Особенности работы с Microsoft SQL Server в Delphi 5
Модель безопасности
Роли
Вместо групп пользователей, которые фигурировали в предыдущих версиях, версия 7.0 использует роли пользователей. Права могут даваться или отниматься у роли, и это отражается на правах всех ассоциированных с ней пользователей. При этом пользователь может быть ассоциирован одновременно с несколькими ролями.
Для облегчения управления сервером и базами данных поддерживаются встроенные серверные роли и роли баз данных. Так, например, серверная роль serveradmin дает право на настройку конфигурации и остановку сервера, а роль базы данных db_securityadmin позволяет управлять правами доступа пользователей. Набор встроенных ролей дает возможность не предоставлять административных привилегий пользователям, нуждающимся в каких-либо специфических правах. Так, роль db_securityadmin не предоставляет своим членам прав на чтение или модификацию пользовательских таблиц.
Интегрированная безопасность
Сильной стороной Microsoft SQL Server является его тесная интеграция с системой безопасности Windows NT. Права на доступ к серверу и базам данных можно давать пользователям и группам Windows NT. Механизм делегирования полномочий позволяет пользователям, подключившимся к одному из серверов, иметь доступ к другим серверам в сети со своими правами, отличающимися от прав сервера, к которому они подключились. Также возможна прозрачная для пользователя проверка его полномочий при доступе к серверу через Microsoft Internet Information Server или Microsoft Transaction Server.
Оптимизатор запросов Microsoft SQL Server
В версии 7.0 существенно переработан оптимизатор запросов. Сервер может использовать несколько индексов на каждую таблицу в запросе; один запрос может исполняться параллельно на нескольких процессорах. В SQL Server 7.0 реализованы три метода выполнения операции слияния таблиц (JOIN):
- LOOP JOIN — для каждой записи в одной из таблиц производится цикл по связанным записям второй таблицы. Этот метод наиболее эффективен для малых результирующих наборов данных.
- MERGE JOIN — требует, чтобы оба набора данных были отсортированы по сливаемому полю (набору полей). В этом случае сервер осуществляет слияние за один проход по каждому из наборов данных. Поскольку они уже упорядочены, нет необходимости просматривать все записи, достаточно выбирать их начиная с текущей, пока значение поля не изменится. Это самый быстрый метод слияния больших наборов данных.
- HASH JOIN используется, когда невозможно использовать MERGE JOIN, а наборы данных велики. По одному из наборов строится хэш-таблица, а затем для каждой записи из второго набора вычисляется та же хэш-функция и производится ее поиск в таблице. В случае больших неотсортированных наборов данных этот алгоритм существенно эффективнее, чем LOOP JOIN.
При фильтрации по индексу сервер не осуществляет сразу выборку данных из таблицы. Вместо этого строится набор «закладок» (Bookmark), а затем производится выборка данных в одной операции (Bookmark Lookup). Это позволяет резко снизить количество обращений к диску.
Новые стратегии оптимизации требуют учета при проектировании базы данных и структуры индексов. Например, для следующей структуры таблиц:
CREATE TABLE T1 ( Id INTEGER PRIMARY KEY, ... ) CREATE TABLE T2 ( Id INTEGER PRIMARY KEY, ... ) CREATE TABLE T3 ( Id INTEGER PRIMARY KEY, T1Id INTEGER REFERENCES T1(Id), T2Id INTEGER REFERENCES T2(Id), ... )
запрос
SELECT * FROM T1 INNER JOIN T3 ON T1.Id = T3.T1Id INNER JOIN T2 ON T2.Id = T3.T2Id WHERE ...
может быть существенно ускорен созданием индексов:
CREATE INDEX T3_1 ON T3(T1Id, T2Id)
После слияния T3 с T1 он позволяет получить упорядоченный по T2Id набор данных, который может быть слит с T2 путем эффективного алгоритма MERGE JOIN. Впрочем, лучший эффект, возможно, даст индекс:
CREATE INDEX T3_2 ON T3(T2Id, T1Id)
Это зависит от количества записей в T1, T2 и распределения их сочетаний в T3. В OLAP-системе (или в слабо загруженном OLTP-приложении) лучше построить оба этих индекса, в то время как при интенсивном обновлении таблицы T3, возможно, от одного из них придется отказаться. Сервер может сам выдать рекомендации по построению индексов — для этого в него включен Index Tuning Wizard, доступный через Query Analyzer. Он анализирует запрос (или поток команд, собранный при помощи SQL Trace) и выдает рекомендации по структуре индексов в конкретной базе данных.
В процессе работы с Microsoft SQL Server в оптимизаторе запросов автором были обнаружены два «тонких» места , которые рекомендуется учитывать.
- Алгоритм выбора способа объединения таблиц не всегда выдает оптимальный
результат. Это обычно бывает связано с невозможностью определить точное количество
записей, участвующих в объединении на момент генерации плана запроса.
DECLARE @I INTEGER SET @I = 10 SELECT * FROM History H INNER JOIN Objects O ON O.Id = H.ObjectId WHERE H.StatusId = @I
Сервер сгенерировал следующий план исполнения:
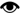
Внимание: в качестве параметра выступает переменная, при этом сервер не может точно оценить, в какой диапазон статистики она попадет. В этом случае он делает предположение, что количество записей, полученных из History, будет равно средней селективности по используемому полю, помноженной на количество записей в таблице (в данном случае – 10 151). Исходя из этого выбирается алгоритм слияния HASH JOIN, требующий значительных накладных расходов на построение хэш-таблицы. В случае если реальное количество записей ощутимо меньше (реально этот запрос выбирает 100-200 записей, имеющих соответствующий StatusId за последний день), алгоритм LOOP JOIN дает во много раз большую производительность. Итак, если вы точно знаете, что фильтрация по конкретному полю даст ограниченный набор данных (не более нескольких сотен записей), а сервер об этом «не догадывается», — укажите ему алгоритм слияния явно.
SELECT * FROM History H INNER LOOP JOIN Objects O ON O.Id = H.ObjectId WHERE H.StatusId = @I
Делать это надо, только если вы уверены, что этот запрос будет выполняться со значениями параметра, имеющими высокую селективность. На больших наборах данных выполнение LOOP JOIN будет гораздо медленнее.
- Цена операции Bookmark Lookup (извлечение данных из таблицы по известным
значениям индекса) явно завышена. Поэтому иногда, даже при наличии подходящего
индекса, вместо INDEX SCAN (поиск по индексу) с последующим Bookmark Lookup
(выборка из таблицы) сервер принимает решение о полном сканировании таблицы
(TABLE SCAN или CLUSTERED INDEX SCAN). Пример такого запроса приведен на рисунке.
Обратите внимание на предполагаемую стоимость запроса (Estimated subtree cost)
для случая, когда для таблицы явно задан поиск по индексу: она чрезвычайно
завышена. Видно, что 100% расчетной стоимости выполнения дает операция Bookmark
Lookup. Реально же этот запрос быстрее выполняется при индексном доступе,
чем при сканировании таблицы. В этом случае рекомендуется попробовать явно
указать индекс для доступа к таблице.
Однако необходимо предостеречь пользователей от слишком частого использования подсказок оптимизатору. Их можно использовать, только если вы уверены, что этот запрос будет выполняться в конкретных условиях и вам лучше, чем оптимизатору, известно распределение данных в таблице. В большинстве случаев оптимизатор запросов сам хорошо планирует его выполнение. Предпочтительным способом оптимизации представляется грамотное планирование структуры индексов.
Другие особенности Microsoft SQL Server
Получение уникальных идентификаторов
Сервер имеет средства для автоматической генерации уникальных идентификаторов, которые могут использоваться в качестве первичного ключа. Такими идентификаторами могут служить целые числа либо новый тип данных UNIQUEIDENTIFIER.
Для получения целочисленного уникального идентификатора записи в Microsoft SQL используется ключевое слово IDENTITY [(seed, increment)].
Здесь:
seed — начальное значение
increment — приращение
По умолчанию seed и increment равны 1.
Чтобы создать в таблице автоинкрементный столбец, необходимо записать:
CREATE TABLE TableName ( Id INTEGER NOT NULL IDENTITY )
Иметь атрибут IDENTITY в таблице может только одна из колонок: TINYINT, SMALLINT, INT или DECIMAL(p,0). После этого при вставке новых записей поле Id будет получать новое значение счетчика. Если таблица имеет поле с установленным IDENTITY, то к этому полю можно обратиться при помощи ключевого слова IDENTITYCOL. Например, запрос
SELECT IDENTITYCOL FROM TableName
эквивалентен
SELECT Id FROM TableName
если поле Id создано с атрибутом IDENTITY.
Значение последнего поля с IDENTITY, вставленного текущей сессией, можно получить функцией @@IDENTITY. Например, следующий скрипт добавляет записи в главную и дочернюю таблицы:
DECLARE @IdentityValue INTEGER INSERT MainTable (Name) VALUES (‘Петров’) SELECT @IdentityValue = @@IDENTITY INSERT ChildTable (MainId, Data) VALUES (@IdentityValue, ‘Первая’) INSERT ChildTable (MainId, Data) VALUES (@IdentityValue, ‘Вторая’)
Следует обратить внимание, что если значение ключевого поля нужно для нескольких вставок, то его необходимо сохранить в переменной; в противном случае при наличии у таблицы ChildTable своего поля с IDENTITY после первой вставки в нее @@IDENTITY вернет уже значение для ChildTable.
Использование вышеописанной техники требует соблюдения осторожности при написании триггеров. Если триггер на MainTable сам производит вставку в какие-то таблицы с IDENTITY, то после
INSERT MainTable (Name) VALUES (‘Петров’)
функция @@IDENTITY уже не вернет значения для MainTable.
В версии Microsoft SQL Server 2000 появилась функция SCOPE_IDENTITY(),аналогичная @@IDENTITY, однако возвращающая значение, вставленное в текущем контексте (триггере, хранимой процедуре, пакете команд). Например, в предыдущем примере SCOPE_IDENTITY() вернет значение, вставленное в MainTable, независимо от операций в триггере, поскольку они выполняются уже не в текущем контексте.
Значения seed и increment можно использовать, например, для предоставления диапазонов значений первичного ключа в распределенной базе данных. Например, один филиал может генерировать значения, начиная с 1, другой — с 1 000 000 и т.д.
По умолчанию в поле с IDENTITY не может быть вставлено явное значение. Однако Microsoft SQL Server позволяет разрешить такую вставку путем установки
SET IDENTITY_INSERT [database.[owner.]]{table} {ON|OFF}
Вставка может быть разрешена только для одной таблицы в сессии. Если в таблицу вставляется число, большее максимального значения, сервер использует это число как основу для генерации последующих значений IDENTITY.
Другим способом генерации уникальных идентификаторов, появившемся в Microsoft SQL 7.0, является тип данных UNIQUEIDENTIFIER. Физически это 16-байтовое число. Этот тип аналогичен GUID (Global Unique Identifier), активно использующемуся в технологии COM. Над этим типом данных определены только операции =, <>, IS NULL и IS NOT NULL. Сравнение >, < или т.п. не допускается. Для генерации значений используется функция NEWID()
CREATE TABLE MyUniqueTable (
UniqueColumn UNIQUEIDENTIFIER DEFAULT NEWID(),
Characters VARCHAR(10)
)
GO
INSERT INTO MyUniqueTable(Characters) VALUES ('abc')
INSERT INTO MyUniqueTable VALUES (NEWID(), 'def')
Приведенные операторы вставки эквивалентны, и оба создают записи с уникальными значениями UniqueColumn. Аналогично, значение может быть предоставлено клиентским приложением посредством функции CoCreateGUID при помощи свойства AsGUID классов TField и TParam, без опасения, что оно окажется неуникальным.
Временные таблицы
Для промежуточной обработки данных клиентское приложение может создавать временные таблицы. Временной называется таблица, имя которой начинается с # или ##. Таблица, имя которой начинается с #, является локальной и видима только той сессии, в которой она была создана. После завершения сеанса временные таблицы, созданные им, автоматически удаляются. Если временная таблица создана внутри хранимой процедуры, она автоматически удаляется по завершении процедуры. Если имя таблицы начинается с ##, то она является глобальной и видима всеми сессиями. Таблица удаляется автоматически, когда завершается последняя из использовавших ее сессий.
Для примера рассмотрим хранимую процедуру, которая выдает значения продаж по месяцам. Если в данном месяце продаж не было, выводится имя месяца и NULL.
CREATE PROCEDURE AmountsByMonths AS BEGIN DECLARE @I INTEGER CREATE TABLE #Months ( Id INTEGER, Name CHAR(20) ) SET @I = 1 WHILE (@I <= 12) BEGIN INSERT Months (Id, Name) VALUES (@I, DATENAME(month, '1998' + REPLACE(STR(@I,2),' ','0')+'01')) SET @I = @I + 1 END SELECT M.Name, SUM(P.Amount) FROM #Months M INNER JOIN Payment P ON M.Id = DATEPART(month, P.Date) DROP TABLE #Months END
В версии Microsoft SQL 2000 появилась возможность создавать переменные типа table, представляющие собой таблицу. Работа с такой переменной может выглядеть следующим образом:
DECLARE @T TABLE (Id INT) INSERT @T (Id) VALUES (10250) INSERT @T (Id) VALUES (10257) INSERT @T (Id) VALUES (10259) SELECT O.* FROM Orders O INNER JOIN @T AS T ON O.OrderId = T.Id
Переменные типа table более предпочтительны для использования, чем временные таблицы, поскольку последние приводят к невозможности кэширования плана запроса (он генерируется при каждом выполнении), а в случае использования переменных этого не происходит.
Создание хранимых процедур и триггеров
Если логика работы процедуры или триггера требует установки каких-либо SET-параметров в определенные значения, процедура или триггер могут установить их внутри своего кода. По завершении их выполнения будут восстановлены исходные параметры, которые были на сервере до запуска процедуры или оператора, вызвавшего срабатывание триггера. Исключением являются SET QUOTED_IDENTIFIER и SET ANSI_NULLS для хранимых процедур. Сервер запоминает их на момент создания процедуры и автоматически восстанавливает при исполнении.
Microsoft SQL Server использует отложенное разрешение имен объектов и позволяет создавать процедуры и триггеры, ссылающиеся на объекты, не существующие при их создании.
Кластерные индексы
Microsoft SQL Server позволяет иметь в таблице один кластерный (CLUSTERED) индекс. Данные в таблице физически расположены на нижнем уровне B-дерева этого индекса, поэтому доступ по нему является самым быстрым. По умолчанию такой индекс автоматически создается по полю, объявленному первичным ключом. Все остальные индексы в качестве ссылки на запись хранят значение кластерного индекса этой записи, поэтому не рекомендуется строить его по полям большого размера. Кроме того, для оптимизации операции вставки записей рекомендуется строить этот индекс по полю с монотонно возрастающими значениями. Исходя из этих рекомендаций лучший кандидат на построение кластерного индекса – поле INTEGER (минимальный размер), IDENTITY (возрастание), объявленное как первичный ключ (заведомо уникальное, частый доступ по этому индексу).
Определяемые пользователем функции
В версии MicrosoftSQL 2000 предусмотрена возможность создавать функции в базе данных. Функции могут быть трех типов:
- Скалярные функции — возвращают скалярную величину. Они аналогичны функциям
в любом языке программирования
CREATE FUNCTION FirstWord (@S VARCHAR(255)) RETURNS VARCHAR(255)
AS BEGIN DECLARE @I INT SET @I = CHARINDEX(' ', @S) RETURN CASE @I WHEN 0 THEN @S ELSE LEFT(@S, @I-1) END END GO SELECT dbo.FirstWord ('Hello world !') - Inline-табличные функции — состоят из одного оператора SELECT и возвращают
его результат в виде таблицы
CREATE FUNCTION OrdersByCustomer (@S VARCHAR(255)) RETURNS TABLE AS RETURN SELECT * FROM Orders WHERE CustomerId = @S GO SELECT * FROM OrdersByCustomer('VINET') AS T INNER JOIN [Order Details] OD ON OD.OrderId = T.OrderId - Многооператорные табличные функции. Эти функции наиболее интересны, поскольку позволяют динамически сформировать таблицу с требуемыми данными, которую затем можно использовать в запросе.
В качестве примера рассмотрим функцию, генерирующую таблицу, которая содержит номера и названия месяцев года. Параметр позволяет сгенерировать эту таблицу за один квартал.
CREATE FUNCTION Months (@Quoter INT) RETURNS @table_var TABLE (Id int, Name VARCHAR(20)) AS BEGIN DECLARE @Start INTEGER, @End INTEGER SET @Start = CASE WHEN @Quoter = 2 THEN 4 WHEN @Quoter = 3 THEN 7 WHEN @Quoter = 4 THEN 10 ELSE 1 END SET @End = CASE WHEN @Quoter = 1 THEN 3 WHEN @Quoter = 2 THEN 6 WHEN @Quoter = 3 THEN 9 ELSE 12 END WHILE (@Start <= @End) BEGIN INSERT @table_var (Id, Name) VALUES (@Start, DATENAME(month, '1998' + REPLACE(STR(@Start,2),' ','0')+'01')) SET @Start = @Start + 1 END RETURN END GO
SELECT T.Name, SUM(O.Freight) FROM dbo.Months(NULL) AS T INNER JOIN Orders O ON DATEPART(month, O.OrderDate) = T.Id GROUP BY T.Name
При помощи подобных функций можно также легко раскрывать иерархии и выполнять прочие задачи, которые в предыдущих версиях сервера требовали временных таблиц.
Советы по работе с Microsoft SQL Server
- Устанавливайте SET NOCOUNT ON. При установке OFF после каждого оператора сервер посылает клиенту сообщение DONE_IN_PROC с количеством обработанных записей. Запретив это, вы кардинально сократите сетевой трафик и существенно увеличите производительность.
- При необходимости изменить режим блокирования какой-либо таблицы без изменения
уровня изоляции транзакций используйте подсказки режима блокирования. Так,
в приведенном ниже примере оператор SELECT накладывает блокировку на запись,
предотвращая изменение ее другими сессиями до окончания транзакции, несмотря
на то что установленный уровень изоляции не предусматривает этого:
SET TRANSACTION ISOLATION LEVEL READ COMMITED BEGIN TRANSACTION SELECT * FROM City WHERE Name = ‘Ленинград’ WITH (HOLDLOCK) -- Какие-то операторы, во время их выполнения -- запись остается заблокированной UPDATE City SET Name = ‘Санкт-Петербург’ WHERE Name = ‘Ленинград’ COMMIT
- Явно указывайте параметры в запросах. Это поможет серверу более эффективно кэшировать планы выполнения. При динамическом формировании текста запроса не подставляйте параметры в текст, а используйте хранимую процедуру sp_executesql.
- Не начинайте названия своих хранимых процедур с префикса «sp_». Сервер ищет процедуры с такими именами в первую очередь в базе данных Master, а затем уже в текущей базе данных. Это приводит к дополнительным накладным расходам.
- Если ваше приложение интенсивно использует базу данных tempdb (например, создает много временных таблиц), увеличьте ее минимальный размер. В противном случае при старте сервера создается tempdb малого размера, которая затем динамически расширяется, непроизводительно загружая компьютер.
КомпьютерПресс 6'2001
![]()








