Использование объектно-реляционных СУБД для хранения и анализа временных рядов
Андрей Прохоров ![]()
Методы индексирования значений временного ряда
Проблемы хранения и анализа временных рядов в СУБД
Использование реляционной модели
Использование объектно-релационной модели
Informix TimeSeries DataBlade как пример коммерческого продукта
Физическая и логическая модели временного ряда
Введение
Подавляющее большинство потребителей информационных технологий в той или иной степени уже решили задачу оперативного ввода данных. Однако при этом многие из них испытывают насущную потребность в организации анализа накопленных данных.
Одними из наиболее часто встречающихся объектов анализа являются временные ряды. По своему содержанию временной ряд — это результат наблюдения за одним или несколькими параметрами какого-либо процесса. При наблюдении значения этих параметров фиксируются и привязываются к моменту наблюдения. В результате образуется упорядоченная в хронологическом порядке последовательность измеренных значений, которая и называется временным рядом [1].
За последние несколько десятилетий разработан обширный математический аппарат анализа временных рядов. Главные задачи этого аппарата — выявлять закономерности в поведении наблюдаемого процесса и прогнозировать его поведение в будущем.
Несмотря на глубокую теоретическую проработку методов анализа временных рядов, их практическая реализация в настоящее время встречает серьезные трудности. В числе наиболее серьезных источников проблем следует назвать неспособность крупных промышленных реляционных СУБД (РСУБД) эффективно хранить и обрабатывать временные ряды [2]. Дело в том, что именно этот класс СУБД составляет основу крупных корпоративных информационных систем. При этом они имеют все необходимые средства для описания временного ряда как одной из хранимых структур данных. Однако производительность обработки этой структуры данных оказывается столь низкой, а трудоемкость описания прикладной логики столь высокой, что на практике эти СУБД для хранения и обработки временных рядов не используются.
Сегодня для решения задач хранения и анализа временных рядов вместо РСУБД используются узкоспециализированные системы, лишенные недостатков, свойственных РСУБД при работе с временными рядами. Правда, эти специализированные системы, в свою очередь, имеют ряд принципиальных ограничений:
- неспособность эффективно обрабатывать большие объемы данных;
- закрытый формат хранения временных рядов;
- отсутствие интерфейсов для расширения методов поиска и хранения внутри временных рядов;
- трудность интеграции в корпоративные информационные системы (КИС).
Из этого следует, что использование специализированных систем позволяет решить проблему эффективного хранения и обработки временных рядов только на первых порах, при относительно небольших объемах данных. К тому же даже на начальном этапе пользователям приходится преодолевать серьезные трудности. Проблема состоит в том, что в большинстве случаев анализ временных рядов является только одной из подзадач КИС. Интеграция закрытых специализированных систем в общую структуру корпоративной информационной системы требует значительных усилий.
В результате у многих пользователей возникает потребность в такой системе управления временными рядами (СУВР), которая может:
- эффективно хранить и обрабатывать временные ряды;
- обеспечивать масштабируемость на уровне РСУБД;
- поддерживать существующие стандарты доступа к данным;
- обеспечивать расширяемость на системном и прикладном уровнях.
Методы индексирования значений временного ряда
Все существующие на данный момент коммерческие системы управления временными рядами предполагают использование индексов только для быстрого позиционирования на записи по отметке времени. Индексирование же самих элементов временного ряда в коммерческих системах не применяется. Это связано тем, что задачи поиска по элементам ряда принципиально отличаются от тех, для которых создавались классические структуры индексов. Разработка методов индексирования значений временного ряда находится пока на уровне исследовательских работ.
ST-индекс
Способ индексированного поиска по элементам временного ряда одним из первых предложила группа исследователей университета штата Мэриленд (США) [3]. Они рассмотрели задачу, часто встречающуюся в техническом анализе. Суть ее сводится к тому, что задается шаблон в виде временного ряда фиксированной длины, а в исходном ряде необходимо найти фрагменты, похожие на шаблон с заданной точностью. Естественно, что в итоге прикладная область применения данной задачи может оказаться гораздо шире.
Для решения задачи «в лоб» необходимо прежде всего установить окно выборки из исходного ряда, равное длине шаблона. Далее — установить окно на начало ряда и, смещая на один элемент, выбирать из него фрагменты. Затем каждый фрагмент следует сравнить с шаблоном. Очевидно, что данная задача весьма трудоемка и ее выполнение требует значительного времени. Поэтому необходимо найти способы оптимизации данного процесса.
В качестве меры, определяющей точность соответствия шаблона и фрагмента ряда, взято евклидово расстояние. Выбор основан на том, что дискретное преобразование Фурье (ДПФ) не изменяет расстояния между рядами. Это следует из теоремы Парсеваля:
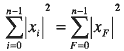
Из свойства линейности ДПФ следует, что сохраняется и евклидово расстояние между рядами:
![]()
Авторы опирались на ряд работ по исследованию спектра временных рядов различных процессов, в том числе поведения основных биржевых показателей. В этих работах было дано заключение о том, что наибольшей энергией обладают несколько первых гармоник ряда Фурье. Таким образом, если рассчитать евклидово расстояние на основе только первых n коэффициентов ДПФ, то оно будет мало отличаться от действительного расстояния между рядами. При этом оно будет меньше либо равно действительному расстоянию между рядами:
![]()
Таким образом, сохранив критерий точности соответствия шаблона и фрагмента ряда и вычисляя евклидово расстояние по первым n коэффициентам Фурье образов шаблона и фрагмента, мы гарантированно не пропустим искомый фрагмент ряда. Конечно, существует возможность ошибочной выборки такого фрагмента, полное расстояние между которым и шаблоном будет больше установленного. Для окончательного ответа необходимо вычислить полное евклидово расстояние между отобранными фрагментами и шаблоном.
Если длина шаблона w меньше количества первых n гармоник, содержащих основную энергию спектра шаблона и ряда, то описанным образом можно отсеять большую часть заведомо неподходящих фрагментов. Это позволит значительно сократить объем вычислений.
Как уже отмечалось, для большого количества процессов можно ограничиться рассмотрением первых двух коэффициентов Фурье. В этом случае данные коэффициенты можно рассматривать как координаты точки на плоскости. Соответственно заданный шаблон вырождается в точку на этой плоскости. Критерий точности ограничивает расстояние между шаблоном и множеством точек, соответствующих фрагментам ряда.
Для увеличения скорости поиска близлежащих точек можно воспользоваться индексом на основе R*-деревьев. Поскольку индекс строится для ряда заранее, то в последующем задача поиска сводится к вычислению первых двух коэффициентов ДПФ у шаблона, к поиску с использованием R*-индекса и точного вычисления евклидова расстояния для отобранных точек. Если точно подсчитанное евклидово расстояние превысит заданную меру для некоторых фрагментов ряда, то эти фрагменты отбрасываются, а остальные являются ответом. Как показано в вышеуказанной публикации, время выполнения поиска по данной технологии многократно сокращается.
IP-индекс
Довольно часто при работе с временными рядами следует решить более простую задачу, чем рассмотренная выше. Необходимо найти, когда наблюдаемая величина принимала заданные значения. На первый взгляд нужно только построить классический индекс на основе B+-дерева и использовать его для поиска.
Однако для временных рядов абсолютных значений ситуация сложнее, чем кажется. В этом случае исходная наблюдаемая величина непрерывна, а во временном ряде регистрируются ее дискретные значения через фиксированные интервалы времени. При использовании индекса на основе B+-дерева будут обнаружены только такие моменты времени, когда наблюдаемая величина была равна искомой в момент наблюдения.
Во многих процессах наблюдаемая величина изменяется непрерывно. В этом случае искомое значение может устанавливаться между моментами наблюдения. Для точного установления момента времени необходимо знать аппроксимирующую функцию. Чтобы не терять общность метода, можно, на занимаясь поиском точного момента времени, свести задачу к установлению двух элементов ряда, на отрезке между которыми было достигнуто искомое значение.
Очевидно, что классические индексы не могут помочь решению этой задачи. Значит, необходимо разработать индекс принципиально новой структуры. И такой индекс был разработан Лингом Линном (Ling Linn) — аспирантом университета Линкепинг в Швеции [4].
Рассмотрим принцип построения этого индекса. В его основе лежит предположение об аппроксимации кривой произвольной неубывающей функцией. Для простоты изображения она на всех рисунках представляется прямой. Обозначим элементы ряда как Si, а отрезки, соединяющие элементы, как Sgi (рис. 1). Значения элементов ряда упорядочим по возрастанию и обозначим элементы новой последовательности ki. Эти элементы образуют новые отрезки [ki, ki+1). С каждым таким отрезком соотнесем список отрезков Sgi, которые пересекают прямые v=ki или v=ki+1. Совокупность отрезков [ki, ki+1) и связанных с ними списков отрезков Sgi и составляет структуру IP-индекса (рис. 2).
Чтобы найти элементы ряда, между которыми наблюдаемая величина принимает искомое значение S0, необходимо выяснить, для какого ki выполняется условие:
![]()
Искомыми интервалами будет список отрезков Sgi, ассоциированный с отрезком [ki, ki+1).
При большом количестве отрезков [ki, ki+1) прямой перебор в случае поиска, какому из них принадлежит заданная величина S0, может занимать много времени. Этот процесс поиска можно ускорить, если применить соответствующий индекс. Ling Linn предложил использовать для построения такого индекса AVL-деревья [4]. Хотя для этой же цели можно использовать и деревья B+ и R*.
Выводы
Расширение спектра задач, решаемых при помощи СУВР, требует реализации всех новых методов вторичного доступа, то есть индексов. Эти методы постоянно совершенствуются, предлагаются новые способы организации индексов. Возникает необходимость наличия у СУВР открытого API для описания вторичных методов доступа, что позволило бы как самому поставщику СУВР, так и конечным пользователям оперативно модифицировать существующие и включать в СУВР новые вторичные методы доступа. Пока еще новые методы построения индексов не нашли своего применения в коммерческих продуктах. Однако потребность в них реально существует, так что их практическая реализация в коммерческих системах остается лишь вопросом времени.
Существующие специализированные системы хранения и анализа временных рядов не предусматривают расширения перечня вторичных методов доступа. На сегодня данная технология отработана в объектно-реляционных СУБД (ОРСУБД). Поэтому именно ОРСУБД могут стать перспективной платформой для построения СУВР.
Проблемы хранения и анализа временных рядов в СУБД
Как уже отмечалось выше, практика показала, что РСУБД не способны в полной мере обеспечить эффективное хранение и обработку временных рядов. Поэтому возникает сложная задача интеграции средств эффективной работы с временными рядами при сохранении всех преимуществ РСУБД. Средства для решения данной проблемы предоставила объектно-реляционная технология.
Использование реляционной модели
При первом рассмотрении не очень ясно, почему РСУБД не могут справиться со столь простой структурой данных, как временной ряд. Ни для кого не секрет, что РСУБД хорошо зарекомендовали себя как основа для построения крупных информационных систем; они с успехом применяются как для задач оперативной обработки информации, так и в системах поддержки принятия решений. Развитая математическая теория, которая лежит в основе логической модели базы данных, хорошо отработанная технология и наличие поддерживаемых промышленных стандартов способствовали широкому распространению РСУБД.
К сожалению, хранение и анализ временных рядов не стали очередной успешной областью применения РСУБД. В лучшем случае РСУБД используют для хранения временных рядов BLOB-поля. При этом ей отводится выполнение только двух операций: сохранить BLOB и извлечь BLOB [2]. В результате мощный и сложнейший инструмент используется как самое примитивное устройство.
Главная причина неэффективной работы РСУБД с временными рядами заключается в плохой совместимости основ реляционной модели и природы временного ряда. Одной из фундаментальных основ реляционной модели является понятие отношения — неупорядоченного множества кортежей [6]. Напротив, принципиальным свойством временного ряда является упорядоченность его элементов.
Некоторые производители РСУБД вводят в свои продукты средства оптимизации работы с упорядоченными последовательностями. Так, широкое распространение получили кластерные индексы. При построении такого индекса записи на диске упорядочиваются в соответствии со значениями ключей индекса. Указанный подход позволяет оптимизировать доступ к данным, но при этом проблемы применения реляционной модели к временным рядам полностью не решаются.
В качестве классического примера рассмотрим ведение торгов ценными бумагами. Предметом анализа является регистрация сделок: время сделки, код ценной бумаги, объем и цена. Согласно всем канонам проектирования реляционных баз данных необходимо создать таблицу очень простой структуры (табл. 1).
Записи появляются в хронологическом порядке, по мере совершения сделок по любой из бумаг. Однако для анализа временного ряда используются данные, относящиеся только к одному объекту (ценной бумаге), и значительно реже производятся манипуляции с несколькими рядами одновременно. Таким образом, из таблицы будут извлекаться записи, относящиеся к одной ценной бумаге, в порядке возрастания или убывания отметок времени сделки.
Проанализируем эффективность доступа к данным в описанной таблице. Длина строки невелика — несколько десятков байт, поэтому в одной странице данных СУБД может помещаться около сотни записей. В большинстве приложений временных рядов одной структуры также около ста. Получается, что при очень грубой оценке для каждого временного ряда записи распределены примерно по одной на каждую страницу дискового пространства. Значит, чтобы выбрать записи, относящиеся к одному временному ряду, необходимо обращаться практически к каждой странице данных. Очень часто на практике размер таблицы значительно превосходит размер буферов СУБД. В этой ситуации почти каждое обращение к элементу временного ряда потребует подкачки новой страницы данных с дисковых накопителей. В таком режиме эффективность индексированного доступа практически равна нулю, поскольку основное время занимают операции ввода-вывода с дисковой подсистемы.
Ситуация может улучшиться в том случае, если необходимо извлечь не весь временной ряд, а только элементы, находящиеся в определенном временном интервале. Тогда индекс помогает ограничить количество извлекаемых страниц данных.
Необходимо обратить внимание на то, что при использовании индексного доступа к элементам временного ряда по аналогичным причинам происходит сканирование значительной части индексного дерева. Здесь удается избежать прохода по всему индексному дереву за счет построения сцепленного индекса по коду ценной бумаги и времени сделки. В таком сцепленном индексе ключи, относящиеся к одному временному ряду, будут локализованы в одном месте дерева. Это позволит последовательно пройти по ключам индекса, относящимся к запрошенному пользователем интервалу времени.
В начале каждого ключа содержится код ценной бумаги, который увеличивает размер индекса, замедляет поиск и (особенно сильно) вставку новых записей. Поэтому индекс, хоть и может помочь при выборке элементов ряда, попадающих в один временной интервал, в целом работает малоэффективно.
Очевидна необходимость выделения записей, относящихся к одному временному ряду, в отдельную область хранения. При использовании классической реляционной структуры это можно сделать только отведя под каждый временной ряд отдельную таблицу. Но тогда для обращения к конкретному временному ряду придется задавать имя таблицы как параметр, то есть придется использовать динамический SQL. Далеко на все инструментальные средства в принципе поддерживают возможность работы с динамическим SQL (например, SQLJ level 0). Кроме того, динамический SQL значительно затрудняет разработку и замедляет выполнение программ. К тому же большое количество таблиц, соответствующее числу временных рядов в базе данных, сильно усложняет администрирование СУБД.
Использование объектно-реляционной модели
Принципиальное отличие объектно-реляционной СУБД от классической РСУБД заключается в поддержке концепции абстрактного типа данных. При этом разработчик имеет возможность описать структуру нового типа данных и переопределить методы для манипулирования этой структурой.
В настоящий момент коммерческие и исследовательские проекты по созданию СУБД, способной эффективно работать с временными рядами, сосредоточены на применении объектно-реляционной технологии. Полученный в последние годы опыт эксплуатации коммерческих продуктов, использующих объектно-реляционную технологию, подтверждает перспективность данного направления.
Первым на рынке коммерческих продуктов, использующих объектно-реляционную технологию, появился модуль Time Series DataBlade компании Illustra. Он был призван дополнить возможности одноименной объектно-реляционной СУБД средствами работы с временными рядами.
Данный модуль определял в объектно-реляционной СУБД новый тип данных — TimeSeries. После этого в таблицах стало возможным создание колонок нового типа. Так, если вернуться к рассмотренному ранее примеру (см. табл. 1), то структура таблицы примет иной вид (табл. 2).
Будет нерационально физически размещать длинный временной ряд вместе с обычными полями таблицы. Поэтому для хранения временных рядов на дисковом пространстве сервера выделяется отельная область. В результате логическая модель временного ряда принимает вид, на рис. 3.
Примечательно, что большинство методов анализа временных рядов разработано для регулярных временных рядов. В таких рядах интервал между наблюдениями фиксирован. Если исходный наблюдаемый процесс порождает нерегулярный временной ряд, то на его основе строится набор регулярных рядов с различными интервалами, которые впоследствии анализируются.
Фиксированный интервал между наблюдениями позволяет оптимизировать физическую модель хранения временного ряда. При этом отметки времени могут быть заменены целочисленным индексом — номером наблюдения. Задав момент начала наблюдения и интервал между наблюдениями, можно элементарным способом определить преобразование целочисленного индекса в отметку времени и обратно. Поддерживая расположение элементов временного ряда в хронологической последовательности, можно на основе целочисленного индекса однозначно определить положение любого элемента. В результате для регулярного временного ряда вообще отпадает необходимость поддерживать индекс по отметкам времени. Концепция абстрактного типа данных позволяет скрыть от пользователя все манипуляции. Внутренние механизмы становятся абсолютно прозрачным для пользователя.
Следует отметить, что во многих случаях целочисленный индекс занимает меньше места при хранении на диске, чем полная отметка времени. В результате на диске временной ряд хранится в очень компактном виде, что повышает скорость доступа к данным. Даже в случае нерегулярного ряда такая модель имеет преимущество перед классической реляционной моделью, поскольку отпадает необходимость сохранять идентификатор временного ряда с каждым его элементом.
Выводы
Применение концепции абстрактного типа данных позволяет определить логическую и физическую модели хранения временного ряда, обладающую следующими преимуществами по сравнению с классической реляционной моделью:
- простая логическая модель;
- компактный формат хранения;
- быстрый метод доступа к элементам регулярного ряда.
Informix TimeSeries DataBlade как пример коммерческого продукта
После приобретения компании Illustra владельцем продукта TimeSeries DataBlade стала компания Informix. Для интеграции с новым объектно-реляционным сервером Informix модуль TimeSeries был переписан, полностью сохранив логическую модель временного ряда и во многом позаимствовав принципы физической модели.
Физическая и логическая модели временного ряда
Для хранения временных рядов большого размера на дисковом пространстве сервера выделяется раздел, называемый контейнером. При создании в таблице колонки типа TimeSeries устанавливается размер временного ряда, который может храниться вместе с другими полями таблицы. Обычно этот размер составляет несколько килобайт. Если временной ряд превышает этот размер, то будет храниться в контейнере.
По своей структуре контейнер мало чем отличается от пространства, выделяемого для хранения обычной таблицы. При его создании описывается структура элементов временного ряда, которые будут в нем храниться. Временные ряды, принадлежащие одной таблице, могут располагаться в различных контейнерах. Одновременно с этим в самом контейнере могут располагаться временные ряды, принадлежащие различным таблицам.
В контейнере для каждого временного ряда по возможности отводится непрерывная область дискового пространства. Внутри этой области элементы хранятся упорядоченно, в хронологической последовательности. Порядок поддерживается даже при изменении отметки времени.
Для повышения эффективности при создании временного ряда можно указать, является ли он регулярным или нерегулярным. Также при создании контейнера устанавливается, какой из этих типов рядов будет храниться в контейнере. У регулярного ряда вместо отметки времени сохраняется величина его смещения от начала, которая кодируется четырехбайтовым числом (для сравнения: полная отметка времени кодируется восьмибайтовым числом). В случае регулярного ряда можно быстро вычислить точное местоположение записи по величине смещения. За счет этого существенно повышается скорость работы с регулярными временными рядами, поскольку для позиционирования в нерегулярном временном ряде используется индекс по отметкам времени.
Календарь
Значительную часть анализируемых при помощи временных рядов процессов можно назвать регулярными только с определенной оговоркой. Дело в том, что процесс не протекает непрерывно, а имеет паузы. Примером могут служить торги на бирже, которые, как правило, ведутся только в рабочие часы по будним дням.
Подобные временные ряды можно приводить к регулярным за счет исключения из рассмотрения периодов времени, когда торги не ведутся. В этом случае можно описывать регулярные ряды цен с интервалом наблюдений пять, десять минут и т.д. Обычно такое приведение возможно при выборе календаря, который определяет периоды протекания процесса.
Календарь может быть использован и для работы с нерегулярными рядами, у которых интервалы наблюдений в принципе непостоянны. В данной ситуации календарь выполняет функцию контроля вносимых значений и не допускает внесения измерений, относящихся к периодам паузы в наблюдаемом процессе. Кроме того, календарь может быть использован для приведения нерегулярного временного ряда к регулярному.
В TimeSeries DataBlade календарь определяется по двум компонентам из шаблона Pattern и по собственно календарю Calendar. Шаблон описывает периодичность протекания процесса. При обычной пятидневной рабочей неделе шаблон описывается следующим образом:
INSERT INTO CalendarPatterns VALUES(‘working_week’, ‘{5 on, 2off}, day’)
Здесь working_week — имя шаблона; day — указывает единицу времени, то есть день; {5 on, 2off} — говорит о том, что 5 дней процесс протекает, а последующие 2 дня его нет. На основе шаблона определяется календарь. Для этого необходимо задать имя календаря, дату начала отсчета, начало отсчета шаблона и имя шаблона:
INSERT INTO CalendarTable(c_name,c_calendar) VALUES( ‘start2000’, ‘startdate(2000-01-01 00:00:00.00000), pattstart(2000-01-03 00:00:00.00000), pattname(working_week)’)
Теперь сформированный календарь с именем start2000 может быть использован для работы как с регулярными, так и с нерегулярными временными рядами.
Скользящие функции
В стандартный комплект поставки TimeSeries DataBlade включен набор встроенных функций для анализа временных рядов. Эти встроенные функции написаны на языке С, что обеспечивает высокую скорость их исполнения. Вот пример вызова скользящей функции для построения «свечного графика»:
SELECT AggregateBy( ‘MAX($price), MIN($price), FIRST($price), LAST($price)’, “start2000”, stock_ts )::TimeSeries(candle_t) FROM trade_ts WHERE stock_id=”some_code”
При помощи этого оператора вычисляются максимальная и минимальная цены, а также первая и последние цены за период. Период определяется календарем start2000 и равен одному дню.
Специфика анализа временных рядов заключается в огромном перечне используемых функций. В целях расширения стандартного набора функций, входящих в комплект поставки, модуль TimeSeries обладает открытым интерфейсом, который позволяет пользователям определять новые функции. В качестве средств описания новых функций могут использоваться языки С или Java. Кроме того, компания Informix поставляет модуль NAG DataBlade, включающий в себя большое количество аналитических функций, реализованных по алгоритмам компании NAG.
Выводы
TimeSeries DataBlade позволяет решить основные проблемы, стоящие перед современными СУВР, обеспечивая:
- эффективное хранение и обработку временных рядов;
- масштабируемость на уровне РСУБД;
- поддержку промышленных стандартов доступа к данным SQL, ODBC, JDBC;
- расширяемость на системном и прикладном уровнях.
Заключение
Развитие объектно-реляционной технологии предоставило промышленным РСУБД возможность проникнуть в очередную, прежде закрытую для них сферу — обработку временных рядов. Это не только позволяет достичь возможностей, доступных ранее только специализированным системам, но и открывает новые перспективы для данной прикладной области.
Список литературы
- Лугачев М. Методы социально-экономического прогнозирования, http://www.dei.econ.msu.ru/books/prognoz/, 1996.
- Dreyer W., Kotz Dittrich A., Schmidt D. Research Perspectives for Time Series Management Systems, SIGMOD Record, Vol. 23 No. 1, 1994.
- faloutsos C., Ranganathan M., Manolopoulos Y. Fast Subsequence Matching in Time-Series Databases. In Proc. of the ACM SIGMOD Conference on Management of Data, 1994
- Ling L., Risch T. Using a Sequencial in Terrain-aided Navigation. In Preceedings of 6th International Conference on Information and Knowledge Management, Las Vegas, Nevada, Nov. 1997.
- Адельсон-Вельский Г.М., Ландис Е.М. Доклады Академии Наук СССР, 1962. С. 146, 263-266.
- Дейт К. Введение в системы баз данных, Киев—Москва: Диалектика, 1998. С. 90.
КомпьютерПресс 6'2001








