Средства бизнес-анализа в SQL Server 2005
Часть 7. Прогнозирование взаимосвязанных событий
Алгоритм Microsoft Association Rules
Алгоритм Microsoft Sequence Clustering
В предыдущей статье данного цикла (см. КомпьютерПресс № 11’2006) речь шла о применении алгоритма временных рядов, используемого для прогнозирования поведения данных в будущем на основе информации об их поведении в прошлом. Сегодня, завершая наше знакомство со средствами бизнес-анализа в SQL Server 2005, мы рассмотрим алгоритмы Microsoft Association Rules и Microsoft Sequence Clustering, также впервые реализованные в версии SQL Server 2005 и предназначенные для прогнозирования взаимосвязанных событий.
Алгоритм Microsoft Association Rules
Общие принципы
Алгоритм Microsoft Association Rules предназначен для определения правил наиболее вероятного совместного появления нескольких объектов, например товаров, приобретенных одним и тем же клиентом или купленных совместно, и их применения для предсказания появления данного товара при наличии у клиента (или в заказе) других товаров. Анализ данных с целью выявления наиболее вероятных наборов товаров, приобретаемых совместно, или анализ так называемой корзины покупателя (market basket analysis), является основной сферой применения этого алгоритма (именно такой пример и будет рассмотрен ниже).
Данный алгоритм обеспечивает эффективный метод определения корреляций в больших наборах данных. Принцип его работы заключается в циклическом перемещении по таблице с исходными данными (например, по таблице транзакций, счетов, кассовых чеков) и нахождении наиболее вероятных наборов совместно появляющихся объектов (например, товаров в одном кассовом чеке). Такие наборы объектов (в данном примере — товаров) объединяются в группы, и на основе полученных групп формируются правила, которые потом можно использовать для прогнозирования.
Алгоритм Microsoft Association Rules чувствителен к выбору параметров, поэтому на небольших выборках и наборах объектов он может оказаться менее эффективным, нежели алгоритм деревьев принятия решений.
Создание и обучение модели
В предыдущих статьях была подробно рассмотрена последовательность создания моделей Data Mining с помощью SQL Server Business Intelligence Development Studio. Для выполнения описанного ниже примера можно воспользоваться либо готовым проектом, созданным во время изучения алгоритмов, рассмотренных в предыдущих статьях, либо создать новое представление источников данных в соответствии с описанием, приведенным в одной из предыдущих статей данного цикла (см. КомпьютерПресс № 3’2006). В нашем примере мы воспользовались готовой базой данных AdventureWorks, входящей в комплект поставки SQL Server 2005.
Как и в предыдущих случаях, следует приступить к созданию структуры модели (Mining Structure), выбрав соответствующий пункт контекстного меню папки Mining Structures, затем выбрать модель Data Mining (в данном случае — Microsoft Association Rules), используемое представление источников данных (в данном случае — AdventureWorksDW) , таблицы, содержащие строки, предназначенные для обучения модели (в данном случае — vAssocSecOrders и vAssocSecLineItems).
В примере следует также указать, какая из таблиц содержит сведения о случаях совместного появления объектов — case table (в данном случае — заказов) и о появлениях самих объектов — nested table (в данном случае — товаров) — рис. 1.

Рис. 1. Выбор таблиц со сведениями о случаях совместного появления объектов
и о появлениях объектов
Далее следует выбрать прогнозируемые атрибуты (значения которых в дальнейшем нужно будет предсказывать) и входные атрибуты (на основании которых будет осуществляться прогноз) — рис. 2.
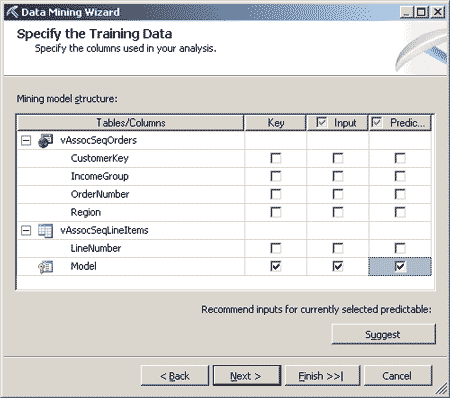
Рис. 2. Выбор входных и прогнозируемых атрибутов
Присвоим модели и структуре Data Mining имя Association и сохраним модель (рис. 3).
Рис. 3. Сохранение модели Data Mining
По аналогии с предыдущими примерами, помимо изменения состава используемых полей набора данных, можно вносить изменения и в их свойства.
Как уже было отмечено, на поведение модели, созданной с применением алгоритма Microsoft Association Rules, могут существенно влиять некоторые его параметры, в частности параметры Support и Probability. Первый из них равен минимальной доле случаев совместного появления объектов во всем наборе, которая считается существенной для формирования правил. Второй параметр равен минимальной вероятности ассоциации (совместного появления объектов), которая считается важной для формирования правил.
Изменим одно из свойств только что созданной модели. Для этого на закладке Mining Models выберем колонку Forecasting, а из ее контекстного меню — пункт Set Algorithm Parameters (рис. 4).
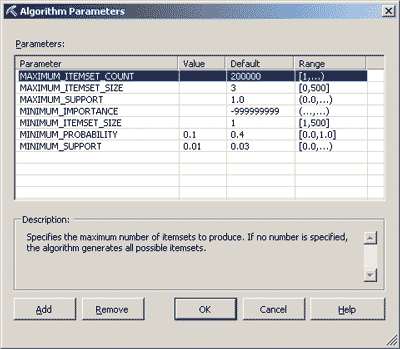
Рис. 4. Изменение свойств модели
Установим следующие значения параметров:
MINIMUM_PROBABILITY = 0.1
MINIMUM_SUPPORT = 0.01
Теперь можно приступать к обучению модели. Для этого, как и в предыдущих случаях, из того же контекстного меню колонки Forecasting выберем пункт Process Mining Structure and All Models и в диалоговой панели Process Mining Structure — Forecasting щелкнем на кнопке Run. В появившейся диалоговой панели Process Progress будет отображаться состояние процесса выполнения обучения модели, а также список выполняемых операций (рис. 5).
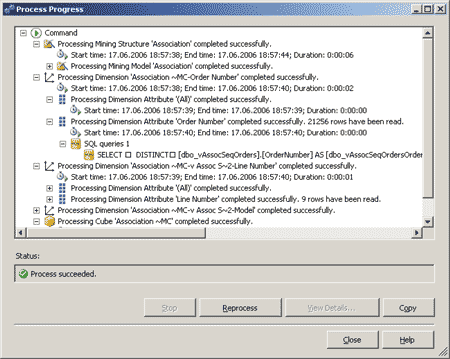
Рис. 5. Обучение модели Data Mining
В очередной раз напомним, что процесс обучения модели может оказаться весьма долгим, особенно в случае накопленного за много лет набора данных. В то же время процесс обучения моделей выполняется существенно реже, нежели процесс прогнозирования.
Результаты обучения модели
Для просмотра результатов обучения модели мы, как и в прошлый раз, воспользуемся средством Mining Model Viewer, содержащим в данном случае три закладки.
Закладка Itemsets отображает для каждого набора объектов (товаров) следующие данные: число заказов, в которых присутствует данный набор; количество товаров в наборе; состав набора. Эти данные можно фильтровать, выбирая минимальные значения числа заказов (в которых появляется набор) и количества товара в наборе. Можно также выбирать конкретные элементы наборов — к примеру, выбрав один из товаров, можно получить сведения о появлении в заказах различных наборов, включающих данный товар (рис. 6).
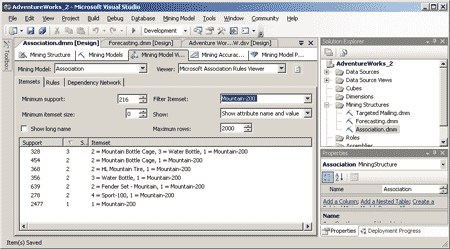
Рис. 6. Закладка Itemsets
Закладка Rules отображает правила, сформированные в результате обучения модели. Для каждого правила на ней отображаются формулировка, вероятность его выполнения и важность (то есть значимость факта его выполнения для прогнозирования, которая в большинстве случаев не связана с вероятностью). Эти данные можно фильтровать, выбирая наиболее важные правила или наиболее вероятные из них. Как и на закладке Itemsets, на закладке Rules можно также выбирать конкретные элементы наборов (рис. 7).
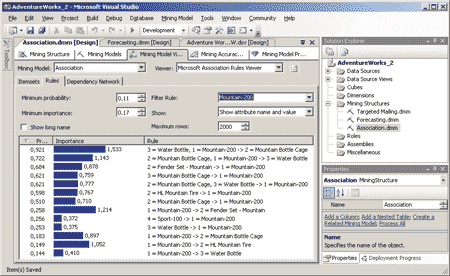
Рис. 7. Закладка Rules
Закладка Dependency Network позволяет исследовать связи между товарами в модели. Перемещая ползунок в соответствующем элементе управления в левой части данной закладки, можно менять вероятность возникновения правила, связывающего два товара, и наблюдать, как постепенно исчезают линии, отображающие наиболее слабые связи (рис. 8). Выбрав конкретный товар на закладке, можно проследить цепочку связей между ним и остальными товарами (товары, приобретаемые совместно с данным, плюс товары, приобретаемые совместно с этими товарами, и т.д.) — рис. 9.
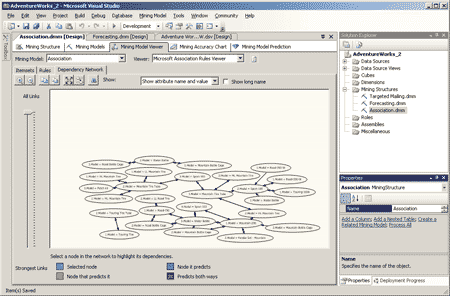
Рис. 8. Закладка Dependency Network — просмотр связей
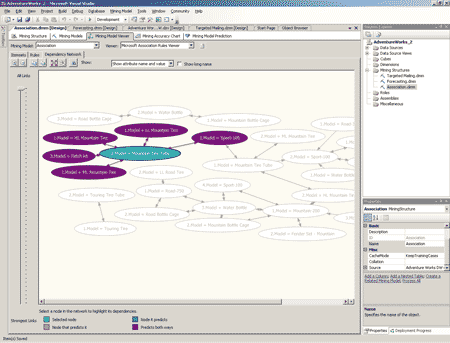
Рис. 9. Закладка Dependency Network — просмотр цепочки связей
для конкретного товара
***
Итак, мы рассмотрели применение алгоритма Microsoft Association Rules для выявления ассоциаций — правил совместного появления объектов, например товаров в заказах. Однако нередко может оказаться интересной и последовательность отбора товаров покупателями — поняв правила, на основе которых происходит подобный отбор, можно более эффективно проектировать и интернет-магазины, и обычные торговые точки. Алгоритму, который решает подобные задачи, будет посвящена следующая часть данной статьи.
Алгоритм Microsoft Sequence Clustering
Общие принципы
Алгоритм последовательной кластеризации (Microsoft Sequence Clustering) сочетает анализ последовательности операций с кластеризацией. Хотя этот алгоритм чувствителен к последовательности возникновения событий, он учитывает и другие атрибуты при группировке данных в кластеры, что позволяет создать модель, в которой есть корреляция между последовательной и непоследовательной информацией.
Алгоритм последовательной кластеризации используется для решения таких задач, как анализ маршрута перемещения пользователя по страницам при анализе трафика web-сайта, выявление страниц сайта, которые больше всего связаны с продажей определенного товара, прогнозирование наиболее вероятной последовательности посещения тех или иных страниц сайта. Еще одно применение этого алгоритма заключается в изучении и применении правил, по которым покупатели последовательно приобретают товары в интернет-магазинах.
Создание и обучение модели
Как и в предыдущем примере, нам следует создать структуру модели, но в качестве типа модели необходимо выбрать Microsoft Sequence Clustering. Выберем то же представление данных AdventureWorksDW и те же самые таблицы vAssocSecOrders и vAssocSecLineItems.
Далее следует задать прогнозируемые (значения которых в дальнейшем нужно будет предсказывать) и входные атрибуты (на их основании будет осуществляться прогноз) — рис. 10.
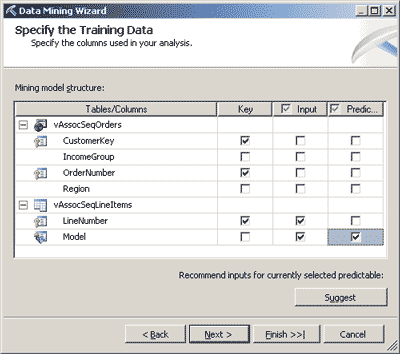
Рис. 10. Выбор входных и прогнозируемых атрибутов
Присвоим модели и структуре Data Mining имя Sequence Clustering и сохраним модель.
В данном случае можно воспользоваться значениями параметров модели, принятыми по умолчанию, поэтому можно сразу приступить к обучению модели, для чего, как и ранее, из контекстного меню колонки Forecasting выберем пункт Process Mining Structure and All Models и в диалоговой панели Process Mining Structure — Forecasting щелкнем на кнопке Run.
Результаты обучения модели
Для данного алгоритма средство просмотра Model Viewer содержит пять закладок.
Закладка Cluster Diagram отображает кластеры, найденные в базе данных в процессе обучения модели, и связи между ними. Интенсивность окраски значков кластеров по умолчанию соответствует количеству наборов в кластере, однако правила окрашивания этих значков можно менять, выбирая соответствующий атрибут и его состояние из выпадающих списков в верхней части закладки (рис. 11).
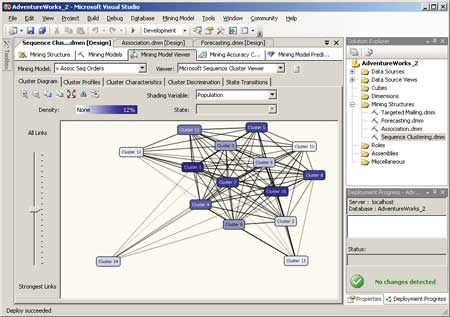
Рис. 11. Закладка Cluster Diagram
Закладка Cluster Profiles отображает последовательность возникновения событий (в данном примере — помещения товара в корзину в интернет-магазине) в каждом кластере, распределение товаров в каждом кластере, примеры поведения случайно выбранного пользователя из кластера (рис. 12).
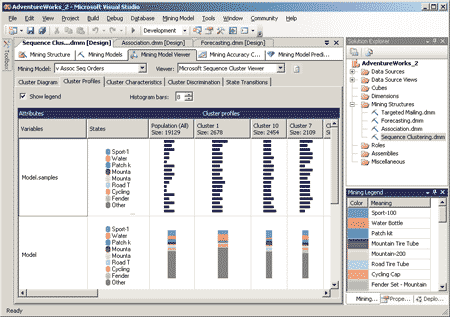
Рис. 12. Закладка Cluster Profiles
Закладка Cluster Characteristics для каждого кластера отображает различные смены состояний корзины в кластере, их вероятность и степень важности. На основе этих данных можно определить, какими именно действиями пользователя в первую очередь характеризуется выбранный кластер (например, помещением в корзину первым конкретного товара либо помещением одного товара вслед за другим) — рис. 13.
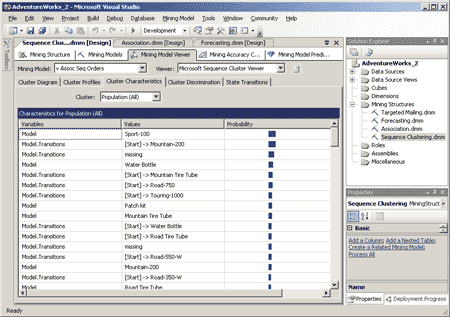
Рис. 13. Закладка Cluster Characteristics
Закладка Cluster Discrimination позволяет сравнивать кластеры между собой, определяя, какие корреляции между событиями соответствуют каждому из кластеров (рис. 14).
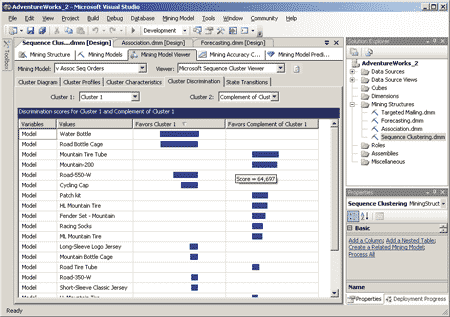
Рис. 14. Закладка Cluster Discrimination
Закладка State Transitions позволяет просмотреть возможные последовательности событий в кластерах. К примеру, выбрав кластер, соответствующий какому-либо товару, помещенному в корзину первым, можно определить вероятность последующего приобретения других товаров (рис. 15).
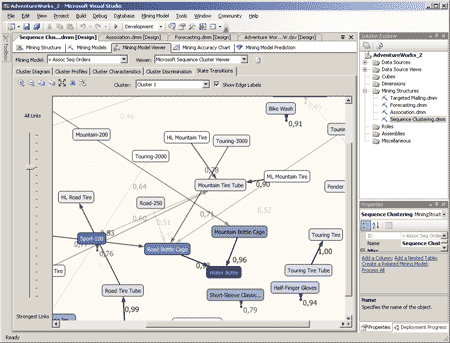
Рис. 15. Закладка State Transitions
Заключение
В настоящей статье мы рассмотрели алгоритмы, предназначенные для прогнозирования взаимосвязанных событий — Microsoft Association Rules и Microsoft Sequence Clustering, впервые реализованные в версии SQL Server 2005. На этом мы пока закончим рассмотрение алгоритмов Data Mining и других средств бизнес-анализа данной СУБД. Однако заметим, что в ожидаемой в этом году новой версии Microsoft Office будет много интересных средств применения и отображения результатов бизнес-анализа, предоставляемых аналитическими службами SQL Server 2005, поэтому вскоре мы снова вернемся к данной теме.








