AMD наносит ответный удар: графические процессоры серии ATI Radeon HD 2000
Графический процессор ATI Radeon HD 2900 XT
Архитектура процессора ATI Radeon HD 2900 XT в деталях
Унифицированные суперскалярные шейдерные процессоры
Кольцевая архитектура шины памяти
14 мая компания AMD анонсировала новое поколение графических процессоров (GPU) серии ATI Radeon HD 2000, ранее известное под кодовым названием R600. Одновременно с этим на базе новых GPU были представлены пять видеокарт, ориентированных на различные сегменты рынка. В этой статье мы рассмотрим особенности архитектуры новых графических процессоров серии ATI Radeon HD 2000.
Коротко о главном
Итак, свершилось! Спустя почти семь месяцев после выхода графического процессора NVIDIA GeForce 8800 (кодовое название чипа G80) компания AMD объявила о выходе долгожданных графических процессоров ATI Radeon HD 2000с поддержкой API Microsoft DirectX 10. Теперь и у компании AMD, и у компании NVIDIA имеются в ассортименте видеокарты с поддержкой API Microsoft DirectX 10.
Между графическими процессорами семейств ATI Radeon HD 2000 и NVIDIA GeForce 8800 очень много общего, и это не удивительно, поскольку аппаратная поддержка API Microsoft DirectX 10, реализованная в операционной системе Microsoft Vista, налагает определенные требования на архитектуру графического процессора. В то же время GPU NVIDIA GeForce 8800 и ATI Radeon HD 2000 имеют и существенные различия. Впрочем, не будем форсировать события. Прежде чем перейти к детальному рассмотрению архитектуры процессора ATI Radeon HD 2000, остановимся вкратце на ключевых особенностях новых GPU для дискретной графики. Итак, графические процессоры семейства ATI Radeon HD 2000 делятся на пять серий:
- ATI Radeon HD 2900 XT;
- ATI Radeon HD 2600 XT;
- ATI Radeon HD 2600 Pro;
- ATI Radeon HD 2400 XT;
- ATI Radeon HD 2400 Pro.
Видеокарты на базе GPU ATI Radeon HD 2900 XT — это высокопроизводительные, топовые решения, ориентированные в первую очередь на геймеров. Данные графические процессоры выполняются по 80-нм техпроцессу и содержат 700 млн транзисторов. Отметим, что в новой линейке GPU Radeon HD 2000 только процессоры ATI Radeon HD 2900 XT основаны на 80-нм технологии, а все остальные — на 65-нм. Скорее всего, первоначально предполагалось и топовые процессоры ATI Radeon HD 2900 XT выполнять по 65-нм техпроцессу, но, по-видимому, что-то не сложилось у AMD или TSMC, поскольку все графические процессоры ATI Radeon HD 2900 XT производятся компанией TSMC. Было бы логично предположить, что в будущем и эти процессоры будут выполняться по 65-нм техпроцессу, однако пока о таких планах компания AMD не заявляла.
Тактовая частота графического процессора ATI Radeon HD 2900 XT составляет 742 МГц. Видеокарты на базе GPU ATI Radeon HD 2900 XT имеют 512 Мбайт видеопамяти GDDR3, которая функционирует на частоте 828 МГц (эффективная частота — 1656 МГц). При этом ширина шины памяти составляет 512 бит, а пропускная способность — 106 Гбайт/с. Почему мы так уверены в том, что все видеокарты (независимо от вендора) на базе графического процессора ATI Radeon HD 2900 XT имеют одни и те же характеристики? Все очень просто. Ни одна компания не производит этих видеокарт самостоятельно, а потому все различия заключаются лишь в логотипах и упаковочных коробках. Соответственно под референсной видеокартой на базе графического процессора ATI Radeon HD 2900 XT (в дальнейшем — видеокарта ATI Radeon HD 2900 XT) можно понимать видеокарту любого производителя. Остается добавить, что рекомендованная стоимость видеокарт ATI Radeon HD 2900 XT составляет 399 долл.
Видеокарты на базе GPU ATI Radeon HD 2600 XT и ATI Radeon HD 2600 Pro (в дальнейшем — видеокарты ATI Radeon HD 2600 XT и ATI Radeon HD 2600 Pro) позиционируются как массовые решения. Они выполнены на базе графических процессоров ATI Radeon HD 2600 XT и ATI Radeon HD 2600 Pro соответственно, которые основаны на 65-нм технологии и содержат 390 млн транзисторов.
Тактовая частота процессора ATI Radeon HD 2600 XT составляет 800 МГц, а процессора ATI Radeon HD 2600 Pro — 600 МГц.
Видеокарты ATI Radeon HD 2600 XT и ATI Radeon HD 2600 Pro имеют 256 Мбайт видеопамяти. При этом может использоваться память GDDR2, GDDR3 и GDDR4, тактовая частота которой может составлять от 400 до 1100 МГц (эффективная частота — от 800 до 2200 МГц). С учетом того, что в этих видеокартах ширина шины памяти составляет 128 бит, пропускная способность шины памяти может варьироваться от 12,8 до 35,2 Гбайт/с.
Как видим, разнообразие поддерживаемой видеопамяти позволяет реализовать довольно большую линейку видеокарт на базе процессоров ATI Radeon HD 2600 XT и ATI Radeon HD 2600 Pro. Естественно, видеокарты ATI Radeon HD 2600 XT будут оснащаться более скоростной памятью, а видеокарты ATI Radeon HD 2600 Pro — менее скоростной. Рекомендованная стоимость видеокарты ATI Radeon HD 2600 XT составляет (в зависимости от типа памяти) от 179 до 199 долл., а видеокарты ATI Radeon HD 2600 Pro — от 99 до 129 долл.
Видеокарты на базе GPU ATI Radeon HD 2400 XT и ATI Radeon HD 2400 Pro относятся к бюджетным и построены на базе графических процессоров ATI Radeon HD 2400 XT и ATI Radeon HD 2400 Pro соответственно. Эти процессоры выполняются по 65-нм техпроцессу и содержат 180 млн транзисторов.
Тактовая частота процессора ATI Radeon HD 2400 XT составляет 700 МГц, а процессора ATI Radeon HD 2400 Pro — 525 МГц.
Видеокарты ATI Radeon HD 2400 XT и ATI Radeon HD 2400 Pro могут иметь 256 Мбайт видеопамяти GDDR3 или 256/128 Мбайт видеопамяти GDDR2. Тактовая частота памяти может быть равна от 400 до 800 МГц (эффективная частота от 800 до 1600 МГц). С учетом того, что в этих видеокартах ширина шины памяти составляет 64 бит, ее пропускная способность может варьироваться от 6,4 до 12,8 Гбайт/с.
Разнообразие и объем поддерживаемой видеопамяти позволяют реализовать весьма широкую линейку видеокарт на базе процессоров ATI Radeon HD 2400 XT и ATI Radeon HD 2400 Pro. Естественно, видеокарты ATI Radeon HD 2400 XT будут оснащаться более скоростной памятью, а видеокарты ATI Radeon HD 2400 Pro — менее скоростной. Остается добавить, что стоить они будут менее 99 долл.
Все видеокарты серий ATI Radeon HD 2000 объединяет одна ключевая особенность — поддержка API Microsoft DirectX 10. Соответственно графические процессоры ATI Radeon HD 2000 базируются на унифицированной шейдерной архитектуре с использованием потоковых процессоров. Кроме того, из аппаратной поддержки API Microsoft DirectX 10 следует и поддержка Shader Model 4.0. Новые процессоры поддерживают также функцию тесселяции, функцию AVIVO HD и многое другое. Впрочем, не будем забегать вперед. Детально об особенностях архитектуры новых процессоров мы расскажем далее, а пока, не вникая в детали, приведем сравнительную таблицу характеристик новых графических процессоров и видеокарт.
Технические характеристики видеокарт семейства ATI Radeon HD 2000
|
ATI Radeon HD 2400 Pro |
ATI Radeon HD 2400 XT |
ATI Radeon HD 2600 Pro |
ATI Radeon HD 2600 XT |
ATI Radeon HD 2900 XT |
Кодовое название процессора |
RV610 |
RV630 |
R600 |
||
Техпроцесс |
65 нм |
65 нм |
80 нм |
||
Количество транзисторов, млн |
180 |
390 |
700 |
||
Тактовая частота GPU, МГц |
525 |
700 |
600 |
800 |
742 |
Количество унифицированных шейдерных процессоров |
40 |
120 |
320 |
||
Количество текстурных блоков |
4 |
8 |
16 |
||
Количество модулей рендеринга |
4 |
4 |
16 |
||
Производительность (операции MAD), GigaFLOPS |
42 |
56 |
144 |
192 |
475 |
Скорость обработки пикселов, Гпикс/с |
4,2 |
5,6 |
14,4 |
19,2 |
47,5 |
Скорость обработки треугольников, треугольников/с |
262 млн |
350 млн |
600 млн |
800 млн |
740 млн |
Частота памяти, МГц |
400-800 |
400-1100 |
828 |
||
Тип памяти |
DDR-2/GDDR3 |
GDDR3/GDDR4 |
GDDR3 |
||
Объем памяти, Мбайт |
128/256 |
|
256 |
|
512 |
Ширина шины памяти, бит |
64 |
64 |
128 |
128 |
512 |
Пропускная способность шины памяти, Гбайт/с |
6,4-12,8 |
12,8-35,2 |
106 |
||
Типичное энергопотребление, Вт |
25 |
45 |
215 |
||
Графический процессор ATI Radeon HD 2900 XT
Итак, после краткого перечисления основных особенностей нового семейства GPU самое время ознакомиться с новинками более детально. Основное внимание мы сосредоточим именно на рассмотрении архитектуры графического процессора ATI Radeon HD 2900 XT. Впрочем, прежде чем разобраться во всем многообразии терминов, с которыми поневоле придется столкнуться при описании особенностей нового графического процессора, и понять, чем унифицированные шейдерные процессоры отличаются от классических вершинных и пиксельных, нам придется сделать небольшое отступление и рассказать о классической архитектуре графического процессора.
Общие понятия
На заре развития персональных компьютеров видеокарты выполняли функцию кадрового буфера. Это значит, что изображение формировалось центральным процессором компьютера и программным обеспечением, а карта отвечала лишь за его хранение (в буфере памяти) и вывод с определенной частотой отдельных кадров на монитор. По мере возрастания требований к качеству и реалистичности формируемого изображения, а также к скорости рендеринга отдельных кадров, пришло понимание того, что центральный процессор ПК, то есть процессор общего назначения, не в состоянии эффективно решать специфические задачи формирования трехмерного изображения и для этих целей необходим специализированный графический процессор (GPU), который занимался бы исключительно расчетом трехмерного изображения. Собственно, современные графические процессоры по сложности не уступают центральным процессорам (процессорам общего назначения), а их наличие заключается лишь в их специализации, благодаря которой они могут более эффективно справляться с задачей формирования изображения, выводимого на экран монитора.
Как и центральные, графические процессоры характеризуются такими параметрами, как микроархитектура, тактовая частота работы графического ядра и технологический процесс производства. Для графических процессоров существуют и специфические характеристики, которые обычно приводятся в технической документации. К примеру, к важнейшим характеристикам графического процессора относится число вершинных (Vertex Pipelines) и пиксельных (Pixel Pipelines) конвейеров.
Забегая вперед, скажем, что для построения трехмерного изображения необходимо выполнить целый ряд операций: принять решение, какие объекты (видимые и невидимые) вообще должны присутствовать в сцене, определить местоположение вершин, которые задают каждый из этих объектов, построить по этим вершинам грани, заполнить получившиеся полигоны текстурами в соответствии с освещением, степенью детализации и с учетом перспективных искажений и т.д. Чем тщательнее делаются все эти расчеты, тем реалистичнее получается трехмерное изображение. Повысить производительность этих рутинных операций можно, разбив их по стадиям (конвейеризовав) и распараллелив. Именно эти вопросы и решают графические процессоры.
На первом этапе графический процессор получает от центрального процессора данные об объекте, который необходимо построить. Эти данные обрабатываются в вершинном процессоре, или блоке (Vertex Pipeline), который является частью общего конвейера обработки данных. На основании полученных данных вершинный процессор занимается расчетом геометрии сцены и рассчитывает положение вершин, которые при соединении образуют каркасную модель трехмерного объекта. Кроме того, в вершинном процессоре производятся дополнительные операции над вершинами — преобразование и освещение (Transform & Lighting, T&L).
Обработка данных в вершинном процессоре происходит под управлением специализированной программы, называемой вершинным шейдером (Vertex Shader). Вершинные шейдеры осуществляют математические операции с вершинами, то есть предоставляют возможность выполнять программируемые алгоритмы по изменению параметров вершин и их освещению (T&L). Каждая вершина в 3D-модели определяется тремя координатами: X, Y и Z. Вершины также могут быть описаны характеристиками цвета, текстурными координатами и т.п. Вершинные шейдеры, в зависимости от алгоритмов, изменяют эти данные в процессе своей работы, например вычисляя и записывая новые координаты и цвет. Входными данными вершинного процессора являются данные об одной вершине геометрической модели, которая в тот или иной момент обрабатывается. Это могут быть координаты в пространстве, нормаль, компоненты цвета и текстурные координаты.
При помощи вершинных шейдеров вершинный процессор может выполнять такие операции, как деформация и анимация объектов, имитация ткани и многое другое.
На следующем этапе конвейера (Triangle) происходит сборка (Setup) трехмерной модели в полигоны. При этом вершины соединяются между собой линиями, образуя каркасную модель. При соединении вершин друг с другом образуются полигоны (треугольники).
После сборки данные поступают в пиксельный процессор (Pixel Pipeline), который определяет конечные пикселы, которые будут выведены в кадровый буфер. Пиксельный процессор в итоге своей работы выдает конечное значение цвета пиксела и Z-значение для последующего этапа конвейера. Пиксельный процессор функционирует под управлением специальной программы, называемой пиксельным шейдером (Pixel Shader). Пиксельные шейдеры — это программы, выполняемые пиксельными процессорами, во время растеризации для каждого пиксела изображения. Дабы данное определение не показалось уж слишком заумным, поясним, что подразумевается под понятием «растеризация». Это процесс разбиения объекта на отдельные точки — пикселы. Поскольку пиксельные шейдеры реализуют различные операции над отдельными пикселами, такие как затенение или освещение, текстурирование (операцию выполняет блок наложения текстур TMU), присвоение цвета, данных о прозрачности и т.п., то можно говорить, что пиксельный процессор работает на этапе растеризации.
Пиксельные шейдеры реализуют такие функции, как мультитекстурирование (наложение нескольких слоев текстуры), попиксельное освещение, создание процедурных текстур, постобработка кадра и т.д.
После обработки данных в пиксельном процессоре с использованием пиксельных шейдеров данные обрабатываются блоком растровых операций ROP (Raster Operations). На данном этапе с использованием буфера глубины (Z-буфера) определяются и отбрасываются те пикселы, которые не будут видны пользователю. Когда рассчитывается новый пиксел, его глубина сравнивается со значениями глубин уже рассчитанных пикселов с теми же координатами Х и Y. Если новый пиксел имеет значение глубины больше какого-либо значения в Z-буфере, новый пиксел не записывается в буфер для отображения.
Кроме буфера глубины, позволяющего отсекать невидимые поверхности, при создании реалистичных трехмерных изображений необходимо учитывать, что объекты могут быть полупрозрачными. Эффект полупрозрачности создается путем объединения цвета исходного пиксела с пикселом, уже находящимся в буфере. В результате цвет точки представляет собой комбинацию цветов переднего и заднего плана. Для учета прозрачности объектов используется так называемый alpha-коэффициент прозрачности, который имеет значение от 0 до 1 (для каждого цветового пиксела).
Описанная нами классическая архитектура графического конвейера дает наглядное представление об основных этапах формирования изображения видеокартой. При этом следует отметить, что в графическом процессоре используется не один, а несколько конвейеров, работающих параллельно, и чем больше в нем таких конвейеров, тем он более производительный. Действительно, если, к примеру, в графическом процессоре реализовано 16 конвейеров, то первый конвейер обрабатывает 1-й, затем 17-й, затем 33-й пиксел и т.д., второй — 2, 18 и 34-й соответственно.
Процесс развития графических процессоров до сих пор шел в одном направлении — увеличивалось число конвейеров. Понятие «конвейер» можно считать устойчивым, но не строгим техническим термином. Дело в том, что в графическом процессоре используются разные конвейеры, которые выполняют различные функции. В этом смысле более правильно говорить о вершинных или пиксельных конвейерах, но не о конвейерах вообще. Традиционно под конвейером понимали пиксельный процессор, который был подключен к своему блоку наложения текстур (TMU). Например, если у графического процессора (GPU) применяется восемь пиксельных процессоров, каждый из которых подключен к своему блоку TMU, то говорят, что у GPU восемь конвейеров. Тем не менее отождествлять число конвейеров с числом пиксельных процессоров не совсем корректно, поскольку конвейерная обработка подразумевает работу не только с пикселами, но и с вершинами, а значит, необходимо учитывать и количество вершинных процессоров. Поэтому число конвейеров может выступать в качестве корректной характеристики графического процессора только в том случае, если их количество совпадает с числом пиксельных и вершинных процессоров и блоков TMU. В то же время подобный подход к архитектуре графического процессора нельзя признать оптимальным. Дело в том, что такая линейная организация конвейера подразумевает равномерное распределение нагрузки между отдельными стадиями конвейера. Однако в реальных приложениях нагрузка на отдельные блоки графического процессора может быть различной. Отчасти решить проблему оптимизации нагрузки графического процессора позволяет такая архитектура, при которой количество пиксельных процессоров не совпадает с числом вершинных процессоров. При этом разработчикам приходится искать золотую середину между количеством вершинных и пиксельных процессоров, поскольку важно не переборщить с геометрическими характеристиками и в то же время не урезать красоты, получаемые мультитекстурированием и сложными пиксельными шейдерами.
Недостатки конвейерной обработки данных в графических процессорах можно было бы решить, перейдя к архитектуре унифицированных процессоров, при которой не существует отдельных вершинных или пиксельных процессоров, а есть процессоры общего назначения, способные исполнять как вершинные, так и пиксельные шейдеры. Естественно, для унифицированных процессоров потребуются и новые программы обработки, то есть шейдеры (Shader Model, SM). Унифицированные процессоры на аппаратном уровне поддерживаются API Microsoft DirectX 10, а это автоматически означает, что архитектура GPU основана именно на унифицированных процессорах.
Архитектура процессора ATI Radeon HD 2900 XT в деталях
Как уже отмечалось, одно из центральных мест в архитектуре графического процессора ATI Radeon HD 2900 XT занимает унифицированный шейдерный процессор, что позволяет избежать главного недостатка классической архитектуры — отсутствия сбалансированной нагрузки вершинных и пиксельных шейдеров.
Компания AMD называет эту архитектуру архитектурой унифицированных шейдеров второго поколения (2nd Generation Unified Shader Architecture). Дело в том, что впервые подобная архитектура была реализована в процессоре Xenos для игровой приставки XBOX 360.
Преимущества унифицированной шейдерной архитектуры можно объяснить следующим образом. Предположим, что в воображаемом графическом процессоре с классической архитектурой имеется четыре вершинных и восемь пиксельных процессоров. Если, к примеру, в игре используются преимущественно вершинные шейдеры (трехмерные модели с насыщенной геометрией), то может сложиться ситуация, что будут заняты все четыре вершинных процессора и только один пиксельный процессор, а оставшиеся семь пиксельных процессоров будут бездействовать. В этом случае производительность всего графического процессора будет определяться производительностью и количеством вершинных процессоров. В случае если в игре используются преимущественно пиксельные шейдеры (трехмерные модели с насыщенными пиксельными эффектами), то может возникнуть обратная ситуация, когда будет занят только один вершинный процессор и все семь пиксельных процессоров. И тогда производительность всего графического процессора будет определяться производительностью и количеством пиксельных процессоров.
Данной проблемы можно избежать, если вместо четырех вершинных и восьми пиксельных процессоров использовать 12 унифицированных шейдерных процессоров, которые могли бы выполнять как вершинные, так и пиксельные шейдеры.
Унифицированные суперскалярные шейдерные процессоры
Унифицированные шейдерные процессоры представляют собой суперскалярные процессоры общего назначения для обработки данных с плавающей запятой. Напомним, что традиционно в процессорах задействовано два тип математики: векторная и скалярная. В случае векторной математики данные (операнды) представляются в виде n-мерных векторов, при этом над большим массивом данных производится всего одна операция. Самый простой пример — задание цвета пиксела в виде четырехмерного вектора с координатами R, G, B, A, где первые три координаты (R, G, B) задают цвет пиксела, а последняя — его прозрачность. В качестве простого примера векторной операции можно рассмотреть операцию сложения цвета двух пикселов. При этом одна операция осуществляется одновременно над восемью операндами (двумя четырехмерными векторами).
В скалярной математике операции осуществляются над парой чисел. Понятно, что векторная обработка увеличивает скорость и эффективность обработки за счет того, что обработка целого набора (вектора) данных выполняется одной командой.
До недавнего времени векторная архитектура являлась в какой-то мере традиционной для графических процессоров, то есть в графических процессорах предыдущего поколения применялась векторная архитектура исполнительных блоков.
Вместе с тем многие инструкции в шейдерах не используют все компоненты векторов. Поэтому в GPU до DirectX 9 применялась так называемая функция recall, которая описывала способ объединения двух инструкций в одну. К примеру, можно применять разные операции к значениям цвета (вектор из трех элементов, vec3) и к альфа-уровню. В этом случае вместо одной векторной команды над четырехмерными векторами необходимо выполнить одну векторную операцию для трехэлементных векторов плюс одну скалярную операцию (схема «3+1»).
Векторные исполнительные блоки в графических процессорах ATI X1000 работают по схеме 3+1, то есть способны выполнять за такт одну векторную операцию над четырехэлементными векторами или одну векторную операцию для трехэлементных векторов плюс одну скалярную операцию. Векторные исполнительные блоки в графических процессорах NVIDIA GeForce 6x работают по схеме «2+2», то есть способны выполнять одновременно две векторные операции для двухэлементных векторов или одну векторную операцию для четырехэлементных векторов. В графическом процессоре NVIDIA GeForce 8800 применяются полностью скалярные блоки, которые работают по схеме «1+1+1+1». Теоретически такой подход обеспечивает большую гибкость.
В графических процессорах семейства ATI Radeon HD 2000 также используются скалярные блоки, которые называются суперскалярными потоковыми процессорами (Stream Processing Untits, SPU)
Всего в процессоре ATI Radeon HD 2900 XT применяется 64 SPU, каждый из которых способен одновременно выполнять пять скалярных инструкций. Каждый SPU состоит из пяти унифицированных суперскалярных шейдерных процессоров и одного модуля ветвлений (Branch Execution Unit) — рис. 1.
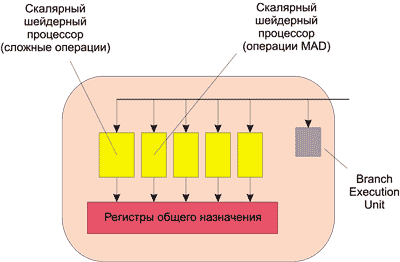
Рис. 1. Структура исполнительного блока
в процессорах семейства ATI Radeon HD 2000
Таким образом, в графическом процессоре ATI Radeon HD 2900 XT используется 320 скалярных унифицированных шейдерных процессоров, что по сравнению с 128 унифицированными процессорами в GPU NVIDIA GeForce 8800 выглядит весьма впечатляюще.
Однако сравнение «в лоб» в данном случае не вполне корректно. Действительно, в процессоре ATI Radeon HD 2900 XT исполнительные блоки могут одновременно работать с пятью полями данных, однако сами блоки не идентичны. Дело в том, что сложные инструкции (SIN, COS, LOG) могут выполняться только с одним полем данных, а с остальными четырьмя производятся только самые простые инструкции умножения или сложения (Multiply-Add, MAD). В идеальном случае каждый из 64 исполнительных блоков в процессоре ATI Radeon HD 2900 XT может выполнять пять MAD-операций над скалярами. В результате получается, что в процессоре ATI Radeon HD 2900 XT одновременно может быть реализовано 320 операций MAD. При этом в процессоре GeForce 8800 может одновременно выполняться 128 скалярных операций, однако это могут быть сложные операции, а не только простые, как в случае процессора ATI Radeon HD 2900 XT.
Архитектура ядра
Теперь более детально рассмотрим архитектуру самого ядра GPU ATI Radeon HD 2900 XT.
Как уже отмечалось, данный графический процессор включает 320 унифицированных суперскалярных шейдерных процессоров, которые сгруппированы в 64 блока; структурная схема ATI Radeon HD 2900 XT представлена на рис. 2.
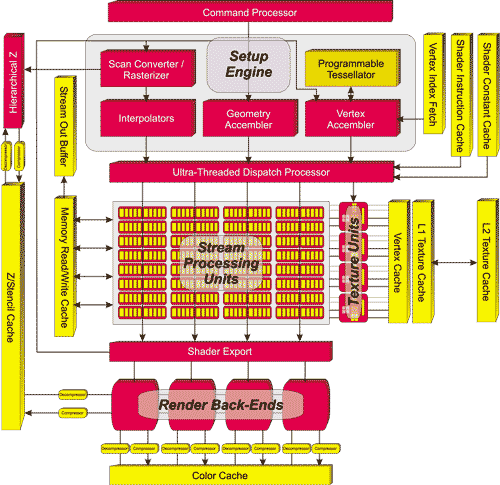
Рис. 2. Структурная схема графического процессора
ATI Radeon HD 2900 XT
В этом процессоре используется диспетчер задач (Ultra-Threaded Dispatch Processor), который распределяет потоки задач на 64 SPU, а также четыре текстурных модуля, которые отвечают за выборку текстурных и вертексных данных (рис. 3).
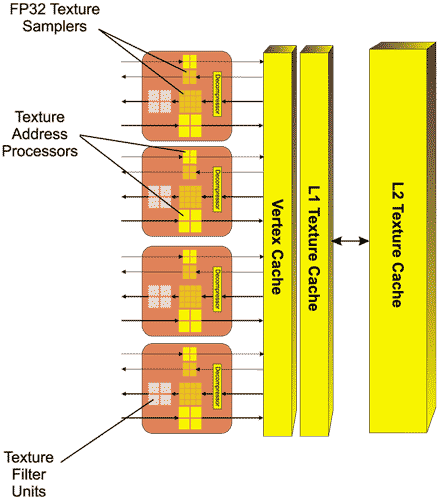
Рис. 3. Текстурные модули в процессоре ATI Radeon HD 2900 XT
Каждый текстурный модуль имеет четыре модуля фильтрации текстур (Texture Filtering Unit, TF) и четыре модуля адресации текстур (Texture Address Unit, TA). Данный модуль связан с двухуровневым кэшем текстур L1 и L2, а также с вертексным кэшем.
Текстурные модули работают с новым 32-битным HDR-форматом текстур, поддерживают полноскоростную билинейную фильтрацию 64-битных HDR-текстур, фильтрацию 128-битных текстур на половинной скорости, а трилинейная и анизотропная фильтрация поддерживается для всех форматов текстур. При этом максимальный размер поддерживаемых текстур составляет 67 мегатекселей (8192x8192).
Отметим, что текстурные модули, как и все остальные компоненты графического процессора, работают на одной и той же частоте (742 МГц для ATI Radeon HD 2900 XT). Об этом необходимо упомянуть потому, что в графическом процессоре GeForce 8800 потоковые процессоры работают на частоте, отличающейся от частоты всего остального ядра. Так, в процессоре GeForce 8800 GTX потоковые процессоры работают на частоте 1350 МГц, а все остальные компоненты процессора — на частоте 575 МГц. Именно поэтому прямое сравнение процессоров GeForce 8800 GTX и ATI Radeon HD 2900 XT по частотам не вполне корректно.
Говоря о частотах, отметим, что при тактовой частоте ядра ATI Radeon HD 2900 XT в 742 МГц теоретическая производительность достигает 475 гигафлоп. Однако еще раз подчеркнем, что речь идет только об операциях MAD. Соответственно в режиме CrossFire пиковая производительность достигает 950 Гфлоп.
Если пересчитать приведенные цифры в удельную производительность в расчете на 1 мм2 площади кристалла, то получим более 1 Гфлоп на 1 мм2, что является своеобразным рекордом. Аналогично производительность в расчете на ватт потребляемой мощности составляет 3,4 Гфлоп, что также можно считать рекордом.
Кольцевая архитектура шины памяти
В процессорах семейства ATI Radeon HD 2000 используется кольцевая архитектура шины памяти, которая впервые была реализована в процессорах серии ATI Radeon X1000. Однако в процессорах ATI Radeon HD 2000 кольцевая шина памяти подверглась существенной переработке (рис. 4).
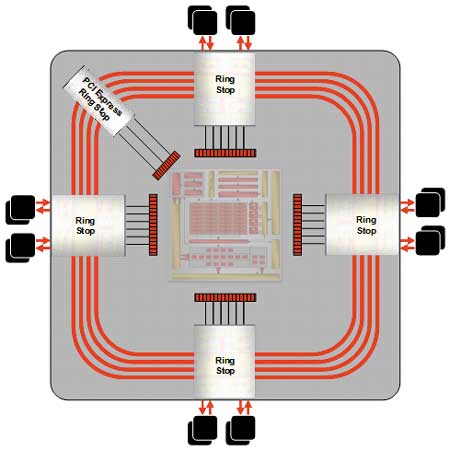
Рис. 4. Структурная схема контроллера памяти
с кольцевой архитектурой
Шина памяти имеет кольцевую топологию и состоит из двух (одна на чтение, другая на запись) противоположно направленных кольцевых шин разрядностью по 512 бит (в случае процессора ATI Radeon X1800 разрядность кольцевых шин составляла 256 бит). Напомним, что при традиционной архитектуре (не кольцевой) контроллер памяти оснащается 256-битной шиной, разделенной на четыре 64-битных канала. Вместо четырех 64-битных каналов памяти, подключенных к большому интегрированному кэшу, в контроллере памяти ATI Radeon HD 2000 используются четыре блока Ring Stop, связанных друг с другом по кольцевой шине. Каждый Ring Stop связан по 64-битным каналам с двумя модулями памяти, имеющими 32-битный интерфейс, то есть всего используется восемь модулей памяти с 64-битным интерфейсом, что в сумме дает 512-битный интерфейс памяти. Отметим, что в данном случае модуль памяти не отождествляется с чипом памяти. Например, один модуль может состоять из двух чипов памяти, каждый из которых имеет 32-битный интерфейс.
Принцип работы контроллера памяти с кольцевой архитектурой довольно прост. Внутри графического процессора содержатся клиенты, которым необходим доступ к памяти. Когда один из этих клиентов требует данные, отсутствующие в кэше, клиент посылает по кольцевой шине запрос на получение данных. После считывания из памяти требуемые данные отсылаются по кольцевой шине до блока Ring Stop, который находится ближе всего к устройству, сделавшему запрос. После этого блок Ring Stop, который выступает в роли получателя данных, передает их запросившему устройству.
Отметим, что в процессорах серии ATI Radeon X1000 кольцевая архитектура была лишь частичной. Запросы данных отправлялись контроллером памяти напрямую к чипам, а кольцевая шина использовалась только как канал для ответа. В процессорах семейства ATI Radeon HD 2000 применяется полностью распределенная технология кольцевой шины (Fully Distibuted), при которой запросы и ответы передаются по одной и той же шине.
Среди нововведений кольцевой шины, реализованной в ATI Radeon HD 2000, отметим прямую связку этой шины с шиной PCI Express x16 (посредством PCI Express Ring Stop). Это должно улучшить производительность конфигураций CrossFire.
Блок тесселяции
Одним из нововведений, реализованных в графических процессорах серии ATI Radeon HD 2000, является программируемый модуль тесселяции. В данном случае он является скорее наследием процессора Xenos для игровой приставки XBOX 360, нежели реальной необходимостью, поскольку в текущей версии API Microsoft DirectX 10 тесселяция не поддерживается на программном уровне. Возможно, в очередных версиях DirectX будет реализована поддержка тесселяции, однако на данный момент это не более чем красивая маркетинговая «фишка».
Принцип тесселяции достаточно прост. Тесселяция — это способ динамического превращения простых структур в более сложные полигональные модели путем рекурсивного выполнения операций на сетке полигонов (рис. 5).
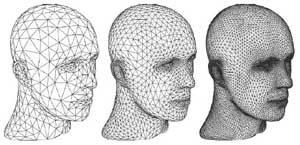
Рис. 5. Принцип тесселяции
Казалось бы, зачем нужна тесселяция, то есть возможность динамического изменения числа полигонов, если можно изначально создать объект с большим числом полигонов? Действительно, если объект находится близко, то для придания реалистичности можно сразу использовать сетку с большим числом полигонов. Однако по мере удаления объекта такой подход становится неоптимальным, поскольку на качестве картинки это не скажется и ресурсы процессора будут израсходованы впустую. Для удаленных объектов целесообразно применять сетки с невысоким числом полигонов.
Именно поэтому разработчики зачастую идут на компромисс, используя среднее число полигонов. Конечно, такой подход далек от совершенства, и тесселяция позволяет избежать проблем, связанных с необходимостью применения разного числа полигонов на сетке при приближении и удалении одного и того же объекта. В каком-то смысле тесселяция напоминает mip-уровни для текстур, когда используются различные детализации одной и той же текстуры в зависимости от положения объекта на экране.
Новые режимы антиалиасинга
В графических процессорах серии ATI Radeon HD 2000 реализованы новые режимы полноэкранного сглаживания (антиалиасинга, AA).
Так, помимо 8x Multi-Sample AA процессоры поддерживают режим CFAA (Custom Filter Anti-Aliasing) (4x, 6x, 8x, 12x, 16x, 24x CFAA). Кроме того, процессоры поддерживают режимы HDR+AA, Adaptive SSAA/MSAA, Temporal AA и Super AA.
Технология AVIVO HD
Технология AVIVO HD, реализованная на аппаратном уровне во всех видеокартах на процессорах семейства ATI Radeon HD 2000, является логическим продолжением технологии AVIVO, на которой базируются видеокарты на базе графических процессоров ATI предыдущих поколений.
Данная технология предназначена для высококачественной аппаратной обработки HD-видео. Аппаратная реализация ATI Avivo HD включает два модуля: универсальный видеодекодер UVD (Universal Video Decoder) и расширенный видеопроцессор AVP (Advanced Video Processor). Обработка видеоконтента с помощью UVD поддерживает обработку форматов VC-1 и H.264, что позволяет разгрузить CPU при работе с современными HD DVD/Blu-ray дисками.
Заключение
Итак, после краткого знакомства с новой линейкой графических процессоров ATI Radeon HD 2000 еще раз напомним, что эти процессоры изначально задумывались как ответный ход компании AMD на графические процессоры NVIDIA серии GeForce 8800. Правда, вышли они со значительным опозданием. Впрочем, торопиться не было смысла. Ведь главная «фишка» видеокарт на этих графических процессорах — это аппаратная поддержка API Microsoft DirectX 10, который реализован только в операционной системе Windows Vista. Мало того что эта операционная система пока еще не получила признания пользователей и никто особенно не спешит на нее переходить — даже если предположить, что это произойдет, все равно игр под DirectX 10 нет, а значит, нет и особого смысла использовать такие видеокарты.
Конечно, компания AMD задержалась с выходом графических процессоров ATI Radeon HD 2000 отнюдь не потому, что торопиться не имело смысла. Конкурентная борьба между NVIDIA и AMD подразумевает, что каждый шаг одной компании тут же порождает ответный ход другой. После выхода графического процессора GeForce 8800GTX, который установил новый рекорд производительности, ожидалось, что компания AMD выпустит еще более производительный процессор R600 (ATI Radeon HD 2900 XT). Однако этого не произошло. Процессор ATI Radeon HD 2900 XT оказался не столь производительным, как того хотелось, и конкурировать с GeForce 8800GTX не в состоянии. А потому компании AMD пришлось пересмотреть ценовую нишу для этого продукта. В результате видеокарты ATI Radeon HD 2900 XT по цене являются конкурентами видеокарт NVIDIA GeForce 8800GTS, а по производительности превосходят их. Тем не менее если речь заходит о топовых решениях, когда производительность стоит на первом месте, то у компании NVIDIA конкурентов нет. Этот сегмент рынка пока еще не «по зубам» компании AMD.
В следующем номере нашего журнала мы проведем детальное сравнительное тестирование видеокарт AMD и NVIDIA и постараемся более мотивированно показать, кто и в каком сегменте лидирует и по производительности, и по цене, и по соотношению «цена/качество».








