OCR как предмет первой необходимости
Как уже неоднократно доказывалось, лень — двигатель прогресса. Человеку лень было ходить пешком — появился автомобиль, лень было ехать на другой конец города, чтобы поговорить с приятелем, — появился телефон, лень одеваться и идти в театр — был создан телевизор и так до бесконечности. Лень привела и к появлению программных продуктов, о которых пойдет речь в этой статье.
 ачем
набирать текст, если ранее это уже кто-то сделал? У пользователя такая задача
вызывает яростное сопротивление с примесью обиды за то, что приходится дублировать
чью-то работу. Помощь компьютера, который уже умел считать, рисовать и делать
множество других вещей за человека, стала необходима еще в одной области. Естественно,
разработчики программного обеспечения не могли остаться равнодушными к столь
вопиющей несправедливости, ликвидация которой к тому же обещала солидные дивиденды.
Так были созданы системы искусственного интеллекта, известные в России как системы
оптического распознавания текста, а в англоговорящих странах — как Optical Character
Recognition (OCR).
ачем
набирать текст, если ранее это уже кто-то сделал? У пользователя такая задача
вызывает яростное сопротивление с примесью обиды за то, что приходится дублировать
чью-то работу. Помощь компьютера, который уже умел считать, рисовать и делать
множество других вещей за человека, стала необходима еще в одной области. Естественно,
разработчики программного обеспечения не могли остаться равнодушными к столь
вопиющей несправедливости, ликвидация которой к тому же обещала солидные дивиденды.
Так были созданы системы искусственного интеллекта, известные в России как системы
оптического распознавания текста, а в англоговорящих странах — как Optical Character
Recognition (OCR).
В общих чертах работа современной OCR-программы выглядит так: выделив на отсканированном изображении объекты, которые могут оказаться буквами, система вычисляет для каждого из них определенный набор параметров (таких, например, как плотность черных точек по диагонали). Затем полученные значения поочередно сравниваются с эталонами — наборами тех же параметров, рассчитанных для известных символов. В зависимости от того, для какого эталона разница параметров окажется наименьшей, система принимает решение, каким символом следует считать обнаруженный объект.
Сегодня область использования программного обеспечения для OCR существенно расширилась: вначале оно применялось в финансово-банковской сфере, а затем для работы с любыми документами. Трудно переоценить значение OCR-систем, превратившихся в необходимый софт и для офисного, и для домашнего компьютера. Автора, как, наверное, и многих читателей, системы распознавания текста сопровождают всю трудовую жизнь, начиная (каюсь!) со сканирования чужих рефератов и создания электронного архива любимого журнала и заканчивая систематизацией невесть откуда появившихся и забивших все пространство письменного стола документов. Потому логичным стало появление в нынешнем спецвыпуске, наряду с материалами о графических редакторах и антивирусах, статьи, посвященной OCR.
Откуда пришла OCR
 опытки
автоматического распознавания предпринимались, начиная с 30-х годов XX века,
однако первый OCR-аппарат от американской компании Intelligent Machines Research
Corporation появился только в 1952 году. Естественно, ни о каком искусственном
интеллекте речь тогда не шла. Первые OCR-аппараты не имели ничего общего даже
с компьютерной техникой. В них свет, отраженный от подсвеченного участка оригинала,
проходил через сложную систему зеркал, причем некоторые из них были расположены
на вращающихся дисках. В результате из общего потока поочередно выделялись узкие
световые пучки, соответствующие небольшим участкам оригинала — аналогам пикселов
электронного изображения. Эти «квазипикселы» поступали на вход фотоэлектронного
умножителя — оптико-электронного преобразователя с большим коэффициентом усиления.
Полученные сигналы обрабатывались электронной схемой. В ходе обработки устанавливалось,
является подсвеченная точка оригинала белой или черной. На основе полученной
информации OCR-аппарат воспроизводил образ подсвеченного знака.
опытки
автоматического распознавания предпринимались, начиная с 30-х годов XX века,
однако первый OCR-аппарат от американской компании Intelligent Machines Research
Corporation появился только в 1952 году. Естественно, ни о каком искусственном
интеллекте речь тогда не шла. Первые OCR-аппараты не имели ничего общего даже
с компьютерной техникой. В них свет, отраженный от подсвеченного участка оригинала,
проходил через сложную систему зеркал, причем некоторые из них были расположены
на вращающихся дисках. В результате из общего потока поочередно выделялись узкие
световые пучки, соответствующие небольшим участкам оригинала — аналогам пикселов
электронного изображения. Эти «квазипикселы» поступали на вход фотоэлектронного
умножителя — оптико-электронного преобразователя с большим коэффициентом усиления.
Полученные сигналы обрабатывались электронной схемой. В ходе обработки устанавливалось,
является подсвеченная точка оригинала белой или черной. На основе полученной
информации OCR-аппарат воспроизводил образ подсвеченного знака.
Возможности этих машин были ограничены рядом условий. Для сколько-нибудь уверенного распознавания требовались исключительно хорошее качество, высокая контрастность и отсутствие каких-либо повреждений оригиналов. Кроме того, распознавать можно было далеко не все надписи, а только набранные определенными шрифтами. Именно с этой целью в 60-х годах были разработаны и стандартизованы специальные шрифты — OCR-A (в США) и OCR-B (в Европе).
В 70-х годах компания Kurzweil Computer Products предприняла качественно новый шаг в развитии OCR, создав систему, способную учиться распознавать шрифты. Результаты обучения, продолжавшегося обычно несколько часов, записывались на диск, и система приобретала способность распознавать тексты, набранные выученным шрифтом. В то же время в отечественном Научно-исследовательском центре электронной и вычислительной техники (НИЦЭВТ CCCР) группой под руководством Александра Шамиса велись исследования по распознаванию «рукопечатных» (сделанных от руки печатными буквами) надписей. Впоследствии результаты деятельности группы неоднократно находили воплощение в программном коде. Наиболее известной OCR-системой, на практике реализующей методики группы Шамиса, является созданная в России ABBYY FineReader, о которой подробнее будет рассказано далее.
В 1986 году компания Calera Recognition Systems разработала систему, позволяющую работать с неизвестными ей шрифтами без предварительного многочасового обучения. Это была первая OCR-система, обладавшая искусственным интеллектом. Вместо применявшейся ранее методики посимвольного сравнения с шаблонами она действовала по методу обобщения, ныне более известному как принцип нейронной сети. Разработчики предоставили в распоряжение программы свыше 10 тыс. образцов начертания каждой буквы; обобщая их, система получала представление об основных закономерностях начертания знака, что и позволяло обходиться без длительного обучения. Впрочем, некоторое обучение требуется и современным OCR-программам. Например, иногда приходится проводить «ликбез» при распознавании редких и декоративных шрифтов.
В конце прошлого века на практике был реализован новый подход к OCR с использованием нечеткой логики. Программа выдвигала не одну, а несколько гипотез относительно каждого символа, причем каждой из них присваивала рейтинг, отражающий степень уверенности в данной гипотезе. При обработке списков гипотез во внимание принимались различные обстоятельства, например наличие или отсутствие получающегося слова в словаре, при этом соответственно менялся рейтинг каждой гипотезы. В конечном счете списки поступали в распоряжение так называемого эксперта — алгоритма выбора, за которым и оставалось решающее слово. Как правило, в таких системах правильным считается символ, чья гипотеза набрала максимальный суммарный рейтинг.
Следует отметить, что современные OCR-системы решают намного более сложные задачи, нежели их предшественницы. Простым распознаванием текста теперь никого не удивишь. Потребности пользователей возросли, и подлежащий распознаванию документ часто выглядит намного сложнее, чем белая страница с черным текстом — иллюстрации, таблицы, колонтитулы, фоновые изображения и прочие оформительские элементы усложняют ее структуру. Для того чтобы корректно воспроизводить в электронном виде такие документы, все современные OCR-программы начинают распознавание именно с анализа структуры. Как правило, при этом выделяют несколько иерархически организованных логических уровней. Объект наивысшего уровня только один — собственно страница, на следующей ступени иерархии располагаются таблица и текстовый блок, затем ячейка таблицы, абзац или картинка, за ними следует строка, потом слово или картинка внутри строки и, наконец, нижний уровень — символ.
Понятно, что любой высокоуровневый объект может быть представлен как набор объектов более низкого уровня: буквы образуют слова, слова — строки и т.д. Поэтому анализ всегда начинается в направлении сверху вниз. Программа делит страницу на объекты, их, в свою очередь, на объекты низших уровней и т.д., вплоть до символов. Когда символы выделены и распознаны, начинается обратный процесс — сборка объектов высших уровней, которая завершается формированием целой страницы. Такая процедура называется многоуровневым анализом документа, или MDA (Мultilevel document Analysis).
Таким образом, задача распознавания отдельного символа, над которой работали последние полвека множество специалистов, хотя и не имеет идеального решения, но близка к нему, а потому несколько отошла на задний план, став лишь одной из множества ступеней логической лестницы, ведущей пользователя от бумажной страницы к ее электронной копии.
Научить компьютер читать — задача не из легких, и, несмотря на значительные достижения в этой сфере, ошибки время от времени (обычно в документах с обильными графическими вкраплениями) проскальзывают. Но поскольку распознавание, как правило, занимает гораздо меньше времени, чем ввод того же объема текста с клавиатуры, прогресс очевиден. Слова «как правило» употреблены не случайно. Бывают клинические случаи, когда приходится помучиться с какой-нибудь страницей журнала, содержащей много иллюстраций и таблиц, которые упорно не хотят принимать в окончательном варианте свое первоначальное положение и все норовят куда-нибудь сползти, увлекая за собою текст.
По результатам опросов, проведенных компанией ABBYY среди пользователей ее продукта FineReader, речь о котором пойдет далее, к наиболее важным аспектам работы систем распознавания пользователи относят следующие:
- точность распознавания — 95%;
- точность сохранения оформления в документах для текстовых процессоров (в форматах MS Word, MS Excel, Word Pro, Word Perfect) — 89%;
- точность сохранения оформления для последующей электронной публикации (в форматах PDF, HTML) — 87%;
- работа с таблицами и многоколоночными текстами — 87%;
- простота использования — 85%;
- надежность работы — 82%;
- удобный поиск ошибок и сверка с оригиналом — 80%;
- работа с цветом (сохранение цветных картинок, цвета шрифта и фона) — 63%;
- прямой экспорт в другие приложения — 61%;
- скорость — 55%;
- многоязычное распознавание — 25%.
Обратите внимание, что экспорт в Web-форматы сочли необходимым параметром 87% пользователей. Таким образом, возможность выкладывания результатов распознавания в Интернет становится даже более приоритетной, чем такие важные требования к OCR и вообще к программным продуктам, как удобство и простота интерфейса и надежность работы. Похоже, что сетевой фактор становится все более актуальным даже в областях, непосредственно с Интернетом не связанных. В данном случае привязанность OCR к Сети во многом можно объяснить появлением в Интернете многочисленных библиотек самой разной тематической направленности, содержащих электронные копии документов и изданий. Число таких виртуальных читален растет день ото дня, как и их популярность. Недавно, правда, над ними стали сгущаться тучи, нагоняемые поборниками авторского права, но это уже совсем другая история.
В настоящее время на рынке систем распознавания существует ряд разработок, ориентированных как на различные сферы деятельности пользователя, так и на разные платформы. Отдельная отрасль рынка ориентирована на Mac-платформу. Практически все популярные системы распознавания имеют в настоящее время версии для «яблочного» детища. Абсолютным же лидером продаж OCR-систем в России и одним из лидеров продаж за рубежом в течение нескольких лет остается система ABBYY FineReader.
«Прекрасный чтец» и иже с ним
 етище
студента четвертого курса МФТИ Давида Яна — компания BIT Software появилась
на свет в 1989 году. В 1997-м она получила свое современное название — ABBYY
Software House, а еще через год вышла со своим основным продуктом FineReader
на мировой рынок. В то время такой шаг казался авантюрным, поскольку на Западе
бал правили такие OCR-гиганты, как Caere с системой распознавания OmniPage и
ScanSoft с TextBridge, а рынок был насыщен и поделен. Однако начало оказалось
для ABBYY весьма успешным. За последние несколько лет ABBYY удалось отвоевать
у конкурентов порядка 20% мирового рынка OCR-систем, и с каждым годом все больше
пользователей переходят с программ других разработчиков на FineReader, по достоинству
оценив преимущества этой системы. ABBYY заключила контракты с такими крупнейшими
производителями сканеров, как Mustek, Acer, Compaq, Lexmark, на поставку FineReader
в комплекте с их сканерами и МФУ. Дилеры и партнеры ABBYY работают в 80 странах
мира, а у самой компании есть офисы в США, Германии, Великобритании, Швеции
и на Украине. FineReader успела сменить семь версий, получить более ста наград
в тестах различных международных изданий и тестовых лабораторий и по сей день,
несмотря на ряд других софтверных решений от ABBYY, остается флагманским продуктом
компании, обитая на абсолютном большинстве компьютеров, по крайней мере российских.
етище
студента четвертого курса МФТИ Давида Яна — компания BIT Software появилась
на свет в 1989 году. В 1997-м она получила свое современное название — ABBYY
Software House, а еще через год вышла со своим основным продуктом FineReader
на мировой рынок. В то время такой шаг казался авантюрным, поскольку на Западе
бал правили такие OCR-гиганты, как Caere с системой распознавания OmniPage и
ScanSoft с TextBridge, а рынок был насыщен и поделен. Однако начало оказалось
для ABBYY весьма успешным. За последние несколько лет ABBYY удалось отвоевать
у конкурентов порядка 20% мирового рынка OCR-систем, и с каждым годом все больше
пользователей переходят с программ других разработчиков на FineReader, по достоинству
оценив преимущества этой системы. ABBYY заключила контракты с такими крупнейшими
производителями сканеров, как Mustek, Acer, Compaq, Lexmark, на поставку FineReader
в комплекте с их сканерами и МФУ. Дилеры и партнеры ABBYY работают в 80 странах
мира, а у самой компании есть офисы в США, Германии, Великобритании, Швеции
и на Украине. FineReader успела сменить семь версий, получить более ста наград
в тестах различных международных изданий и тестовых лабораторий и по сей день,
несмотря на ряд других софтверных решений от ABBYY, остается флагманским продуктом
компании, обитая на абсолютном большинстве компьютеров, по крайней мере российских.
В настоящее время актуальны две последние версии FineReader — 6.0 и 7.0, выпущенные соответственно в 2002-м и 2003 году. Шестая версия произвела в свое время революцию на OCR-рынке. В продукте были использованы новые алгоритмы адаптивной бинаризации и фильтрации текстуры — проще говоря, резко повысилась точность распознавания документов с дизайнерскими изысками, вроде текста на цветном фоне, цветных шрифтов, многоколоночного текста. Значительно улучшилось и сохранение этого благолепия в нетронутом виде, в том числе в HTML. При этом качество распознавания оформительских элементов теперь можно было оценить, не экспортируя результат в текстовый процессор или в браузер, а с помощью собственного многоколоночного WYSIWYG-редактора. К «сырьевым» форматам, пригодным для распознавания, добавился PDF. Помимо редактирования в данном формате стало возможно сохранить и результаты работы. Возможность работы с PDF стала, пожалуй, самым полезным новшеством шестой версии FineReader.
Седьмая версия, на данный момент — венец творения, приобрела ряд новых полезных функций. Были улучшены уже упоминавшиеся алгоритмы бинаризации и фильтрации и разработан новый структурный классификатор. Как утверждают в ABBYY, это повысило точность распознавания на 25%, сложная верстка стала распознаваться лучше на 33%, а с добавлением юридического и медицинского словарей для английского и немецкого языков распознавание специализированных текстов стало более безошибочным на 30-40%. Не забыли и про «конек» прошлой версии — PDF. Точность распознавания PDF-документов возросла на 45%, а PDF-файлы, вышедшие из-под пера FineReader, стали оптимизироваться для онлайн-публикаций1. Но результаты, тем более количественные, внутренних корпоративных тестов довольно специфичны, и оценить справедливость указанных процентов самому весьма проблематично. Так что представление о том, насколько быстрее стала работать последняя «инкарнация» FineReader, читатели могут составить сами. Благодаря поддержке формата XML, FineReader теперь интегрируется в Microsoft Office Word 2003. Выражается интеграция в редактировании OCR-результатов средствами Word с одновременным просмотром увеличенного рабочего участка оригинала. Стала возможной работа с другим приложением Office — PowerPoint. Благодаря инструментам для разбиения изображения FineReader легко распознает распечатки презентаций, которые затем можно также легко сохранить в формате PowerPoint.
1 Автор негативно относится к использованию PDF в Сети, хотя бы в силу размера файлов, но Adobe делает все возможное, чтобы утвердить PDF в этом качестве, с чем приходится считаться.
Традиция разделять софт на несколько вариантов, различающихся по функциональности и цене, появившаяся, видимо, с подачи Microsoft, не обошла стороной и FineReader. Продукт поставляется в двух ипостасях: Professional и Corporate Edition. В седьмую версию Professional перекочевали некоторые функции, ранее доступные только в корпоративной версии. Пользователи FineReader Professional теперь могут использовать инструменты для разбиения изображения, полнотекстовый морфологический поиск и функцию распознавания штрих-кодов. В Corporate Edition к джентльменскому OCR-набору добавлены инструменты для совместной работы в локальной сети: автоматическая сетевая установка, поддержка сетевых многофункциональных устройств (например, сканер + копир + принтер) и средства администрирования.
FineReader выпускается еще в двух разновидностях: Pro for Mac (в настоящее время последняя версия — 5.0) и Sprint. Первая, как понятно из названия, предназначена для использования на компьютерах от Apple. По возможностям и цене Mac-версия аналогична профессиональной и отличается меньшим количеством поддерживаемых для распознавания языков (117 против 177), поддержкой «яблочных» технологий (Quick Time, Drag-n-Drop, Speech, Navigation Services) и интерфейса AppleScript.
FineReader Sprint — это light-версия продукта, которая поставляется вместе со сканерами и многофункциональными устройствами, ее вполне достаточно для типовой работы. Если же возникает необходимость в дополнительных возможностях, в Sprint предусмотрена возможность апгрейда до полнофункциональной версии.
Цены: Corporate Edition, как и следовало ожидать, самая дорогая — 259 долл., Professional и Pro for Mac стоят в два раза дешевле — 129 долл.
Помимо FineReader, ABBYY представляет на рынке еще ряд продуктов для распознавания: программу для автоматической обработки большого количества форм, заполненных от руки (ICR-технология), ABBYY FormReader (под формами понимаются всевозможные анкеты, опросные листы, заявки клиентов, налоговые декларации и т.д.); продукт для оперативного ввода платежных документов FineReader Банк; инструмент TestReader для обработки результатов экзаменационных тестов, анкет и прочих документов учебных заведений. Кроме распознавания, ABBYY занимается разработкой электронных словарей Lingvo (последняя версия — 9.0), а также созданием решений для разработчиков и системных интеграторов. Последние позволяют встраивать в другие программные продукты технологии распознавания (FineReader SDK), полнотекстового поиска и лингвистического анализа (Retrieval & Morphology Engine) и обработки форм (FormReader Developer Edition и FlexiCapture Studio).
Заканчивая краткий рассказ о FineReader, стоит упомянуть еще об одном достижении ABBYY — от распознавания как такового далеком. Продукты компании обладают одним из наиболее высоких в России уровнем защиты. В них используется комбинированный метод защиты, включающий регистрацию и трудно копируемый носитель. В отдельных случаях (для дорогих продуктов) вместе с продуктом поставляется электронный ключ. Только начиная с седьмой версии FineReader стал поставляться без дискеты активации. Теперь его можно активировать в Интернете, по телефону, факсу или e-mail. При этом защита у продуктов ABBYY многоуровневая. Конечно, программы все равно взламывают, однако довольно часто не до конца, а только первые несколько уровней, в результате чего нелегальная копия работает некорректно или вовсе прекращает свое существование через некоторый промежуток времени. Этим достигается основная цель компании — вызвать у пользователей недоверие к пиратскому софту. Естественно, потратить столько времени и сил на антипиратские разработки ABBYY пришлось не от хорошей жизни. Ощутимые потери компания несет начиная с 1989 года, когда ее электронный словарь Lingvo был распространен по России в десятках тысяч контрафактных копий.
Практические основы
 бычно,
делая обзор FineReader, журналисты проводят разнообразные тесты продукта «в
боевых условиях» с использованием навороченных журнальных страниц, старинных
фолиантов или текстов на редких языках. На этот раз хотелось бы изменить традиции
просто потому, что автору публикация результатов таких экспериментов кажется
бесполезной для читателей. В самом деле, большинство пользователей наверняка
применяют FineReader для распознавания обычных офисных документов или журнальных
статей. Точность распознавания в этом случае будет на высоте, а все множество
более сложных вариантов, вызывающих проблемы, не удастся рассмотреть, даже посвятив
им номер журнала. Поэтому решено было изложить общие правила работы с продуктом,
которые каждый читатель смог бы применять на практике независимо от особенностей
стоящих перед ним задач.
бычно,
делая обзор FineReader, журналисты проводят разнообразные тесты продукта «в
боевых условиях» с использованием навороченных журнальных страниц, старинных
фолиантов или текстов на редких языках. На этот раз хотелось бы изменить традиции
просто потому, что автору публикация результатов таких экспериментов кажется
бесполезной для читателей. В самом деле, большинство пользователей наверняка
применяют FineReader для распознавания обычных офисных документов или журнальных
статей. Точность распознавания в этом случае будет на высоте, а все множество
более сложных вариантов, вызывающих проблемы, не удастся рассмотреть, даже посвятив
им номер журнала. Поэтому решено было изложить общие правила работы с продуктом,
которые каждый читатель смог бы применять на практике независимо от особенностей
стоящих перед ним задач.
При первом запуске программы, а также при всех последующих, если только не отключить эту опцию, взору пользователя представляется welcome-окошко, предлагающее выбрать следующие варианты работы: ввод документа с помощью мастера Scan&Read, обучение на примерах и открытие демо-примера. Если выбрать последний вариант, программа загрузит TIFF-изображение страницы с текстом о местной группе галактик, сдобренным несколькими иллюстрациями и таблицей. Ну а пользователь должен додуматься, как довести дело до ума, то есть картинку до текста. Немного напоминает самый действенный способ научить плавать, когда тренер бросает подопечного подальше от бортика. Впрочем, здесь все гораздо проще. Как и следовало ожидать, от пользователя требуется только разобраться, какие кнопки нажимать, что нетрудно, так как интерфейс достаточно простой, а сама тестовая страница распознается без сучка, без задоринки (рис. 1).
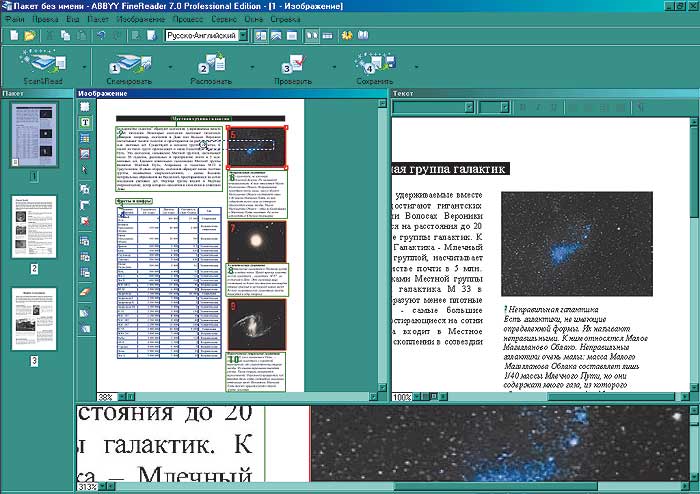
Рис. 1. Тестовая страница распознается без сучка, без задоринки
Если выбрать «Обучение на примерах», то откроется обычный раздел справки с тремя основными главами: «Быстрое знакомство», «Примеры» и «Советы». В первой пользователю рекомендуют начать работу с нажатия кнопки Scan&Read, во второй приводится список наиболее часто используемых типов распознаваемых документов, назначение третьей, думается, понятно без слов.
Все варианты работы с FineReader разработчики разделяют по следующим шестнадцати категориям: простое письмо, документ — текст в одну колонку, многоязычный документ, книжный разворот, факс, сложная журнальная страница, газетная страница, PDF-документ, простая таблица, таблица с неполным количеством черных разделителей, сложная таблица, визитная карточка, презентация PowerPoint, программная распечатка, документ с декоративным шрифтом, документ с артикулами. Описание некоторых вариантов сопровождается изложением ситуации и пошаговой инструкцией по решению характерных проблем. Довольно часто рекомендуется сканировать документ в режиме GrayScale, при котором автоматически устанавливается оптимальная контрастность. Декоративным шрифтам, как уже упоминалось, программу нужно научить.
Следующие несколько абзацев данной статьи рассчитаны на начинающих, так что опытные пользователи вполне могут их пропустить.
Итак, переходим непосредственно к работе. Распознавание текста можно провести как с использованием мастера Scan&Read, так и без оного. В нижней части панели инструментов находятся пять больших кнопок: Scan&Read и кнопки, запускающие четыре основные операции — «Сканировать», «Распознать», «Проверить» и «Сохранить». Имеет смысл рассмотреть вариант работы с мастером (рис. 2).
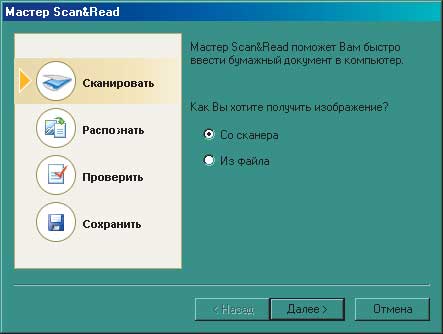
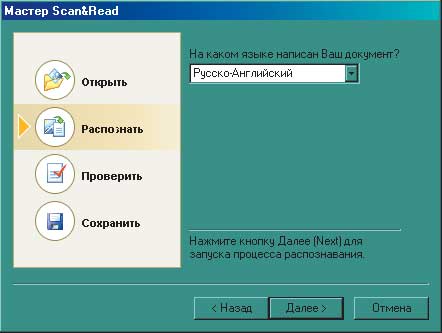
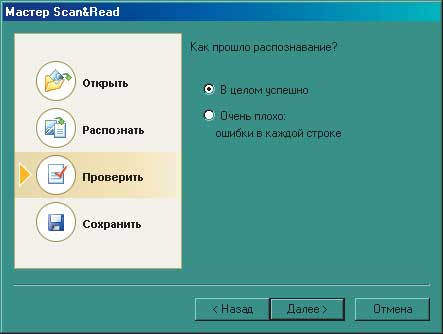
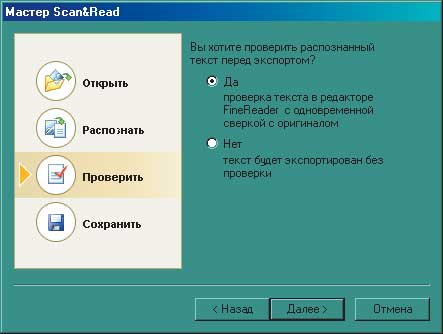
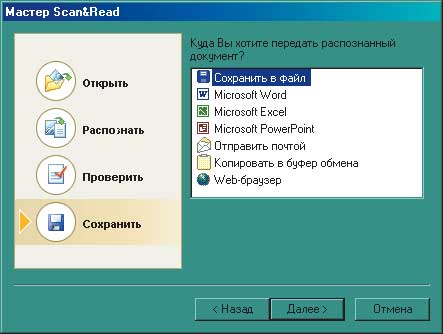
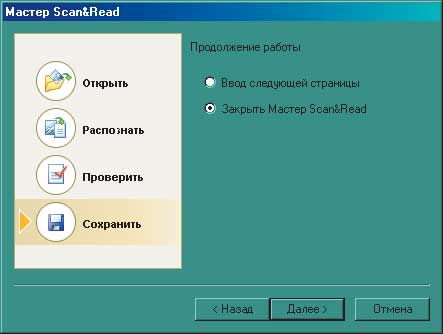
Рис. 2 Этапы работы мастера Scan&Read
Если Scan&Read запущен, то в первую очередь у пользователя спрашивается, хочет он документ отсканировать или же загрузить из файла. В первом случае показываются установленные в настоящее время настройки сканера: разрешение, яркость и тип изображения — и загружается программа управления сканером, а во втором — появляется диалоговое окно, где нужно выбрать «сырье» для распознавания в одном из форматов: BMP, DCX, JPEG, JPEG-2000, PCX, PNG, TIFF или PDF. После завершения сканирования/добавления документа программа интересуется, на каком (каких) языке (языках) написан текст для распознавания. Как уже указывалось, FineReader поддерживает 177 языков, однако на практике автору еще не приходилось менять стоящий по умолчанию «Русский-Английский». Сделав выбор и нажав «Далее», можно съесть бутерброд, сходить покурить, выпить кофе или пообедать (в зависимости от быстродействия компьютера и объема документа), так как начинается наиболее длительный2 процесс — собственно распознавание. Пользователь может наблюдать за его ходом — распознанные фрагменты подсвечиваются голубым. По завершении предлагается оценить результат: появляются три окна, в одном из которых показывается исходное изображение, во втором — полученный текст, а в третьем — его увеличенный фрагмент. В окне «Изображение» можно посмотреть, как FineReader разбил на пронумерованные блоки текстовую, графическую и табличную составляющие документа. Блоки, определившиеся как текстовые, обведены зеленым контуром, графические — красным, табличные — синим3. Штрих-коды по умолчанию не распознаются, для выделения их в отдельные блоки нужно поставить соответствующую галочку в подменю Сервис -> Опции. Для редактирования блоков используется панель инструментов в левой части окна. О назначении каждого инструмента сообщается при наведении на него курсора, так что нет нужды подробно останавливаться на этом. Пример редактирования блоков приведен на рис. 3.

Рис. 3. Текст на фоне фотографии не был распознан и не выделился
в отдельный блок.
Для исправления достаточно выделить мышью соответствующую область и в контекстном
меню выбрать «Распознать»
2 Конечно, при условии, что результат будет более или менее приличный. В противном случае последующая обработка может растянуться на неопределенный срок.
3 Все цвета, естественно, можно поменять по своему вкусу, выполнив команду: Сервис -> Опции -> Вид.
Мастер Scan&Read дипломатично интересуется: «Как прошло распознавание?» Надо по достоинству оценить тактичность положительного варианта ответа — «В целом успешно». Неужели на полностью успешное распознавание разработчики не рассчитывали?! Отрицательный вариант ответа — «Очень плохо: ошибки в каждой строке». Это вам не стандартное «хорошо/плохо» — сразу чувствуется глубокое понимание психологии пользователя. (Шутка.) Возвращаемся к работе.
Если вдруг качество распознавания не устраивает, пользователю последовательно выводятся возможные причины неудачи и соответствующие советы: изменить параметры сканирования или воспользоваться специальными функциями FineReader для тяжелых случаев. Если качество устраивает, программа предлагает проверить текст перед экспортом в какое-либо приложение (рис. 4).
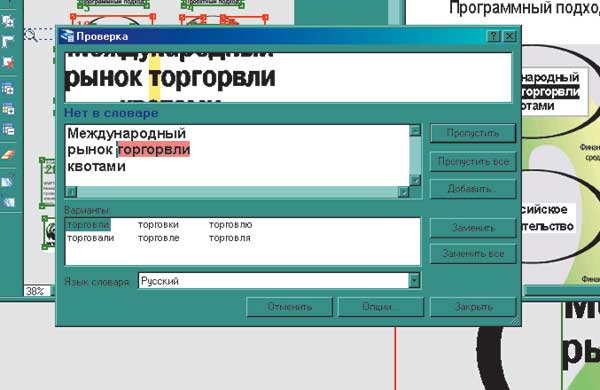
Рис. 4. Встроенная программа проверки орфографии очень напоминает Word’овскую…
Встроенная программа проверки орфографии очень напоминает Word’овскую, с тем лишь отличием, что в окошке есть дополнительная область, в которой отображается соответствующий увеличенный участок исходного изображения, в котором эта проверка происходит. После окончания процесса необходимо выбрать место экспортирования результатов труда. Помимо стандартного сохранения в файл можно сразу перенести распознанный документ для последующего просмотра и редактирования в Word, Excel, PowerPoint, а также отправить по почте, скопировать в буфер обмена или показать через браузер. Вот и весь рабочий цикл. Потом можно закрыть мастер или начать работу со следующим документом.
Альтернативные OCR
 многих пользователей уже давно сложилось впечатление, что ABBYY FineReader —
единственный в своем роде продукт. Самые продвинутые знают, что в плане распознавания
латиницы у него кое-какая конкуренция имеется, но что касается кириллицы — сейчас,
наверное, уже нет. Года четыре назад главным конкурентом ABBYY на отечественном
рынке была компания Cognitive Technologies со своей системой распознавания CuneiForm.
Но OCR для Cognitive теперь не считается приоритетным направлением деятельности:
компания в основном занята в проектной интеграции в сферах электронной торговли,
документооборота и информационно-аналитических систем. Один из наиболее популярных
программных продуктов Cognitive — система электронного документооборота «Евфрат».
CuneiForm, когда-то дышавший в затылок FineReader, в отличие от последнего,
прекратил эволюционировать на версии 2000 (Professional и Master). Тем не менее
CuneiForm также входит в комплект некоторых продаваемых в России сканеров и
многофункциональных устройств от Canon, Hewlett-Packard, OKI, Seiko EPSON, Olivetti.
Этот «дедушка» хотя и позволяет экспортировать результаты с сохранением форматирования,
но так и не научился распознавать PDF, поддерживает всего 15 языков, но при
этом неправильно распознает документы, текст которых содержит более одного языка,
исключая стандартную пару русский-английский, не производит автоматического
ориентирования текстовых строк и т.д. Конечно, при соответствующей цене на эти
недостатки можно закрыть глаза. Но в случае с CuneiForm сделать это не получается,
так как версия Professional стоит 129 долл., а Master — 249 долл., то есть почти
столько же, что и FineReader. Профессиональная версия, в отличие от «мастерской»,
не может производить пакетного сканирования и распознавания и не имеет персонального
электронного архива «Евфрат». Порекомендовать данную программу можно, видимо,
только тем, кто использует систему «Евфрат», так как в CuneiForm поддерживается
интеграция с этим продуктом.
многих пользователей уже давно сложилось впечатление, что ABBYY FineReader —
единственный в своем роде продукт. Самые продвинутые знают, что в плане распознавания
латиницы у него кое-какая конкуренция имеется, но что касается кириллицы — сейчас,
наверное, уже нет. Года четыре назад главным конкурентом ABBYY на отечественном
рынке была компания Cognitive Technologies со своей системой распознавания CuneiForm.
Но OCR для Cognitive теперь не считается приоритетным направлением деятельности:
компания в основном занята в проектной интеграции в сферах электронной торговли,
документооборота и информационно-аналитических систем. Один из наиболее популярных
программных продуктов Cognitive — система электронного документооборота «Евфрат».
CuneiForm, когда-то дышавший в затылок FineReader, в отличие от последнего,
прекратил эволюционировать на версии 2000 (Professional и Master). Тем не менее
CuneiForm также входит в комплект некоторых продаваемых в России сканеров и
многофункциональных устройств от Canon, Hewlett-Packard, OKI, Seiko EPSON, Olivetti.
Этот «дедушка» хотя и позволяет экспортировать результаты с сохранением форматирования,
но так и не научился распознавать PDF, поддерживает всего 15 языков, но при
этом неправильно распознает документы, текст которых содержит более одного языка,
исключая стандартную пару русский-английский, не производит автоматического
ориентирования текстовых строк и т.д. Конечно, при соответствующей цене на эти
недостатки можно закрыть глаза. Но в случае с CuneiForm сделать это не получается,
так как версия Professional стоит 129 долл., а Master — 249 долл., то есть почти
столько же, что и FineReader. Профессиональная версия, в отличие от «мастерской»,
не может производить пакетного сканирования и распознавания и не имеет персонального
электронного архива «Евфрат». Порекомендовать данную программу можно, видимо,
только тем, кто использует систему «Евфрат», так как в CuneiForm поддерживается
интеграция с этим продуктом.
Из других OCR-разработок можно выделить зарубежные продукты Readiris 9.0 от I.R.I.S. и OmniPage Pro 14.0 от ScanSoft. Readiris отличается прежде всего скромными размерами, что не мешает ему распознавать текст из LZW-сжатых TIFF-изображений, что недоступно его старшим собратьям. Однако если эти аспекты не очень актуальны и продукт не шел в поставке со сканером, то особого смысла приобретать Readiris автор не видит. Вряд ли он покажется лучше, чем, например, «спринтерский» вариант FineReader или OEM-версия другой программы.
OmniPage Pro — гораздо более мощный продукт, близкий по своим возможностям к детищу ABBYY (и, кстати, за рубежом успешно с ним конкурирующий): в нем реализованы те же расширенная работа с PDF-файлами, экспорт в офисные приложения, поддержка XML. К эксклюзиву можно отнести поддержку ODMA-совместимых корпоративных систем управления документами, формата eBook и наличие открытого OLE-интерфейса, позволяющего проводить интеграцию продукта с другими приложениями. Еще одно достоинство OmniPage Pro — звуковое чтение распознанного текста — вряд ли будет по достоинству оценено отечественными пользователями, так как читать программа умеет только по-английски. Кстати, русский интерфейс также отсутствует. И в заключение хотелось бы привести без комментариев стоимость продукта — 634 долл.
Подводя итоги, можно сказать, что сегодня по соотношению «цена/качество» на российском рынке у ABBYY нет достойных конкурентов. Возможно, они появятся после локализации (как в плане языка, так и цены) OmniPage. Жизнь покажет.








