Весенний Форум IDF 2006
Понятие производительности процессора и способы ее увеличения
Энергетическая эффективность процессоров Intel
Преимущества многоядерной архитектуры
Процессорная микроархитектура нового поколения
Схема классического процессора
Intel и Microsoft представили планы совершенствования технологий управления и виртуализации...
7 марта в Сан-Франциско (шт.Калифорния, США) стартовал весенний цикл Форумов Intel для разработчиков (Intel Developer Forum, IDF).
 орум IDF на протяжении уже многих лет проводится дважды в год — весной и осенью, традиционно привлекая к себе пристальное внимание как компьютерной прессы, так и разработчиков аппаратных средств и программного обеспечения. В ходе форума рассматриваются различные вопросы, связанные с передовыми компьютерными технологиями, и продукты, предназначенные для ПК, серверов, коммуникационного оборудования и карманных вычислительных устройств. И если говорить об эпохальных событиях, которые можно рассматривать как поворотную точку в истории развития ИТ-индустрии, то все они так или иначе связаны именно с Форумом IDF.
орум IDF на протяжении уже многих лет проводится дважды в год — весной и осенью, традиционно привлекая к себе пристальное внимание как компьютерной прессы, так и разработчиков аппаратных средств и программного обеспечения. В ходе форума рассматриваются различные вопросы, связанные с передовыми компьютерными технологиями, и продукты, предназначенные для ПК, серверов, коммуникационного оборудования и карманных вычислительных устройств. И если говорить об эпохальных событиях, которые можно рассматривать как поворотную точку в истории развития ИТ-индустрии, то все они так или иначе связаны именно с Форумом IDF.
Значение IDF заключается не только и даже не столько в том, что на нем анонсируются те или иные продукты, сколько в том, что именно этот форум позволяет высветить те векторы развития, в соответствии с которыми пойдет общее развитие компьютерной индустрии в течение ближайших лет. Это и не удивительно, ведь вся история компьютерной индустрии неразрывно связана с именем Intel. Кому, как не Intel — крупнейшей компьютерной корпорации, принимающей непосредственное участие в разработке и внедрении всех новейших компьютерных технологий, — задавать курс развития.
Предугадать, что станет лейтмотивом форума, труда не составляло. Достаточно было отследить события последних месяцев, чтобы понять, что основной акцент на форуме будет сделан на многоядерные процессоры и на новую микроархитектуру процессоров Intel, о которой было объявлено еще на осеннем Форуме IDF 2005 года. И мы не ошиблись в своих прогнозах. На форуме во всех подробностях были обнародованы особенности новой процессорной микроархитектуры Intel, которая в ближайшем будущем станет основой для мобильных, серверных и многоядерных процессоров Intel, и, что немаловажно, было дано достаточно подробное разъяснение причин необходимости перехода на новую микроархитектуру и невозможности дальнейшего развития традиционной архитектуры десктопных и серверных процессоров (архитектура NetBurst).
Но форум, естественно, не ограничился лишь обсуждением новой микроархитектуры. Как и ожидалось, компания Intel объявила свои планы по выпуску мобильных, десктопных и серверных процессоров, обозначила основные тренды в развитие мобильных платформ, платформ для цифрового дома, для корпоративного сегмента рынка и многое другое. В рамках форума было также сделано немало анонсов.
Форум IDF 2006 затронул практически все современные направления развития компьютерной индустрии, и к более подробному рассмотрению многих актуальных тем мы еще будем неоднократно возвращаться на страницах нашего журнала. А в данной статье мы сконцентрируемся главным образом на рассмотрении новой процессорной микроархитектуры, получившей название Intel Core, и детально изучим причины возникновения тупиковой ситуации в развитии традиционной для процессоров Intel микроархитектуры NetBurst.
Понятие производительности процессора и способы ее увеличения
 режде чем переходить к обоснованию того утверждения, что традиционная архитектура десктопных и серверных микропроцессоров исчерпала все свои возможности по наращиванию производительности и не имеет перспектив дальнейшего развития, мы хотим сделать небольшое теоретическое отступление, чтобы дать точное определение того, что называют производительностью процессора, и выяснить, какими способами ее можно увеличивать.
режде чем переходить к обоснованию того утверждения, что традиционная архитектура десктопных и серверных микропроцессоров исчерпала все свои возможности по наращиванию производительности и не имеет перспектив дальнейшего развития, мы хотим сделать небольшое теоретическое отступление, чтобы дать точное определение того, что называют производительностью процессора, и выяснить, какими способами ее можно увеличивать.
Производительность процессора (Performance) принято отождествлять со скоростью выполнения им инструкций программного кода (Instruction Per Second, IPS):
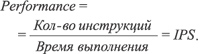
Переписав это выражение в виде произведения количества инструкций, выполняемых за один такт процессора (Instruction Per Clock, IPC), на количество тактов процессора за единицу времени (тактовая частота процессора, F), получаем, что производительность процессора прямо пропорциональна его тактовой частоте:

Количество инструкций, выполняемых за такт, зависит и от микроархитектуры процессора, и от напряжения питания, и от технологии производства, определяющей минимальные размеры используемых транзисторов, их быстродействие и время задержки передачи сигнала в межуровневых соединениях.
Как видим, производительность процессора прямо пропорциональная как тактовой частоте, так и количеству инструкций, выполняемых за один такт. Из этой формулы также следует, что существует два принципиальных подхода к увеличению производительности процессора: первый из них заключается в увеличении тактовой частоты, а второй — в увеличении IPC.
Естественно, что на практике, как правило, одновременно реализуются оба подхода, то есть производительность процессора увеличивается как за счет масштабирования тактовой частоты, так и за счет увеличения IPC. Вопрос лишь в том, какой из двух подходов является доминирующим.
Если вспомнить историю развития десктопных процессоров Intel, становится понятно, что до недавнего времени доминирующим средством увеличения производительности процессора являлось масштабирование тактовой частоты. Производительность процессоров буквально отождествлялась с их тактовой частотой, а сама микроархитектура процессора создавалась с таким расчетом, чтобы обеспечить максимально возможное масштабирование тактовой частоты. Например, микроархитектура NetBurst с гипердлинным конвейером, положенная в основу процессоров семейства Pentium 4, изначально разрабатывалась под возможность наращивания тактовой частоты. В результате за пять лет существования процессоров семейства Pentium 4 их тактовая частота была увеличена более чем в три раза — стартовав с отметки чуть больше 1 ГГц, за пять лет тактовая частота достигла значения 3,8 ГГц. Конечно, увеличение тактовой частоты — это далеко не единственное нововведение, которое сопутствовало появлению новых процессоров семейства Intel Pentium 4. В то же время можно сказать, что для процессора Pentium 4, как, впрочем, и для процессоров всех предыдущих поколений, повышение тактовой частоты являлось одним из основных способов увеличения его производительности.
Казалось бы, если масштабирование тактовой частоты представляет собой вполне эффективное средство для увеличения производительности процессоров, то что мешает разработчикам двигаться в том же направлении и дальше? Почему уже сейчас можно говорить о том, что наращивание тактовой частоты процессоров в качестве доминирующего способа увеличения производительности — это тупиковый путь?
Дело в том, что увеличение тактовой частоты процессора приводит к росту его энергопотребления и, как следствие, к повышению тепловыделения процессора.
Еще в относительно благополучном в плане тепловыделения 2001 году Патрик Гелсингер, бывший в то время главным директором корпорации Intel по технологиям, заметил: «Если мы будем продолжать использовать современные методы разработки процессоров, то к 2010 году процессоры будут вырабатывать больше тепла на квадратный миллиметр, чем ядерный реактор».
Зависимость потребляемой процессором мощности от его тактовой частоты можно выразить следующей формулой:
Power ~ CU2F,
то есть мощность, потребляемая процессором, прямо пропорциональна тактовой частоте, квадрату напряжения питания процессора и его динамической емкости. С учетом того, что сама тактовая частота зависит в том числе и от напряжения питания процессора, получаем, что потребляемая мощность нелинейным образом зависит от частоты процессора.
Для убедительности демонстрации ограниченных возможностей по масштабированию тактовой частоты процессоров Intel с целью увеличения их производительности Джастин Раттнер (Justin Rattner), главный директор Intel по технологиям, в своем докладе на IDF привел следующий пример. Эмпирическим путем установлено, что при увеличении (разгоне) тактовой частоты процессора на 20% его производительность возрастает на 13%. Дело в том, что, несмотря на теоретическую прямолинейную зависимость производительности процессора от его тактовой частоты, в реальности эта зависимость не является в строгом смысле пропорциональной. При этом потребляемая процессором мощность возрастает на 73%! При уменьшении тактовой частоты процессора на 20% производительность снижается на 13%, а потребляемая мощность — на 49%! Приведенный пример наглядно демонстрирует, что увеличение тактовой частоты процессора приводит к явному дисбалансу между приростом производительности у потребляемой мощности.
Прежде чем продолжить разговор об энергопотреблении процессоров, следует дать небольшой комментарий. Цифры, приведенные компанией Intel в качестве примера, довольно спорны и скорее носят чисто рекламный характер, нежели отражают действительность. К примеру, если речь идет именно о разгоне тактовой частоты, то совершенно непонятно, почему 20-процентному росту тактовой частоты соответствует 73-процентный рост потребляемой мощности. Ведь при разгоне частоты вовсе не обязательно увеличивать напряжение питания. Ну а если разгон производится при одновременном увеличении и напряжения, и тактовой частоты, то хорошо бы пояснить, на сколько процентов увеличивается при этом напряжение. Кроме того, прирост производительности в 13%, соответствующий росту тактовой частоты на 20%, также, на наш взгляд, несколько занижен. Ведь при разгоне меняется не только частота процессора, но и частота работы памяти. Поэтому в реальности наблюдаемый прирост производительности при разгоне процессора зависит от типа приложения, но в любом случае он окажется несколько выше 13%.
Intel и Microsoft представили планы совершенствования технологий управления и виртуализации7 марта на Форуме IDF 2006 представители корпораций Intel и Microsoft объявили о своем намерении интегрировать технологии управления вычислительными сетями и объединить усилия с целью совершенствования перспективной технологии виртуализации, которая предоставит компаниям новые возможности и поможет сократить расходы. Стремясь предложить уникальные средства управления системами широкой аудитории пользователей решения Microsoft Systems Management Server 2003 (SMS), корпорация Intel планирует интегрировать с ним свою новую технологию Intel Active Management (Intel AMT), что позволит надежнее защищать компьютеры от вирусов и значительно снизит расходы на обслуживание систем. Кроме того, корпорации Intel и Microsoft приняли решение объединить свои усилия для включения в технологию Intel Virtualization Technology (Intel VT) аппаратной поддержки назначения устройств ввода-вывода для виртуальных машин на серверах и уже опубликовали новую спецификацию под названием Intel Virtualization for Directed I/O (Intel VT-d). Входящая в семейство технологий Intel VT технология Intel VT-d повышает надежность, гибкость и эффективность ввода-вывода в виртуальных средах. Сотрудничество Microsoft и Intel в ходе разработки этой спецификации должно обеспечить пользователям оптимальную функциональность. Intel представила технологии, которые сделают Интернет более персональным и мобильнымВ рамках Форума IDF 2006 исполнительный вице-президент корпорации Intel Шон Мэлоуни (Sean Maloney) рассказал о планах корпорации Intel по развитию мобильных технологий и анонсировал ряд важных инноваций в области мобильных устройств и широкополосного беспроводного доступа. Отмечая постоянно растущий спрос со стороны потребителей и предприятий на мобильное использование Интернет-приложений, Мэлоуни впервые обнародовал информацию о платформе на базе нового поколения технологии Intel Centrino для мобильных ПК, о коммуникационном продукте с интеграцией поддержки Wi-Fi и WiMAX на одной микросхеме и о PCMCIA-картах с поддержкой мобильной версии стандарта WiMAX, которые будут выпускаться под торговой маркой Intel. В своем выступлении г-н Мэлоуни впервые подробно рассказал о новом поколении технологии Intel Centrino для мобильных ПК под кодовым названием Santa Rosa. Новая технология обеспечит более высокую общую производительность и улучшенные возможности для работы с графикой, предоставит более совершенные средства беспроводной связи, а также более высокий уровень безопасности и удобства управления. В состав технологии Santa Rosa войдут более мощный мобильный процессор, набор микросхем с улучшенными графическими возможностями под кодовым названием Crestline, а также адаптер Wi-Fi стандарта IEEE 802.11n под кодовым названием Kedron и оптимизированные решения для управления системой и обеспечения безопасности. Также эта платформа будет содержать ускоритель на базе флэш-памяти Intel класса NAND под кодовым названием Robson, который позволит заметно сократить время загрузки и обеспечит более экономичное энергопотребление. В системах на базе технологии под кодовым названием Santa Rosa, которые появятся в первой половине 2007 года, будут использоваться двухъядерные мобильные процессоры Intel нового поколения под кодовым названием Merom на базе микроархитектуры Intel Core. Начальная версия процессора Merom также войдет в состав текущей платформы Intel Centrino Duo и будет совместима на уровне разъема (контактов) с существующими процессорами Intel Core Duo. Корпорация Intel представила семейство прикладных процессоров нового поколения для карманных устройств под кодовым названием Monahans, образцы которых уже поставляются производителям. Платформа Monahans построена на базе третьего поколения технологии Intel XScale и поддерживает конструктивные решения, обеспечивающие разные уровни производительности, энергопотребления и интеграции для карманных ПК, смартфонов и устройств бытовой электроники. Г-н Мэлоуни рассказал о технологиях, входящих в платформу Monahans, в том числе Wireless Intel SpeedStep with MusicMax, Intel Wireless MMX2 и Intel VideoMax. Все эти технологии способны обеспечить значительное снижение энергопотребления и повышение производительности карманных устройств при воспроизведении звука и видео. Кроме того, г-н Мэлоуни представил Ultra Mobile PC (UMPC) — новую категорию мобильных устройств малых формфакторов. Он рассказал о работе корпорации в области разработки платформ для таких ультрамобильных ПК и отметил расширение экосистемы разработчиков приложений и поставщиков услуг, с которыми Intel сотрудничает в этой области. Крупные ОЕМ-производители начнут выпускать первые ультрамобильные ПК на базе компонентов Intel уже в I квартале текущего года. Ждать выпуска платформ Intel следующего поколения осталось недолгоВ рамках Форума IDF 2006 Патрик Гелсингер (Pat Gelsinger), старший вице-президент корпорации Intel и генеральный менеджер ее отделения Digital Enterprise Group, рассказал о том, как корпорация Intel собирается улучшить в 2006 году производительность и экономичность своих систем, содействуя при этом компаниям в снижении совокупной стоимости владения IT-решениями. К концу этого года на базе микроархитектуры Intel Core будут разработаны платформы для ПК и серверов. Кроме того, г-н Гелсингер объявил, что процессор Conroe войдет в состав профессиональной бизнес-платформы Intel (кодовое наименование Averill), которая будет выпущена во второй половине 2006 года. Платформа Averill обеспечит компаниям передовые средства защиты и администрирования IT-систем, основанные на комбинации двухъядерного процессора Conroe, нового набора микросхем под кодовым наименованием Broadwater, технологии Intel Virtualization Technology и технологии Intel Active Management Technology второго поколения. Что касается двухпроцессорных серверов и рабочих станций, то в 2006 году корпорация Intel выпустит три новых процессора для этого сегмента рынка. Поставки процессоров Sossaman со сверхнизким энергопотреблением, ориентированных на создание blade-серверов, систем хранения данных и телекоммуникационных устройств, начнутся уже совсем скоро. Процессор Dempsey — первый двухъядерный процессор Intel Xeon для новой платформы с кодовым наименованием Bensley — также будет выпущен в ближайшее время. Потребляющая в большинстве конфигураций менее 100 Вт энергии, платформа Bensley будет отличаться наилучшим соотношением производительности и энергопотребления. В III квартале 2006 года корпорация Intel обновит платформу Bensley, интегрировав в нее процессор под кодовым наименованием Woodcrest, который будет потреблять еще на 35% меньше энергии, обеспечивая при этом более чем 80-процентное повышение производительности. Рассказывая о ближайших планах корпорации Intel в отношении разработки передовых многоядерных процессоров, г-н Гелсингер также впервые представил информацию о четырехъядерном процессоре под кодовым наименованием Clovertown для двухпроцессорных серверов. Запуск процессора Clovertown, который будет механически совместим с платформой Bensley, запланирован на начало 2007 года. Обладая повышенной вычислительной мощностью, он будет идеально соответствовать требованиям многопоточных приложений, таких как СУБД, финансовые решения и системы управления цепочкой поставок. Также в начале 2007 года корпорация Intel планирует выпустить четырехъядерный процессор для настольных ПК высшего класса под кодовым наименованием Kentsfield. Программа Tera-Scale Computing ResearchВ рамках Форума IDF корпорация Intel представила программу Tera-Scale Computing Research — крупный проект сообщества исследователей корпорации Intel, нацеленный на разработку компьютерных платформ будущего, которые по возможностям многократно превзойдут современные компьютеры. Программа Tera-Scale Computing Research объединит сотни ученых и инженеров, работающих над более чем 80 связанными проектами в исследовательских лабораториях Intel по всему миру. Эта программа охватывает широкий диапазон исследовательских областей, в том числе разработку полупроводниковых решений и платформенных технологий, а также развитие многопоточного ПО с целью создания в течение следующего десятилетия компьютерных систем, основанных на процессорах с десятками и даже сотнями вычислительных ядер. «Шанс предложить миллионам людей преимущества компьютеров с принципиально улучшенными возможностями, таких как этот, предоставляется один раз в поколение, — отметил Джастин Раттнер (Justin Rattner), главный директор корпорации Intel по технологиям. — Потенциал этой программы позволяет рассчитывать на появление совершенно новых типов систем и приложений, которые, в частности, будут обладать возможностями, в какой-то степени присущими человеку». Существенной частью программы Tera-Scale Computing Research станет анализ требований, которые люди будут предъявлять к персональным компьютерам и серверам в следующем десятилетии. Таким образом, анализ будущих прикладных задач или «рабочих нагрузок» компьютеров будет играть важную роль при выборе направлений проведения исследований. Объявлены лауреаты второго конкурса Technology Innovation Accelerated AwardsГлавную награду на втором конкурсе Technology Innovation Accelerated Awards, организованном в рамках Форума IDF, получило разработанное компанией Matrox Graphics решение TripleHead2Go, посредством которого можно подключить несколько мониторов к одной видеокарте. Решение TripleHead2Go, разработанное компанией Matrox Graphics, представляет собой устройство размером с ладонь, которое позволяет подключить к компьютеру три 19-дюймовых монитора с общим разрешением 3840Ѕ1024 пиксела. Это решение, удостоенное главной награды в категории «Цифровой дом», а также признанное лучшим в рамках данного конкурса (Best of Show), обеспечивает поддержку трех мониторов в системе с единственным видеовыходом. В качестве инновационной была отмечена его возможность погружения в виртуальную реальность на 45-дюймовом экране во время игр, а кроме того, он был признан идеальным решением для дома и работы в дизайнерской студии. К конкурсу допускались все компании, участвовавшие в американском IDF, включая спонсоров (кроме самой Intel). Всего было подано более 45 заявок — это примерно вдвое больше, чем на первом конкурсе, проходившем в августе прошлого года. |
||
Впрочем, оставим приведенные цифры на совести компании Intel. В конечном счете они вполне адекватно отражают суть: увеличение тактовой частоты процессора (причем речь идет не о разгоне в домашних условиях, а о выпуске новых моделей процессоров с более высокими тактовыми частотами) приводит к нелинейному росту потребляемой мощности.
Последние версии процессоров Intel на архитектуре NetBurst достигают уровня энергопотребления в 130 Вт, и это привело к тому, что проблема энергопотребления стала одной из важнейших для дизайна современных процессоров. Основная задача, которая ставится при конструировании современных процессоров, — обеспечивать не просто максимально возможную производительность любой ценой, а максимально возможный уровень производительности при заданном уровне энергопотребления. В связи с этим компания Intel даже ввела в обиход новый термин — энергетическая эффективность процессора.
Энергетическая эффективность процессоров Intel
 сли абсолютную производительность процессора принято измерять в количестве программных инструкций, выполняемых за единицу времени (Instruction Per Second, IPS), то энергетическая эффективность процессоров может характеризоваться величиной, численно равной среднему количеству поглощенной энергии, приходящейся на одну выполненную инструкцию (Energy Per Instruction, EPI). EPI измеряется в джоулях (Дж) и определяется как:
сли абсолютную производительность процессора принято измерять в количестве программных инструкций, выполняемых за единицу времени (Instruction Per Second, IPS), то энергетическая эффективность процессоров может характеризоваться величиной, численно равной среднему количеству поглощенной энергии, приходящейся на одну выполненную инструкцию (Energy Per Instruction, EPI). EPI измеряется в джоулях (Дж) и определяется как:
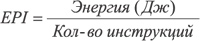 .
.
EPI нетрудно связать и с другой часто используемой характеристикой энергетической эффективности процессора, иногда называемой оптимизированной производительностью процессора и определяемой как производительность процессора в расчете на каждый ватт потребляемой мощности (Performance Per Watt):
 .
.
Таким образом, энергетическую эффективность процессора EPI можно трактовать как потребляемую мощность в расчете на единицу производительности, если последняя измеряется в количестве исполняемых в единицу времени инструкций.
Как видно из приведенной формулы, количество поглощенной энергии, приходящейся на одну выполненную инструкцию (EPI), есть величина, обратная производительности процессора в расчете на каждый ватт потребляемой мощности (IPS/Power).
Энергетическая эффективность процессора, равно как и оптимизированная производительность, зависит от отношения двух величин: скорости выполнения процессором инструкций и скорости поглощения энергии. При этом ни энергетическая эффективность процессора, ни оптимизированная производительность не зависят от времени выполнения инструкций (латентности). Именно поэтому и EPI, и IPS/Power являются удобными величинами для оценки энергетической эффективности процессора в условиях, когда основным критерием для сравнения процессоров является производительность в заданном диапазоне энергопотребления.
Для того чтобы понять, от чего зависит энергетическая эффективность процессора EPI, удобно рассматривать процессор как некий конденсатор, который периодически заряжается и разряжается по мере выполнения им программных инструкций. Как известно из школьного курса физики, при зарядке конденсатор запасает энергию, которую можно представить в виде следующего выражения:
![]()
Именно эту формулу можно применить и к воображаемому процессору, если понимать под E средний расход энергии на выполнение одной инструкции; под C — суммарную емкость процессора, возникающую при периодической зарядке-разрядке в ходе выполнения им инструкции (динамическая емкость процессора); под U — напряжение питания.
При рассмотрении данной емкостной модели процессора EPI зависит только от двух факторов: суммарной динамической емкости процессора при выполнении инструкции и приложенного напряжения. Отметим, что рассматриваемая нами емкостная модель процессора учитывает только потребляемую процессором мощность при его переключениях (динамическое потребление мощности). Более точный анализ должен учитывать как динамическое потребление мощности, так и статическое, вызываемое возникающими токами утечки в транзисторах.
При рассмотрении энергетической эффективности реального процессора (в отличие от рассмотренной выше упрощенной емкостной модели) EPI зависит от таких факторов, как дизайн процессора, технологический процесс производства и напряжение питания.
Дизайн процессора в конечном счете отражается на его емкостных характеристиках, а технологический процесс производства определяет как емкость процессора, так и диапазон рабочих напряжений. Переход с одного технологического процесса производства на другой, более совершенный (что сопровождается уменьшением размеров транзисторов), снижает как динамическую емкость процессора, так и рабочее напряжение.
В то же время при переходе на новый технологический процесс производства увеличивается и плотность размещения транзисторов на кристалле, и их суммарное количество, что можно рассматривать, как изменение дизайна процессора. Увеличение числа транзисторов внутри процессора, в свою очередь, приводит к росту суммарной емкости процессора. Таким образом, если уменьшение проектной нормы производства процессоров приводит к сокращению емкости, то изменение дизайна процессора, связанное с увеличением общего числа транзисторов на кристалле, наоборот, к возрастанию суммарной емкости процессора.
Итак, на энергетическую эффективность процессора одновременно влияют и дизайн процессора, и технологический процесс производства, и напряжение питания. Для того чтобы определить степень влияния каждой из указанных характеристик на EPI, необходимо рассмотреть их изолированное влияние, то есть, к примеру, зафиксировать напряжение питания и технологический процесс производства и посмотреть, как отражается дизайн процессора на его энергетической эффективности. Однако в реальности такой анализ нереализуем, поскольку процессоры различных поколений имеют индивидуальный дизайн, изготовлены по разному техпроцессу и требуют различного напряжения питания. Единственная возможность произвести такой анализ — рассматривать не реальные, а воображаемые процессоры. К примеру, чтобы определить влияние именно дизайна процессора на его энергетическую эффективность, необходимо рассматривать воображаемые процессоры, как если бы все они были изготовлены по одному и тому же техпроцессу и работали бы при одном и том же напряжении питания.
Продемонстрируем на конкретных примерах, каким образом можно выделить вклад в EPI, обусловленный дизайном процессора. Рассмотрим, к примеру, процессоры Intel Pentium и Intel Pentium Pro, которые выпускались еще в 1995 году. Оба процессора производились по одному и тому же технологическому процессу 0,6 мкм, поэтому вклад в EPI, вызванный техпроцессом производства, в этих процессорах одинаковый. Процессор Pentium Pro работает на тактовой частоте 150 МГц; в тесте SpecInt95 демонстрирует результат 6,08; имеет энергопотребление 29,2 Вт при напряжении питания 3,1 В.
Процессор Pentium работает на тактовой частоте 100 МГц и имеет энергопотребление 10,1 Вт при напряжении питания 3,3 В, а в тесте SpecInt95 демонстрирует результат 3,33. Отметим, что более высокая тактовая частота процессора Pentium Pro обусловлена иной микроархитектурой процессора с более длинным конвейером.
Как видим, эти процессоры имеют разные напряжения. Поскольку мы хотим сравнить эти процессоры по EPI, обусловленному именно дизайном процессора, нам необходимо прежде всего привести их к одному уровню рабочего напряжения. Поскольку мощность, потребляемая процессором, пропорциональна квадрату напряжения питания, то если при напряжении 3,1 В процессор Pentium Pro потребляет 29,2 Вт, то при напряжении 3,3 В он будет потреблять уже 29,2·(3,3/3,1)2 = 33,1 Вт. Таким образом, энергопотребление процессора Pentium Pro окажется в 3,28 раза выше (33,1 Вт/10,1 Вт), чем у процессора Pentium.
В тесте SpecInt95 процессор Pentium Pro демонстрирует результат в 1,8 раза более высокий (6,08/3,33=1,8), чем процессор Pentium, и значит, можно говорить о том, что производительность Pentium Pro в 1,8 раза выше производительности Pentium.
Если же сравнить эти процессоры по эффективности энергопотребления EPI, то достаточно разделить отношение энергопотреблений сравниваемых процессоров на отношение их производительностей, то есть:
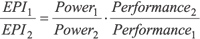 .
.
При этом в нашем случае для процессора Pentium Pro значение EPI в 1,8 раза выше (3,28/1,8=1,8), чем для процессора Pentium.
Еще раз подчеркнем, что приведенное сравнение процессоров справедливо только в случае одного и того же технологического процесса производства процессоров при одном и том же рабочем напряжении, что позволяет акцентировать внимание на сравнении EPI процессоров, обусловленных именно дизайном процессоров.
Аналогичный анализ может быть проделан и для процессоров, приведенных в табл. 1.
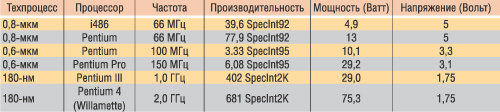
Таблица 1. Производительность и потребляемая мощность процессоров Intel
с проектными нормами производства 0,8, 0,6 и 0,18 мкм
При упрощенном анализе аналогичным алгоритмом можно воспользоваться и при сравнении друг с другом процессоров, выполненных по разным техпроцессам, но при условии, что техпроцессы различаются не более чем на одно поколение (например, процессоры, выполненные по 0,6- и 0,8-мкм техпроцессу). Однако при сравнении друг с другом процессоров, выполненных по техпроцессам, различающимся более чем на два поколения, данная схема сравнения уже не подойдет. В этом случае можно воспользоваться алгоритмом с использованием результатов промежуточного процессора. К примеру, при сравнении процессоров Pentium Pro и i486 первоначально находятся соотношения потребляемых мощностей и производительностей для процессоров Pentium Pro и Pentium, а затем — для процессоров Pentium и i486. В итоге с применением промежуточного сравнения можно сопоставить EPI процессоров Pentium Pro и i486.
Для сравнения друг с другом процессоров более поздних моделей (табл. 2) используется несколько иной подход. Дело в том, что микроархитектура процессора Pentium 4 претерпела существенное изменение при переходе с 130- на 90-нанометровый технологический процесс производства. Поэтому для корректного сравнения вклада в EPI, обусловленного дизайном процессоров, при сопоставлении энергопотребления процессоров необходимо ввести поправочный коэффициент, определяемый эмпирическим методом. Так, для сравнения процессоров, выполненных по 130- и 90-нм техпроцессу, применяется поправочный коэффициент 0,7.
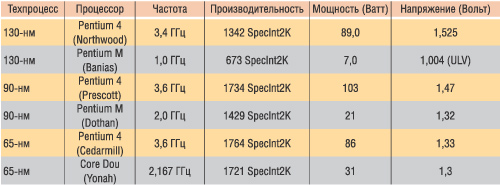
Таблица 2. Производительность и потребляемая мощность процессоров Intel с проектными нормами производства 130, 90 и 65 нм
Производительность всех процессоров, указанных в табл. 2, рассчитывается на основании одного и того же теста SpecInt2K, поэтому можно сопоставить производительность процессоров друг с другом.
Сравнивая друг с другом производительность и энергопотребление процессоров Intel различных поколений, можно получить график, показанный на рис. 1.
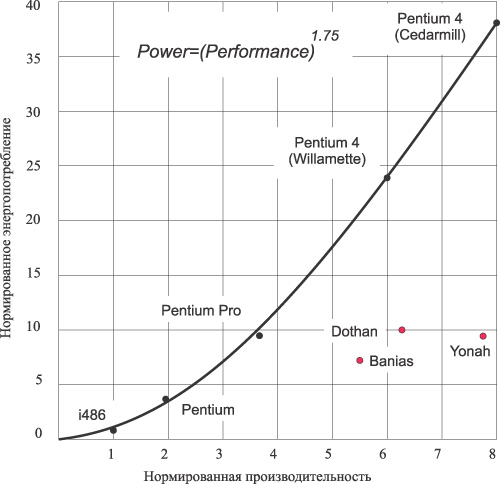
Рис. 1. Зависимость нормированного энергопотребления от нормированной производительности процессоров Intel
В графике на рис. 1 используются данные, нормированные относительно мощности и производительности процессора i486, а для того, чтобы оценить влияние именно дизайна процессоров на потребляемую мощность и производительность, при сравнении производительности и потребляемой мощности применяются алгоритмы, описанные выше. То есть при сравнении процессоров используются не реальные, а некие воображаемые процессоры, как если бы все они были изготовлены по одному и тому же техпроцессу и имели бы одно и то же напряжение питания.
Аппроксимируя данные, приведенные на рис. 1, можно получить эмпирический закон зависимости потребляемой мощности от производительности процессора:
Power ~ (Performance)1,75
Данный закон справедлив для десктопных процессоров различных поколений. В то же время мобильные процессоры семейства Pentium M (Banias, Dothan) и Core Duo (Yonah) не могут быть описаны этим эмпирическим законом.
Приведенный график зависимости нормированного энергопотребления от нормированной производительности процессоров позволяет сравнивать энергетическую эффективность EPI у различных процессоров. Для расчета абсолютного значения EPI, как уже отмечалось, необходимо знать не только потребляемую мощность, но и количество инструкций, выполняемых процессором в единицу времени (IPS), или количество инструкций, выполняемых процессором за один такт (IPC). Тогда
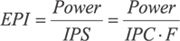 .
.
К примеру, в тесте SpecInt2K для процессора Pentium 4 (Cedarmill) значение IPC составляет приблизительно 0,5. Поскольку данный процессор работает на тактовой частоте 3,6 ГГц, а его потребляемая мощность равна 86 Вт, то значение EPI для этого процессора составит:
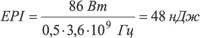 .
.
Значения EPI для всех остальных процессоров можно рассчитать, основываясь на их нормированной по отношению к процессору Pentium 4 (Cedarmill) производительности и потребляемой мощности:
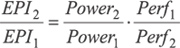 .
.
В этом случае мы получим значения EPI процессоров, как если бы все они работали при напряжении 1,33 В и были бы выполнены по 65-нм техпроцессу. Результаты сравнения EPI приведены в табл. 3.
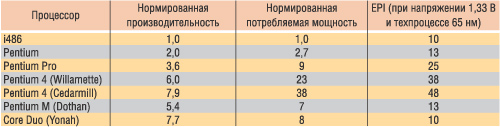
Таблица 3. Сравнение процессоров различных поколений по EPI
Попробуем проанализировать приведенные данные. Как видно из рис. 1 и табл. 3, в случае десктопных процессоров наблюдается явный дисбаланс между ростом производительности и увеличением потребляемой мощности. При восьмикратном увеличении производительности процессор Pentium 4 (Cedarmill) потребляет в 38 раз больше энергии в сравнении с процессором i486. Если бы и процессор Pentium 4 (Cedarmill), и процессор i486 изготавливались по одному техпроцессу и имели одно и то же напряжение питания, то оказалось бы, что процессор Pentium 4 (Cedarmill) тратит в пять раз больше энергии на обработку каждой инструкции в сравнении с процессором i486.
Интересно отметить, что данная нелинейная зависимость между потребляемой мощностью и производительностью процессора была впервые подмечена Фредом Поллаком (Fred Pollack) еще в 1999 году, то есть еще до внедрения архитектуры NetBurst. Остается лишь спросить у компании Intel: если с самого начала все было известно, зачем вообще понадобилось разрабатывать архитектуру NetBurst, у которой изначально не было будущего? Скорее всего, ответ на этот вопрос достаточно прост: восемь лет назад, когда проблема энергопотребления процессоров не стояла на повестке дня столь остро, как сейчас, было проще убедить всех вокруг в том, что будущее — за тактовой частотой, и не заниматься разработкой новой архитектуры. Вспомните маркетинговые заявления о том, что недалек тот день, когда тактовая частота процессоров будет измеряться десятками гигагерц. Мечты остались метами, а то, что должно было случиться, случилось. И сейчас о тактовой частоте процессоров как о средстве увеличения производительности уже никто не говорит.
Причина нелинейной зависимости между потребляемой мощностью и производительностью десктопных процессоров заключается в том, что сам дизайн процессоров изначально ориентирован на достижение максимальной производительности любой ценой. Под «любой ценой» в данном случае подразумевается высокая динамическая емкость десктопных процессоров, в результате чего такие процессоры потребляют довольно много энергии для обработки каждой инструкции. Длинный конвейер, сложная структура блока внеочередного исполнения команд, спекулятивный характер обработки команд и многое другое — все это в конечном счете не может не привести к высокому значению EPI.
В полную противоположность десктопным процессорам мобильные процессоры имеют существенно меньшее значение EPI. Это достигается за счет использования меньшего по длине конвейера, оптимизированного по своим размерам блока внеочередного исполнения команд, улучшенного алгоритма слияния микроопераций (micro-op fusion) и т.д. Процессоры семейства Pentium M и Core Duo достигают высокой производительности, выполняя больше операций на каждом такте процессора. Наглядно это можно продемонстрировать, сравнивая по производительности процессоры Pentium M 2,0 ГГц (Dothan) и Pentium 4 3,4 ГГц (Northwood) в тесте SpecInt2K. Нормированная на тактовую частоту (отношение результата теста к тактовой частоте процессора или производительность, приходящаяся на единицу тактовой частоты), производительность процессора Pentium M оказывается в 1,8 раза выше, чем нормированная производительность процессора Pentium 4. Это означает, что за каждый такт процессор Pentium M выполняет в 1,8 раза больше работы, чем процессор Pentium 4.
Если же сравнить процессоры Core Duo (Yonah) и i486, то выяснится, что каждое ядро процессора Yonah в 8 раз производительнее, чем процессор i486. При этом энергопотребление каждого ядра процессора Yonah всего в 7,7 раза превосходит энергопотребление процессора i486. В результате процессор Yonah имеет такую же энергетическую эффективность (EPI), как и процессор i486. Таким образом, несмотря на восьмикратное превосходство по производительности, энергия, потребляемая процессором Yonah при обработке каждой инструкции, примерно такая же, как и энергия, потребляемая процессором i486.
Подытоживая вышеизложенное, еще раз отметим концептуальную разницу между традиционными десктопными и мобильными процессорами.
Архитектура современных десктопных процессоров ориентирована на достижение максимальной производительности любой ценой (читай — за счет увеличения тактовой частоты). Архитектура современных мобильных процессоров ориентирована на достижение максимальной производительности в заданных рамках энергопотребления. В данном случае доминирующим средством увеличения производительности является не рост тактовой частоты, а рост IPC, поскольку именно технология увеличения IPC позволяет создавать процессоры с меньшим значением EPI.
С учетом того, что энергопотребление десктопных процессоров сегодня уже достигло своего критического значения, дальнейший рост их производительности в рамках существующей архитектуры просто невозможен. Можно говорить, что архитектура NetBurst полностью исчерпала свои потенциальные возможности, создав, без преувеличения, тупиковую ситуацию в дальнейшем развитии процессоров.
Выходом из сложившейся ситуации может стать переход к многоядерным процессорам и новой микроархитектуре процессоров, которая обеспечит рост производительности не за счет масштабирования тактовой частоты, а за счет увеличения количества инструкций, выполняемых процессором за один такт (IPC).
Преимущества многоядерной архитектуры
 вухъядерные процессоры Intel, основанные на архитектуре NetBurst, позволяют (но только частично) решить проблему снижения энергопотребления. Дело в том, что при переходе от одноядерной архитектуры процессора к двухъядерной можно сохранить прежний уровень производительности, но при снижении частоты каждого из ядер почти вдвое (рис. 2). В реальности, конечно, все несколько сложнее и результат будет во многом зависеть от используемого приложения и от его оптимизации к двухъядерному процессору.
вухъядерные процессоры Intel, основанные на архитектуре NetBurst, позволяют (но только частично) решить проблему снижения энергопотребления. Дело в том, что при переходе от одноядерной архитектуры процессора к двухъядерной можно сохранить прежний уровень производительности, но при снижении частоты каждого из ядер почти вдвое (рис. 2). В реальности, конечно, все несколько сложнее и результат будет во многом зависеть от используемого приложения и от его оптимизации к двухъядерному процессору.
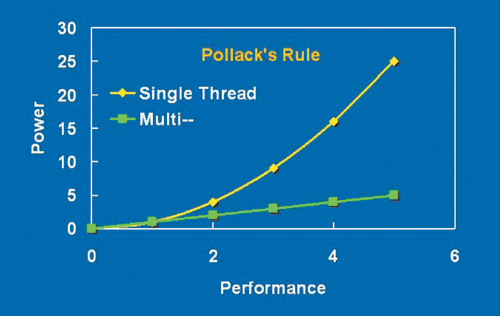
Рис. 2. Сравнение энергопотребления при одинаковой производительности одноядерного
и двухъядерного процессоров
Можно рассуждать иначе. Если принять частоту, производительность и потребляемую мощность одноядерного процессора за единицу, то при снижении напряжения питания и частоты процессора на 15% и одновременном переходе к двухъядерному процессору можно обеспечить увеличение производительности в 1,8 раза при неизменной потребляемой мощности (рис. 3). Однако еще раз подчеркнем, что речь идет об идеализированной ситуации, когда каждое ядро процессора удваивает его производительность, чего на практике не встречается.

Рис. 3. Преимущество двухъядерной архитектуры процессора
Как мы уже отмечали, переход к двухъядерной архитектуре в рамках существующей микроархитектуры каждого ядра процессора позволяет лишь частично решить проблему энергопотребления, поскольку сама по себе микроархитектура каждого ядра процессора оптимизирована под масштабирование тактовой частоты.
Другим способом повышения производительности в рамках заданного энергопотребления является переход на принципиально иную микроархитектуру ядра. Отметим, что данный способ не противоречит, а скорее дополняет идею многоядерности.
Процессорная микроархитектура нового поколения
 аконец, после столь длительного вступления, пришла пора рассказать о главном событии IDF 2006 — объявлении процессорной микроархитектуры следующего поколения — Intel Core.
аконец, после столь длительного вступления, пришла пора рассказать о главном событии IDF 2006 — объявлении процессорной микроархитектуры следующего поколения — Intel Core.
Напомним, что впервые о новой микроархитектуре было объявлено еще на осеннем Форуме IDF 2005. Тогда эта микроархитектура была известна под кодовым названием Next Generation Power-Optimized Microarchitecture (оптимизированная микроархитектура следующего поколения).
Прежде чем приступить к рассмотрению особенностей микроархитектуры Intel Core, напомним основные принципы работы процессоров на основе конструктивной схемы простейшего гипотетического процессора.
Схема классического процессора
В основе архитектуры любого процессора лежит несколько конструктивных элементов: кэш команд и данных, предпроцессор (Front End) и постпроцессор, который также называется блоком исполнения команд (Execution Engine).
Процесс обработки данных состоит из нескольких характерных этапов. Прежде всего программные инструкции выбираются из кэша процессора (как правило, он разделен на кэш данных и кэш инструкций). Эта процедура называется выборкой. Затем выбранные из кэша инструкции декодируются в понятные для данного процессора примитивы (машинные команды). Название этой процедуры соответствующее — декодирование. Далее декодированные команды поступают на исполнительные блоки процессора, выполняются, а результат записывается в оперативную память.
Процесс выборки инструкций из кэша, их декодирование и продвижение к исполнительным блокам осуществляются в предпроцессоре, а процесс выполнения декодированных команд — в постпроцессоре. Таким образом, даже в простейшем случае команда проходит как минимум четыре стадии обработки:
- выборка из кэша;
- декодирование;
- выполнение;
- запись результатов.
Данные стадии принято называть конвейером обработки команд. В нашем гипотетическом случае конвейер является четырехступенчатым. Важно, что каждую из этих ступеней команда должна проходить ровно за один такт. Соответственно для четырехступенчатого конвейера на выполнение одной команды отводится ровно четыре такта.
Еще раз отметим, что рассмотренный нами процессор является гипотетическим. В реальных процессорах конвейер обработки команд может быть более сложным и может включать большее число ступеней. Однако сама идеология построения процессора остается неизменной. Причина увеличения длины конвейера заключается в том, что многие команды являются довольно сложными и не могут быть выполнены за один такт процессора, особенно при высоких тактовых частотах. Поэтому каждая из четырех стадий обработки команд (выборка, декодирование, выполнение и запись) может состоять из нескольких ступеней конвейера.
Короткий конвейер, как, впрочем, и длинный, имеет свои как сильные, так и слабые стороны. Чем больше количество ступеней конвейера, тем меньший объем работы выполняется на каждой ступени и, следовательно, тем меньше времени требуется для прохождения командой данной ступени. С учетом того, что каждая ступень выполняется за один такт, длинные конвейеры позволяют повышать тактовую частоту процессора, что невозможно в случае коротких процессоров. Классический пример процессора с длинным конвейером — процессор Intel Pentium 4. Так, первоначально (в процессорах на ядре с кодовым названием Northwood) длина конвейера составляла 20 ступеней, а впоследствии (в процессорах на ядре с кодовым названием Prescott) она была увеличена до 31 ступени.
Всякий процессор в конечном счете должен быть сконструирован таким образом, чтобы за минимальное время выполнять максимальное количество инструкций. Ведь именно скорость выполнения процессором инструкций и определяет его производительность.
Один из способов повышения производительности процессора, так или иначе реализованный в любом современном процессоре, заключается в увеличении количества исполнительных блоков. Таким образом, по существу, реализуется множество параллельных коротких конвейеров. При этом постпроцессор работает по классической схеме: осуществляет выборку команд, их декодирование и посылку на множество исполнительных блоков. Такой подход позволяет в полной мере реализовать параллелизм на уровне инструкций (Instruction-Level Parallelism, ILP), когда несколько инструкций выполняются одновременно в различных исполнительных блоках процессора.
Для того чтобы реализовать параллелизм на уровне инструкций, необходимо, чтобы поступающие на исполнительные блоки команды можно было выполнять параллельно. Однако, если, к примеру, для выполнения следующей по порядку инструкции требуется знать результат выполнения предыдущей инструкции (взаимозависимые инструкции), то в этом случае параллельное выполнение невозможно. Поэтому препроцессор прежде всего проверяет взаимосвязь команд и переупорядочивает их не в порядке поступления (out-of-order), а так, чтобы их можно было выполнять параллельно. На последних ступенях конвейера инструкции выстраиваются в исходном порядке.
Микроархитектура Intel Core
Теперь, после краткого знакомства с особенностями архитектуры современных процессоров, перейдем к рассмотрению микроархитектуры нового поколения Intel Core. Структурная блок-схема ядра процессора на основе микроархитектуры Intel Core показана на рис. 4.
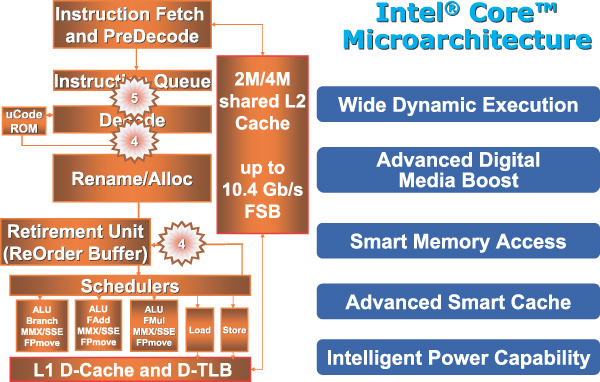
Рис. 4. Структурная блок-схема ядра процессора на основе микроархитектуры Intel Core
Как следует из блок-схемы ядра процессора, новая микроархитектура Intel Core в большей степени напоминает микроархитектуру Banias (мобильные процессоры Intel Pentium M), нежели архитектуру NetBurst (процессоры Intel Pentium 4). Первое, что бросается в глаза, — это отсутствие легендарного кэша декодированных инструкций с отслеживанием исполнения (Trace Cache), который является неотъемлемой частью архитектуры NetBurst.
При работе процессора на базе микроархитектуры Intel Core программные инструкции выбираются из кэша L2 (Instruction Fetch), транслируются в команды x86 и подлежат предварительному декодированию (PreDecode). Далее команды поступают в кэш инструкций, где из них организуется очередь (Instruction Queue), а затем из кэша передаются в декодер. При декодировании (Decode) команды преобразуются в машинные микрооперации (micro-op). Большинство команд при декодировании разбивается на две-три микрооперации, однако встречаются и такие команды, для декодирования которых потребовались бы десятки и даже сотни микроопераций. Для этих целей используется специальная ROM-память (uCode ROM), в которой сохраняются программы, состоящие из последовательности микроопераций, причем каждая такая программа соответствует одной декодированной инструкции.
После процесса декодирования команд начинается этап их исполнения. Первоначально происходит переименование и распределение дополнительных регистров процессора (Allocate & Rename), которые не определены архитектурой набора команд. Переименование регистров позволяет добиться их бесконфликтного существования.
На следующем этапе (Retirement Unit (ReOrder Buffer)) происходит переупорядочивание микроопераций не в порядке их поступления (Out-of-Order) с тем, чтобы впоследствии можно было реализовать их параллельное выполнение на исполнительных блоках.
Далее происходит планирование и распределение микроопераций по исполнительным блокам. Планировщик (Scheduler) формирует очереди микроопераций, в результате чего микрооперации попадают на один из пяти портов функциональных устройств (dispatch ports). Этот процесс называется диспетчеризацией (Dispatch), а сами порты выполняют функцию шлюза к функциональным устройствам.
После того как микрооперации пройдут порты диспетчеризации, они загружаются в блок регистров для дальнейшего выполнения.
В архитектуре Intel Core имеется три порта ALU для операций с плавающей запятой (Float Point) (FMul/FPMove, FAdd/FPMove, Branch/FPMove), а также по одному порту для записи (Store) и выгрузки (Load) данных из памяти.
Процесс непосредственного выполнения микроопераций в исполнительных устройствах происходит на последующих ступенях конвейера. Отметим, что эффективная длина конвейера в микроархитектуре Intel Core составляет 14 ступеней. Под эффективной длиной обычно понимается длина конвейера в случае выполнения непредсказанного перехода. В качестве примера отметим, что у процессора Pentium М она составляет 12 ступеней, а у процессора Pentium 4 — от 20 до 30, в зависимости от модели. Как видим, новый процессор относится к классу «короткоконвейерных».
Новая микроархитектура Intel Core объединяет в себе пять инновационных технологий:
- Intel Wide Dynamic Execution;
- Intel Intelligent Power Capability;
- Intel Advanced Smart Cache;
- Intel Smart Memory Access;
- Intel Advanced Digital Media Boost.
Технология Intel Wide Dynamic Execution позволяет обрабатывать больше команд за такт процессора путем повышения эффективности выполнения приложений и сокращения энергопотребления. Это достигается за счет реализации целой совокупности технологий, наиболее важными из которых являются следующие:
- механизм декодирования до четырех инструкций за такт;
- технология слияния макроопераций Macro Fusion;
- технология слияния микроопераций micro-ops fusion.
По сравнению с ядрами процессоров семейства Pentium M и Pentium 4, где за каждый такт могло декодироваться до трех программных инструкций, декодер ядра процессора с архитектурой Intel Core может декодировать в каждом такте до четырех инструкций x86, порождая до четырех микроопераций. Аналогичным образом расширены и все последующие тракты процессора, в результате чего ядро процессора может выполнять до четырех инструкций за такт.
Отметим, что в процессорах семейства Pentium M трехканальный декодер работает по несимметричной схеме 4-1-1, то есть первый канал декодера может декодировать инструкции, порождающие до четырех микроопераций, а остальные два канала — только инструкции, порождающие по одной микрооперации. При этом на полной скорости декодер может работать только с x86-инструкциями длиной не более 7-8 байт, а при появлении инструкции, порождающей более четырех декодированных микроопераций, будет обрабатываться только одна эта инструкция. Данные ограничения в ряде случаев могут снизить темп декодирования до двух либо до одной инструкции за такт.
В противовес несимметричному декодеру 4-1-1 архитектура Intel Core предусматривает симметричный декодер 4-4-4-4, то есть каждый из четырех каналов декодера может декодировать инструкции, порождающие до четырех микроопераций.
Технология Macro Fusion основана на слиянии двух инструкций x86 в одну. В предыдущих версиях процессорной микроархитектуры каждая инструкция в формате x86 декодировалась независимо от остальных. При использовании технологии Macro Fusion некоторые пары инструкций (например, инструкция сравнения и условного перехода) при декодировании могут быть слиты в одну микроинструкцию (micro-op), которая в дальнейшем будет выполняться именно как одна микроинструкция. Отметим, что для эффективного поддержания технологии Macro Fusion в архитектуре Intel Core используются расширенные блоки ALU (Arithmetical Logic Unit), которые способны поддержать выполнение слитых микроинструкций.
Отметим также, что без применения технологии Macro Fusion за каждый такт процессора могут декодироваться только четыре инструкции (в четырехканальном декодере). При использовании технологии Macro Fusion в каждом такте считывается пять инструкций, которые преобразуются в четыре за счет слияния и подвергаются декодированию.
Следующая технология, позволяющая увеличить количество обрабатываемых команд за такт, — это технология слияния микроопераций micro-ops fusion, суть которой сводится к тому, что в ряде случаев две микрооперации сливаются в одну, содержащую два элементарных действия. В дальнейшем две такие слитые микрооперации обрабатываются как одна, что в результате позволяет снизить количество обрабатываемых микроопераций и тем самым увеличить общее количество исполняемых процессором инструкций за один такт. В частности, как показывают расчеты, технология micro-ops fusion дает возможность снизить общее количество микроопераций на 10%.
Из других технологий, способствующих увеличению числа обрабатываемых команд за такт процессора, отметим увеличение размера буферов, связанных с внеочередным исполнением инструкций (Out-of-Order). Кроме того, улучшены предвыборка данных из памяти (prefetch) и механизм предсказания переходов.
Технология Intel Intelligent Power Capability позволяет снизить энергопотребление процессора. Суть ее заключается в том, что в конкретный момент питанием обеспечиваются только те блоки ядра процессора, которые в этом действительно нуждаются, а остальные — отключаются от питания.
Технология Intel Advanced Smart Cache подразумевает реализацию разделяемой между двумя ядрами процессора кэш-памяти L2. В случае когда в двухъядерном процессоре кэш L2 не является разделяемым, каждому ядру процессора приходится работать со своим собственным кэшем, и если одному ядру требуются данные, которые находятся в кэше другого ядра, то они передаются через системную шину, что увеличивает время доступа к данным. В случае разделяемого кэша каждому ядру процессора становится доступен весь кэш. Кроме того, каждому ядру процессора позволяется использовать всю кэш-память при динамическом отключении другого ядра.
Технология Intel Smart Memory Access — еще одно новшество в архитектуре Intel Core. Если быть предельно кратким, то данная технология повышает производительность системы, сокращая время отклика памяти и оптимизируя таким образом использование пропускной способности подсистемы памяти.
Технология Intel Smart Memory Access включает два ключевых механизма: memory disambiguation и advanced prefetchers. Не вникая в довольно сложный алгоритм работы данных механизмов, отметим лишь, что они позволяют повысить эффективность переупорядочивания команд и оптимизировать размещение данных в кэше.
И наконец, последняя из пяти ключевых технологий архитектуры Intel Core — технология Intel Advanced Digital Media Boost, которая позволяет обрабатывать все 128-разрядные команды SSE, SSE2 и SSE3, широко используемые в мультимедийных и графических приложениях, за один такт, что повышает скорость их выполнения.
Заключение
 жидается, что микроархитектура Intel Core будет реализована в новых многоядерных процессорах Intel для серверов (Woodcrest), настольных ПК (Conroe) и ноутбуков (Merom) уже в III квартале этого года. Первые двухъядерные процессоры с микроархитектурой Intel Core будут производиться с использованием 65-нм технологии.
жидается, что микроархитектура Intel Core будет реализована в новых многоядерных процессорах Intel для серверов (Woodcrest), настольных ПК (Conroe) и ноутбуков (Merom) уже в III квартале этого года. Первые двухъядерные процессоры с микроархитектурой Intel Core будут производиться с использованием 65-нм технологии.
Джастин Раттнер (Justin Rattner) пояснил, что микроархитектура Intel Core позволяет улучшить соотношение производительности и энергопотребления.
«Микроархитектура Intel Core — это очередной этап улучшения масштабируемости производительности и экономичности, — сказал г-н Раттнер. — Позднее в этом году мы представим разработанные на ее основе двухъядерные процессоры, а в 2007 году — четырехъядерные процессоры, которые, как мы полагаем, будут отличаться самым привлекательным в отрасли соотношением производительности и энергопотребления. Благодаря этому пользователи смогут приобрести более производительные, компактные и тихие системы с продленным сроком автономной работы и меньшими требованиями к электропитанию».
Выступая с докладом, Джастин Раттнер продемонстрировал, как десктопный процессор с кодовым наименованием Conroe для настольных ПК может обеспечить примерно 40-процентное повышение производительности и 40-процентное же снижение энергопотребления по сравнению с процессором Intel Pentium D 950. Если же говорить о новом серверном процессоре Woodcrest, то в сравнении с двухъядерным процессором Intel Xeon 2,8 ГГц он обеспечивает 80-процентный прирост производительности при 40-процентном снижении энергопотребления. Новый мобильный процессор Merom по сравнению с мобильным процессором Yonah позволит получить 20-процентный прирост производительности при 20-процентном снижении энергопотребления.
Конечно же, сравнение по производительности и энергопотреблению новых и уже существующих процессоров Intel — это интересно, но недостаточно информативно. Куда как любопытнее сравнить их с их основными конкурентами — двухъядерными процессорами AMD. Конечно же, ждать такого сравнения от компании Intel абсолютно бессмысленно, однако уже имеются результаты сравнительного тестирования первых инженерных образцов этих процессоров, проведенного независимыми тестовыми лабораториями. Мы лишь подытожим представленные ими результаты.
Итак, сравнивались две платформы: на базе процессора Conroe с тактовой частотой 2,6 ГГц (частота FSB 1066 МГц) и на базе процессора Athlon 64 FX-60, разогнанного до частоты 2,8 ГГц.
Платформа на базе процессора Conroe была оснащена системной платой Intel на чипсете Intel 975X, с памятью 1 Гбайт DDR2-667 (тайминги 4-4-4) и двумя видеокартами Radeon X1900 XT в режиме CrossFire.
Платформа на базе процессора Athlon 64 FX-60 была построена на базе системной платы DFI RD480 и оснащена памятью 1 Гбайт DDR400 (тайминги 2-2-2), а также двумя видеокартами Radeon X1900 XT в режиме CrossFire.
А теперь самое интересное. Во всех тестах (использовались игровые тесты и тесты аудио- и видеокодирования) процессор Conroe демонстрирует производительность на 20-30% выше, чем флагман AMD — процессор Athlon 64 FX-60.
Ну что ж, самое время сказать: «Здравствуй, Intel, до свидания, AMD»!
P.S. В следующем номере мы продолжим обзор основных событий весеннего Форума IDF 2006 и, в частности, расскажем о развитии мобильных платформ.








