Большие данные: насколько они большие?
Big Data: критерии определения
Размер и структура рынка Big Data
Опросы IDC в области BA и Big Data
В последнее время становится всё более популярным термин Big Data. Очевидно, что появление этого понятия так или иначе связано с резким ростом количества доступной для анализа информации. Действительно, в большинстве статей на тему Big Data рассказ о новой технологии начинается с обсуждения проблемы экспоненциального роста объема данных. Например, IDC считает, что в 2011 году объем созданной и реплицированной информации превзошел 1,8 ZB (1600 млрд гигабайт). Социальные сети, мобильные устройства, показатели разного рода оборудования, всевозможная бизнес-информация, научные исследования — вот лишь несколько источников формирования «больших данных». Говоря о лавинообразном росте объема данных, компания Capgemeni перечисляет следующие новые источники информации (рис. 1).

Рис. 1. Новые источники «больших данных» (источник: Capgemeni)
Способно ли сегодня человечество анализировать столь мощные потоки разнородной информации? Международный опыт свидетельствует о том, что организации, которые начали использовать технологию Big Data, могут получить существенное конкурентное преимущество, так как могут принимать решения на основе своевременной, актуальной, точной и полной информации.
Возможности, связанные с анализом «больших данных», могут кардинально повлиять на перераспределение компаний на рынке: организациям, которые не стремятся использовать преимущества от применения технологии «больших данных», придется потесниться.
Для оценки значимости технологии важно количественно оценить явление. Однако, чтобы говорить о цифрах, то есть о размерах рынка, нужен четкий количественный критерий.
Big Data: критерии определения
Обычно при определении понятия Big Data говорят о четырех V: Volume, Variety, Velocity и Value (объеме, вариативности, скорости и ценности), а само определение звучит следующим образом: Big Data — это «технологии и архитектуры нового поколения для экономичного извлечения ценности из разноформатных данных большого объема путем их быстрого захвата, обработки и анализа». Однако очевидно, что эта формулировка весьма расплывчата. Неслучайно многие участники рынка отмечают, что термин Big Data еще не устоялся, что понятие «большие данные» относительно: то, что вчера было большим, сегодня уже таковым не является, а завтра и вовсе может оказаться маленьким. Действительно, во все времена компании стремились обработать как можно больший объем данных и извлечь из него максимум пользы для бизнеса. Так о чем же тогда говорят аналитики? Есть ли повод выделять новый рынок, и можно ли оценивать его размеры?
Более конкретное определение Big Data как рынка прозвучало на конференции «Большие данные и бизнес-аналитика 2012» в докладе менеджера по исследованиям IDC Александра Прохорова (рис. 2). Согласно рис. 3, для каждой категории (данные, инфраструктура, приложения, значения для бизнеса) есть набор критериев, на основании которых тот или иной проект можно причислить к Big Data.

Рис. 2. Александр Прохоров, менеджер
по исследованиям IDC
Для категории «Данные» это те же четыре V, но снабженные численными значениями. Параметр «Объем» говорит о том, что накопленные данные должны достигать объема в 100 Тбайт.
Для параметра «Скорость» приводятся два значения. Первое характеризует захват и обработку данных в режиме, близком к реальному времени (получение данных путем высокоскоростной потоковой передачи со скоростью более 60 Гбит/с). Второе — это скорость накопления в организации данных, подлежащих анализу. Генерируемые данные должны накапливаться со скоростью более 60% в год, то есть рост данных таков, что в компании, не имеющей ИТ-инфраструктуры, которая позволяет осуществлять масштабирование в широких пределах при минимальных затратах, через какоето время ресурсы масштабирования ИТ-инфраструктуры будут исчерпаны, а апгрейд будет стоить столько, что окажется экономически нецелесообразным. В этом случае и встает вопрос о переходе на технологию Big Data.
Параметр «Вариативность» определяется следующим образом: «данные собираются из одного или нескольких источников и, возможно, в разных форматах».
При этом IDC отмечает, что перечисленные требования необязательно выполняются одновременно, а кроме того, количественные критерии соответствуют текущему моменту и через годдва могут быть пересмотрены.
Для категории «Инфраструктура» необходимым условием является то, что решение разворачивается на базе динамически адаптируемой инфраструктуры. IDC не указывает четко архитектуру ИТ-инфраструктуры (используется распределенная модель горизонтального или вертикального масштабирования) — в качестве определяющего фактора выдвигается такой параметр, как обеспечение вычислительных ресурсов и памяти по мере необходимости. При этом отмечается, что подавляющее большинство решений Big Data представляют собой системы постоянной обработки данных, где отказоустойчивость ИТ-инфраструктуры является критичным параметром.
IDC подчеркивает, что распределенная инфраструктура на базе так называемого commodity hardware — это один из способов организации ИТ-инфраструктуры, который не является определяющим для понятия Big Data.
Говоря о платформе (категория «Приложения»), на которой обрабатываются «большие данные», в последнее время многие ставят знак равенства между решениями Big Data и Hadoop. Однако IDC не ограничивает определение Big Data сравнением с Hadoop, подчеркивая, что Hadoop является лишь одним из способов развертывания инфраструктуры Big Data. В то же время Hadoop демонстрирует важную тенденцию в развертывании Big Data с помощью Open source-модели (а именно Linux-вариаций) на commodity hardware. Тем не менее это не означает, что коммерческие варианты UNIX закрыты для построения систем Big Data.
По словам Александра Прохорова, анализ рынка Big Data, проведенный IDC, показывает, что возможно множество комбинаций ПО, аппаратного обеспечения и сервисов, посредством которых реализуются успешные решения по анализу «больших данных».
Аналитические задачи (например, интеллектуальный анализ данных, многомерный анализ, визуализация данных) — наиболее частый пример использования Big Data, однако далеко не единственный. Технологии Big Data могут применяться также для поддержки социальных медиа и игровых приложений, рассчитанных на огромное число пользователей.
Критерий последней категории на рис. 3 — «Значение для бизнеса» — формулируется как постоянное извлечение ценной информации для бизнеса.
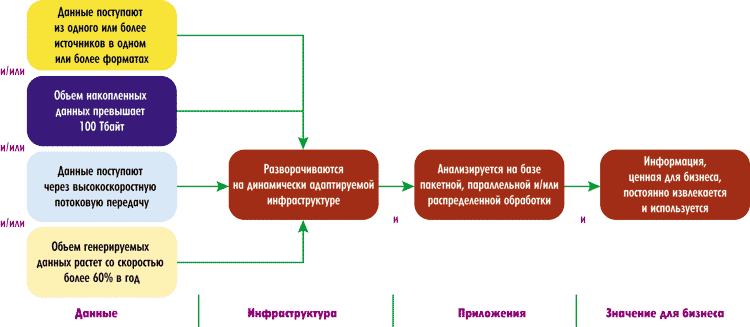
Рис. 3. Методика отнесения ИТ-проектов к Big Data (источник: IDC Russia)
Размер и структура рынка Big Data
Базируясь на определениях с рис. 3, IDC оценивает размеры мирового рынка Big Data следующим образом (рис. 4).
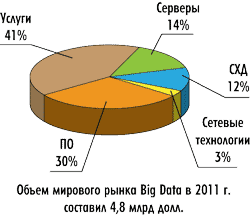
Рис. 4. Структура рынка Big Data
(источник: IDC, Worldwide Big Data Technology and Services
2010-2015 Forecast)
Согласно данным IDC, мировой рынок Big Data в 2011 году составил 4,8 млрд долл. и вырастет до 7 млрд долл. в 2012-м (рис. 5).

Рис. 5. Мировой рынок Big Data и BA
(источник: IDC, Worldwide Big Data Technology
and Services 2010 -2015 Forecast
и Worldwide Business Analytics 2011-2016 Forecast
and 2011 Vendor Shares)
Рынок Big Data экстрактивен: c одной стороны, он частично пересекается с рынком (BA Business Аnalytics) бизнес-аналитики (который в 2012 году с учетом ПО, аппаратного обеспечения и услуг составит около 100 млрд долл.) (см. рис. 5), а с другой — состоит из базовых рынков (серверы, СХД, сетевые технологии, ПО и услуги) (см. рис. 4). Более 40% рынка Big Data — это услуги, в состав которых входят консалтинг, системная интеграция, обучение и т.п.
Структура рынка Big Data свидетельствует, что технология открывает широкие возможности для поставки решений от компаний, специализирующихся в различных областях (ПО, аппаратное обеспечение, ИТ-услуги).
Согласно прогнозам IDC, рынок, связанный с технологией Big Data, вырастет с 3,2 млрд долл. в 2010 году до 16,9 млрд долл. в 2015-м (рис. 6). То есть совокупный среднегодовой темп роста (CAGR) рынка составит 39,4%, или этот рынок будет расти примерно в семь раз быстрее, чем ИКТ-рынок в целом.
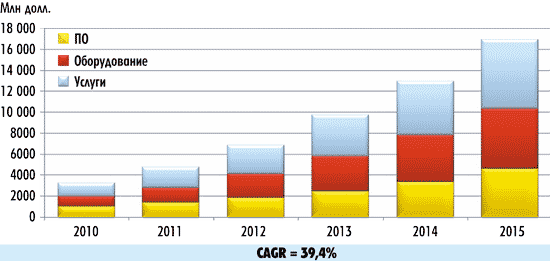
Рис. 6. Прогноз роста мирового рынка Big Data
(источник: IDC, Worldwide Big Data Technology and Services 2010-2015 Forecast)
IDC отмечает, что задачи, требующие применения технологий Big Data, характерны для целого ряда отраслей и видов деятельности (рис. 7).
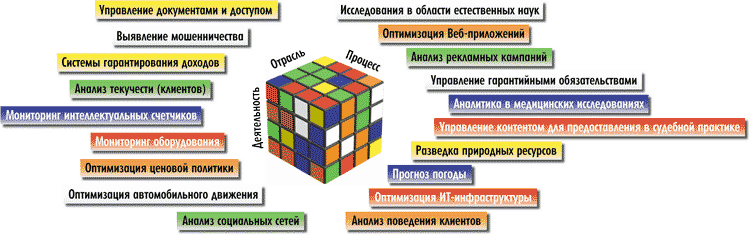
Рис. 7. Примеры задач, решаемых методами Big Data
Невозможно перечислить все отрасли, где технология Big Data сможет обеспечить новые эффективные решения. Упомянем лишь некоторые из них. Например, в медицине Big Data обещает качественные изменения в уровне диагностики и лечения пациентов. Рост объемов данных и появление более мощных аналитических инструментов позволяют делать прогнозы об эффективности различных методов лечения пациентов, основываясь на просмотре истории всех обращений к врачу конкретного пациента (его медицинские снимки, результаты прежних и текущих лабораторных обследований), а также на многочисленных накопленных материалах из других историй болезней. Технологии Big Data позволяют находить подобную информацию в реальном времени и применять ее в ходе консультаций у того или иного специалиста.
Другая область, где актуально использование технологий Big Data, — это решения класса Revenue Assurance (гарантирование доходов), предназначенные для автоматизации деятельности по гарантированию доходов предприятий. Основное назначение технологии — гарантировать полноту обработки информации об оказанных услугах, корректность учета этой информации и своевременное обнаружение возможных потерь или искажения информации, которые могут привести к снижению финансовых результатов. Например, системы Revenue Assurance позволяют сопоставлять объем потребленных услуг и величину начислений за них по действующим тарифам, давая возможность быстро выявлять подозрительные расхождения. Как правило, современные системы гарантирования доходности имеют в своем составе инструменты обнаружения несоответствий и углубленного анализа данных.
Сентимент-анализ рекламных кампаний на базе мониторинга социальных сетей с их огромным количеством постов — еще один из примеров применения технологии Big Data.
Опросы IDC в области BA и Big Data
Для того чтобы понять тенденции на рынке Big Data, следует обратиться к результатам опросов ИТ-специалистов крупных компаний. Рынок Big Data США — крупнейший в мире, поэтому наблюдаемые на нем тенденции представляют особый интерес. На рис. 8 представлено распределение ответов респондентов на вопрос: «Что стимулирует использование Big Data-технологий в вашей организации?». На него ответило более 4 тыс. специалистов уровня ИТ-директоров и высшего руководства из организаций США. Интересно отметить, что почти для 30% респондентов стимулом для применения Big Data-технологий послужил сравнительно новый тип исследований, а именно анализ онлайнового поведения клиентов. При этом респонденты подтверждают, что не все задачи связаны с аналитическими приложениями. Более 10% респондентов указали на применение этой технологии для решения неаналитических задач.
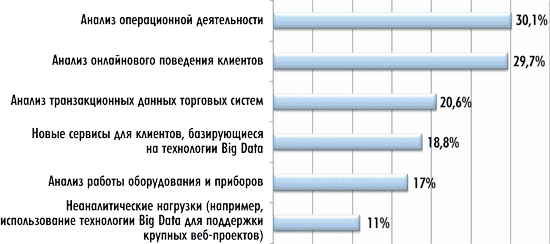
Рис. 8. Стимулы использования Big Data
(источник: IDC Vertical IT & Communications Survey, 2012, N = 4177)
Среди факторов, которые тормозят внедрение ВА-проектов, называют их высокую стоимость (рис. 9), при этом, говоря о факторах тормозящих внедрение Big Data-проектов, первым (c большим отрывом) отмечается такой фактор, как «выбор фиксируемых данных». Таким образом, сложна сама постановка задачи — выбор данных, значимых для исследуемого вопроса, то есть определение того, какие данные нужно захватывать, хранить и анализировать, а какие — пропускать.
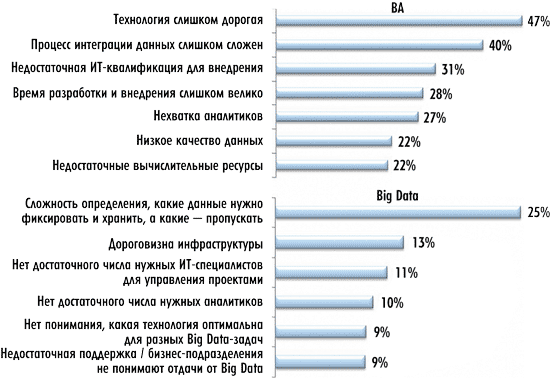
Рис. 9. Что тормозит внедрение ВА и Big Data во всем мире
(источник: IDC Vertical IT & Communications Survey Preliminary, 2012, N = 2699)
Третий и четвертый параметры, характеризующие сложности при внедрении Big Data-проектов (см. рис. 9), связаны с нехваткой специалистов — как менеджеров, так и аналитиков. Последний, но столь же весомый фактор — это недостаточная поддержка внедрения проектов по Big Data со стороны бизнес-руководителей (его отметили почти 10% респондентов). Частично ответ на вопрос, почему это происходит, дает рис. 10, где показано распределение ответов респондентов на вопрос: «Каково среднее время возврата инвестиций по проектам в области Big Data и BA?».
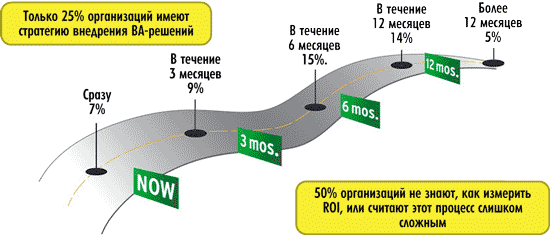
Рис. 10. Проблемы измерения ROI
(источник: IDC and Computerworld BI and Analytics Survey Research Group IT Survey, 2012, N = 111)
Из рис. 10 следует, что даже на развитом американском рынке 50% организаций не знают, как измерить возврат инвестиций (ROI) в проектах по внедрению технологии Big Data.
Ответ на вопрос, каких же именно специалистов не хватает для внедрения Big Data-проектов, дает рис. 11. Согласно этому рисунку, прежде всего нужны специалисты в области глубинной и предсказательной аналитики — потребность в таких кадрах указали почти 70% респондентов. При этом отмечается, что найти таких экспертов крайне сложно.

Рис. 11. Дефицит специалистов в области Big Data
(источник: IDC and Computerworld BI and Analytics Survey Research Group IT Survey, 2012, N = 45 services firms)
Рис. 12 дает представление о динамике внедрения решений в области Big Data и ВА на рынке США. Почти 70% респондентов уже внедрили реляционные базы данных. Однако рост внедрения подобных систем гораздо меньше, чем таких, например, как in-memory БД. Решения на базе Hadoop внедрили лишь 10% из опрошенных организаций.
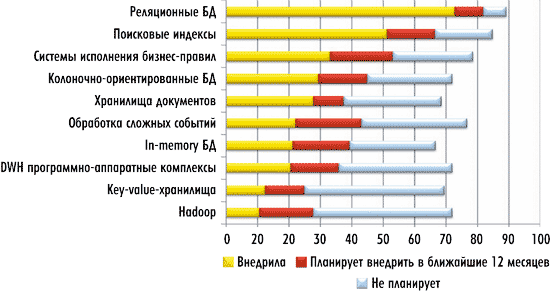
Рис. 12. Динамика внедрения решений в области Big Data и ВА на рынке США
А что же происходит в России? В докладе Александра Прохорова были представлены данные опроса российских компаний — провайдеров ВА-решений. В частности, на рис. 13 представлено распределение ответов на вопрос: «Что стимулирует и тормозит развитие рынка ВА в России?» (оценка дана по пятибалльной шкале). Как видите, отечественные компании — провайдеры ВА отмечают факторы, которые говорят о потенциальном наличии спроса на технологии Big Data и в России. Максимальное число респондентов в качестве фактора, стимулирующего развитие ВА в России, отметили именно экспоненциальный рост данных, вторым по важности оказался такой фактор, как необходимость ускорения принятия управленческих решений, а третьим — качество управленческих решений; среди прочего была отмечена и гетерогенность систем. Таким образом, опрос показывает, что упомянутые ранее четыре V актуальны и для российского рынка.
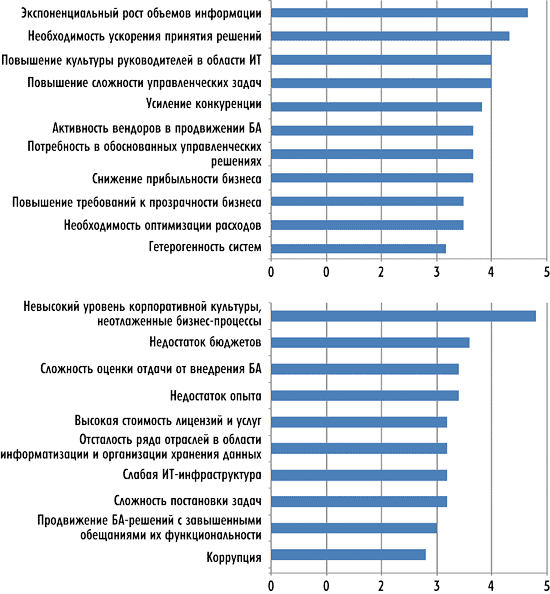
Рис. 13. Что стимулирует и тормозит развитие рынка Business Analytics (ВА)
в России
(источник: «Российский рынок ВА-решений», IDC, 2012)
Игроки рынка Big Data
Для полноты картины в докладе IDC не хватало информации об основных игроках рынка Big Data. Для того чтобы восполнить этот пробел, можно обратиться к материалам другой аналитической компании — Capgemeni (рис. 14).
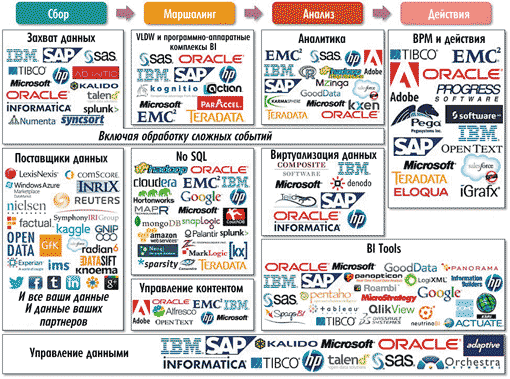
Рис. 14. Big Data-вендоры и технологии
(источник: Manuel Sevilla, Capgemeni, 2012)
Все компании на рис. 14 помещены в отдельные блокикатегории, которые соотнесены с четырьмя этапами обработки данных: сбор, маршалинг, аналитика и действия, а также с управлением данными.
Сбор данных
Этап сбора данных предполагает процедуры ETL, часто в режиме реального времени, в связи с большим объемом и высокой скоростью потока данных. Поскольку данные, как правило, внешние, на этом этапе должны решаться вопросы обеспечения безопасности данных и определения степени доверия к ним. На этом же этапе выполняется проверка лицензионности данных и соблюдения прав на использование внешних данных.
Среди фирм, работающих в категории «Захват данных», отмечены такие технологические компании, как Ab Initio, HP, IBM (DataStage, Streams, Data Mirror), Informatica (PowerCenter, PowerExchange, CEP), Kalido, Microsoft, Numenta, Oracle, SAP, SAS, Splunk, Syncsort, Talend и Tibco.
На рис. 14 категория «Инструментарий обработки сложных событий» (Complex Event Processing tools, CEP tools) распространяется не только на этап «Сбор», но и на последующие этапы — «Маршалинг» и «Аналитика». Инструментарий CEP позволяет производить обработку множества событий, происходящих на различных уровнях организации, с идентификацией наиболее существенных из них, анализом их влияния и принятием необходимых действий в режиме реального времени.
В категории «Поставщики данных», которая также относится к этапу «Сбор», отмечены такие игроки, как ComScore, Datasift, Experian, Factual, GfK, Gnip, IMS, Inrix, Kaggle, Knoema, LexisNexis, Microsoft, Nielsen, Reuters, Salesforce Radian6 и Symphony IRI.
В качестве отдельной категории поставщиков данных выделены сайты социальных сетей, такие как Facebook, Google, LinkedIn, Tumblr, Twitter и Viadeo. Здесь также нужно отметить всех других поставщиков открытых данных, например правительства и т.п.
Маршалинг данных
Все полученные данные должны быть отсортированы для удаления бесполезной информации и хранения в оптимальных форматах, исходя из применяемых решений (Hadoop, No-SQL, BI-приложения, In-memory).
На данном этапе в категории «VLDW и программно-аппаратные комплексы BI» упомянуты вендоры, предоставляющие большие хранилища данных и программно-аппаратные BI-комплексы для бизнес-аналитики (Actian, EMC2 (Greenplum), HP (Vertica), IBM (Netezza), Kognitio, Microsoft (SQL 2012 и PDW), Oracle (Exadata), ParAccel, SAP (HANA и Sybase IQ), SAS и Teradata.
В категории NoSQL основные игроки — это прежде всего Amazon (как «облачный» провайдер с собственными NoSQL-решениями), Cassandra, Cloudera (CDH, дистрибьюция Hadoop), CouchDB, EMC2, Google, Hadoop, Google, Hortonworks (Hadoop-дистрибьюция), HP, IBM, KX, MapR (Hadoop-дистрибьюция), Marklogic, Microsoft (Hadoop на базе Windows и Azure), MongoDB, Neo4J, Oracle, Palantir, Snaplogic, Sparsity, Splunk, Teradata (Aster Data) и ZL Technologies.
Необходимость использования технологий Big Data в системах управления контентом тоже связана с увеличением объема хранимых документов. На определенном этапе роста объема данных становится слишком затратно обеспечивать их хранение и осуществлять в них поиск, возникает потребность в применении технологий Big Data, чтобы классифицировать данные, выделяя наиболее ценные из них для последующего сохранения.
В категории «Управление контентом» отмечены такие компании, как Adobe, Alfresco, EMC2 (Documentum), IBM (FileNet), HP (Autonomy), Microsoft, OpenText и Oracle.
Аналитика
На данном этапе выделены собственно блок «Аналитика», блок «Виртуализация данных»; частично к этапу «Аналитика» относится также блок «BI-инструменты».
В блоке «Аналитика» собраны компании, которые предлагают решения в области глубинной и прогнозной аналитики. Здесь отмечены такие вендоры, как Adobe, EMC2, GoodData, Hadoop Map Reduce, HP, IBM (SPSS), Karmasphere, Kxen, Microsoft, Mzinga, Oracle, R, Salesforce, SAS, SAP (R on HANA) и Teradata (Aprimo).
На этапе «Аналитика» авторы схемы выделяют также блок «Виртуализация данных». Виртуализация данных — это процесс предоставления данных пользователям посредством интерфейса, абстрагирующего данные от технических аспектов их хранения (способ хранения, местоположение, структура, язык доступа). В разделе «Виртуализация данных» в качестве лидеров выделены такие компании, как Composite, Denodo, HP (IDOL), IBM, Informatica, Microsoft, Oracle (Exalytics), SAP и Teiid (JBoss community).
Как на стадии «Аналитика», так и на стадии «Действия» поставщиками BI-инструментов являются такие компании, как Actuate, Dassault Systemes (Exalead), Domo, Esri, GoodData, Google, HP (Autonomy), IBM (Cognos suite), Information Builders, LogiXML, Microsoft (SQL 2012), Microstrategy, NeutrinoBI, Oracle (OBI Foundation), Panopticon, Panorama, Pentaho, Qlikview, Roambi, SAP (BI4 suite), SAS, SpagoBI, Tableau и Tibco.
Действия
Обнаруженные на стадии аналитики важные зависимости и закономерности должны быть положены в основу принятия бизнес-решений, которые трансформируют их в прибыль за счет оптимизации расходов и т.п. На стадии «Действия» присутствуют все игроки, специализирующиеся в захвате данных, а также разработчики ERP-, CRM- и BPM-систем, в том числе Adobe, Eloqua, EMC2, IBM, iGrafx, Microsoft, OpenText, Oracle, Pega, Progress Software, SAP, Salesforce, Software AG, Teradata (Aprimo) и Tibco.
Управление данными
Система не может функционировать без качественных данных и эффективного управления мастер-данными — бизнес-данными, которые служат основой для принятия бизнес-решений и используются всеми информационными системами компании. Управление мастер-данными заключается в сборе, агрегации, трансформации и объединении основных данных при обеспечении их качества и согласованности (исключаются повторяющиеся и противоречивые данные).
В блоке «Управление данными» (Data governance) выделены такие компании, как Adaptive, HP, IBM, Informatica, Kalido, Microsoft, Oracle, Orchestra Networks, SAP, SAS, Talend и Tibco.
Проекты Big Data в России
Аналитические компании пока не оценивают российский рынок Big Data, находящийся на стадии формирования. Однако отдельные проекты, которые можно отнести к данной категории, уже появляются. В частности, инвестиционная компания «Тройка Диалог» (c января 2012 года принадлежит ОАО «Сбербанк России») использует EMC2 Greenplum как основу своей платформы хранилища данных с 2010 года. Массово-параллельная архитектура (MPP) Greenplum обеспечивает высокопроизводительную, надежную и масштабируемую платформу для решения аналитических задач.
Выполняя функции брокера на рынке ценных бумаг, «Тройка Диалог» проводит огромный объем сделок: для брокеров генерируются необходимые для работы аналитические прогнозы, брокерские отчеты. Все данные по сделкам хранятся в информационных системах компании не менее трех лет, при этом объем данных каждый год в среднем удваивается.
На основе хранилища построены системы мониторинга нормативных требований и количественного анализа, при этом запросы к хранилищу и загрузка данных из Back Office системы компании в Greenplum осуществляются в режиме, близком к реальному времени.
Другой проект по внедрению платформы EMC2 Greenplum был осуществлен в банке «Тинькофф Кредитные Системы». Он был завершен совсем недавно — в октябре текущего года, в этом случае интегратором выступила российская компания GlowByte Consulting.
Банк «Тинькофф Кредитные Системы» на протяжении последних лет демонстрировал высокие темпы роста абонентов кредитных карт. Планы по наращиванию клиентской базы и возросшие требования к скорости обработки накопленной информации сделали необходимыми применение средств работы с «большими данными» и анализ данных в режиме реального времени. Согласно официальному прессрелизу банка «Тинькофф Кредитные Системы», «в дальнейшем банк планирует развивать не только инструмент Greenplum, адаптированный для массивно-параллельных вычислений, но и Hadoop, предназначенный для обработки неструктурированных данных, и платформу Chorus, которая предоставляет возможность совместной работы с корпоративными данными, получаемыми из разных источников».
Известно о ряде внедрений в России системы SAP HANA. В частности, об этом официально заявили торговая сеть «Эльдорадо», металлургический холдинг «Северсталь»; по сообщениям SAP СНГ, еще пять или шесть компаний тестируют платформу либо готовятся к запуску решений.
Проект по созданию аналитического решения на базе SAP HANA в «Сургутнефтегазе» стартовал в 2011 году. Аппаратная платформа для поддержки аналитического решения была подготовлена компанией «Инлайн Груп» на базе серверов HP. В 2012 году с решениями на базе SAP HANA одновременно работали уже более тысячи пользователей «Сургутнефтегаза».
Еще один выполняемый в настоящее время проект, который можно отнести к категории «больших данных», — это создание аналитического слоя федерального хранилища данных ФНС России силами системного интегратора — компании IBS. В рамках данного проекта создаются единое информационное пространство и единая технология доступа к налоговым данным для статистической и аналитической обработки. В проекте применяются технологии DWH (Teradata 6650, ETL Informatica PC, SAP BusinessObjects) и OLTP (Oracle Exadata). Необходимость в работе с большими объемами данных здесь очевидна, поскольку речь идет об анализе информации по всем физическим и юридическим лицам РФ. В проекте выполняются работы по централизации аналитической информации более чем с 1200 источниками местного уровня (ИФНС).
Реализовано еще несколько проектов, которые можно отнести к категории Big Data. Решение на платформе Teradata применяется в «Сбербанке» и банке «ВТБ 24». Компания «ВымпелКом СНГ» внедрила решение по оптимизации маркетинговых кампаний с помощью IBM SPSS.








