Средства бизнес-анализа в SQL Server 2005. Часть1. Общие сведения
Хранилища данных в SQL Server 2005
Введение
Сейчас практически невозможно найти компанию, которая вообще не использовала бы в своей деятельности тех или иных информационных систем или не начала бы применять их менее года назад. Мало того, большинство предприятий (причем не только крупных, но и совсем небольших) уже владеет определенным объемом накопленных данных, нередко представляющих собой немалую ценность. Если вспомнить, сколько скандалов, связанных с утечкой корпоративных данных, обсуждалось в прессе за последний год, насколько бурно развивался в последнее время бизнес компаний, поставляющих на рынок средства защиты от подобных утечек, и как процветала криминальная торговля украденными данными, становится очевидно — корпоративные данные сегодня представляют немалую ценность.
Не секрет, что ценность корпоративных данных заключается не только в суммарной стоимости отдельных записей, но и в общей стоимости набора данных как единого целого — именно совокупность записей может служить источником сведений о закономерностях, тенденциях или взаимозависимостях между какими-либо данными, позволяющих топ-менеджерам компаний принимать определенные бизнес-решения. Учитывая этот факт, поставщики бизнес-приложений нередко включают в их состав не только средства ввода и редактирования данных, но и средства аналитической обработки данных, позволяющие тем или иным способом выявлять и представлять закономерности и тенденции, прослеживающиеся в данных.
Отметим, что аналитическая обработка данных традиционно базируется на построении специальным образом спроектированных реляционных хранилищ данных, позволяющих с высокой скоростью осуществлять аналитические запросы (как правило, речь идет о запросах на выбор данных, нередко агрегатных, например сумм или средних величин), на создании на их основе многомерных хранилищ данных, содержащих агрегатные данные в нереляционной структуре, на отображении этих данных или генерации отчетов по ним, а также на более сложной обработке, например генерации и проверке гипотез о закономерностях, характерных для указанного набора данных. Именно таким образом обычно осуществлялась аналитическая обработка данных как в SQL Server 2000, так и в ряде конкурирующих продуктов от IBM, Oracle и Sybase. Подробнее об этом можно прочесть в циклах «Введение в OLAP» и «Введение в Data Mining», публиковавшихся в нашем журнале в 2001-2003 годах (эти статьи вы сможете найти и на нашем CD-ROM), однако ниже мы напомним о том, как именно это было реализовано, и рассмотрим, что нового из средств аналитической обработки данных появилось в очередной версии SQL Server.
Хранилища данных
Хранилищем данных (Data Warehouse) обычно называют базу данных, основным назначением которой является выполнение аналитических запросов на выбор данных. Хранилища данных могут быть как реляционными, так и многомерными.
Ральф Кимбалл (Ralph Kimball), один из авторов концепции хранилищ данных, сформулировал в 2000 году основные требования к хранилищам данных, а именно:
- поддержка высокой скорости получения данных;
- поддержка внутренней непротиворечивости данных;
- возможность получения и сравнения так называемых срезов данных (slice and dice);
- наличие удобных средств просмотра данных;
- полнота и достоверность хранимых данных;
- поддержка качественного процесса пополнения данных.
С точки зрения реализации хранилищ данных SQL Server 2000 был вполне самодостаточным продуктом, поскольку позволял создавать как реляционные, так и многомерные хранилища.
Реляционные хранилища данных
В отличие от так называемых оперативных баз данных, с которыми работают приложения, модифицирующие данные, проектирование реляционных хранилищ данных обычно подразумевает требование минимального времени выполнения запросов на чтение (тогда как у оперативных баз данных чаще всего минимизируется время выполнения запросов на изменение данных). Обычно данные копируются в хранилище из оперативных баз данных согласно определенному расписанию (в случае SQL Server 2000 для этой цели использовались службы преобразования данных (Data Transformatio Services, DTS).
Типичная структура хранилища данных существенно отличается от структуры обыкновенной реляционной СУБД и, как правило, не имеет никакого отношения к третьей нормальной форме. Обычно эта структура денормализована (это позволяет повысить скорость выполнения запросов) и может допускать избыточность данных (рис. 1).
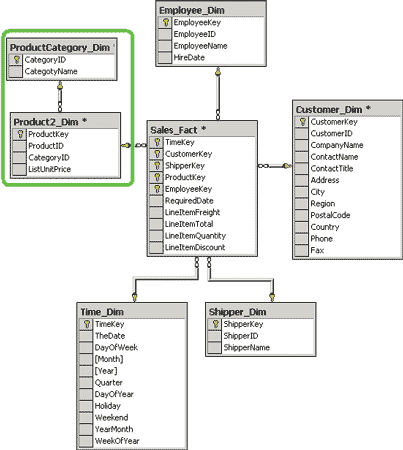
Рис. 1. Пример структуры хранилища данных
Основными составляющими структуры хранилищ данных являются таблица фактов (fact table) и таблицы измерений (dimension tables).
Таблица фактов (в примере на рис. 1 она называется Sales_Fact) является основной таблицей хранилища данных. Как правило, она содержит сведения об объектах или о событиях (в данном примере — о фактах продаж), совокупность которых будет в дальнейшем анализироваться. Обычно такая таблица содержит уникальный составной ключ, объединяющий первичные ключи таблиц измерений. Чаще всего это целочисленные значения либо значения типа «дата/время» — ведь таблица фактов может содержать сотни тысяч или даже миллионы записей, поэтому хранить в ней повторяющиеся текстовые описания, как правило, невыгодно. Помимо этого таблица фактов содержит одно или несколько числовых полей, на основании которых в процессе выполнения аналитических запросов вычисляются агрегатные данные.
Отметим, что в таблице фактов отсутствуют сведения о том, как группировать записи при вычислении агрегатных данных. Эти сведения содержатся в таблицах измерений.
Таблицы измерений содержат неизменяемые либо редко изменяемые данные. Таблицы измерений содержат как минимум одно описательное поле и, как правило, целочисленное ключевое поле (обычно суррогатный ключ). Нередко таблица измерений может содержать и поля, указывающие на дополнительные атрибуты, имевшиеся в исходной оперативной базе данных, или на атрибуты, ответственные за группировку ее собственных данных. Каждая таблица измерений должна находиться в отношении «один ко многим» с таблицей фактов.
Различают две оcновные разновидности схем данных для подобных хранилищ — «звезда» (таблицы измерений связаны только с таблицей фактов) и «снежинка» (хотя бы одна таблица измерений ссылается на таблицу, которая находится по отношению к ней в связи «один ко многим», — именно эта схема приведена на рис. 1).
Многомерные хранилища данных
Многомерные хранилища данных являются основой OLAP-средств (OLAP On-Line Analytical Processing), предназначенных для комплексного многомерного анализа данных. Концепция OLAP была описана в 1993 году Э.Ф.Коддом, автором реляционной модели данных, и в настоящее время поддержка OLAP реализована во многих СУБД и в средствах анализа данных.
Многомерные хранилища обычно содержат агрегатные данные (например, суммы, средние значения, количество значений) для различных выборок. Чаще всего такие агрегатные функции образуют многомерный набор данных, называемый кубом, оси которого (называемые измерениями) содержат параметры, а ячейки — зависящие от них агрегатные данные (иногда они называются мерами). Вдоль каждой оси данные могут быть организованы в иерархии, отражающие различные уровни их детализации. Как правило, агрегатные данные получаются путем выполнения серии запросов на группировку данных типа
SELECT Country, ShipperName, SalesPerson SUM (ExtendedPrice)
FROM Invoices
GROUP BY COUNTRY, ShipperName, Year
Число осей куба обычно совпадает с количеством полей для группировки (рис. 2).
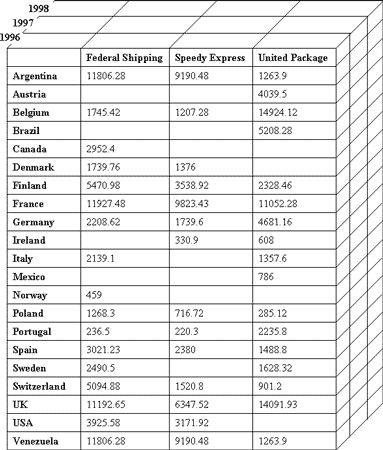
Рис. 2. Многомерный куб
Отметим, что зачастую в качестве источника данных для подобных запросов выступают реляционные хранилища данных. В этом случае, как правило, таблицы измерений содержат исходные данные для формирования измерений куба, а таблица фактов — исходные данные для вычисления мер куба.
В многомерных хранилищах данных содержатся агрегатные данные различной степени детализации, например объемы продаж по дням, месяцам, годам, по категориям товаров и т.п. Цель хранения агрегатных данных — сократить время выполнения запросов, поскольку в большинстве случаев для анализа и прогнозов интерес представляют не детальные, а суммарные данные.
Как исходные, так и агрегатные данные могут храниться либо в реляционных, либо в многомерных структурах. Большинство современных серверных OLAP-средств (включая и аналитические службы SQL Server) поддерживают все три способа хранения данных.
Отметим, что OLAP-источники данных, в том числе аналитические службы SQL Server 2000, чаще всего обладали определенными недостатками, такими как сложность получения актуальных значений агрегатных данных, поскольку и обновление данных в промежуточном хранилище, и пересчет OLAP-кубов являются отдельными операциями, производимыми по расписанию и нередко ресурсоемкими.
Хранилища данных в SQL Server 2005
В отличие от реализации средств бизнес-анализа в SQL Server 2000 и в ряде конкурирующих продуктов, аналитические службы SQL Server 2005 позволяют описать набор кубов и измерений в виде единой универсальной модели измерений (Unified Dimensional Model, UDM), позволяющей спроектировать единую базу данных, которая может использоваться и для оперативного ввода данных, и для выполнения аналитических запросов. В частности, аналитические службы SQL Server 2005 позволяют создавать OLAP-кубы без промежуточного хранилища данных в виде «звезды» и выполнять аналитические запросы непосредственно в оперативной БД — UDM может обращаться к любому источнику данных, находящемуся в третьей нормальной форме. При этом производительность оперативной БД не снижается, поскольку OLAP-кубы являются самостоятельным хранилищем данных. Это заметно упрощает решение такой задачи, как поддержка OLAP-данных в актуальном состоянии, — OLAP кубы создаются и обслуживаются практически в режиме реального времени, при этом аналитические приложения получают выигрыш в производительности за счет упреждающего OLAP-кэширования.
Упреждающее кэширование позволяет при создании куба указывать, когда и как данный куб должен быть обновлен. Например, анализ в режиме реального времени может быть достигнут такой настройкой кэша, при которой каждая новая транзакция в реляционной базе данных будет посылать уведомление UDM. Это приведет в действие обновление куба в фоновом режиме и будет поддерживать синхронизацию между кубом и реляционной БД. В качестве альтернативы возможно обновление кэша по временному расписанию, например каждые полчаса.
Более того, аналитические службы SQL Server позволяют создавать сложные схемы на основе существующей структуры данных, включая вычисляемые поля или SQL-выражения.
Еще одно интересное новшество SQL Server 2005, используемое аналитическими службами, — так называемые представления источников данных (Data Source Views, DSV), позволяющие создавать сложные аналитические модели на основании существующих схем оперативных БД либо на основании схем «звезда», в том числе модели с виртуальными связями (рис. 3). Одно из главных преимуществ DSV заключается в том, что они могут быть созданы пользователями, не имеющими права создавать объекты в самой БД. Единожды созданные многомерные объекты анализа могут основываться на DSV, позволяя строить OLAP-кубы даже на основе базы данных, в схему которой вносятся изменения.
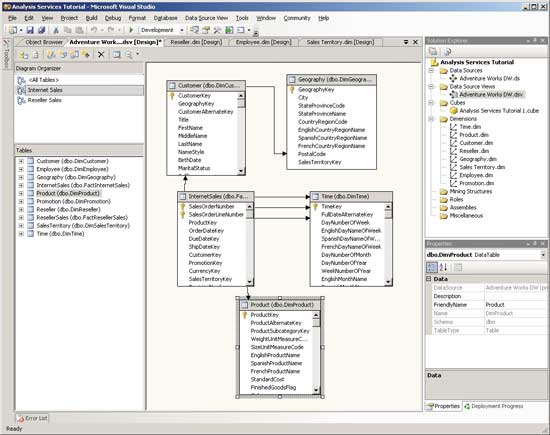
Рис. 3. Пример Data Source View
Витрины данных и отчеты
Одним из базовых понятий аналитической обработки данных являются так называемые витрины данных (Data Marts) — подвыборки наборов данных, предоставляемые для разных подразделений компании или для решения разного рода задач. Традиционно витрины данных реализуются в виде отдельных хранилищ меньшего размера, куда поступают данные с помощью ETL-служб. Еще одна проблема, с которой сталкиваются многие компании (особенно те, что пережили слияние и приобретение других компаний, а также те, что расхлебывают последствия плохо спланированной или спонтанной автоматизации различных служб и отделов), — объединение в единое хранилище нескольких источников данных. Естественно, чем больше промежуточных хранилищ данных используется для решения указанных задач, тем дороже обходится их сопровождение и тем выше оказываются риски потери целостности данных.
Аналитические службы SQL Server 2005 позволяют — с помощью все той же модели UDM — создать единое представление для различных источников данных, в том числе для реляционных БД, для данных, хранящихся в файлах или получаемых с помощью веб-служб, и затем осуществлять анализ данных, основываясь на этой модели. Для создания витрин данных можно использовать так называемые проекции данных — подвыборки, предоставляемые для разных подразделений или для решения различных задач. В отличие от традиционных витрин данных, проекции данных не предполагают создания отдельных хранилищ и организации процедур их синхронизации с основным хранилищем.
Отметим, что UDM также значительно упрощает создание решений, использующих различные типы отчетов, будь то OLAP-отчеты или отчеты, основанные на реляционных данных, поскольку источник данных в этом случае становится единым, а значит, автоматически решается проблема согласованности отчетов разного типа.
Для упрощения аналитической обработки данных в Transact-SQL было добавлено несколько новых аналитических функций, таких как ROW_NUMBER (порядковый номер строки в результирующем наборе данных), RANK и DENSE_RANK (ранг строк в результирующем наборе данных), NTILE (разделение отсортированного результирующего набора данных на группы строк приблизительно одинакового размера). Кроме того, в Transact-SQL были добавлены операторы pivot и unpivot для генерации отчетов в виде перекрестных таблиц и превращения перекрестных таблиц в обычные (ранее такие задачи решались с помощью наборов запросов, аналогичных тому, что приведен в предыдущем разделе), а также средства создания рекурсивных запросов (то есть запросов к таблице, представляющей иерархическую структуру данных наподобие организационного подчинения сотрудников в виде связи одного и того же поля с самим собой в соотношении «один ко многим»). |
Ключевые показатели
Ключевые показатели (Key Performance Indicator, KPI) — это метрики, определенные при проектировании данных с целью отображения состояния того или иного значения, являющегося ключевым показателем бизнеса, в виде, наиболее удобном для принятия управленческого решения (например, отображение цветом положительной или отрицательной динамики роста продаж)(рис. 4). Описание метрик хранится и создается в базе данных, и все использующие ее приложения могут получить доступ к значениям этих метрик.
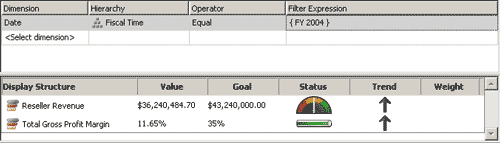
Рис. 4. Пример ключевых показателей
Детализация данных
Одна из распространенных задач, стоящих перед разработчиками решений, включающих элементы бизнес-анализа, — реализация интерактивных способов нестандартных видов анализа. Возможность детализации данных позволяет пользователям определить, из чего складываются получаемые ими агрегатные данные, однако этих сведений зачастую недостаточно для понимания того, что именно влияет на полученные значения. Нередко взаимозависимость данных, представленных в виде OLAP-кубов, оказывается неочевидной, особенно при наличии корреляции между значениями данных в различных измерениях (например, между датой заказа товара и датой его доставки). Отметим, что традиционные OLAP-системы чаще всего обладают ограниченными средствами проведения подобного анализа, особенно на уровне конечных пользователей, ограничивая его возможности манипуляциями в иерархиях одного и того же измерения и не предоставляя возможности проверить наличие подобных корреляций, если таковые не были предусмотрены при изначальном проектировании данных.
Отметим также, что аналитические службы SQL Server 2005 способны решать описанные выше проблемы с помощью ряда нововведений, таких как измерения, основанные на атрибутах. Все атрибуты могут быть использованы для декомпозиции и фильтрации данных, предоставляя возможность построения любой комбинации взаимосвязи измерений в полном смысле слова на лету.
Аналитические службы SQL Server 2005 наряду с прочим предоставляют концепцию измерений «многие ко многим». Если традиционные хранилища данных допускают взаимосвязь факта только с одним измерением, то SQL Server 2005 поддерживает взаимосвязи, в которых одна запись фактов может отображаться на множество записей измерений.
Еще одно нововведение, упрощающее анализ данных, — создание так называемых ролевых измерений. Например, для анализа заказов по датам заказа или по датам отправки можно создать одно временное измерение, а затем использовать его как базовое и для даты заказа, и для даты отправки.
Немаловажной для анализа данных является поддержка так называемых вырожденных измерений — измерений, предназначенных для записей таблицы фактов, не связанных ни с одной записью таблицы измерений.
Локализация данных
Одной из проблем, встречающихся при разработке приложений для международных компаний, является возможность представления данных в виде, удобном для анализа в конкретной стране, например применение для анализа местной валюты, единиц измерений или местных названий географических регионов, дней недели, месяцев. Модель UDM дает возможность описать правила конвертации валют, преобразования единиц измерения, названий. Это упрощает анализ данных, поступивших из разных стран, позволяя хранить их в едином хранилище и представлять сотрудникам из разных стран в виде, удобном для жителей конкретной страны. Возможность использования локализованных представлений отдельных кубов и создания их на лету называется Translations (рис. 5).
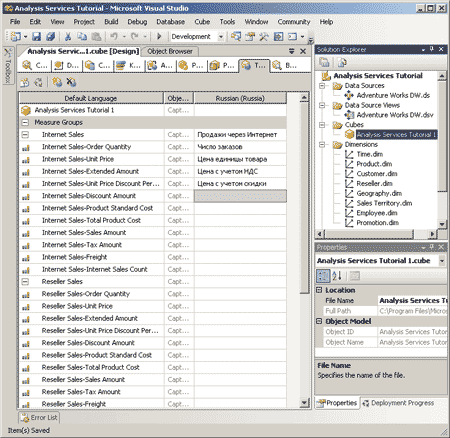
Рис. 5. Средства создания локализованных представлений кубов
Заключение
Как видим, аналитические службы SQL Server 2005 предоставляют разработчикам и бизнес-пользователям сравнительно много интересных возможностей, таких как генерация единого консолидированного представления данных из разных источников, создание OLAP-хранилищ, обновляющихся практически в режиме реального времени, возможность предложить пользователям представления данных, выполняющие функции витрин данных, но не требующие создания отдельных хранилищ, возможность создания локализованных представлений данных и осуществления сложных видов анализа, не предусмотренных при изначальном проектировании базы данных. Многое сделано и для повышения производительности приложений, и для упрощения представления ключевых показателей бизнеса для бизнес-пользователей. Отметим, что далеко не все из перечисленных возможностей доступны в конкурирующих продуктах — и это при том, что заметным игроком на рынке средств аналитической обработки данных компания Microsoft стала не так давно.
На этом мы не заканчиваем знакомство с аналитическими службами SQL Server 2005 — в последующих статьях мы рассмотрим некоторые детали перечисленных нами нововведений и обсудим, что представляют собой включенные в состав данного продукта средства Data Mining.








