Средства бизнес-анализа в SQL Server 2005
Часть 6. Анализ временных рядов
Алгоритм Microsoft Time Series
Просмотр результатов обучения модели
В предыдущей статье данного цикла (см. КомпьютерПресс № 8’2006) мы рассмотрели основные шаги, которые обычно выполняются при построении моделей Data Mining, такие как создание структуры, обучение модели, визуальный просмотр результатов обучения, оценка точности моделей, выполнение прогнозов. Мы также обсудили применение алгоритмов Microsoft Decision Trees и Microsoft Clustering, доступных и в предыдущей версии SQL Server, а также байесового алгоритма. Поскольку число алгоритмов, доступных в указанной версии SQL Server, ими не ограничивается, мы продолжим обсуждение алгоритмов Data Mining, впервые появившихся в этой версии. Настоящая статья посвящена анализу временных рядов — технологии, которая применяется для осуществления прогнозов данных, изменяющихся во времени.
Алгоритм Microsoft Time Series
В качестве примеров алгоритмов мы будем использовать алгоритм временных рядов (Microsoft Time Series).
Алгоритм временных рядов применяется для прогнозирования одной или нескольких переменных, значение которых изменяется во времени (например, биржевые котировки акций). Прогнозирование с помощью этого алгоритма основывается на тенденциях изменения данных, полученных при обучении модели.
Чаще всего временные ряды представляют в виде последовательности данных, упорядоченных в неслучайные моменты времени, — анализ временных рядов основывается на предположении, что последовательные значения в наборе данных наблюдаются через равные промежутки времени (в то время как во многих других методах прогнозирования привязка данных ко времени может быть несущественной).
Отметим, что временным рядам посвящено целое направление статистического анализа, и для реализации прогнозирования с применением временных рядов существует множество методик прогнозирования и их реализаций, в которые мы не будем подробно вдаваться в данной статье — интересующиеся этим вопросом могут найти достаточно много материалов, посвященных данной теме. Отметим лишь, что методика, используемая в SQL Server 2005 и носящая название AutoRegression Trees, является одной из наиболее простых в применении при довольно высокой точности.
Создание модели
В предыдущей статье, изучая алгоритмы Microsoft Decision Trees, Microsoft Clustering и байесов, мы подробно обсудили, как создавать модели Data Mining с помощью SQL Server Business Intelligence Development Studio. Для выполнения описанных далее примеров можно использовать готовый проект, созданный при изучении перечисленных алгоритмов, или разработать новое представление источников данных (как это сделать, описывается в одной из предыдущих статей данного цикла (см. КомпьютерПресс № 3’2006); в нашем примере мы воспользовались готовой базой данных AdventureWorks, входящей в комплект поставки SQL Server 2005). Затем, как и в предыдущий раз, следует приступить к созданию структуры модели (Mining Structure), выбрав соответствующий пункт контекстного меню папки Mining Structures.
Как и в предыдущем примере, при ответе на вопросы мастера выбираются модель Data Mining (в данном случае — Microsoft Time Series), используемое представление источников данных (в данном случае — AdventureWorksDW), таблица, содержащая строки, которые предназначены для обучения модели (в данном случае — vTimeSeries), прогнозируемые атрибуты (то есть те, значения которых в дальнейшем нужно будет предсказывать) и входные атрибуты (то есть атрибуты, на основании которых будет осуществляться прогноз, — рис. 1).
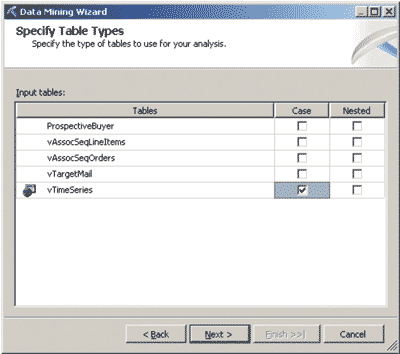
Рис. 1. Выбор таблиц для создания модели временных рядов
В данном примере поля TimeIndex и ModelRegion выбраны в качестве ключевых (рис. 2). Это означает, что для каждого значения ModelRegion будет создана отдельная модель временных рядов. При этом предполагается, что значения поля TimeIndex должны быть уникальны для каждого выбранного значения поля ModelRegion (то есть данная пара полей является составным ключом используемого набора данных). Отметим также, что в ряде случаев следует определить, дискретными или непрерывными являются значения полей, используемых при создании модели (последнее можно осуществить автоматически, нажав кнопку Detect в одном из окон мастера создания модели) (рис. 3).
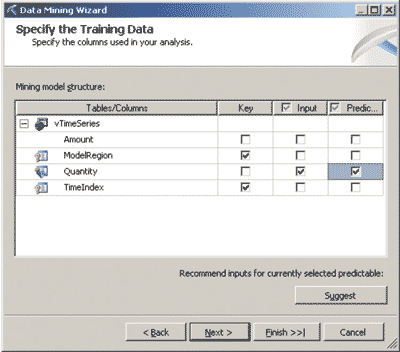
Рис. 2. Выбор входных и прогнозируемых атрибутов
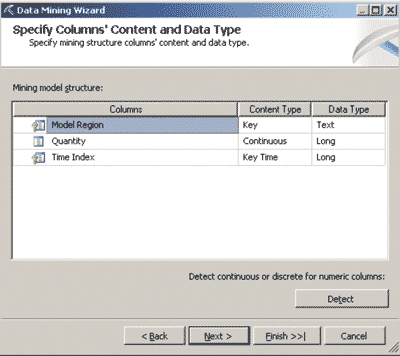
Рис. 3. Определение типов данных для используемых полей
Присвоим модели и структуре Data Mining имя Forecasting и сохраним модель (рис. 4).
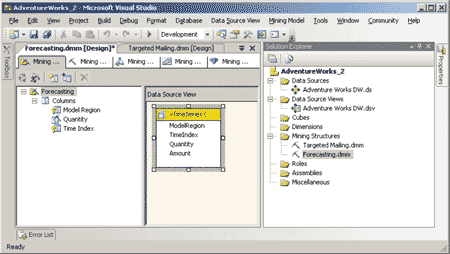
Рис. 4. Сохранение модели Data Mining
В дальнейшем можно внести изменения в модель, перенеся мышью, к примеру, поле Amount из представления источника данных в список колонок, используемых для моделирования, и указать, что соответствующее значение нужно предсказывать, выбрав опцию Predict из соответствующего выпадающего списка (рис. 5).
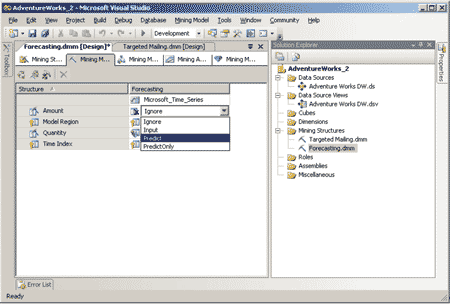
Рис. 5. Изменение состава полей, используемых в модели Data Mining
Помимо состава используемых полей набора данных, изменения можно вносить и в их свойства. При этом можно изменять свойства поля как для отдельной модели, так и для всей структуры (включая и другие модели, связанные с этой структурой).
На поведение модели, созданной с применением алгоритма временных рядов, могут повлиять некоторые ее параметры. Рассмотрим простой пример. Большинство регулярных составляющих временных рядов, описывающих бизнес-данные (например, продажи), принадлежит к двум классам: они являются либо трендом (тенденцией), либо сезонной составляющей. Тренд представляет собой систематический компонент, который может изменяться во времени, тогда как сезонная составляющая — это периодически повторяющийся компонент. При этом обе составляющие часто присутствуют в ряду одновременно (например, продажи компании могут возрастать из года в год и содержать сезонную составляющую). Если мы хотим учесть наличие и тренда, и сезонной составляющей при осуществлении прогноза, то должны указать, с какой периодичностью происходит повтор данных в сезонной составляющей. Для этого мы можем использовать параметр PERIODICITY_HINT. В таком случае об исходных данных, применяющихся в этом примере, заранее известно, что они отражают ежемесячные сводки с ежегодной периодичностью. Поэтому имеет смысл установить значение данного параметра равным {12}.
Изменим одно из свойств только что созданной модели. Для этого на закладке Mining Models выберем колонку Forecasting, а из контекстного меню этой колонки — пункт Set Algorithm Parameters (рис. 6).
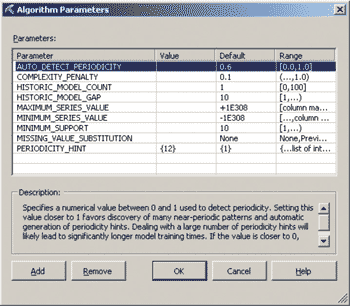
Рис. 6. Изменение свойств модели
Обучение модели
Теперь можно заняться обучением модели. Для этого из того же контекстного меню колонки Forecasting выберем пункт Process Mining Structure and All Models и в диалоговой панели Process Mining Structure — Forecasting щелкнем на кнопке Run. В появившейся диалоговой панели Process Progress будет отображаться состояние процесса выполнения обучения модели, а также список выполняемых операций (рис. 7).
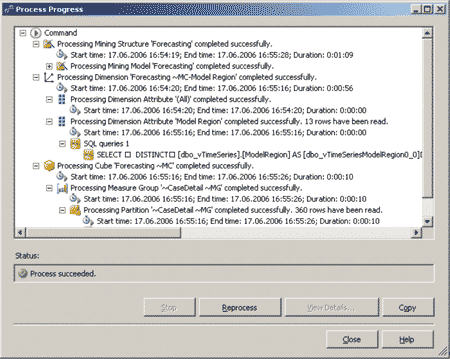
Рис. 7. Обучение модели Data Mining
Напомним, что процесс обучения модели может быть весьма длительным, особенно в случае реального набора данных, накопленного, возможно, за много лет. В то же время процедура обучения моделей выполняется либо однократно, либо редко (к примеру, для учета вновь накопленных данных), в отличие от многократно выполняющегося процесса прогнозирования.
Просмотр результатов обучения модели
Для просмотра результатов обучения модели мы, как и в прошлый раз, воспользуемся средством Mining Model Viewer, содержащим в данном случае две закладки.
Закладка Decision Tree позволяет просмотреть дерево решений, созданное в процессе обучения модели (рис. 8).
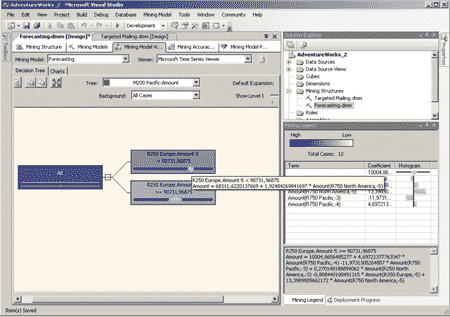
Рис. 8. Дерево решений для модели временных рядов
Каждая из ветвей дерева решений отображает следующие данные:
- концентрацию исходных записей, для которых предсказываемый атрибут находится в состоянии, определенном в элементе управления Background (точное число записей отображается в окне легенды Node Legend и во всплывающей подсказке);
- формулу регрессии для данной ветви;
- ромб, представляющий диапазон атрибутов и расположенный посередине ветви. Ширина ромба соответствует разбросу значений атрибута в данной ветви, поэтому чем тоньше ромб, тем точнее осуществляется прогноз.
Закладка Charts инструмента Microsoft Time Series Viewer позволяет исследовать созданные указанным алгоритмом временные ряды (рис. 9) .
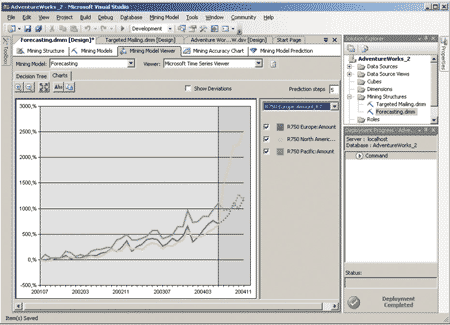
Рис. 9. Отображение имеющихся и прогнозируемых данных
Выбрав из выпадающего списка справа от графика предсказываемые величины, можно получить график их изменения и прогнозируемое поведение.
Заключение
В настоящей статье мы рассмотрели применение алгоритма временных рядов, используемого для прогнозирования поведения данных в будущем на основе данных об их поведении в прошлом. В следующих статьях мы продолжим обсуждение алгоритмов Data Mining — среди них еще осталось несколько весьма интересных.








