Агенты приходят на помощь
За 15 лет своего существования World Wide Web из небольшой научной сети превратилась в глобальную информационную среду, используемую практически во всех областях деятельности человека. В настоящий момент во Всемирной паутине находятся миллиарды страниц, содержащих информацию, созданную и опубликованную как профессиональными авторами и редакторами, так и обычными пользователями в рамках порталов, сайтов, блогов, форумов, wiki-проектов и других типов ресурсов. Современные web-технологии позволяют разработчикам реализовывать Интернет-приложения, обладающие гибкими, удобными и динамическими интерфейсами, поднимая их уровень до традиционных приложений и тем самым обеспечивая удобство работы в Сети. Но, как и раньше, остается актуальной проблема эффективного доступа к информации для конечных пользователей, причем по мере роста www она только усложняется. Рассматриваемые в данной статье агентские технологии предназначены для решения этой проблемы и для обеспечения удобного способа получения, быстрой обработки и интеллектуальной фильтрации контента.
Эволюция World Wide Web
 реда World Wide Web была разработана Тимом Бернерсом-Ли (рис. 1) в 1990 году во время его работы в CERN — Европейской лаборатории физики элементарных частиц в Женеве. Все началось с того, что в 1989 году внутри CERN была поставлена задача — создать среду, которая предоставила бы научным группам, работающим в разных городах и странах, простой и удобный способ доступа к совместно используемой информации. Были сформулированы основные принципы разрабатываемой системы, в том числе требования того, чтобы интерфейс системы был простым, чтобы поддерживалось множество форматов данных и технологий, чтобы информация была доступна «по чтению» из любого места, чтобы документы предоставлялись всем пользователям в едином оформлении.
реда World Wide Web была разработана Тимом Бернерсом-Ли (рис. 1) в 1990 году во время его работы в CERN — Европейской лаборатории физики элементарных частиц в Женеве. Все началось с того, что в 1989 году внутри CERN была поставлена задача — создать среду, которая предоставила бы научным группам, работающим в разных городах и странах, простой и удобный способ доступа к совместно используемой информации. Были сформулированы основные принципы разрабатываемой системы, в том числе требования того, чтобы интерфейс системы был простым, чтобы поддерживалось множество форматов данных и технологий, чтобы информация была доступна «по чтению» из любого места, чтобы документы предоставлялись всем пользователям в едином оформлении.

Рис. 1. Тим Бернерс-Ли, разработчик World Wide Web (CERN, 1990 год)
Осенью 1990 года сотрудники CERN получили в пользование первые web-сервер и web-браузер, написанные собственноручно Бернерсом-Ли для компьютеров NeXT. А уже летом 1991 года проект «WWW», покоривший научный мир Европы, пересек океан и влился в американский проект «Internet». В качестве основы для нового языка разметки гипертекстовых документов HTML (Hyper Text Markup Language) был выбран язык SGML (Standard Generalized Markup Language), разработанный в 1986 году в ISO (International Standard Organization). Для передачи документов был разработан протокол HTTP (Hyper Text Transfer Protocol). Надо отметить, что концепция гипертекста возникла задолго до появления World Wide Web, но именно WWW стал первой внедренной и получившей широкое распространение системой, использующей эту концепцию.
Начало бурного роста и широкого развития www связывают с появлением в 1993 году графического браузера Mosaic, созданного в Национальном центре суперкомпьютерных приложений США. К концу того года программы просмотра www были разработаны для различных платформ, включая Х Window System, Apple Macintosh и PC Windows. Через год, в 1994-м, при участии CERN был создан консорциум World Wide Web (W3C, http://www.w3.org) — международная организация, основной целью которой стала поддержка и координация разработок стандартов, протоколов, прикладных программ в области WWW. Возглавил консорциум Тим Бернерс-Ли.
При работе в 1995 году над третьей версией HTML со всей очевидностью выявилось противоречие между идеологией структурной разметки и потребностями пользователей, заинтересованных в первую очередь в гибких и богатых возможностях визуального представления. Попыткой разрешить эту проблему было добавление в третьей версии HTML нового средства — так называемых каскадных таблиц стилей CSS (Cascading Style Sheets). CSS формально был независим от HTML, имел совершенно иной синтаксис и позволял, только уже в других терминах, задавать параметры визуального представления для любого HTML-тэга. С его помощью можно было, например, указать, каким шрифтом и какого кегля следует выводить заголовки заданного уровня или фрагмента текста. По сути, создание CSS стало первым шагом на пути решения такой задачи, как разделение содержимого HTML-страниц и их оформления.
Свидетельством коммерческой популярности www стала война, разразившаяся между браузерами Netscape Navigator и Internet Explorer. В погоне за популярностью и Netscape, и Microsoft начали создавать собственные HTML-тэги, не входившие в стандарт и не поддерживаемые браузером конкурента, что вызывало немало проблем и у пользователей, и у разработчиков сайтов.
Когда битва уже близилась к своему логическому завершению, консорциум W3C принял решение создать гибкий язык разметки, в котором были бы воплощены многие из лучших возможностей SGML в сочетании со всеми полезными функциями HTML. Роль такого языка была уготована XML (eXtensible Markup Language) — расширяемому языку разметки. Первый рабочий проект спецификации появился в ноябре 1996 года, а финальная рекомендация XML 1.0 была опубликована в феврале 1998 года.
XML предоставил разработчикам новые инструменты, которые охватывали не только простые web-приложения, но и базы данных, электронные коммерческие системы, а также фактически любые информационные системы. Это стало возможным, поскольку, в отличие от HTML, XML был нацелен на структурированное представление данных, в то время как задача представления данных возлагалась на специальные таблицы стилей. Таким образом, был сделан второй шаг на пути к разделению содержимого и оформления в WWW.
Выпущенный консорциумом W3C в 2000 году язык XHTML представлял собой смесь HTML и XML и был предназначен для того, чтобы сгладить переход от HTML к XML, позволить постепенно переводить web-сайты на платформу XML, оставляя их содержимое доступным для просмотра при помощи ранее созданных браузеров. В то же время развитие XML и появление на его базе специализированных языков разметки неизменно вело к представлению информации в WWW в более структурированном виде.
Web 2.0
овременная World Wide Web принципиально отличается от той среды, которую представляла собой 10 или даже 5 лет назад. При этом изменения коснулись как самого контента, так и технологий, используемых для работы с ним.
Во-первых, необходимо отметить значительное увеличение числа источников информации. Здесь и появление огромного числа новых тематических сайтов, в том числе авторских, и такое явление, как повальное увлечение блогами. В итоге современному пользователю сети доступно большое число информационных источников, причем он имеет возможность выбирать, читать ли ему, например, сообщения какого-либо информационного агентства или записи пользователя живого журнала, оказавшегося очевидцем тех или иных событий. Однако на практике избыток информации вызывает не меньше проблем, чем нехватка, поскольку воспользоваться ею в этом случае бывает практически невозможно. Кроме того, к задаче глобального поиска добавилась необходимость осуществлять эффективную фильтрацию (специальный поиск в реальном времени) уже в рамках отдельных web-ресурсов.
Web второго поколения — Web 2.0 — предполагает существование единого информационного пространства в виде множества информационных единиц, которые могут распространяться по различным сайтам и сервисам. Таким образом, сеть документов превратилась в сеть данных. Пользователи теперь уже не обращаются за информацией к первоисточнику, а ищут новые инструменты для агрегирования информационных единиц наиболее удобным для себя способом. Подтверждение этому уже существует в виде RSS-агрегаторов и агрегаторов новостей, поисковых систем, порталов, всевозможных API и различных web-сервисов, использующих такие технологии, как XML-RPC и SOAP, и предоставляющих интерфейсы к «внутренностям» своих сайтов. Например, такие порталы, как eBay и Amazon, дают возможность через специальный API работать со своими базами данных и тем самым позволяют сторонним разработчикам создавать собственные интерфейсы для этих сайтов.
Кроме того, современные технологии позволяют создавать мощные и сверхдинамичные web-интерфейсы. В качестве примеров можно привести такие сервисы, как Google Mail (рис. 2) и Google Maps (рис. 3), работа с которыми во многом напоминает работу с традиционными (локальными) приложениями.
Рис. 2. Google Mail
Рис. 3. Google Maps
В целом можно выделить следующие наиболее важные основные тенденции, характерные для среды Web 2.0:
- семантическая разметка информации и переход на XML;
- развитие web-сервисов и предоставление доступа к информации из любого места;
- возможность отчуждения информации от своего источника;
- независимая навигация и управление сайтом, позволяющие пользователям полностью контролировать интерфейс;
- отложенное добавление метаданных, осуществляемое сообществами пользователей;
- изменение парадигмы разработки, полное разделение структуры и дизайна сайта.
Описанные выше технологии должны создать определенную инфраструктуру, в рамках которой будут решаться задачи эффектного доступа и обработки распределенной информации, особенно в тех случаях, когда ее объемы требуют специальных средств. Например, многие современные сайты — агрегаторы новостей наподобие «Rambler mass media» и «Яндекс.Новости», тематические многопользовательские блоги создают столь мощный информационный поток, что самостоятельно отбирать для себя необходимые материалы становится попросту невозможно. Не спасают даже имеющиеся рубрикаторы, поскольку интересы пользователя, как правило, не ограничиваются одной темой.
Отдельная проблема — это устранение дублей, когда одну и ту же новость или другой материал редакторы сайтов перепечатывают друг у друга, зачастую даже без ссылки на источник. Причем это касается как крупных новостных ресурсов, так и тематических блогов. У пользователя просто нет времени и желания искать наиболее полный источник или проверять, содержит ли очередное сообщение что-либо новое по сравнению с уже известной ему информацией. При этом надо учесть, что с чем большим числом сайтов приходится работать, тем большее неудобство создает наличие дублей. Постепенно у пользователя начинает возникать постоянное ощущение «дежа вю», что сказывается на комфортности работы.
Понятно, что для работы с подобными объемами информации необходимо использовать эффективные средства и адекватные технологии. Пользователи должны иметь возможность с удобством искать и фильтровать данные в больших распределенных хранилищах и осуществлять мониторинг интересующей их информации в потоках новых или измененных данных, группировать материалы, а также выделять дубли и повторы, не содержащие никаких новых данных.
Персональный доступ
 ногие популярные форумные движки поддерживают удобное слежение за новыми сообщениями и предоставляют возможность в любой момент подписаться на интересную тему или отменить свою подписку. Кроме того, некоторые сайты (в основном крупные блоги) позволяют зарегистрированным пользователям показывать новые публикации, появившиеся с момента последнего визита, сохранять закладки на отдельные материалы и следить за обновлениями в темах или за появлением новых комментариев к отдельным сообщениям.
ногие популярные форумные движки поддерживают удобное слежение за новыми сообщениями и предоставляют возможность в любой момент подписаться на интересную тему или отменить свою подписку. Кроме того, некоторые сайты (в основном крупные блоги) позволяют зарегистрированным пользователям показывать новые публикации, появившиеся с момента последнего визита, сохранять закладки на отдельные материалы и следить за обновлениями в темах или за появлением новых комментариев к отдельным сообщениям.
К подобным сервисам быстро привыкаешь, вплоть до того, что на ресурсе, который не предоставляет аналогичные возможности, начинаешь ощущать дискомфорт от того, что нельзя сохранить закладку на публикацию, чтобы вернуться к ней позже, или подписаться на комментарии к отдельному сообщению. Все эти функциональные возможности в значительной мере облегчают жизнь пользователям данных сайтов, но на практике этого оказывается недостаточно. Пользователям нужны более гибкие и мощные инструменты, позволяющие, в том числе, работать с тематическими рубрикаторами, особенно когда информационный поток на ресурсе значителен.
Надо также учитывать, что разработчики сайтов исходят из образа некоторого среднего пользователя. Если, например, кого-либо не устраивает модель, по которой новости объединяются в сюжеты в новостном агрегаторе типа «Яндекс.Новости», то единственная альтернатива — вручную просматривать полную ленту. Это вовсе не означает, что разработчики сервиса допустили какую-то ошибку — просто у некоторых пользователей, в силу их привычек или рода занятий, отличный от усредненного взгляд на этот вопрос.
Отдельные продвинутые порталы уже сегодня предлагают своим пользователям расширенные возможности фильтрации и оптимизации работы со своим содержанием и предоставляемыми сервисами. Но при этом пользователю приходится вручную настраивать, например, область своих интересов, список тем и различные дополнительные критерии. Причем средств, позволяющих автоматизировать или упростить этот процесс, как правило, просто не существует.
Если пользователь работает с несколькими такими порталами и у каждого из них имеются свои тематические рубрикаторы, расширенные настройки и свой специальный интерфейс, то внесение необходимых изменений в профайл (например, в случае изменения интересов) на каждом из них превращается в трудоемкую и малоприятную процедуру. Кроме того, часто возникает необходимость в дополнительной персонализации, например пользователю нужна возможность дополнительной фильтрации или сортировки уже отобранной информации, которая просто не была предусмотрена разработчиками ресурса. Решение заключается в использовании специализированного программного обеспечения, разработанного с использованием принципов агентских технологий.
Агентские технологии
 лан Кэй, который начал первым продвигать теорию агентов, определил агент как программу, которая после получения задания способна поставить себя на место пользователя. Если агент попадает в тупик, он может задать пользователю вопрос, чтобы определить, каким образом ему необходимо действовать дальше.
лан Кэй, который начал первым продвигать теорию агентов, определил агент как программу, которая после получения задания способна поставить себя на место пользователя. Если агент попадает в тупик, он может задать пользователю вопрос, чтобы определить, каким образом ему необходимо действовать дальше.
Агенты рассматриваются как активные объекты, которые, в отличие от обычных (пассивных) объектов, не «засыпают» до получения следующего сообщения (от пользователя или из внешней среды) и его выполнения, а постоянно функционируют, решая порученные им задачи. Таким образом, главное их отличие состоит в том, что они сами являются инициаторами действий по изменению своего поведения в окружающей среде.
Повышенное внимание агентским технологиям начали уделять около 10 лет назад, но и за такое сравнительно короткое время интерес к ним уже переместился из области академических исследований в сферу коммерческих и промышленных приложений. При этом идеи и методы, лежащие в их основе, быстро мигрировали из теории искусственного интеллекта в практику разработки программного обеспечения.
Агенты по сути не являются абсолютно новым направлением в науке и технике. Их предшественниками можно считать адаптивные системы, то есть системы, которые умеют подстраиваться под ситуацию или обстоятельства и принципиальным образом менять свое поведение или характеристики, для того чтобы обеспечить решение стоящих перед ними задач. Действительно, иногда агент и простейшая адаптивная система могут быть очень близки друг к другу, но в тех случаях, когда агент функционирует в сложной внешней среде, взаимодействуя при этом с другими агентами, картина существенно меняется.
Другая парадигма
 ак чем же все-таки различаются обычные системы и системы, построенные с использованием агентов? Прежде всего необходимо отметить, что агенты — это совершенно другая парадигма, поэтому и подход к решению задач, и различия между этими системами столь же значительны, как, например, различия между разработкой программного обеспечения и применением объектно-ориентированного и структурного подходов.
ак чем же все-таки различаются обычные системы и системы, построенные с использованием агентов? Прежде всего необходимо отметить, что агенты — это совершенно другая парадигма, поэтому и подход к решению задач, и различия между этими системами столь же значительны, как, например, различия между разработкой программного обеспечения и применением объектно-ориентированного и структурного подходов.
Следует отметить, что в качестве источника информации агент может использовать информацию, полученную от другого агента. Системы, в которых предусмотрено взаимодействие агентов, называются мультиагентными. Подобные способы организации с общением агентов и вызывают наибольший интерес, поскольку позволяют реализовывать весьма сложные, но в то же время эффективно работающие системы.
Простые правила могут порождать сложные структуры. Так, например, поведение колонии муравьев можно моделировать с помощью следующих трех простых правил, выполняемых каждым муравьем:
- Перемещайся случайным образом.
- Если найдена пища, отнеси ее часть обратно в колонию и оставь след феромона (который со временем испарится), а затем перейди к правилу 1.
- Если след феромона найден, двигайся по нему к пище, а затем перейди к правилу 2.
Таким образом, колония муравьев не представляет собой ничего сложного. С одной стороны, система является сложной тогда, когда ее можно полностью описать в терминах огромного количества ее компонентов. С другой стороны, система сложна, если ее невозможно полностью понять, анализируя ее компоненты. В данном случае следует учитывать и взаимодействия между компонентами, которые по назначению и принципам функционирования могут быть как одинаковыми (гомогенные среды), так и разными (гетерогенные среды).
Другой пример — автомобильная пробка. Каждый водитель, оказавшийся в ней, также руководствуется несколькими несложными правилами, но возникающее при этом явление достаточно сложно и с трудом поддается анализу. Кроме того, необходимо отметить, что машины в пробке меняются, тогда как сама пробка сохраняется в течение длительного времени. Подобное явление называется «возникновение». Возникновение — это существование логически связанной схемы, которая формируется как результат взаимодействия между агентами. При этом возникновения сами по себе могут являться компонентами более сложных структур или явлений.
Зачастую сложные системы невозможно до конца понять именно потому, что трудно полностью представить себе взаимодействие их компонентов (агентов). Централизованные теории не ошибочны, они лишь не всегда адекватны, поскольку централизованный агент — это критическая к ошибке точка, которая делает систему уязвимой и способной к сбою.
Простая программа отличается от агента также тем, что не утруждает себя целевым поведением и анализом достигнутых результатов. Тогда как агент, представляя интересы пользователя, «заинтересован» в том, чтобы задание было выполнено. В случае неудачи или какого-то сбоя он должен повторить попытку позднее или иметь про запас альтернативный вариант решения проблемы.
В принципе, многие задачи агенты могут выполнять и без использования методов искусственного интеллекта, однако ряд проблем без них просто не может быть решен. На данный момент существует ряд технологий, таких как нейронные сети и генетические алгоритмы, нечеткая логика и другие, которые успешно применяются в различных специализированных системах, агентах и мультиагентных системах (рис. 4).

Рис. 4. Технологии, используемые интеллектуальными агентами
Под интеллектуальным агентом понимается агент, который обладает рядом знаний о себе и окружающем мире и поведение которого определяется этими знаниями. Если простой объект определяется как «данные + методы», то интеллектуальный агент — это уже «данные + методы + знания», причем методы в последнем случае включают функции работы с данными, со знаниями, а также методы взаимодействия с окружающей средой и с другими агентами.
Стационарный агент выполняется только на той системе, на которой он был запущен. Если ему понадобится информация извне, то он может использовать механизм RPC (Remote Procedure Call) или другие методы обмена и получения информации, доступные ему в среде, в которой он функционирует.
Мобильный агент, в отличие от стационарного, не привязан к системе, на которой он был запущен. Он обладает способностью перемещаться из одной системы в другую, полностью сохраняя свое состояние и перенося свой код. Его работа в разных системах должна поддерживаться специальной средой, которая в том числе обеспечивает безопасность.
Возникает закономерный вопрос: как можно доверять решение важных вопросов программе, которая не работает по строго заданному алгоритму? Ведь она может ошибиться, сделать что-нибудь не так или пропустить важную для пользователя информацию. На самом деле мы давно уже используем агентов в повседневной жизни. Относительно простые (пока) агенты фильтруют спам, следят за изменениями на сайтах, предоставляют удобный доступ к RSS-лентам. Кроме того, различные методы интеллектуальной фильтрации и обработки информации используются поисковыми системами и многими другими сервисами. Обычно эти методы позволяют добиваться неплохих результатов.
К задачам, которые можно поручать агентам, относятся: поиск в Интернете, отбор и фильтрация информационных потоков, управление электронной почтой, календарное планирование встреч, рекомендации по выбору книг и кинофильмов. Агенты могут быть уполномоченными представителями пользователя при общении с другими пользователями или их агентами, при решении порученных им задач: от торговли на Интернет-аукционе до автоответчика, обеспечивающего выполнение сложных нелинейных сценариев при работе с электронной почтой, Интернет-пейджерами и различными средствами голосовой коммуникации.
Главная особенность интерфейса, формы и способов представления информации, которые могут предоставить агенты, состоит в том, что они оказываются персонифицированными. Это достигается за счет того, что интеллектуальные агенты способны к обучению. В одном случае они могут целенаправленно анкетировать пользователя, в другом — агент получает информацию о привычках пользователя путем наблюдения за его действиями.
Программы-агенты
 ассмотрим несколько примеров программ, которые являются ярко выраженными персональными агентами или обладают их чертами.
ассмотрим несколько примеров программ, которые являются ярко выраженными персональными агентами или обладают их чертами.
Copernic Agent (рис. 5, http://www.copernic.com/), являясь по сути метапоисковиком, работает по методу «опроса свидетелей». Она одновременно отправляет запросы нескольким популярным поисковым системам, выбирает наиболее рейтинговые ссылки, сопоставляет их между собой, удаляет дубли и, сортируя отобранное по рейтингу в соответствии со своим алгоритмом ранжирования, выводит их пользователю. Недействующие ссылки можно исключить из списка, а результаты поиска помимо рейтинга могут быть также отсортированы по доменам, географическим регионам, времени последнего изменения и статусу. Ключевые слова выделяются цветной подсветкой.
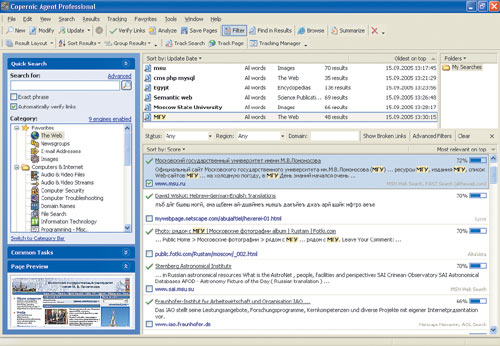
Рис. 5. Copernic Agent
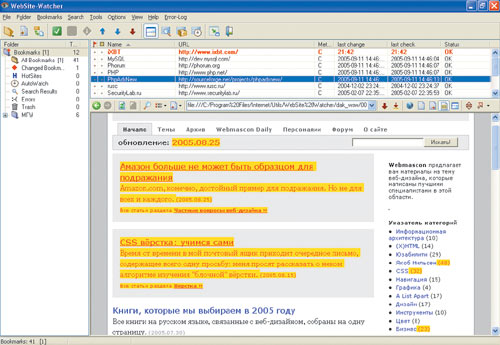
Рис. 6. WebSite-Watcher
Все доступные для работы поисковики (всего их более 1000) сгруппированы в тематические категории. При формировании нового запроса, в зависимости от области и тематики поиска, пользователь указывает, поисковыми системами из какой группы он хочет воспользоваться. Набор и тематика категорий весьма широки — всего в программе их более 120. С их помощью можно осуществлять как текстовый поиск с применением универсальных поисковых систем, так и, используя специализированные поисковые системы и сервисы, искать изображения, медиафайлы, новости, статьи в энциклопедиях, обзоры программного обеспечения, получать информацию по доменным именам и многое другое. Подобная специализация позволяет добиться весьма неплохой релевантности результатов.
Программа ведет полную историю запросов, что позволяет в любой момент вернуться к полученным результатам и, например, проверить их на наличие обновлений или осуществлять мониторинг изменений с заданной периодичностью. В случае если обновления будут обнаружены, Agent немедленно оповестит о них, и если пользователь выбрал соответствующую опцию, то он может отправить страницу с подсвеченными изменениями по электронной почте. То же самое будет сделано при обнаружении нового ресурса по заданной тематике.
Хорошим дополнением к Copernic Agent будет программа Copernic Summarizer, которая позволяет создавать резюме документов и выделять список ключевых понятий анализируемого материала. К сожалению, на данный момент поддерживаются только английский, французский, немецкий и испанский языки. Результат может быть сохранен или распечатан. Но самое главное — это то, что Copernic Summarizer интегрируется с Agent’ом и может «резюмировать» найденные им страницы, что позволяет пользователю быстро понять их содержание, не тратя времени на открытие документов.
MySimon (http://www.mysimon.com/) — это shop-агент, построенный по технологии «The Virtual Learning Agent», который осуществляет интеллектуальный поиск, сравнивая цены миллионов товаров в более чем двух тысячах онлайновых магазинов. Агент прост в обращении, осуществляет быстрый поиск, надежен с точки зрения релевантности и качества предоставляемой им информации.
Поисковый агент MP3-Wolf (http://www.trellian.com/) сканирует Интернет в поисках нужных пользователю музыкальных файлов. В процессе работы он использует различные поисковые системы, а также сайты, найденные им ранее и содержащиеся в его базе. Робот работает в режиме реального времени и способен находить, сортировать и анализировать десятки тысяч музыкальных файлов и ссылок в час, отбрасывая при этом мертвые ссылки. Поддерживает списки сайтов-исключений.
Программа WebSite-Watcher (рис. 6, http://www.aignes.com/) предназначена для слежения за изменениями на сайтах. Поддерживает работу RSS-ленты. Имеет гибкие настройки по предотвращению ложных срабатываний, когда отдельные изменения на страницах носят случайный или технический характер, например изменение числа просмотров. WebSite-Watcher может работать по расписанию и дает возможность устанавливать дополнительные ограничения по времени проверки, что позволяет, например, избежать обращений к сайту в выходные, когда тот не обновляется. В целом программа является одной из самых мощных в своем классе.
Существуют и другие специализированные агенты, которые, например, занимаются поиском изображений, осуществляют мониторинг новых почтовых сообщений, служат автоответчиками с поддержкой сложных нелинейных сценариев и возможностью отправить письмо или sms-сообщение.
Конечно, не всегда можно провести четкую границу между обычной программой и агентом. Некоторые современные программы уже приобретают отдельные черты агентов: представление интересов пользователя, ответственность за свои действия и за результат, постоянный или периодический режим работы, общение и обмен информацией с себе подобными. К сожалению, иногда слово «агент» (подобно тому, как это было с другими технологиями) используется исключительно в маркетинговых целях, для привлечения внимания к продукту, но нездоровый интерес пройдет и время расставит все по своим местам, как произошло, например, с нейросетевыми технологиями.
Как видно из приведенных примеров, агенты могут заниматься весьма разнообразными задачами, для решения которых им, конечно же, необходимы соответствующие данные. В настоящий момент источником таких данных в основном служат другие сервисы (например, поисковые системы) или агенты самостоятельно анализируют неструктурированную информацию, представленную в Сети. Надо отметить, что функционал современных RSS-агрегаторов, использующих структурированную информацию с семантикой, пока весьма слаб. Таким образом, можно предположить, что программы этого класса будут активно развиваться в дальнейшем, скорее всего претендуя на роль некоторых универсальных агентов, предназначенных для сбора, обработки и фильтрации информации из Интернета. Ведь использование нескольких программ для решения одной и той же задачи при работе с разными источниками информации вряд ли можно назвать удобным решением.
Но полностью возможности интеллектуальных агентов должны раскрыться по мере внедрения семантического web’а, в котором благодаря семантической разметке им не понадобится строить предположения о назначении и природе той или иной информации, поскольку эти моменты будут описаны в онтологиях.
Семантический web
![]() лавное отличие семантического web’а от среды WWW заключается в том, что в нем страницы содержат информацию на двух языках: обычном, понятном человеку и показываемом браузером, и специальном (описываемом онтологиями), информация на котором скрыта от людей, содержит семантическую составляющую и предназначена для различных программ, агентов и роботов.
лавное отличие семантического web’а от среды WWW заключается в том, что в нем страницы содержат информацию на двух языках: обычном, понятном человеку и показываемом браузером, и специальном (описываемом онтологиями), информация на котором скрыта от людей, содержит семантическую составляющую и предназначена для различных программ, агентов и роботов.
Онтология охватывает понятия некоторой предметной области и связи между этими понятиями. В основе онтологий лежат классы, являющиеся основными понятиями рассматриваемой предметной области. Классы выстраиваются в иерархию понятий из расчета того, что каждый подкласс наследует все свойства и характеристики родительского класса, при этом расширяя или уточняя его. Каждый класс содержит атрибуты, которые определяют свойства и характеристики этого класса.
Важной частью онтологии являются логические правила вывода и ограничения, позволяющие агентам собирать информацию из разрозненных источников, получать из данных, для которых построены онтологии, новые знания, а также проверять содержащуюся в онтологии информацию на полноту и непротиворечивость. Эти правила переносят знания о зависимостях между разными понятиями из реального мира в построенную модель. Дополнительную информацию о семантическом web’е можно найти в статье «Интеллектуальные агенты семантического web’а», опубликованной в 10-м номере нашего журнала за прошлый год.
В целом крупные российские Интернет-порталы, имеющие собственные поисковые системы, довольно скептически относятся к практическому внедрению семантического web’а в ближайшее время в том виде, в каком его описывает консорциум W3C. Именно такая позиция озвучивалась сотрудниками Рамблера и Яндекса на Российском Интернет-форуме в текущем году. Отчасти понять их можно. К примеру, по словам технического директора компании «Яндекс» Ильи Сегаловича, далеко не все разработчики сайтов в состоянии разобраться со спецификацией формата RSS и реализовать его поддержку без ошибок. Еще одна проблема, о которой не стоит забывать, — это поисковый спам, когда разработчики сайтов различными путями вводят поисковые системы в заблуждение.
Но если взглянуть на проблему немного под другим углом, можно увидеть, что элементы семантического web’а (пока простейшие) медленно, но уверено завоевывают свое место в сети. Тот же самый формат RSS (Really Simple Syndication), получивший весьма широкую поддержку в последние два года, обеспечил возможность быстро и эффективно получать анонсы новых материалов сайтов, форумов и блогов.
Проект Яндекса — поиск по блогам (рис. 7, http://blogs.yandex.ru/) — в его текущем виде стал возможен во многом благодаря широкому внедрению формата RSS, за счет чего индексирующие модули поисковой системы могут точно определить дату, автора, заголовок и тело сообщения и обеспечить индексацию новой информации почти в реальном времени или с минимальными задержками. Еще один сервис компании — «Яндекс.Лента», запущенный в середине лета (http://lenta.yandex.ru/), использующий RSS и предназначенный для агрегации RSS-лент, служит подтверждением высказанным выше предположениям относительно перспектив и будущего этих технологий.
Рис. 7. Поиск Яндекса по блогам и форумам
Так, может быть, порталы лукавят и все-таки ведут исследования совместно с разработками в области семантического web’а? Просто компании не хотят раньше времени афишировать свою работу. Помимо RSS есть и другие словари для онтологий, например Dublin Core, vCard, iCalendar. Они уже сегодня получили достаточно широкое распространение, используются во многих информационных системах, и их надо применять лишь при разметке данных. Открытая их поддержка хотя бы одним крупным игроком рынка могла бы значительно повысить интерес к этому направлению.
Каковы перспективы?
 одводя некоторые итоги вышеизложенного, можно утверждать, что интеллектуальные агенты и семантический web являются весьма перспективным направлением, способным помочь людям выбраться из существующей информационной ямы. Конечно, посещая несколько web-страниц в день и пару раз в месяц пользуясь поисковой системой, пользователь может составить ошибочное мнение, что никакой особенной проблемы на самом деле не существует. Именно с этим и связано определенное недоверие к использованию агентских технологий. Одни утверждают, что они и сами справляются со «своим» объемом данных, другие опасаются, что агенты все равно не смогут решить их «информационных» проблем.
одводя некоторые итоги вышеизложенного, можно утверждать, что интеллектуальные агенты и семантический web являются весьма перспективным направлением, способным помочь людям выбраться из существующей информационной ямы. Конечно, посещая несколько web-страниц в день и пару раз в месяц пользуясь поисковой системой, пользователь может составить ошибочное мнение, что никакой особенной проблемы на самом деле не существует. Именно с этим и связано определенное недоверие к использованию агентских технологий. Одни утверждают, что они и сами справляются со «своим» объемом данных, другие опасаются, что агенты все равно не смогут решить их «информационных» проблем.
Тем не менее сложные системы на базе агентов уже нашли широкое применение в промышленности. Так, например, IBM использует агентов для производства полупроводниковых микросхем, датская судостроительная компания — для заварки отверстий в кораблях, а в Японии система на базе агентов выполняет функции интерфейса оператора сверхскоростного поезда. Персональные агенты начинают применяться в такой области, как дистанционное образование, являясь весьма важным инструментом, облегчающим работу преподавателя и позволяющим сделать обучение более качественным и персонифицированным.
Следует учесть, что переход к использованию агентских технологий в программном обеспечении будет постепенным, а значит, изменения и улучшения, производимые на каждом шаге, окажутся не столь заметными. К примеру, проблема распознавания печатного текста изначально считалась весьма сложной задачей из области искусственного интеллекта. В настоящее время с ней весьма успешно справляется, например, ABBYY Fine Reader, обеспечивая высокое качество распознавания даже в тех случаях, когда текст плохо напечатан или располагается поверх фонового изображения. Другим примером может служить ряд антиспамерских плагинов для почтовых программ, применяющих байесовы сети и предназначенных для персонифицированной фильтрации спама. Ведь, по сути, речь идет о персональном интеллектуальном агенте, решающем важные задачи пользователей, но большинство будет считать его не более чем дополнительным модулем, пусть даже отягощенным некоторой сложной математикой.
Когда человек сталкивается с проблемой, которую не в состоянии решить самостоятельно, он или находит себе помощника, или создает инструмент, необходимый для работы. Так было на протяжении всей истории человечества, и наши дни не составляют исключения. На роль персональных помощников в информационную эпоху интеллектуальные агенты подходят как нельзя лучше, но когда они окончательно войдут в нашу повседневную жизнь, то мы, скорее всего, этого даже не заметим и просто назовем их умными программами.








