Процессор Haswell
Блок внеочередного исполнения команд
Исполнительные блоки ядра процессора
Подсистема памяти в микроархитектуре Haswell
Новые режимы энергосбережения в процессоре Haswell
Графическое ядро в микроархитектуре Haswell
Модельный ряд процессоров Haswell
Производительность в неигровых приложениях
Одним из самых значимых событий этого года в сегменте настольных ПК безусловно можно считать выпуск нового семейства процессоров Intel Core четвертого поколения, известных под кодовым наименованием Haswell. В этой статье мы вкратце рассмотрим микроархитектуру Haswell и сравним производительность процессора Intel Core i7-4770 на базе этой микроархитектуры с производительностью процессора Intel Core i7-3770 на базе микроархитектуры предыдущего поколения Sandy Bridgе.
Напомним, что уже в течение многих лет выход новых поколений процессоров Intel подчиняется эмпирическому правилу TICK-TOCK («тиктак»), суть которого заключается в том, что перевод производства на новый технологический процесс (TICK) и внедрение новой процессорной микроархитектуры (TOCK) происходит поочередно, с периодичностью примерно в два года. То есть если в первый год происходит переход на новый техпроцесс производства, то на второй год на этом же техпроцессе внедряется новая процессорная микроархитектура. На следующий год происходит перенос микроархитектуры на новый техпроцесс производства и т.д.
В частности, в 2012 году компания Intel выпустила 22-нм версию процессоров на базе микроархитектуры Sandy Bridge, которые известны под кодовым наименованием Ivy Bridge (цикл TICK), а теперь настал черед выпуска 22-нм процессоров на базе новой процессорной микроархитектуры Haswell.
Подробно об особенностях новой микроархитектуры Haswell мы уже писали в КомпьютерПресс № 10’2012. Однако с тех пор прошло много времени, а самое главное — стали известны новые подробности этой микроархитектуры. А потому позволим себе в чемто повториться и сделать краткий обзор микроархитектуры Haswell, акцентируясь на тех деталях, которые в нашем предыдущем обзоре были опущены.
Вычислительное ядро Haswell
Haswell — это кодовое название новой процессорной микроархитектуры, но по традиции этим же именем называются все базирующиеся на ней процессоры. Кроме того, Haswell — это кодовое название ядра процессора Haswell, что вполне логично, поскольку микроархитектура и ядро процессора — это две стороны одной медали.
Итак, рассмотрим вкратце микроархитектуру Haswell (или вычислительное ядро Haswell, что в принципе одно и то же).
Вычислительное ядро Haswell не претерпело кардинальных изменений в сравнении с вычислительным ядром Ivy Bridge/Sandy Bridge — были улучшены лишь отдельные блоки ядра процессора. А потому уместным будет напомнить в общих чертах микроархитектуру Sandy Bridge и остановиться на внесенных в нее изменениях.
Блок предпроцессора
Традиционно описание микроархитектуры ядра процессора начинается с блока предпроцессора (front-end), который отвечает за выборку инструкций x86 из кэша инструкций и их декодирование (рис. 1). В микроархитектуре Haswell блок предпроцессора претерпел минимальные изменения.
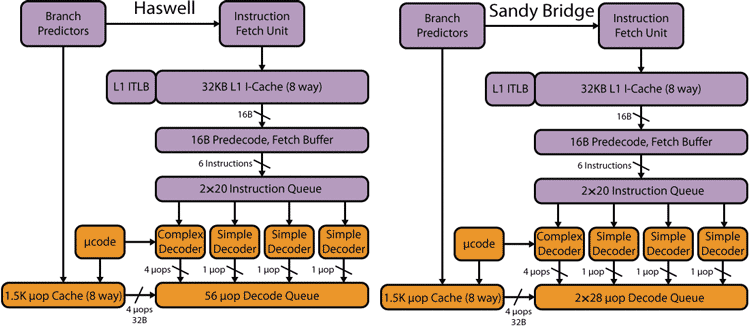
Рис. 1. Предпроцессор в микроархитектурах Haswell и Sandy Bridge
Инструкции x86 выбираются из кэша инструкций L1I (Instruction Сache), который не изменился в микроархитектуре Haswell. Он имеет размер 32 Кбайт, является 8-канальным и динамически разделяем между двумя потоками инструкций (поддержка технологии Hyper-Threading).
Из кэша L1I команды загружаются 16-байтными блоками в 16-байтный буфер предкодирования (Fetch Buffer).
Поскольку инструкции x86 имеют переменную длину (от 1 до 16 байт), а длина блоков, которыми команды загружаются из кэша, фиксированная, при декодировании команд определяются границы между отдельными командами (информация о размерах команд хранится в кэше инструкций L1I в специальных полях). Процедура выделения команд из выбранного блока называется предварительным декодированием (PreDecode).
После операции выборки команды организуются в очередь (Instruction Queue). В микроархитектуре Sandy Bridge и Haswell буфер очереди команд рассчитан на 20 команд в каждом из двух потоков, причем из буфера предкодирования за каждый такт в буфер очереди команд могут загружаться до шести выделенных команд.
После этого выделенные команды (x86-инструкции) передаются в декодер, где они преобразуются в машинные микрооперации (обозначаются как micro-ops или uOps).
Декодер ядра процессора Haswell остался без изменений. Он по-прежнему является четырехканальным и может декодировать в каждом такте до четырех инструкций x86. Как уже отмечалось, длина одной команды может достигать 16 байт, однако средняя длина команд составляет 4 байта. В среднем в каждом 16-байтном блоке загружаются четыре команды, которые при использовании четырехканального декодера одновременно декодируются за один такт.
Четырехканальный декодер состоит из трех простых декодеров, декодирующих простые инструкции в одну микрооперацию, и одного сложного, который способен декодировать одну инструкцию не более чем в четыре микрооперации (декодер типа 4-1-1-1). Для еще более сложных инструкций, декодирующихся более чем в четыре микрооперации, сложный декодер соединен с блоком uCode Sequenser, который и применяется для декодирования подобных инструкций.
При декодировании инструкций используются технологии Macro-Fusion и Micro-Fusion.
Macro-Fusion — это слияние двух x86-инструкций в одну сложную микрооперацию micro-ops, которая в дальнейшем будет выполняться как одна микрооперация. Естественно, такому слиянию могут подвергаться не любые инструкции, а только некоторые пары инструкций (например, инструкция сравнения и условного перехода). Без применения технологии Macro-Fusion за каждый такт процессора могут декодироваться только четыре инструкции (в четырехканальном декодере), а при использовании технологии Macro-Fusion в каждом такте могут считываться пять инструкций, которые за счет слияния преобразуются в четыре и подвергаются декодированию.
Отметим, что для эффективного поддержания технологии Macro-Fusion применяются расширенные блоки ALU (Arithmetical Logic Unit), способные поддержать выполнение слитых микроопераций.
Micro-Fusion — это слияние двух микроопераций (не x86-инструкций, а именно микроопераций) в одну, содержащую два элементарных действия. В дальнейшем две такие слитые микрооперации обрабатываются как одна, что позволяет снизить количество обрабатываемых микроопераций, а следовательно, увеличить общее количество исполняемых процессором инструкций за один такт.
Кроме того, в микроархитектуре Haswell и Sandy Bridge применяется кэш декодированных микроопераций (Uop Cache), в который поступают все декодированные микрооперации. Этот кэш рассчитан приблизительно на 1500 микроопераций средней длины. Кэш декодированных микроопераций представляет собой восемь банков (то есть данный кэш является 8-канальным), каждый из которых состоит из 32 кэшстрок, а каждая кэшстрока вмещает до шести декодированных микроопераций (uop). Отсюда и получается, что кэш может содержать примерно 1500 микроопераций.
Концепция кэша декодированных микроопераций заключается в том, чтобы сохранять в нем уже декодированные последовательности микроопераций. В результате, если нужно выполнить некую x86-инструкцию повторно, а соответствующая ей последовательность декодированных микроопераций все еще находится в кэше декодированных микроопераций, не требуется вторично выбирать эту инструкцию из кэша L1 и декодировать ее — из кэша на дальнейшую обработку поступают уже декодированные микрооперации.
После процесса декодирования x86-инструкций они, по четыре штуки за такт, поступают в буфер очереди декодированных инструкций (Decode Queue). В микроархитектуре Sandy Bridge этот буфер очереди декодированных инструкций был рассчитан на два потока команд по 28 микроопераций на каждый поток. В микроархитектурах Ivy Bridge и Haswell он не делится на два потока команд и рассчитан на 56 микроопераций. Такой подход оказывается более предпочтительным при выполнении однопоточного приложения (с одним потоком команд). В этом случае одному потоку команд доступен буфер емкостью на 56 микроопераций, а в микроархитектуре Sandy Bridge — только на 28 микроопераций.
Казалось бы, если сравнивать ядра процессоров Haswell и Ivy Bridge, то разницы в их предпроцессорах нет вообще, а предпроцессоры ядер Haswell и Sandy Bridge различаются лишь структурой буфера очереди декодированных инструкций.
Тем не менее, как заявляет компания Intel, некоторые улучшения в предпроцессор Haswell все же были внесены и касались усовершенствования блока предсказания ветвлений (Branch Predictors). Однако, какие именно улучшения были реализованы, компания Intel не раскрывает.
Заканчивая описание предпроцессора в микроархитектуре Haswell, нужно также упомянуть и о TLB-буфере.
Буфер TLB (Translation Look-aside Buffers) — это специальный кэш процессора, в котором сохраняются адреса декодированных инструкций и данных, что позволяет значительно сократить время доступа к ним. Этот кэш предназначен для сокращения времени преобразования виртуального адреса данных или инструкций в физический. Дело в том, что процессор использует виртуальную адресацию, а для доступа к данным в кэше или оперативной памяти нужны реальные физические адреса. Преобразование виртуального адреса в физический занимает приблизительно три такта процессора. TLB-кэш хранит результаты предыдущих преобразований, благодаря чему преобразование адреса возможно осуществлять за один такт.
В процессорах c микроархитектурой Haswell и Sandy Bridge (как и в процессорах Intel на базе других микроархитектур) используется двухуровневый кэш TLB, причем если кэш L2 TLB является унифицированным, то L1 TLB-кэш разделен на буфер данных (DTLB) и буфер инструкций (ITLB).
L1 TLB-кэши инструкций и данных в микроархитектуре Haswell не претерпели изменений — они точно такие же, как и в микроархитектуре Sandy Bridge. L1 ITLB-кэш инструкций рассчитан на 128 записей, в случае если каждая запись адресует страницу памяти емкостью 4 Кбайт. Таким образом, при применении 4 Кбайт страниц памяти L1 ITLB-кэш может адресовать 512 Кбайт памяти. В случае страниц емкостью 4 Кбайт ITLB-кэш является 4-канальным и статически разделен между двумя потоками команд. Кроме того, L1 ITLB-кэш может адресовать 2 Мбайт страниц памяти. В этом случае кэш содержит восемь записей на каждый поток и является полностью ассоциативным.
Блок внеочередного исполнения команд
После процесса декодирования x86-инструкций начинается этап их внеочередного исполнения (Out-of-Order).
На первом этапе происходит переименование и распределение дополнительных регистров процессора, которые не определены архитектурой набора команд. Техника переименования регистров будет бессмысленной без переупорядочения команд. Поэтому из буфера очереди декодированных инструкций (Decode Queue) микрооперации по четыре штуки за такт поступают в буфер переупорядочения (ReOrder Buffer), где происходит переупорядочение микроопераций не в порядке их поступления (Out-of-Order).
В микроархитектуре Sandy Bridge размер буфера переупорядочения рассчитан на 168 микроопераций, а в микроархитектуре Haswell — на 192 микрооперации.
Отметим, что буфер переупорядочения (ReOrder Buffer) и блок отставки (Retirement Unit) совмещены в едином блоке процессора, но первоначально производится переупорядочение инструкций, а блок Retirement Unit включается в работу позже, когда надо выдать исполненные инструкции в заданном программой порядке.
Далее происходит распределение микроопераций по исполнительным блокам. В блоке процессора Unified Scheduler формируются очереди микроопераций, в результате чего микрооперации попадают на один из портов функциональных устройств (Dispatch ports). Этот процесс называется диспетчеризацией (Dispatch), а сами порты выполняют функцию шлюза к функциональным устройствам.
В микроархитектурах Sandy Bridge и Haswell кластеры внеочередного выполнения команд (Out-of-Order Cluster) используют так называемые физические регистровые файлы (Physical Register File, PRF), в которых хранятся операнды микроопераций.
Напомним, что, когда в ядрах процессоров не применялись физические регистровые файлы (например, в микроархитектуре Nehalem), каждая микрооперация имела копию необходимого ей операнда (или операндов). Фактически это означало, что блоки кластера внеочередного выполнения команд должны были обладать достаточно большим размером, чтобы иметь возможность вмещать микрооперации вместе с требуемыми им операндами.
Использование PRF позволяет самим микрооперациям сохранять лишь указатели на операнды, но не сами операнды. С одной стороны, такой подход обеспечивает снижение энергопотребления процессора, поскольку перемещение по конвейеру микроопераций вместе с их операндами требует существенных затрат по энергопотреблению. С другой — применение физического регистрового файла позволяет сэкономить размер кристалла, а высвободившееся пространство использовать для увеличения размеров буферов кластера внеочередного выполнения команд.
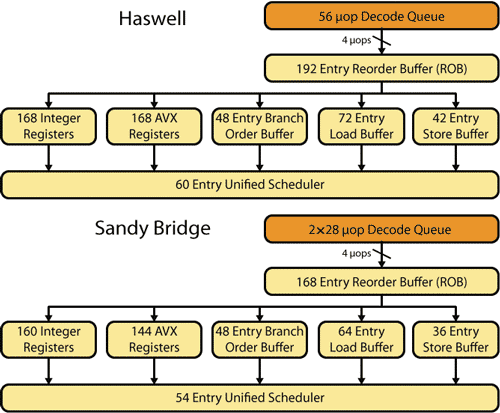
Рис. 2. Блоки внеочередного выполнения команд
в микроархитектурах Haswell и Sandy Bridge
В микроархитектуре Sandy Bridge физический регистровый файл для целочисленных операндов (Integer Registers) рассчитан на 160 записей, а для операндов с плавающей запятой (AVX Registers) — на 144 записи.
В микроархитектуре Haswell физические регистровые файлы Integer Registers и AVX Registers рассчитаны на 168 записей.
Буферы чтения (Load) и записи (Store), которые используются для доступа к памяти, также увеличились. Например, если в микроархитектуре Sandy Bridge буферы Load и Store были рассчитаны на 64 и 36 записей соответственно, то в микроархитектуре Haswell они рассчитаны соответственно на 72 и 42 записи.
Размер буфера Unified Scheduler, в котором формируются очереди микроопераций к портам функциональных устройств, также изменился в микроархитектуре Haswell. Если в Sandy Bridge он был рассчитан на 54 микрооперации, то в Haswell — на 60.
Итак, если сравнивать архитектуры Haswell и Sandy Bridge, то в блоке внеочередного исполнения команд микроархитектура Haswell имеет не структурные, а лишь качественные изменения, касающиеся увеличения размеров буферов. Но никаких принципиальных изменений в блоке внеочередного исполнения команд в микроархитектуре Haswell нет.
Исполнительные блоки ядра процессора
Что касается исполнительных блоков ядра процессора, то в микроархитектуре Haswell они претерпели существенные изменения по сравнению с микроархитектурой Sandy Bridge. Так, в Sandy Bridge насчитывается шесть портов функциональных устройств (портов диспетчеризации): три вычислительных и три для работы с памятью (на рис. 3 показаны только вычислительные порты).
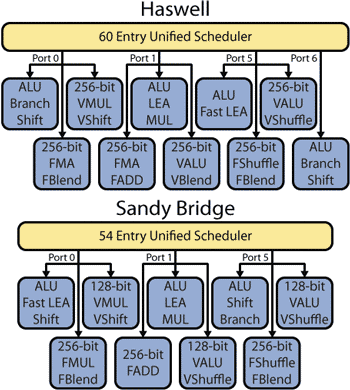
Рис. 3. Исполнительные блоки в микроархитектурах Sandy Bridge
и Haswell (порты для работы с памятью не показаны)
В микроархитектуре Haswell количество портов функциональных устройств увеличено до восьми. К тому, что было в микроархитектуре Sandy Bridge, добавили еще один порт для записи адреса (Store address) и вычислительный порт для операций с целыми числами и операций сдвига (Integer ALU & Shift). Таким образом, процессоры Haswell могут за один такт выполнять до восьми микроопераций, в то время как в микроархитектуре Sandy Bridge максимальное количество выполняемых за такт микроопераций равно шести.
Кроме того, в микроархитектуре Haswell немного изменены и сами исполнительные устройства. Связано это с тем, что в микроархитектуре Haswell появились дополнительные наборы инструкций: AVX2, FMA3 и BMI.
Набор инструкций AVX2 (Advanced Vector Instructions) является расширением набора инструкций AVX, который присутствует в микроархитектуре Sandy Bridge. Вообще, набор инструкций AVX является логическим продолжением наборов инструкций SSE, SSE2, SSE3 и SSE4. Для обработки данных в инструкциях AVX используется 16 векторных регистров разрядностью по 256 бит, благодаря чему можно во много раз ускорить многие операции. К примеру, умножение четырех 64-разрядных чисел с использованием AVX-команды возможно всего за один такт, в то время как без AVX-инструкции для этого потребуется четыре такта.
Главное отличие нового набора инструкций AVX2 от прежней версии AVX заключается в том, что если ранее 256-битные операции с AVX-регистрами были доступны только для операнда с плавающей запятой, а для целочисленных операндов были доступны лишь 128-битные операции, то в AVX2 256-битные операции стали доступны и для целочисленных операндов. Фактически, при использовании AVX за один такт можно реализовать 16 операций с числами одинарной точности и восемь операций с числами двойной точности. А при использовании AVX2 за один такт можно реализовать 32 операции с числами одинарной точности и 16 операций с числами двойной точности.
Кроме того, в AVX2 появилась улучшенная поддержка сдвигов и перестановок в векторных операциях. Есть и новые инструкции, используемые для сборки нескольких (четырех или восьми) несвязанных элементов в один векторный элемент, благодаря чему есть возможность более полно загружать 256-битные AVX-регистры.
Новый набор инструкций FMA3 (Fused Multiply Add) предназначен для проведения операций совмещенного умножения и сложения над тремя операндами.
Использование операций FMA3 позволяет более эффективно реализовать операции деления, извлечения квадратного корня, умножение векторов и матриц и т.д. Набор FMA3 включает 36 инструкций с плавающей точкой для выполнения 256-битных вычислений и 60 инструкций для 128-битных векторов.
В набор команд BMI (Bit Manipulation Instructions) входят 15 скалярных инструкций для битовых операций, которые работают с целочисленными регистрами общего назначения. Эти инструкции разбиты на три группы: манипуляции над отдельными битами, такие как вставка, сдвиг и извлечение бит, подсчет битов, например подсчет ведущих нулей в записи чисел, и целочисленное умножение произвольной точности. Данный набор инструкций позволяет ускорять ряд специфических операций, используемых, например, при шифровании.
Подсистема памяти в микроархитектуре Haswell
Одно из наиболее значимых изменений в микроархитектуре Haswell в сравнении с Sandy Bridge было сделано в подсистеме памяти. И дело не только в том, что увеличен размер буферов чтения (Load) и записи (Store), которые используются для доступа к памяти (72 и 42 записи соответственно). Главное, был добавлен еще один порт для записи адреса (Store address), кэш данных L1 стал более производительным, а пропускная способность между кэшами L1 и L2 увеличена. Рассмотрим эти изменения более подробно.
Доступ к подсистеме памяти начинается с того, что соответствующие микрооперации поступают в буферы чтения (Load) и записи (Store), которые в совокупности могут накапливать более ста микроопераций. В микроархитектуре Sandy Bridge порты функциональных устройств, которые маркируются на схемах как 2, 3 и 4, отвечали именно за доступ к памяти (рис. 4). Порты 2 и 3 связаны с функциональными устройствами генерации адреса (Address Generation Unit, AGU) для записи или чтения данных, а порт 4 связан с функциональным устройством для записи данных из ядра процессора в кэш данных L1 (DL1). Процедура генерации адреса занимает один или два такта процессора.
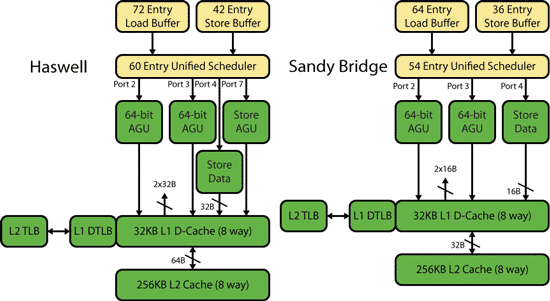
Рис. 4. Подсистема памяти в микроархитектурах Sandy Bridge и Haswell
В микроархитектуре Haswell к портам 1, 2 и 3 добавлен еще порт 7, который связан с функциональным устройством генерации адреса для записи данных (Store AGU). В результате ядро Haswell может поддерживать две операции загрузки данных и одну операцию записи данных за такт.
Выделенное функциональное устройство генерации адреса для записи данных немного проще в исполнении в сравнении с функциональными устройствами генерации адреса общего назначения (для записи и загрузки данных). Дело в том, что микрооперация записи данных просто записывает адрес (и, в конечном счете, сами данные) в буфер записи (store buffer). А микрооперация загрузки данных должна записывать в буфер чтения и также отслеживать содержимое буфера записи, для того чтобы исключить возможные конфликты.
Как только сгенерирован нужный виртуальный адрес, начинается просмотр кэша L1 DTLB на предмет соответствия этого виртуального адреса физическому. Сам кэш данных L1 DTLB в микроархитектуре Haswell не претерпел изменений. Он поддерживает 64, 32 и 4 записи для страниц памяти размером 4 Кбайт, 2 Мбайт и 1 Гбайт соответственно и является 4-канальным.
При промахе в кэше L1 DTLB начинается просмотр соответствующих записей в унифицированном кэше L2 TLB, который имеет ряд улучшений в микроархитектуре Haswell. Этот кэш поддерживает страницу размером 4 Кбайт и 2 Мбайт, является 8-канальным и рассчитан на 1024 записи. А в микроархитектуре Sandy Bridge L2 TLB кэш был рассчитан на 512 записей (то есть был вдвое меньше), поддерживал только страницы памяти размером 4 Кбайт и был 4-канальным.
Сам кэш данных L1 остался размером 32 Кбайт и 8-канальным (как и в микроархитектуре Sandy Bridge). При этом доступ в TLB-кэш и проверка тэгов кэша данных L1 может производиться параллельно.
Однако в микроархитектуре Haswell кэш данных L1 имеет более высокую пропускную способность. Он поддерживает одновременно одну 256-битную операцию чтения и две 256-битные операции записи, что в совокупности дает агрегированную полосу пропускания в 96 байт за такт. В микроархитектуре Sandy Bridge кэш данных L1 поддерживает одновременно одну 128-битную операцию чтения и две 128-битные операции записи, то есть имеет теоретическую полосу пропускания в два раза ниже. При этом реальная полоса пропускания кэша данных L1 в микроархитектуре Sandy Bridge более чем вдвое ниже полосы пропускания в микроархитектуре Haswell по причине того, что в Sandy Bridge только два функциональных блока AGU.
Кроме того, в микроархитектуре Haswell увеличена и пропускная способность между кэшами L1 и L2. Так, если в Sandy Bridge пропускная способность между кэшем L2 и L1 составляла 32 байта за цикл, то в Haswell она повышена до 64 байтов за цикл. И при этом кэш L2 в Haswell имеет ту же латентность, что и в Sandy Bridge. В заключение отметим, что, как и в микроархитектуре Sandy Bridge, в Haswell кэш L2 не эксклюзивен и не инклюзивен по отношению к кэшу L1.
Новые режимы энергосбережения в процессоре Haswell
Одно из нововведений в процессоре Haswell — это позволяющие снизить совокупное энергопотребление процессора новые состояния энергопотребления, которые называются S0ix и позаимствованы у процессоров Intel Atom (такие режимы энергопотребления были реализованы еще в процессорах Moorestown).
Напомним, что традиционно система может находиться либо в активном состоянии S0 (обычный рабочий режим), либо в одном из четырех состояний «сна» S1-S4.
В состоянии S1 все процессорные кэши сброшены и процессор прекратил выполнение инструкций. Однако поддерживается питание процессора и оперативной памяти, а устройства, которые не обозначены как включенные, могут быть отключены. Состояние S2 — это еще более глубокое состояние «сна», когда процессор отключен.
Состояние S3 (другое название — Suspend to RAM (STR) или режим ожидания — Standby) — это состояние, в котором на оперативную память (ОЗУ) продолжает подаваться питание и она остается практически единственным компонентом, потребляющим энергию.
Состояние S4 известно как гибернация (Hibernation). В этом состоянии всё содержимое оперативной памяти сохраняется в энергонезависимой памяти (например, на жестком диске или SSD).
Состояния S0ix (S0i1, S0i2, S0i3, S0i4) аналогичны состояниям S1, S2, S3 и S4 в смысле энергопотребления, но отличаются от них тем, что для перехода системы в активное состояние S0 требуется гораздо меньше времени. К примеру, для перехода из состояния S0 в состояние S0i3 требуется 450 мкс, а для обратного перехода — 3,1 мс.
Графическое ядро в микроархитектуре Haswell
Одно из основных нововведений в микроархитектуре Haswell — это новое графическое ядро c поддержкой DirectX 11.1, OpenCL 1.2 и OpenGL 4.0.
Но самое главное, что графическое ядро в микроархитектуре Haswell масштабируемое. Существуют варианты графического ядра с кодовыми названиями GT3, GT2 и GT1 (рис. 5).
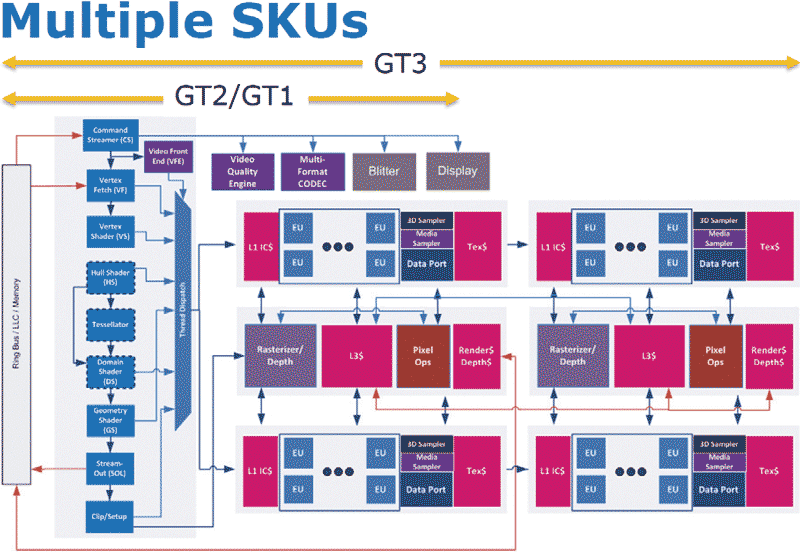
Рис. 5. Блок-схема графического ядра Haswell
Ядро GT1 будет иметь минимальную производительность, а GT3 — максимальную.
В графическом ядре GT3 появится второй вычислительный блок, за счет чего удвоится количество блоков растеризации, пиксельных конвейеров, вычислительных ядер и сэмплеров. Ожидается, что GT3 будет вдвое производительнее GT2.
Ядро GT3 содержит 40 исполнительных блоков, 160 вычислительных ядер и четыре текстурных блока. Для сравнения напомним, что в графическом ядре Intel HD Graphics 4000 процессоров Ivy Bridge содержится 16 исполнительных устройств, 64 вычислительных ядра и два текстурных блока. Поэтому, несмотря на приблизительно одинаковые тактовые частоты их работы, графическое ядро Intel GT3 превосходит своего предшественника по уровню производительности. Кроме того, ядро GT3 имеет более высокую производительность благодаря интеграции памяти EDRAM (в ядре GT3e) в упаковку процессора.
Ядро GT2 содержит 20 исполнительных блоков, 80 вычислительных ядер и два текстурных модуля, а ядро GT1 — только 10 исполнительных блоков, 40 вычислительных ядер и один текстурный модуль.
Сами исполнительные блоки имеют по четыре вычислительных ядра наподобие тех, что используются в архитектуре AMD VLIW4.
Еще одно нововведение заключается в том, что при работе с памятью применятся технология Instant Access, которая позволяет вычислительным ядрам процессора и графическому ядру напрямую обращаться к оперативной памяти. В предыдущих версиях графического ядра вычислительные ядра процессора и графическое ядро тоже работали с общей оперативной памятью, но при этом память делилась на две области с динамически изменяемыми размерами. Одна из них отводилась для графического ядра, а другая — для вычислительных ядер процессора. Однако получить одновременный доступ к одному и тому же участку памяти графическое ядро и вычислительные ядра процессора не могли. И в случае, если графическому процессору требовались те же данные, что использовались вычислительным ядром процессора, ему приходилось копировать этот участок памяти. Это приводило к росту задержек, а кроме того, возникала проблема отслеживания когерентности данных.
Технология InstantAccess позволяет драйверу графического ядра ставить указатель на положение определенного участка в области памяти графического ядра, к которой вычислительному ядру процессора необходимо напрямую получить доступ. При этом вычислительное ядро процессора будет работать с этой областью памяти напрямую, без создания копии, а после выполнения необходимых действий область памяти будет возвращена в распоряжение графического ядра.
Семейство новых графических ядер GT1, GT2 и GT3 обладает улучшенными возможностями по кодированию-декодированию видеоданных. Поддерживается аппаратное декодирование форматов H.264/MPEG-4 AVC, VC-1, MPEG-2, MPEG-2 HD, Motion JPEG, DivX с разрешением вплоть до 4096×2304 пикселов. Заявляется, что графическое ядро способно одновременно декодировать несколько видеопотоков 1080p и воспроизводить видео 2160p без подтормаживания и пропуска кадров.
Появился и специальный блок улучшения качества видео, который называется Video Quality Engine и отвечает за шумоподавление, цветокоррекцию, деинтерлейсинг, адаптивное изменение контраста и т.д. Также новые графические ядра будут поддерживать функции стабилизации изображения, преобразования частоты кадров и расширенной гаммы.
Кроме того, графическое ядро в процессоре Haswell обеспечивает подключение до трех мониторов одновременно. Поддерживаются порты Display Port 1.2 с разрешениями до 3840×2160 и частотой 60 Гц, HDMI c разрешением до 4096×2304 и частотой 24 Гц (при максимальном разрешении), а также порт DVI.
Модельный ряд процессоров Haswell
Пока еще преждевременно говорить о модельном ряде процессоров Haswell. Естественно, в Интернете можно найти разнообразную и порой противоречивую информацию относительно планов компании Intel по выпуску процессоров Haswell. Однако официально эту информацию компания не подтверждает, поэтому неизвестно, какие именно модели процессоров будут объявлены в первую очередь.
Достоверно известно лишь, что процессоры Haswell будут официально называться Intel Core четвертого поколения и составят три серии: Core i7, Core i5 и Core i3. Как и предыдущие поколения процессоров Intel, модели процессоров Haswell маркируются четырехзначным числом, которое начинается с цифры 4 (первая цифра обозначает номер поколения процессоров).
Первоначально компания Intel объявит о выпуске процессоров для настольных ПК и ноутбуков серий Core i7 и Core i5, а более слабые и дешевые процессоры серии Core i3 появятся позже.
Процессоры для настольных ПК будут наделяться графическим ядром GT2 с официальным названием Intel HD Graphics 4600, однако это лишь слухи, поэтому вполне возможно, что в семействе процессоров для настольных ПК окажется модель с графическим ядром GT3 (официальное название Intel HD Graphics 5200).
Мобильные версии процессоров Haswell будут оснащаться графическим ядром либо GT3 (топовые модели), либо GT2.
Опять же по слухам, все версии мобильных процессоров будут четырехъядерными с поддержкой технологии Hyper-Threading (речь идет о семействе мобильных процессоров Core i7). Процессоры для настольных ПК семейств Core i7 и Core i5 также будут преимущественно (за исключением одной модели в семействе Core i5) четырехъядерными, однако технологию Hyper-Threading будут поддерживать только топовые модели семейства Core i7 и двухъядерная модель процессора семейства Core i5.
Все процессоры семейств Core i5 и Core i7 будут поддерживать технологию Turbo Boost.
Размер кэша L3 у процессоров семейств Core i7 и Core i5 может составлять 8, 6 и 4 Мбайт, ну а TDP этих процессоров варьируется от 35 до 84 Вт.
Процессоры для настольных ПК имеют разъем LGA 1150 и совместимы только с материнскими платами на базе новых чипсетов Intel 8-й серии.
Процессор Intel Core i7-4770
Если обо всем модельном ряде процессоров Haswell и их характеристиках на момент написания этой статьи официальной информации мы не имели, то о процессоре Intel Core i7-4770, который был у нас на тестировании, мы знали все. Этот процессор не самый топовый в семействе Intel Core i7 четвертого поколения и уступает лишь модели Intel Core i7-4770K, которая отличается от него тем, что имеет полностью разблокированный коэффициент умножения и на 100 МГц более высокую базовую тактовую частоту. Во всем остальном эти процессоры одинаковы.
Итак, процессор Intel Core i7-4770 является четырехъядерным, поддерживает технологию Hyper-Threading, а его базовая частота составляет 3,4 ГГц. В режиме Turbo Boost максимальная тактовая частота может достигать 3,9 ГГц. Процессор наделен кэшем L3 размером 8 Мбайт и графическим ядром GT2 (официальное название Intel HD Graphics 4600), которое работает на тактовой частоте 1,2 ГГц. Контроллер памяти в процессоре, как и прежде, двухканальный, а официальная максимальная частота поддерживаемой памяти DDR3 составляет 1600 МГц (можно, конечно, использовать и более скоростную память).
Опять же, как и ранее, процессор Intel Core i7-4770 имеет встроенный контроллер PCI Express 3.0 на 16 линий. Ну и последнее немаловажное обстоятельство — TDP этого процессора составляет 84 Вт.
Для сравнения напомним, что процессор Intel Core i7-3770 (кодовое наименование Ivy Bridge) предыдущего поколения имеет очень похожие характеристики. Он также является четырехъядерным, поддерживает Hyper-Threading и имеет кэш L3 размером 8 Мбайт. Немного отличаются базовые тактовые частоты этих процессоров: для модели Intel Core i7-4770 она составляет 3,4 ГГц, а для Intel Core i7-3770К — 3,5 ГГц. Однако в режиме Turbo Boost тактовые частоты этих процессоров совпадают: если загружено одно или два ядра процессора, то максимальная тактовая частота может составлять 3,9 ГГц (при условии, что не превышено максимальное энергопотребление и максимальный ток). В случае если загружены три ядра процессора, максимальная тактовая частота может составлять 3,8 ГГц, а при загрузке всех четырех ядер — 3,7 ГГц.
Отличаются в этих процессорах графические ядра и, конечно же, сама микроархитектура вычислительных ядер. А теперь маленькая деталь: процессор Intel Core i7-3770 имеет TDP 77 Вт, то есть меньше, чем Intel Core i7-4770. Что ж, видимо увеличение размеров буферов и количества регистров, дополнительные порты функциональных устройств и увеличение пропускной подсистемы памяти процессора даром не прошли. Всё это привело и к увеличению энергопотребления процессора. С этим, однако, вполне можно примириться, если за счет небольшого увеличения энергопотребления достигнут адекватный прирост производительности процессора. Что ж, осталось проверить, так ли это на самом деле.
Производительность в неигровых приложениях
Для тестирования процессора Intel Core i7-4770 мы использовали нашу утилиту ComputerPress Benchmark Script v.12.0, подробное описание которой можно найти в мартовском номере журнала. Напомним, что данная тестовая утилита основана на следующих реальных приложениях:
- Xilisoft Video Converter Ultimate 7.7.2;
- Wondershare Video Converter Ultimate 6.0.3.2;
- Movavi Video Converter 10.2.1;
- Adobe Premier Pro CS 6.0;
- Photodex ProShow Gold 5.0.3276;
- Adobe Audition CS 6.0;
- Adobe Photoshop CS 6.0;
- ABBYY FineReader 11;
- WinRAR 4.20;
- WinZip 17.0.
В качестве показателя производительности используется время выполнения тестовых заданий.
Понятно, что само по себе время выполнения тестовых заданий еще не позволяет оценить производительность процессора. Подобные результаты имеют смысл только в сравнении с некоторыми результатами, принимаемыми за референсные. Такое сопоставление результатов позволяет оценить, во сколько раз (или на сколько процентов) тестируемый процессор более производителен (а может, и менее) референсного при выполнении определенной задачи.
Мы сравнивали процессор Intel Core i7-4770 с процессором Intel Core i7-3770. Для наглядности представления результатов также рассчитывались общий интегральный показатель производительности процессора и интегральные оценки по отдельным группам тестов (видеоконвертирование, создание видеоконтента, аудиообработка, обработка цифровых фотографий, распознавание текста, архивирование и разархивирование данных).
Для расчета интегральной оценки производительности результаты тестирования процессора Intel Core i7-4770 нормировались относительно результатов процессора Intel Core i7-3770K. Нормированные результаты тестов разбивались на шесть логических групп (видеоконвертирование, аудиообработка, создание видеоконтента, обработка цифровых фотографий, распознавание текста, архивирование и разархивирование данных), и в каждой группе рассчитывался интегральный результат как среднегеометрическое от нормированных результатов. Для удобства представления результатов полученное значение умножалось на 1000. После этого рассчитывалось среднегеометрическое от полученных интегральных результатов, которое и представляет собой результирующий интегральный показатель производительности. Для процессора Intel Core i7-3770K интегральный результат производительности, а также интегральные результаты по каждой отдельной группе тестов составляют 1000 баллов.
Для тестирования процессора Intel Core i7-3770K использовалась следующая конфигурация ПК:
- материнская плата — Gigabyte GA-Z77X-UD5H;
- чипсет системной платы — Intel Z77 Express;
- память — DDR3-1600;
- объем памяти — 16 Гбайт (два модуля GEIL по 8 Гбайт);
- режим работы памяти — двухканальный;
- видеокарта — процессорное графическое ядро Intel HD 4000;
- накопитель — Intel SSD 520 (240 Гбайт).
- Тестирование процессора Intel Core i7-4770 проводилось на следующем стенде:
- материнская плата — Intel DH87MC;
- чипсет системной платы — Intel H87 Express;
- память — DDR3-1600;
- объем памяти — 16 Гбайт (два модуля GEIL по 8 Гбайт);
- режим работы памяти — двухканальный;
- видеокарта — процессорное графическое ядро Intel HD 4600;
- накопитель — Intel SSD 520 (240 Гбайт).
В обоих случаях применялась операционная система Microsoft Windows 8 Enterprise (64-bit).
Отметим, что материнская плата Intel DH87MC, которую мы использовали для тестирования процессора Intel Core i7-4770, — это инженерный сэмпл. Компания Intel отказалась от производства материнских плат под своим брендом и теперь занимается лишь референсным дизайном, то есть производит платы в качестве образца для своих партнеров. Поэтому плата Intel DH87MC никогда не поступит в продажу.
Как для процессора Intel Core i7-3770K, так и для процессора Intel Core i7-4770 тестирование проводилось с настройками BIOS по умолчанию, то есть режим Intel Turbo Boost был активирован, но никакого разгона процессоров не производилось.
Для обеспечения высокой точности результатов все тесты прогонялись по пять раз.
Результаты тестирования представлены в табл. 1 и на рис. 6.
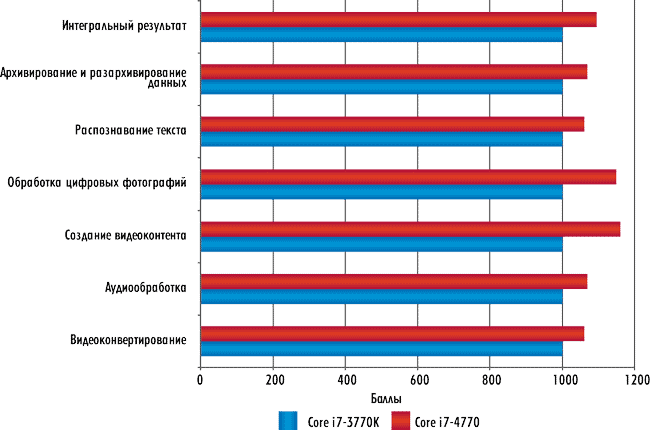
Рис. 6. Интегральные результаты тестирования процессоров утилитой
ComputerPress Benchmark Script v.12.0
Как видите, интегральная производительность процессора Intel Core i7-4770 почти на 10% превосходит производительность процессора Core i7-3770K, причем наибольший прирост в производительности наблюдается в таких приложениях, как Adobe Photoshop CS6 (15%) и Adobe Premier Pro CS 6.0 (18%) и Photodex ProShow Gold 5.0.3276 (13%).
При этом нужно учесть, что процессоры Intel Core i7-4770 и Core i7-3770K работают на одной и той же тактовой частоте и наблюдаемая разница в производительности объясняется исключительно изменениями в микроархитектуре процессора Intel Core i7-4770. В неигровых приложениях новая микроархитектура процессора Haswell позволяет получить выигрыш в производительности в среднем на 10%.
Производительность в играх
Утилита ComputerPress Benchmark Script v.12.0 позволяет оценить производительность процессора лишь при работе с неигровыми приложениями, в которых возможности интегрированного графического ядра практически не используются.
Поэтому мы также оценили производительность графического ядра процессора Intel Core i7-4770 в 3D-играх с использованием бенчмаков 3DMark Professional и 3DMark 11 Advanced Edition.
Бенчмарк 3DMark Professional — это новый тест, который поддерживает как Windows-, так и Android-платформы. В состав этого бенчмарка входят три теста: Ice Storm, Cloud Gate и Fire Strike. Первый из них ориентирован на мобильные устройства типа смартфонов, планшетов или нетбуков, второй — на ноутбуки/ультрабуки и универсальные компьютеры среднего уровня; а третий — на производительные игровые ПК с мощной графикой.
Результаты тестирования процессоров с применением бенчмарков 3DMark Professional и 3DMark 11 Advanced Edition представлены в табл. 2 и табл.3 и на рис. 7 и 8.
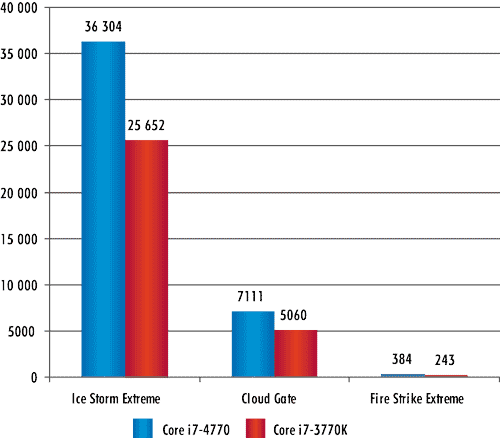
Рис. 7. Результаты тестирования процессоров
в бенчмарке 3DMark Professional
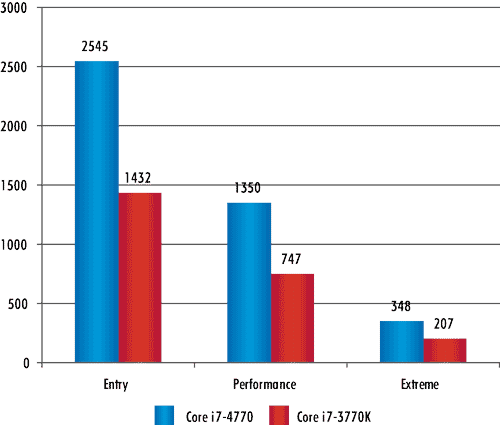
Рис. 8. Результаты тестирования процессоров
в бенчмарке 3DMark 11 Advanced Edition
Как видно из результатов тестов 3DMark Professional и 3DMark 11 Advanced Edition, графическое ядро Intel HD 4600 (процессор Core i7-4770) действительно имеет большую производительность, чем ядро Intel HD 4000 (процессор Core i7-3770K). Однако разница по производительности в этих тестах не в два раза, как об этом заявляла компания Intel в своих презентационных материалах, а немного меньше. Тем не менее прогресс в производительности графической подсистемы налицо.
Открытым, однако, остался еще один вопрос. Да, производительность графической подсистемы в процессоре Core i7-4770 увеличилась почти вдвое по сравнению с процессором Core i7-3770K. Но достаточно ли этой производительности, чтобы на компьютере можно было играть без использования дискретной графической видеокарты? Если посмотреть на детальный результат в тестах 3DMark Professional и 3DMark 11 Advanced Edition (значение FPS в графических тестах), то можно сделать вывод, что для игр графическое ядро Intel HD 4600 не годится. Однако всё же бенчмарки 3DMark Professional и 3DMark 11 Advanced Edition — это специфические программы. А потому, чтобы дать объективный ответ на этот вопрос, обратимся к результатам тестирования процессора Core i7-4770 и в других игровых бенчмарках. В данном случае нет необходимости сравнивать результаты тестирования графических ядер процессоров Core i7-4770 и Core i7-3770K, поскольку нас интересует лишь абсолютный результат процессора Core i7-4770 в FPS.
- Для этого тестирования мы использовали следующие бенчмарки:
- Unigine Heaven Benchmark 4.0;
- Unigine Valley 1.0;
- Bioshock Infinite (встроенный бенчмарк);
- Metro 2033 (встроенный бенчмарк).
Тестирование проводилось при разрешении экрана 1920×1080 (меньшее разрешение просто неактуально) и в двух режимах: максимальной производительности и максимального качества. Эти крайние настройки определяют своеобразную вилку, за пределы которой FPS выйти уже не может при любых настройках игры.
Настройки каждого бенчмарка на режимы максимальной производительности и качества представлены в табл. 4, табл. 5, табл. 6 и табл. 7, а результаты тестирования — на рис. 9.
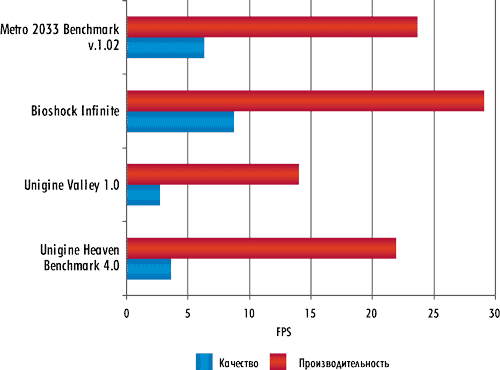
Рис 9. Результаты тестирования процессора Intel Core i7-4770 в играх
и игровых бенчмарках
Из результатов тестирования видно, что даже при настройке на минимальное качество (максимальную производительность) встроенное в процессор Intel Core i7-4770 графическое ядро не позволит играть в современные 3D-игры. Ни в одном из используемых нами бенчмарков среднее значение FPS не поднимется выше 30 FPS, что, конечно же, нельзя признать удовлетворительным результатом. А посему, вывод такой: действительно, новое графическое ядро Intel HD 4600 более производительное в сравнении с ядром Intel HD 4000, но это обстоятельство не означает, что встроенная графика позволит вам обходиться без дискретной графической карты. Для компьютера, на котором будут запускаться игры, встроенная графика явно не годится.
Заключение
В заключение нашего обзора процессора Intel Core i7-4770 подведем краткий итог.
В сравнении с процессором Intel Core i7-3770K производительность процессора Intel Core i7-4770 выросла примерно на 10% в неигровых приложениях. Однако, говоря о росте производительности процессоров Haswell, нужно иметь в виду очень важное обстоятельство.
Одно из главных достоинств процессоров Intel Core второго (Sandy Bridge) и третьего (Ivy Bridge) поколений заключалось в том, что они были хорошо разгоняемы и понятие базовой тактовой частоты было в какойто мере виртуальным. Эти процессоры делились на полностью разблокированные (процессоры К-серии) и частично разблокированные (все остальные процессоры). Процессоры K-серии можно было разгонять путем изменения коэффициента умножения (максимальное значение для коэффициента умножения хоть и существует, но оно достаточно высокое).
Для частично разгоняемых процессоров можно было установить коэффициент умножения на четыре ступени выше, чем максимальное значение в режиме Turbo Boost. К примеру, процессор Intel Core i7-3770 c базовой тактовой частотой 3,4 ГГц можно разогнать до частоты 4,3 ГГц (коэффициент умножения 43), поскольку максимальная тактовая частота этого процессора в режиме Turbo Boost составляет 3,9 ГГц (коэффициент умножения 39).
Однако в процессорах Haswell, не относящихся к K-серии, такой частичный разгон заблокирован вообще, а значит разогнать их невозможно.
Казалось бы, кроме манипуляций с коэффициентом умножения процессор можно также разгонять путем увеличения частоты системной шины. Формально, действительно, можно. Но, как показывает практика, процессоры Intel Core второго, третьего и четвертого поколений практически невозможно разогнать за счет увеличения частоты системной шины. В частности, наши эксперименты с процессором Intel Core i7-4770 показали, что после увеличения частоты системной шины всего на 3 МГц система уже не загружается.
Зачем Intel заблокировала возможность частичного разгона — абсолютно непонятно. Скорее всего, этот недружественный шаг компании по отношению к пользователям и партнерам, занимающимся производством материнских плат, можно расценить как очередную маркетинговую ошибку компании.
Невозможность разгона процессоров Haswell, не относящихся к К-серии, приводит к следующему печальному выводу. С точки зрения стоимости и производительности выгоднее купить частично разблокированный процессор Intel Core i7-3770, чем абсолютно заблокированный процессор Intel Core i7-4770. Разогнав его до частоты 4,3 ГГц (до такой частоты он разгоняется без проблем), вы получите более высокую производительность в сравнении с процессором Intel Core i7-4770.








