Конфиденциальные данные и лингвистические технологии
Реализация и возникающие проблемы
Большинство современных организаций серьезно беспокоятся за свою внутреннюю безопасность. Развитие Интернета и средств коммуникации вывело проблему утечек на совершенно иной уровень — сегодня ее невозможно решить исключительно административными средствами. Количество информации, пересылаемой даже небольшой компанией, настолько велико, что ее нельзя контролировать вручную. В результате все большее распространение получают автоматизированные системы, которые анализируют информацию и определяют ее смысл. Если система обнаруживает конфиденциальные данные — она мгновенно блокирует эту пересылку и оповещает сотрудников службы безопасности.
Как правило, современные системы сводят анализ информации к анализу текстовых данных, из которых эта информация и состоит. Другими словами, они используют лингвистические технологии. Отметим, что это намного более эффективно, чем применение детерминистских методов поиска приватных данных, суть которых состоит в том, чтобы пометить все конфиденциальные документы и затем считывать эти метки. Сфера применения детерминистских методов ограничена небольшими компаниями, так как в сложной системе документооборота пометить файлы становится практически невозможно. К тому же в детерминистских методах отсутствует научная составляющая.
Лингвистический анализ текста
Понятно, что алгоритм работы автоматизированной системы во многом зависит от языка анализируемых текстов. Например, для некоторых языков характерно большое количество форм склонения и спряжения, что выражается в изменении окончаний (флексий). Такие языки называются флективными — к их числу относится и русский. Глаголы флективных языков тоже имеют большое количество словоформ. В отдельных случаях оно достигает нескольких десятков, включая безличные формы — причастия и деепричастия («сливать информацию» — «сливавший информацию», «сливая информацию»).
В других языках (типичный пример — английский) больше распространены аналитические конструкции, которые строятся с помощью вспомогательных слов («he has stolen a database of corporate clients»). Естественно, что особенности языка оказывают влияние на алгоритм работы системы. Так, система, разработанная для анализа русских текстов, обязана «понимать» словоформы. В противном случае заказчик обречен на весьма серьезные проблемы во время формирования словаря ключевых слов и категоризации информации.
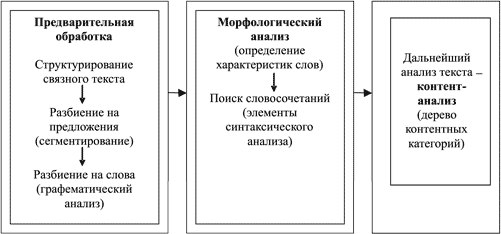
Концептуальная схема работы лингвистического ядра Morph-o-Logic
Сегодня можно выделить три основных подхода к анализу текстовых данных. Два из них (digital fingerprints и сигнатурный анализ) оптимизированы для аналитических языков, а третий (морфологический анализ) хорошо работает с флективными текстами. Абсолютное большинство представленных на рынке систем предлагается американскими компаниями, а значит, основной язык для них — английский. Таким образом, морфологические методы встречаются на практике довольно редко.
Сигнатурный анализ — самый простой метод распознавания конфиденциальной информации, основанный на сравнении с ключевыми фразами. Вместе с тем это и самый ненадежный метод: простейшее изменение данных приводит к невозможности зафиксировать утечку.
Digital fingerprints — весьма распространенный метод идентификации приватных сведений. С каждого защищаемого документа снимается один или несколько «отпечатков» (хеш-функции). Они используются для обнаружения защищенных документов в каналах передачи данных и предотвращения неавторизованных действий с ними (пересылка, печать, копирование и пр.). Данный метод имеет большой недостаток: digital fingerprints неустойчивы к изменению категоризованных данных: при изменении хотя бы одного символа результат применения хеш-функции будет отличаться от эталонного.
С научной точки зрения наибольший интерес представляют морфологические методы, которые не только подсчитывают хеш или сравнивают текстовые блоки с ключевыми словами, но и формируют целостное представление о документе. Одним из примеров реализации морфологической системы является интеллектуальное ядро Morph-o-Logic, интегрированное в решения российской компании InfoWatch. Далее мы рассмотрим, каким образом оно работает.
Morph-o-Logic
Стадии работы
На рисунке представлена концептуальная схема работы лингвистического ядра Morph-o-Logic (она не зависит от специфики языка, на котором написан анализируемый текст). Рассмотрим подробнее этапы работы данной морфологической системы.
Этап 0. Создание категорий, а также наполнение их ключевыми словами и словосочетаниями. Данный этап не входит в концептуальную схему Morph-o-Logic просто потому, что выполняется вручную до начала эксплуатации системы. На этой стадии формируется некая база данных, на основе которой будут определяться конфиденциальные сведения. Очевидно, что определить, какие сведения являются секретными, может только заказчик, а следовательно, он должен принимать участие в формировании базы. Впрочем, некоторые шаблоны такой базы могут поставляться разработчиком системы, но они все равно должны быть адаптированы. Построенная база данных будет использована на третьем этапе — контентном анализе текста.
Этап 1. Первичный анализ текста (предварительная обработка). Этот этап одновременно является и самым простым, и самым сложным. Задача системы здесь — извлечь текстовое содержимое из документа и разбить его на предложения и слова. Сделать это, казалось бы, совсем нетрудно, но только для одного формата файлов. Реальность такова, что количество файловых форматов (а также кодировок) все время растет и их необходимо как-то поддерживать. В некоторых случаях (например, когда текст передается в виде картинки, сделанной с помощью PrintScreen) задача предварительной обработки перетекает из банальной технической в самую что ни на есть научную плоскость.
Этап 2. Морфологический анализ. В начале этого этапа система получает так называемый пустой текст (plain text). Основная задача морфологического модуля — определение характеристик слов без учета их смысловой нагрузки. Каждому слову приписываются различные характеристики (например, выделяется падежное окончание), после чего на основе выявленных атрибутов слов начинается поиск словосочетаний. В дальнейшем выделенные фрагменты используются для проведения третьего этапа — контентного анализа текста.
Этап 3. Контентный анализ. На входе система получает текст, разбитый на словосочетания. Она сравнивает полученные словосочетания с некими эталонами, которые хранятся в базе данных (см. этап 0), и на основе вероятностных характеристик определяет степень конфиденциальности документа. Если это значение больше определенного порога — документ признается секретным и его передача блокируется.
Реализация и возникающие проблемы
Очевидно, что основная работа системы происходит на втором и третьем этапах. Первая стадия носит технический характер и сложности ее реализации вполне понятны — все они связаны с охватом максимального количества форматов. Поэтому мы более подробно рассмотрим второй и третий этапы — морфологический и контентный анализ текста.
Этап 2. Морфологический анализ
Трудность морфологического анализа обусловлена одним из свойств любого языка — его изменяемостью. Условно весь лексический состав языка можно разделить на две части. Первая представляет собой некую совокупность слов (лексикон), которая сформировалась в ходе развития языка. Она обладает достаточной устойчивостью и является базой для создания текстов письменной и устной речи.
Второй лексический пласт характеризуется большей подвижностью. Он включает новые слова, которые существуют в языке сравнительно недавно, например имена собственные и словообразовательные варианты уже известных слов (мобильный телефон, мобильник и т.д.). Поэтому важно иметь алгоритмы, встроенные в анализатор и рассчитанные на обработку как известных, так и новых слов.
Кроме новых слов, важно определять и старые слова, написанные в искаженной форме. Можно выделить две ситуации, когда пользователь искажает написание слов. В первом случае он непреднамеренно, по неосмотрительности допускает опечатки. Это часто происходит при быстром наборе текста электронного письма или когда сообщения посылаются через систему обмена мгновенными сообщениями (ICQ и т.д.). Во втором случае пользователь умышленно видоизменяет привычное написание слов. Для защиты от любых действий пользователя в анализаторе имеются элементы нечеткого поиска слов. Слова могут быть обнаружены, даже если некоторые буквы в них были заменены на похожие по начертанию цифры: 4 — ч, 0 — о, 1 — l (строчная L) и т.п. Под нечетким поиском также подразумевается детектирование слов, даже если буквы в них переставлены местами или латинские буквы набраны вместо эквивалентных по начертанию русских («п» и «n»). Кроме того, в словах могут быть допущены орфографические ошибки.
В лексиконе любого языка есть множество составных слов или конструкций, использующих знаки препинания: переносы, дефисы, апострофы («бизнес-план», «clients’ personal data» и т.д.). Для обработки составных конструкций применяется специальный алгоритм «склейка составных конструкций». Для каждого символа, помеченного как разделитель составных выражений, производится анализ предыдущего и последующего слов и информации о пробелах слева и справа от него. После этого, если информация о пробелах и языке соседних слов позволяет сделать предположение о составной конструкции, строится составное слово.
Этап 3. Контентный анализ
Существует много трактовок понятия «контент-анализ» или «контентный анализ». Наиболее точно сущность данного термина отражает следующее определение: это методика выявления в тексте определенных характеристик.
На основе частоты появления характеристик делаются соответствующие выводы о рассматриваемых в тексте темах. Из текста также можно определить намерения его создателя, его отношение к описываемым явлениям (негативное, положительное или индифферентное), возможную реакцию читателя. Если найденных характеристик достаточно, то принимается решение, что текст содержит конфиденциальные сведения. В результате контент-анализа делается классификация данных для анализируемого текста. При этом определяется, какие именно сведения были в нем отражены.
Важным этапом контент-анализа является задание контентных категорий для конфиденциальных данных. Каждая компания создает собственное дерево категорий еще до эксплуатации системы. Важность этого процесса трудно переоценить — фактически дерево категорий определяет конфиденциальность информации в компании. Собственно, категория — это совокупность слов, которые объединены по определенным признакам. Например, категория «Безопасность» может объединять слова и словосочетания, относящиеся к сведениям, важным для обеспечения безопасности. В большинстве случаев эти сведения не подлежат огласке: Безопасность = {секретные коды, схема расположения объектов, внутреннее расследование …}.
Слова и словосочетания, выделенные во время морфологического анализа, являются смысловыми элементами текста. Каждому такому элементу сопоставляется число, показывающее степень его значимости (релевантности) для каждой категории. Чем больше этот коэффициент, тем выше вероятность обнаружения данной категории в анализируемом тексте. Весовой коэффициент задается не только для ключевых слов, но и для самой категории. Это позволяет использовать гибкие настройки системы в зависимости от уровня конфиденциальности и критичности данных.
Текст, попавший в модуль контент-анализа, может быть отнесен либо только к одной, либо к нескольким категориям одновременно. Это говорит о том, что в тексте могут быть представлены конфиденциальные данные только одной категории или нескольких сразу. Кроме того, они могут вообще не содержаться в тексте — в таком случае ни одна категория не соотносится с текстом.
Для оптимизации поиска ключевых слов можно задавать конкретные параметры. Например, можно найти слово, написанное в определенном регистре: только строчными буквами, только прописными или комбинацией из строчных и прописных букв. Это имеет значение для некоторых атрибутов конфиденциальных документов. Некоторые сокращения являются маркерами конфиденциальных документов и пишутся строчными буквами: КТ (коммерческая тайна), ДСП (для служебного пользования) и т.д.
Часть ключевых словосочетаний можно искать без учета морфологии. Это особенно актуально для клишированных выражений (то есть для стандартных фраз официально-делового стиля, например «за отчетный период») или для определенной части предложения, которую необходимо найти в тексте в неизменном виде (например, «победителем закрытого тендера объявлен»).
Что мы имеем в конце
По завершении контент-анализа документа система выдает пользователю один бит информации. Если его значение равно 0 — значит, документ вполне легальный. В противном случае у сотрудника службы безопасности появляется работа.
Однако этот бит является не единственным результатом работы системы. Фактически лингвистические технологии позволяют ответить не только на вопросы: «кто отправил?», «кому отправил?» и «как отправил?», но и определить, что именно было отправлено. Это означает, что лингвистика решает целый ряд задач, связанных с обобщенной категоризацией контента. В этом свете обнаружение утечек является лишь частным случаем, который, впрочем, не теряет от этого важности и актуальности.








