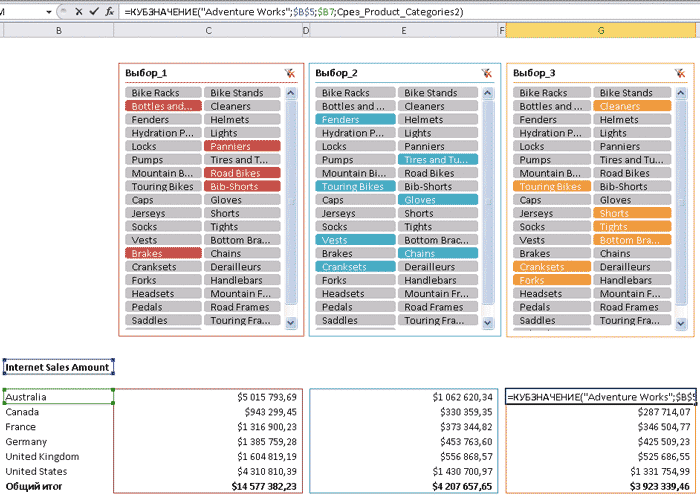
Рис. 9. Использование независимых срезов в одном аналитическом отчете
Теперь несколько слов об использовании срезов при создании производных наборов. Напомним читателям, в чем суть вопроса. Если в нашем распоряжении есть два набора элементов {Набор_1} и {Набор_2}, выбранных из одного измерения, то язык MDX позволяет составить новый набор {Набор_3}, объединяющий в себе представителей первых двух: {Набор_3}={ {Набор_1}, {Набор_2} }. В свою очередь, {Набор_3} может выступать в качестве исходного компонента для следующего набора: {Набор_5} = { {Набор_3}, {Набор_4} }. Функция КУБМНОЖ() позволяет реализовать такую логику, но уже на уровне клиентского приложения. В одной из прошлых статей цикла (КомпьютерПресс № 8’2011) мы рассказывали о возможной форме записи оператора КУБМНОЖ(«OLAP_Connection»;(Множество_1; Множество_2)). В данной синтаксической конструкции идентификаторы Множество_1 и Множество_2 являются ссылками на ячейки с вызовами других функций КУБМНОЖ().
Похожий прием возможен и при использовании срезов. К сожалению, простой способ, заключающийся в явном перечислении названий срезов в аргументах оператора КУБМНОЖ(), приводит к ошибке исполнения функции (рис. 10).

Рис. 10. Варианты формирования наборов с помощью срезов
Данное ограничение довольно просто обойти. Функцию КУБМНОЖ() можно использовать различными способами, в том числе в качестве своеобразного «контейнера» для среза данных. Напишем в ячейке Microsoft Excel следующее выражение (выражение 1).
Выражение 1
КУБМНОЖ(«Adventure Works”;Срез_Product_Categories;”Множ: Выбор_1”)
На рис. 10 эта формула занесена в ячейку с подписью «Множ: Выбор_1». Аналогичным образом поступим с остальными срезами, представляющими подкатегории каталога продукции фирмы. Затем все ранее созданные множества следует объединить в один итоговый набор (выражение 2).
Выражение 2
КУБМНОЖ(«Adventure Works”;(Выбор_1;Выбор_2;Выбор_3); “Множ: итог № 1”)
В выражении 2 идентификатор Выбор_1 представляет название ячейки, содержащей выражение 1.
Обращаем внимание читателей, что описанная выше процедура по «упаковке» среза в оболочку оператора КУБМНОЖ() превращает его в самый обычный набор, который воспринимается всеми остальными функциями семейства КУБ(). В частности, набор, объединяющий в себе элементы из нескольких срезов, можно упорядочить согласно некоторому критерию. Допустим, нам требуется, чтобы в отчетной форме подкатегории товаров, выбранные в нескольких срезах, были размещены в порядке увеличения объема продаж, произведенных в Австралии в 2008 году. Для организации такой сортировки расширим функцию из выражения 2 еще одним аргументом — параметром «Сорт_По».
Выражение 3
КУБМНОЖ( «Adventure Works»; (Выбор_1; Выбор_2; Выбор_3); «Множ: итог № 1»; 1; «([Date].[Calendar Year].&[2008], [Customer].[Customer Geography].[Country].&[Australia], [Measures].[Internet Sales Amount])»)
Результат работы выражения 3 представлен на рис. 10 множеством, заключенным в красную рамку. Получившийся в итоге набор объединяет все элементы, выбранные из трех срезов (с учетом дубликатов), причем подкатегории ранжированы по правилу, заданному пользователем. В действительности параметр «Сорт_По» определяет локальный контекст, в котором выполняется конкретное выражение. А контекст обычно задается путем перечисления отдельных элементов из разных измерений в одном кортеже. Возникает резонный вопрос: если срезы одного измерения сводятся в набор, то можно ли срезы элементов из различных измерений объединить в один кортеж, который использовать затем для упорядочения элементов основного набора? Оказывается, разработчики из компании Microsoft предусмотрели в системе даже такую экзотическую возможность. Вспомним, что кортежи элементов в Microsoft Excel собираются при помощи функции КУБЭЛЕМЕНТ(). В аргументе Выражение_элемента этого оператора последовательно указываются отдельные координаты на различных измерениях, определяющие в совокупности конкретную ячейку многомерного пространства. Принципиально важно, чтобы при добавлении в кортеж из каждого измерения выбирался единственный элемент. Но срез данных всегда является множеством, даже в тех случаях, когда он состоит из одного элемента. Поэтому напрямую использовать срезы для формирования кортежей (внутри функции КУБЭЛЕМЕНТ()) нельзя. Необходимо предварительно выбрать из набора определенный элемент. В MDX-выражениях такая операция выполняется посредством вызова оператора Item(), в ней аргумент Index задает ранг элемента в наборе. В семействе функций КУБ() для этих целей служит оператор КУБПОРЭЛЕМЕНТ().
Допустим, на лист Microsoft Excel добавлен срез, показывающий территориальное разделение продаж компании. Мы же хотим использовать регион, выбранный пользователем, для сортировки списка товарных позиций. Для этого элемент из измерения Sales_Territory требуется добавить в аргумент Сорт_По функции КУБМНОЖ(), формирующей перечень товаров. Добавление элемента производится в два этапа. Сначала в промежуточной ячейке посредством функции КУБПОРЭЛЕМЕНТ() выбирается первый элемент из множества среза Срез_Sales_Territory (см. выражение 4).
Выражение 4
=КУБПОРЭЛЕМЕНТ(«Adventure Works”;Срез_Sales_Territory;1)
На рис. 10 ячейка с выражением 4 имеет значение North America и светло-зеленую заливку фона. Затем координату, полученную на первом этапе, можно добавлять внутрь функции КУБМНОЖ() (см. выражение 5).
Выражение 5
=КУБМНОЖ(«Adventure Works»;(Выбор_1;Выбор_2;Выбор_3);»Множ: итог № 2»;1;Territory_Coordinate)
В выражении 5 формируется набор, содержащий элементы сразу из трех срезов, который при этом еще и сортируется по возрастанию продаж в регионе, выбранном из среза Срез_Sales_Territory (на рис. 10 он представлен списком, размещенным в правом верхнем углу рабочего листа книги). При желании можно продолжить конкретизировать условия сортировки. Предположим, что мы хотим при упорядочивании товаров учитывать не только регион, в котором они продавались, но и период их реализации. Для этого в условии Сорт_По элемент Territory_Coordinate следует заменить кортежем, содержащим координаты двух измерений, — (Territory_Coordinate, Calendar_Coordinate). Синтаксис КУБМНОЖ() не разрешает составлять кортежи непосредственно внутри вызова самой функции. Другими словами, исполнение выражения 6 будет возвращать ошибку типа #ЗНАЧ!.
Выражение 6
=КУБМНОЖ(«Adventure Works»;(Выбор_1;Выбор_2;Выбор_3);»Множ: итог № 2»;1;(Territory_Coordinate, Calendar_Coordinate))
Как и в прошлых случаях, описанная проблема относится к категории технических, а не принципиальных. Она легко решается посредством одного дополнительного промежуточного вычисления. На помощь здесь приходит функция КУБЭЛЕМЕНТ(), позволяющая составлять кортежи произвольной размерности путем простого перечисления координат из различных измерений. На листе рабочей книги выделим произвольную ячейку, назовем ее «Итоговый_Фильтр» и добавим в нее выражение 7.
Выражение 7
=КУБЭЛЕМЕНТ(«Adventure Works»; (Territory_Coordinate; Calendar_Coordinate))
Подставим полученный кортеж в функцию КУБМНОЖ(), которая в итоге должна принять следующий вид (см. выражение 8).
Выражение 8
=КУБМНОЖ(«Adventure Works»;(Выбор_1;Выбор_2;Выбор_3);»Множ: итог № 2»;1;Итоговый_Фильтр)
Результат вычисления выражения 8 представлен на рис. 10 перечнем элементов, расположенным под заголовком «“Сложное” объединение № 2». Обращаем внимание, что в приведенном примере срезы использовались только для сортировки элементов набора, который впоследствии будет размещаться на одной из осей отчета, но при этом они никак не влияют на содержание самого отчета. Заметим также, что в любом из срезов можно всегда деактивировать ранее выставленный фильтр. Снятие фильтра визуально выглядит как выделение всех элементов в форме среза, а с позиций многомерного анализа равносильно выбору элемента [(All)]. Такая операция просто исключает выбранное измерение из условий сортировки. Если фильтры удалить во всех срезах, которые использовались при формировании аргумента Сорт_По, набор будет отсортирован по возрастанию значений предопределенной меры (Default Measure). Во второй части статьи мы использовали для примеров классическую учебную базу Microsoft — Adventure Works. В ней в качестве предопределенной назначена мера Resseler Sales Amount. Составим последний набор при помощи выражения 9.
Выражение 9
=КУБМНОЖ(«Adventure Works”;(Выбор_1;Выбор_2;Выбор_3);”Множ: итог № 1”;1;”[Measures].[Reseller Sales Amount]”)
На рис. 11 элементы набора представлены перечнем значений, размещенным под заголовком «“Сложное” объединение № 1». Как видно из рисунка, данный список тождествен набору, формируемому выражением 8 в режиме одновременного отключения фильтров в срезах Group и Calendar Year.

Рис. 11. Снятие фильтров в срезах








