Процессоры семейства Intel Core i7
Процессорная микроархитектура Nehalem
Ядро процессора на базе микроархитектуры Nehalem
Выборка и предварительное декодирование инструкций
Буфер ассоциативной трансляции
Переименование и распределение дополнительных регистров
Переупорядочение микроопераций
Набор расширений инструкций SSE4.2
Технология Hyper-Тhreading в микроархитектуре Nehalem
Иерархия кэш-памяти в микроархитектуре Nehalem
Турбо-режим в процессорах Intel Core i7
О новой процессорной микроархитектуре Intel Core i7, известной также под кодовым названием Nehalem, говорят уже не первый год. В преддверии массового производства процессоров нового поколения появлялось все больше подробностей относительно этой микроархитектуры. В течение года мы публиковали всю известную нам информацию о процессорах Intel следующего поколения. И вот наконец 17 ноября эти процессоры были объявлены официально и, более того, стали доступны для тестирования. Что ж, пришло время обобщить все данные, касающиеся новых процессоров Intel Core i7.
Кратко о самом важном
Как известно, в следующем году Intel собирается приступить к массовому выпуску процессоров семейства Intel Core i7 (Nehalem) для всех сегментов рынка. Четырехъядерный процессор Intel Core i7 с кодовым названием Bloomfield для сегмента высокопроизводительных настольных ПК и двухпроцессорных серверных систем уже доступен для заказа партнерам компании Intel, однако его появления в розничной торговле стоит ожидать только в будущем году.
Отличительной особенностью процессоров Intel Core i7 является наличие в них интегрированного контроллера памяти DDR3, а следовательно, с памятью DDR2 они будут уже несовместимы. Причем в процессоре Bloomfield будет применяться уже трехканальный контроллер памяти (Integrated Memory Controller, IMC) DDR3, поддерживающий память DDR3-1333, DDR3-1066 и DDR3-800. Интегрированный контроллер памяти может использовать до двух DIMM-слотов на каждый канал, то есть на материнских платах для процессоров Intel Core i7 будет располагаться шесть слотов памяти.

Важно отметить, что никакой особой трехканальной DDR3-памяти для процессоров Intel Core i7 не потребуется. Все заявления производителей памяти относительно выпуска новой трехканальной DDR3-памяти для таких процессоров — не более чем анонс новой упаковки для старых модулей. Если ранее DDR3-память продавалась наборами по два модуля в одной упаковке, то теперь набор будет включать три одинаковых модуля самой обычной DDR3-памяти. В принципе, никто не запрещает применять один или два модуля DDR3-памяти в ПК на базе процессора Intel Core i7, но в этом случае память будет работать в одно- или двухканальном режиме соответственно. Для работы памяти в трехканальном режиме, когда реализуется весь потенциал трехканального контроллера памяти, потребуется использовать три одинаковых модуля памяти. Отметим также, что контроллер памяти, интегрированный в процессор Intel Core i7, поддерживает спецификацию XMP, что позволяет в случае применения соответствующих модулей эффективно разгонять память.
Следующая особенность процессоров семейства Intel Core i7 заключается в том, что на кристалле процессора расположен разделяемый между всеми ядрами кэш L3. Отметим, что в некоторых моделях процессоров Intel Core i7 (предположительно в процессорах для ноутбуков) кэш L3 может и отсутствовать.
Напомним, что в процессорах с архитектурой Intel Core установлен разделяемый между всеми ядрами кэш L2. В процессорах с архитектурой Nehalem кэш L2 не является разделяемым и находится в эксклюзивном использовании каждого ядра процессора, но зато появился разделяемый кэш L3.
В процессоре Bloomfield каждому ядру процессора отводится кэш L2 размером 256 Кбайт.
Еще одна особенность процессоров семейства Intel Core i7 заключается в том, что вместо шины FSB, которая ранее применялась для связи процессора с чипсетом, теперь используется принципиально иной интерфейс, называемый Intel QuickPath Interconnect (QPI). Эта шина увеличивает скорость передачи данных в 4-8 раз по сравнению с шиной FSB. Соответственно на кристалле процессора располагается и контроллер шины QPI.
Шина QPI применяется для связи процессора с чипсетом и для связи процессоров друг с другом (в случае многопроцессорных конфигураций).
QPI является последовательной высокоскоростной двунаправленной шиной. Ее ширина в каждую сторону (передача и прием) составляет по 20 бит (20 отдельных пар линий), при этом 16 бит отводится для передачи данных, две линии зарезервированы для передачи служебных сигналов и еще две — для передачи кодов коррекции ошибок CRC. C учетом еще двух пар линий, используемых для синхронизации сигналов (одна на прием и одна на передачу), получаем, что шина QPI состоит из 42 пар линий, то есть является 84-контактной. Теоретическая пропускная способность шины QPI составляет 25,6 Гбайт/с, хотя такая единица измерения, как гигабайт в секунду (Гбайт/с), более не будет служить характеристикой QPI-шины. Вместо этого будет применяться термин «трансферы в секунду» — количество передач запакетированных данных по шине в секунду.
Вообще нужно отметить, что архитектура процессора Intel Core i7 подразумевает модульную двухуровневую структуру (рис. 1). На одном уровне (уровень Core Logic) располагаются ядра процессора, количество которых, как уже отмечалось, может варьироваться от двух до восьми. На другом уровне (уровень Uncore Logic) находятся такие компоненты процессора, как L3-кэш, контроллер памяти и интерфейсы QPI. Причем компоненты уровня Core Logic, то есть ядра процессора, и компоненты уровня Uncore Logic и электрически, и по частоте независимы друг от друга. Это означает, что компоненты уровня Uncore Logic не синхронизованы по частоте с ядрами процессора, то есть кэш L3 будет работать на частоте, отличающейся от частоты работы ядер процессора и соответственно кэшей L1 и L2. Однако частоту работы элементов Ucore Logic компания Intel не раскрывает. Известно лишь, что все компоненты уровня Uncore Logic (контроллер памяти, кэш L3 и шина QPI) работают на одной частоте. Тут следует подчеркнуть, что частота работы контроллера памяти и частота работы памяти хотя и связаны между собой, но это не одно и то же, а зная, что QPI процессора имеет характеристику, к примеру, 6,4 GT/s (гигатрансфера/с), нельзя сказать, какой при этом будет работа шины QPI. Известно лишь, что максимальная частота работы компонентов Uncore Logic составит 2, 8 ГГц, а максимальная частота ядер процессора — 3,2 ГГц.
При этом пользователю предоставляется возможность через настройки BIOS разгонять по частоте элементы Uncore Logic, но разгон производится синхронно для всех элементов уровня. Это означает также, что каждый процессор ориентирован на использование только одного типа памяти. То есть если процессор поддерживает память DDR3-1066, то с ним, в принципе, можно применять и менее скоростную память, но в этом случае понизится частота и всех остальных компонентов уровня Uncore Logic. К примеру, существуют варианты процессоров Bloomfield с QPI 6,4; 4,8 и 3,2 GT/s. Процессор с QPI 6,4 GT/s поддерживает память DDR3-1333, процессор с QPI 4,8 GT/s — память DDR3-1066, ну а процессор с QPI 3,2 GT/s — DDR3-800.
Кроме того, в некоторые модели процессоров Intel Core i7 также будет интегрироваться графический контроллер, который ранее, так же как и контроллер памяти, интегрировался в северный мост чипсета. Причем в новые процессоры будет интегрироваться тот самый графический контроллер, который имеется сегодня у Intel. Естественно, название графического контроллера будет иным, но никаких конструктивных изменений в его архитектуре пока производиться не будет. Правда, нужно иметь в виду, что если ранее графический контроллер был составной частью северного моста чипсета и выполнялся (как и сам чипсет) по 90-нм техпроцессу, то теперь он станет составной частью процессора и, как и сам процессор, будет выполняться по 45-нм техпроцессу. Вероятно, это позволит увеличить тактовую частоту графического ядра, а значит, и производительность интегрированной графики.
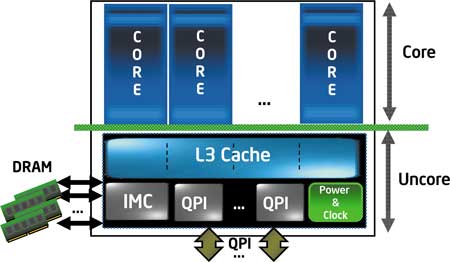
Рис. 1. Двухуровневая структура процессора Intel Core i7
Следующий интересный момент заключается в том, что процессоры семейства Intel Core i7 поддерживают технологию многопоточной обработки Hyper-Threading. Напомним, что данная технология использовалась еще в процессорах Intel Pentium 4 с микроархитектурой NetBurst, однако в процессорах c микроархитектурой Intel Core она отсутствовала. С учетом технологии Hyper-Threading операционная система будет видеть четырехъядерный процессор как восемь отдельных логических процессоров или ядер.
Еще одна инновационная особенность процессоров семейства Intel Core i7 заключается в том, что они поддерживают новый режим Turbo Mode, смысл которого состоит в динамической подстройке тактовых частот ядер процессора.
Новые процессоры Intel Core i7 совместимы с чипсетом Intel X58 Express (кодовое название Tylersburg) и несовместимы с чипсетами Intel 4-й серии. Чипсет Intel X58 Express представляет собой двухчиповое решение: северный мост плюс традиционный южный мост. Причем будет применяться южный мост ICH10R, то есть тот самый, который сейчас используется в чипсетах Intel 4-й серии.
Связь между процессором и северным мостом чипсета реализуется по шине QPI (соответственно в северном мосте чипсета есть контроллер QPI), а связь между северным и южным мостами чипсета — по традиционной шине DMI.
Отметим, что и процессор, и северный и южный мосты чипсета тактируются частотой 133,33 МГц.
За счет переноса контроллера памяти на процессор северный мост чипсета Tylersburg существенно упростится. Он включает 32 линии PCI Express 2.0 и поддерживает два интерфейса PCI Express 2.0 x16 в режиме «x16 + x16» или четыре интерфейса PCI Express 2.0 x8 в режиме «x8 + x8 + x8 + x8». Также возможны конфигурации c тремя интерфейсами PCI Express 2.0 x16, функционирующими в режиме «x16 + x8 + x8».
Кроме того, в чипсете Intel X58 Express предусмотрена поддержка режима NVIDIA SLI. Ранее сообщалось, что данный режим в материнских платах на чипсете Intel X58 Express будет реализован аппаратным образом за счет использования микросхемы nForce 200. Однако позднее было объявлено, что поддержка режима SLI возможна и на программном уровне (на уровне BIOS) без применения микросхемы nForce 200. Скорее всего, на большинстве материнских плат будет реализован именно этот способ. Платы на базе чипсета Intel X58 Express могут поддерживать режимы SLI (две видеокарты), 3-Way SLI (три видеокарты) и Quad SLI (четыре видеокарты).
Таким образом, платы на базе чипсета Intel X58 Express можно будет использовать как с видеокартами ATI в режиме CrossFire, так и с видеокартами NVIDIA в режиме SLI.
В настоящее время производится три варианта процессора Bloomfield: Intel Core i7-965 Extreme Edition, Intel Core i7-940 и Intel Core i7-920. Процессор Intel Core i7-965 Extreme Edition имеет тактовую частоту 3,2 ГГц и скорость QPI 6,4 GT/s; процессор Intel Core i7-940 — тактовую частоту 2,93 ГГц и скорость QPI 4,8 GT/s, ну а Intel Core i7-920 — тактовую частоту 2,66 ГГц и скорость QPI 4,8 GT/s. Кроме разницы в тактовой частоте и скорости QPI, процессор Intel Core i7-965 Extreme Edition отличается от моделей Intel Core i7-940 и Intel Core i7-920 еще и тем, что в нем разблокирован коэффициент умножения, а следовательно этот процессор можно разгонять за счет изменения не только частоты системной шины, но и коэффициента умножения.
Все процессоры Bloomfield изготавливаются по 45-нанометровой технологии, а их TDP составляет 130 Вт. Для процессоров Bloomfield размер L3-кэша составляет 8 Мбайт.
Кроме того, процессор Bloomfield имеет разъем LGA 1366 (то есть у процессора будет уже 1366 контактов) и, естественно, несовместим с разъемом LGA 775. Размер упаковки процессора составит 42,5x45 мм (размер упаковки процессора с разъемом LGA 775 — 37,5x37,5 мм). Важно, что для процессора Bloomfield потребуется кулер, совместимый именно с разъемом LGA 1366, а вот использование кулеров под разъем LGA 775 принципиально невозможно.

Конструктивно процессор Bloomfield представляет собой четыре ядра на одном кристалле, то есть является истинно четырехъядерным и содержит 731 млн транзисторов.
Вслед за процессором Bloomfield в 2009 году появится четырехъядерный процессор Lynnfield и двухъядерный процессор Havendale. Они будут ориентированы уже на сегмент массовых ПК и оснащены разъемом LGA 1160. То есть процессоры нового поколения будут существовать с двумя вариантами разъемов, что, конечно же, создаст для пользователей определенные неудобства.
После ознакомления с особенностями нового семейства процессоров Intel Core i7 давайте более детально рассмотрим характеристики нового процессора и новой микроархитектуры Nehalem.
Процессорная микроархитектура Nehalem
Новая микроархитектура Nehalem, по сути, является продолжением микроархитектуры Intel Core, а потому они очень похожи, но вместе с тем между ними имеются и важные различия, в том числе различна длина конвейера: в микроархитектуре Nehalem она насчитывает 16 ступеней, а в микроархитектуре Intel Core — 14.
Ядро процессора на базе микроархитектуры Nehalem
Напомним, что в основе архитектуры любого процессора лежит несколько конструктивных элементов: кэш команд и данных, предпроцессор (Front End) и постпроцессор, который также называется блоком исполнения команд (Execution Engine).
Процесс обработки данных состоит из нескольких характерных этапов: сначала программные инструкции выбираются из кэша инструкций процессора — эта процедура называется выборкой; затем выбранные из кэша инструкции декодируются в понятные для данного процессора примитивы (машинные команды); далее декодированные команды поступают на исполнительные блоки процессора, выполняются, а результат записывается в оперативную память.
Процесс выборки инструкций из кэша, их декодирование и продвижение к исполнительным блокам осуществляются в предпроцессоре (Front End), а процесс выполнения декодированных команд — в постпроцессоре (Execution Engine).
Выборка и предварительное декодирование инструкций
При работе процессора на базе микроархитектуры Nehalem инструкции x86 выбираются из кэша инструкций L1 (Instruction Сache) размером 32 Кбайт (рис. 2). Команды загружают из кэша блоками фиксированной длины, из которых выделяются инструкции, направляемые на декодирование. Поскольку инструкции x86 имеют переменную длину, а блоки, которыми команды загружаются из кэша, — фиксированную длину, при декодировании команд нужно определить границы между отдельными командами.
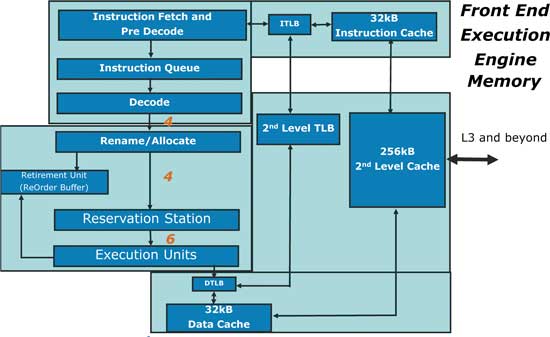
Рис. 2. Структурная схема ядра процессора на базе микроархитектуры
Intel Core и Nehalem
Информация о размерах команд хранится в кэше инструкций L1 в специальных полях (по 3 бита информации на каждый байт инструкций). В принципе, эту информацию для определения границ команд можно было бы использовать в самом декодере непосредственно в процессе их декодирования. Однако это неизбежно отразилось бы на скорости декодирования, к тому же нельзя было бы декодировать одновременно несколько команд. Поэтому перед декодированием производится выделение команд из выбранного блока. Данная процедура называется предварительным декодированием (PreDecode) и позволяет поддерживать постоянный темп декодирования независимо от длины и структуры команд.
В процессорах с микроархитектурой Nehalem, так же как и в процессорах с микроархитектурой Intel Core, выборка команд производится 16-байтными блоками, то есть за каждый такт из кэша загружается 16-байтный блок команд.
Буфер ассоциативной трансляции
Говоря о процедуре выборки инструкций, нужно отметить, что в микроархитектуре Nehalem используется новая двухуровневая иерархия буфера ассоциативной трансляции (Translation Lookaside Buffer, TLB), выполняющего трансляцию виртуальных адресов страниц памяти в физические. То есть если в архитектуре Intel Core традиционно применялись два отдельных TLB-буфера для инструкции (ITLB) и данных (DTLB), которые можно рассматривать как буферы первого уровня, то в архитектуре Nehalem дополнительно введен унифицированный TLB-буфер для данных и команд, то есть буфер второго уровня. TLB-буфер второго уровня рассчитан на 512 записей, причем поддерживаются записи только для страниц памяти размером 4K (Small Page). ITLB-буфер рассчитан на 128 записей страниц памяти типа Small Page и семь записей (в расчете на один поток) для страниц типа Large Page (размером 2M/4M), а буфер DTLB — на 64 записи страниц памяти типа Small Page и 32 записи для страниц типа Large Page.
Loop Stream Detector
Одним из важнейших этапов в процедуре выборки программных инструкций является обнаружение программных циклов. В любом программном коде практически всегда присутствуют программные циклы. Дабы избежать повторов в выполнении одних и тех же операций (предсказания ветвлений, выборки), в процессорах с микроархитектурой Intel Core и Nehalem используется технология обнаружения циклов. Для этого предназначен блок обнаружения программных циклов — буфер Loop Stream Detector, принимающий непосредственное участие в процессе выборки инструкций. В процессорах с микроархитектурой Intel Core применяется буфер Loop Stream Detector на 18 инструкций, причем он располагается до декодера. То есть в архитектуре Intel Core могут отслеживаться и распознаваться только циклы, содержащие не более 18 инструкций. При обнаружении программного цикла инструкции в цикле пропускают фазы выборки (Fetch) и предсказания ветвлений в программе (Branch Prediction), а сами команды генерируются и поступают в декодер непосредственно из Loop Stream Detector (рис. 3). С одной стороны, это позволяет снизить энергопотребление ядра процессора, а с другой — обойти фазу выборки команд. В случае если в цикле насчитывается более 18 инструкций, инструкции каждый раз будут проходить все стандартные шаги.
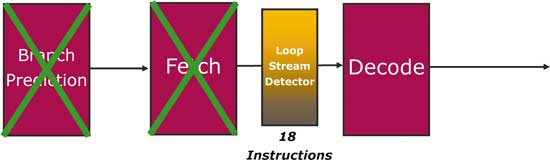
Рис. 3. Расположение модуля Loop Stream Detector в процессоре
с микроархитектурой Intel Core
В архитектуре Nehalem используется улучшенный блок обнаружения циклов, который претерпел некоторые изменения. Теперь он расположен не перед, а за декодером и рассчитан на 28 декодированных инструкций, то есть теперь он может обнаруживать циклы на 60% более длинные (рис. 4). Кроме того, поскольку Loop Stream Detector хранит декодированные инструкции (так как расположен после декодера), инструкции будут «пропускать» не только фазу предсказания ветвлений и выборки, как раньше, но и фазу декодирования. Таким образом, в микроархитектуре Nehalem инструкции в цикле будут проходить через конвейер быстрее и чаще.
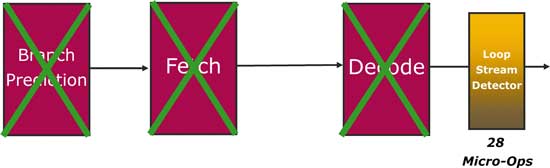
Рис. 4. Расположение модуля Loop Stream Detector в процессоре
с микроархитектурой Nehalem
Декодирование инструкций
После операции выборки команды организуются в очередь (Instruction Queue), а затем передаются в декодер. При декодировании (Decode) команды преобразуются в машинные микрооперации (micro-op).
Декодер ядра процессора с микроархитектурой Intel Core и Nehalem является четырехканальным и может декодировать в каждом такте до четырех инструкций x86. За каждый такт из кэша загружается 16-байтный блок команд, из которого в процессе предварительного декодирования выделяются отдельные команды. В принципе, длина одной команды может достигать 16 байт, однако ее средняя длина составляет 4 байта. Поэтому в среднем в каждом блоке загружается четыре команды, которые при использовании четырехканального декодера одновременно декодируются за один такт.
Четырехканальный декодер состоит из трех простых декодеров, которые декодируют простые инструкции в одну микрооперацию, и одного сложного, способного декодировать одну инструкцию в четыре микрооперации (декодер типа 4-1-1-1). Для еще более сложных инструкций, которые декодируются более чем в четыре микрооперации, сложный декодер соединен с блоком uCode Sequenser, который и служит для декодирования подобных инструкций.
Естественно, что декодирование четырех инструкций за такт возможно только в том случае, если в одном 16-байтном блоке содержится не менее четырех инструкций. Однако существуют команды и длиннее 4 байт, и при загрузке нескольких таких команд в одном блоке эффективность декодирования снижается.
Слияние макроинструкций
При декодировании инструкций в микроархитектуре Intel Core используется технология слияния макроопераций MacroFusion, смысл которой заключается в слиянии двух x86-макроинструкций в одну. В предыдущих версиях процессорной микроархитектуры каждая инструкция в формате x86 декодировалась независимо от остальных. В случае применения технологии MacroFusion некоторые пары инструкций (например, инструкция сравнения и условного перехода) при декодировании могут быть слиты в одну микроинструкцию (micro-op), которая в дальнейшем будет выполняться именно как одна. Для эффективного поддержания технологии MacroFusion в архитектуре Intel Core использовались расширенные блоки ALU (Arithmetical Logic Unit), которые способны поддержать выполнение слитых микроинструкций. Отметим также, что без применения технологии MacroFusion за каждый такт процессора декодировались только четыре инструкции (в четырехканальном декодере). При использовании технологии MacroFusion в каждом такте может считываться пять инструкций, которые преобразуются в четыре за счет слияния и подвергаются декодированию.
В микроархитектуре Nehalem на этапе декодирования также применяется технология MacroFusion. Однако по сравнению с микроархитектурой Intel Core расширен набор команд, для которых возможно слияние макроопераций. Кроме того, в микроархитектуре Intel Core слияние макроопераций не поддерживалось для 64-битного режима работы процессора, то есть технология MacroFusion могла быть реализована только в 32-битном режиме. В архитектуре Nehalem это узкое место устранено и операции слияния работают как в 32-, так и в 64-битном режиме процессора.
Слияние микроопераций
Кроме того, на стадии декодирования и в микроархитектуре Intel Core, и в микроархитектуре Nehalem реализована технология слияния микроопераций micro-ops fusion. Данная технология заключается в том, что в ряде случаев две микрооперации сливаются в одну, содержащую два элементарных действия. В дальнейшем две такие слитые микрооперации обрабатываются как одна, что в результате позволяет снизить количество обрабатываемых микроопераций и тем самым увеличить общее количество исполняемых процессором инструкций за один такт.
Переименование и распределение дополнительных регистров
После процесса декодирования инструкций x86 начинается этап их исполнения. Первоначально происходит переименование и распределение дополнительных регистров процессора (Allocate & Rename), которые не определены архитектурой набора команд. Переименование регистров, позволяющее добиться исполнения команд вне очереди, заключается в следующем. В архитектуре x86 количество регистров общего назначения сравнительно невелико: доступно восемь регистров в 32-битном режиме и 16 — в 64-битном. Представим, что исполняемая команда дожидается загрузки значений операндов в регистр из памяти. Это долгая операция, и хорошо бы на это время позволить использовать данный регистр для другой команды, операнды которой находятся ближе (например, в кэше первого уровня). Для этого временно переименовывается «ждущий» регистр и отслеживается история переименования. А «готовому к работе» регистру присваивается стандартное имя, чтобы снабженную операндами команду исполнить прямо сейчас. Когда придут данные из памяти, обращаются к истории переименования и возвращают изначальному регистру его законное имя. Иными словами, техника переименования регистров позволяет снизить простои, а ведение истории переименования служит для нивелирования конфликтов.
Переупорядочение микроопераций
На следующем этапе (буфер переупорядочения — ReOrder Buffer, ROB) происходит переупорядочение микроопераций не по принципу очередности их поступления (Out-of-Order) с тем, чтобы впоследствии можно было реализовать их более эффективное выполнение на исполнительных блоках. В микроархитектуре Nehalem увеличен размер буфера переупорядочения (ReOrder Buffer, ROB), и если в микроархитектуре Intel Core он был рассчитан на 98 микроинструкций, то теперь в нем можно размещать 128 микроинструкций.
Отметим, что буфер переупорядочения (ReOrder Buffer) и блок отставки (Retirement Unit) совмещены в едином блоке процессора, но первоначально производится переупорядочение инструкций, а блок Retirement Unit включается в работу позже, когда надо выдать исполненные инструкции в заданном программой порядке.
Распределение микроопераций
Далее происходит распределение микроопераций по исполнительным блокам. В блоке процессора Reservation Station формирует очереди микроопераций, в результате чего микрооперации попадают на один из портов функциональных устройств (dispatch ports). Этот процесс называется диспетчеризацией (Dispatch), а сами порты выполняют функцию шлюза к функциональным устройствам.
Исполнение микроопераций
После того как микрооперации пройдут порты диспетчеризации, они направляются в соответствующие функциональные блоки для дальнейшего выполнения. Переработке подверглись и исполнительные блоки ядра процессора. Процессор на базе микроархитектуры Nehalem способен выполнять до шести операций за один такт. При этом возможно выполнение одновременно трех вычислительных операций и трех операций с памятью (рис. 5).
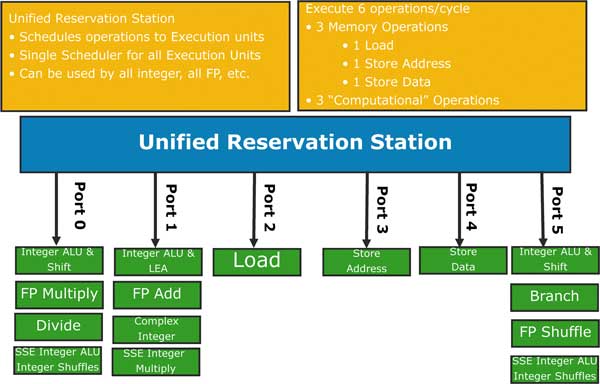
Рис. 5. Исполнительные блоки ядра процессора Nehalem
Набор расширений инструкций SSE4.2
Еще одно существенное нововведение — это новый набор расширений инструкций SSE4.2. Он включает поддержку всех 47 команд SSE4, а также семь новых программно-ориентированных ускорителей (Application Targeted Accelerator, ATA) обработки строк и текстовой информации.
Технология Hyper-Тhreading в микроархитектуре Nehalem
Как известно, технология Hyper-Тhreading используется для того, чтобы наиболее эффективно загрузить все имеющиеся исполнительные блоки процессора и тем самым избежать появления пустых циклов. Технология Hyper-Тhreading была анонсирована компанией Intel еще в 2002 году и, по сути, является технологией многопоточной обработки команд. Фактически она позволяет организовать два логических процессора в одном физическом.
Известно, что технология Hyper-Тhreading, которая будет реализована в микроархитектуре Nehalem, практически ничем не отличается от той, что использовалась в микроархитетуре Intel Burst, а потому мы лишь вкратце напомним основные принципы ее реализации.
Для реализации параллельной обработки инструкции в технологии Hyper-Threading все инструкции разделяются на два параллельных потока.
В конструктивном плане ядро процессора с поддержкой технологии Hyper-Threading состоит из двух логических процессоров, каждый из которых имеет свои регистры и контроллер прерываний (Architecture State, AS), а значит, две параллельно исполняемые задачи работают с собственными независимыми регистрами и прерываниями, но при этом применяют одни и те же ресурсы процессора для выполнения своих задач. После активации каждый из логических процессоров может самостоятельно и независимо от другого процессора выполнять свою задачу, обрабатывать прерывания либо блокироваться. Таким образом, от реальной двухпроцессорной конфигурации новая технология отличается только тем, что оба логических процессора используют одни и те же исполняющие ресурсы, одну и ту же разделяемую между двумя потоками кэш-память и одну и ту же системную шину. Применение двух логических процессоров позволяет усилить параллелизм на уровне потока, реализованный в современных операционных системах и высокоэффективных приложениях. Команды от обоих исполняемых параллельно потоков одновременно посылаются ядру процессора для обработки. Посредством технологии out-of-order (исполнение командных инструкций не в порядке их поступления) ядро процессора тоже способно параллельно обрабатывать оба потока за счет использования нескольких исполнительных модулей.
Идея технологии Hyper-Threading основана на том, что как бы хорошо ни был оптимизирован программный код, не все исполнительные модули процессора оказываются задействованными на протяжении каждого тактового цикла. Было бы вполне логично организовать работу процессора таким образом, чтобы в каждом тактовом цикле максимально использовать его возможности. Именно эту идею и реализует технология Hyper-Threading, подключая незадействованные ресурсы процессора к выполнению параллельной задачи.
Иерархия кэш-памяти в микроархитектуре Nehalem
Как мы уже отмечали, одна из главных особенностей новой микроархитектуры — это изменение структуры кэш-памяти процессора (рис. 6). Собственно, кэш-память первого уровня (L1) практически не претерпела изменений. Изменился лишь размер TLB-буфера и ассоциативность кэша инструкций. Если ранее кэш L1 делился на 32-килобайтный кэш данных и 32-килобайтный кэш инструкций и оба они являлись 8-канальными, а размер их строки составлял 64 байт, то теперь кэш L1 делится на 8-канальный 32-килобайтный кэш данных и 4-канальный 32-килобайтный кэш инструкций.
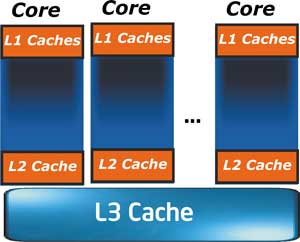
Рис. 6. Структура кэш-памяти процессора Nehalem
Новизна заключается в том, что к каждому ядру процессора теперь добавлен унифицированный (единый для инструкций и данных) кэш второго уровня (L2) размером 256 Кбайт и разделяемый между всеми ядрами процессора кэш третьего уровня (L3).
Кэш L2 также является 8-канальным, а размер его строки составляет 64 байт. Кэш L3 —16-канальный.
Размер разделяемого кэша L3 может быть различным и зависит от числа ядер процессора. В частности, как мы уже отмечали, для четырехъядерного процессора Bloomfield размер L3-кэша составляет 8 Мбайт.
Кэш L3 по своей архитектуре является инклюзивным (inclusive) по отношению к кэшам L1 и L2, то есть в кэше L3 всегда дублируется содержимое кэшей L1 и L2. Однако кэши L1 и L2 по отношению друг к другу не являются ни инклюзивными, ни эксклюзивными.
Использование именно инклюзивного кэша L3 имеет преимущества по сравнению с эксклюзивной архитектурой.
Рассмотрим несколько характерных примеров чтения данных из кэша L3. Предположим сначала, что ядро процессора Core 0, обнаружив, что требуемых ему данных нет ни в кэше L1, ни в кэше L2, обращается к кэшу L3 (рис. 7). Если требуемых данных нет также и в кэше L3, то в случае эксклюзивной архитектуры кэша L3 потребовалось бы также проверить наличие требуемых данных в кэшах L1 и L2 каждого из ядер Core 1, Core 2 и Core 3. В случае инклюзивной архитектуры кэша L3 необходимость в подобной проверке отпадает, поскольку инклюзивная архитектура кэша L3 гарантирует, что при отсутствии данных в кэше L3 их не будет и в кэшах L1 и L2 (рис. 8).
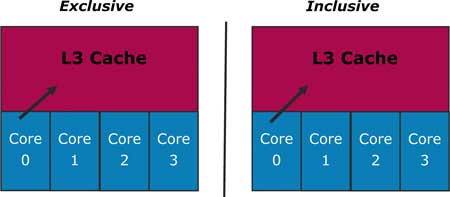
Рис. 7. Ядро Core 0, обнаружив, что требуемых ему данных
нет ни в кэше L1, ни в кэше L2,
обращается к кэшу L3
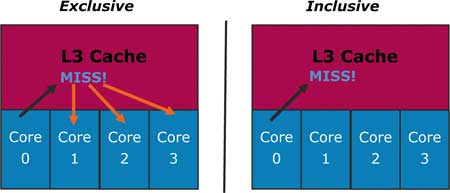
Рис. 8. В случае эксклюзивной архитектуры кэша L3 при отсутствии
данных
в кэше L3 необходимо проверить наличие этих данных
в кэшах L1 и L2 каждого из ядер Core 1, Core 2 и Core 3
Если же требуемые ядру Core 0 данные обнаруживаются в кэше L3 (рис. 9), то при эксклюзивной архитектуре кэша больше не нужно предпринимать каких-либо действий, поскольку данная архитектура гарантирует их отсутствие в кэшах L1 и L2 ядер Core1, Core 2 и Core 3. Однако при инклюзивной архитектуре кэша L3 наличие требуемых данных в кэше L3 означает, что эти данные также содержатся и в каком-то из кэшей ядра Core 1, Core 2 или Core 3. В архитектуре Nehalem в этом случае нет необходимости в дополнительной проверке кэшей L1 и L2 всех остальных ядер. Достигается это тем, что в тэг-поле кэш-строки L3-кэша записывается, к какому из ядер принадлежат данные (рис. 10), поэтому достаточно лишь прочитать его содержимое.
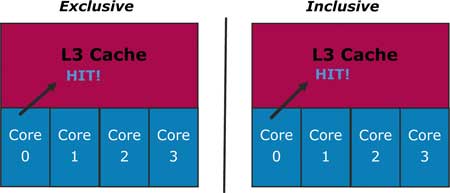
Рис. 9. Если требуемые ядру Core 0 данные обнаруживаются в кэше L3,
то при инклюзивной архитектуре кэша L3 больше
не нужно предпринимать каких-либо действий, поскольку
данная архитектура гарантирует их отсутствие в кэшах L1
и L2 остальных ядер
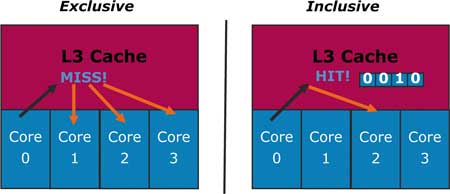
Рис. 10. Для того чтобы определить, в кэш-памяти
какого именно ядра находятся данные, в тэг-поле кэш-строки L3-кэша
записывается,
к какому из ядер
принадлежат данные
Турбо-режим в процессорах Intel Core i7
Как уже отмечалось, одной из особенностей процессоров семейства Intel Core i7 является реализация в них нового режима Turbo Mode. Смысл его заключается в динамической подстройке тактовых частот ядер процессора. Для этого в процессорах семейства Intel Core i7 предусмотрен специальный функциональный блок PCU (Power Control Unit), который отслеживает уровень загрузки ядер процессора, температуру процессора, а также отвечает за энергопитание каждого ядра и регулирование его тактовой частоты. Этот блок PCU включает более миллиона транзисторов и имеет даже свой микроконтроллер с микрокодом (рис. 11).
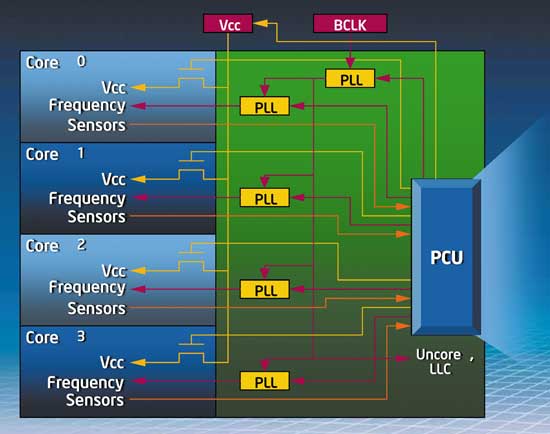
Рис. 11. Блок PCU в процессорах семейства Intel Core i7
Составной частью PCU является так называемый Power Gate (затвор), который применяется для перевода каждого ядра процессора по отдельности в режим энергопотребления C6 (фактически Power Gate отключает или подключает ядра процессора к линии питания VCC) — рис. 12.
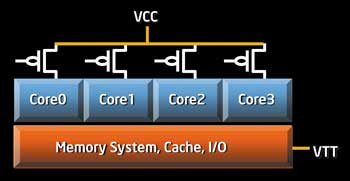
Рис. 12. Power Gate, используемый
для перевода каждого ядра процессора
по отдельности в режим энергопотребления C6
Казалось бы, если все так просто, то почему блок Power Gate не использовался в процессорах предыдущего поколения для перевода ядер в состояние низкого (фактически нулевого) энергопотребления? Действительно, идея отключения ядер процессоров сама по себе проста, но вот реализовать ее на практике нелегко. Дело в том, что для создания блока Power Gate требуются особые транзисторы со сверхнизкими токами утечки (транзисторы Ultra-low Leakage) — рис. 13. Они должны иметь очень низкое сопротивление в открытом состоянии и очень высокое — в закрытом. Собственно, с технологической точки зрения проблема создания эффективного затвора Power Gate для отключения ядер процессора от линии питания как раз и заключалась в том, чтобы создать такие транзисторы со сверхнизкими токами утечки. И только в новом поколении процессоров Intel Core i7 эту проблему удалось решить.

Рис. 13. Структура транзисторов Ultra-low Leakage в блоке Power Gate
Так вот, в том случае, если какие-то ядра процессора оказываются незагруженными, они попросту отключаются от линии VCC с использованием блока Power Gate (их энергопотребление при этом равно нулю). Соответственно тактовую частоту и напряжение питания оставшихся загруженных ядер можно динамически увеличить (за это отвечает PCU), но так, чтобы энергопотребление процессора не превышало его TDP. То есть фактически сэкономленное за счет отключения нескольких ядер энергопотребление применяется для такого разгона оставшихся ядер, чтобы увеличение энергопотребления в результате разгона не превышало сэкономленного энергопотребления (рис. 14).
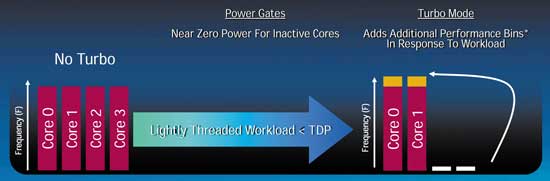
Рис. 14. Реализация режима Turbo Mode
Более того, режим Turbo Mode в процессорах Intel Core i7 реализуется и в том случае, когда изначально загружаются все ядра процессора, но при этом его энергопотребление не превышает значение TDP. При этом частота каждого ядра может динамически увеличиваться, но так, чтобы энергопотребление процессора не превышало заданного в BIOS значения.
Значение энергопотребления процессора будет задаваться в BIOS (типичное значение для четырехъядерного процессора составляет 130 Вт). Кроме того, в BIOS можно будет также задать и степень разгона в отдельности каждого ядра, то есть максимальный коэффициент умножения. Увеличение частоты в режиме Turbo Mode будет производиться скачкообразно, порциями по 133 МГц (частота системной шины в процессорах Intel Core i7 составляет 133 МГц). Те пользователи, кому режим Turbo Mode придется не по вкусу, смогут запретить его использование в настройках BIOS.








