Программы распознавания речи
...Да только воз и ныне там.
И.А. Крылов. Басня «Лебедь, Щука и Рак»
Две главные задачи машинного распознавания речи — достижение гарантированной точности при ограниченном наборе команд хотя бы для одного фиксированного голоса и независящее от дикции распознавание произвольной слитной речи с приемлемым качеством — не решены до сих пор, несмотря на длительную историю их разработки. Более того, существуют сомнения в принципиальной возможности решения обеих задач, поскольку даже человек не всегда может стопроцентно распознать речь собеседника.
 огда-то
писателям-фантастам возможность обычного разговора с компьютером казалась столь
очевидной и естественной, что первые вычислительные машины, лишенные голосового
интерфейса, воспринимались как нечто неполноценное.
огда-то
писателям-фантастам возможность обычного разговора с компьютером казалась столь
очевидной и естественной, что первые вычислительные машины, лишенные голосового
интерфейса, воспринимались как нечто неполноценное.
Казалось бы, почему не заняться решением этой проблемы программно, с использованием «умных» компьютеров? Ведь и производители подобных продуктов вроде бы имеются, и мощность компьютеров непрерывно растет, и технологии совершенствуются. Однако успехи в области автоматического распознавания речи и преобразования ее в текст, похоже, находятся на том же уровне, что и 20-40 лет назад. Помнится, еще в середине 90-х годов компания IBM уверенно заявила о наличии такого рода инструментов в OS/2, а чуть позже и Microsoft подключилась к внедрению подобных технологий. Пыталась заниматься распознаванием речи и компания Apple, но в начале 2000 года она официально объявила об отказе от этого проекта. Продолжают работать в этой области компании IBM (Via Voice) и Philips, причем функцию распознавания речи IBM не только встраивала в свою операционную систему OS/2 (ныне уже канувшую в лету), но и до сих пор выпускает в качестве отдельного продукта. Пакет для распознавания слитной речи Via Voice (http://www-306.ibm.com/software/voice/viavoice) от IBM отличался тем, что с самого начала даже без обучения распознавал до 80% слов. При обучении же вероятность правильного распознавания повышалась до 95%, а к тому же параллельно с настройкой программы на конкретного пользователя происходило освоение будущим оператором навыков работы с системой. Сейчас ходят слухи о том, что подобные новации будут реализованы и в составе Windows XP, хотя глава и основатель корпорации Билл Гейтс неоднократно заявлял, что считает речевые технологии еще не готовыми для массового применения.
Когда-то американская компания Dragon Systems создала, наверное, первую коммерческую систему распознавания речи — Naturally Speaking Preferred, которая работала еще в 1982 году на IBM PC (даже не XT!). Правда, эта программа больше напоминала игру и с тех пор никаких серьезных подвижек компания так и не сделала, а к 2000 году и вовсе разорилась, причем ее последняя версия Dragon Dictate Naturally Speaking была продана компании Lernout&Hauspie Speech Products (L&H), являвшейся тоже одним из лидеров в области систем и методов распознавания и синтеза речи (Voice Xpress). L&H, в свою очередь, тоже дошла до банкротства с распродажей активов и имущества (к слову сказать, Dragon Systems была продана почти за 0,5 млрд. долл., а L&H — уже за 10 млн., так что своими масштабами в этой области впечатляет не прогресс, а регресс!). Технологии L&H и Dragon Systems перешли к компании ScanSoft, которая занималась до этого распознаванием оптических образов (в ее ведении сегодня находятся некоторые известные программы распознавания печатного текста типа OmniPage), но там, похоже, этим никто серьезно не занимается.
Российская компания Cognitive Technologies, достигнувшая значительных успехов в области распознавания символов, сообщила в 2001 году о совместном проекте с Intel по созданию систем распознавания русской речи — для Intel был подготовлен речевой корпус русского языка RuSpeech. Собственно, RuSpeech представляет собой речевую базу данных, которая содержит фрагменты непрерывной русской речи с соответствующими текстами, фонетической транскрипцией и дополнительной информацией о дикторах. Cognitive Technologies ставила перед собой цель создать «дикторонезависимую» систему распознавания непрерывной речи, а речевой интерфейс состоял из системы сценария диалога, синтеза речи по тексту и системы распознавания речевых команд.
Однако на деле до настоящего времени программ для реального распознавания речи (да еще и на русском языке) практически не существует, и созданы они будут, очевидно, не скоро. Более того, даже обратная распознаванию задача — синтез речи, что, казалось бы, значительно проще распознавания, до конца так и не решена. Любая синтезированная речь воспринимается человеком хуже, чем живая, причем это особенно заметно при передаче по каналу телефонной связи, то есть как раз там, где она сегодня наиболее востребована.
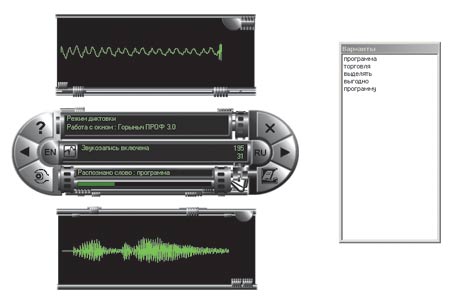
«Горыныч проф.» версии 3.0
«Ну все, тебе конец», — сказал Иван Царевич, глядя прямо в глаза третьей голове Змея Горыныча. Она растерянно посмотрела на две другие. Те в ответ злорадно ухмыльнулись.
Анекдот
 1997 году выход на коммерческий рынок знаменитого «Горыныча» (по существу адаптации
программы Dragon Dictate Naturally Speaking, проведенной силами малоизвестной
до того времени российской компании White Group, официального дистрибьютора
Dragon Systems) стал своеобразной сенсацией. Программа казалась вполне работоспособной,
а ее цена представлялась весьма умеренной. Однако время идет, «Горынычи» меняют
интерфейсы и версии, но никаких ценных свойств не приобретают. Может быть, ядро
Dragon Naturally Speaking было как-то настроено на особенности англоязычной
речи, но даже после последовательной замены драконьей головы на три головы «Горыныча»
оно дает не более 30-40% распознавания среднего уровня лексики, причем при тщательном
проговаривании. Да и кому это вообще нужно? Как известно, по заявлениям разработчиков
компаний Dragon Systems, IBM и Lernout&Hauspie, их программы при непрерывной
диктовке были способны правильно распознавать до 95% текста, но ведь и они давно
уже не выпускаются, ибо известно, что для комфортной работы точность распознавания
необходимо довести до 99%. Надо ли говорить, что для завоевания подобных высот
в реальных условиях требуются, мягко говоря, немалые усилия.
1997 году выход на коммерческий рынок знаменитого «Горыныча» (по существу адаптации
программы Dragon Dictate Naturally Speaking, проведенной силами малоизвестной
до того времени российской компании White Group, официального дистрибьютора
Dragon Systems) стал своеобразной сенсацией. Программа казалась вполне работоспособной,
а ее цена представлялась весьма умеренной. Однако время идет, «Горынычи» меняют
интерфейсы и версии, но никаких ценных свойств не приобретают. Может быть, ядро
Dragon Naturally Speaking было как-то настроено на особенности англоязычной
речи, но даже после последовательной замены драконьей головы на три головы «Горыныча»
оно дает не более 30-40% распознавания среднего уровня лексики, причем при тщательном
проговаривании. Да и кому это вообще нужно? Как известно, по заявлениям разработчиков
компаний Dragon Systems, IBM и Lernout&Hauspie, их программы при непрерывной
диктовке были способны правильно распознавать до 95% текста, но ведь и они давно
уже не выпускаются, ибо известно, что для комфортной работы точность распознавания
необходимо довести до 99%. Надо ли говорить, что для завоевания подобных высот
в реальных условиях требуются, мягко говоря, немалые усилия.
Кроме того, программа требует длительного периода тренировки и настройки под конкретного пользователя, очень капризна к оборудованию, более чем чувствительна к интонации и скорости произнесения фраз, так что возможности ее обучения распознаванию различных голосов сильно различаются.
Впрочем, может, кто-нибудь и приобретет этот пакет в качестве некой продвинутой игрушки, но пальцам, уставшим от работы с клавиатурой, это никак не поможет, пусть даже производители «Горыныча» утверждают, что скорость ввода речевого материала и трансформации его в текст составляет 500-700 знаков в минуту, что недоступно даже для нескольких опытных машинисток, если сложить скорость их работы.
При ближайшем рассмотрении новой версии этой программы ничего путного извлечь из нее нам так и не удалось. Даже после длительного «обучения» программы (а стандартный словарь нам вообще не помог) оказалось, что диктовка по-прежнему должна осуществляться строго по словам (то есть после каждого слова нужно делать паузу) и слова нужно произносить отчетливо, что не всегда характерно для речи. Конечно, «Горыныч» — это модификация англоязычной системы, а для английского иной подход просто немыслим, но говорить в такой манере по-русски показалось нам особенно неестественным. К тому же в процессе обычного разговора на любом языке интенсивность звука практически никогда не падает до нуля (в этом можно убедиться по спектрограммам), а ведь распознавать диктовку текстов общей тематики, выполняемую в манере слитной речи, коммерческие программы научились уже лет 5-10 назад.
Система ориентирована в первую очередь на ввод, но содержит средства, позволяющие исправить неверно услышанное слово, для чего «Горыныч» предлагает список вариантов. Можно поправить текст и с клавиатуры, что, кстати, постоянно и приходится делать. С клавиатуры вводятся и слова, отсутствующие в словаре. Помнится, в прежних версиях утверждалось, что чем чаще вы диктуете, тем больше система привыкает к вашему голосу, но ни тогда, ни сейчас мы этого что-то не заметили. Нам даже показалось, что работать с программой «Горыныч» по-прежнему сложнее, чем, например, обучать попугая разговаривать, а из новинок версии 3.0 можно отметить только более «попсовый» мультимедийный интерфейс.
Одним словом, проявление прогресса в этой области только одно: из-за увеличения мощности компьютера совершенно пропала временная задержка между произнесением слова и отображением его письменного варианта на экране, а число правильных попаданий, увы, не увеличилось.
Анализируя возможности программы, мы все больше склоняемся к мнению специалистов, что лингвистический анализ текста — обязательная стадия процесса автоматического ввода под диктовку. Без этого современное качество распознавания не может быть достигнуто, да и многие эксперты связывают перспективы речевых систем именно с дальнейшим развитием содержащихся в них лингвистических механизмов. Как следствие, речевые технологии делаются все более зависимыми от того языка, с которым они работают. А это значит, во-первых, что распознавание, синтез и обработка русской речи являются тем делом, заниматься которым должны именно российские разработчики, а во-вторых, только специализированные отечественные продукты, изначально ориентированные именно на русский язык, смогут по-настоящему решить ту задачу. Правда, здесь следует отметить, что отечественные специалисты петербургского «Центра речевых технологий» (ЦРТ) считают, что создание собственной системы диктовки в нынешних российских условиях не окупится.
Прочие игрушки
 ока
технологии распознавания речи российскими разработчиками успешно применяются
в основном в интерактивных обучающих системах и играх вроде «Мой говорящий словарь»,
Talk to Me или «Профессор Хиггинс», созданных фирмой «ИстраСофт». Используются
они для контроля произношения у изучающих английский язык и аутентификации пользователя.
Развивая программу «Профессор Хиггинс», сотрудники «ИстраСофт» научились членить
слова на элементарные сегменты, которые соответствуют звукам речи и не зависят
ни от диктора, ни от языка (прежде системы распознавания речи не производили
такой сегментации, а наименьшей единицей для них было слово). При этом выделение
фонем из потока слитной речи, их кодирование и последующее восстановление происходит
в режиме реального времени. Указанная технология распознавания речи нашла довольно
остроумное применение — она позволяет существенно сжимать файлы с диктофонными
записями или речевыми сообщениями. Способ, предложенный фирмой «ИстраСофт»,
допускает сжатие речи в 200 раз, причем при сжатии менее чем в 40 раз качество
речевого сигнала практически не ухудшается. Интеллектуальная обработка речи
на уровне фонем перспективна не только как способ сжатия, но и как шаг на пути
к созданию нового поколения систем распознавания речи, ведь теоретически машинное
распознавание речи, то есть ее автоматическое представление в виде текста, как
раз и является крайней степенью сжатия речевого сигнала.
ока
технологии распознавания речи российскими разработчиками успешно применяются
в основном в интерактивных обучающих системах и играх вроде «Мой говорящий словарь»,
Talk to Me или «Профессор Хиггинс», созданных фирмой «ИстраСофт». Используются
они для контроля произношения у изучающих английский язык и аутентификации пользователя.
Развивая программу «Профессор Хиггинс», сотрудники «ИстраСофт» научились членить
слова на элементарные сегменты, которые соответствуют звукам речи и не зависят
ни от диктора, ни от языка (прежде системы распознавания речи не производили
такой сегментации, а наименьшей единицей для них было слово). При этом выделение
фонем из потока слитной речи, их кодирование и последующее восстановление происходит
в режиме реального времени. Указанная технология распознавания речи нашла довольно
остроумное применение — она позволяет существенно сжимать файлы с диктофонными
записями или речевыми сообщениями. Способ, предложенный фирмой «ИстраСофт»,
допускает сжатие речи в 200 раз, причем при сжатии менее чем в 40 раз качество
речевого сигнала практически не ухудшается. Интеллектуальная обработка речи
на уровне фонем перспективна не только как способ сжатия, но и как шаг на пути
к созданию нового поколения систем распознавания речи, ведь теоретически машинное
распознавание речи, то есть ее автоматическое представление в виде текста, как
раз и является крайней степенью сжатия речевого сигнала.
Сегодня фирма «ИстраСофт» помимо обучающих программ предлагает на своем сайте (http://www.istrasoft.ru/user.html) и программы для сжатия/проигрывания звуковых файлов, а также демонстрационную программу голосонезависимого распознавания команд русского языка Istrasoft Voice Commander.
Казалось бы, теперь для того, чтобы создать основанную на новой технологии систему распознавания, осталось сделать совсем немного…
Компьютерные транскрайберы
етербуржская
компания «Центр речевых технологий» (http://www.speechpro.ru),
которая работает в этой области с 1990 года, похоже, добилась определенных успехов.
ЦРТ имеет в своем арсенале целый набор программных и аппаратных средств, предназначенных
для шумоочистки и для повышения качества звуковых, и в первую очередь речевых,
сигналов — это компьютерные программы, автономные устройства, платы (DSP), встраиваемые
в устройства каналов записи или передачи речевой информации (мы уже писали об
этой фирме в статье «Как улучшить разборчивость речи?» в № 8’2004). «Центр речевых
технологий» известен как разработчик средств шумоподавления и редактирования
звука: Clear Voice, Sound Cleaner, Speech Interactive Software, Sound Stretcher
и др. Специалисты фирмы принимали участие в восстановлении аудиоинформации,
записанной на борту затонувшей подлодки «Курск» и на потерпевших катастрофы
воздушных судах, а также в расследовании ряда уголовных дел, для которых требовалось
установить содержание фонограмм речи.
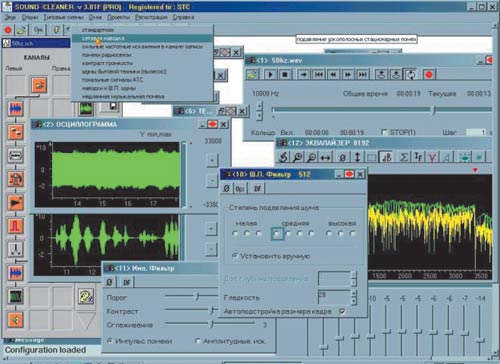
Комплекс шумоочистки речи Sound Cleaner представляет собой профессиональный набор программно-аппаратных средств, предназначенных для восстановления разборчивости речи и для очищения звуковых сигналов, записанных в сложных акустических условиях или передаваемых по каналам связи. Этот действительно уникальный программный продукт предназначен для шумоочистки и повышения качества звучания живого (то есть поступающего в реальном времени) или записанного звукового сигнала и может помочь в повышении разборчивости и текстовой расшифровке низкокачественных речевых фонограмм (в том числе архивных), записанных в сложных акустических условиях.
Естественно, Sound Cleaner эффективнее работает в отношении шумов и искажений звука известной природы, таких как типовые шумы и искажения каналов связи и звукозаписи, шумы помещений и улиц, работающих механизмов, транспортных средств, бытовой техники, голосового «коктейля», медленной музыки, электромагнитных наводок систем питания, компьютерной и другой техники, эффектов реверберации и эха. В принципе, чем равномернее и «регулярнее» шум, тем успешнее этот комплекс с ним справится.
Однако при двухканальном съеме информации Sound Cleaner существенно снижает влияние шумов любого типа — например, он имеет методы двухканальной адаптивной фильтрации, предназначенные для подавления как широкополосных нестационарных помех (таких как речь, радио или телетрансляция, шумы зала и т.д.), так и периодических (вибрации, сетевые наводки и т.п.). Эти методы основаны на том, что при выделении полезного сигнала используется дополнительная информация о свойствах помехи, представленная в опорном канале.
Коль скоро мы говорим о распознавании речи, то нельзя не упомянуть о другой разработке ЦРТ — семействе компьютерных транскрайберов, которые, к сожалению, пока еще не являются программами автоматического распознавания речи и преобразования ее в текст, а скорее представляют собой компьютерные цифровые магнитофоны, управляемые из специализированного текстового редактора. Данные устройства предназначены для повышения скорости и улучшения комфортности документирования звукозаписей устной речи при подготовке сводок, протоколов совещаний, переговоров, лекций, интервью, их также применяют в безбумажном делопроизводстве и во многих других случаях. Транскрайберы отличаются простотой и удобством в использовании и доступны даже для непрофессиональных операторов. При этом скорость работы по набору текста возрастает в два-три раза у профессиональных операторов, печатающих вслепую, а у непрофессионалов — в пять-десять раз! Кроме того, значительно уменьшается механический износ магнитофона и ленты, если речь идет об аналоговом источнике. К тому же у компьютерных транскрайберов существует интерактивная возможность сверки набранного текста и соответствующего звукового трека. Связь текста и речи устанавливается автоматически и позволяет в набранном тексте при подведении курсора к исследуемой части текста мгновенно автоматически находить и прослушивать соответствующие звуковые фрагменты речевого сигнала. Повышения разборчивости речи можно добиться здесь как путем замедления скорости воспроизведения без искажения тембра голоса, так и путем многократного повторения неразборчивых фрагментов в режиме кольца.
По желанию заказчика компания может поставить транскрайбер с ножной педалью, посредством которой осуществляется управление функциями цифрового магнитофона, что повышает производительность и комфортность работы. Возможен также вариант программы для стандартной звуковой карты типа Sound Blaster.
Заметки на полях
 есмотря
на отсутствие сколько-нибудь заметной динамики развития, технология распознавания
речи уже достигла такого уровня, что теперь стало возможным использовать ее
для организации полностью автоматизированных телефонных служб, способных работать
в интерактивном голосовом режиме. Одно за другим появляются сообщения об успешном
внедрении таких служб и о предоставляемых ими преимуществах.
есмотря
на отсутствие сколько-нибудь заметной динамики развития, технология распознавания
речи уже достигла такого уровня, что теперь стало возможным использовать ее
для организации полностью автоматизированных телефонных служб, способных работать
в интерактивном голосовом режиме. Одно за другим появляются сообщения об успешном
внедрении таких служб и о предоставляемых ими преимуществах.
Разумеется, гораздо проще реализовать программу, способную распознавать только ограниченный, небольшой набор управляющих команд и символов. Это, например, могут быть цифры от 0 до 9 в телефоне, слова «да»/«нет» и односложные команды вызова нужных абонентов и т.д. Такие программы появились самыми первыми и уже давно применяются в телефонии для голосового набора номера или выбора абонента.
Точность распознавания, как правило, повышается при предварительной настройке на голос конкретного пользователя, причем этим способом можно добиться распознавания речи даже тогда, когда у говорящего имеется дефект дикции или акцент. Все вроде бы хорошо, но заметные успехи в этой области видны только в том случае, если предполагается индивидуальное применение оборудования или ПО одним или несколькими пользователями, в крайнем случае, для каждого из которых создается свой индивидуальный «профиль».
Короче говоря, несмотря на все достижения последних лет, средства для распознавания слитной речи все еще допускают большое количество ошибок, нуждаются в длительной настройке, требовательны к аппаратной части и к квалификации пользователя и отказываются работать в зашумленных помещениях, хотя последнее важно как для шумных офисов, так и для мобильных систем и эксплуатации в условиях телефонной связи.
Однако распознавание речи, как и машинный перевод с одного языка на другой, относится к так называемым культовым компьютерным технологиям, к которым проявляется особое внимание. Интерес к данным технологиям постоянно подогревается бесчисленными произведениями писателей-фантастов, поэтому неизбежны постоянные попытки создать такой продукт, который должен соответствовать нашим представлениям о технологиях завтрашнего дня. И даже те проекты, которые по своей сути ничего собой не представляют, часто бывают коммерчески вполне успешны, так как потребителя живо интересует сама возможность подобных реализаций, даже независимо от того, сможет ли он применить ее на практике.








