Интеллектуальные агенты семантического Web’а
 редположим,
что ваш приятель рассказал вам о недавно прочитанном новом научно-фантастическом
романе, который ему очень понравился. Вы заинтересовались его рассказом, потому
что тоже увлекаетесь фантастикой, и сами захотели прочитать это произведение.
Приняв такое решение, вы сообщаете специальной программе — вашему персональному
интеллектуальному агенту — о том, что хотите купить книгу такого-то автора и
с таким-то названием, причем желательно того же издательства, что и у вашего
приятеля. При этом вы хотели бы, по возможности, приобрести ее в книжном магазине,
расположенном недалеко от того места, где вы живете или работаете. Ваш агент
находит и просматривает список книжных магазинов города, проверяет, в каких
из них есть такая книга, и следит, чтобы ее цена не превышала среднюю цену в
других магазинах. После этого отбираются магазины, которые находятся на пути
вашего следования из дома на работу. Вы выбираете один из них и при этом хотите
убедиться, что вам удобно будет до него добраться и что там есть нужная книга.
Агент открывает для вас две страницы сайта магазина: со схемой проезда и с информацией,
где указано, что книга, которую вы ищете, входит в ассортимент магазина и сейчас
имеется в наличии. Сверяясь со своими планами на неделю, вы решаете, когда поедете
за покупкой. Затем агент делает соответствующую запись в вашем персональном
еженедельнике, чтобы вы не забыли о своих планах. В итоге на поиск нужной книги
у вас уйдет от силы несколько минут. При этом вы не будете ни искать подходящие
магазины, ни проверять, есть ли нужная вам книга в продаже, ни еще раз перезванивать,
чтобы убедиться в этом.
редположим,
что ваш приятель рассказал вам о недавно прочитанном новом научно-фантастическом
романе, который ему очень понравился. Вы заинтересовались его рассказом, потому
что тоже увлекаетесь фантастикой, и сами захотели прочитать это произведение.
Приняв такое решение, вы сообщаете специальной программе — вашему персональному
интеллектуальному агенту — о том, что хотите купить книгу такого-то автора и
с таким-то названием, причем желательно того же издательства, что и у вашего
приятеля. При этом вы хотели бы, по возможности, приобрести ее в книжном магазине,
расположенном недалеко от того места, где вы живете или работаете. Ваш агент
находит и просматривает список книжных магазинов города, проверяет, в каких
из них есть такая книга, и следит, чтобы ее цена не превышала среднюю цену в
других магазинах. После этого отбираются магазины, которые находятся на пути
вашего следования из дома на работу. Вы выбираете один из них и при этом хотите
убедиться, что вам удобно будет до него добраться и что там есть нужная книга.
Агент открывает для вас две страницы сайта магазина: со схемой проезда и с информацией,
где указано, что книга, которую вы ищете, входит в ассортимент магазина и сейчас
имеется в наличии. Сверяясь со своими планами на неделю, вы решаете, когда поедете
за покупкой. Затем агент делает соответствующую запись в вашем персональном
еженедельнике, чтобы вы не забыли о своих планах. В итоге на поиск нужной книги
у вас уйдет от силы несколько минут. При этом вы не будете ни искать подходящие
магазины, ни проверять, есть ли нужная вам книга в продаже, ни еще раз перезванивать,
чтобы убедиться в этом.
Приведенный пример (рис. 1) — всего лишь один вариант использования тех возможностей, которые будут доступны в новой семантической сети, должной прийти на смену современной сети World Wide Web, концепция и принципы работы которой практически не менялись с момента ее появления и уже в некоторой степени сдерживают развитие Интернета. Благодаря семантическому Web’у с информацией, опубликованной в Интернете, можно будет работать на совершенно ином уровне. И если сейчас в большинстве случаев для анализа информации, представленной на страницах различных сайтов, необходим человек (поскольку достижения в области искусственного интеллекта пока еще не позволяют программам полностью понимать даже текстовую информацию), то в семантической сети информация перестанет быть просто данными, а превратится в знания, которые смогут использовать как люди, так и различные программы. Таким образом, программные агенты не только будут работать с уже существующими знаниями при решении поставленных перед ними задач, но и смогут получать из семантических сетей новые знания.
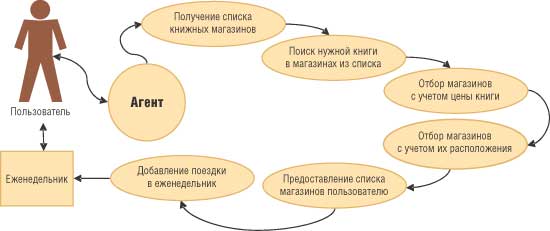
Рис. 1. Поиск нужной книги в книжных магазинах города с использованием персонального интеллектуального агента и семантической сети
Проблемы World Wide Web
оявление
World Wide Web сделало Интернет одним из важнейших и крупнейших источников информации,
но проблема заключалась в распределенном характере Сети, что сильно затрудняло
поиск нужной информации среди массы разнообразных материалов, охватывающих самые
разные сферы человеческой деятельности. Поэтому практически с самого зарождения
Интернета были разработаны и запущены так называемые поисковые машины. До появления
WWW они индексировали и позволяли искать в основном содержимое сети FTP-серверов,
через которую пользователи могли обмениваться файлами, но с появлением HTML
они быстро переключились на Web-сайты.
С расширением WWW работа поисковых систем все более усложнялась: чтобы обеспечить достаточный охват, им приходилось индексировать и обрабатывать все больший объем информации. Но главная сложность заключалась даже не в увеличении количества индексируемых сайтов, а в том, чтобы обеспечить релевантные ответы на поисковые запросы пользователей, то есть выдавать пользователям ссылки на те ресурсы, которые, по их мнению, соответствуют тому, что они искали.
В соответствии со своей первоначальной концепцией WWW была средой, в значительной степени ориентированной на участие людей. Когда со временем возникла необходимость в обработке Web-контента различными роботами, в частности индексирующими модулями поисковых систем, то стало понятно, что интерпретировать информацию так же качественно, как человек, программы не могут. Конечно, отдельные достижения в области искусственного интеллекта были сделаны, но на практике внедрить большую их часть в поисковые системы оказалось невозможным. Таким образом, поисковикам оставалось только строить предположения о том, где, например, на странице у статьи расположен заголовок, которому надо придать больший вес, чем остальному тексту, а где находится навигация сайта, которую индексировать вовсе не следует. И даже если внутри сайта, например в базе данных, информация хранилась в структурированном виде, то выдавалась она уже в качестве текстовой информации, при этом значительная часть информации о связях между различными элементами данных терялась.
Поисковые системы используют ряд технических приемов, которые позволяют поддерживать качество поиска на соответствующем уровне, когда пользователь, как правило, все-таки может найти то, что он искал, если очень постарается. В основном эти приемы связаны с сортировкой результатов поиска и с ускорением индексирования новых или меняющихся страниц. Среди них — различные алгоритмы, определяющие авторитетность ресурсов (например, PageRank), использование данных о посещаемости и получение информации о новых страницах с помощью специальных счетчиков (как, например, в Rambler’s Top100), получение информации о сайтах из тематических каталогов для точного определения тематики ресурса (так, в частности, делает Яндекс). Но, несмотря на все эти меры, многие пользователи не удовлетворены работой современных поисковых систем.
Исправить сложившуюся ситуацию должна семантическая сеть — следующий эволюционный этап WWW, на котором вся информация, опубликованная в Интернете, в обязательном порядке должна содержать метаданные, то есть данные о данных, позволяющие понять смысл и назначение той или иной информации, а также связь между отдельными ее составляющими. Проще говоря, семантика означает смысловую нагрузку.
Семантическая сеть
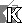 онцепцию
семантической сети (Semantic Web) как новой формы представления Web-контента
председатель W3C Тим Бернерс-Ли представил в 2001 году, выступив на Восьмой
конференции консорциума W3C и опубликовав соответствующий трактат в журнале
Scientific American (рис. 2). Он подробно описал преимущества новой формы представления
информации в WWW, которая предусматривает максимальную степень классификации
любой информации, делая совместную работу людей и машин на порядок более эффективной.
Главное отличие Semantic Web от Web состоит в том, что каждая страница семантической
сети содержит информацию на двух языках: на обычном, понятном человеку и показываемом
браузером, и на специальном, информация на котором скрыта от человеческих глаз,
но понятна интеллектуальным программам-агентам, роботам. Этот специальный язык
описывает представленный на странице материал с помощью тэгов и атрибутов, понятных
машинам.
онцепцию
семантической сети (Semantic Web) как новой формы представления Web-контента
председатель W3C Тим Бернерс-Ли представил в 2001 году, выступив на Восьмой
конференции консорциума W3C и опубликовав соответствующий трактат в журнале
Scientific American (рис. 2). Он подробно описал преимущества новой формы представления
информации в WWW, которая предусматривает максимальную степень классификации
любой информации, делая совместную работу людей и машин на порядок более эффективной.
Главное отличие Semantic Web от Web состоит в том, что каждая страница семантической
сети содержит информацию на двух языках: на обычном, понятном человеку и показываемом
браузером, и на специальном, информация на котором скрыта от человеческих глаз,
но понятна интеллектуальным программам-агентам, роботам. Этот специальный язык
описывает представленный на странице материал с помощью тэгов и атрибутов, понятных
машинам.
Рис. 2. Архитектура семантической сети, представленная в докладе
Тимоти Бернерс-Ли
«Semantic Web — XML2000» (http://www.w3.org/2000/Talks/1206-xml2k-tbl/)
В основе семантической сети лежат три принципа: агрегация, безопасность и логика. Агрегация означает совместное использование данных. Подобно тому, как гипертекст является неотъемлемой частью WWW и благодаря ему «всё можно связать со всем», в Semantic Web при решении поставленной задачи могут быть использованы любые данные. Для этих данных будет создана соответствующая семантическая информация (онтологии), позволяющая использовать их надлежащим образом. В основу безопасности, обеспечивающей доверие к семантической сети, положены цифровые подписи, которые могут использоваться агентами и компьютерами для проверки того, что информация получена из достоверного источника, например от какого-то публичного сервиса или персонального агента другого доверенного пользователя. Логика — это набор правил описания информационной структуры данных, протоколы и язык описания страниц. Именно логика дает семантической сети правила вывода для проведения рассуждений и методики выбора тактик выполнения операций с данными, чтобы получить ответы на вопросы.
Онтологии
 нтологии
(от гр. on (ontos) — сущее) составляют фундамент семантической сети и представляют
собой описание на некотором формальном языке понятий некоторой предметной области
и отношений между ними. Онтологии во многом похожи на тезаурусы и таксономии,
но на самом деле шире их, поскольку предоставляют дополнительные средства для
описания структуры описываемых данных. Поскольку по своей сути онтологии — это
информация об информации, то они являются метаданными.
нтологии
(от гр. on (ontos) — сущее) составляют фундамент семантической сети и представляют
собой описание на некотором формальном языке понятий некоторой предметной области
и отношений между ними. Онтологии во многом похожи на тезаурусы и таксономии,
но на самом деле шире их, поскольку предоставляют дополнительные средства для
описания структуры описываемых данных. Поскольку по своей сути онтологии — это
информация об информации, то они являются метаданными.
Онтологии разрабатываются и могут быть использованы при решении различных задач, в том числе для совместного применения людьми или программными агентами, для возможности накопления и повторного использования знаний в предметной области, для создания моделей и программ, оперирующих онтологиями, а не жестко заданными структурами данных, для анализа знаний в предметной области.
В центре большинства онтологий находятся классы, каждый из которых может иметь подклассы, представляющие собой более точные понятия, чем исходный класс. Все классы онтологии выстраиваются в одну или несколько иерархий и описывают понятия предметной области. При этом классы могут содержать атрибуты, которые описывают свойства и внутреннюю структуру понятий, лежащих в основе классов. Все подклассы наследуют атрибуты родительских классов. Каждый атрибут класса помимо названия имеет тип значения, разрешенные значения, число значений (мощность). Тип значения атрибута описывает, какие типы значений может содержать атрибут, например строку или целое число. Существует также ограничение значения атрибута, состоящее в том, что он может принимать только определенные классы или экземпляры определенных классов. Разрешенные значения атрибута устанавливают ограничения на атрибут, но уже в рамках его типа, например заданный диапазон целых чисел. Мощность атрибута определяет, сколько значений он может иметь: только одно значение — это единичная мощность или любое число значений — множественная мощность. Онтология может включать и экземпляры классов, то есть такие классы, в которых установлены значения всех их атрибутов. Считается, что онтология вместе с набором индивидуальных экземпляров классов образует базу знаний, хотя на самом деле трудно определить, где кончается онтология и где уже начинается база знаний.
Для того чтобы лучше понять, как устроены онтологии, рассмотрим пример онтологии издательства, выпускающего книги и журналы. Основными понятиями этой предметной области являются: издательство, книга и журнал, и именно они и будут классами в нашей онтологии (в скобках указаны типы значений и разрешенные значения).
Класс «издательство» имеет следующие атрибуты:
• название (строка);
• город (строка).
Класс «книга» имеет следующие атрибуты:
• название (строка);
• автор (строка);
• ISBN (строка специального формата);
• число страниц (натуральное число);
• тип обложки (строка; возможные значения: мягкая, твердая, суперобложка);
• издательство (экземпляр класса «издатель»);
• год издания (натуральное число — четыре цифры);
• описание (текст);
• цена (число с плавающей точкой — два знака после запятой).
Класс «журнал» имеет следующие атрибуты:
• название (строка);
• ISSN (строка специального формата);
• число страниц (натуральное число);
• издательство (экземпляр класса «издатель»);
• год выпуска (натуральное число — четыре цифры);
• номер (натуральное число);
• описание (текст);
• цена (число с плавающей точкой — два знака после запятой).
Поскольку классы «книга» и «журнал» имеют много общих атрибутов (полей), имеет смысл вынести их в отдельный класс под названием «печатная продукция». В результате мы получаем в этой онтологии два дерева классов: первое состоит из единственного класса «издательство», а второе — из класса «печатная продукция» и двух его подклассов — «книга» и «журнал». На рис. 3 представлены классы рассматриваемой нами онтологии, экземпляры классов и отношения между ними: черным обозначены классы, синим — экземпляры; прямые связи обозначают атрибуты и внутренние связи, такие как «подкласс» и «экземпляр класса».
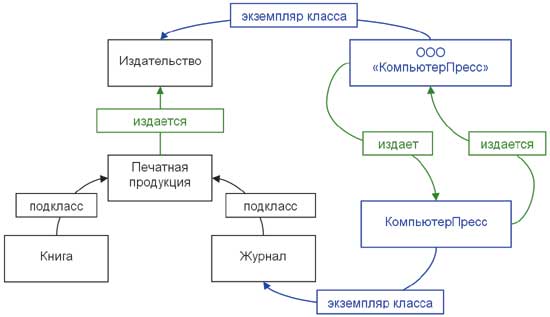
Рис. 3. Фрагмент онтологии издательства с классами и экземплярами классов
Логические правила вывода при работе с онтологиями дают возможность манипулировать понятиями и данными гораздо эффективнее, позволяя извлекать новые знания. В данной онтологии издательства в качестве примера можно привести следующее правило вывода: если существует книга, изданная в некотором году, то издательство, ее выпустившее, работает как минимум с этого года. И если для человека это кажется очевидным, то для программы-агента смысл значения года, с которого издательство выпускает печатную продукцию, выявляется только после того, как мы создали правило, устанавливающее зависимость.
Процесс разработки онтологии обычно начинается с того, что составляется глоссарий терминов (понятий), который в дальнейшем используется для исследования свойств и характеристик представленных в нем терминов. Далее на естественном языке создается список точных определений терминов, представленных в глоссарии. Затем на основе таксономических отношений строятся деревья классификации понятий (иерархии классов), которых в онтологии может быть несколько. Из понятий, не задействованных при составлении деревьев классификации, выделяются атрибуты классов и их возможные значения. Именно эти понятия и устанавливают основные связи между классами. После этого в зависимости от целей, для которых разрабатывается онтология, в нее могут добавляться экземпляры классов. И на последнем этапе эксперты по той предметной области, в которой разрабатывается онтология, создают правила логических выводов, позволяющие оперировать данными, представленными в онтологии, и извлекать из созданной онтологии новые знания.
Разработка онтологий во многом напоминает проектирование классов в объектно-ориентированном программировании, однако есть и ряд существенных отличий. В объектно-ориентированном программировании программист принимает решения, связанные с проектированием, ориентируясь в основном на методы классов, тогда как разработчик онтологии принимает эти решения на основе структурных свойств классов. В результате структура класса и отношения между классами в онтологии отличаются от структуры той же предметной области в объектно-ориентированной программе.
Для описания онтологий используются различные формальные языки, которые можно разделить на две группы. В первую входят традиционные языки описания онтологий: Interlinguas, CycL; языки, основанные на дескриптивных логиках (такие, как LOOM), и языки, основанные на фреймах (OKBC, OCML, Flogic). Вторая группа — языки, основанные на Web-стандартах: XOL, UPML, SHOE, RDF с RDFS, DAML, OIL, OWL, созданные специально для использования онтологий в WWW. Различия между языками заключаются в их возможностях по описанию предметной области и в некоторых возможностях механизма логического вывода для этих языков.
Язык RDF (Resource Description Framework) разработан консорциумом W3C для описания метаданных в семантической сети. Он предназначен для описания отношений между ресурсами и должен стать одним из составляющих фундамента семантической сети. RDF является подмножеством языка XML и имеет специальный язык RDF Schema для описания структуры документов. Спецификация RDF очень проста: здесь все отношения между ресурсами определяются как триады «объект — атрибут — значение». Например, «книга издается издательством»: в роли объекта выступает «книга», в роли атрибута — «издается», а «издательство» является значением атрибута. Объект и атрибут обязательно представляются как URI (Uniform Resource Identifier), а значение может быть записано либо в виде URI, либо в виде текста. Частным случаем URI является URL (Uniform Resource Locator) вместе с «якорем», указывающим объект на Web-странице, но, в отличие от него, URI не обязательно должен указывать адрес объекта в Сети. Таким образом, RDF является самым низкоуровневым из существующих языков описания метаданных, поскольку оперирует лишь понятиями связей примитивных сущностей.
Первыми предложениями по описанию онтологий на базе RDFS были European Commission OIL (Ontology Inference Layer) и DARPA DAML-ONT (DARPA Agent Markup Language). Язык OIL был основан на описательной логике (Description Logics), позволяющей описывать классы через наборы свойств, которым должны удовлетворять объекты, относящиеся к понятию, и наборы логических операторов (конъюнкция, дизъюнкция, отрицание и различные виды ролевых кванторов). DAML обеспечивал примитивы для объявления пересечений, объединений, дополнений классов и т.д. Еще одним расширением RDFS стал DRDFS, который, как и OIL, давал возможность для выражения классов и определения свойств, однако выразительная мощность языков DRDFS и OIL такова, что ни один из них не мог рассматриваться как фрагмент другого.
На базе языков DAML и OIL возникло совместное решение — DAML+OIL, вобравшее в себя всё лучше, что было в обоих языках, и по этой причине выбранное специалистами консорциума W3C в качестве базы для построения нового языка онтологий, когда средств XML и RDF оказалось недостаточно для представления информации и метаданных для построения полноценной семантически связанной сети. Новый язык получил название OWL (Web Ontology Language), и именно ему, по мнению консорциума, была уготована главенствующая роль в семантической сети. 10 февраля этого года консорциум W3C присвоил OWL статус рекомендованной к реализации технологии. Эта дата и была названа некоторыми специалистами официальным днем рождения семантической сети.
Интеллектуальные агенты
 ажнейшую
роль в семантической сети должны играть специальные программы — интеллектуальные
агенты, в задачу которых входит работа с информацией, представленной в семантической
сети. Агенты по заданиям пользователей будут находить источники информации,
запрашивать данные, сопоставлять и проверять их на соответствие критериям поиска,
а затем выдавать ответ в удобной для пользователей форме. При необходимости
агенты смогут осуществлять не только поиск информации, но и другие действия,
в частности заказывать билеты или вносить записи о планируемых мероприятиях
в персональный еженедельник.
ажнейшую
роль в семантической сети должны играть специальные программы — интеллектуальные
агенты, в задачу которых входит работа с информацией, представленной в семантической
сети. Агенты по заданиям пользователей будут находить источники информации,
запрашивать данные, сопоставлять и проверять их на соответствие критериям поиска,
а затем выдавать ответ в удобной для пользователей форме. При необходимости
агенты смогут осуществлять не только поиск информации, но и другие действия,
в частности заказывать билеты или вносить записи о планируемых мероприятиях
в персональный еженедельник.
Чтобы эффективно решать задачи, поставленные пользователем перед своим персональным интеллектуальным агентом, последний должен обладать некоторой информацией о пользователе, например знать его интересы, пристрастия, расписание, личные контакты, иметь сведения о тех информационных источниках, которые обычно используются. В противном случае агент не сможет автоматически отфильтровать интересные для пользователя материалы, понять, к какой области знаний относится по умолчанию введенное им в поиске слово, если оно имеет несколько значений, или найти в расписании свободное время для какого-то мероприятия. Если пользователь захочет убедиться, было ли найденное решение правильным, агент представит ему цепочку своих «рассуждений», построенную для того, чтобы получить результат, назовет используемые источники данных и укажет на степень их достоверности, основанную на цифровых сертификатах.
В роли агентов в семантической сети будут выступать не только персональные агенты, но и различные Web-сервисы, с которыми те будут взаимодействовать. Если при обращении к такому сервису с запросом не найдется нужной информации или какой-то ее части, но будут известны дополнительные источники, то сервис сможет обратиться к последним за помощью с необходимым подзапросом. Передаваясь таким образом от сервиса к сервису, первоначальный запрос будет обрастать необходимой информацией — до тех пор, пока сервис, к которому обратился агент, не вернет полный ответ с найденным решением или не сообщит о неудаче. По такой схеме будет возможна и работа поисковых систем, переправляющих запрос одному или нескольким специализированным сайтам в зависимости от тематики запроса. На практике будут использоваться оба подхода: и когда агент самостоятельно собирает в семантической сети информацию, необходимую для решения задачи, и когда он обращается к специальным сервисам, способным получать эту информацию из других источников (рис. 4).
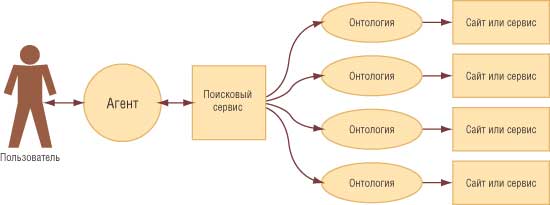
Рис. 4. Поиск нужной информации через поисковый сервис, работающий с семантической сетью
Агенты будут способны обмениваться между собой не только информацией и правилами логических выводов, используемых в онтологиях, но и цепочками построенных ими рассуждений, чтобы пользователь мог при необходимости проверить результат либо чтобы на основании уже собранной информации другой агент попробовал найти более оптимальное решение или уточнить какие-то условия первоначального запроса. В определенных ситуациях для решения поставленной задачи может потребоваться и передача одним персональным агентом другому агенту некоторой личной информации пользователя (рис. 5). Например, если вы пытаетесь договориться о встрече со своим знакомым, то легче вашему агенту передать другому агенту информацию, когда вы на следующей неделе будете точно заняты, чем если вы сами попытаетесь угадать, кто и когда будет свободен. Конечно, обмен любой важной или конфиденциальной информацией между агентами будет осуществляться только с согласия пользователя и при проверке «личностей» агентов посредством цифровых подписей с последующим шифрованием конфиденциальной информации. Это позволит людям без боязни осуществлять с помощью семантической сети такие важные дела, как денежные переводы, бронирование билетов или передача личной информации.
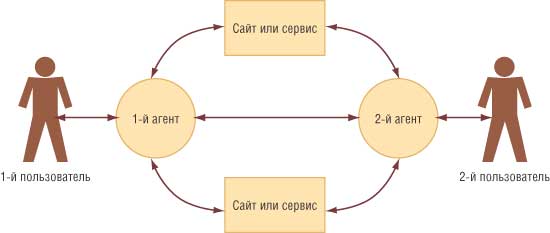
Рис. 5. Взаимодействие агентов двух пользователей и использование ими для получения необходимых данных других сайтов или сервисов
На пути к новому Web’у
 емантическая
сеть должна стать надстройкой над WWW. С ее помощью станет возможным создание
новых сервисов, которые технически невозможны при нынешних принципах организации
и работы Сети. Прежде всего, семантический Web превратит информацию, опубликованную
в Сети, в структурированные знания, с которыми смогут работать специальные интеллектуальные
агенты и различные сервисы, взаимодействующие между собой и оперирующие понятиями
соответствующих предметных областей. Цепочки логических рассуждений, осуществляемые
агентами, позволят получать информацию, представленную в Сети, в разрозненном
виде, то есть из разных информационных источников.
емантическая
сеть должна стать надстройкой над WWW. С ее помощью станет возможным создание
новых сервисов, которые технически невозможны при нынешних принципах организации
и работы Сети. Прежде всего, семантический Web превратит информацию, опубликованную
в Сети, в структурированные знания, с которыми смогут работать специальные интеллектуальные
агенты и различные сервисы, взаимодействующие между собой и оперирующие понятиями
соответствующих предметных областей. Цепочки логических рассуждений, осуществляемые
агентами, позволят получать информацию, представленную в Сети, в разрозненном
виде, то есть из разных информационных источников.
Изменения должны коснуться и работы поисковых систем. Посредством онтологий, используемых в семантической сети, они смогут в некоторой степени решить проблему качества поиска информации в Интернете. Внедрение семантического Web’а будет происходить постепенно — по мере того, как все больше разработчиков сайтов и сервисов, а также пользователей будут осознавать преимущества и перспективы Semantic Web. Однако нельзя утверждать, что со временем вся информация, представленная в WWW, будет иметь семантическую составляющую, поэтому поисковые системы не смогут совсем отказаться от механизмов индексации информации, используемых ими в настоящее время. В дополнение к поисковым движкам (search engine) поисковые системы обзаведутся специальными логическими движками (logical engine), предназначенными для поиска и обработки информации в семантической сети. Комбинация этих двух поисковых механизмов позволит поднять качество и точность поиска в Сети на совершено иной уровень (рис. 6).
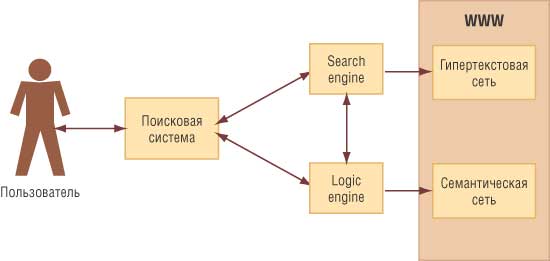
Рис. 6. Принцип работы поисковой системы, использующей поисковый и логический модули
Кроме того, должны развиться надежные и удобные механизмы получения источников информации для интеллектуальных агентов, с которых они могут начинать строить свои цепочки рассуждений. Например, когда ваш персональный агент ищет тот самый фантастический роман по вашему заданию, то ему нужен список книжных магазинов города, причем этот список должен быть максимально точным и получен из авторитетного источника с удостоверяющим его цифровым сертификатом. Вряд ли подобные сервисы возникнут на пустом месте — на их поддержку потребуются значительные ресурсы. Скорее всего, существующие в настоящее время модерируемые каталоги со временем трансформируются или дополнительно будут поддерживать подобные сервисы.
По всем расчетам, переход к семантической сети не будет ни простым, ни быстрым. Работы начались еще в 1998 году, а официальная рекомендация OWL консорциумом W3C в качестве основного языка для описания онтологий была представлена только в феврале этого года. Немало специалистов считают, что семантический Web — это утопия, и с ними можно частично согласиться, поскольку его внедрение требует немалых усилий от различных категорий разработчиков и пользователей, включая разработчиков крупных информационных порталов, поисковых систем, каталогов и небольших сайтов, а также от разработчиков интеллектуальных программ-агентов.
Чтобы разработчики сайтов начали повсеместно внедрять поддержку онтологий в свои ресурсы, у них должен быть стимул, то есть использование онтологий должно давать их сайту некоторые преимущества, например увеличение числа переходов с поисковиков или увеличение числа пользователей за счет предоставления дополнительных сервисов и т.п. Необходимы мощные и гибкие программы-агенты, которые смогут полноценно использовать возможности семантического Web’а. Но их активная разработка начнется только тогда, когда у пользователей появится реальная необходимость в них. Чтобы ускорить этот процесс и собственно процедуру внедрения семантической сети, необходимо начать с поддержки онтологий в крупных поисковых системах и различных сервисах — на первом этапе этого будет вполне достаточно. Если сервис или поисковая система будет давать ощутимый приток посетителей тем сайтам, которые предоставляют информацию, предназначенную для семантической сети, то это будет способствовать распространению новой сети.
Пройдет несколько лет, и мы получим совершенно другой Интернет, в который так трудно поверить сегодня. Открываемые им возможности позволят перейти на новый уровень использования и обработки информации, опубликованной в Сети. Альтернатива внедрению семантического Web’а сегодня только одна — дальнейшее ухудшение качества поиска, невозможность совершенствования механизмов обработки информации, продолжение участия человека в интерпретации данных в WWW, а также другие проблемы, описанные в этой статье. Вряд ли кому-то эта альтернатива покажется более привлекательной.








