Особенности работы со строковыми переменными в VisualBasic. Часть 1
Строки переменной и фиксированной длины
Передача строковых параметров в DLL
Особенности работы с символьными данными
Национальные особенности работы с символьными строками
Еще несколько любопытных моментов
От ASCII к ANSI/DBCS и Unicode
Как перекодировать символы в Word 97
Преобразование кодов в Windows выполняется довольно странно
Как восстановить текст в Word 97
Программный код многих приложений связан с обработкой строковых переменных. Visual Basic всегда отличался достаточно большим набором функций для выполнения таких операций, однако их эффективное применение требует от разработчика хорошего понимания внутреннего механизма их реализации. На этот аспект проблемы уже не раз обращалось внимание в «Советах для тех, кто программирует на VisualBasic».
Строки переменной и фиксированной длины
Visual Basic использует строковые переменные двух типов: с переменной (до 231 байт) и фиксированной длиной (до 216 байт):

Обратите внимание, что тип строки переменной длины можно задать с помощью суффикса $. Так было принято еще в первых версиях бейсик Visual Basic, и, на наш взгляд, данное представление более удобно для работы. Но это, конечно, дело привычки и вкуса.
Принципиальным различием строк этих двух типов является порядок формирования их содержимого. В момент создания строки переменной длины оператором Dim в программе резервируется только внутренний описатель переменной (в начальный момент длина строки равна нулю), а память под содержимое переменной динамически выделяется (и заполняется соответствующим значением) только в момент выполнения операции присвоения:

Область памяти для содержимого строки фиксированной длины резервируется однозначно при ее первом определении и заполняется в начальный момент нулевым цифровым кодом.
VB-программисты обычно пользуются строками переменной длины, так как это позволяет не задумываться о необходимой длине, а также экономить память (выделяется столько места, сколько действительно нужно). Однако при этом следует помнить, что операции с любыми динамическими переменными по определению требуют больше времени по сравнению со статическими, поэтому при работе со строковыми переменными данный тезис особенно актуален.
Ключевым положением является то, что в отличие от работы с данными фиксированной длины (практически всеми простыми типами данных, в том числе числовыми) самая длительная операция с динамическими строками — это самое простое присвоение: A$=..., так как в этом случае каждый раз идет обращение к внутреннему диспетчеру динамической памяти, который фактически формирует новую переменную. Например, сравнение этих двух операторов:

примерно в 2,5 раза быстрее, чем первый. В связи с этим можно сформулировать следующий СОВЕТ: при работе со строками переменной длины избегайте операций присвоения. Подробный пример реализации подобной рекомендации подробно рассмотрен в нашем Совете 135. Здесь же рассмотрим два варианта решения задачи со строкой длиной 255 символов, каждый байт которой равен его номеру в строке.

Второй вариант выглядит более длинным, но он будет работать примерно в два раза быстрее. Причем если увеличивать длину формируемых байтов, то разница в скорости будет возрастать в десятки и даже сотни раз. Этот алгоритм можно использовать и для случая, когда длина строки до начала цикла ее формирования неизвестна — сначала резервируется строка заведомо большей длины, а после окончания цикла выделяется нужное количество символов оператором Left$.
Передача строковых параметров в DLL
Следует сразу отметить, что передача строковых переменных в процедуры VB (внутри данного проекта) и DLL выполняется по-разному.
При работе со строками необходимо иметь в виду различия в их формировании в VB и других системах программирования (С, Pascal, Fortran и др.). В VB для каждой строковой переменной формируется ее описатель, в котором хранится адрес самой строки и ее длина. Этот описатель и выступает в качестве параметра при передаче данных между процедурами. В С строка передается непосредственно с помощью ее адреса (указателя), а ее длина символов определяется по нулевому значению байта (код ASCII = 0) в конце сроки. Таким образом, в C нулевой код не может использоваться в качестве значимого символа внутри строки.
Обычные DLL, в том числе и Win API, используют модель языка C при работе со строковыми переменными. Поэтому для передачи строки в такую DLL необходимо использовать ключевое слово ByVal. В этом случае автоматически создается новая строка, к концу которой приписывается нулевой код. В саму библиотеку передается адрес новой строки LPSTR. (Следует также помнить о преобразовании из кода Unicode в ANSI, о чем было писано в Совете 203.)
Подобные функции не могут напрямую создавать строковые переменные в формате VB, однако они способны выполнять преобразование переданных им строк, значение которых возвращается в вызывающую программу. Рассмотрим для примера API-функцию, которая определяет значение системного каталога Windows. Типичное обращение к ней выглядит следующим образом:

В данном случае функция сама возвращает число загруженных символов имени каталога. Но можно было бы обойтись и без значения Result&, написав такой код:

В приведенном примере Buffer$ используется только для возврата данных. Но возможен случай, когда переменная используется и для передачи, и для новой строки. Тогда можно предложить такой вариант:

Здесь резервируется строка длиной 256 символов, но с точки зрения функции SomeApiFuction ее начальное значение имеет только 6 знаков.
При обращении к VB-процедуре в качестве параметра передается исходный описатель строки. Если же используется вариант ByVal, то фактически создается обычная копия переменной, которая обрабатывается внутри вызванной процедуры.
При обращении к DLL строковая переменная может передаваться и без использования ключа ByVal. Однако это возможно производить только тогда, когда данная библиотека реализована в варианте OLE 2.0. В этом случае туда передается указатель в формате VB (BSTR), и DLL-процедура работает с ним примерно так же, как и VB-процедура.
ВНИМАНИЕ. Традиционное использование ключевого слова ByVal означает одностороннюю передачу данных в вызываемую процедуру. Это происходит при обращении и к VB-процедурам (для переменных любого типа, в том числе и String), и к DLL-процедурам (для любых переменных, за исключением String). Соответственно при передаче строкой переменной в DLL в режиме ByVal ее значение в вызывающей программе может быть изменено.
Обработка строк в VB
Для обработки строк в VB имеется довольно большой набор встроенных операторов и функций. Однако среди них можно выделить несколько базовых, с помощью которых получаются все остальные. Ключевыми функциями являются: операция конкатенации (слияния) строк, операции сравнения (равно, больше, меньше), Mid$ (оператор), Mid$ (функция), Asc и Chr$.
Вот примеры реализации некоторых встроенных функций:

Раньше, до версии VB 2.0, для операции конкатенации использовался только знак "+" (плюс). Однако в VB 3.0 стало возможно также применять и знак "&" (амперсенд). Их принципиальное различие заключается в том, что "+" подразумевает наличие переменных и выражений только строкового типа, а "&" допускает любые типы (они автоматически преобразуются в строковые).
Например, оператор

приведет к появлению ошибки (недопустимый тип операнда). А оператор

выполнится без проблем. Хотя Microsoft рекомендует использовать для конкатенации второй вариант, отметим, что следующий эквивалентный код:

не намного сложнее, но позволяет более точно следить за преобразованиями типов данных. С точки зрения быстродействия я не обнаружил сколько-нибудь значительных различий в этих вариантов.
Будьте осторожны с кодом 0
Ранее уже говорилось о том, что VB позволяет использовать любые значения кода байтов от 0 до 255. И тем не менее в ряде случаев он «плохо» реагирует на некоторые коды, в частности на 0, который он воспринимает как конец строки (чего не должен делать). Например, напишите такой код с использование текстового поля:

Вы получите следующие результаты:

Здесь видно, что текстовое поле восприняло код 0 как конец строки и обрезало ее. В переменную Finish$ было записано уже измененное значение строки. Получается, что в результате тривиальной операции присвоения происходит изменение строки.
Использование байтовых строк
Переменные типа String традиционно называются «строковыми», при этом подразумевается, что в них содержится последовательность байтов с любым числовым значением от 0 до 255. Здесь следует еще раз подчеркнуть, что VB в отличие от C позволяет использовать байт с кодом 0.
Использовать строковые переменные для хранения и передачи данных произвольной структуры бывает очень удобно. Обычно для описания структуры данных применяется тип User Defined, например:

Однако подобную структуру можно легко представить в виде строки:

К сожалению, Microsoft не включила операторы Mkx$ в состав VB (они же были в ее Basic для DOS!), но их достаточно легко создать самому с помощью функций API (см. Совет 173). Мне сейчас не хотелось бы отвлекаться на обсуждение того, зачем нужно и когда полезно использовать строки вместо структур — это отдельная тема. Сошлюсь на собственный опыт. Такой технический прием обеспечил нам (когда мы еще писали "боевые" коммерческие программы) полную независимость программного кода от конкретной структуры данных: наши программы могли работать без перекомпиляции кода с любыми структурами таблиц и любыми конфигурациями визуального интерфейса.
Хотелось бы отметить, что для такого варианта (строка двоичных байтов) все операции сводились к слиянию или разделению отдельных полей строки, к преобразованию их в переменные другого формата (например, Integer или та же String) и к последующей обработке этих отдельных данных.
В VB4 были также введены переменные типа Byte (беззнаковые целые числа 0-255). В связи с этим нужно прежде всего отметить, что скорость обработки (пересылка, арифметические и логические операции) целочисленных переменных различного типа (Byte, Integer и Long) практически одинакова в современных процессорах. Поэтому преимущество использования байтовых переменных проявляется в первую очередь при хранении информации, то есть когда речь идет не о простых переменных, а о массивах.
В свою очередь, одномерный байтовый массив является практически точным аналогом строковой переменной с точки зрения хранения данных, но при этом имеет заметные преимущества в скорости обработки данных.
Рассмотрим такой пример (Exam3.vbp): необходимо произвести инверсию всех байтов, хранящихся в переменной Source$. Можно предложить два варианта решения этой задачи:

По моим оценкам, второй вариант (переменная с 60 байтами) работает в пять раз быстрее, хотя и выглядит несколько громоздко (резервирование дополнительного массива, перезапись в него байтов, затем обратная перезапись данных в строку). Причина этого вполне понятна: копирование последовательности байтов выполняется очень быстро (одной машинной командой), но при работе с байтовым массивом не нужно использовать довольно длительные операции преобразования их строковой переменной в байтовую и обратно. (Каждая подобная операция сопровождается созданием временных строковых переменных, но в данном случае это свидетельствует о слабой оптимизации таких распростаненных конструкций создателями VB.)
Здесь стоит также отметить, что я использовал очень простой вариант копирования из строки в массив и обратно. Однако этот способ можно применять только для динамических байтовых массивов. Кроме того, следует обратить внимание, что при операции:

всегда создается массив с нумерацией индекса от 0, даже если установлен режим Option Base 1. То есть всегда создается массив следующей размерности:

Отметим также, что использование строковых переменных для хранения двоичных байтов может быть гораздо более эффективным, чем применение массовов Byte. Например, массив srtArray$(N) фактически представляет собой уникальную конструкцию, позволяющую выполнять прямой доступ к записям переменной длины.
Особенности работы с символьными данными
Однако основное применение строк приходится на работу с символьными данными — алфавитно-цифровым представлением при обмене информацией между человеком и компьютером. Более того, многие строковые функции ориентированы именно на обработку символьных данных. Например, LTrim$ убирает слева только крайние пробелы (код ASCII = 32). В то же время ряд функций поиска и сравнения может работать со строками в двух режимах: двоичной обработки (в этом случае, например, будет Z < z) и символьной (Z = z).
Ключевая проблема заключается в том, что, с одной стороны, некоторые двоичные коды не воспринимаются как символы (например, тот же 0) или используются некоторым зафиксированным образом (коды управления печатью, например перевод строки — 13), а с другой стороны, — 255 символов (на самом деле меньше) просто не хватает для всего многообразия символов народов мира.
Радикальным решением данного вопроса является переход от традиционной для MS DOS/Windows-системы кодирования символов ANSI/DBCS к универсальной Unicode (см. врезку «От ANSI/DBCS к Unicode»). Поскольку DBCS используется лишь для азиатских стран, далее речь пойдет только об ANSI и Unicode.)
Один из аспектов этой проблемы для VB-программистов заключается в том, что все 32-разрядные версии VB используют для внутреннего хранения Unicode, то есть один символ занимает два байта, а не один, как раньше, в 16-разрядных системах. Следовательно, понятия «»байтовая строка» и «символьная строка» перестали быть синонимами. В связи с этим мы обратим внимание на следующие моменты:
- Ранее любая двоичная байтовая строка могла быть интерпретирована как некий набор ASCII-кодов (значения 0-255 были значимыми), но теперь такая интерпретация может вызвать ошибку выполнения (незначимый код). В частности, VB (и многие другие приложения) при выводе символьной информации автоматически обозначают несуществующие значения знаком вопроса (?). Проблема заключается в том, что многие американские приложения не признают других наборов символов, кроме родного cp1252, и поэтому считают символы кириллицы также ошибочными. (Наверное, многие читатели сталкивались с получением электронных писем, состоящих из одних вопросительных знаков.)
- Многие привычные строковые функции на самом деле теперь работают только с символьными данными: Asc, Chr, Input, InStr, Left, Right, Len, Mid. Для работы с байтами нужно использовать модификации этих функций, у которых в конце тех же имен добавлена латинская буква B: AscB, ChrB и т.д.
- В соответствии с принятыми в VB правилами младший байт в целочисленном коде является первым по порядку, а старший — вторым.
Проиллюстрирую сказанное на следующих примерах:

В последнем случае я искусственно включил между двумя символьными строками один двоичный байт. В результате произошло смещение байтов (четные и нечетные поменялись местами), и коды символов для второй части строки стали незначимыми (при выводе их заменили вопросительные знаки “?”). Кроме того, число байтов в строке стало нечетным (17), что невозможно для символьной строки.
Если вы работаете со строками, используя только символьные функции, то все сказанное здесь не имеет значения. Но если вы применяете двоичные операции (например, для повышения быстродействия — это будет показано далее), то нужно учитывать все эти нюансы.
Национальные особенности работы с символьными строками
Как было сказано выше, при работе со символьными переменными в VB постоянно происходит преобразование данных из ANSI в Unicode и обратно. Рассмотрим такой пример:

Проблема здесь заключается в неоднозначности вариантов такого преобразования. Дело в том, что русскому символу "И" соответствует в ASNI/ASCII значение 200 (C8 в шестнадцатеричной системе). Однако этому же коду соответствуют символы "И" (для западноевропейских языков, кодовая таблица 1252) и "Č" (для восточноевропейских языков, кодовая таблица 1250). В тоже время все эти три символа имеют разный Unicode (шестнадцатеричное представление): И — 0418, И — 00C8, Č — 0107.
В приложениях, использующих ANSI-коды (например, Word 6.0, среда VB или Notepad), изменение изображения этого символа достигается простой заменой шрифта самим пользователем. В приложениях, использующих Unicode (Word 97), выбор изображения символа (выбор шрифта) выполняется автоматически самой программой в соответствии с кодом символа.
Итак, вопрос формулируется следующим образом: по каким правилам происходит преобразование кодов? Ответ на него может быть интересен тем, кто создает приложения для интернациональных приложений (которые могут работать не только внутри России), и тем, кто пишет макросы для многоязычных документов в Word 97.
В VB/VBA преобразование символьных кодов в явном виде выполняется двумя способами:
- Функциями Chr/Asc, которые преобразуют числовой ASCII-код в строковую переменную (два двоичных байта, один символ), и наоборот.

- Функцией StrConv, которая делает аналогичные преобразования в зависимости от ее второго параметра, но подобная операция выполняется над всеми байтами строки:

Так вот, для VB 5.0 и VBA 5.0 (который входит в состав MS Office 97) в обоих случаях режимом преобразования управляет параметр "ANSI кодовая таблица" (ACP), который записан в системном реестре по адресу:
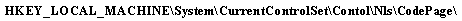
Для VB 6.0 (и, вероятно, для VBA в составе MS Office 2000) для функций Chr/Asc используется тот же параметр ACP, а для StrConv — параметр «региональные установки» (LocaleID), который хранится в системном реестре по адресу:

Оба этих параметра определяются в Windows 9x при начальной установке системы, но при этом могут быть изменены (в международных версиях) прямой коррекцией реестра, а LocaleID — через окно Control Panel | Regional Setting.
Значения этих параметров в системе можно определить в программе с помощью API-функций:

Следует также отметить, что параметр ACP в VB 6.0 влияет на режим перекодировки при неявных операциях преобразования кодов типа:

А параметр LocaleID управляет режимом преобразования для операций UCase/LCase (и их аналога StrConv), а также при выполнении операций сравнения — InStr, StrComp — в режиме Text Compare.
В VB 6.0 реализован расширенный вариант функции StrConv — можно использовать LocaleID, установленный в системе, или задать его в явном виде:

На основании вышеизложенного можно определить параметры приложения или операционной системы, которые влияют на представление (для Win16) или преобразование (Win32) национальных символов:
| Группа языков | Win16, ANSI | Win32, Unicode | |
|---|---|---|---|
| Тип шрифта | Кодовая таблица | LocaleID (региональные установки) | |
| Central European | Courier CE | cp1250 | &h415 (Польша) |
| Cyrillic | Courier Cyr | cp1251 | &h419 (Россия) |
| Western | Courier | cp1252 | &h409 (США) |
При этом следует подчеркнуть следующие моменты:
- При работе с приложениями, использующими ANSI-формат символьных данных, тип шрифта влияет только на внешнее представление символа. Тип шрифта устанавливается индивидуально для приложения (например, Word 6.0 или среда VB 6.0).
- В приложениях, применяющих Unicode, кодовая таблица и региональные установки (которые являются параметрами Windows, а не приложения!) влияют на преобразование из ANSI в Unicode и обратно.
- Каждой кодовой таблице (и типу шрифта) соответствует несколько национальных языков (стран). Польша, Россия и США выбраны здесь только для примера.
Еще несколько любопытных моментов
Все обстоит достаточно просто при преобразовании из ANSI в Unicode. Выполнение следующего кода приведет к формированию различных двоичных строк в зависимости от установленной кодовой таблицы:

Для cp1250 будет напечатано 10C, для cp1251 — 418, для cp1252 — C8. В то же время нужно иметь в виду специфику выполнения следующего кода:

При работе в среде VB 5.0 переменные strValue1$ и strValue2$ будут всегда равны, в среде VB 6.0 — только в случае согласованных значений кодовой таблицы и региональных установок.
Гораздо более запутанно обстоит дело с преобразованием из Unicode в ANSI. Выполним следующий программный код:

Здесь формируются три переменные, состоящие из одного символа, — соответственно Č, И, И , — каждой из которых соответствует один и тот же ANSI-код — 200 (&h00C8). Однако что же получится, если далее мы выполним такую операцию:

Казалось бы, должно получиться "200 200 200", но на самом деле это не так — результат будет выглядеть следующим образом:
Переменная (Unicode, изображение)
Результат выполнения функции Asc для различных кодовых таблиц, десятичное/шестнадцатеричное представление
cp1250
cp1251
cp1252
v1250$ (&h010C, Č)
200/C8
63/3F
69/45
v1251$ (&h0418, И)
67/43
200/С8
69/45
v1252$ (&h00C8, И)
67/43
63/3F
200/C8
Из этого можно сделать такой вывод: Правильное преобразование из Unicode в ANSI выполняется только в том случае, когда код таблицы Unicode (старший байт-код) соответствует кодовой таблице (или параметру региональных установок для функции StrConv в VB 6.0). Возможно, Microsoft так и хотел сделать, но подобная задумка выглядит весьма странно — вполне вероятно, что в данном случае просто допущена ошибка.
Может показаться, что приведенная здесь информация скорее напоминает теоретические размышления, однако возможности практического применения всего этого проиллюстрированы во врезке «Как перекодировать символы в Word 97».
Следует также упомянуть о том, что в составе Win API имеется целый набор функций для работы со строковыми переменными, но в целом он не очень значительно расширяет возможности встроенных VB-функций. Пользоваться последними гораздо проще.
Выводы и советы
- Использование оптимальных конструкций при работе строковых данных позволяет порой увеличить скорость обработки в десятки раз. При этом внешне простые конструкции порой работают медленнее, чем более сложные и, вроде бы, громоздкие.
- Если производительность является для вас критичной — не поленитесь провести специальные тестовые испытания разных вариантов программных конструкций.
- Использование двоичной обработки строковых переменных чаще всего позволяет повысить скорость операций, однако при этом нужно бытьпредельно внимательным.
- При обработке символьных данных нужно учитывать национальные особенности алгоритмов и влияние тех или иных системных установок. Помните, что это относится не только к внутренним переменным, но и к идентификаторам, передаваемым, например, через OLE Automation. Поэтому рекомендую использовать для имен объектов, их свойств и методов только английские символы.
VBP-проекты и Word-документы примеров , приведенных в данной статье, вы можете найти на Web-узле по адресу: http://visual.2000.ru/develop/vb/source/.
(Окончание следует. В следующей части будет рассказано о новых строковых функциях VB 6.0, операторе Like и использовании байтовых переменных для ускорения операций работы со строками.)
От ASCII к ANSI/DBCS и Unicode
Проблема оптимального кодирования символов, наверное, исторически берет свое начало с создания телеграфа, где применялось 4-битовое обозначение. 5-й разряд на перфоленте был контрольным. Для перехода от одного набора символов к другому использовались специальные символы «смены регистра». На смену этому коду пришел 7-битовый (8-й — контрольный), который позволил одному языку (английскому или русскому) умещаться полностью. Поэтому именно он заложил основу системы ASCII (American Standard Code for Information Interchange) — еще задолго до создания современных компьютеров.
Переход на «байтовый» принцип хранения информация произошел только в конце 60- годов, но тем не менее в компьютерной технике еще долго доминировал 7-разрядный код (американских разработчиков тогда не очень волновала проблема завоевания зарубежных рынков, и уже тем более — адаптации к национальным языкам).
В результате «локализация» ПО для зарубежных стран (для СССР, в частности) решалась простой заменой строчных английских букв прописными русскими. Таким образом, до конца 80-х советские программисты работали только с верхним регистром английского и русского алфавита.
Решением проблемы использования национальных языков стал переход к системе ANSI (American National Standards Institute) и DBCS (Double-Byte Character Set). ANSI является сегодня наиболее популярным символьным стандартом для ПК, в котором используется 8-битовое кодирование (до 256 кодов). Основу его составляет традиционная (основная) таблица ASCII (0-127), дополненная еще 128 символами, которые иногда называют «расширенной» таблицей ASCII. Именно поэтому ANSI часто называют расширенным вариантом ASCII (или даже воспринимают в качестве синонима ACSII, что на самом деле не совсем верно).
ANSI применяется в основном для европейских языков, которые основаны на классическом латинском алфавите, но в отличие от английского языка имеют некоторые дополнительные символы, а еще чаще — варианты расширений типа «A с точкой», «I с двумя точками» и пр.
Русский язык (кириллица) также смог уместиться в дополнительный набор символов (33 буквы), но с некоторыми проблемами. Дело в том, что многие коды из состава таблицы 128-255 уже использовались (без соответствующей стандартизации) в целом ряде программ для некоторых специальных целей (американским разработчикам не приходило тогда в голову, что их программы будут использоваться в России). В качестве классических примеров можно вспомнить русскую «р», которую не признавал Norton Commander 3.0 для DOS, или FoxBase, который считал русскую «Н» переводом строки.
Подобных «тяжелых наследий» прошлого было довольно много, и именно этим во многом объясняется наличие специальных «панъевропейских версий» Windows до 95 включительно — адаптация к использованию подобных нестандартизованных спецсимволов требовала специальной коррекции кода.
Однако многим языкам (в основном азиатским) дополнительных 128 символов никак не хватало. Поэтому появилась система DBCS, которая строится по другому принципу. Для латинских букв она использует кодировку ASCII (0-127). Для своих собственных символов (японский набор включает около 12 тыс. символов) она использует двухбайтовый набор, когда первый код (128-255) выполняет функцию упреждающего, а следующий является его дополнением. Легко подсчитать, что подобная кодировка позволяет использовать 32K+128 символов.
UniCode — это схема кодирования символов, которая использует на каждый символ два байта: первый байт определяет как бы номер набора символов, второй — собственно код символа. Например, набор символов английского и западноевропейских языков (cp1252) имеет код первого байта 0, восточноевропейских (cp1250) — 1, русского (кириллица, cp1251) — 4.
Эта система продвигается Международной организацией по стандартизации (ISO) в качестве универсального единого стандарта. И если говорить о программном обеспечении компьютеров, то она сейчас переживает непростой период перехода от ANSI/DBCS к Unicode, когда в силу огромного информационного наследства приходится использовать смешанные варианты кодирования. Именно этим во многом определяется серьезная путаница с преобразованием кодов символов, которую мы рассматриваем сейчас на примере VB.
Типичным примером этого является Microsoft Windows 9x, ядро и WinAPI которой по-прежнему используют кодировку ANSI/DBCS. Однако многие ее компоненты, а также автономные приложения (в частности, VB и Office) применяют Unicode (см. табл. 1).
Подчеркну, что, хотя Unicode и DBCS имеют двухбайтовые символы и покрывают набор символов примерно одного объема, их схемы кодирования абсолютно различны. С точки зрения программистов, принципиальным моментом является следующее: ANSI использует строго один байт на символ, Unicode — строго два байта, а DBCS — 1-2 байта, в зависимости от используемых символом.
Кроме того, известной проблемой русского языка является наличие нескольких однобайтовых кодировок символов (см. табл. 2). Строго говоря, ANSI-кодировкой для кириллицы является таблица Windows cp1251.
Как перекодировать символы в Word 97
Преобразование кодов в Windows выполняется довольно странно
Наверное, многие читатели встречались с ситуацией, когда в результате копирования или перезаписи текстов неожиданно происходили странные преобразования текста, подобные следующим:
из
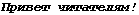
в
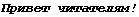
а потом в
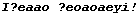
а еще в какой-то момент в
Проиллюстрирую причины таких неожиданных преобразований на примере MS Office и VBA. Однако следует отметить, что обнаруженные здесь проблемы характерны не только для VB и причина их заключается в специфике работы системных функций Windows API.
Для выполнения данного примера вам понадобится Word 6.0 и Word 97.
Загрузите обе программы. В документе Word 6.0 введите три одинаковые строки со следующим набором символов:
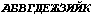
Вы видите нормальные русские символы, если у вас установлен какой-то шрифт кириллицы, например Courier Cyr (Courier — чтобы были символы одной ширины). Теперь выделите вторую строку текста, установите для нее шрифт Courier (западноевропейский набор или Western), а для третей строки — Courier CE (восточноевропейский, который по-английски называется «центральноевропейский»). Вы увидите следующий текст:
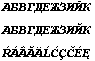
Сохраните документ как DocWord6.doc. Потом сохраните этот же документ в формате «Просто текст» (DocWord6.txt) и закройте. А затем заново прочитайте DocWord6.txt, и вы увидите:
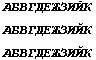
Ситуация понятна: в этом случае мы имеем дело с тремя строками, в которых каждый символ задан однобайтовыми ANSI-кодами со значениями 128-138. Двоичные коды байтов во всех строках одинаковы, и их графическое изображение зависит от установки пользователем типа шрифта. В TXT-файле мы просто убрали форматирование — установили одинаковый шрифт для всех строк. Обратите внимание, что формирование содержимого TXT-файла никак не зависит от установленной кодовой таблицы или региональных установок. (TXT-файлы лучше посмотреть простым редактором типа Notepad.)
Теперь скопируйте через буфер обмена содержимое DocWord6.doc в новый документ DocWord8.doc и далее проделайте описанные выше манипуляции по созданию и чтению TXT-файла. В DocWord8.doc вы увидите те же строки:
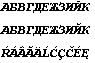
а вот в DocWord8.txt будет нечто новое:
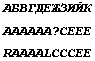
В данном случае мы имеем дело со следующей ситуацией: в результате последовательности преобразования ANSI -> Unicode -> ANSI для двух последних строк мы получили, что результирующий вариант не соответствует исходному. Чего, в общем-то, не должно быть.
Подобное преобразование данных объясняется следующим образом: при копировании строк из Word 6.0 в Word 97 символьные данные были преобразованы из ANSI в Unicode, при этом учитывался установленный тип шрифта — Script — для каждой строки (то есть соответствующая ему кодовая таблица — 1251, 1252 и 1250). Таким образом три одинаковые двоичные строки байтов ANSI-кодов были преобразованы в три РАЗНЫЕ строки Unicode-кодов, а те, в свою очередь, — в РАЗНЫЕ строки ANSI-кодов.
Обратное же преобразование из Unicode в ANSI (при сохранении в виде TXT-файла) было произведено по следующим правилам:
- Для русского кода исходный ANSI-код был восстановлен правильно.
- Для символов других языков коды верхней ASCII-таблицы (128-255) были преобразованы в 7-разрядное представление по правилу, когда расширенные варианты латинских символов, которые используются в европейских языках, заменяются на их основной вариант (например, разные варианты A — с крышкой, точкой, апострофом и пр. — заменяются на английскую A).
Правильное преобразование для русского кода объясняется тем, что в данном случае у нас в Windows 98 была установлена кодовая таблица кириллицы, cp1251. В случае cp1252 мы получили DocWord8.txt (Script=Cyrillic):
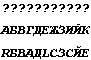
а для cp1250 (Script=Cyrillic):
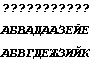
Результаты проведенных преобразований приведены в табл. 3. Обратите внимание, что при чтении TXT-файла в Word 97 происходит обратная перекодировка из ANSI в Unicode в соответствии с текущей системной кодовой таблицы, то есть автоматически выбирается нужный тип шрифта Script. Поэтому для сравнения получаемых результатов в TXT-файле лучше использоваться редактором NotePad и устанавливать одинаковый тип шрифта.
Здесь мы видим, что символы, у которых нет «базового» аналога из таблицы кодов 32-127, подвергаются замене на «?» (&h3F). Причем это касается не только символов кодовой таблицы кириллицы, но и европейского символа Ж (Unicode — &h00C6).
Конечно, ситуация, когда правильное преобразование из Unicode в ANSI выполняется только для кодов, которые соответствуют кодовой таблице, установленной в Windows, представляется если не ошибочной, то по крайней мере очень странной. Ведь в этом случае происходит потеря информации (разные исходные ANSI-коды заменяются одинаковыми): обратное восстановление исходного кода невозможно.
ПРИМЕЧАНИЕ. В ходе подготовки этой статьи была обнаружена ошибочная ситуация в работе Word 97. Когда я прочитал в Word 97 созданный ранее файл DocWord6.doc, то увидел такое его содержимое:
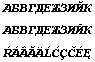
То есть вторая строка из западноевропейской записи превратилась в русскую — это к вопросу о том, что от простого чтения в разных версиях Word содержимое документов может меняться...
Как восстановить текст в Word 97
К сожалению, случай, когда довольно неожиданно происходит преобразование типа:
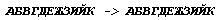
встречается довольно часто. В Word 6.0 восстановление исходного текста производится очень просто — установкой нужного шрифта. Но в Word 97 подобной возможности нет: выбор шрифта (Cyrillic или Western) осуществляется автоматически в зависимости от Unicode-кода. Как быть?
Для этого можно воспользоваться VBA и написать соответствующую макрокоманду, но на самом деле встроенных средств VBA недостаточно для полного решения такой задачи. Проблема заключается в том, что он может правильно преобразовывать из Unicode в ANSI только символы установленной в системе в данный момент кодовой таблицы, то есть по тем же правилам, что описаны выше.
Решение задачи на VB 6.0 выглядело бы следующим образом:
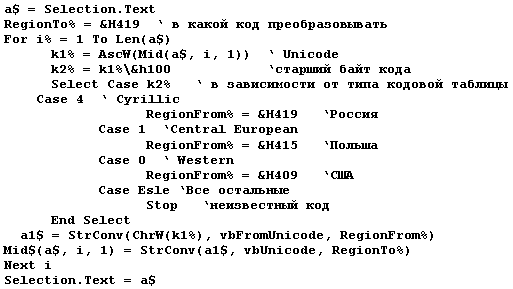
Но для Word 97 оно не годится — в VBA 5.0 нет расширенного варианта функции StrConv. Хотя, возможно, в Office 2000 эта функция уже реализована. Тем не менее вариант преобразования из Western в Cyrillic (наиболее распространенный вариант искажения текстов) решается и в Word 97 достаточно просто:

Тут я воспользовался тем, что для символов Western коды Unicode и ANSI равны. Впрочем, и для всех других случаев проблема перекодировки является вполне разрешимой — нужно просто самим составить таблицу Unicode-кодов для разных кодовых таблиц и написать достаточно простую программу их преобразования.
КомпьютерПресс 10'1999








