Средства бизнес-анализа в SQL Server 2005
Часть 2. Средства создания OLAP-кубов
Создание OLAP-кубов в SQL Server 2005
В предыдущей статье данного цикла (см. № 2’2005) мы рассказали об основных новшествах аналитических служб SQL Server 2005. Сегодня мы подробнее рассмотрим средства создания OLAP-решений, входящие в этот продукт.
Коротко об основах OLAP
 режде чем начать разговор о средствах создания OLAP-решений, напомним, что OLAP (On-Line Analytical Processing) — это технология комплексного многомерного анализа данных, концепция которой была описана в 1993 году Э.Ф.Коддом, знаменитым автором реляционной модели данных. В настоящее время поддержка OLAP реализована во многих СУБД и иных инструментах.
режде чем начать разговор о средствах создания OLAP-решений, напомним, что OLAP (On-Line Analytical Processing) — это технология комплексного многомерного анализа данных, концепция которой была описана в 1993 году Э.Ф.Коддом, знаменитым автором реляционной модели данных. В настоящее время поддержка OLAP реализована во многих СУБД и иных инструментах.
OLAP-кубы
Что представляют собой OLAP-данные? В качестве ответа на этот вопрос рассмотрим простейший пример. Предположим, в корпоративной базе данных некоего предприятия имеется набор таблиц, содержащих сведения о продажах товаров или услуг, и на их основе создано представление Invoices с полями Country (страна), City (город), CustomerName (название компании-клиента), Salesperson (менеджер по продажам), OrderDate (дата размещения заказа), CategoryName (категория товара), ProductName (наименование товара), ShipperName (компания-перевозчик), ExtendedPrice (оплата за товар), при этом последнее из перечисленных полей, собственно, и является объектом анализа.
Выбор данных из такого представления можно осуществить с помощью следующего запроса:
SELECT Country, City, CustomerName, Salesperson,
OrderDate, CategoryName, ProductName, ShipperName, ExtendedPrice
FROM Invoices
Предположим, нас интересует, какова суммарная стоимость заказов, сделанных клиентами из разных стран. Для получения ответа на этот вопрос необходимо сделать следующий запрос:
SELECT Country, SUM (ExtendedPrice) FROM Invoices
GROUP BY Country
Результатом этого запроса будет одномерный набор агрегатных данных (в данном случае — сумм):
| Country | SUM (ExtendedPrice) |
| Argentina | 7327.3 |
| Austria | 110788.4 |
| Belgium | 28491.65 |
| Brazil | 97407.74 |
| Canada | 46190.1 |
| Denmark | 28392.32 |
| Finland | 15296.35 |
| France | 69185.48 |
Germany |
209373.6 |
... |
... |
Если же мы хотим узнать, какова суммарная стоимость заказов, сделанных клиентами из разных стран и доставленных различными службами доставки, мы должны выполнить запрос, содержащий два параметра в предложении GROUP BY:
SELECT Country, ShipperName, SUM (ExtendedPrice) FROM Invoices
GROUP BY COUNTRY, ShipperName
Исходя из результатов этого запроса можно создать таблицу следующего вида:
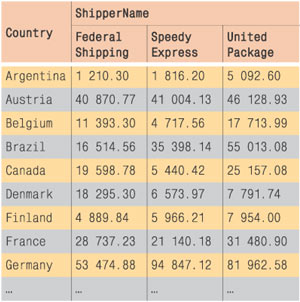
Такой набор данных называется сводной таблицей (pivot table).
Далее можно добавить для рассмотрения третий параметр, выполнив запрос, например, следующего вида:
SELECT Country, ShipperName, SalesPerson SUM (ExtendedPrice) FROM Invoices
GROUP BY COUNTRY, ShipperName, Year
На основании результатов этого запроса можно построить трехмерный куб (рис. 1).
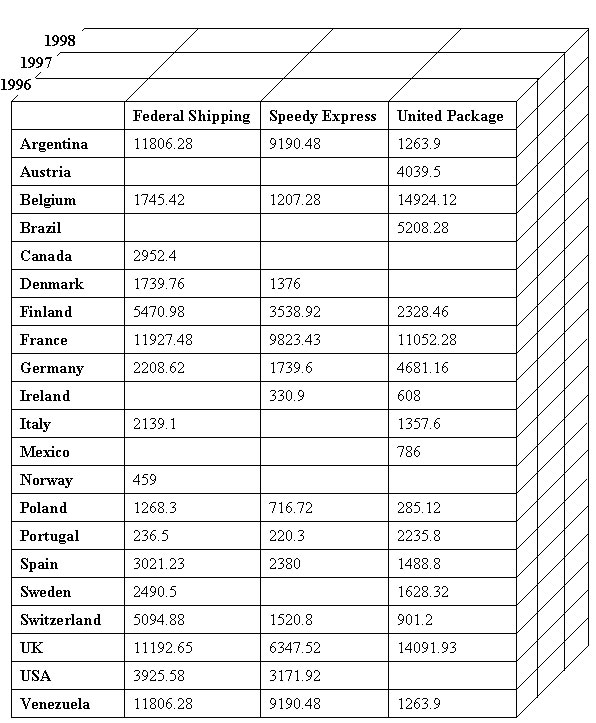
Рис. 1. Трехмерный OLAP-куб
Добавляя дополнительные параметры для анализа, можно создать куб с теоретически любым числом измерений, при этом наряду с суммами в ячейках OLAP-куба могут содержаться результаты вычисления иных агрегатных функций (например, средние, максимальные, минимальные значения, количество записей исходного представления, соответствующее данному набору параметров). Поля, на основании которых вычисляются результаты, называются мерами куба.
Иерархии в измерениях
Предположим, нас интересует не только суммарная стоимость заказов, сделанных клиентами в разных странах, но и суммарная стоимость заказов, сделанных клиентами в разных городах одной страны. В этом случае можно воспользоваться тем, что значения, наносимые на оси, имеют различные уровни детализации — это описывается в рамках концепции иерархии изменений. Скажем, на первом уровне иерархии располагаются страны, на втором — города. Отметим, что начиная с SQL Server 2000 аналитические службы поддерживают так называемые несбалансированные иерархии, содержащие, например, такие члены, «дети» которых содержатся не на соседних уровнях иерархии или отсутствуют для некоторых членов изменения. Типичный пример подобной иерархии — учет того факта, что в разных странах могут существовать, либо отсутствовать такие административно-территориальные единицы, как штат или область, размещающиеся в географической иерархии между странами и городами (рис. 2).
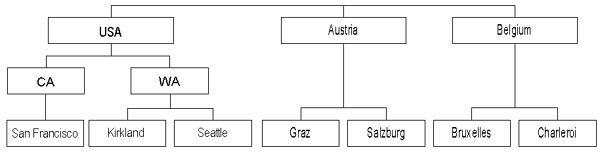
Рис. 2. Примеры несбалансированных иерархий в измерениях OLAP-кубов
Отметим, что в последнее время принято выделять типичные иерархии, например содержащие географические или временные данные, а также поддерживать существование нескольких иерархий в одном измерении (в частности, для календарного и финансового года).
Создание OLAP-кубов в SQL Server 2005
 SQL Server 2005 кубы создаются с помощью SQL Server Business Intelligence Development Studio. Этот инструмент представляет собой специальную версию Visual Studio 2005, предназначенную для решения данного класса задач (а при наличии уже установленной среды разработки список шаблонов проектов пополняется проектами, предназначенными для создания решений на основе SQL Sever и его аналитических служб). В частности, для создания решений на основе аналитических служб предназначен шаблон Analysis Services Project (рис. 3).
SQL Server 2005 кубы создаются с помощью SQL Server Business Intelligence Development Studio. Этот инструмент представляет собой специальную версию Visual Studio 2005, предназначенную для решения данного класса задач (а при наличии уже установленной среды разработки список шаблонов проектов пополняется проектами, предназначенными для создания решений на основе SQL Sever и его аналитических служб). В частности, для создания решений на основе аналитических служб предназначен шаблон Analysis Services Project (рис. 3).
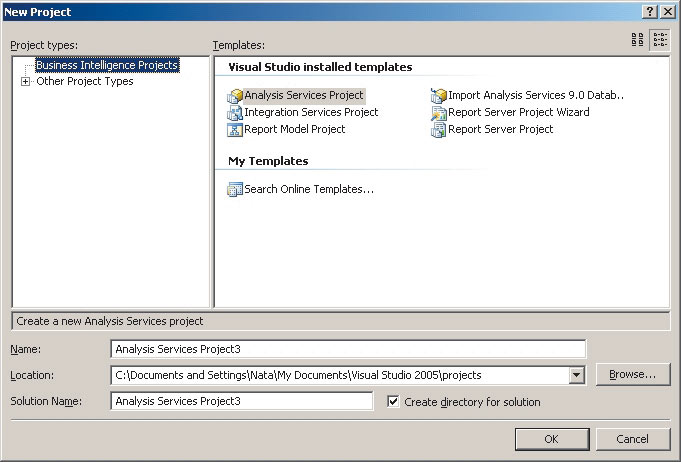
Рис. 3. Шаблоны проектов решений на основе аналитических служб
Для создания OLAP-куба в первую очередь следует решить, на основе каких данных его формировать. Наиболее часто OLAP-кубы строятся на основе реляционных хранилищ данных со схемами «звезда» или «снежинка» (о них мы рассказывали в предыдущей части статьи). В комплекте поставки SQL имеется пример такого хранилища — база данных AdventureWorksDW, для использования которой в качестве источника следует найти в Solution Explorer папку Data Sources, выбрать пункт контекстного меню New Data Source и последовательно ответить на вопросы соответствующего мастера (рис. 4).
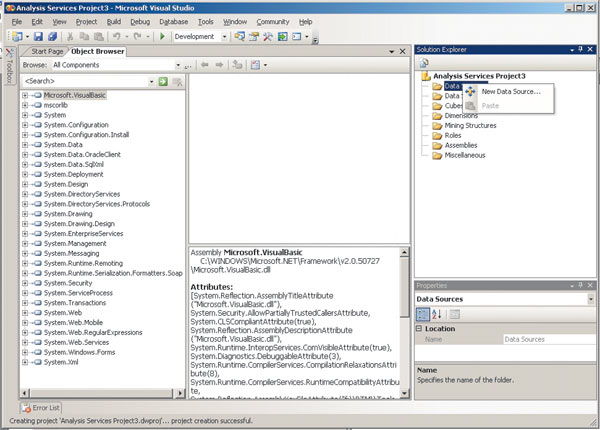
Рис. 4. Новый проект решения на основе аналитических служб
Затем рекомендуется создать Data Source View — представление, на основе которого будет создаваться куб. Для этого необходимо выбрать соответствующий пункт контекстного меню папки Data Source Views и последовательно ответить на вопросы мастера. Результатом указанных действий станет схема данных, с помощью которых будет построено представление источников данных, при этом в полученной схеме вместо исходных можно указать «дружественные» имена таблиц (рис. 5).
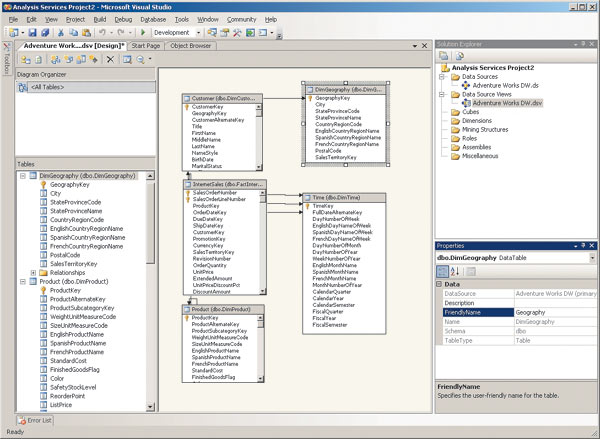
Рис. 5. Представление источников данных
Далее можно приступить к созданию куба, выбрав соответствующий пункт контекстного меню папки Cubes. При ответе на вопросы мастера выбираются измерения, меры, определяются члены иерархий (рис. 6).
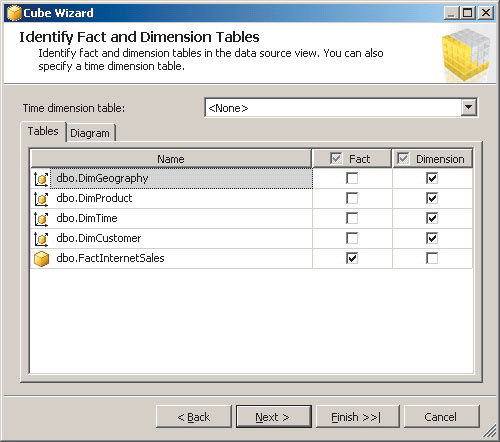
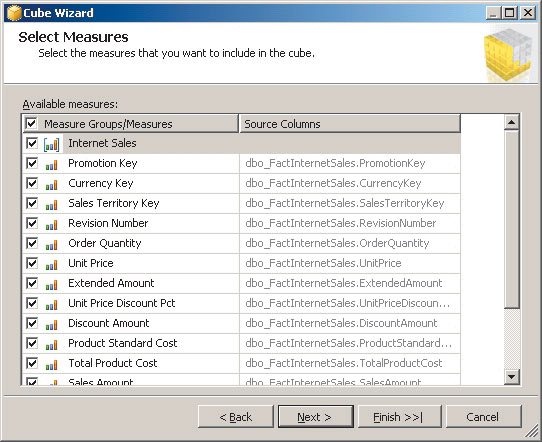
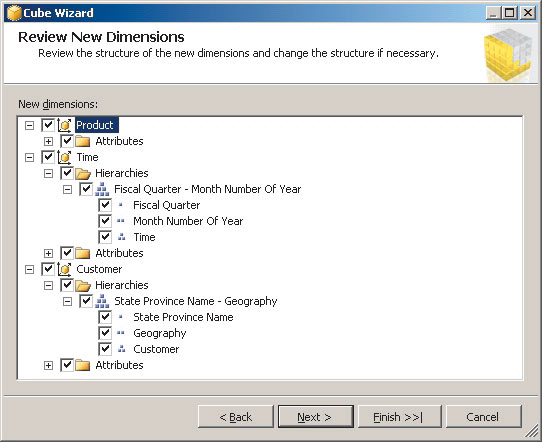
Рис. 6. Создание куба
Описанный таким образом куб можно перенести на сервер аналитических служб, выбрав из контекстного меню проекта опцию Deploy, и осуществить просмотр его данных (рис. 7).
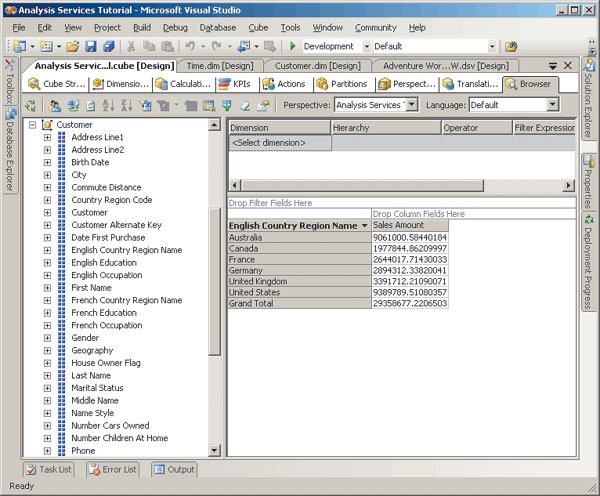
Рис. 7. Просмотр данных куба
При создании кубов в настоящее время используются многие особенности новой версии SQL Server, такие, например, как представление источников данных. Описание исходных данных для построения куба, равно как и описание структуры куба, теперь производится с помощью знакомого многим разработчикам инструмента Visual Studio, что является немалым достоинством новой версии этого продукта — изучение разработчиками аналитических решений нового инструментария в этом случае сведено к минимуму.
Отметим, что в созданном кубе можно менять состав мер, удалять и добавлять атрибуты измерений и добавлять вычисляемые атрибуты членов измерений на основе имеющихся атрибутов (рис. 8).
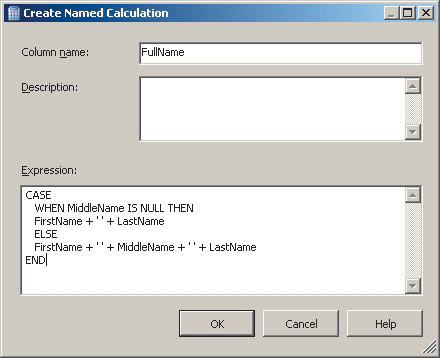
Рис. 8. Добавление вычисляемого атрибута
Кроме того, в кубах SQL Server 2005 можно осуществлять автоматическую группировку или сортировку членов измерения по значению атрибута, определять связи между атрибутами, реализовывать связи «многие ко многим», определять ключевые показатели бизнеса, а также решать многие другие задачи (подробности о том, как выполняются все эти действия, можно найти в разделе SQL Server Analysis Services Tutorial справочной системы данного продукта).
В последующих частях данной публикации мы продолжим знакомство с аналитическими службами SQL Server 2005 и выясним, что нового появилось в области поддержки Data Mining.








