Средства бизнес-анализа в SQL Server 2005
Часть 4. Data Mining
Принципы создания решений с применением Data Mining
Алгоритмы Data Mining в SQL Server 2005
Средства для построения решений Data Mining
Ознакомиться с нейросетевыми алгоритмами можно в книге...
Обучаемые модели и самомодифицирующиеся алгоритмы относятся...
В предыдущей части данной статьи (№ 4’2005) мы рассказали о средствах модификации структуры OLAP-кубов в аналитических службах SQL Server 2005 для решения наиболее часто встречающихся задач. А теперь, начиная с этой части, мы будем рассматривать новшества в реализации средств Data Mining, доступных пользователям этой СУБД.
 о появления средств Data Mining в составе Microsoft SQL Server 2000 указанная технология традиционно относилась к числу дорогостоящих: цена некоторых продуктов, ее реализующих, доходила до нескольких десятков тысяч долларов, что позволяло применять ее главным образом для оценки кредитных и финансовых рисков в крупных банках и страховых компаниях. С включением средств Data Mining в состав Microsoft SQL Server 2000 эта технология стала доступной для предприятий малого и среднего бизнеса, а с выходом новой версии SQL Server у потребителей этой технологии заметно расширился выбор методов реализации.
о появления средств Data Mining в составе Microsoft SQL Server 2000 указанная технология традиционно относилась к числу дорогостоящих: цена некоторых продуктов, ее реализующих, доходила до нескольких десятков тысяч долларов, что позволяло применять ее главным образом для оценки кредитных и финансовых рисков в крупных банках и страховых компаниях. С включением средств Data Mining в состав Microsoft SQL Server 2000 эта технология стала доступной для предприятий малого и среднего бизнеса, а с выходом новой версии SQL Server у потребителей этой технологии заметно расширился выбор методов реализации.
Что такое Data Mining
 ловосочетанием Data Mining (от англ. mining — добыча полезных ископаемых) обычно называют поиск тенденций, взаимосвязей и закономерностей между данными посредством различных математических и статистических алгоритмов, таких как кластеризация, регрессионный и корреляционный анализ и т.д. Искомая информация зачастую является неочевидной, но ее ценность с позиции применения в стратегическом планировании или получения прогнозов может оказаться очень высокой.
ловосочетанием Data Mining (от англ. mining — добыча полезных ископаемых) обычно называют поиск тенденций, взаимосвязей и закономерностей между данными посредством различных математических и статистических алгоритмов, таких как кластеризация, регрессионный и корреляционный анализ и т.д. Искомая информация зачастую является неочевидной, но ее ценность с позиции применения в стратегическом планировании или получения прогнозов может оказаться очень высокой.
Выявление неочевидных зависимостей, как правило, не может быть осуществлено с помощью традиционной математической статистики или OLAP-средств (последние чаще всего применяются для проверки заранее сформулированных гипотез). Однако формулировка гипотезы зачастую представляется самой сложной задачей при реализации бизнес-анализа для поддержки принятия решений, вследствие чего поиск закономерностей методами, не использующими никаких предположений о характере этих закономерностей, может оказаться единственным способом получить прогноз развития какого-то процесса или оценить риск принятия какого-либо решения. Средства Data Mining отличаются от инструментов статистической обработки данных и средств OLAP тем, что вместо проверки заранее предполагаемых пользователями взаимозависимостей они на основании имеющихся данных могут находить такие взаимозависимости самостоятельно и строить гипотезы об их характере.
В качестве примера приведем задачу выбора печатных изданий для размещения рекламы определенного товара. При статистическом анализе или при использовании OLAP для решения такой задачи обычно формулируются вопросы типа «Каков процент купивших данный товар среди разведенных женщин со средним образованием?» или «Каков процент купивших данный товар среди программистов?», но применение Data Mining чаще всего подразумевает ответы на вопросы несколько иного вида, например «Существует ли типичная категория покупателей данного товара?». При этом именно ответ на данный вопрос нередко обеспечивает принятие успешного бизнес-решения.
Разумеется, применение средств Data Mining не исключает использования статистических инструментов и OLAP-средств, поскольку результаты обработки данных с помощью последних, как правило, способствуют лучшему пониманию характера закономерностей, которые следует искать. Для этого существуют средства Data Mining, способные выполнять поиск закономерностей и в реляционных, и в многомерных хранилищах данных.
Обычно выделяют пять стандартных типов закономерностей, выявляемых методами Data Mining:
- ассоциация — высокая вероятность связи событий друг с другом (например, приобретение контракта с оператором сотовой связи и мобильного телефона);
- последовательность — высокая вероятность цепочки связанных во времени событий (в течение какого-то времени после покупки жилья с высокой степенью вероятности будет приобретаться мебель);
- классификация — наличие признаков, характеризующих группу, к которой принадлежит то или иное событие либо объект (обычно при этом на основании анализа уже классифицированных событий формулируются определенные правила);
- кластеризация — закономерность, сходная с классификацией, но отличающаяся от нее тем, что сами группы не заданы, а выявляются автоматически, в процессе обработки данных;
- временные закономерности — шаблоны в динамике поведения тех или иных данных (типичный пример — сезонные колебания спроса на те или иные товары), используемых для прогнозирования.
Сегодня существует довольно много разнообразных методов исследования данных, среди которых можно выделить:
- регрессионный, дисперсионный и корреляционный анализ;
- методы анализа в конкретной предметной области, базирующиеся на эмпирических моделях;
- нейросетевые алгоритмы, основанные на аналогии с функционированием нервной ткани: исходные параметры рассматриваются как сигналы, преобразующиеся в соответствии с имеющимися связями между «нейронами», а в качестве ответа, являющегося результатом анализа, рассматривается отклик всей сети на исходные данные. Связи в этом случае создаются с помощью так называемого обучения сети посредством выборки большого объема, содержащей как исходные данные, так и правильные ответы;
- метод «ближайшего соседа» — выбор соответствующего аналога исходных данных из уже имеющихся накопленных данных;
- деревья решений — построение иерархической структуры, базирующейся на наборе вопросов с ответами «Да» или «Нет»;
- кластерные модели (модели сегментации) — применяются для объединения сходных событий в группы на основании сходных значений нескольких полей в наборе данных, а также весьма популярны при создании систем прогнозирования;
- алгоритмы ограниченного перебора, вычисляющие частоты комбинаций простых логических событий в подгруппах данных;
- эволюционное программирование — поиск и генерация алгоритма, выражающего взаимозависимость данных, на основании изначально заданного алгоритма, модифицируемого в процессе поиска.
Средства Data Mining в составе SQL Server впервые появились в 2000 году, когда в комплект поставки SQL Server 2000 вошли два алгоритма — построения деревьев решений и кластеризации, при этом существовала техническая возможность разработать собственный алгоритм и подключить его к данному продукту. В составе SQL Server 2005 содержатся уже семь алгоритмов, но, прежде чем приступить к их рассмотрению, следует уяснить, как создаются решения, использующие технологию Data Mining.
Принципы создания решений с применением Data Mining
 бщий принцип построения решений, использующих Data Mining, заключается в создании соответствующей модели, в ее обучении и тестировании, а также в разработке приложения, применяющего созданную модель для прогнозирования значений неизвестных атрибутов. При этом процессы создания и обучения модели включают обязательное использование большого по объему набора данных (training set), для которых известны значения атрибутов и прогнозирование которых предполагается в данной модели. Так, если модель предназначена для оценки риска несвоевременного возврата кредита, то набор данных должен содержать статистически значимое количество записей о заемщиках, о выданных им кредитах и о своевременности их возврата, и чем больше записей в этом наборе данных, тем точнее будут прогнозы, сделанные с помощью обученной модели. Перед созданием модели, предназначенной для реальной эксплуатации, иногда создается ее прототип, обучаемый на наборе данных меньшего объема, а другой набор (меньшего объема и не пересекающийся с предыдущим) предназначен для тестирования созданной модели или прототипа.
бщий принцип построения решений, использующих Data Mining, заключается в создании соответствующей модели, в ее обучении и тестировании, а также в разработке приложения, применяющего созданную модель для прогнозирования значений неизвестных атрибутов. При этом процессы создания и обучения модели включают обязательное использование большого по объему набора данных (training set), для которых известны значения атрибутов и прогнозирование которых предполагается в данной модели. Так, если модель предназначена для оценки риска несвоевременного возврата кредита, то набор данных должен содержать статистически значимое количество записей о заемщиках, о выданных им кредитах и о своевременности их возврата, и чем больше записей в этом наборе данных, тем точнее будут прогнозы, сделанные с помощью обученной модели. Перед созданием модели, предназначенной для реальной эксплуатации, иногда создается ее прототип, обучаемый на наборе данных меньшего объема, а другой набор (меньшего объема и не пересекающийся с предыдущим) предназначен для тестирования созданной модели или прототипа.
|
Ознакомиться с нейросетевыми алгоритмами можно в книге «Нейронные сети. Полный курс» Саймона Хайкина, выпущенной издательством «Вильямс» в этом году. Там можно найти математическое обоснование нейросетевых алгоритмов, описание компьютерных экспериментов в этой области, примеры практического применения.
|
||

После подготовки исходных наборов данных выбирается алгоритм Data Mining (при неочевидности такого выбора вначале обычно используются алгоритмы построения деревьев решений или простейшие нейросетевые алгоритмы), параметры работы алгоритма и входные поля (при неочевидности их выбора обычно выбираются все вероятные поля и параметры). В дальнейшем возможно уточнение модели, например отбрасывание параметров, не влияющих на прогнозируемый атрибут, либо выбор другого алгоритма (критерием окончательного выбора алгоритма и параметров является наибольшая точность прогнозов, определенная на основании тестирования модели с помощью предназначенного для этой цели набора данных).
После построения и обучения модели, предназначенной для реальной эксплуатации, следует создать приложение, осуществляющее прогноз. Указанное приложение должно, с одной стороны, получать набор параметров (в случае описанной выше задачи оценки кредитного риска — те сведения о клиенте банка, которые являются параметрами модели), а с другой — выполнять запрос с полученными параметрами к построенной и обученной модели и получать в качестве ответа прогноз (вероятность того, что данный клиент не вернет кредит вовремя).
Алгоритмы Data Mining в SQL Server 2005
 комплект поставки SQL Server 2005 входит семь алгоритмов Data Mining:
комплект поставки SQL Server 2005 входит семь алгоритмов Data Mining:
- алгоритм деревьев принятия решений (Microsoft Decision Trees) — алгоритм классификации, позволяющий прогнозировать как непрерывные, так и дискретные атрибуты. При построении модели по данному алгоритму оценивается степень влияния входных атрибутов на прогнозируемый атрибут, а его целью является нахождение комбинации входных атрибутов и их состояний, позволяющей осуществить корректное прогнозирование. Реализация подобного алгоритма подразумевает создание в процессе обучения модели иерархической структуры, базирующейся на наборе вопросов с ответами «Да» или «Нет» (рис. 1);
- байесовский алгоритм (Naпve Bayes) — рассчитывает вероятность, с которой каждое возможное состояние входного атрибута приводит к каждому возможному состоянию прогнозируемого атрибута. Алгоритм поддерживает только дискретные атрибуты и базируется на предположении, что все входные атрибуты влияют на прогнозируемый атрибут независимо друг от друга. Данный алгоритм относится к категории быстродействующих, поэтому его обычно используют на этапе первичного исследования данных. На этом алгоритме, в частности, основана работа многих антиспамовых фильтров;
- алгоритм нейронных сетей (Microsoft Neural Net) — основан на исследовании всех возможных взаимосвязей между данными. По причине очень тщательного исследования данных с помощью этого алгоритма он считается довольно медленным по сравнению с двумя предыдущими;
- алгоритм кластеризации (Microsoft Clustering) — использует итеративный процесс для группировки строк из набора данных в кластеры, которые содержат строки с одинаковыми или близкими по значению характеристиками. Этот алгоритм основан на объединении сходных событий в группы на основании похожих значений нескольких полей в наборе данных (рис. 2);
- алгоритм поиска ассоциаций (Microsoft Association) — обеспечивает эффективный метод нахождения корреляций в больших наборах данных за счет поиска наборов записей, появляющихся одновременно (например, сведений о товарах, купленных одновременно одним покупателем). На основании полученных сведений генерируются правила о том, какие категории записей должны появляться вместе с наибольшей вероятностью (например, какие другие товары обычно покупаются с данным товаром). Чаще всего этот алгоритм используется именно для анализа так называемых покупательских корзин в крупных торговых предприятиях с большим списком возможных товаров;
- алгоритм последовательной кластеризации (Microsoft Sequence Clustering) — сочетает анализ последовательности операций с кластеризацией, то есть, в отличие от обычных алгоритмов кластеризации, он учитывает последовательность возникновения событий. Данный алгоритм последовательной кластеризации используется для анализа маршрутов перемещения пользователей по страницам Web-сайтов и для их прогнозирования, а также для оценки влияния этих маршрутов на приобретение тех и иных товаров. Отметим, что данный алгоритм доступен в очень ограниченном количестве средств Data Mining;
- алгоритм временных рядов (Microsoft Time Series) — предназначен для прогнозирования значений величин, зависящих от времени, и основан на анализе тенденций, полученных на основе обучения модели (это биржевые котировки акций, объемы продаж того или иного товара).
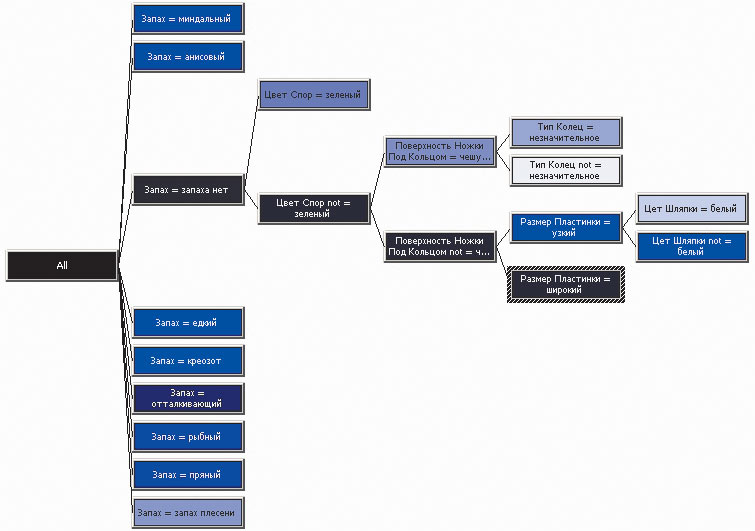
Рис. 1. Пример дерева решений
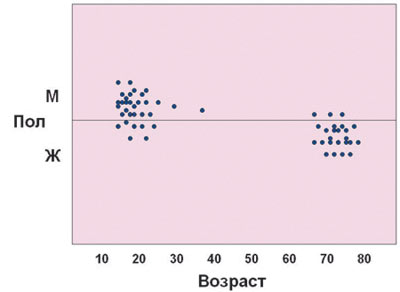
Рис. 2. Пример кластеризации данных
Помимо перечисленных алгоритмов, возможно применение алгоритма поиска в тексте (Text Mining), доступного с помощью служб SQL Server Integration Services. Данный алгоритм предназначен для анализа неструктурированного текста, содержащегося, к примеру, в длинных текстовых полях.
Алгоритмы кластеризации и построения деревьев решений были описаны в опубликованном несколько лет назад цикле статей «Введение в Data Mining» (его можно найти на нашем компакт-диске). Остальные алгоритмы будут рассмотрены в последующих частях данной статьи.
|
Обучаемые модели и самомодифицирующиеся алгоритмы относятся к набору технологий, объединенных общим названием «искусственный интеллект». Современные представления об этой области знаний представлены в книге «Искусственный интеллект. Современный подход» Стюарта Рассела и Питера Норвига, выпущенной издательством «Вильямс» в текущем году. В этой книге рассмотрены современные достижения и идеи, положенные в основу данной области знаний, а также приведены примеры алгоритмов, иллюстрирующих изложенные теоретические описания. Отметим, что изучение данного труда не требует серьезных профессиональных знаний, за исключением знакомства с основными понятиями информатики.
|
||

Средства для построения решений Data Mining
ля создания моделей Data Mining и их обучения предназначен инструмент Business Intelligence Development Studio из комплекта поставки SQL Server. С его помощью можно описывать и обучать модель, оценивать точность прогнозов, находить взаимосвязи между данными (рис. 3).
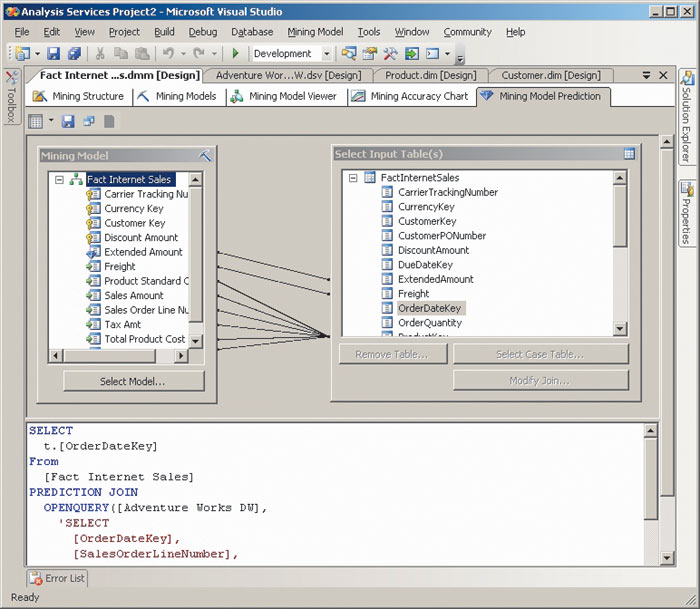
Рис. 3. Создание моделей Data Mining с помощью Business Intelligence Development Studio
Что касается приложений для конечных пользователей, применяющих Data Mining для построения прогнозов, то их следует создавать с помощью средств разработки приложений, например Microsoft Visual Studio (это может быть как Windows-, так и Web-приложение). Нестандартной частью таких приложений является выполнение запросов к модели — для этого используется язык запросов DMX (он описан в спецификации OLE DB for Data Mining, доступной на сайте корпорации Microsoft). Запросы на языке DMX можно писать и вручную, но в Business Intelligence Development Studio имеется графический инструмент для построения таких запросов — Prediction Query Builder.
Если же требуется не только осуществлять прогнозы с помощью готовой модели, но и снабдить приложение средствами построения моделей, похожими на имеющиеся в Business Intelligence Development Studio, то такая задача может быть решена с помощью библиотек Analysis Management Objects (AMO).
***
В последующих частях данной статьи мы рассмотрим применение некоторых алгоритмов Data Mining более подробно.








