Что такое кэш процессора, и как он работает
Принцип работы кэша процессора
Политики замещения данных в кэшпамяти
Полностью ассоциативная кэшпамять
Кэшпамять с прямым отображением
Многоуровневая организация кэша
Иерархия кэшпамяти в микроархитектуре Intel Core
О наличии у любого процессора кэш-памяти знают, наверное, все, кто вообще представляет, что такое процессор. Причем современные х86-совместимые процессоры для ноутбуков и настольных ПК имеют не просто кэш, а целую систему иерархии кэш-памяти, включающей кэш-память первого, второго и даже третьего уровней, которые расположены на кристалле процессора. Но вот зачем процессору нужен кэш и чем один кэш отличается от другого — на эти вопросы сможет ответить уже далеко не каждый пользователь ПК. А вопрос, почему делается несколько кэшей разных уровней и не проще ли создать один большой, может поставить в тупик даже многих опытных пользователей, разбирающихся в «железе». Итак, если вы не знаете, как ответить на перечисленные вопросы, то эта статья будет для вас небезынтересна..
Назначение кэш памяти
Проще всего ответить на вопрос, зачем нужна кэшпамять. Как известно, процессор работает с данными, хранящимися в оперативной памяти. Однако скорость работы оперативной памяти и процессора существенно различаются: если бы процессор напрямую общался с оперативной памятью (читал или записывал данные), то большую часть времени попросту простаивал бы. Именно для сокращения задержек доступа к оперативной памяти и применяется кэшпамять, которая значительно более скоростная в сравнении с оперативной. Фактически если оперативная память используется для того, чтобы сгладить задержки доступа к данным на накопителе (HDD-диске, SSD-накопителе или флэшпамяти), то кэшпамять процессора применяется для нивелирования задержек доступа к самой оперативной памяти. В этом смысле оперативную память можно рассматривать как кэш накопителя. Однако между оперативной памятью и кэшем процессора есть одно очень серьезное различие: кэш процессора полностью прозрачен для программиста, то есть нельзя адресовать программным образом находящиеся в нем данные.
Понятно, что для того, чтобы кэш процессора мог выполнять свою основную задачу, то есть сглаживать доступ к оперативной памяти, он должен работать гораздо быстрее, чем она. Так, если оперативная память представляет собой динамическую память с произвольным доступом (Dynamic Random Access Memory, DRAM), то кэш процессора выполняется на базе статической оперативной памяти (Static Random Access Memory, SRAM).
Статическая память SRAM без проблем работает на частотах в несколько гигагерц, то есть кэш на основе такой памяти может работать на тактовой частоте процессора. Динамическая память DRAM функционирует на частотах существенно более низких. К примеру, эффективная частота наиболее распространенной сегодня DRAM-памяти DDR3 составляет 1600 МГц. Однако это именно эффективная частота памяти, то есть частота, с которой данные поступают на внешнюю шину в пакетном режиме доступа, а реальная частота ядра памяти составляет всего 200 МГц. Конечно же, нас интересует в первую очередь именно эффективная частота памяти, то есть 1600 МГц, или 1,6 ГГц. Казалось бы, это немало, но нужно учитывать и тайминги памяти, которые характеризуют ее латентность. Причем тайминги памяти определяются в тактах работы ядра памяти, а не в тактах эффективной частоты, то есть для памяти DDR3-1600 c частотой работы ядра памяти 200 МГц каждый такт составляет 1/200 МГц = 5 нс. В то же время такт процессора с частотой, к примеру, 3 ГГц длится всего 0,3 нс, то есть в 17 раз меньше.
Напомним, что тайминги памяти — это задержки, измеряемые в тактах работы ядра памяти, между отдельными командами. Выделяют несколько таймингов памяти, соответствующих задержкам между различными командами. Наиболее важными являются тайминги RAS-to-CAS Delay (tRCD), CAS Latency (tCL), Active-to-precharge delay (tRAS) и RAS Precharge (tRP).
Тайминг tRCD определяет задержку командой активации (ACTIVE) нужной строки памяти и командой записи (WRITE) или чтения (READ) данных.
От команды чтения (записи) данных и до выдачи первого элемента данных на шину (записи данных в ячейку памяти) проходит промежуток времени tCL. Каждый последующий элемент данных появляется на шине данных в очередном такте (при пакетном доступе).
Завершение цикла обращения к банку памяти осуществляется подачей команды PRECHARGE, приводящей к закрытию строки памяти. От команды PRECHARGE и до поступления новой команды активации строки памяти должен пройти промежуток времени tRP.
А минимальный промежуток времени, длящийся с момента подачи команды активации строки до команды PRECHARGE, которая приводит к закрытию строки памяти, называется tRAS. Основные тайминги памяти обычно записываются в виде такой последовательности: tCL-tRCD-tRP-tRAS.
Теперь рассмотрим в качестве примера память DDR3-1600 c таймингами 9-9-9-27. Предположим, что процессор напрямую обращается к данным оперативной памяти, которые нужно загрузить в его регистры для дальнейшей обработки. С момента активации нужной строки памяти и до появления данных на шине пройдет промежуток времени, равный tRCD+tCL, то есть 18 тактов. С учетом того что частота работы ядра памяти DDR3-1600 составляет 200 МГц, это время равно 90 нс. Если частота работы процессора составляет 3 ГГц, то это означает, что процессор должен будет дожидаться нужных данных (по сути простаивать) минимум 270 тактов! Понятно, что если бы современные процессоры общались с оперативной памятью напрямую, то есть без кэша, то были бы крайне медлительны и в их гигагерцах не было бы никакого смысла.
Есть и другая причина, по которой необходимо использовать кэшпамять как промежуточное звено между процессором и оперативной памятью. Дело в том, что процесс чтения и записи данных в оперативную память происходит не отдельными байтами, а пакетами, состоящими как минимум из четырех 64-разрядных ячеек (из четырех четверных слов). Это позволяет повысить эффективность работы памяти. Однако процессор загружает данные в свои регистры в виде байт, слов, двойных слов или даже четверных слов. В любом случае он не работает с пакетами данных. То есть минимальная единица информации, считываемая из оперативной памяти, всегда больше той минимальной единицы информации, с которой работает процессор.
Естественно, возникает вопрос: если из памяти считывается целый пакет данных, а требуется, к примеру, только одно двухбайтовое слово, то куда девать все остальные байты? Отбрасывать их было бы крайне нерентабельно, поскольку велика вероятность, что если сейчас процессору требуются данные, расположенные по одному адресу в оперативной памяти, то в следующий момент он запросит данные, находящиеся по соседнему адресу. А потому считанный пакет данных из оперативной памяти нужно гдето временно сохранить, то есть требуется промежуточная память для временного хранения считываемых данных. Аналогично запись в оперативную память происходит пакетами данных, но эти пакеты нужно гдето предварительно сформировать, то есть опять-таки нужна временная память или кэш.
Итак, кэш процессора используется для временного хранения данных, которые записываются в оперативную память или считываются из нее, и позволяет нивелировать задержки доступа к оперативной памяти. Прежде чем перейти к рассмотрению принципов работы кэша, попытаемся ответить еще на один вопрос. Как мы уже отмечали, кэш процессора делается на основе очень быстрой статической SRAM-памяти, а оперативная память выполняется на базе достаточно медленной динамической DRAM-памяти. А почему бы не делать оперативную память на базе быстрой SRAM-памяти? Как правило, отвечают на этот вопрос следующим образом: SRAM-память дороже и делать на ее основе оперативную память экономически невыгодно. Это действительно так, однако дело не только в этом — стоимость в данном случае отнюдь не первостепенный фактор.
SRAM-память на самом деле более быстродействующая в сравнении с DRAM-памятью, однако если каждая ячейка DRAM-памяти состоит из одного полевого транзистора и одного конденсатора, то ячейка SRAM-памяти — как минимум из шести полевых транзисторов (есть варианты с числом транзисторов 8 и 12). Понятно, что при таком количестве транзисторов на одну ячейку микросхема SRAM-памяти просто не может иметь такой же объем, как микросхема DRAM-памяти. То есть модули SRAM-памяти, во-первых, были бы меньшего объема в сравнении с модулями DRAM-памяти, а во-вторых, стоили бы дороже.
Но и это еще не всё. Даже если создать оперативную память, которая по скорости не будет уступать кэшу на основе SRAM-памяти, то это не избавит от необходимости использования кэша в силу того, что считываемые из памяти (или записываемые в память) блоки данных нужно гдето временно размещать.
Таким образом, даже при наличии сверхбыстрой оперативной памяти всё равно потребовался бы кэш для промежуточного хранения данных. Конечно, в этом случае кэш был бы устроен совсем по-другому и имел бы иной размер.
Аналогично при записи модифицированных процессором данных в оперативную память логично было бы первоначально накапливать их во временном хранилище (кэше), а затем, дождавшись освобождения системой шины, выгружать в оперативную память одним махом. Это ликвидировало бы никому не нужные задержки и значительно увеличило бы производительность подсистемы памяти. Попутно отметим, что такой механизм отложенной записи реализован во всех современных процессорах.
Есть и еще одна причина, по которой нет смысла в применении оперативной памяти на основе сверхбыстрой SRAM-памяти. Дело в том, что в современных процессорах кэш настолько хорошо справляется со своей задачей, что от скорости работы оперативной памяти мало что зависит. То есть, используя высокоскоростной кэш, который по объему существенно (примерно в тысячу раз) меньше оперативной памяти, можно добиться того, что все данные, которые требуются процессору, будут практически всегда находиться в кэше. Так зачем же тогда делать оперативную память на основе сверхбыстрой SRAM-памяти? Более того, нет смысла и в быстрой DRAM-памяти. Но почему тогда производители модулей памяти гордятся присутствием высокоскоростной памяти в линейке своей продукции, ориентируя ее на геймеров, оверклокеров и компьютерных энтузиастов? Действительно, если рассмотреть память DDR3, то, кроме модулей памяти, работающих на стандартизованной эффективной частоте 1066, 1333 и 1600 МГц, имеются модули памяти с частотой 1867, 2100 и 2400 МГц. На самом деле это просто рекламная уловка производителей: между памятью DDR3-1333 и DDR3-2400 никакой разницы нет, то есть, используя более скоростную память, вы не добьетесь ощутимого прироста производительности системы. Весь фокус в данном случае в том, что кэш процессора, основная задача которого заключается в нивелировании задержки обращения к оперативной памяти, отлично справляется со своей задачей.
Принцип работы кэша процессора
Итак, мы разобрались с назначением кэша процессора, а теперь рассмотрим базовые принципы работы кэша, которые позволяют ему решать свою основную задачу.
Кэш состоит из контроллера и собственно кэшпамяти. Кэшконтроллер управляет работой кэшпамяти, то есть загружает в нее нужные данные из оперативной памяти и возвращает, когда нужно, модифицированные процессором данные в оперативную память. Архитектурно кэшконтроллер расположен между процессором и оперативной памятью (рис. 1). Перехватывая запросы к оперативной памяти, кэшконтроллер определяет, имеется ли копия затребованных данных в кэше. Если такая копия там есть, то это называется кэшпопаданием (cache hit) — в таком случае данные очень быстро извлекаются из кэша (существенно быстрее, чем из оперативной памяти). Если же требуемых данных в кэше нет, то говорят о кэшпромахе (cache miss) — тогда запрос данных переадресуется к оперативной памяти.
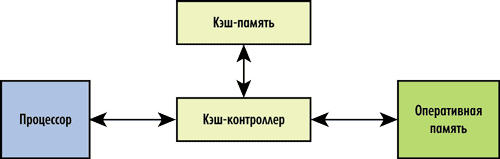
Рис. 1. Структура кэш-памяти процессора
Для достижения наивысшей производительности кэшпромахи должны происходить как можно реже (в идеале — отсутствовать). Учитывая, что по емкости кэшпамять намного меньше оперативной памяти, добиться этого не такто просто. А потому основная задача кэшконтроллера заключается в том, чтобы загружать кэшпамять действительно нужными данными и своевременно удалять из нее данные, которые больше не понадобятся. Важно понимать, что кэш всегда «полон», так как оставлять часть кэшпамяти пустой нерационально. Новые данные попадают в кэш только путем вытеснения (замещения) какихлибо старых данных.
Загрузка кэша данными реализуется на основе так называемой стратегии кэширования, а выгрузка данных — на основе политики замещения.
Политики замещения данных в кэшпамяти
Как уже отмечалось, кэш всегда полон и новые данные попадают в него только путем замещения какихлибо старых данных. Алгоритмы, определяющие стратегию замещения данных, различны. Самый простой алгоритм, не наделенный интеллектом, — это алгоритм произвольного выбора, когда замещаемые данные выбираются случайным образом (Random). Понятно, что политика замещения на основе алгоритма произвольного выбора проста в реализации, однако неэффективна, а потому не используется в современных процессорах (мы рассматриваем только x86-совместимые процессоры).
Решение о замещении данных в кэше может приниматься также на основе частотного анализа обращений к данным (Least Frequently Used, LFU), когда в первую очередь замещаются те данные, у которых самая низкая частота обращений. Политика замещения на основе частотного анализа обращений требует наличия счетчиков в каждой строке кэша (о том, что такое строка кэша, мы расскажем далее), обновляемых при каждом удачном запросе.
Следующий возможный алгоритм, определяющий политику замещения, — это алгоритм LRU (Least Recently Used), когда замещаются те данные, к которым дольше всего не обращались.
Возможен также алгоритм FIFO (First Input First Output) или LRR (Least Recently Replaced), когда замещаются те данные, которые были загружены раньше всех.
Отметим, что алгоритмы LRU и FIFO тоже требуют наличия счетчиков в каждой строке кэша и именно эти два алгоритма применяются во всех современных процессорах.
Стратегии кэширования
Мы рассмотрели алгоритмы, на которых основаны политики замещения данных в кэшпамяти, а теперь поговорим об алгоритмах, лежащих в основе стратегии кэширования, то есть об алгоритмах загрузки кэша данными. Напомним, что основная задача кэшконтроллера заключается в том, чтобы наполнить кэш актуальными данными и свести к минимуму количество кэшпромахов.
Фактически для этого кэшконтроллер должен знать или уметь предсказывать, какие данные потребуются процессору в будущем, и на основе этого заранее загружать их в кэш (упреждающая загрузка данных). Понятно, что «наверняка» кэшконтроллер ничего не знает и никаким сверхъестественным интеллектом не обладает, а потому хоть и редко, но случаются кэшпромахи.
Существует несколько стратегий помещения данных в кэшпамять. Самая простая и неинтеллектуальная стратегия заключается в том, что обращение к оперативной памяти (с последующим помещением копии данных в кэш) происходит только в том случае, если затребованных процессором данных нет в кэше (возникает кэшпромах). Данная стратегия называется кэшированием по требованию (on demand). Однако при такой стратегии кэширования частота кэшпромахов достаточно высока — по этой причине она не используется.
Значительно более эффективна стратегия упреждающей спекулятивной загрузки данных в кэш, когда кэшконтроллер заранее загружает данные в кэшпамять на основе прогнозируемых предположений о том, какие данные понадобятся процессору в ближайшем будущем.
Существует несколько алгоритмов упреждающей спекулятивной загрузки данных в кэш. Самый простой алгоритм основан на предположении, что данные из оперативной памяти обрабатываются последовательно, в порядке возрастания адресов. То есть кэшконтроллер попросту загружает в кэш из оперативной памяти не только затребованные процессором данные, но и соседние данные в порядке возрастания адресов. Если данные действительно обрабатываются последовательно, то последующие запросы процессора приведут к попаданию в кэшпамять.
Описанный алгоритм упреждающей загрузки является самым простым, но не самым эффективным, поскольку далеко не всегда данные в программе обрабатываются последовательно. Более интеллектуальные алгоритмы упреждающей спекулятивной загрузки данных в кэш предсказывают адрес следующей запрашиваемой ячейки памяти на основе анализа предыдущих обращений.
Изучая последовательность кэшпромахов, кэшконтроллер пытается установить, когда может произойти следующий кэшпромах и производит упреждающую загрузку данных, чтобы избежать его. Интеллектуальная стратегия упреждающей спекулятивной загрузки данных в кэш имеет высокую эффективность и сводит частоту возникновения кэшпромахов к ничтожно малому значению.
Отметим, что в современных процессорах используются исключительно интеллектуальные стратегии упреждающей спекулятивной загрузки данных в кэш.
Загрузка данных из памяти может либо начинаться после фиксации кэшпромаха (стратегия Look Through), либо осуществляться параллельно с проверкой наличия соответствующей копии данных в сверхоперативной памяти и прерываться в случае кэшпопадания (стратегия Look Aside). При реализации алгоритма Look Aside сокращаются задержки доступа к памяти в случае кэшпромахов, однако при этом увеличивается энергопотребление процессора.
Организация кэша
Теперь рассмотрим, как структурно устроен кэш. Как мы уже знаем, размер кэша всегда намного меньше размера оперативной памяти, поэтому необходимо, чтобы вместе с каждым блоком информации, сохраняемым в кэше, сохранялся адрес этого блока данных в оперативной памяти.
Рассмотрим гипотетический пример. Пусть имеется система с 32-разрядной адресацией памяти, то есть для задания адреса каждого байта памяти требуется четырехбайтный адрес. Предположим, что наш гипотетический кэш работает на уровне отдельных байтов, то есть может сохранять в качестве элемента байт оперативной памяти. Тогда каждый структурный элемент кэшпамяти должен сохранять не только байт данных оперативной памяти, но еще и его четырехбайтный адрес в оперативной памяти. Получается уже некое подобие строки, которая называется кэшстрокой (cache-line).
Адрес сохраняемого байта принято именовать тегом (tag).
При чтении данных из кэша процессор формирует адрес, который сравнивается с тегом кэшстроки. В случае совпадения кэш выдает требуемый байт данных, если же совпадения адреса с тегом нет (кэшпромах) — производится обращение к оперативной памяти. Понятно, что для реализации данного механизма необходимо дополнить каждую строку кэша еще и устройством сравнения адреса с тегом (рис. 2).
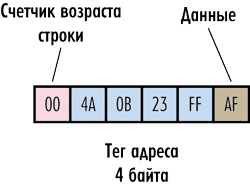
Рис. 2. Структура гипотетического кэша
Но и это еще не всё. Как мы уже отмечали, для реализации политики замещения на основе алгоритма FIFO или LRU, необходимо, чтобы каждая строка кэша была дополнена счетчикам возраста. Причем сколько именно байт отводится под счетчик, зависит от того, каков размер кэша. Если, к примеру, описанный нами кэш имеет размер 64 Кбайт, то в нем должно быть 65 536 строк. Тогда необходимо к каждой строке кэша добавить еще двухбайтовое поле (216 = 65 536), чтобы реализовать счетчик возраста строк.
Строка, к которой обращались в последнюю очередь, имеет возраст 0, а строка с самым поздним обращением — возраст 65 535.
В описанном выше гипотетическом кэше объем полезной сохраняемой информации в шесть раз меньше полного объема кэша, поскольку на каждый байт хранимых данных приходится еще шесть служебных байт. Понятно, что такая структура кэша абсолютно нецелесообразна.
Для того чтобы повысить объем полезной информации и одновременно уменьшить объем служебных данных, достаточно сохранять информацию в кэше не в виде отдельных байтов, а в виде блоков данных. То есть в каждой строке кэша будем сохранять не один байт данных, а блок данных фиксированного размера, идущих подряд в оперативной памяти, — он называется размером кэшстроки. Тегом строки будет адрес в оперативной памяти первого содержащегося в ней байта. Отметим, что блок сохраняемых данных в кэшстроке (то есть по сути сама кэшстрока) имеет строго фиксированный размер и является минимальной единицей информации, которая может быть считана из кэша или загружена в кэш. Размер кэшстроки может быть равен только степени двойки (2, 4, 8, 16 и т.д.) — рис. 3. Как мы помним, чтение из оперативной памяти (равно как и запись в нее) происходит пакетом данных, а кэш работает только с кэшстроками. Поэтому адрес первого байта кэшстроки всегда кратен размеру пакета данных, то есть начало кэшстроки всегда совпадает с началом пакета данных.
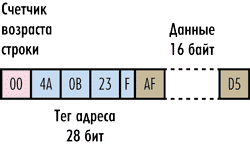
Рис. 3. Пример кэш-строки размером 16 байт
Теперь посмотрим, насколько эффективнее сохранять в кэшстроке не один байт, а фиксированный блок данных. Предположим, что размер кэшстроки составляет 32 байта. Возникает вопрос, какова должна быть при этом разрядность поля адреса тега? Если, как и ранее, рассматривается 32-разрядная адресация оперативной памяти, а тег, как мы отмечали, должен сохранять адрес первого байта кэшстроки, то, казалось бы, нужно четырехбайтовое поле адреса. Однако следует учесть, что данные в кэшстроках не могут перекрываться, а значит, теги всех строк должны быть кратны 32. Именно поэтому необходимая для адресации разрядность тега будет ниже. Предположим, к примеру, что в кэше сохраняется последовательная цепочка данных и адрес первого байта в оперативной памяти равен 0000 (в шестнадцатеричной системе). Тогда тег первой строки будет равен 0000, тег второй строки (адрес 32-го байта) — 0020, тег третьей строки — 0040 и т.д. То есть теги будут образовывать последовательность 0000, 0020, 0040, 0060, 0080, 00A0 и т.д. Если записать эту последовательность в двоичном виде, то можно заметить, что последние пять цифр в каждом теге всегда будут равны нулю. Эти пять нулей можно смело откинуть — тогда поле тега будет уже не 32-, а 27-битным.
Но в этом случае возникает вопрос: если процессору нужно получить доступ к отдельному байту, то как выделить его из кэшстроки? Всё очень просто. Процессор формирует именно 32-битный адрес, который делится на старшие 27 бит и младшие 5 бит. Старшие 27 бит используются для поиска нужной кэшстроки, а младшие 5 бит (смещение адреса) определяют конкретное положение нужного байта в строке, то есть по сути задают смещение данных относительно первого байта в кэшстроке. Этих пяти бит как раз достаточно для задания любого из 32 байт в строке кэша (25=32).
Вообще, правило в данном случае работает такое. Как уже отмечалось, размер кэшстроки всегда равен степени двойки. Тогда размер смещения адреса равен log2 S, где S — размер кэшстроки в байтах. Соответственно размер тега (в битах) равен 32 –log2 S.
Так, если размер кэшстроки равен 16 байт, то размер смещения адреса — 4 битам, а размер тега адреса — 28 битам (рис. 3). Если размер кэшстроки равен 64 байтам, то размер смещения адреса — 6 битам, а размер тега адреса — 26 битам.
Понятно, что описанная нами структура кэшпамяти имеет куда лучшее соотношение полезного и полного размеров. Попутно отметим, что под указываемым в документации размером кэшпамяти всегда подразумевается полезный размер.
Рассмотрим конкретный пример. Пусть имеется кэш размером 32 Кбайт и длина строки составляет 128 байт. Исходя из предположения, что кэш имеет структуру, описанную выше, определим полный размер кэша.
Прежде всего, такой кэш будет содержать 256 строк (32 Кбайт/128 байт). Каждая строка имеет тег размером 25 бит (32 – log2 128). Кроме того, нужно добавить еще счетчик старения, содержащий 8 бит (log2 256). То есть к каждой строке добавляется еще 33 служебных бита. А всего таких служебных бит будет 8448 или 1056 байт. Соответственно полный объем кэша составит чуть более 33 Кбайт. То есть полный объем кэша лишь немного превосходит его полезный объем.
В рассмотренном нами кэше мы не учитывали так называемые биты модификации, которые также добавляются в каждой строке кэша и необходимы для поддержания когерентности, о которой мы расскажем далее. Однако наличие этих дополнительных служебных бит принципиально не меняет соотношение между полным и полезным размерами кэшпамяти.
Понятие ассоциативности кэша
До сих пор мы не рассматривали, каким именно образом происходит отображение оперативной памяти на кэшпамять. Поскольку минимальной единицей информации, с которой работает кэш, является кэшстрока, условно разобьем всю оперативную память на блоки (строки), равные по размеру кэшстрокам. Предположим для простоты, что кэш состоит из восьми строк, а объем оперативной памяти равен 24 строкам кэша. Пронумеруем все строки так, чтобы нумерация начиналась с 0. То есть в кэшпамяти номер последней строки равен 7, а в оперативной памяти — 23. Возникает вопрос: как связать строки оперативной памяти со строками кэшпамяти? То есть если, к примеру, требуется загрузить в кэш первую строку оперативной памяти, то в какую именно строку кэшпамяти она будет загружаться? Вот тутто как раз и возможны различные варианты.
Полностью ассоциативная кэшпамять
Первый и самый простой вариант заключается в том, что любая строка оперативной памяти может быть записана в любую строку кэшпамяти. То есть каждая строка кэшпамяти может быть связана с любой строкой оперативной памяти и наоборот (рис. 4). Такая кэшпамять получила название полностью ассоциативной (fully associative).
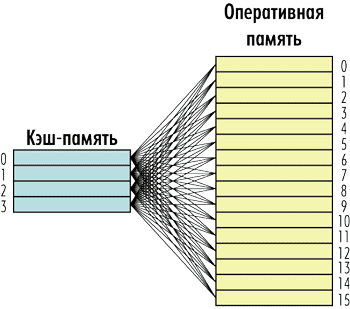
Рис. 4. Структура полностью ассоциативной
кэш-памяти
Полностью ассоциативный кэш имеет как свои плюсы, так и минусы. Главный его минус заключается в том, что поиск информации в нем по тегу строки требует сложной аппаратной реализации, а потому довольно дорог. Действительно, для того чтобы определить, имеются ли запрошенные процессором данные в кэшпамяти, нужно перебрать все кэшстроки, то есть сравнить тег кэшстроки со старшими битами адреса (напомним, что младшие биты адреса описывают смещение в самой кэшстроке). Наиболее простой способ — это последовательный перебор всех тегов. Однако при большом их количестве этот способ крайне непроизводителен, и, даже если несколько тегов будут просматриваться за один такт, поиск нужной кэшстроки может растянуться на сотни тактов, что сделает кэшпамять низкопроизводительной. Поэтому в случае полностью ассоциативного кэша приходится реализовывать параллельный одновременный просмотр всех тегов, что довольно сложно сделать. Да и с точки зрения энергопотребления параллельный просмотр всех тегов — не самое лучшее решение. Именно поэтому полностью ассоциативные кэши не могут иметь большой размер.
Кэшпамять с прямым отображением
Другой вариант организации отображения оперативной памяти на кэшпамять противоположен рассмотренному полностью ассоциативному кэшу. Это так называемый кэш прямого отображения (Direct mapping), когда каждая строка оперативной памяти соответствует не любой, а только одной, строго определенной строке кэшпамяти. В этом случае каждая строка оперативной памяти связана только с одной строкой кэшпамяти, а каждой строке кэшпамяти соответствует несколько строк оперативной памяти, но опять-таки не любых, а строго определенных.
В рассмотренном примере кэша из восьми строк и оперативной памяти из 24 строк можно установить следующую жесткую связь между кэшстроками и строками памяти. Строке кэшпамяти с номером 0 соответствуют строки оперативной памяти с номерами 0, 8 и 16; строке с номером 1 — строки с номерами 1, 9 и 17, а последней строке с номером 7 — строки с номерами 7, 15 и 23 (рис. 5). То есть в нашем примере каждой строке кэшпамяти будут соответствовать три строки оперативной памяти.
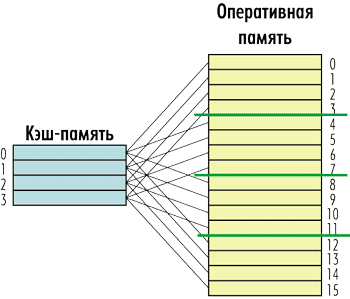
Рис. 5. Структура кэш-памяти с прямым отображением
Если обозначить через Ncache номер кэшстроки, через Nmax_cache количество строк кэшпамяти, а через Nmemory номер строки оперативной памяти, то достаточно очевидно, что соотношение между номерами строк оперативной памяти и номерами кэшстрок будет следующим:
Ncache = (Nmemory)mod(Nmax_cache),
где mod — это функция получения остатка от деления Nmemory на Nmax_cache.
К примеру, в нашем случае строка оперативной памяти с номером 8 попадет в строку кэшпамяти с номером 0, поскольку 8 mod 8 = 0, а строка оперативной памяти с номером 22 — в строку кэшпамяти с номером 6, поскольку 22 mod 8 = 6. Ну а строка оперативной памяти с номером 23 окажется в строке кэшпамяти с номером 7, поскольку 23 mod 8 = 7.
До сих пор мы говорили об отображении условных строк оперативной памяти на строки кэшпамяти. Однако можно рассмотреть и отображение конкретного элемента (байта) оперативной памяти на кэшпамять. То есть если нас интересует вопрос, в какой кэшстроке окажется элемент оперативной памяти с заданным адресом ADDR, то ответ следующий.
Несложно перейти от введенных нами ранее строк оперативной памяти к адресному пространству. Действительно, если элемент оперативной памяти имеет адрес ADDR, то он находится в оперативной памяти в строке с номером:
Ncache = (ADDR)div(CACHE LINE SISE),
где div — это функция целочисленного деления адреса элемента на размер кэшстроки CACHE LINE SIZE.
Аналогично количество строк кэшпамяти можно выразить следующим образом:
Nmax_cache = (CACHE SIZE)div(CACHE LINE SISE).
Тогда выражение, определяющее номер строки кэшпамяти, в которую попадет элемент оперативной памяти с адресом ADDR, запишется в виде:
Ncache = [(ADDR)div(CACHE LINE SISE)]mod[(CACHE SISE)div(CACHE LINE SISE)].
Несомненный плюс кэшпамяти с прямым отображением заключается в том, что поиск элементов в такой памяти происходит очень быстро, поскольку для этого нужно просмотреть тег только одной кэшстроки.
Однако у такой кэшпамяти есть и очень существенный недостаток. Представьте ситуацию, когда процессор пытается последовательно обратиться к строкам оперативной памяти с условными номерами 0, 8 и 16 (в рассмотренном ранее примере). Все эти строки оперативной памяти жестко связаны с одной и той же строкой кэшпамяти с номером 0. При каждом таком обращении будет происходить помещение содержимого строк оперативной памяти в одну и ту же строку кэша. Причем помещение данных в кэш будет производиться путем их замещения, то есть процессор будет сначала размещать данные в кэшстроку, а потом эти же данные будут записываться обратно в оперативную память, а на их место в кэшпамяти будут записываться новые данные. И это несмотря на тот факт, что в кэше могут быть пустые кэшстроки (кэшстроки с неактуальными данными). Конечно, такой алгоритм работы памяти крайне неэффективен, а всё из-за того, что у процессора нет свободы выбора: все строки кэшпамяти жестко связаны с элементами оперативной памяти. Поэтому в настоящее время такой тип кэшпамяти в процессорах не встречается.
Наборно-ассоциативный кэш
Промежуточным вариантом между полностью ассоциативным кэшем и кэшем с прямым отображением является наборноассоциативный кэш (N-way cache — N-канальный кэш).
Такой кэш состоит из нескольких независимых банков (сегментов), каждый из которых представляет собой кэш с прямым отображением, а сами банки являются полностью ассоциативными по отношению к оперативной памяти. То есть любой элемент оперативной памяти может быть размещен в любом банке кэшпамяти, однако внутри банка ему соответствует строго определенная кэшстрока (рис. 6).
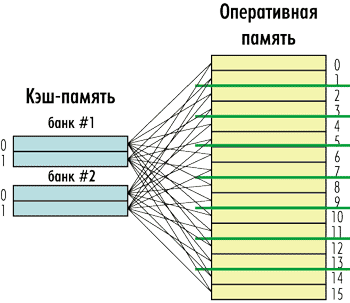
Рис. 6. Структура наборно-ассоциативного кэша
Количество банков кэша называется его степенью ассоциативности или канальностью (way). То есть может быть 2-канальный (2-way), 4-канальный (4-way), 8-канальный (8-way) и т.д. кэш. Причем количество каналов кэша — это степень числа 2. Наибольшее распространение получили 4- и 8-канальные кэши. На рис. 6 в качестве примера показан 4-канальный кэш.
Отметим, что при количестве каналов равном 1 мы получаем кэш прямого отображения, а если число каналов совпадает с числом кэшстрок — то получается полностью ассоциативный кэш.
Определить, в какую именно строку кэшпамяти попадет элемент оперативной памяти, довольно просто. Поскольку каждый банк кэшпамяти является сегментом памяти с прямым отображением, в нем действует то же правило, что и для кэшпамяти с прямым отображением, то есть:
Nbank_cache = (Nmemory)mod(Nmax_bank_cache).
Только в данном случае Nbank_cache — это номер кэшстроки в банке памяти; Nmax_bank_cache — количество строк кэшпамяти в банке; а Nmemory — номер строки оперативной памяти. Поскольку количество строк кэшпамяти в банке определяется очевидным соотношением Nmax_bank_cache = Nmax_cache/N, где Nmax_cache — количество строк в кэшпамяти, а N — степень его ассоциативности (количество банков или каналов).
Рассмотрим, к примеру, 4-канальный кэш с восемью кэшстроками и оперативную память, размер которой соответствует 24 кэшстрокам. Такой кэш делится на четыре банка, причем в каждом банке две кэшстроки.
Тогда строка оперативной памяти с номером 3 может находиться в кэшстроке с номером 1 (3 mod 2 = 1) любого из четырех банков (см. рис. 6).
Наборно-ассоциативный кэш обладает быстродействием, сравнимым с быстродействием кэша с прямым отображением, и в то же время лишен недостатка, присущего этому кэшу.
Понятно, что наборноассоциативный кэш должен иметь несколько иную структуру тега. Напомним, что в случае 32-битной адресации при размере кэшстроки S байт размер тега в битах равен 32 –log2 S в случае полностью ассоциативного кэша. Так, если размер кэшстроки равен 64 байтам, то размер тега адреса — 26 битам.
Если имеется N-канальный кэш, то потребуется log2 N бит для задания номера банка и размер тега, который нужно записывать в кэш в каждом банке, уменьшится на log2 N. Так, в случае 4-канального кэша с размером строки 64 байта размер тега составит уже 24 бита.
Когерентность кэша
Под когерентностью кэшпамяти понимается алгоритм, обеспечивающий согласованность содержимого оперативной памяти и кэшпамяти. Обеспечение когерентности кэшпамяти — это очень важная задача, выполняемая кэшконтроллером. Если бы оперативная память была доступна только на чтение, то копия данных в кэшпамяти всегда совпадала бы с оригиналом данных в оперативной памяти. Однако оперативная память доступна и для записи, что ставит задачу своевременной модификации данных в оперативной памяти. Действительно, к оперативной памяти могут обращаться не только процессор, но и периферийные устройства, а во многопроцессорных и многоядерных процессорах разные процессоры или ядра.
Допустим, к некоторой ячейке памяти, уже модифицированной в кэше, но еще не выгруженной в основную память, обращается периферийное устройство или другой процессор. В этом случае кэшконтроллер должен сначала обновить содержимое соответствующей ячейки оперативной памяти, иначе оттуда будут считаны неактуальные данные. Аналогично, если периферийное устройство или другой процессор изменяет содержимое ячейки оперативной памяти, кэшконтроллер должен выяснить, загружены ли модифицированные ячейки в его кэшпамять, и если да, то их необходимо обновить.
То есть нужно своевременно отслеживать изменение данных в кэше и оперативной памяти и синхронизировать эти изменения — поддерживать когерентность между кэшем и оперативной памятью.
Поддержка когерентности кэша и оперативной памяти может осуществляться различными способами. Самое простое, но и самое неэффективное решение — это так называемая сквозная запись (Write True). Данный алгоритм предполагает, что оперативная память кэшируется только на чтение, а запись осуществляется напрямую, минуя кэш, сразу в оперативную память. Понятно, что в силу своей неэффективности этот алгоритм поддержания когерентности не используется в современных процессорах. Однако отметим, что именно такой алгоритм применялся в процессоре Intel 80486.
Более сложный алгоритм поддержания когерентности — это алгоритм обратной записи (Write Back). Он предполагает, что для отслеживания операций модификации данных в кэшпамяти каждая кэшстрока имеет специальный флаг состояния. Если данные кэшстроки подверглись модификации, то флаг устанавливается в состояние «модифицированное» (Dirty). Когда периферийное устройство обращается к памяти, то кэшконтроллер проверяет, имеются ли соответствующие данные в кэше, и если да, то по флагу модификации определяется, были ли они модифицированы, то есть актуальны ли данные в оперативной памяти. Если данные были модифицированы, то в оперативной памяти данные не актуальны и содержимое соответствующей кэшстроки выгружается в оперативную память, а флаг устанавливается в состояние «не модифицировано» (Clear). При замещении кэшстрок кэшконтроллер также проверяет сначала состояние флага, и если строка была модифицирована, то она прежде выгружается в оперативную память.
В современных процессорах реализация когерентности осуществляется по протоколу MESI, который является вариантом алгоритма Write Back, но с четырьмя возможными значениями флага модификации кэшстроки: M (Modified), E (Exclusive), S (Shared) и I (Invalid) (см. таблицу).
Если кэшстрока имеет флаг Modified (Модифицировано), то она модифицирована и содержит наиболее свежие, корректные данные, а соответствующие этой строке данные в оперативной памяти устарели и недействительны. Кроме того, в случае многопроцессорных систем ни один другой кэш не имеет этой копии данных. Статус Modified автоматически присваивается кэшстрокам при их модификации. Кэшстрока с таким флагом не может быть просто удалена из кэша, и при замещении она обязательно должна выгружаться в кэшпамять более высокой иерархии или же в оперативную память. Кроме того, данные такой кэшстроки могут быть повторно модифицированы без какихлибо запросов и изменений состояния. При записи измененных данных в оперативную память состояние может поменяться на Exclusive.
Если кэшстрока имеет флаг Exclusive (Эксклюзивно), то это означает, что данные этой кэшстроки эксклюзивны и не присутствуют в других кэшах (в случае многоуровневого кэша). Кэшстрока в эксклюзивном состоянии содержит наиболее свежие, корректные данные, а их копия в оперативной памяти — наиболее свежую, корректную копию данных.
Флаг Exclusive автоматически присваивается кэшстрокам при их загрузке из кэша более высокой иерархии или оперативной памяти. Кэшстрока с флагом Exclusive при ее замещении может быть либо просто удалена, либо обменивается своим содержимым с одной из строк кэшпамяти более высокой иерархии в случае многоуровневого кэша. Состояние Exclusive может измениться на Modified в любой момент для модификации содержимого данной кэшстроки. Также состояние в любой момент может поменяться на Invalid.
Флаг Shared (Разделяемое) актуален для многопроцессорных систем и означает, что копии данных этой кэшстроки также могут храниться в других кэшах иных процессоров. Кэшстрока в состоянии Shared содержит наиболее свежие, корректные данные, а копия в оперативной памяти — наиболее свежую, корректную копию данных. Запись в данную кэшлинию запрещена и требует перевода ее в состояние Exclusive с одновременным переводом всех остальных разделяемых копий в состояние Invalid. Также состояние Shared может измениться на состояние Invalid в любой момент.
Если кэшстрока имеет флаг Invalid (Неактуально), то это означает, что кэшстрока не содержит корректных данных. Корректные копии данных могут быть либо в основной памяти, либо в кэше другого процессора.
Протокол MESI несовершенен, но довольно прост в реализации и хорошо подходит для однопроцессорных конфигураций с одним или двумя уровнями кэшпамяти. Отметим, что существует несколько разновидностей протокола MESI, таких как MSI (Modified, Shared, Invalid), MOSI (Modified, Owned, Shared, Invalid), MOESI (Modified, Owned, Exclusive, Shared, Invalid) и MOWESI (Modified, Owned, Written, Exclusive, Shared, Invalid).
Протоколы MSI и MOSI неактуальны, а вот протоколы MOESI и MOWESI применяются в современных процессорах.
Отметим, что протокол MESI требует два бита в кэшстроке для задания ее состояния, а такие протоколы, как MOESI и MOWESI, — уже три бита.
Протокол MOESI (впервые стал использоваться в процессорах AMD) позволяет избежать главного недостатка протокола MESI — невозможности хранения измененных кэшстрок более чем в одном кэше. Для этого и было введено новое состояние Owned (владелец), которое означает владение правами собственности на данную строку кэшпамяти, ее копии в других кэшах и оперативной памяти.
Однако протокол MOESI тоже неидеален. Фактически состояние Owned дает преимущества процессору — владельцу кэшстроки, но ставит остальные процессоры в положение «только для чтения». А если кому-нибудь из них необходимо выполнить запись в свою кэшстроку с состоянием Shared, то приходится производить ее и в оперативную память, что приводит к ликвидации состояния Owned у другого процессора. Это несколько неэффективно в многопоточных средах, где различные процессоры или процессорные ядра могут одновременно выполнять разные потоки одного и того же процесса. Для повышения производительности в этом случае и было введено состояние Written, которое привело к созданию протокола MOWESI. При записи в кэшстроку с состоянием Shared ее статус меняется на Written, а остальные процессоры должны ликвидировать или обновить свои устаревшие копии, после чего состояние их кэшстрок меняется на Modified или Owned. Обновления оперативной памяти удается при этом избежать в обоих случаях. Отметим, что поддержка данного протокола впервые появилась в двухъядерном процессоре IBM POWER5.
Многоуровневая организация кэша
Все современные процессоры имеют как минимум двухуровневую структуру кэшпамяти, а большинство процессоров Intel — трехуровневую кэшпамять. При этом различают кэш первого уровня (обозначается L1), кэш второго уровня (L2) и кэш третьего уровня (L3). Причем в случае процессоров Intel кэши всех уровней размещены на кристалле процессора.
Казалось бы, зачем нужно делать так много кэшей? Не проще ли создать один большой кэш? Оказывается, не проще. Проблема заключается в том, что чем больше размер кэша, тем ниже его скорость. То есть можно сделать один большой, но медленный кэш, а можно — несколько маленьких, но быстрых кэшей, и второй вариант оказывается более предпочтительным.
Кроме того, кэши разных уровней в процессоре выполняют различные задачи. Так, самый быстрый и маленький кэш первого уровня L1 всегда делится на кэш данных (L1D) и кэш команд или инструкций (L1I). Это так называемая гарвардская архитектура процессора. Кэш L1 всегда принадлежит только конкретному ядру процессора.
Кэш второго уровня L2 является уже унифицированным (содержит и данные и команды). Кэш L2 всегда больше, чем кэш L1, но медленнее его. В случае многоядерных процессоров кэш L2 принадлежит конкретному ядру процессора.
А вот кэш L3 является самым большим и медленным и разделяется между всеми ядрами процессора (в архитектуре процессоров Intel).
Понятно, что в случае, когда в процессоре имеется многоуровневая система кэшпамяти, необходимо организовать взаимодействие между кэшами разных уровней.
Для начала рассмотрим двухуровневую систему кэша. Такая кэшпамять строится на базе одной из двух архитектур: включающей, которую также называют инклюзивной (inclusive), и исключающей, именуемой эксклюзивной (exclusive). То есть кэш L2 всегда построен либо по включающей, либо по исключающей архитектуре по отношению к кэшу L1 (отметим, что при наличии кэша L3 кэши L2 и L1 могут быть и не включающими, и не исключающими по отношению друг к другу).
Кэш L2, построенный по включающей архитектуре, всегда дублирует содержимое кэша L1, а потому эффективная емкость кэшпамяти равна емкости кэша L2.
Кэш L2, построенный по исключающей архитектуре, никогда не дублирует содержимое кэша L1, а потому эффективная емкость кэшпамяти равна суммарной емкости кэшей L1 и L2.
Пусть кэш имеет включающую архитектуру. Рассмотрим, каким образом происходит запись данных из оперативной памяти в такой кэш. Если в такой системе кэшпамяти при полностью заполненном кэше L2 процессор пытается загрузить еще одну кэшстроку, то произойдет следующее. Обнаружив, что все кэшстроки заняты, кэш L2 избавляется от наименее ценной из них, стремясь при этом найти линейку, которая еще не была модифицирована, поскольку в противном случае ее еще придется выгружать в оперативную память.
Затем кэш L2 передает полученные из памяти данные кэшу L1. Если кэш первого уровня также заполнен, ему приходится избавляться от одной из кэшстрок по сценарию, описанному выше.
Таким образом, загруженная порция данных присутствует и в кэше L1, и в кэше L2.
Отметим, что процессоры Intel Pentium II и Pentium III имели двухуровневый кэш, построенный по включающей архитектуре.
В случае кэша, построенного по исключающей архитектуре, кэш L1 никогда не уничтожает кэшстроки при нехватке места. Даже если кэшстроки не были модифицированы, они вытесняются в кэш L2 на то место, где находилась только что переданная кэшу L1 кэшстрока. То есть кэши L1 и L2 как бы обмениваются друг с другом своими кэшстроками, благодаря чему кэшпамять используется весьма эффективно.
Иерархия кэшпамяти в микроархитектуре Intel Core
В заключение рассмотрим конкретный пример организации многоуровневой кэшпамяти в процессорах c микроархитектурой Intel Core.
Все современные процессоры Intel основаны на базе микроархитектуры Intel Core (которая в плане кэша не отличается от микроархитектуры Nehalem) и имеют трехуровневую подсистему кэшпамяти.
Кэшпамять первого уровня L1 делится на 8-канальный 32-килобайтный кэш данных (L1D) и 4-канальный 32-килобайтный кэш инструкций (L1I).
Каждое ядро процессора имеет унифицированный (единый для инструкций и данных) кэш второго уровня (L2) размером 256 Кбайт. Кэш L2 является также 8-канальным, а размер строки кэша составляет 64 байт.
Кэш третьего уровня (L3) разделяется между всеми ядрами процессора. Его размер зависит от количества ядер процессора. Кэш L3 является 16-канальным.
Кэш L3 — включающий по своей архитектуре по отношению к кэшам L1 и L2, то есть в кэше L3 всегда дублируется содержимое кэшей L1 и L2. А вот кэши L1 и L2 не являются ни включающими, ни исключающими по отношению друг к другу, то есть кэш L2 может содержать, а может и не содержать копию данных кэша L1.
Применение именно включающего кэша L3 имеет свои преимущества по сравнению с исключающей архитектурой. Рассмотрим несколько характерных примеров чтения данных из кэша L3 в четырехъядерном процессоре Intel. Предположим сначала, что ядро процессора Core 0, обнаружив, что требуемых ему данных нет ни в кэше L1, ни в кэше L2, обращается к кэшу L3. Если необходимых данных нет также и в кэше L3, то в случае исключающей архитектуры кэша L3 потребовалось бы проверить и наличие требуемых данных в кэшах L1 и L2 каждого из ядер Core 1, Core 2 и Core 3. При включающей архитектуре кэша L3 надобность в подобной проверке отпадает, поскольку включающая архитектура кэша L3 гарантирует, что при отсутствии данных в кэше L3 их также не будет в кэшах L1 и L2.
Если же требуемые ядру Core 0 данные обнаруживаются в кэше L3, то при исключающей архитектуре кэша больше не нужно выполнять никаких действий, поскольку данная архитектура гарантирует их отсутствие в кэшах L1 и L2 ядер Core 1, Core 2 и Core 3. Однако при включающей архитектуре кэша L3 наличие требуемых данных в кэше L3 означает, что они также содержатся в какомнибудь из кэшей ядер Core 1, Core 2 или Core 3. Но в этом случае не нужна дополнительная проверка кэшей L1 и L2 всех остальных ядер. Достигается это тем, что в теге кэшстроки L3-кэша записывается, к какому из ядер принадлежат данные, поэтому достаточно лишь прочитать содержимое этого тега.








