«Память переводчика», или Что такое Translation Memory
Рынок систем Тranslation Мemory
Как настроить систему Тranslation Memory
Работа с непереведенными сегментами
Говоря об автоматизированном переводе, обычно подразумевают программы, осуществляющие перевод на основе технологии машинного перевода (Machine Translation). Однако существует и другая технология — Translation Memory, которая хотя и не столь широко известна российским пользователям, но, тем не менее, имеет ряд преимуществ.
Бурное развитие технического прогресса привело к увеличению числа технических устройств, машин и другой сложной техники, без которых жизнь современного человека практически немыслима. Например, объем документации для европейского самолета Airbus исчисляется десятками тысяч страниц. Как показывают данные исследования, проведенного в конце 2004 года ассоциацией LISA1 (LISA 2004 Translation Memory Survey), 42% опрошенных переводят около 1 млн. слов в год, у 24% компаний — участников опроса ежегодный объем переводов составляет 1-5 млн., 12% переводят от 5 до 10 млн., объем переводов остальных компаний — от 10 до 500 и более миллионов слов в год. В частности, большинство производителей сегодня не ограничиваются своим локальным рынком и активно осваивают региональные рынки. При этом локализация продукции, в том числе перевод описания продукта на местный язык, является одним из обязательных условий для выхода на новый рынок.
В то же время, хотя производители регулярно выпускают новые версии своих продуктов — автомобилей, экскаваторов, компьютеров и мобильных телефонов, программного обеспечения, — далеко не все из них принципиально отличаются от предыдущих моделей. Подчас новая модель телефона представляет собой слегка измененную (или рестайлинговую) предыдущую модель. Новые версии продаются лучше, поэтому производителям приходится регулярно обновлять свои продукты. В результате документация по каждому из таких продуктов зачастую на 70-90% совпадает с той, что была у предыдущей версии.
Два фактора — большой объем требующих перевода документов и их высокая повторяемость — послужили стимулом к созданию технологии Translation Memory (сокращенно именуется TM, общепринятый русский перевод этого термина отсутствует). Суть технологии TM можно образно передать одной фразой: «Не переводить один и тот же текст дважды». Иначе говоря, Translation Memory используется для повторного использования ранее сделанных переводов. Это позволяет серьезно сократить время на подготовку перевода, особенно при работе с текстами, имеющими высокую степень повторяемости.
Технологию Translation Memory часто путают с машинным переводом (Machine Translation), которая, безусловно, тоже полезна и интересна, но ее описание не является целью настоящей статьи. Использование технологии ТМ повышает скорость перевода за счет уменьшения объема механической работы. Однако важно отметить, что TM не выполняет перевод за переводчика, а является мощным инструментом для сокращения затрат при переводе повторяющихся текстов.
Технология ТМ работает по принципу накопления результатов перевода: в процессе перевода в базе ТМ сохраняются исходный текст и его перевод. Для облегчения обработки информации и сравнения различных документов система Translation Memory разбивает весь текст на отдельные кусочки, которые называются сегментами. Такими сегментами чаще всего являются предложения, но могут быть приняты и другие правила сегментации. При загрузке нового текста система TM осуществляет сегментирование и сравнивает сегменты исходного текста с уже имеющимися в подключенной базе переводов. Если системе удается найти полностью или частично совпадающий сегмент, то его перевод отображается с указанием совпадения в процентах. Сегменты, которые отличаются от сохраненного текста, выделяются подсветкой. Таким образом, переводчику остается только перевести новые сегменты и отредактировать частично совпадающие.
Как правило, задается порог совпадений на уровне не ниже 75%, так как если установить меньший процент совпадений, то увеличатся затраты на редактирование текста. Каждое изменение или новый перевод сохраняются в ТМ, так что нет необходимости переводить одно и то же дважды!
Важно также постоянно пополнять базу Translation Memory, сохраняя в базе (или в базах, если перевод выполняется по различным тематикам) пары сегментов «исходный текст — правильный перевод». Это позволит значительно сократить время, необходимое для перевода сходных текстов. Помимо снижения трудоемкости перевода система TМ позволяет выдержать единство терминологии и стиля во всей документации.
Использование технологии ТМ обеспечивает переводчику следующие преимущества:
- повышение производительности труда. Подстановка даже на 80% совпадающих сегментов из базы переводов может сократить время работы над переводом на 50-60%. Как показывает практика, гораздо эффективнее править уже готовый перевод, чем переводить заново — «с нуля»;
- единство терминологии и стиля при наличии базы переводов по тематике переводимого документа. Это особенно важно при переводе узкоспециальной документации;
- организация работы коллектива переводчиков с гарантированным качеством перевода благодаря доступу к общей базе Translation Memory.
Отдельно отметим, что в западных странах, где технология Translation Memory давно уже стала де-факто обязательным инструментом переводчика, средства, потраченные на создание базы переводов, рассматриваются не как затраты, а, скорее, как инвестиции в стабильную и качественную работу, что увеличивает не только прибыль, но и стоимость самой компании.
Рынок систем Тranslation Мemory
Бесспорным лидером на рынке систем Translation Memory являются программы SDL-TRADOS. Летом 2005 года произошло объединение двух крупнейших разработчиков систем ТМ — компаний SDL и TRADOS (программные продукты под торговой маркой TRADOS хорошо известны многим пользователям), и теперь они выпускают совместный продукт, который является законодателем стандартов в области Translation Memory.
Новая система SDL-TRADOS имеет расширенные (настраиваемые пользователем) функциональные возможности нечеткого соответствия (поиск по совпадениям в базе переводов), а также инструментарий для проверки качества переводимых документов. Программа осуществляет проверку орфографии и защищает содержимое блоков памяти с помощью технологии шифрования.
Система поддерживает такие форматы, как Word DOC и RTF, online help RTF, PowerPoint, FrameMaker, FrameMaker +SGML, FrameBuilder, Interleaf, QuickSilver, Ventura, QuarkXPress, PageMaker, SGML/HTML/XML, включая HTML Help, RC (Windows Resource), Bookmaster (DCF) и Troff. Помимо системы SDL-TRADOS, на IT-рынке имеются и другие системы ТМ. Особенно широко представлены французские производители.
Система французской компании Atril (www.atril.com) называется . Ее разработчики сначала организовали собственное бюро перевода технической документации, после чего возникла идея создания специализированного ПО на основе технологии Translation Memory.
— это самостоятельное приложение с систематизированным меню. Система может создавать базы ТМ, а также базы данных терминологии и подключать словари. Процесс перевода осуществляется в специальной оболочке Project, куда при ее создании прикрепляется файл, который необходимо перевести, и подключаются дополнительные настройки: база ТМ, словари и др. Текст переводится в специальной таблице, где напротив каждой графы его оригинала нужно заполнить вариант перевода. К преимуществам также относится дополнительная функция для перевода файлов различных форматов, которая позволяет сохранить исходное форматирование файла.
Другая система ТМ — Wordfast (www.wordfast.net) — разработана профессиональным французским переводчиком Ивом Чамполлионом и предназначена для перевода информации путем накопления переводов непосредственно в текстовом редакторе Word. Программа не сегментирует текст в виде таблицы, а выделяет цветом одно предложение за другим непосредственно в тексте и вставляет дополнительные скобки для варианта перевода.
Помимо поддержки форматов Word, система может переводить документы Excel и PowerPoint. При переводе можно использовать и базы ТМ других программ: Trados версий 2, 3 и 5, документы формата TMX и базы программы IBM Translation Manager. Кроме того, система может работать без лицензии с базами перевода объемом до 110 Кбайт.
ТМ в России
Помимо иностранных компаний, разработкой систем класса Тranslation Мemory занимается российская компания ПРОМТ — всемирно известный разработчик систем машинного перевода (Machine Translation).
Разработка продукта PROMT Translation Suite 7.0 — это дебют компании ПРОМТ в области применения технологии Translation Memory. Уникальность продукта заключается в интеграции сразу двух технологий перевода: Translation Memory и Machine Translation. Помимо работы с базой ТМ в виде самостоятельного приложения путем создания специального документа «Проект», система PROMT Translation Suite 7.0 самостоятельно переводит те сегменты текста, которые отсутствуют в базе ТМ.
Для облегчения работы с незнакомым текстом в продукте также имеется интегрированный электронный словарь, который позволяет оперативно просмотреть варианты перевода слова (рис. 1).
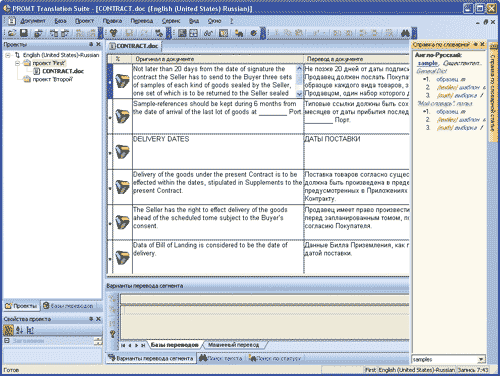
Рис. 1. Окно программы PROMT Translation Suite с развернутой панелью справки по словарной статье
Основные достоинства PROMT Translation Suite:
- Интеграция двух технологий — интеграция машинного перевода с технологией Translation Memory позволяет значительно снизить расходы на перевод текстов. Как правило, даже наличие обширной базы Translation Memory не гарантирует 100%-ного совпадения сегментов оригинального текста с базой переводов. Как показывает практика, даже при высокой степени совпадения, не менее 30-40% текста переводчикам приходится переводить вручную. Наличие функции машинного перевода позволяет ускорить процесс перевода. По ряду оценок, использование МТ повышает производительность труда переводчика на 40-60% в зависимости от сложности текста.
- Дружественный интерфейс — в отличие от большинства систем TM, продукт PROMT Translation Suite предлагает удобный и интуитивно понятный интерфейс. Фактически пользователь может начать переводить сразу же после инсталляции, не нуждаясь в дорогостоящем тренинге по обучению работе с продуктом.
- Наличие русской локализации — данный продукт имеет русский интерфейс и документацию на русском языке.
- Привлекательная цена — PROMT Translation Suite в комплектации с системой машинного перевода с английского на русский и обратно стоит 400 долл.
Как настроить систему Тranslation Memory
Процесс перевода с помощью системы Translation Memory можно условно разделить на следующие этапы:
- Сегментирование исходного текста в соответствии с заданными правилами сегментации.
- Поиск совпадений между сегментами исходного текста и сегментами, хранящимися в базе переводов. Найденные совпадения программа подставляет в текст перевода с указанием процента совпадения.
- Перевод ненайденных сегментов и редактирование частично совпадающих сегментов.
- Сохранение корректных переводов в базе TM для последующего использования.
Для упрощения изложения в рамках данной статьи мы сознательно не рассматриваем этапы извлечения текста из исходного документа и последующей верстки переведенного текста в случае перевода документов в таких форматах, как XML, PDF и др.
Рассмотрим возможности настройки системы Translation Memory на примере уже упоминавшейся нами программы PROMT Translation Suite.
Правила сегментации текста
Одна из основных задач во время настройки системы — правильное сегментирование текста. Успех поиска совпадающих сегментов в базе зависит от того, насколько правильно заданы правила сегментации текста (рис. 2).
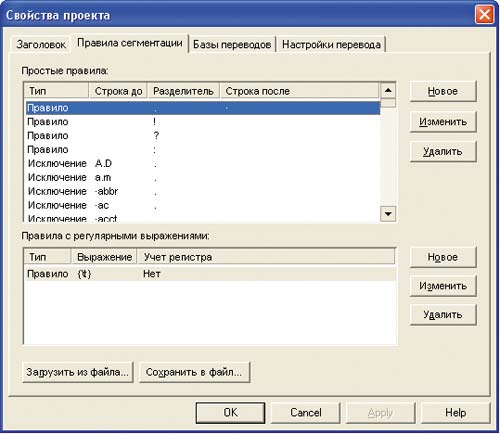
Существует два типа условий сегментации:
- правило — задает условия, при которых определенные символы (точка, запятая и т.д.) являются границами сегментов;
- исключение — задает условия, при которых определенные символы не являются границами сегментов.
Базовый набор правил сегментации автоматически добавляется в каждый проект перевода при его создании. Для того чтобы получить возможность редактирования этих правил, необходимо выбрать команду Свойства в контекстном меню искомого проекта (второй способ: меню Проект -> Все проекты -> Свойства -> Правила сегментации).
В системе можно задать две группы правил сегментации: простые правила и правила с регулярными выражениями.
Простые правила задают условия, определяющие последовательность символов, которые надо или не надо считать границей сегмента. К простым правилам относится строка до разделителя (возможна пустая или определенная последовательность символов), символ разделителя (всегда один!) и строка после разделителя.
Правила с регулярными выражениями существуют для создания более гибких условий сегментации, что также отнюдь не лишне. Если должным образом не задать такие условия, то, например, предложение «Команда выиграла матч со счетом 3:1» может быть неправильно сегментировано. В данном случае необходимо задать исключение (то есть символ, который система не будет считать границей сегмента) в виде строки до разделителя с помощью регулярного выражения « \d+ » (обозначает любое количество цифр), символа разделителя «:» и строки после разделителя с помощью регулярного выражения « \d+ » (любое количество цифр). В этом случае система не обратит внимание на двоеточие между цифрами.
Работа с непереведенными сегментами
В процессе перевода система анализирует текст, находит полностью или частично совпадающие предложения в базе ТМ и подставляет их в текст перевода. В каждом сегменте сбоку указывается процент совпадений, нижний предел которого можно устанавливать самостоятельно, задавая настройки перед переводом.
Как уже упоминалось, система PROMT Translation Suite позволяет переводить сегменты, отсутствующие в базе переводов, с помощью технологии машинного перевода (Machine Translation). Это значительно сокращает время работы над переводом, поскольку править уже готовый перевод легче, чем переводить заново. Для настройки машинного перевода можно использовать стандартный набор функций: создание и пополнение собственных словарей, резервирование слов, применение препроцессоров и ряд других (более подробно читайте о них в статье «Настройка — залог качественного перевода» в этом спецвыпуске).
Нельзя также забывать о необходимости постоянного пополнения баз ТМ для сокращения затрат на перевод в дальнейшем. Для того чтобы добавить корректно переведенные сегменты в базу, щелкните правой клавишей мыши по выделенному сегменту и выберите команду Добавить выделенные сегменты в базу (или нажмите соответствующую кнопку на панели инструментов). Сохранение новых сегментов перевода в базе не только повышает эффективность работы с системой, но и экономит время при переводе последующих текстов.
Кроме того, следует пользоваться командой контекстного меню Завершить перевод сегментов после окончания редактирования сегментов. В этом случае можно избежать случайного внесения изменений в уже отредактированный сегмент.
Импорт баз переводов
Одна из наиболее полезных опций системы PROMT Translation Suite — возможность импорта баз переводов (во внутреннем формате программы (*.pts) и баз переводов ассоциированной памяти PROMT (*.apd)), а также сегментов из файлов (во внутреннем формате *.pts и в формате TMX Level 1 (*.tmx)). Используя эту возможность системы, можно избавить себя от составления базы переводов с нуля в том случае, если база ТМ по необходимой тематике уже создана, например, другими сотрудниками компании.
Процесс импорта баз переводов PROMT Translation Suite сравнительно прост. Необходимо открыть меню База -> Импортировать и выбрать команду База переводов, а затем найти нужный файл базы и обязательно указать тип файла *.pts.
Особое внимание следует уделить возможности импорта сегментов файлов TMX.
Файлы TMX — это универсальный формат обмена данными для систем Translation Memory, поэтому с их помощью вы можете переносить содержимое баз данных, даже если раньше работали с другой системой ТМ. Чтобы импортировать сегменты из файла ТМХ, нужно выбрать в том же меню База -> Импортировать команду Сегменты и необходимый ТМХ-файл. После этого следует выбрать ту базу переводов, в которую необходимо добавить сегменты из ТМХ-файла, и нажать кнопку Выбрать.
В заключение отметим, что технология Translation Memory является мощным инструментом для решения проблемы эффективного перевода повторяющихся текстов. В этом обзоре мы не только рассказали о сути технологии TM, но и описали представленные на рынке системы. В частности, российским пользователям можно порекомендовать обратить внимание на систему PROMT Translation Suite, разработанную российской компанией ПРОМТ.
Важным преимуществом системы PROMT Translation Suite, по сравнению с зарубежными аналогами, является наличие интегрированной технологии машинного перевода. Это позволяет значительно ускорить создание собственных баз Translation Memory и повысить эффективность работы с системой.
Постоянное пополнение баз переводов новыми сегментами сведет к минимуму работу переводчика вручную при переводе текстов схожей тематики.
1 Данное исследование основано на данных опроса посетителей сайта ассоциации LISA (www.lisa.org). LISA — некоммерческая ассоциация, объединяющая компании и индивидуалов, занятых в индустрии GILT (Globalization, Internationalization, Localization, Translation — глобализация, интернационализация, локализация, перевод). Членами LISA являются более 400 IT-компаний, поставщиков переводческих сервисов, а также крупные корпоративные пользователи.








