Cкоростная память DDR3: стоит ли игра свеч?
Принципы функционирования SDRAM-памяти
Логическая организация микросхем динамической памяти
Частота, пропускная способность и обозначение памяти
Используемые бенчмарки и приложения
Зависимость производительности от тактовой частоты и режима работы памяти
Зависимость производительности памяти от таймингов
Память DDR3 постепенно становится массовой. Уже сегодня все новые материнские платы, поддерживающие новейшие высокопроизводительные процессоры и ориентированные на создание высокопроизводительных ПК, рассчитаны именно на память DDR3.
«Как же так? — спросите вы. — Ведь материнские платы, поддерживающие новейшие процессоры AMD, совместимы только с памятью DDR2». Да, действительно, сегодня процессоры AMD совместимы только с памятью DDR2, однако никакого противоречия в данном случае нет, поскольку мы говорим только о материнских платах, поддерживающих высокопроизводительные процессоры, то есть процессоры Intel.
В скором будущем память DDR3 придет в сегмент массовых, а затем и бюджетных ПК и о памяти DDR2 постепенно забудут точно так же, как в свое время забыли о DDR.
Сегодня память DDR3 пока еще стоит дорого. Причем если сравнивать стоимость модулей равного объема памяти DDR2 и DDR3, то можно сказать, что цена памяти DDR3 неоправданно высока.
Понятно, что стоимость памяти зависит и от производителя, и от частоты, и от таймингов. И естественно, что более скоростная память, то есть память, поддерживающая более высокие тактовые частоты и имеющая меньшее значение таймингов, будет стоить гораздо дороже низкоскоростной памяти. Но настолько ли критичны для памяти DDR3 тактовая частота и значения таймингов? Возможно, высокие тактовые частоты — это не что иное, как очередная рекламная «утка» производителей.
В данной статье мы постараемся выяснить, как влияют тактовая частота, тайминги и режим работы памяти (двухканальный, одноканальный) на реальную производительность компьютера. Кроме того, мы попытаемся понять, стоит ли переплачивать за высокоскоростную память и адекватен ли прирост производительности от использования высокоскоростной памяти заплаченным за это деньгам.
Но прежде, чем переходить к обсуждению методики и результатов тестирования, нам придется сделать небольшое отступление от темы, дабы разговаривать в дальнейшем на одном языке. Итак, давайте вкратце напомним основе аспекты, связанные с оперативной памятью.
Принципы функционирования SDRAM-памяти
Подробный рассказ о принципах функционирования оперативной памяти (SDRAM-памяти) потребовал бы от нас написания отдельной книги. Собственно, в этой статье мы не ставим целью во всех деталях изложить принципы функционирования SDRAM-памяти, но в то же время без базовых знаний, касающихся принципов функционирования SDRAM-памяти, дальнейшее изложение материала может показаться слишком мудреным. А потому попробуем освежить в памяти основные теоретические аспекты.
Строение ядра памяти
Итак, напомним, что вся современная оперативная память относится к синхронной динамической памяти с произвольным доступом (Synchronous Dynamic Random Access Memory, SDRAM). Под синхронностью в данном случае понимают тот факт, что все управляющие сигналы и сами данные на шине памяти синхронизированы с некоторой опорной частотой (тактирующими импульсами). Динамической память является в том смысле, что информация в ней сохраняется только при включенном питании, а кроме того, содержимое этой памяти (в отличие от статической памяти) необходимо периодически обновлять (производить регенерацию памяти).
Ядро микросхемы SDRAM-памяти принято рассматривать как некий двумерный массив (матрицу) ячеек памяти, находящихся на пересечении строк (Row) и столбцов (Column) (столбцы матрицы памяти также иногда называют страницами (Page)). По сути, ячейки памяти подсоединены к линиям строк и линиям столбцов (рис. 1).
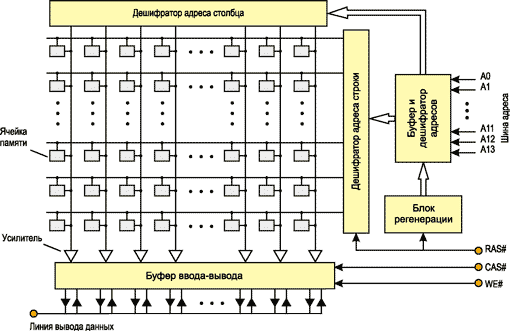
Рис. 1. Структура матрицы памяти
На элементарном уровне запоминающая ячейка SDRAM-памяти, способная запомнить 1 бит информации, представляет собой конденсатор, который выполняет функцию хранителя заряда. Наличие заряда на конденсаторе можно ассоциировать с единичным битом информации, а его отсутствие — с нулевым битом.
Однако одного лишь конденсатора недостаточно для формирования ячейки памяти. Дело в том, что если конденсатор соединить с линией строк и линией столбцов, то он мгновенно разрядится, то есть не сможет сохранять информацию. Поэтому в паре с конденсатором в элементарной ячейке памяти применяется транзистор, выполняющий функцию электронного ключа (рис. 2). Затвор транзистора (управляющий электрод) подключается к линии строк, а остальные два электрода (сток и исток) подключены к одной из обкладок конденсатора и линии столбцов. Если на затвор транзистора не подается напряжение, то транзистор находится в запертом состоянии и конденсатор физически отсоединен от линии столбцов.
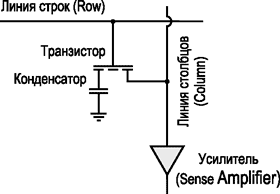
Рис. 2. Структура элементарной
ячейки динамической памяти
При подаче напряжения на затвор транзистора он переходит в открытое состояние и конденсатор подключается к линии столбцов. В результате происходит разряд конденсатора и заряд, хранящийся на конденсаторе данной ячейки, поступает в особый статический буфер, называемый усилителем уровня (Sense Amplifier), который установлен на выходе линии столбца. Отсутствие заряда на обкладках соответствует логическому нулю на выходе, а его наличие — логической единице.
Поскольку считывание содержимого ячейки памяти происходит при подаче напряжения на линию строк, что эквивалентно открытию транзистора (линии строк также называют адресными линиями). Линии столбцов, по которым считывается информация, называют линиями данных.
Сама по себе операция чтения данных из ячейки памяти деструктивна в том смысле, что если на конденсаторе содержался заряд (ячейка памяти хранила логическую единицу), то в ходе считывания конденсатор разрядится и значение ячейки памяти будет соответствовать уже логическому нулю.
Более того, в силу организации памяти как двумерного массива элементов подача напряжения на линию строк (открытие строки) приводит к тому, что открывается не один, а все транзисторы, соединенные с этой линией строк, и данные окажутся на выходе усилителей по всем столбцам сразу. То есть при открытии строки считывается вся страница памяти целиком, а для чтения значения конкретной ячейки памяти необходимо просто считать значения усилителя нужной линии данных (линии столбца).
Итак, после краткого знакомства с устройством ячейки памяти и организацией памяти давайте рассмотрим, каким образом происходит считывание информации, то есть доступ к ячейке памяти.
Для доступа к ячейке памяти прежде всего необходимо знать ее адрес, то есть знать, на пересечении какой строки и какого столбца расположена нужная ячейка памяти. Адреса строки и столбца передаются по одним и тем же адресным линиям, что позволяет вдвое уменьшить количество адресных линий, а следовательно, уменьшить количество выводов микросхемы памяти. Правда, в этом случае для задания адреса ячейки памяти требуется в два раза больше времени, поскольку адреса столбца и строки приходится передавать последовательно. Кроме того, микросхеме памяти необходимо каким-то образом указать, чей именно адрес передается по адресной шине. Для этого используются два специальных управляющих сигнала: RAS# и CAS#. RAS# — это сигнал выбора строки (Row Access Strobe), а CAS# — сигнал выбора столбца (Column Access Strobe). В случае если доступ к ячейке памяти не осуществляется, поддерживается высокий уровень сигналов RAS# и CAS#, что говорит об отсутствии информации на адресной шине.
Если требуется осуществить доступ к ячейке памяти, первоначально на адресные линии микросхемы памяти подается адрес строки и одновременно с этим уровень сигнала RAS# переводится в низкое состояние (подача сигнала RAS#). При этом микросхема памяти помещает адрес с шины адреса в буфер адреса строки. Далее производится выбор нужной строки (за это отвечает декодер адреса строки), то есть на нужную строку матрицы памяти подается напряжение и все транзисторы, соединенные с данной строкой, переходят в открытое состояние, а содержимое всей строки помещается в усилитель уровня. Такая операция называется активацией строки.
Далее по адресной шине передается адрес столбца и одновременно с этим уровень сигнала CAS# переводится в низкое состояние (подача сигнала CAS#). При этом микросхема памяти помещает адрес с шины адреса в буфер адреса столбца. После этого усилитель уровня передает данные, соответствующие адресу столбца в буфер вывода.
Отметим, что в SDRAM-памяти реализована пакетная обработка данных, что позволяет производить обращение по новому адресу столбца ячейки памяти на каждом тактовом цикле. Смысл пакетной обработки заключается в том, при активированной строке задание адреса одного столбца позволяет получить доступ сразу к последовательности нескольких столбцов (пакету столбцов) без дополнительного указания их адресов. В микросхеме SDRAM имеется счетчик для наращивания адресов столбцов ячеек памяти, чтобы обеспечить к ним быстрый доступ. Количество адресуемых таким образом столбцов называется длиной пакета (Burst Length, BL).
Поскольку активация строки является деструктивной операцией, то после считывания данных строки их необходимо восстановить в строке. Эта операция называется перезарядкой строки (PRACHARGE). Поэтому на заключительном этапе сигналы RAS# и CAS# устанавливаются в высокое состояние, а микросхема памяти производит восстановление содержимого строки.
Как видим, доступ к ячейке памяти происходит в строго определенной последовательности и требует некоторого времени. Задержки между подачей сигналов измеряются в тактах системной шины и называются таймингами. К примеру, задержка между сигналами RAS# и CAS#, то есть между сигналами выбора строки и выбора столбца, называется RAS-to-CAS Delay (tRCD). Впрочем, более подробно о таймингах памяти мы расскажем далее, а пока рассмотрим логическую организацию микросхемы памяти.
Логическая организация микросхем динамической памяти
Итак, теперь попытаемся представить себе, как может выглядеть микросхема памяти объемом, к примеру, 512 Мбит. В такой микросхеме должно быть 536 870 912 ячеек памяти, и если предположить, что все ячейки памяти представляют собой прямоугольную матрицу, то в ней должно быть 16 384 строки и 32 768 столбцов (или наоборот). Для задания адреса строки/столбца в микросхемах памяти применяется 14-разрядная адресная шина (A0-A13), что позволяет адресовать 16 384 строки или столбца, но не более. Как видите, в нашем случае ограничения по разрядности адресной шины не позволяют нам организовать микросхему памяти емкостью 512 Мбит в виде одной матрицы памяти.
Для того чтобы иметь возможность создавать емкие микросхемы памяти с использованием ограниченной разрядности адресной шины, в одной микросхеме реализуют несколько отдельных параллельных матриц запоминающих ячеек, имеющих один адрес. В этом случае размерность шины данных микросхемы памяти не будет равна единице, как в случае с одной матрицей памяти, когда данные считываются или записываются в матрицу последовательно по одному биту, — она будет соответствовать количеству матриц памяти в микросхеме.
Кроме того, что такой подход позволяет увеличивать емкость отдельной микросхемы памяти без увеличения разрядности адресной шины, он дает возможность уменьшить количество микросхем памяти в модуле памяти и упростить их электрические соединения друг с другом. Действительно, разрядность шины данных модулей памяти составляет 64 бита. Если модуль памяти составлять из отдельных микросхем с разрядностью шины данных, равной 1 биту, то потребовалось бы 64 отдельных микросхем!
Наиболее популярными оказались варианты, когда микросхема памяти имеет разрядность, равную 4, 8 или 16 бит (иногда встречаются микросхемы памяти с разрядностью 32 бит). К примеру, микросхему памяти емкостью 512 Мбит можно организовать как четыре матрицы по 128 Мбит. В этом случае структура микросхемы памяти обозначается как 128Мx4. Первая из этих цифр называется глубиной микросхемы памяти (безразмерная величина), а вторая — шириной (выраженная в битах).
Отметим, что в данном случае 4 бита — это разрядность шины данных микросхемы памяти, причем все четыре информационных бита будут считываться или записывать в микросхему памяти одновременно (рис. 3).
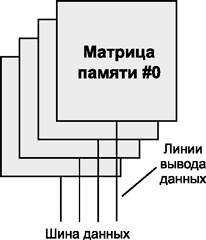
Рис. 3. Логическая организация
микросхемы памяти
Кроме физической организации микросхемы памяти в виде нескольких параллельных матриц памяти, применяется еще логическое разделение микросхемы памяти на отдельные логические банки. Как правило, используется деление на две или четыре логических банка. Для выбора того или иного логического банка памяти используются специальные адресные линии. К примеру, если в микросхеме памяти имеются четыре логических банка, то для выбора отдельного банка памяти применяются две адресные линии: BA0 и BA1 (рис. 4).
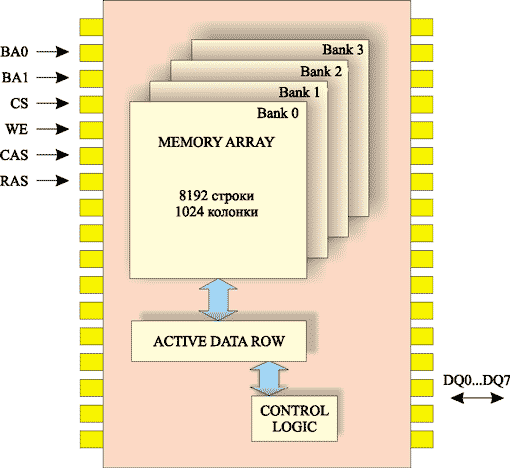
Рис. 4. Упрощенная схема чипа памяти с шириной шины данных 8 бит
Разбиение микросхемы памяти на логические банки применяется для повышения производительности. Дело в том, что после реализации любой операции со строкой памяти требуется определенное время для ее обновления. Если используется логическое разбиение микросхемы памяти на несколько банков, то можно обращаться к строке одного логического банка, пока строка другого банка обновляется. Такая схема доступа к памяти называется доступом с чередованием банков (Bank Interleave).
Структура модуля памяти
Модуль памяти состоит из нескольких микросхем (чипов) памяти. Для доступа к конкретному чипу памяти применяется специальный сигнал CS# (Chip Select). Когда сигнал активен, возможен доступ к чипу памяти, то есть чип активируется. В противном случае чип памяти недоступен.
Если говорить о модуле памяти, который включает несколько чипов памяти, то, кроме емкости, выражаемой в мегабайтах (Мбайт) или в гигабайтах (Гбайт), он характеризуется шириной или разрядностью интерфейса шины данных. Для всей современной памяти ширина шины данных составляет 64 бита. Ширина шины данных модуля памяти (64 бит) больше, чем ширина шины данных отдельного чипа памяти (4, 8, 16 или 32 бит). Для того чтобы согласовать передачу данных, используется простое слияние шин данных отдельных чипов памяти в шину данных модуля памяти.
Такое «заполнение» шины данных памяти принято называть составлением физического банка памяти. К примеру, для составления одного физического банка 64-разрядного модуля памяти SDRAM необходимо наличие 16 чипов шириной x4, или восьми чипов шириной x8, или четырех чипов шириной x16.
Как и отдельный чип памяти, модуль памяти характеризуется глубиной, которая определяется как емкость модуля, выраженная в битах и деленная на разрядность шины данных (64 бит). Соответственно произведение ширины на глубину дает полную емкость модуля и определяет его организацию. Так, для модуля памяти емкостью 1024 Мбайт справедлива запись 128 Мx64.
Частота, пропускная способность и обозначение памяти
Основной характеристикой памяти является ее пропускная способность, то есть максимальное количество данных, которое можно считать из памяти или записать в память в единицу времени. Именно эта характеристика прямо или косвенно отражается в названии типа памяти. Пропускная способность памяти зависит от ширины шины данных и частоты работы памяти. Ширина шины данных определяет количество бит, передаваемых за один такт, а частота работы памяти — количество тактов в единицу времени. Поэтому для того, чтобы определить пропускную способность памяти, нужно умножить частоту системной шины на ширину шины данных. Как уже отмечалось, память SDRAM имеет 64-битную (8-байтную) шину данных.
К примеру, память DDR-400, функционирующая на эффективной частоте 400 МГц, имеет пропускную способность 400 МГц x 8 байт = 3,2 Гбайт/с, а память DDR3-1066, функционирующая на эффективной частоте 1066 МГц, — 1066 МГцx8 байт = 8,5 Гбайт/с.
Кроме того, необходимо учесть, что синхронная память DDR, DDR2 и DDR3 может функционировать в двухканальном режиме, и в этом случае максимальная пропускная способность удваивается.
Существует так называемое официальное и неофициальное обозначение памяти. Официальное обозначение памяти базируется на ее пропускной способности, а неофициальное — на эффективной тактовой частоте. К примеру, неофициальное обозначение памяти DDR3, функционирующей на тактовой частоте 1066 МГц, выглядит так: DDR3-1066. Официальное обозначение той же памяти записывается в следующем виде: PC3-8500, где число 8500 обозначает пропускную способность в одноканальном режиме работы (8500 Мбайт/с). Отметим, что, несмотря на наличие официального обозначения, неофициальное обозначение употребляется чаще.
Если говорить об эффективной тактовой частоте, то для памяти DDR3 типичными эффективными частотами являются следующие: 1066, 1333 и 1600 МГц, то есть стандартными считаются следующие модули памяти: DDR3-1066 (PC3-8500), DDR3-1333 (PC3-10600) и DDR3-1600 (PC3-12800).
Тайминги памяти
Как уже отмечалось, кроме максимальной пропускной способности, память характеризуется латентностью.
Под латентностью принято понимать задержку между поступлением команды и ее реализацией. Латентность памяти определяется ее таймингами, то есть задержками, измеряемыми в количестве тактов между отдельными командами. Принято различать несколько разных таймингов памяти, соответствующих задержкам между различным командами. Тайминги памяти можно устанавливать в настройках BIOS системной платы, а потому рассмотрим их более подробно.
Для этого еще раз напомним, каким образом происходит считывание или запись в ячейку памяти. Для чтения или записи данных в память существует несколько служебных сигналов, комбинации которых определяют весь набор команд работы с памятью. Ранее мы упоминали о наиболее важных сигналах RAS# и CAS#, комбинации которых позволяют сформировать команды активации строки памяти и чтения (записи) данных ячейки памяти. Однако мы рассматривали эти сигналы на примере одной матрицы памяти, но ведь каждый чип памяти имеет логическую структуру нескольких банков, а модуль памяти состоит из нескольких чипов. Кроме того, необходимо каким-то образом определять, о чем конкретно идет речь — о чтении данных из памяти или о записи данных в память. Поэтому для работы с памятью применяется четыре типа сигналов: CS#, RAS#, CAS# и WE#.
Сигнал CS# (Chip Select) — это сигнал выбора чипа. Когда происходит изменение сигнала CS# с высокого уровня на низкий, чип активируется, то есть становится доступным. Если же уровень сигнала CS# поддерживается высоким, то чип памяти недоступен.
Сигнал RAS#, как уже отмечалось, используется для активации строки памяти (для считывания адреса строки памяти и ее выбора). Когда происходит изменение сигнала RAS# с высокого уровня на низкий, происходит считывание адреса строки памяти, ее выбор в матрице памяти и считывание всего значения строки памяти в усилитель уровня. Изменение сигнала RAS# с высокого уровня на низкий трактуется как команда ACTIVE. Естественно, что эта команда будет восприниматься только в том случае, если предварительно активирован чип памяти.
Сигнал CAS# служит для считывания адреса столбца памяти. Когда происходит изменение сигнала СAS# с высокого уровня на низкий, производится считывание адреса столбца памяти, после которого возможно либо чтение данных, соответствующих выбранному столбцу, либо запись данных в ячейку. При операции чтения данные, соответствующие выбранному столбцу, поступают из усилителя уровня в буфер вывода шины данных. При записи данных выбранный столбец подключается к буферу ввода данных и в элементарную ячейку памяти записывается бит данных (по сути, заряжается или разряжается конденсатор). Для того чтобы различать операции чтения и записи, применяется специальный сигнал WE# (Write Enable). Если этот сигнал поддерживается на высоком уровне, то реализуется операция чтения, а если он переводится в низкий уровень, то реализуется операция записи. Таким образом, для реализации чтения данных сигналы CS#, RAS#, WE# и CAS# должны быть переведены с высокого уровня на низкий.
Попутно заметим, что все события памяти (считывание адреса строки и столбца, выдача или запись данных) синхронизированы с тактирующими импульсами, определяющими частоту работы ядра памяти. Если точнее, то все события памяти синхронизированы с положительным фронтом тактирующих импульсов. К примеру, само считывание адреса строки происходит не в момент изменения сигнала RAS# c высокого уровня на низкий, а синхронно с положительным фронтом тактирующего импульса. Аналогичным образом считывание адреса столбца происходит после изменения уровня сигнала CAS# с высокого значения на низкое синхронно с положительным фронтом тактирующего импульса.
В совокупности сигналы CS#, RAS#, CAS# и WE# позволяют сформировать все команды, необходимые для работы с памятью, то есть команды активации строки и чипа памяти (ACTIVE), команду чтения (READ), команду записи (WRITE) и команду деактивации (закрытия) строки (PRECHARGE) (существуют и другие специфические команды, но для понимания сути процесса они не нужны).
Как мы уже отмечали, под таймингами памяти понимают задержки, измеряемые в количествах тактов синхроимпульса, между последовательностью команд или, что равносильно, между изменениями управляющих сигналов CS#, RAS#, CAS# и WE#. Различают несколько типов таймингов памяти.
RAS# to CAS# Delay (tRCD)
Первоначально происходит активация нужной строки памяти (команда ACTIVE), для чего сигнал RAS# переводится в низкий уровень и происходит считывание адреса логического банка памяти и строки в этом банке памяти (сигнал выбора чипа памяти для простоты не рассматривается). Далее следует команда записи (WRITE) или чтения (READ) данных, для чего сигнал CAS# переводится в низкий уровень. При установке CAS# в низкий уровень после прихода положительного фронта тактирующего импульса происходит выборка адреса столбца, наличествующего в данный момент на шине адреса, и открывается доступ к нужному столбцу матрицы памяти. Однако команда чтения или записи не может следовать непосредственно за командой активации — требуется, чтобы между этими командами, то есть между импульсами RAS# и CAS#, оставался некий промежуток времени — RAS-to-CAS Delay (задержка сигнала CAS# относительно сигнала RAS#). Эту задержку, измеряемую в тактах системной шины, принято обозначать tRCD. Учитывая, что импульс RAS# эквивалентен выполнению команды активации строки (ACTIVE), а импульс CAS# — команде READ, под задержкой RAS-to-CAS Delay можно понимать время между командами ACTIVE и READ (рис. 5).
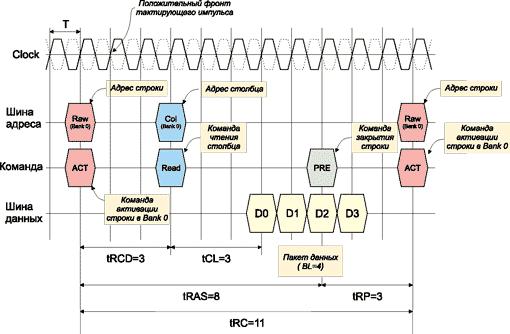
Рис. 5. Определение таймингов памяти на примере чтения в случае
одного логического банка
CAS# Latency (tCL)
От команды чтения (записи) данных и до выдачи первого элемента данных на шину (записи данных в ячейку памяти) проходит промежуток времени, который называется CAS Latency. Эта задержка обозначается tCL. В пакетном режиме работы в случае SDR памяти каждый следующий бит данных появляется на шине данных со следующим тактом до тех пор, пока не будет передан весь пакет (см. рис. 5).
Active to Precharge Delay (tRAS)
Еще один тип задержки, называемый Active to Precharge Delay (иногда используется обозначение RAS# Activate to Precharge или RAS# AСT Time), — это минимальный промежуток времени, который должен пройти с момента подачи команды активации строки (RAS#) до команды PRECHARGE (см. рис. 5). То есть фактически это время, в течение которого строка остается активированной. Такая задержка обозначается tRAS и измеряется в тактах системной шины.
RAS# Precharge (tRP)
Завершение цикла обращения к банку памяти осуществляется подачей команды PRECHARGE, приводящей к закрытию строки памяти. От команды PRECHARGE и до поступления новой команды активации уже другой или той же самой строки памяти (в том же логическом банке) должен пройти промежуток времени (tRP), называемый RAS# Precharge (RAS# PRE Time) (см. рис. 5). Фактически RAS Precharge — это промежуток времени, необходимый для регенерации содержимого строки памяти после ее чтения.
Auto Refresh Cycle Time (tRC)
Активация какой-либо строки банка памяти не может быть осуществлена до тех пор, пока предыдущая строка этого банка остается открытой. Минимальный промежуток времени между активацией двух различных строк одного и того же банка называется Auto Refresh Cycle Time (tRC). Как нетрудно заметить, всегда tRC = tRAS+tRP (см. рис. 5).
RAS# to RAS# Delay (tRRD)
RAS# to RAS# Delay (tRRD) — это минимальный промежуток времени между командами активации строк (RAS#) в разных логических банках памяти (рис. 6).
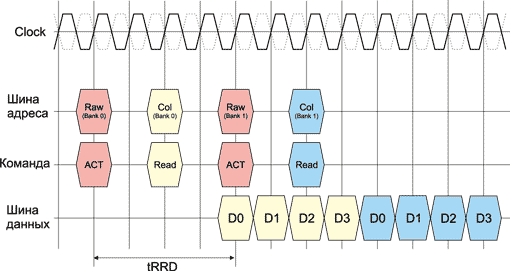
Рис. 6. Определение таймингов памяти на примере чтения в случае
двух логических банков
Write recovery time (tWR)
Write recovery time (tWR) — это минимальный промежуток времени между приемом последней порции данных, подлежащих записи, и готовностью строки памяти к ее закрытию с помощью команды PRECHARGE (рис. 7).
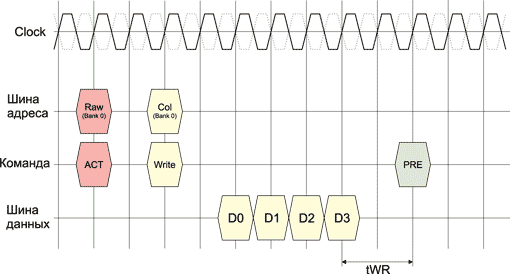
Рис. 7. Определение таймингов памяти на примере записи данных
Write to Read Delay (tWTR)
Write to Read Delay (tWTR) определяет минимальный промежуток времени между приемом последней порции данных, подлежащих записи, и командой чтения.
Read to Precharge Time (tRTP)
Read to Precharge Time (tRTP) — это минимальный промежуток времени между подачей команды на чтение до команды Precharge. Нетрудно убедиться, что tRTP=tRAS-tRCD (см. рис. 5).
Command Rate
Еще один тип задержки — это скорость выполнения команд (Command Rate), представляющая собой задержку в тактах системной шины между командой CS# выбора чипа и командой активации строки. Как правило, задержка Command Rate составляет один или два такта (1T или 2T).
Запись таймингов памяти
Описанные тайминги определяют скоростные характеристики памяти. Наиболее значимыми по их влиянию на производительность являются тайминги tCL, tRCD, tRP и tRAS, иногда называемые основными, — именно они указываются на модулях памяти. Основные тайминги памяти принято записывать в виде последовательности tCL-tRCD-tRP-tRAS. К примеру, на модуле памяти указывается 7-7-7-20 — это означает, что для данного модуля CAS# Latency (tCL) составляет 7 тактов, RAS# to CAS# Delay (tRCD) — 7 тактов, RAS# Precharge (tRP) — 7 тактов и ACTIVE-to-precharge delay (tRAS) — 20 тактов.
Все остальные тайминги памяти, которые называют неосновными, обычно не указываются на модулях памяти. Кроме того, для неосновных таймингов памяти производители могут указывать иные названия. Строго определенной последовательности всех таймингов (основных и неосновных) вообще не существует, а если используется полная запись всех тайминов, нужно четко оговаривать, о каких именно таймингах идет речь. К примеру, в BIOS материнской платы, на которой мы тестировали память, использовалась следующая последовательность записи таймингов: tCL-tRCD-tRP-tRAS-tRRD-tRC-tWR-tWTR-tRTP.
Естественно, для каждого типа памяти значения различных задержек не могут быть произвольными и выбираются из допустимых значений. Кроме того, между разными таймингами должны соблюдаться вполне определенные соотношения. Понятно, например, что должно выполняться соотношение tRAS > tRCD+tCL. Действительно, поскольку tRAS — это время, в течение которого строка остается активированной (время между командой активации строки и командой закрытия строки (PRECHARGE)), оно не может быть меньше, чем время между командой активации строки и появлением данных на шине.
Вообще, в Интернете можно найти немало материалов, посвященных поиску «идеальной формулы» таймингов. Занятие это крайне увлекательное — сродни поиску философского камня. Увы, все эти изыскания абсолютно бесперспективны, поскольку никакой «идеальной формулы» таймингов попросту нет. А если бы она и существовала, то давно была бы реализована в BIOS.
Нужно отметить, что, несмотря на ограничения, которые налагаются на значения таймингов и их соотношения друг с другом, в BIOS материнских плат можно, как правило, устанавливать тайминги памяти независимо друг от друга и выставлять при этом, казалось бы, абсолютно некорректные и даже невозможные значения таймингов. Самое главное, что память при этом будет работать как ни в чем не бывало. Фокус здесь заключается в том, что при установке недопустимого значения одного из таймингов, скорее всего, используются минимально возможные для данного тайминга значения. Однако, каким именно образом это делается — на уровне BIOS или на уровне самих модулей памяти, — тайна, покрытая мраком.
Память SDR, DDR, DDR2 и DDR3
Разобравшись с такими важными характеристиками памяти, как ее тайминги, можно перейти непосредственно к рассмотрению различных типов памяти. Наиболее простой является SDRAM-память типа SDR (Single Data Rate), которая уже практически не встречается. Тем не менее, дабы понять преимущества DDR-, DDR2- и DDR3-памяти, целесообразно прежде рассмотреть именно SDR-память.
В SDR SDRAM-памяти обеспечивается синхронизация всех входных и выходных сигналов с положительными фронтами импульсов тактового генератора. Весь массив памяти SDRAM-модуля разделен на два независимых банка. В SDR-памяти организована пакетная обработка данных, что позволяет производить обращение по новому адресу столбца ячейки памяти на каждом тактовом цикле. Длина пакета (Burst Length, BL) может составлять 2, 4 или 8.
В SDR-памяти ядро памяти и буферы обмена работают в синхронном режиме на одной и той же частоте. Передача каждого бита из буфера происходит с каждым тактом работы ядра памяти.
Временная диаграмма работы памяти SDR при длине пакета BL = 4 и таймингах tRCD = 2 и tCL = 2 показана на рис. 8.
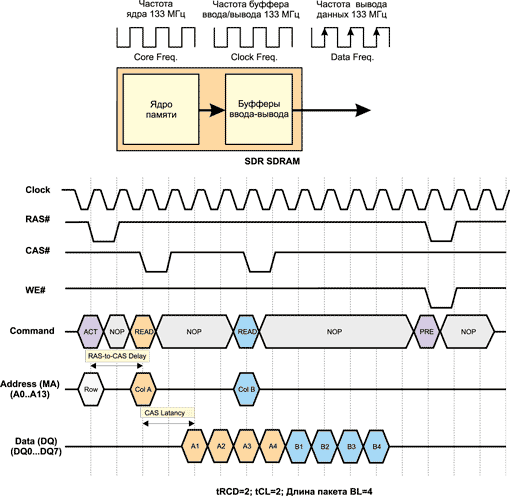
Рис. 8. Упрощенная временная диаграмма работы SDR-памяти в режиме чтения
Память DDR, которая пришла на смену памяти SDR, обеспечивает вдвое большую пропускную способность. Аббревиатура DDR (Double Data Rate) в названии памяти означает удвоенную скорость передачи данных. В DDR-памяти каждый буфер ввода-вывода на каждой из 64 линий шины данных передает два бита за один такт, то есть фактически работает на удвоенной тактовой частоте, оставаясь при этом полностью синхронизированным с ядром памяти. Такой режим работы возможен в случае, если эти два бита доступны буферу ввода-вывода на каждом такте работы памяти. Для этого требуется, чтобы каждая команда чтения приводила к передаче из ядра памяти в буфер ввода-вывода сразу 2n бит. С этой целью применяются две независимые линии передачи от ядра памяти к буферам ввода-вывода шириной n бит каждая, откуда биты поступают на шину данных в требуемом порядке.
Поскольку при таком способе организации работы памяти происходит предвыборка 2n бит перед передачей их на шину данных, его также называют 2n Prefetch (предвыборка 2n бит). В этой архитектуре доступ к данным осуществляется «попарно»: каждая одиночная команда чтения данных приводит к отправке по внешней шине данных двух элементов (разрядность которых, как и в SDR SDRAM, равна разрядности внешней шины данных). Аналогично каждая команда записи данных ожидает поступления двух элементов по внешней шине данных. Именно поэтому длина пакета (Burst Length, BL) при передаче данных в устройствах DDR не может быть меньше 2.
Для того чтобы осуществить синхронизацию работы ядра памяти и буферов ввода-вывода, используется одна и та же тактовая частота (одни и те же тактирующие импульсы). Только если в самом ядре памяти синхронизация осуществляется по положительному фронту тактирующего импульса, то в буфере ввода-вывода, выполняющем функцию мультиплексора, для синхронизации применяется как положительный, так и отрицательный фронт тактирующего импульса. Таким образом, передача 2n бит в буфер ввода-вывода по двум раздельным линиям происходит по положительному фронту тактирующего импульса, а их выдача на шину данных — как по положительному, так и по отрицательному фронту тактирующего импульса. Это обеспечивает удвоенную скорость работы буфера и соответственно удвоенную пропускную способность памяти.
Отличительной особенностью DDR-памяти является реализация четырех логических банков.
Упрощенная временная диаграмма работы DDR-памяти на примере операции чтения показана на рис. 9. Пусть имеются четыре банка памяти (Bank0…Bank3), длина пакета (Burst Length) равна 4, tCAS = 2, tRCD = 3 и tRRD = 2. Первоначально необходимо активировать каждый из четырех банков и получить доступ к строке в этом банке. Задержка между активацией двух банков определяется как tRRD (Row-to Row Delay). Таким образом, через каждые два такта активизируется новый банк, а через каждые три такта после активации банка следует команда чтения данных из него.
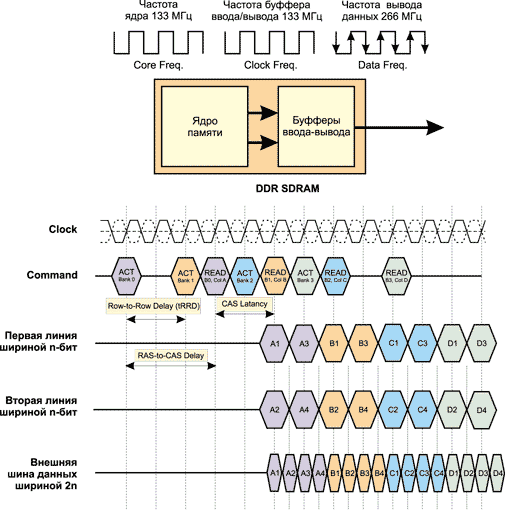
Рис. 9. Упрощенная временная диаграмма работы DDR SDRAM-памяти
Если следовать терминологии SDR (Single Data Rate) и DDR (Double Data Rate), то память DDR2 было бы логично назвать QDR (Quadra Data Rate), поскольку этот стандарт подразумевает в четыре раза большую скорость передачи, то есть в стандарте DDR2 при пакетном режиме доступа данные передаются четыре раза за один такт. Для организации данного режима работы памяти необходимо, чтобы буфер ввода-вывода (мультиплексор) работал на учетверенной частоте по сравнению с частотой ядра памяти. Достигается это следующим образом: ядро памяти, как и прежде, синхронизируется по положительному фронту тактирующих импульсов, а с приходом каждого положительного фронта по четырем независимым линиям в буфер ввода-вывода (мультиплексор) передаются 4n бита информации (выборка 4n битов за такт, 4n-Prefetch). Сам буфер ввода-вывода тактируется на удвоенной частоте ядра памяти и синхронизируется как по положительному, так и по отрицательному фронту этой частоты. Иными словами, с приходом положительного и отрицательного фронтов происходит передача битов в мультиплексном режиме на шину данных. Это позволяет за каждый такт работы ядра памяти передавать четыре слова на шину данных, то есть вчетверо повысить пропускную способность памяти.
По сравнению с памятью DDR память DDR2 обеспечивает ту же пропускную способность, но при вдвое меньшей частоте ядра. К примеру, в памяти DDR-400 ядро функционирует на частоте 200 МГц, а в памяти DDR2-400 — на частоте 100 МГц. В этом смысле память DDR2 имеет гораздо большие потенциальные возможности для увеличения пропускной способности по сравнению с памятью DDR.
В памяти DDR2 реализована схема разбиения массива памяти на четыре логических банка, а для модулей емкостью 1 и 2 Гбайт — на восемь логических банков.
Упрощенная временная диаграмма работы DDR2-памяти на примере операции чтения показана на рис. 10. Пусть имеются два банка памяти (Bank0, Bank1), длина пакета (Burst Length) равна 4, tCAS = 2 и tRCD = 3, tRRD = 2. Первоначально необходимо активировать оба банка и получить доступ к строке в этом банке. Тогда через каждые два такта активируется новый банк, а через каждые три такта после активации банка следует команда чтения данных из этого банка.
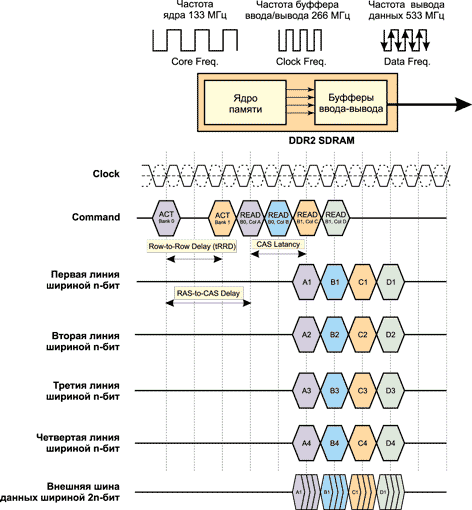
Рис. 10. Упрощенная временная диаграмма работы DDR2-памяти
Поскольку задержка CAS Delay составляет два такта, то через два такта после команды чтения данные могут быть считаны с шины данных. Напомним, что у нас имеются четыре шины данных (линии) шириной n бит каждая и передача данных может происходить параллельно по каждой из этих линий. В нашем упрощенном примере можно считать, что слова A1-A4, соответствующие первому банку, одновременно (в течение одного такта) передаются по четырем линиям. На следующем такте по четырем линиям одновременно передаются слова B1-B4 и т.д.
Далее эти данные передаются в мультиплексор синхронно с положительным фронтом тактового импульса. Поскольку мультиплексор работает на удвоенной частоте и выводит данные по шине шириной n бит синхронно с положительным и отрицательным фронтами, за один такт работы ядра памяти осуществляется вывод на шину данных 4n бит (четыре слова).
Понятно, что в случае реализации архитектуры 4n-Prefetch длина пакета (Burst Length) данных не может быть менее 4. Поэтому для памяти DDR2 минимальная длина пакета составляет 4.
Память стандарта DDR3 можно рассматривать как логическое развитие стандарта DDR2. Для памяти DDR3 реализована 8-банковая логическая структура. Принципиальное отличие памяти DDR3 от памяти DDR2 заключается в реализации механизма 8n-Prefetch вместо 4n-Prefetch.
Для организации данного режима работы памяти необходимо, чтобы буфер ввода-вывода (мультиплексор) работал на частоте в 8 раз большей по сравнению с частотой ядра памяти. Достигается это следующим образом: ядро памяти, как и прежде, синхронизируется по положительному фронту тактирующих импульсов, а с приходом каждого положительного фронта по восьми независимым линиям в буфер ввода-вывода (мультиплексор) передаются 8n бита информации (выборка 8n битов за такт). Сам буфер ввода-вывода тактируется на учетверенной частоте ядра памяти и синхронизируется как по положительному, так и по отрицательному фронту данной частоты. Это позволяет за каждый такт работы ядра памяти передавать восемь слов на шину данных, то есть в восемь раз повысить пропускную способность памяти.
По сравнению с памятью DDR2, DDR3-память обеспечивает ту же пропускную способность при вдвое меньшей частоте ядра. К примеру, в памяти DDR2-800 ядро функционирует на частоте 200 МГц, а в памяти DDR3-800 — на частоте 100 МГц (рис. 11).
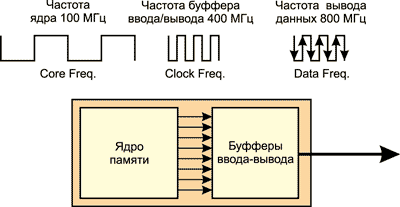
Рис. 11. Реализация метода 8n-Prefetch
Понятно, что в случае реализации архитектуры 8n-Prefetch длина пакета (Burst Length) данных не может быть менее 8. Поэтому для памяти DDR2 минимальная длина пакета составляет 8.
Упрощенная временная диаграмма работы DDR3-памяти для BL = 8, tRRD = 2, tRCD = 3 и tCL = 2 показана на рис. 12.
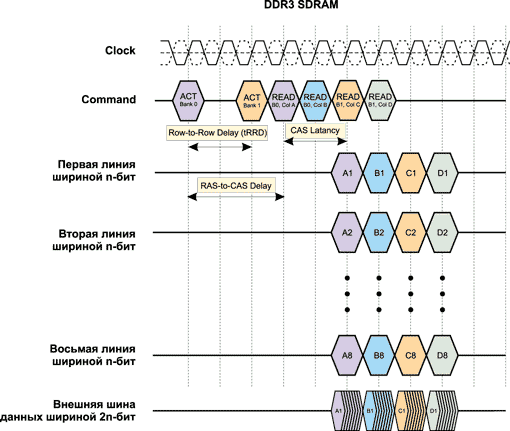
Рис. 12. Упрощенная временная диаграмма работы памяти DDR3
Методика тестирования
Итак, после краткого и довольно поверхностного обзора базовых принципов функционирования SDRAM-памяти перейдем к основной теме нашей статьи. На всякий случай напомним, что мы хотели выяснить, насколько критичны для современной памяти DDR3 высокая тактовая частота и низкие тайминги.
Для тестирования мы использовали стенд следующей конфигурации:
- процессор — Intel Core 2 Extreme QX9650;
- системная плата — ASUS P5K3 Deluxe;
- чипсет системной платы — Intel P35 (Bearlake);
- тип памяти — DDR3 (Patriot PDC32F 1866LLK (PC3-1866));
- объем памяти — 2 Гбайт (два модуля емкостью по 1024 Мбайт);
- видеокарта — MSI NX8800GTX (GPU NVIDIA GeForce 8800GTX; 768 Мбайт видеопамяти GDDR3);
- видеодрайвер — nForce NVIDIA ForceWare 169.26;
- жесткий диск — Seagate Barracuda ST3120827AS (120 Гбайт, 7200 RPM, SATA).
Традиционно для тестирования памяти применяют различные синтетические бенчмарки, позволяющие определить пропускную способность подсистемы памяти, латентность памяти и т.д. Однако результаты таких синтетических тестов очень сложно ассоциировать с реальной производительностью системы в различных приложениях. Нас же в первую очередь интересовало именно влияние настроек памяти на производительность системы в целом. Поэтому в нашем тестировании памяти мы сделали акцент именно на реальные приложения, а не на синтетические тесты.
При тестировании памяти мы использовали методику, которую традиционно применяем для сравнительного тестирования компьютеров. Подробную методику тестирования компьютеров мы уже неоднократно разбирали на страницах нашего журнала, поэтому здесь лишь вкратце напомним основные моменты.
Тестирование проводилось под управлением операционной системы Windows Vista Ultimate 32-bit (английская версия).
Наша методика тестирования предполагает три этапа: подготовка, обучение и получение результатов.
Этап подготовки заключается в установке операционной системы, всех драйверов и обновлений, а также необходимых бенчмарков и приложений. На этапе обучения системы производится сбор и анализ необходимых для самонастройки операционной системы данных, а на этапе получения результатов тестирования — собственно тестирование системы.
При тестировании каждый тест запускается пять раз с перезагрузкой компьютера после каждого прогона теста и выдерживанием двухминутной паузы после перезагрузки. По результатам пяти прогонов теста рассчитываются средний арифметический результат и среднеквадратичное отклонение.
Весь процесс тестирования по описанной схеме был полностью автоматизирован, для чего был разработан соответствующий скрипт. Он последовательно запускал все необходимые тесты, выполнял этап подготовки системы и перезагружал компьютер, выдерживал необходимые паузы и т.д., то есть действовал по принципу «вечером запустил — утром получил результаты». Кроме того, использование такого скрипта полностью исключает человеческий фактор, то есть возможность появления ошибки в ходе тестирования.
Используемые бенчмарки и приложения
Для тестирования памяти мы применяли следующие бенчмарки и приложения:
- Futuremark 3DMark06 v.1.1.0;
- Futuremark PCMark05 v. 1.2.0;
- Lame 4.0 Beta;
- WinRAR 3.71;
- 7-Zip 4.57;
- Windows Media Encoder 9.0;
- MainConcept Reference v.1.0;
- DivX Converter 6.5;
- DivX Codec 6.8;
- DivX Player 6.6;
- Adobe Photoshop CS3;
- Microsoft Excel 2007.
Тест Futuremark 3DMark06 v.1.1.0 запускался при отключенных функциях антиалиасинга (Anti-Aliasing: None) и режима фильтрации Optimal (Filtering: Optimal) и при разрешении экрана 640x480.
В настройках теста Futuremark PCMark05 v. 1.2.0 выбирались подтесты System Test Suite, CPU Test Suite, Memory Test Suite, Graphics Test Suite и HDD Test Suite.
Приложение Lame 4.0 Beta использовалось для определения производительности при конвертировании аудиофайлов из формата WAV в формат MP3. Исходный WAV-файл имел размер 619 Мбайт, а кодирование осуществлялось с битрейтом 192 Кбит/с. Результатом теста являлось время конвертирования — чем оно меньше, тем выше производительность.
Приложения WinRAR 3.71 и 7-Zip 4.57 применялись для определения производительности при архивировании и разархивировании большого массива данных. В качестве тестового задания для архивирования служила директория размером 548 Мбайт, содержащая 743 файла. Результатами этих тестов являлось время архивирования и разархивирования — чем оно меньше, тем выше производительность.
Приложение Windows Media Encoder 9.0 использовалось для определения производительности процессора при конвертировании видеофайла размером 150 Мбайт, записанного в формате WMV, в видеофайл с меньшими разрешением и видеобитрейтом. Исходный файл имел разрешение 1440x1080 и видеобитрейт 8000 Кбит/с, а результирующий — разрешение 320x240 и видеобитрейт 282 Кбит/с.
Приложение DivX Converter 6.5 с кодеком DivX Codec 6.8 применялось для определения производительности при конвертировании исходного видеофайла размером 150 Мбайт, записанного в формате WMV и имеющего разрешение 1440x1080 и видеобитрейт 8000 Кбит/с, в видеофайл формата DivX с разрешением 720x540 и видеобитрейтом 4854 Кбит/с (предустановка Ноme Theater в приложении DivX Converter 6.5).
Приложение MainConcept Reference v.1.0 (кодек H.264) использовалось для определения производительности при конвертировании исходного видеофайла размером 203 Мбайт, записанного в формате WMV и имеющего разрешение 1280x544 в видеофайл с разрешением 1280x720 и видеобитрейтом 8000 Кбит/с (предустановка Н.264 HDTV 720p).
Приложение DivX Player 6.6 применялось в паре с приложением Windows Media Encoder 9.0 для создания многозадачного теста. Смысл этого теста заключался в том, чтобы на фоне проигрывания видеофайла с разрешением 1440x1080 и битрейтом 8000 Кбит/с с применением приложения DivX Player 6.6 запустить процесс конвертирования этого же видеофайла с помощью приложения Windows Media Encoder 9.0. Результирующий файл имел разрешение 320x240 и видеобитрейт 282 Кбит/с. Результатом теста являлось время конвертирования видеофайла.
Еще один многозадачный тест заключался в том, чтобы проигрывать видеофайл при помощи приложения DivX Player 6.6 и одновременно с этим реализовать конвертирование этого же видеофайла с использованием приложения Windows Media Encoder 9.0, конвертирование аудиофайла из формата WAV в формат MP3 посредством приложения Lame 4.0 Beta и архивирование большого массива данных с применением архиватора WinRAR 3.71. То есть в данном тесте мы реализовали одновременное выполнение большинства тех тестов, которые ранее производились по отдельности.
Приложение Adobe Photoshop CS3 использовалось нами для определения производительности системы при обработке цифровых фотографий. Наш тест с приложением Adobe Photoshop CS3 мы разбили на два подтеста. В первом из них мы последовательно применяли различные ресурсоемкие фильтры к одной и той же фотографии, имитируя при этом процесс художественной обработки фотографии, Всего использовалось десять фильтров: Radial Blur (Spin), Radial Blur (Zoom), Shape Blur, Smart Blur, Surface Blur, Twirl, Polar Coordinates, Spherize, ZigZag и Filter Gallery (Colored Pencil). Результатом данного теста стало время последовательного выполнения всех фильтров, включая время открытия файла и время его сохранения в формате TIF.
В следующем подтесте с приложением Adobe Photoshop CS3 имитировалась пакетная обработка большого количества фотографий. Обработка каждой фотографии не отнимает много времени и включает типичные операции, как-то: открытие файла, дублирование слоя, наложение слоев, объединение слоев, изменение размера фотографии и сохранение результатов в формате TIF. Все эти типичные операции являются однопоточными и не позволяют выявить преимущества многоядерной архитектуры. Однако именно с этими простейшими операциями и приходится, как правило, сталкиваться при редактировании фотографий, а потому этот тест хоть и не позволяет выявить преимущества многоядерной архитектуры, но более актуален. Всего в тесте проводилась пакетная обработка 50 фотографий, сделанных 10-мегапиксельной камерой. Результатом данного теста являлось время пакетной обработки всех фотографий.
Приложение Microsoft Excel 2007 применялось для определения производительности системы при выполнении вычислений в электронных таблицах Excel. Мы использовали две задачи в приложении Excel. Первая заключалась в пересчете электронной таблицы размером 6,2 Мбайт, включающей 28 тыс. записей, с помощью таких математических операций, как сложение, вычитание, деление, округление и вычисление квадратного корня. Кроме того, применялись операции статистического анализа, такие как нахождение максимального и минимального значений, среднего значения и т.п. Вторая задача состояла в имитации метода Монте-Карло для вероятностной оценки экономического риска. Данный тест насчитывал 300 тыс. итераций, а таблица Excel с исходными данными имела размер 70,1 Мбайт.
Дабы получить возможность сравнения производительности системы не на отдельных приложениях, а интегрально, то есть на наборе приложений, мы воспользовались понятием интегральной производительности. Интегральный показатель производительности отражает усредненную по всему набору применяемых для тестирования приложений относительную производительность системы. Для расчета относительной производительности компьютера использовалось понятие референсной системы, представляющей собой память в режиме DDR3-1333 в двухканальном режиме со следующими значениями таймингов:
- CAS# Latency (tCL) — 7;
- RAS# to CAS# Delay (tRCD) — 7;
- RAS# PRE Time (tRP) — 7;
- RAS# ACT Time (tRAS) — 20;
- RAS# to RAS# Delay (tRRD) — 4;
- REF Cycle Time (tRC) — 48;
- WRITE Recovery Time (tWR) — 8;
- WRITE to READ Delay (tWTR) — 4;
- READ to PRE Time (tRTP) — 4.
В дальнейшем для простоты тайминги памяти мы будем записывать в виде следующей последовательности:
tCL-tRCD-tRP-tRAS-tRRD-tRC-tWR-tWTR-tRTP. Соответственно для референсной конфигурации применялась следующая последовательность таймингов: 7-7-7-20-4-48-8-4-4.
Для референсной конфигурации результаты каждого теста принимались равными единице.
Для расчета интегрального показателя производительности первоначально результаты всех тестов нормировались на соответствующие результаты референсной системы. Далее вычислялось среднее геометрическое всех нормированных результатов. При расчете среднего результата в тесте 3DMark06 учитывался только результат 3DMark Score. Аналогично в тесте PCMark05 учитывался только результат PCMark Score. Полученный таким образом результат представлял собой интегральный показатель производительности.
Результаты тестирования
Зависимость производительности от тактовой частоты и режима работы памяти
На первом этапе мы протестировали память DDR3 в одноканальном и двухканальном режимах работы при различных частотах. Тайминги памяти при этом не изменялись и составляли следующую последовательность: 7-7-7-20-4-48-8-4-4. Изменение частоты памяти производилось через настройки BIOS путем изменения коэффициента отношения FSB:DRAM. Всего было использовано пять значений частоты памяти: 800, 835, 887, 1066 и 1333 МГц.
Результаты тестирования представлены на рис. 13 и 14. Глядя на результаты, представленные на рисунках, создается впечатление, что интегральная производительность системы сильно зависит и от режима работы памяти (одноканальный, двухканальный), и от частоты памяти. Однако на самом деле это не более чем иллюзия. Давайте повнимательнее присмотримся к результатам тестирования.
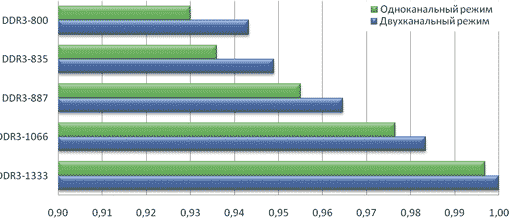
Рис. 13. Сравнение одноканального и двухканального режимов работы памяти
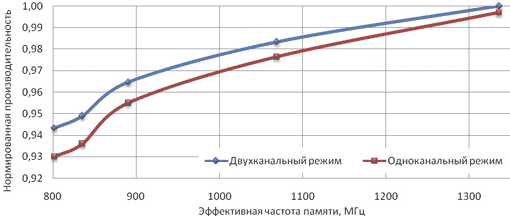
Рис. 14. Зависимость производительности системы от частоты
и режима работы памяти
Сравнение одноканального режима работы памяти при частоте 800 МГц с двухканальным режимом работы памяти при частоте 1333 МГц показывает, что интегральная производительность системы в этих режимах отличается всего на 7%!
Причем в реальной ситуации разница в производительности будет еще меньше. Дело в том, что в памяти DDR3 при частоте 800 МГц используются меньшие тайминги, чем при частоте 1333 МГц. В нашем же случае при всех значениях частоты работы памяти применялись одни и те же тайминги.
Характерно, что с ростом тактовой частоты разница в производительности между одноканальным и двухканальным режимами работы становится все менее значимой. Так, при частоте 800 МГц разница в производительности между одноканальным и двухканальным режимами работы равна примерно 1,4%, а при частоте 1333 МГц та же разница составляет всего 0,3%.
Экстраполируя полученные результаты на более высокие тактовые частоты, можно предположить, что при частоте 1600 МГц разница по производительности между одноканальным и двухканальным режимами работы вообще станет ничтожно малой.
Полученные результаты можно объяснить следующим образом. Большинству современных приложений вполне хватает пропускной способности памяти в одноканальном режиме при частоте выше 1000 МГц, поэтому дальнейшее увеличение тактовой частоты и использование двухканального режима работы не позволяет получить существенного выигрыша в производительности.
Если говорить о зависимости производительности от тактовой частоты, то эмпирически можно вывести следующую зависимость.
Начиная с тактовой частоты 900 МГц в одноканальном режиме работы производительность системы увеличивается примерно на 0,94% при увеличении тактовой частоты на 100 МГц, а в двухканальном режиме — на 0,79%.
Если рассмотреть зависимость производительности в отдельных приложениях от частоты и режима работы памяти, то можно отметить, что наиболее критичными к частоте и режиму работы памяти являются архиваторы WinRAR 3.71 и 7-Zip 7.54. Так, разница по производительности при частоте 1333 и 800 МГц в двухканальном режиме работы составляет примерно 17% как для архиватора WinRAR 3.71, так и для 7-Zip 7.54.
Практически нечувствительны к частоте памяти и режимам работы такие приложения, как Lame 4.0 Beta (аудиокодирование), 3DMark06, Excel 2007 и Photoshop CS3 (использование фильтров). Для остальных же приложений разница в производительности при частоте 1333 и 800 МГц колеблется от 5 до 9%.
Ну и в заключение несколько слов об оптимальности памяти DDR3. Сегодня в продаже встречается память DDR3-1066, DDR3-1333, DDR3-1600 и DDR3-1800. Отметим, что пока еще нет чипсетов, поддерживающих работу памяти на частоте 1600 МГц и выше в штатных режимах, поэтому для памяти DDR3-1600 и DDR3-1800 работа на частотах 1600 и 1800 МГц соответственно отвечает условиям разгона системы.
Средняя стоимость за 1 Гбайт памяти DDR3-1066 составляет 4300 руб., памяти DDR3-1333 — 5000 руб., памяти DDR3-1600 — 5600 руб., а памяти DDR3-1800 — 8400 руб.
Итак, что же мы видим? Давайте сравним память DDR3-1066 и DDR3-1333. Разница по стоимости составляет примерно 16%, а разница по производительности — всего 1,7%.
Разница по стоимости памяти DDR3-1600 и DDR3-1066 составляет примерно 30%, а разница по цене вряд ли превышает 2%. Естественно, что со временем цена памяти DDR3 снизится, однако и в этом случае наилучшим соотношением цены и качества будет обладать память DDR3-1066.
Зависимость производительности памяти от таймингов
Зависимость производительности системы от таймингов мы рассматривали при работе памяти в двухканальном режиме на частоте 800, 1066 и 1333 МГц. Для каждой из этих частот были определены минимально возможные тайминги, при которых система работала стабильно. Это позволило нам сравнить производительность системы в случае применения таймингов памяти 7-7-7-20-4-48-8-4-4 с производительностью системы при использовании разогнанных таймингов. Попутно отметим, что для применяемой нами в тестировании памяти DDR3 Patriot PDC32F 1866LLK тайминги 7-7-7-20-4-48-8-4-4 используются по умолчанию для режима DDR3-1333. Еще раз напомним, что в качестве референсных мы взяли результаты, полученные для памяти в режиме DDR3-1333 (двухканальный режим работы) с таймингами 7-7-7-20-4-48-8-4-4.
Способ разгона таймингов памяти достаточно прост. Первоначально берут тайминги по умолчанию, а затем последовательно уменьшают значения таймингов, начиная с тайминга tCL. После того как определено минимальное значение тайминга tCL, при котором система загружается и стабильно работает, переходят к поиску минимального значения тайминга tRCD и так далее по цепочке tCL-tRCD-tRP-tRAS-tRRD-tRC-tWR-tWTR-tRTP.
Итак, методом проб и ошибок было установлено, что для тактовой частоты 800 МГц минимально возможные тайминги, при которых работа системы стабильна, составляют последовательность 5-3-3-5-1-30-1-4-1; для тактовой частоты 1066 МГц — 5-4-3-10-2-36-6-4-4, а для тактовой частоты 1333 МГц — 6-5-4-14-2-36-6-4-4. Во всех случаях напряжение питания составляло 1,9 В.
Еще раз заметим, что наибольшее влияние на производительность системы оказывают основные тайминги, то есть tCL-tRCD-tRP-tRAS. Остальные тайминги слабо влияют на производительность, но их уменьшение может сказываться на стабильности работы системы, поэтому гнаться за минимальным значением дополнительных таймингов большого смысла не имеет.
Результаты зависимости производительности от таймингов показаны на рис. 15.
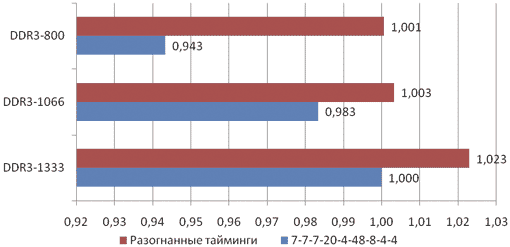
Рис. 15. Зависимость производительности системы от таймингов памяти
Итак, проанализируем полученные результаты.
Прежде всего нужно отметить, что для всех тактовых частот максимальный разгон таймингов позволяет достичь примерно равной производительности!
Если отталкиваться от зафиксированных нами в качестве референсных таймингов 7-7-7-20-4-48-8-4-4, то можно заметить, что с ростом тактовой частоты прирост производительности от разгона памяти по таймингам уменьшается. Так, если для частоты 800 МГц прирост производительности составляет почти 6%, то для частоты 1066 МГц прирост производительности равен всего 2%, а для частоты 1333 МГц — 2,3%.
Впрочем, нужно заметить, что на практике чем ниже тактовая частота памяти, тем лучше тайминги памяти. Поэтому не вполне корректно сравнивать работу памяти на различной частоте с одними и теми же таймингами.
В целом можно констатировать, что для современной памяти DDR3 разгон по таймингам, как, впрочем, и разгон по частоте, малоэффективен.








