Средства бизнес-анализа в SQL Server 2005
Часть 5. Построение моделей Data Mining
Просмотр результатов обучения моделей
В предыдущей части данной статьи (см. КомпьютерПресс № 6’2006) мы рассказали о новшествах, появившихся в реализации средств Data Mining, которые доступны пользователям этой СУБД. Сегодня на примере алгоритмов создания деревьев решений, кластеризации и байесова алгоритма мы рассмотрим основные этапы реализации решений, использующих Data Mining, такие как создание и обучение модели, оценка ее точности и применение модели для получения прогнозов.
Используемые алгоритмы
В качестве примеров алгоритмов мы будем использовать Microsoft Decision Trees, Microsoft Clustering и байесов алгоритм.
Алгоритм Microsoft Decision Tree представляет собой алгоритм классификации, позволяющий прогнозировать как непрерывные, так и дискретные атрибуты на основе оценки в процессе обучения модели степени влияния входных атрибутов на прогнозируемый атрибут и построения иерархической структуры,которая базируется на ответе «да» или «нет» на набор вопросов. Такие алгоритмы весьма популярны и в настоящее время реализованы практически во всех коммерческих средствах Data Mining. Алгоритмы построения деревьев решений позволяют предсказать значение какого-либо параметра для заданного случая (например, возвратит ли вовремя человек выданный ему кредит) на основе большого количества данных о других подобных случаях (в частности, на основе сведений о других лицах, которым выдавались кредиты).
Алгоритм Microsoft Clustering в процессе обучения модели производит группировку в кластеры данных с одинаковыми или близкими по значению характеристиками и осуществляет прогноз на основании принадлежности значений одному из них. Обычно алгоритмы кластеризации применяются в тех случаях, когда нет абсолютно никаких предположений о характере взаимосвязи между данными, а результаты их применения нередко являются исходными данными для других алгоритмов, например для построения деревьев решений.
Байесов алгоритм (Naive Bayes) позволяет в процессе обучения модели вычислить вероятность, с которой каждое возможное состояние каждого входного атрибута приводит к каждому состоянию прогнозируемого атрибута, а затем использовать результаты расчетов для прогнозирования. Этот алгоритм поддерживает только дискретные атрибуты.
Создание и обучение моделей
Создание моделей Data Mining осуществляется с помощью SQL Server Business Intelligence Development Studio — того же самого инструмента, что применяется для создания OLAP-решений. Для выполнения указанной задачи используется тот же самый шаблон Analysis Services Project, и точно так же, как и при создании OLAP-кубов, работа над моделью начинается с указания источников данных (в нашем примере мы воспользовались готовой базой данных AdventureWorks, входящей в комплект поставки SQL Server 2005) и с создания представления источников данных, на основе которого будет генерироваться модель (рис. 1). Подробнее о том, как это сделать, можно прочесть в одной из предыдущих статей данного цикла (см. КомпьютерПресс № 3’2006).
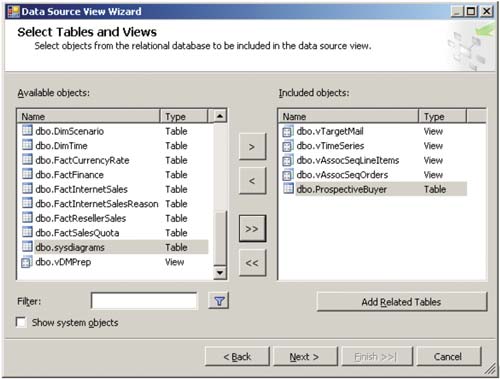
Рис. 1. Представление источников данных для последующего создания моделей Data Mining
Создав представление источников данных, можно приступать к разработке структуры модели (Mining Structure), выбрав соответствующий пункт контекстного меню папки Mining structures. При ответе на вопросы мастера выбираются модель Data Mining, используемое представление источников данных, таблица, содержащая строки, предназначенные для обучения модели (каждая такая строка в терминах Data Mining носит название Case), прогнозируемые атрибуты (то есть такие, значения которых в дальнейшем нужно будет предсказывать) и входные атрибуты (на основании которых будет осуществляться прогноз) (рис. 2).
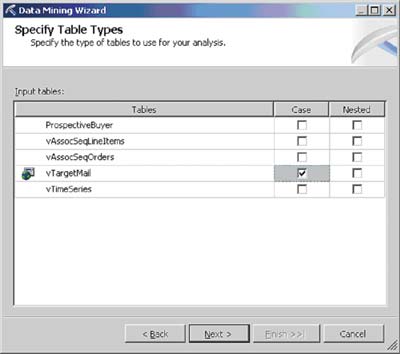
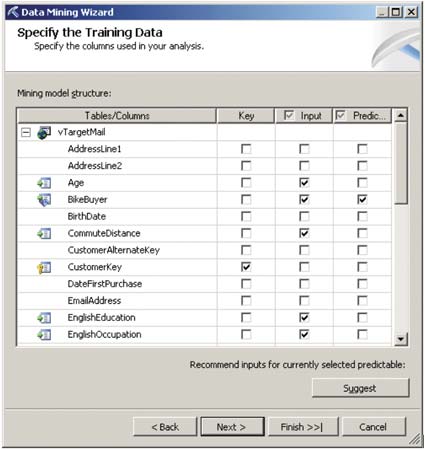
Рис. 2. Выбор таблиц, входных и прогнозируемых атрибутов
Путем анализа выбранных данных мастер создания структуры определяет тип данных в каждом используемом поле и предлагает сохранить полученную модель.
Созданной структурой можно воспользоваться повторно, к примеру для разработки модели, использующей другой алгоритм. Это позволяет сменить алгоритм Data Mining без повторного выбора таблиц и полей в том случае, если анализ с применением первоначально выбранного алгоритма привел к выводу о необходимости его замены (рис. 3).
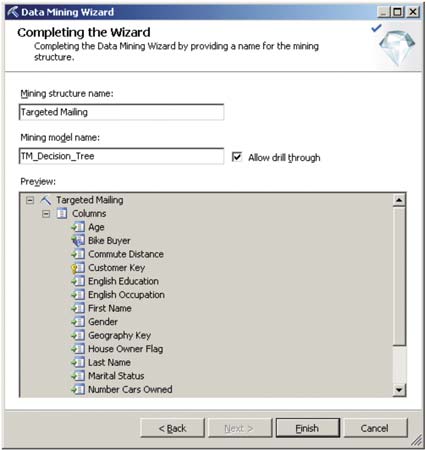
Рис. 3. Сохранение модели Data Mining на основе имеющейся структуры
В нашем примере мы воспользовались одним из перечисленных в начале статьи алгоритмов и затем добавили к нему два оставшихся, избавившись в случае описания структуры для байесова алгоритма от неподдерживаемых им недискретных полей.
Описав структуру моделей, мы можем перенести модели на сервер аналитических служб и осуществить обучение моделей (рис. 4).
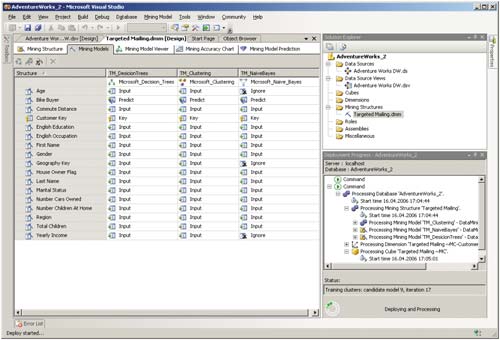
Рис. 4. Обучение моделей Data Mining
Отметим, что процесс обучения модели (состояние которого отображается в окне Deployment Progres) может оказаться весьма длительным, особенно в случае не учебного, как в данном примере, а реального набора данных, накопленного в течение многих лет работы компании, нуждающейся в подобном анализе. Отметим, однако, что процесс обучения моделей выполняется однократно (или изредка, причем только в том случае, если модель предполагается иногда обновлять с учетом значительного количества вновь появившихся данных), тогда как выполняющийся многократно процесс предсказания осуществляется довольно быстро.
Просмотр результатов обучения моделей
Построение дерева решений
Когда один из алгоритмов построения деревьев решений применяется к набору исходных данных, результат отображается в виде дерева. Подобные алгоритмы позволяют осуществить несколько уровней такого разделения, деля полученные группы (ветви дерева) на более мелкие на основании других признаков до тех пор, пока значения, которые предполагается предсказывать, не станут одинаковыми (или, в случае непрерывного значения предсказываемого параметра, близкими) для всех полученных групп (листьев дерева). Именно эти значения и применяются для осуществления предсказаний на основе данной модели.
Действие алгоритмов построения деревьев решений базируется на применении методов регрессионного и корреляционного анализа. В реализации Microsoft Decision Tree разделение производится на основе наиболее высокого для описываемых ветвью данных коэффициента корреляции между параметром, согласно которому происходит разделение, и параметром, который в дальнейшем должен быть предсказан. Указанный алгоритм был доступен и в предыдущей версии SQL Server, но, в отличие от нынешней реализации, он не мог использовать несколько процессоров.
Просмотреть полученное дерево решений можно с помощью закладки Decision Tree средства Mining Model Viewer (рис. 5).
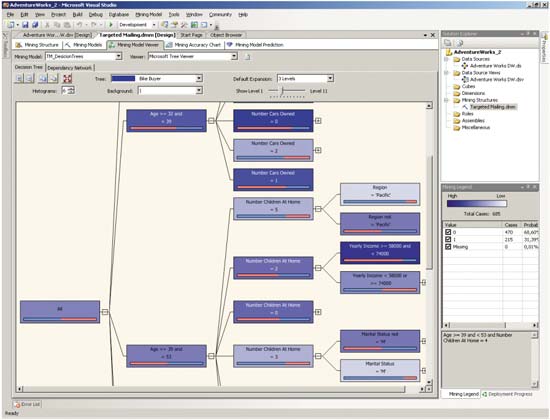
Рис. 5. Дерево решений
Иерархия, представленная в полученном дереве, создана на основе классификации данных по правилу «Если…, то…», причем насыщенность цвета ветвей зависит от количества исходных данных, попавших в указанную ветвь. При этом на гистограмме в отдельном окне можно увидеть процентное распределение возможных результатов предсказания для выбранной ветви.
Ветви дерева можно раскрывать до самого нижнего уровня (до листьев), при этом на нижнем уровне в распределении возможных результатов предсказания обычно превалирует какое-то одно значение. Иными словами, алгоритм построения деревьев решений позволяет определить набор значений характеристик, позволяющих отделить одну категорию данных от другой, — этот процесс называют сегментацией.
Для изучения взаимозависимости атрибутов в данных, использованных для обучения модели, можно воспользоваться закладкой Dependency Network средства Mining Model Viewer (рис. 6).
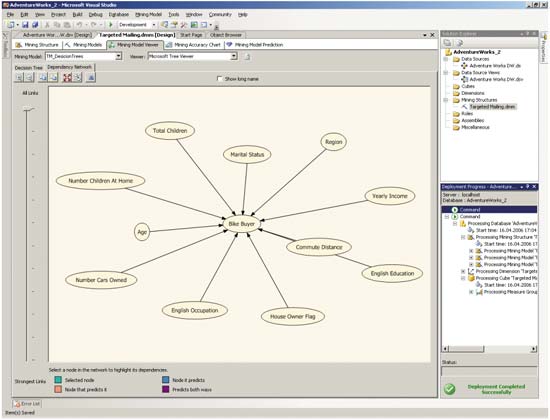
Рис. 6. Изучение взаимозависимости атрибутов, определенной с помощью построения дерева решений
В центральной части представленной схемы расположен предсказываемый атрибут, вокруг него — атрибуты, используемые для прогнозирования. При этом, перемещая указатель в левой части окна, можно оценить степень влияния каждого атрибута на предсказываемый результат: чем ниже указатель, тем меньше связей будет отображаться на представленной схеме.
Следует подчеркнуть, что методы анализа, основанные на построении деревьев решений, чаще всего применяются для выявления таких параметров, которые наиболее важны для принятия однозначного решения (например, давать ли банковский кредит данному юридическому лицу), а также в случаях, когда требуется разбиение исходных данных на очевидные группы по каким-либо признакам.
Кластеризация
Алгоритмы кластеризации обычно осуществляют итеративный поиск групп данных на основании некоторого числа кластеров, центры которых изначально представляют собой случайным образом выбранные точки в n-мерном пространстве возможных значений (где n — число параметров). Затем перебираются все исходные данные, и в зависимости от значений параметров они помещаются в тот или иной кластер, при этом постоянно происходит поиск точек, сумма расстояний которых до остальных точек в данном кластере является минимальной. Эти точки становятся центрами новых кластеров, и процедура повторяется до тех пор, пока центры и границы новых кластеров не перестанут перемещаться.
Указанный алгоритм тоже был доступен пользователям предыдущей версии SQL Server, но в реализации SQL Server 2005 в него были добавлены средства обнаружения естественного числа кластеров в наборе данных, используемом для обучения модели.
Данный алгоритм далеко не всегда приводит к результату, поддающемуся логическому объяснению, — он просто позволяет определить различные группы объектов или событий.
Для просмотра результатов кластеризации можно воспользоваться все тем же средством Mining Model Viewer. На закладке Cluster Diagram (рис. 7) демонстрируются связи между кластерами.
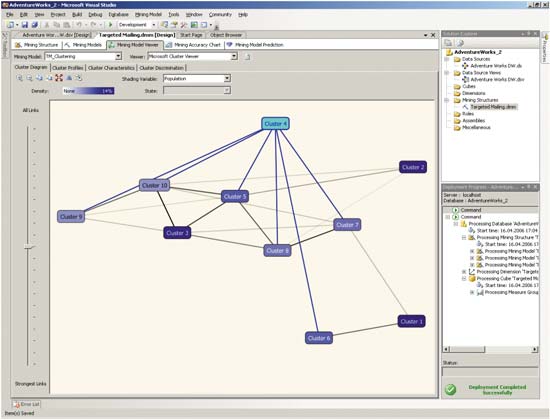
Рис. 7. Связи между кластерами
Интенсивность цвета кластера на диаграмме соответствует процентному распределению записей по значению предсказываемого атрибута. При этом, перемещая указатель в левой части окна, можно оценить степень связи между кластерами: чем ниже указатель, тем меньше связей будет отображаться на представленной схеме.
На закладке Cluster Profiles отображается состав каждого кластера — для каждого атрибута показана гистограмма, отображающая состав записей, содержащих различные значения данного атрибута (рис. 8).
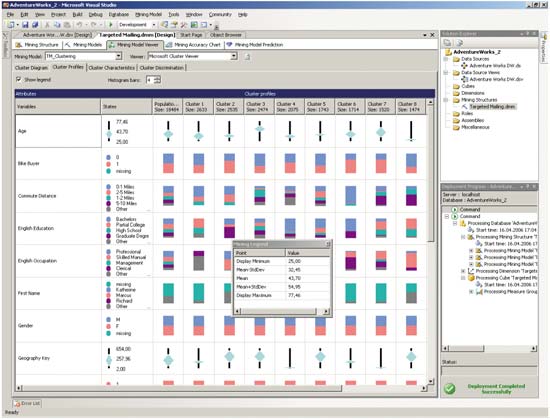
Рис. 8. Состав кластеров
Изучить подробные характеристики кластера можно с помощью закладки Cluster Characteristics, а сравнить кластеры между собой поможет закладка Cluster Discrimination (рис. 9).
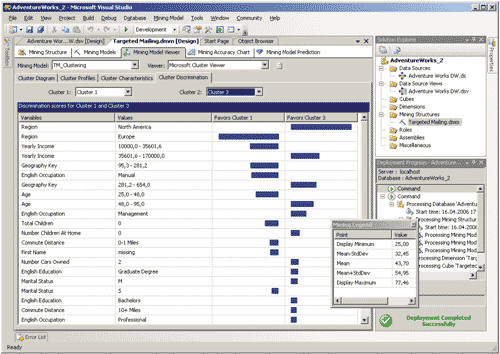
Рис. 9. Сравнение двух кластеров между собой
Отметим, что методы анализа, основанные на кластеризации, применяются для решения многих задач, например при оценке кредитных и страховых рисков, при построении систем контентной фильтрации (например, антиспамовых фильтров).
Байесов алгоритм
Байесов алгоритм полезен при классификации данных. С его помощью можно выявить различия во влиянии, оказываемом на прогнозируемый атрибут различными состояниями входного атрибута. Как и алгоритм кластеризации, он нередко используется в антиспамовых фильтрах, хотя и основан на ином принципе — на вычислении вероятности того, каким будет состояние прогнозируемого атрибута при определенном значении входного атрибута. В предыдущей версии SQL Server указанный алгоритм не поддерживался.
Для изучения взаимозависимости атрибутов, определенной с помощью байесова алгоритма, можно воспользоваться закладкой Dependency Network средства Mining Model Viewer (рис. 10).
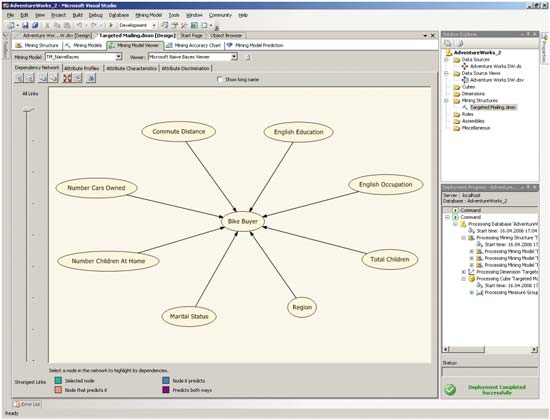
Рис. 10. Изучение взаимозависимости атрибутов, определенной с помощью байесова алгоритма
В центральной части представленной схемы расположен предсказываемый атрибут, вокруг него — атрибуты, используемые для прогнозирования. При этом, перемещая указатель в левой части окна, можно определить влияние каждого атрибута на предсказываемый результат, то есть чем ниже указатель, тем меньше связей будет отображаться на представленной схеме.
Закладка Attribute Profiles предназначена для оценки того, каким образом различные значения входных атрибутов влияют на предсказываемый атрибут (рис. 11).
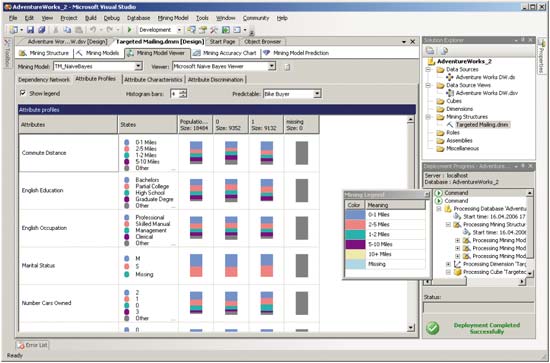
Рис. 11. Профили атрибутов
Закладка Attribute Characteristics предназначена для отображения того, насколько часто выбранное значение входного атрибута встречается в случае выбранного значения предсказываемого атрибута (рис. 12).
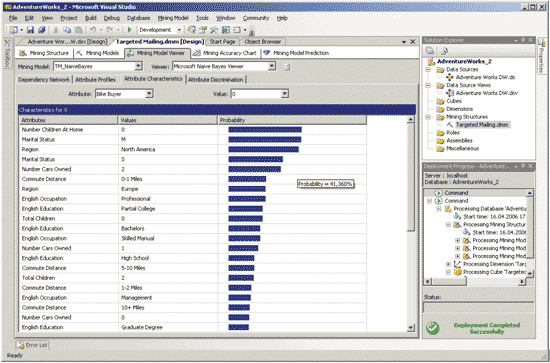
Рис. 12. Характеристики атрибутов
Можно также сравнить различные значения входного атрибута в случае выбранного значения предсказываемого атрибута — для этого используется закладка Attribute Discrimination.
Оценка точности прогнозов
Cозданные модели обычно тестируются и сравниваются на предмет точности осуществляемых с их помощью прогнозов — это позволяет выбрать наиболее приемлемый алгоритм для последующего применения. Метод сравнения моделей в данном продукте носит название lift chart. Для оценки точности моделей и сравнения их с этой точки зрения обычно применяют специальный тестовый набор данных, в общем случае отличный от набора данных, используемого для обучения модели. В процессе оценки точности для строк из тестового набора данных осуществляется предсказание прогнозируемого атрибута на основе входных атрибутов, а затем полученный результат сравнивается с известным значением прогнозируемого атрибута. Полученные результаты сравнения сортируются и отображаются в виде графика; причем на том же графике отображаются и результаты, которые были бы получены при стопроцентно точном прогнозе (ideal model).
Для сравнения моделей следует связать колонки тестового набора данных с колонками структуры моделей и при необходимости осуществить фильтрацию тестовых данных (рис. 13).
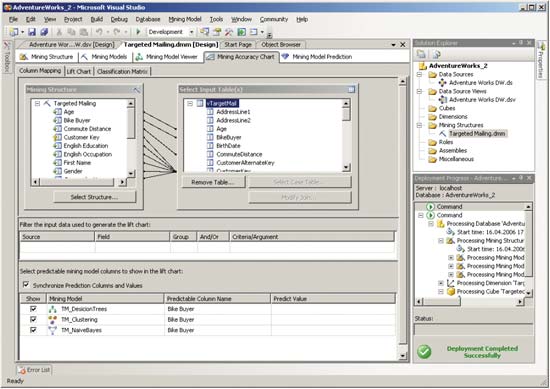
Рис. 13. Подготовка модели к оценке точности прогноза
Выбрав модели, подлежащие сравнению, мы можем получить графики, отображающие зависимость точности прогноза от объема выборки, использованной для обучения модели (рис. 14).
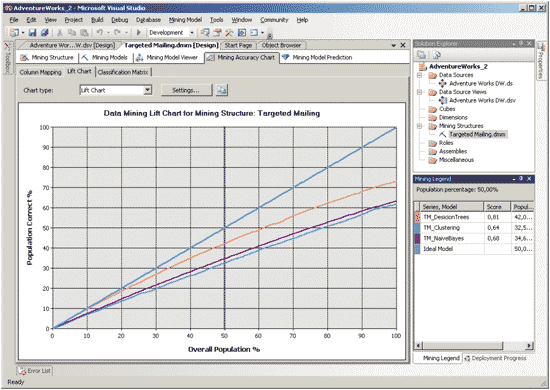
Рис. 14. Зависимость точности прогноза от объема выборки
Выполнение запросов к моделям
Построив модели и оценив их точность, в том случае, если последняя представляется удовлетворительной, можно перейти непосредственно к прогнозам. Для этой цели обычно создаются запросы на языке Data Mining Extensions (DMX), его описание можно найти в спецификации OLE DB for Data Mining на сайте корпорации Microsoft. Код запроса можно как написать вручную, так и сгенерировать с помощью инструмента Prediction Query Builder на закладке Mining Model Prediction инструмента Data Mining Designer (рис. 15).
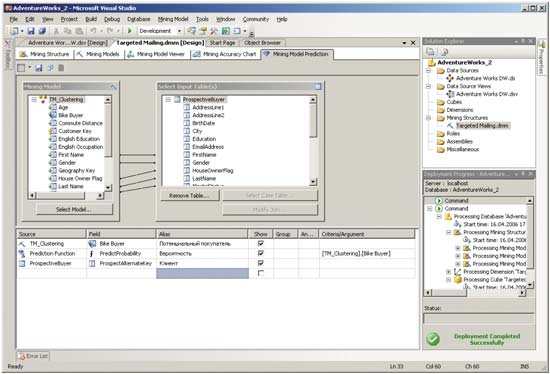
Рис. 15. Инструмент Prediction Query Builder
Типичный запрос, сгенерированный с помощью Prediction Query Builder, имеет примерно следующий вид:
SELECT
(t.[ProspectAlternateKey]) as [Клиент],
([TM_Clustering].[Bike Buyer]) as [Потенциальный покупатель],
(PredictProbability([TM_Clustering].[Bike Buyer])) as [Вероятность]
From
[TM_Clustering]
PREDICTION JOIN
OPENQUERY([Adventure Works DW],
‘SELECT
[ProspectAlternateKey],
[FirstName],
[LastName],
[MaritalStatus],
[Gender],
[YearlyIncome],
[TotalChildren],
[NumberChildrenAtHome],
[HouseOwnerFlag],
[NumberCarsOwned]
FROM
[dbo].[ProspectiveBuyer]
‘) AS t
ON
[TM_Clustering].[First Name] = t.[FirstName] AND
[TM_Clustering].[Last Name] = t.[LastName] AND
[TM_Clustering].[Marital Status] = t.[MaritalStatus] AND
[TM_Clustering].[Gender] = t.[Gender] AND
[TM_Clustering].[Yearly Income] = t.[YearlyIncome] AND
[TM_Clustering].[Total Children] = t.[TotalChildren] AND
[TM_Clustering].[Number Children At Home] = t.[NumberChildrenAtHome] AND
[TM_Clustering].[House Owner Flag] = t.[HouseOwnerFlag] AND
[TM_Clustering].[Number Cars Owned] = t.[NumberCarsOwned]
Типичные результаты прогнозирования для заранее сформированного набора данных представлены на рис. 16.
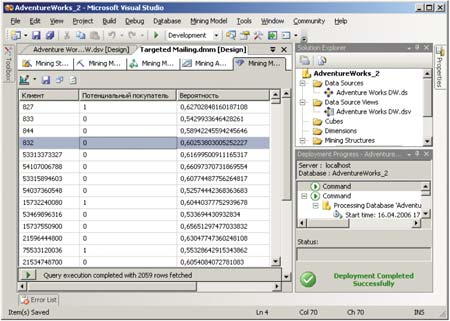
Рис. 16. Типичные результаты прогнозирования
Отметим, что подобные запросы можно применять в клиентских бизнес-приложениях, использующих средства Data Mining для осуществления прогнозов, необходимых конечным пользователям.
Заключение
Итак, мы рассмотрели основные шаги, которые обычно выполняются при построении моделей Data Mining, — это создание структуры, обучение модели, визуальный просмотр результатов обучения, оценка точности моделей, выполнение прогнозов. Мы также рассмотрели три из имеющихся алгоритмов Data Mining и особенности их реализации в SQL Server 2005, но число алгоритмов, доступных в указанной версии SQL Server, этим не ограничивается. Поэтому в последующих частях статьи мы продолжим обсуждение алгоритмов Data Mining.








