Тестируем Prescott
Микроархитектура процессора Prescott
Multimedia Content Creation Winstone 2004
SYSmark 2004 Internet Content Creation
2 февраля корпорация Intel выпустила пять новых процессоров, которые прежде были известны под кодовым названием Prescott, которые производятся с применением технологического процесса с проектной нормой 90 нм. Intel впервые в индустрии внедрила данную технологию в массовое производство. Процессоры расширяют функциональные возможности и обеспечивают высокую производительность персональных компьютеров различного назначения — от массовых домашних моделей до ПК для бизнеса, игровых компьютеров и высокопроизводительных ПК.
 прошлом номере журнала мы уже писали о новом процессоре Prescott, Однако это
было в преддверии выхода процессора, поэтому у нас не было возможности протестировать
его на предмет выявления производительности при работе с современными приложениями.
В настоящей публикации мы представляем подробный отчет о тестировании всего
семейства новых процессоров Prescott. Но, прежде чем переходить к обсуждению
методики и результатов тестирования, еще раз остановимся на особенностях архитектуры
этого процессора и на тех новшествах, которые позволяют говорить об очередном
скачке в области производства процессоров.
прошлом номере журнала мы уже писали о новом процессоре Prescott, Однако это
было в преддверии выхода процессора, поэтому у нас не было возможности протестировать
его на предмет выявления производительности при работе с современными приложениями.
В настоящей публикации мы представляем подробный отчет о тестировании всего
семейства новых процессоров Prescott. Но, прежде чем переходить к обсуждению
методики и результатов тестирования, еще раз остановимся на особенностях архитектуры
этого процессора и на тех новшествах, которые позволяют говорить об очередном
скачке в области производства процессоров.
Краткая справка
 роцессоры
семейства Prescott имеют площадь кристалла 112 мм2 и содержат 125 млн. транзисторов.
Это семейство процессоров на сегодняшний день включает модели с тактовыми частотами
3,4; 3,2 и 3,0 ГГц. Все процессоры поддерживают системную шину с частотой 800
МГц и имеют кэш 2-го уровня 1 Мбайт. Кроме того, процессоры этого семейства
поддерживают технологию Hyper-Threading. Для того чтобы отличать их от моделей
на ядре Northwood, в их названиях фигурирует буква «E». Несколько иначе обстоит
дело с младшей моделью Prescott с тактовой частотой 2,8 ГГц. Таких процессоров
два: Intel Pentium 4 2,8E ГГц и Intel Pentium 4 2,8А ГГц. Процессор с буквой
«Е» ничем, кроме тактовой частоты, не отличается от своих старших собратьев,
а вот модель Intel Pentium 4 2,8А ГГц рассчитана на системную шину 533 МГц и
не поддерживает технологию Hyper-Threading (табл.
1).
роцессоры
семейства Prescott имеют площадь кристалла 112 мм2 и содержат 125 млн. транзисторов.
Это семейство процессоров на сегодняшний день включает модели с тактовыми частотами
3,4; 3,2 и 3,0 ГГц. Все процессоры поддерживают системную шину с частотой 800
МГц и имеют кэш 2-го уровня 1 Мбайт. Кроме того, процессоры этого семейства
поддерживают технологию Hyper-Threading. Для того чтобы отличать их от моделей
на ядре Northwood, в их названиях фигурирует буква «E». Несколько иначе обстоит
дело с младшей моделью Prescott с тактовой частотой 2,8 ГГц. Таких процессоров
два: Intel Pentium 4 2,8E ГГц и Intel Pentium 4 2,8А ГГц. Процессор с буквой
«Е» ничем, кроме тактовой частоты, не отличается от своих старших собратьев,
а вот модель Intel Pentium 4 2,8А ГГц рассчитана на системную шину 533 МГц и
не поддерживает технологию Hyper-Threading (табл.
1).
Тактовые частоты, размер кэша и частота системной шины — эти характеристики нового процессора лежат на поверхности, однако не менее интересно и то, что скрыто от глаз рядового пользователя. В данном случае речь идет о новом технологическом процессе производства процессоров Prescott и об усовершенствованной микроархитектуре процессора.
Все процессоры семейства Prescott (и в этом их главная особенность) изготавливаются по технологическому процессу с проектной нормой 90 нм на подложках диаметром 300 мм. Новый технологический процесс соединяет в себе использование высокопроизводительных, энергоэкономичных транзисторов, технологии напряженного кремния, высокоскоростных медных соединений и нового диэлектрического материала с низкой диэлектрической проницаемостью. В едином технологическом процессе все эти технологии объединены впервые.
Процессоры Intel Pentium 4, изготавливаемые по 90-нанометровому производственному процессу имеют ряд особенностей, включая усовершенствованную микроархитектуру Intel NetBurst, увеличенную кэш-память 2-го уровня емкостью 1 Мбайт и 13 новых инструкций SSE3.
Рассмотрим более подробно особенности микроархитектуры нового процессора.
Микроархитектура процессора Prescott
основе архитектуры любого процессора лежат несколько обязательных конструктивных
элементов: кэш команд и данных, предпроцессор и блоки исполнения команд.
Процесс обработки данных состоит из нескольких характерных этапов. Сначала инструкции и данные забираются из кэша, который разделен на кэш данных и кэш инструкций, — эта процедура называется выборкой. Затем выбранные из кэша инструкции декодируются в понятные для данного процессора примитивы — микроинструкции (uops), и называется данная процедура декодированием. Далее декодированные команды поступают на исполнительные блоки процессора, где и выполняются, а результат записывается в оперативную память.
Процессы выборки инструкций из кэша, их декодирование и продвижение к исполнительным блокам осуществляются в предпроцессоре, а процесс выполнения декодированных команд — в блоке исполнения команд. Таким образом, даже в самом простейшем случае команда проходит как минимум четыре стадии обработки:
• выборка из кэша;
• декодирование;
• выполнение;
• запись результатов.
Указанные стадии принято называть конвейером обработки команд. В простейшем случае конвейер является четырехступенчатым, и каждую из этих ступеней команда должна проходить ровно за один такт. Для четырехступенчатого конвейера на выполнение одной команды соответственно отводится ровно четыре такта.
В реальных процессорах конвейер обработки команд может быть более сложным и включать большее количество ступеней. Собственно говоря, отличительной особенностью процессоров семейства Intel Pentium 4 и является их беспримерно длинный конвейер. Так, в процессорах на ядре Northwood длина конвейера составляла 20 ступеней, а в новом процессоре Prescott она увеличена до 31 ступени. Причина увеличения длины конвейера заключается в том, что поскольку многие команды являются довольно сложными и не могут быть выполнены за один такт процессора, особенно при высоких тактовых частотах, то каждая из четырех стадий обработки команд (выборка, декодирование, выполнение, запись) должна состоять из нескольких ступеней конвейера. Кроме того, в конвейер преднамеренно вставляются так называемые пустые ступени (Drive), на которых не происходит обработка инструкции.
Эти пустые (или передаточные) ступени необходимы для того, чтобы при высоких тактовых частотах сигнал успевал во время одного такта распространится от одного исполнительного блока к другому. Напомним, что при частотах свыше 3 ГГц время одного такта составляет менее 3 нс. За столь короткий промежуток времени свет в вакууме успевает пройти расстояние менее 1 см, а поскольку скорость распространения сигналов в кристалле существенно ниже скорости света, то при высоких тактовых частотах неизбежно приходится вводить пустые ступени конвейера для передачи сигнала.
Всякий процессор в конечном счете должен быть сконструирован таким образом, чтобы за минимальное время выполнять максимальное количество инструкций. Именно количество выполняемых за единицу времени инструкций и определяет производительность процессора.
Существует два принципиально различных способа повышения производительности процессора (не считая, конечно, увеличения тактовой частоты). Суть первого состоит в том, чтобы увеличивать количество исполнительных блоков — таким образом реализуется множество параллельных коротких конвейеров. Данный подход позволяет в полной мере реализовать параллелизм на уровне инструкций (Instruction-Level Parallelism, ILP), когда несколько инструкций выполняются одновременно в различных исполнительных блоках процессора. Количество ступеней конвейера здесь невелико, поэтому инструкции выполняются за небольшое количество циклов.
Для реализации параллелизма на уровне инструкций необходимо, чтобы поступающие на исполнительные блоки команды можно было выполнять параллельно. Однако если, к примеру, для выполнения следующей по порядку инструкции требуется знать результат выполнения предыдущей инструкции (подобные инструкции называются взаимозависимыми), то в этом случае параллельное выполнение невозможно. Поэтому препроцессор прежде всего проверяет взаимозависимость команд и переупорядочивает их — не в порядке поступления (Оut of Оrder), а так, чтобы их можно было выполнять параллельно. На последних ступенях конвейера инструкции выстраиваются в исходном порядке.
При коротком конвейере на каждой ступени процессор способен выполнять большее количество работы, однако на прохождение инструкции через каждую ступень конвейера здесь затрачивается больше времени, что ограничивает повышение тактовой частоты процессора. В этой ситуации увеличение числа команд, выполняемых за единицу времени, достигается за счет распараллеливания инструкций и наращивания исполнительных блоков процессора.
При использовании длинного конвейера возможно увеличение тактовой частоты процессора, то есть сам конвейер оказывается более быстрым. Применение длинных конвейеров с высокими тактовыми частотами процессора — это второй способ увеличения производительности процессора, и именно такая идеология длинного конвейера заложена в архитектуре процессора Intel Pentium 4. При использовании длинного конвейера на стадии исполнения инструкций задействуется меньшее количество исполнительных блоков, но каждый из них обладает длинным и соответственно быстрым конвейером. Это означает, что каждый блок исполнения (Execution Unit) имеет больше доступных для выполнения тактов и способен одновременно выполнять довольно много инструкций.
Этот метод имеет, однако, свои подводные камни. Дело в том, что в случае длинного конвейера предпроцессору необходимо обеспечивать ему соответствующую загрузку. Для этого предпроцессор должен обладать довольно большим буфером, способным вмещать достаточное количество инструкций. Если же в кэше отсутствует инструкция или данные для конвейера, то образуются так называемые конвейерные пузырьки (Рipeline Вubbles), которые проходят все ступени конвейера, но ни на одной из них не производятся никакие действия. Наличие Рipeline Вubbles негативно отражается на производительности процессора, поскольку ресурсы процессора просто-напросто простаивают. Избежать возникновения нежелательных простоев в процессорах позволяют различные хитроумные алгоритмы, например Hyper-Threading.
Как уже отмечалось выше, новый процессор Prescott имеет необычайно длинный конвейер — 31 ступень, что на 11 степеней больше, чем в процессоре Northwood. При этом архитектура Intel NetBurst, заложенная в процессоре, не претерпела существенных изменений. Структурная схема процессора изображена на рис. 1.
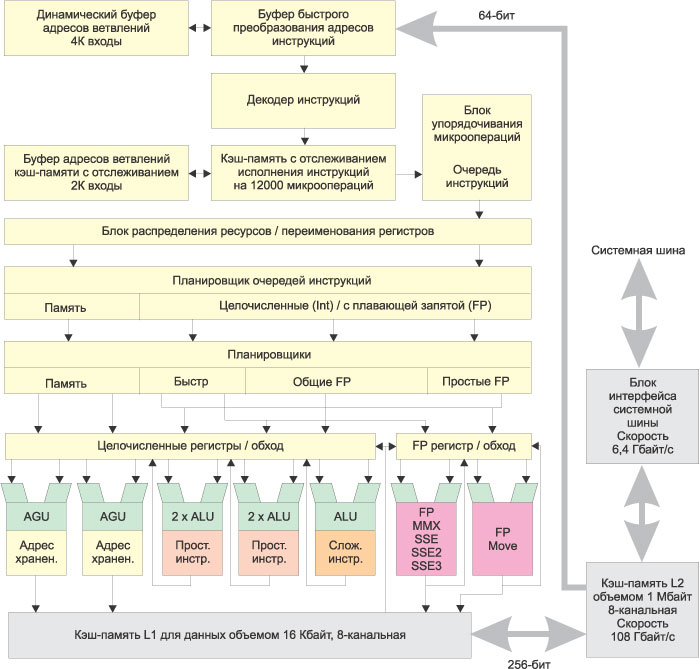
Рис. 1. Структурная схема процессора Intel Pentium 4
При работе процессора инструкции выбираются из кэша L2 и декодируются. Кэш L2 процессоров семейства Pentium 4 под названием Advanced Transfer Cache, имеет 256-битную шину, работающую на частоте ядра, и усовершенствованную схему передачи данных, кэш обеспечивает высочайшую пропускную способность, столь важную для потоковых процессов обработки.
Для выборки команд из кэша L2 и их последующего декодирования в микрооперации отводится несколько начальных ступеней конвейера. Соответственно при выполнении фрагмента программного кода для декодирования команд будет использовано несколько процессорных тактов. Однако во многих современных (прежде всего мультимедийных) приложениях один и тот же фрагмент кода может повторяться многократно, и было бы нерационально тратить процессорные такты на повторную выборку, транслирование и декодирование. Выгоднее хранить уже готовые к исполнению микроинструкции в специальном кэше L1, где из них формируются мини-программы, называемые отслеживаниями (Тraces). Каждая такая программа может содержать до 6 декодированных инструкций uops. Мини-программы формируются из инструкций, которые выполняются последовательно (именно поэтому они и называются отслеживаниями). При этом в самом программном коде указанные инструкции могут не следовать друг за другом, то есть реализуется внеочередное выполнение инструкций (Оut-of-Оrder). При попадании в кэш L1 происходит внеочередное выполнение команд; при этом значительно экономятся ресурсы процессора, так как по своей сути внеочередное выполнение команд подразумевает устранение первых ступеней конвейера, фактическая длина которого в этом случае составляет уже 31 ступень. В кэше с отслеживанием может храниться до 12 тыс. декодированных микрокоманд.
Режим работы процессора при внеочередном выполнении команд (то есть когда происходит попадание в Trace Cache и используются уже декодированные команды) является естественным для процессора Intel Pentium 4. Поэтому, говоря о длине конвейера в 31 ступень, мы имеем в виду длину основного конвейера — без учета первых ступеней, которые используются при необходимости выборки команд, их трансляции, декодирования и сохранения в Trace Cache полученных микрокоманд.
Чтобы обеспечить высокий процент попаданий в кэш L1 с отслеживаниями (Trace Cache) и построение в нем мини-программ, используется специальный блок предсказания ветвлений (Branch Targets Buffers, BTB и Instruction Translation Look-aside Buffers, I-TLB). Этот блок позволяет модифицировать мини-программы, основываясь на спекулятивном предсказании. Так, если в программном коде имеется точка ветвления, то блок предсказаний может предположить дальнейший ход программы вдоль одной из возможных ветвей и с учетом этого спекулятивного предсказания построить мини-программу. Технология использования кэша с отслеживанием вместе с усовершенствованным алгоритмом предсказания получила название Advanced Dynamic Execution и является составляющей частью технологии NetBurst.
Кэш микроинструкций с отслеживаниями имеет еще одну особенность. Известно, что большинство команд х86 при декодировании преобразуются в две-три микроинструкции. Однако встречаются и такие команды, для декодирования которых требуются десятки и даже сотни микрокоманд. Естественно, что сохранять такие декодированные команды в кэше L1 было бы нерационально — для этих целей используется специальная ROM-память (Microcode ROM), а в самом кэше L1 сохраняется лишь метка на область ROM-памяти, где хранятся соответствующие микрокоманды. При попадании на такую метку управление потоком инструкций передается ROM-памяти.
Рассмотрим теперь процесс продвижения микроинструкций по основному конвейеру, то когда процессор работает в режиме внеочередного выполнения инструкций. В течение первых двух тактов в Trace Cache передается указатель на следующие выполняемые инструкции — это две первые ступени конвейера, называемые Trace Cache next instruction pointer. После получения указателя в течение двух тактов происходит выборка инструкций из кэша (Trace Cache Fetch) — это две следующие ступени конвейера. Затем выбранные инструкции должны быть отосланы на внеочередное выполнение. Для того чтобы обеспечить продвижение выбранных инструкций по процессору, используется еще одна дополнительная, или передаточная, ступень конвейера (Drive).
На следующих ступенях конвейера, которые называются Allocate & Rename, происходят переименование и распределение дополнительных регистров процессора. В процессоре Intel Pentium 4 содержится 128 дополнительных регистров, которые не определены архитектурой набора команд. Переименование регистров позволяет добиться их бесконфликтного существования.
Далее формируются две очереди (Queue) микрокоманд: очередь микрокоманд памяти (Memory uop Queue) и очередь арифметических микрокоманд (Integer/Floating Point uop Queue).
На следующих ступенях конвейера происходит планирование и распределение (Schedule) микрокоманд. Планировщик (Scheduler) — это своего рода сердце ядра процессора — выполняет две основные функции: переупорядочивание микрокоманд и распределение их по функциональным устройствам. Суть переупорядочивания микрокоманд заключается в том, что планировщик определяет, какую из них уже можно выполнять и в соответствии с их готовностью меняет порядок следования. Распределение микрокоманд происходит по четырем функциональным устройствам, то есть формируются четыре очереди. Первые две из них предназначены для устройств памяти (Load/Store Unit) и формируются планировщиком Memory Scheduler из очереди памяти Mem uop Queue. Микрокоманды из очереди арифметических микрокоманд (Integer/Floating Point uop Queue) также распределяются в очереди соответствующих функциональных устройств, для чего предназначено три планировщика: Fast ALU Scheduler, Slow ALU/General FPU Scheduler и Simple FP Scheduler.
Fast ALU Scheduler — это распределитель простых целочисленных операций, который собирает простейшие микроинструкции для работы с целыми числами, чтобы затем послать их на исполнительный блок ALU, работающий на двойной скорости. В процессоре Pentium 4 имеются два исполнительных блока ALU, работающих на удвоенной скорости. К примеру, если тактовая частота процессора составляет 3,2 ГГц, то эти два устройства ALU работают с частотой 6,4 ГГц и в параллельном режиме способны выполнять четыре целочисленные операции за один такт. Такие блоки ALU получили название Rapid Execution Engine (блоки быстрого исполнения). Отметим, что в процессоре Prescott в один из быстрых блоков ALU добавлен блок Shifter/Rotator, исполняющий инструкции типа сдвига и вращения. Благодаря этому такие инструкции теперь исполняются гораздо быстрее, поскольку в предыдущих реализациях Pentium 4 сдвиг и вращение трактовались как сложные инструкции и выполнялись на медленном ALU.
Slow ALU/General FPU Scheduler — распределитель целочисленных операций/распределитель операций с плавающей точкой, который и распределяет остальные операции ALU и операции с плавающей точкой.
Simple FP Scheduler — распределитель простых операций с плавающей точкой. Это устройство формирует очередь простых операций с плавающей точкой и операций по доступу к памяти с плавающей точкой.
Говоря о исполнительных блоках процессоров семейства Pentium 4, отметим, что в Prescott несколько иначе производится операция целочисленного умножения. Если в предыдущих моделях процессоров целочисленной умножение выполнялось в блоке FPU с предварительным переводом операндов сначала в формат с плавающей точкой, а потом обратно, то в Prescott целочисленное умножение выполняется в блоке ALU, что, естественно, сказывается на скорости выполнения операций.
На следующих ступенях конвейера реализуется этап диспетчеризации (Dispatch): инструкции попадают на один из четырех портов диспетчеризации (Dispatch Ports), которые выполняют функцию шлюзов к функциональным устройствам.
После того как инструкции пройдут порты диспетчеризации, они загружаются в блок регистров для дальнейшего выполнения. Для этого предназначены следующие ступени процессора, именуемые Register Files.
После загрузки инструкций в блок регистров все готово для непосредственного выполнения команд. Процесс выполнения инструкций в исполнительных устройствах происходит на следующей, ступени конвейера, которая называется Execute. Всего с использованием семи исполнительных блоков процессор Intel Pentium 4 может выполнять до шести микроинструкций за один такт.
Следующие ступени конвейера — это изменение состояния флагов (Flags) и проверка ветвления (Branch Check), на которой процессор узнает, сбылось ли предсказание ветвления. Последняя ступень процессора — еще одна передаточная ступень, назначение которой мы уже рассматривали.
Рассмотрев микроархитектуру нового процессора, можно заметить, что она во многом повторяет микроархитектуру процессора на ядре Northwood. Первое бросающееся в глаза отличие — это более длинный конвейер, реализованный за счет дополнительных передаточных ступеней Drive и за счет того, что некоторые операции (типа Dispatch) стали занимать большее количество ступеней конвейера. Казалось бы, увеличение длины конвейера при неизменной тактовой частоте должно понизить производительность процессора, поскольку меньшее количество инструкций будет выполняться за один такт. Кроме того, при неправильном предсказании перехода придется полностью очищать и перезаполнять конвейер. Отчасти это справедливо, и если сравнивать производительность процессора Northwood с 20-ступенчатым конвейером и Prescott с 31-ступенчатым конвейером, то при одной и той же тактовой частоте Prescott должен был бы проиграть. Однако различие в длинах конвейера — далеко не единственно различие между этими процессорами. Дело в том, что с целью минимизации простоев, связанных с необходимостью очистки и перезаполнения конвейера, существенной модернизации в Prescott подверглась схема предсказания переходов.
Работа блока предсказания переходов основывается на работе 4-Кбайт буфера Branch Target Buffer (BTB), в котором накапливается статистика выполненных переходов. Для предсказания переходов используется вероятностная модель на основе накопленной статистики. Правда, данный алгоритм оправдывает себя только в том случае, если по конкретному переходу статистика уже накоплена. Если же этой статистики нет, то вероятностная модель предсказания не работает. В таком случае в процессорах Northwood осуществлялся переход назад, причем считалось, что обратный переход осуществляется в циклическом фрагменте программы до точки выхода из цикла. Однако это справедливо не всегда, поскольку ветвь программы, по которой осуществляется обратный переход, может и не быть фрагментом цикла. Поэтому в процессоре Prescott статическая схема предсказания переходов была существенно улучшена: если предсказать переход на основании накопленной статистики невозможно, осуществляется переход назад, но не до точки выхода из цикла, а на определенное расстояние, найденное на основе анализа. Зная длину перехода, можно предсказать, является ли фрагмент циклом или нет.
Кроме улучшения модуля статического предсказания переходов, в процессоре Prescott была усовершенствована схема динамического предсказания переходов — добавлен блок косвенного предсказания переходов, который впервые был реализован в процессорах Intel Pentium M. В результате в процессоре Prescott удалось уменьшить число неправильно предсказанных переходов в сравнении с процессором Northwood, что отражается на сокращении числа задержек, вызванных необходимостью очистки и перезаполнения конвейера.
Наряду с уже перечисленными улучшениями в процессоре Prescott реализован целый ряд новаций:
• усовершенствованная технология Hyper-Threading;
• дополнительные буферы отложенной записи (WC);
• 13 новых инструкций процессора (набор инструкций SSE3).
Дополнительные буферы отложенной записи WC (Write Combining) обеспечивают возможность одновременного исполнения большего числа инструкций типа сохранения или загрузки данных.
В процессоре Prescott имеются 13 новых инструкций, позволяющих повысить общую производительность в играх и мультимедийных приложениях (данный набор инструкций теперь известен как SSE3). Новые инструкции разделены на пять групп:
• операции преобразования чисел с плавающей запятой в целочисленный формат;
• операции с комплексными числами;
• операции кодирования-декодирования видео;
• SIMD FP-операции с использованием формата AOS;
• операции синхронизации потоков.
Конечно, для реализации всех преимуществ от использования нового набора команд, нужно, чтобы они поддерживались приложениями. Но это уже дело времени, и вскоре начнут появляться приложения, оптимизированные для использования нового набора команд. Уже сейчас существуют приложения, поддерживающие SSE3 — это различные кодеки и проигрыватели: MainConcept (MPEG 2/4), xMPEG, Ligos (MPEG 2/4), Real (RV9), On2 (VP5/VP6), Pegasys TMPGEnc 3.0, Adobe Premier, Pinnacle (MPEG Encoder и DivX Codec), Sony DVD Source Creator, Ulead (MediaStudio & Video Studio), Intervideo, Showshifter, Snapstream (все используют DivX-кодеки).
Отметим также, что последняя версия компилятора Intel поддерживает набор инструкций SSE3.
От теории к практике
осле
столь подробного рассмотрения архитектуры нового процессора Prescott, перейдем
к практической стороне вопроса, то есть попытаемся выяснить, насколько хорош
новый процессор при работе с современными приложениями.
Мы протестировали имевшиеся в нашем распоряжении три новых модели процессора Prescott: Intel Pentium 4 2,8E ГГц, Intel Pentium 4 3,0E ГГц и Intel Pentium 4 3,2E ГГц.
Тестирование проводилось под управлением операционной системы Windows XP Professional SP1 (английская версия).
Для тестирования был собран стенд в следующей конфигурации:
• системная плата Asus P4C800 Deluxe;
• чипсет системной платы Intel 875P;
• версия BIOS v.1014;
• видеокарта: ASUS Radeon 9800XT;
• память2*256 Мбайт PC 3500 Kingstone KHX3500 в режиме DDR 400;
• жесткий диск Seagate Barracuda ATA V (ST3120023AS), 120 Гбайт.
Сразу оговоримся, что имевшаяся в нашем распоряжении плата Asus P4C800 Deluxe со старой версией BIOS наотрез отказалась «заводиться» с новыми процессорами, поэтому первое, что пришлось сделать — это перепрошить BIOS на плате, используя старый процессор.
Дополнительно использовались следующие драйверы и утилиты:
• видеодрайвер: ATi Catalyst 3.10;
• Intel Chipset Software Installation Utility 5.0.2.1003;
• API DirectX 9.0b.
Для тестирования мы отобрали тесты:
· BapCo SYSmark 2004 Internet Content Creation;
• BapCo SYSmark 2004 Office Productivity;
• BapCo WebMark 2004 (Off line);
• Veritest Business Winstone 2004;
• Veritest Multimedia Content Creation Winstone 2004;
• FutureMark 3DMark 2003;
• MadOnion PCMark 2004;
• SPEC ViewPerf 7.1.1;
• SiSoftSandra 2004 Standart;
• Comanche 4 Demo;
• Unreal Tournament 2003 Demo;
• Serious Sam: Second Encounter Demo;
• Return to Castle Wolfenstein v.1.41;
• 3dsmax 6.0.
Если тесты 3DMark 2003, SPEC ViewPerf 7.1.1, PCMark2004, 3dsmax 6.0 и игровые бенчмарки хорошо известны и не нуждаются в представлении, то к новым пакетам SYSmark 2004 Internet Content Creation, SYSmark 2004 Office Productivity, WebMark 2004, Veritest Business Winstone 2004 и Multimedia Content Creation Winstone 2004 необходимо дать комментарии.
Business Winstone 2004
Тест Business Winstone 2004 предназначен для определения производительности компьютера при работе с наиболее популярными 32-разрядными офисными приложениями. В данном тесте выполняются скрипты реальных приложений, входящих в пакет Windows Office XP, и некоторые другие:
• Microsoft Internet Explorer;
• Microsoft Outlook 2002;
• Microsoft Project 2002;
• Microsoft Access 2002;
• Norton AntiVirus Professional Edition 2003;
• Microsoft PowerPoint 2002 SP-2;
• Microsoft Excel 2002 SP-2;
• Microsoft FrontPage 2002 SP-2;
• Microsoft Word 2002 SP-2;
• WinZip 8.1.
В этом тесте имеется специальный режим многозадачности (Business Winstone 2004 Multitasking Test) — несколько приложений и задач запускается одновременно. Например, при работе с документом Word в фоновом режиме может осуществляться сканирование директорий на наличие вируса. В режиме Multitasking Test предусмотрено три различных сценария. В первом из них в фоновом режиме выполняется операция копирования файлов, а в активном окне имитируется работа пользователя с Microsoft Outlook и браузером Internet Explorer.
Во втором реализуется операция архивации файлов (фоновый режим) на фоне выполнения типичных задач с приложениями Excel и Word. В третьем сценарии запускаются скрипты приложений Microsoft Excel, Microsoft Project, Microsoft Access, Microsoft PowerPoint, Microsoft FrontPage и WinZip и одновременно с этим в фоновом режиме проводится антивирусное сканирование приложением Norton AntiVirus.
Multimedia Content Creation Winstone 2004
Тестовый пакет Multimedia Content Creation Winstone 2004 используется для оценки производительности ПК при работе с мультимедийными контент-приложениями. Суть теста заключается в имитации работы пользователя с наиболее популярными 32-разрядными Windows-приложениями:
• Adobe Photoshop 7.0.1;
• Adobe Premiere 6.50;
• Macromedia Director MX 9.0;
• Macromedia Dreamweaver MX 6.;
• Microsoft Windows Media Encoder 9;
• NewTek LightWave 3D 7.5b;
• Steinberg WaveLab 4.0f.
Чтобы полнее имитировать работу современного пользователя, в тесте Multimedia Content Creation Winstone 2004 одновременно запускается несколько приложений, а в процессе выполнения скрипта осуществляется переключение между различными активными приложениями.
Для расчета интегрального результата в тестах Multimedia Content Creation Winstone 2004 и Business Winstone 2004 с соответствующими весовыми коэффициентами усредняется времена выполнения отдельных задач, после чего полученное значение нормируется. С целью определения нормированного результата теста Business Winstone 2004 результат усреднения соотносится с результатам теста Business Winstone 2004 для некоторого эталонного ПК. Для эталонного ПК результат теста Business Winstone 2004 при последовательном выполнении отдельных задач принимается равным 10, а при работе в мультизадачном режиме — 1,0.
SYSmark 2004 Internet Content Creation
Тест SYSmark 2004 Internet Content Creation также предназначен для измерения производительности ПК при работе с мультимедийными приложениями. В этом тесте эмулируется работа пользователя с цифровыми фотографиями, кодирование видео- и аудиоданных, создание Web-страниц, анимация и 3D-рендеринг. В тесте используются следующие приложения:
• Adobe After Effects 5.5;
• Adobe Photoshop 7.01;
• Adobe Premiere 6.5;
• Discreet 3ds max 5.1;
• Macromedia Dreamweaver MX;
• Macromedia Flash MX;
• Microsoft Windows Media Encoder 9;
• Network Associates McAfee VirusScan 7.0;
• WinZip 8.1.
Для того чтобы лучше сымитировать работу реального пользователя, одновременно открывается множество окон, а некоторые приложения выполняются в фоновом режиме.
SYSmark 2004 Office Productivity
Тест SYSmark 2004 Office Productivity эмулирует работу пользователя с наиболее популярными офисными приложениями при создании текстовых документов, таблиц и презентаций. Эмулируются работа с электронной почтой, поиск нужных файлов, компрессия данных и т.д. В тесте используются приложения:
• Adobe Acrobat 5.0.5;
• Microsoft Access 2002;
• Microsoft Excel 2002;
• Microsoft Internet Explorer 6;
• Microsoft Outlook 2002;
• Microsoft PowerPoint 2002;
• Microsoft Word 2002;
• Network Associates McAfee VirusScan 7.0;
• ScanSoft Dragon NaturallySpeaking 6;
• WinZip 8.1.
Как и в тесте SYSmark 2004 Internet Content Creation, одновременно открывается множество окон с постоянным переключением между ними. Кроме того, предусмотрена одновременная работа нескольких приложений, то когда одно приложение активно, а другое выполняется в фоновом режиме.
WebMark 2004
Как нетрудно понять из названия, тест WebMark 2004 служит для определения интегральной производительности ПК при работе в Интернете. С этой целью эмулируется что-то вроде Интернет-серфинга, когда пользователь заходит на различные сайты, открывает pdf-документы, проигрывает музыкальные или аудиофайлы и т.д. В тесте используются такие приложения:
• Adobe Acrobat Reader v6.0;
• Macromedia Flash Player V7.0.14.0;
• Microsoft Windows Media Player 9;
• Macromedia Shockwave Player v 8.5.1;
• DHTML;
• JavaScript;
• Java Applets;
• SSL;
• XML;
• .NET Framework v1.1.
С тем чтобы исключить влияние сетевой инфраструктуры, мы использовали при тестировании режим Offline, то есть без подключения к реальной сети, когда все необходимые приложения хранятся на самом тестируемом клиенте.
Результаты тестирования
 езультаты,
полученные нами в ходе проведенного тестирования (табл. 2),
оказались весьма любопытными и безусловно заслуживающими более пристального
и детального рассмотрения.
езультаты,
полученные нами в ходе проведенного тестирования (табл. 2),
оказались весьма любопытными и безусловно заслуживающими более пристального
и детального рассмотрения.
Прежде всего определимся с точкой отсчета — в данном случае с процессором, обеспечивающим некую эталонную производительность, что позволит нам оценить плюсы и минусы новых процессоров компании Intel, созданных на ядре Prescott. В качестве точки начала координат нами был выбран процессор Intel Pentium 4 3,0 ГГц, который является третьим по старшинству в последней «династии» Northwood, об архитектуре, характеристиках и возможностях которой уже немало писано и сказано, в том числе и на страницах нашего журнала. Итак, выбрав упомянутую модель в качестве образца, демонстрирующего эталонную производительность, мы сравнили результаты, показанные всеми остальными исследуемыми процессорами, а это Intel Pentium 4 2,8E ГГц/3,0E ГГц/3,2E ГГц (ядро Prescott) и Intel Pentium 4 Extreme Edition 3,2 ГГц/3,4 ГГц, с аналогичными показателями, продемонстрированными этим чипом.
После небольшого вступления перейдем непосредственно к анализу результатов, полученных нами в ходе тестирования. Начнем с самого очевидного: оба процессора семейства Intel Pentium 4 Extreme Edition оказались «в больших плюсах». Да и кто бы в этом сомневался, ведь от нашего эталона они отличаются лишь наличием довольно весомого кэша L3 — объемом ни много ни мало 2048 Кбайт. Этот дополнительный объем быстрой памяти (кэш L3 имеет 64-битную шину, работающую на частоте процессора) вместе с большей тактовой частотой двух тестируемых моделей процессора, безусловно, помогли в установлении рекордов производительности. Но справедливости ради стоит отметить, что наличие кэша L3 далеко не всегда обеспечивает сколь-либо значительный прирост производительности, хотя на приложениях, свойственных для той области применения, в которой позиционируются процессоры этого семейства (а это прежде всего компьютерные игры), демонстрируемые ими результаты, конечно же, впечатляют.
С процессорами Prescott все было далеко не столь гладко и однозначно. Так, даже процессор Intel Pentium 4 3,2E ГГц, работающий на тактовой частоте, которая на 200 МГц больше, чем у нашего эталона, в целом ряде тестов (подтест Communication, входящий в состав теста Office Productivity из пакета SYSMark2004, тест light-06 из тестовой утилиты SPEC ViewPerf 7.1.1, Comanche 4 Demo, Return to Castle Wolfenstein v.1.41, процессорные тесты из состава утилиты SiSoftSandra 2004 Standart и тестовый скрипт для 3dsmax 6.0), не смог превзойти результаты, показанные моделью Intel Pentium 4 3,0 ГГц. В чем же дело? Причины подобной ситуации, естественно, нужно искать в тех изменениях, которые претерпела архитектура нового ядра Prescott по сравнению с предшествующим ему Northwood. Возвратившись к фактам, изложенным в начале данной статьи, можно предположить, что основной причиной возникновения этого отрицательного эффекта является более чем полуторное увеличение длины конвейера.
Что же касается остальных новаций нового ядра, то они, безусловно, призваны повысить производительность процессоров и в большинстве случаев способны полностью компенсировать негативные последствия применения более длинного конвейера. Давайте проследим, как это выглядит на практике. В данном случае наиболее показательным будет рассмотрение результатов процессоров Intel Pentium 4 3,0E ГГц и Intel Pentium 4 3,0 ГГц. Оба процессора работают с одинаковой тактовой частотой — 3,0 ГГц, причем частота системной шины у этих двух моделей также идентична — 200 МГц (частота FSB 800 МГц), а что в итоге? Результаты тестов Content Creation Winstone 2004 v.1.0, Business Winstone 2004 v.1.0 и FutureMark 3DMark 2003 выявили небольшое преимущество процессора на ядре Prescott, и в пяти тестах из шести (входящих в тестовую утилиту SPEC ViewPerf 7.1.1) это преимущество было еще более ощутимым. Итоги тестов пакета SYSMark2004 в целом также остались за Prescott, но здесь не обошлось без срыва, так в подтесте Communication теста Office Productivity производительность процессора Intel Pentium 4 3,0E ГГц оказалась на 4% меньшей, чем у его соперника. Напомним, что в данном подтесте эмулируются действия пользователя по отправке нескольких текстовых документов, заархивированных в zip-файл при помощи почтового клиента Microsoft Outlook 2002, просмотр электронной почты и редактирование календаря, а также просмотр ряда Web-страниц Интернет-браузером Microsoft Internet Explorer 6.0, причем все это происходит на фоне сканирования выполняемого антивирусной программой VirusScan 7.0). Результаты теста WebMark2004 еще раз подтвердили тот факт, что процессоры Prescott не слишком способны к решению задачи Интернет-серфинга. Кроме того, 3-ГГц Prescott значительно уступил аналогичной модели на ядре Northwood во всех игровых тестах, а по итогам Comanche 4 Demo его отставание составило 14,5 %. Но и это не всё: по результатам всех чисто процессорных тестов (как синтетических, включенных в тестовые утилиты MadOnion PCMark2004 и SiSoftSandra 2004 Standart, так и основанных на реальных приложениях, в качестве которых использовался скрипт рендеренга сцен разной сложности для 3dsmax 6.0), тоже оказалось, что новое ядро несколько уступает по производительности предыдущему.
Возьмем на себя смелость дать объяснение полученному феномену. Как уже было сказано, всему виной — огромный конвейер Prescott. В тех случаях, когда усовершенствованные механизмы предсказания переходов и ветвлений справляются со своей задачей (хотя ошибки предсказания все равно неизбежны, но по крайней мере удается минимизировать их последствия, чему в немалой степени способствует увеличение кэша), новые процессоры демонстрирует весьма высокую производительность. Но как только выполняемые действия становятся слабо поддающимися анализу и предсказанию (как следствие, возникает необходимость в частых перезагрузках конвейера, а также учащаются промахи кэша), удлинение конвейера незамедлительно дает о себе знать. Именно этим, на наш взгляд, и объясняются сравнительно невысокие результаты, продемонстрированные процессорами семейства Prescott в тестах, которые были основаны на эмуляции действий пользователя при Интернет-серфинге. Что же в таком случае произошло с итогами процессорных тестов? По логике вещей подобные тестовые программы подразумевают выполнение задач, имеющих довольно простой для предсказания ветвлений программный код. В такой ситуации, казалось бы, процессоры на ядре Prescott должны показать себя во всей красе. Но не тут-то было, ведь увеличение объема кэш-памяти имеет свои негативные последствия — это рост времени задержки (латентности) при обращении к кэшированным данным. В подтверждение сказанного приведем результаты теста Memory Benchmarks, входящего из состава тестовой утилиты ScienceMark 2.1 (рис. 2 и 3).
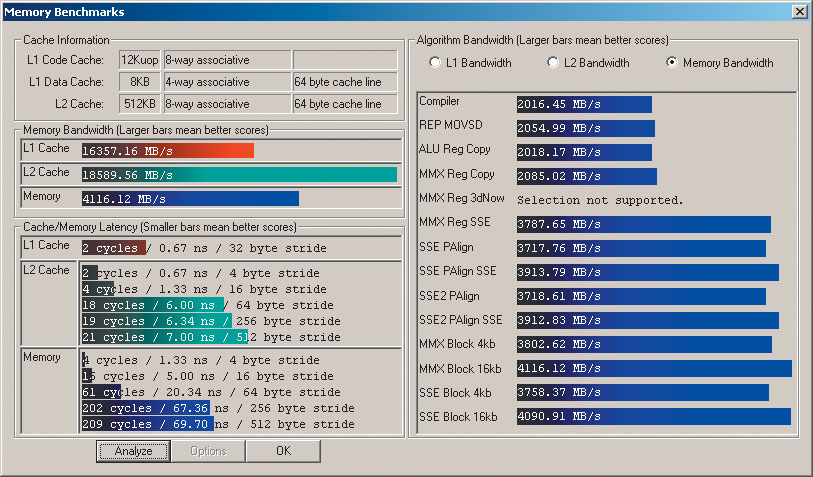
Рис. 2. Результаты теста Memory Benchmarks ScienceMark 2.1 для процессора Intel Pentium 4 3,0 ГГц
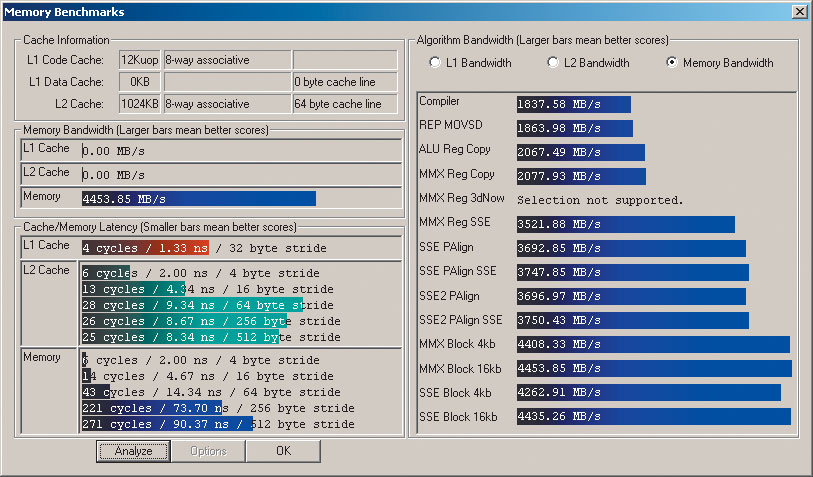
Рис. 3. Результаты теста Memory Benchmarks ScienceMark 2.1 для процессора Intel Pentium 4 3,0E ГГц
Выводы
одводя
итог всему вышесказанному, в заключение хотелось бы высказать наше мнение о
перспективах новых процессоров Intel построенных на ядре Prescott. Не будем
гадать на кофейной гуще и делать различные предположении о скрытых возможностях
и технологиях, реализованных в новом ядре, ибо такие гипотезы (как довольно
правдоподобные, так и сомнительные) в изобилии присутствуют во многих статьях
на эту тему. Приведем лишь очевидное умозаключение по поводу новых моделей процессоров
Prescott. На наш взгляд, в данном случае во многом повторяется история с первыми
моделями Intel Pentium 4, когда появившиеся в то время процессоры новой линейки
по своей производительности при решении целого ряда задач уступали старшим моделям
процессоров Intel Pentium III, хотя и работали на больших тактовых частотах.
Однако дебютировавшие тогда процессоры на ядре Willamette открыли возможности
для дальнейшего наращивания производительности за счет увеличения тактовой частоты
(чему во многом способствовал огромный по тем временам 20-ступенчатый конвейер).
В такую же ситуацию мы наблюдаем и на этот раз, хотя в данном случае уместнее
говорить об эволюционных, а не революционных (хотя и не менее существенных)
изменениях, привнесенных в давно уже знакомую архитектуру NetBurst.
Редакция выражает признательность представительству компании Intel (www.intel.ru) за предоставление процессоров для проведения тестрования |








