Долгожданные процессоры с микроархитектурой AMD K10
Процессоры семейства AMD Opteron
Процессоры семейства AMD Phenom
Особенности микроархитектуры AMD K10
Технология AMD Memory Optimizer Technology
Предвыборка данных и инструкций
Предсказание переходов и ветвлений
Диспетчеризация и переупорядочивание микроопераций
Новые технологии энергосбережения
На одной из пресс-конференций компании Intel на вопрос, когда же наконец она начнет производить подлинные, а не псевдочетырехъядерные процессоры, представитель Intel ответил, что подлинные процессоры — это те, которые продаются в магазинах, а не те, которые существуют лишь в воображении маркетологов AMD.
Конечно, неискушенный читатель может и не понять, в чем тут ирония и почему, собственно, различают псевдочетырехъядерные процессоры и подлинные четырехъядерные процессоры. Дело в том, что четырехъядерные процессоры компании Intel (речь идет о семействе серверных процессоров Intel Xeon и семействе процессоров Intel Core 2 Quad) имеют схему 2x2 и, по сути, представляют собой два двухъядерных процессора, объединенных в одном корпусе. При этом каждый двухъядерный процессор, входящий в состав четырехъядерного, выполнен на едином кристалле, а потому является истинным двухъядерным процессором, четырехъядерный же процессор, объединяющий в себе два истинных двухъядерных, называют псевдочетырехъядерным. Впрочем, термин «псевдочетырехъядерный» не нравится маркетологам компании Intel, зато он пришелся по душе маркетологам AMD. Собственно, это неслучайно. Дело в том, что если использовать слова «подлинный» и «псевдо», то новые четырехъядерные процессоры AMD, известные под кодовым названием Barcelona, как раз являются подлинными четырехъядерными процессорами, так как в них все четыре ядра выполнены на одном кристалле.
Конечно, четырехъядерные процессоры Barcelona появились существенно позже четырехъядерных процессоров Intel, что дало неоспоримое преимущество компании Intel по завоеванию рынка. Да и на процессорную микроархитектуру Intel Core в сегменте топовых моделей процессоров компании AMD долгое время ответить было нечем. На всех презентациях маркетологи компании AMD заявляли, что когда они выйдут на рынок с новой архитектурой процессора, вот тогда и покажут Intel кузькину мать. Это, конечно, не дословные их заявления, но смысл речей был именно такой. И вот наконец-то пришла пора показать кузькину мать всяким там псевдочетырехъядерным процессорам. 10 сентября компания AMD объявила о выходе настоящих, истинных четырехъядерных процессоров Barcelona.
«Сегодня компания AMD представила самый передовой в мире подлинно четырехъядерный процессор на базе архитектуры x86» — именно так говорится в официальном пресс-релизе. Правда, речь пока идет только о серверных процессорах семейства AMD Opteron. Но, как следует из того же официального пресс-релиза, ожидается, что в декабре текущего года станут доступны решения на базе процессора AMD Phenom для настольных ПК, который предоставляет преимущества инновационной четырехъядерной архитектуры AMD нового поколения. То есть, попросту говоря, в декабре компания AMD планирует представить подлинные четырехъядерные процессоры для ПК, которые образуют новое семейство AMD Phenom.
«Сегодня произошло одно из крупнейших событий в микропроцессорной отрасли — AMD снова поднимает планку стандартов производительности, — заявил председатель Совета директоров, президент и исполнительный директор корпорации AMD Гектор Руиз (Hector Ruiz). — Мы уделяли особое внимание требованиям наших заказчиков и партнеров при создании нового поколения решений, воплощенного в объявленном сегодня процессоре AMD Opteron — четырехъядерном лидере по части производительности, энергетической эффективности, виртуализации и защите инвестиций. Первые отклики пользователей были очень позитивными». Что ж, судя по официальным заявлениям руководства компании, хотели показать кузькину мать — и показали.
Более того, 17 сентября компания AMD преподнесла еще один сюрприз — объявила о добавлении трехъядерных процессоров AMD Phenom в планы выпуска своей продукции для настольных ПК, которые станут доступны уже в I квартале 2008 года. Вот этого никто не ожидал. Двухъядерные процессоры — это понятно, четырехъядерные — тоже понятно, а вот трехъядерные выглядят как-то нелогично. Хотя… может быть, очень даже логично. Понятно, что запускать отдельное производство трехъядерных процессоров на базе микроархитектуры, которая изначально оптимизирована под четырехъядерные процессоры, совершенно нелогично и экономически невыгодно. Да и нет у компании AMD столько фабрик, чтобы позволить себе такую роскошь. А потому совершенно очевидно, что трехъядерные процессоры AMD Phenom производятся на той же фабрике, что и четырехъядерные. Казалось бы, зачем это нужно? Ведь выгоднее продавать именно четырехъядерные, а не трехъядерные процессоры. Что ж, это действительно так, да и производство трехъядерных процессоров изначально не значилось в планах компании AMD. Но изготавливать четырехъядерные процессоры AMD Phenom оказалось не так-то просто, и рискнем предположить, что во многих кристаллах четвертое ядро просто не завелось. То есть процент брака оказался выше ожидаемого. Что же делать? Не выбрасывать же, в самом деле, весь кристалл, если брак заключается только в том, что одно ядро не работает, — так ведь и разориться можно! Куда проще отключить неработающее ядро и продавать процессор как трехъядерный. Собственно, идея «урезания» процессора отнюдь не нова. Вспомните процессоры семейства Celeron или Sempron с урезанным кэшем. Да и при производстве графических процессоров ситуация, когда из старшей модели процессора делают младшую путем урезания числа конвейеров, вполне типична. А учитывая, что недавно компания AMD приобрела фирму ATI, опыта у нее, как пристроить некондицию, накоплено более чем достаточно. Другое дело, что в плане «обрезания» ядер в процессорах компания AMD стала пионером.
Итак, хотели как лучше, а получилось… Хотя, конечно, маркетологи компании AMD тоже свой хлеб недаром кушают. Напряглись и… подвели под это дело аж целую теорию, неопровержимо доказывающую, что трехъядерные процессоры — это отнюдь не способ пристроить отбраковку, возникающую при производстве четырехъядерных процессоров, а ответ компании на пожелания трудящихся, так как эти процессоры наиболее востребованы рынком.
«Будучи первыми в мире процессорами для настольных ПК с тремя ядрами на одном кристалле, процессоры AMD Phenom способствуют распространению высокого визуального качества, производительности и многозадачной обработки, присущих многоядерной технологии, на более широкий круг пользователей. Рассчитанный на самые современные платформы и архитектуру нового поколения, единственный в отрасли трехъядерный процессор AMD Phenom даст компании значительное конкурентное преимущество за счет расширения ассортимента продукции для пользователей, делая им уникальное предложение», — вот что говорится в официальном пресс-релизе.
Впрочем, хватит иронии в адрес AMD. В конце концов, никакой, даже самый плохой маркетинг не сможет испортить хорошего продукта (хотя обратное верно далеко не всегда). Новая процессорная микроархитектура AMD K10, на основе которой будут построены все новые семейства процессоров AMD, действительно имеет много интересных особенностей и заслуживает пристального внимания. Ну а тот факт, что новые процессоры AMD смогут успешно конкурировать с процессорами Intel даже в сегменте топовых моделей процессоров, у многих не вызывает сомнения.
Итак, прежде чем переходить к описанию особенностей новой микроархитектуры, давайте ознакомимся с новыми семействами процессоров AMD и с планами по их выпуску.
Новые семейства процессоров
Итак, на базе новой микроархитектуры AMD K10 будут выпускаться как серверные процессоры, так и процессоры для ПК.
Процессоры семейства AMD Opteron
Серверные четырехъядерные процессоры (кодовое название Barcelona), как и прежде, будут образовывать семейство Opteron. На данный момент уже анонсированы модели процессоров серий Opteron 8300 и Opteron 2300 с максимальной тактовой частотой 2 ГГц и энергопотреблением до 95 Вт. В дальнейшем компания AMD собирается представить на рынке более «скоростные» процессоры с тактовой частотой до 2,5 ГГц и энергопотреблением 120 Вт.
Характеристики всех моделей серверных процессоров Barcelona представлены в Долгожданные процессоры с микроархитектурой AMD K10 1.
Таблица 1. Серверные процессоры Barcelona
Модель процессора |
Тактовая частота, ГГц |
TDP, Вт |
Opteron 2350 |
2,0 |
95 |
Opteron 2347 |
1,9 |
95 |
Opteron 2347 HE |
1,9 |
68 |
Opteron 2346 HE |
1,8 |
68 |
Opteron 2344 HE |
1,7 |
68 |
Opteron 8350 |
2,0 |
95 |
Opteron 8347 |
1,9 |
95 |
Opteron 8347 HE |
1,9 |
68 |
Opteron 8346 HE |
1,8 |
68 |
Все четырехъядерные процессоры Barcelona серий Opteron 8000 и Opteron 2000 выполняются по 65-нм техпроцессу, имеют кэш L2 объемом 512 Кбайт и кэш L3 объемом 2 Мбайт. Эти процессоры совместимы с разъемом Socket 1207 (Socket F).
Интегрированный контроллер памяти данных процессоров поддерживает регистровую память DDR2 и имеет три шины HyperTransport 1.x.
Процессоры семейства AMD Phenom
Процессоры для ПК на базе микроархитектуры AMD K10 будут образовывать четыре новых семейства: Phenom FX, Phenom X4, Phenom X3 и Phenom X2.
Phenom FX — это семейство флагманских моделей процессоров AMD. В его состав войдут четырехъядерные процессоры с кодовым названием Agena FX. Такие процессоры имеют кэш L2 объемом 512 Кбайт и кэш L3 объемом 2 Мбайт, интегрированный контроллер памяти процессоров поддерживает память DDR2. Они совместимы с разъемами Socket AM2+ и AM2 и имеют шину HyperTransport 3.0.
Phenom X4 — это семейство четырехъядерных процессоров с кодовым названием Agena. Они, так же как и процессоры семейства Phenom FX, имеют кэш L2 объемом 512 Кбайт и кэш L3 объемом 2 Мбайт, интегрированный контроллер памяти поддерживает память DDR2. Процессоры совместимы с разъемами Socket AM2+ и AM2 и имеют шину HyperTransport 3.0.
Phenom X3 — это семейство трехъядерных процессоров с кодовым названием Toliman. Такие процессоры отличаются от процессоров Agena только числом ядер. Отметим, что кэш L3 тоже равен 2 Мбайт. Процессоры совместимы с разъемами Socket AM2+ и AM2 и имеют шину HyperTransport 3.0.
Phenom X2 — это семейство двухъядерных процессоров с кодовым названием Kuma. В сравнении с процессорами Toliman они урезаны еще больше — вместо четырех ядер в них присутствуют только два. Все остальные характеристики этих процессоров такие же, как у процессоров Toliman и Agena.
В дальнейшем, по некоторым данным, компания AMD выведет на рынок двухъядерные процессоры семейства Athlon X2 LS c кодовыми наименованиями Rana и одноядерные процессоры семейства Sempron LE c кодовыми наименованиями Spica. В одноядерных процессорах Spica кэш L3 будет отсутствовать, а в двухъядерных процессорах Rana — присутствовать, но по объему он будет меньше 2 Мбайт (точный объем пока не сообщается). Остальные характеристики процессоров Spica и Rana не будут отличаться от характеристик процессоров Kuma, Toliman и Agena.
Отметим, что с появлением новых семейств процессоров AMD изменится и система их маркировки. В ней будут отражены их позиционирование (High-еnd, Mainstream, Low-end), энергопотребление и серия (Phenom X4, Phenom X3 и т.д). Первая буква в маркировке процессора определяет его позиционирование, вторая — энергопотребление, а трехзначное число указывает на серию процессора (Долгожданные процессоры с микроархитектурой AMD K10 2). К примеру, семейству четырехъядерных процессоров Phenom X4 соответствует серия 7хх, а семейству двухъядерных процессоров Phenom X2 — серия 6хх. Правда, тут есть одна закавыка. Поскольку трехъядерные процессоры семейства Phenom X2 изначально не планировались к производству, то для них как-то забыли зарезервировать номер серии. Можно, конечно, присвоить им серию 5хх, но это будет крайне нелогично, поэтому, возможно, номера серий еще изменятся.
Таблица 2. Система маркировки процессоров AMD
Позиционирование |
Маркировка |
High-еnd |
G |
Mainstream |
B |
Low-end |
L |
Энергопотребление |
|
Больше 65 Вт |
P |
В пределах 65 Вт |
S |
Меньше 65 Вт |
E |
Серия процессора |
|
Phenom X4 |
7xx |
Phenom X3 |
? |
Phenom X2 |
6xx |
Athlon X2 |
2xx |
Sempron |
1xx |
Как уже отмечалось, все новые процессоры AMD совместимы с разъемами Socket AM2+ и Socket AM2. Точнее, они рассчитаны на использование разъема Socket AM2+, но совместимы и с разъемом Socket AM2.
При применении разъема Socket AM2 реализуются не все функциональные возможности новых процессоров. В частности, разъем Socket AM2 не обеспечивает возможности независимого питания ядер процессора и контроллера памяти, что реализовано в микроархитектуре K10. Кроме того, при использовании разъема Socket AM2 частота шины HyperTransport 3.0 составит всего 2,6 ГГц.
Особенности микроархитектуры AMD K10
Первые упоминания о микроархитектуре следующего поколения, которая должна была прийти на смену микроархитектуре AMD K8, появились еще в 2003 году. В частности, на форуме Microprocessor Forum 2003 отмечалось, что новая микроархитектура будет положена в основу многоядерных процессоров, которые будут работать с тактовыми частотами до 10 ГГц. Позднее, конечно, иллюзии относительно заоблачных тактовых частот прошли, а новая микроархитектура стала постепенно приобретать все более конкретные очертания. Так, летом 2006 года появились планы по выходу процессоров на ее базе. Правда, тогда новая микроархитектура значилась под кодовым наименованием K8L, и только в феврале 2007 года ей было дано название AMD K10.
Итак, что же нового в микроархитектуре AMD K10? Четырехъядерные процессоры на базе новой микроархитектуры имеют площадь кристалла 291 мм2 и содержат порядка 463 млн транзисторов (рис. 1). Они выполняются по 65-нм техпроцессу (SOI) и содержат 11 слоев.

Рис. 1. Сравнение кристаллов процессоров, выполненных по различным техпроцессам
Как уже отмечалось, четырехъядерные процессоры на базе микроархитектуры K10 выполнены на одном кристалле. При этом каждое ядро процессора имеет выделенные кэш L1 данных и инструкцию размером по 64 Кбайт каждый, а также выделенный кэш L2 размером 512 Кбайт. Кроме того, реализован разделяемый между всеми ядрами кэш L3 размером 2 Мбайт (рис. 2). Отметим, что такой кэш отсутствовал в микроархтектуре AMD K8.
Рассмотрение микроархитектуры AMD K10 начнем с интегрированного контроллера памяти, который является важной составляющей микроархитектуры AMD K10.
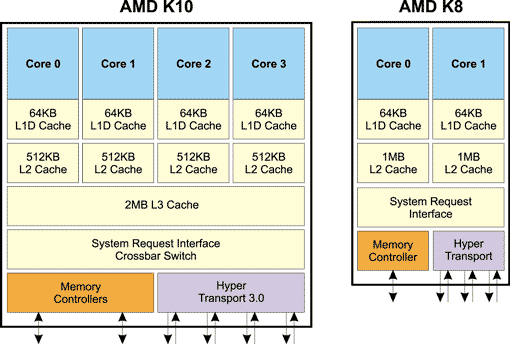
Рис. 2. Сравнение четырехъядерного процессора на базе микроархитектуры K10
и двухъядерного процессора
на базе микроархитектуры K8
Технология AMD Memory Optimizer Technology
Одно из существенных нововведений в микроархитектуре AMD K10 — это новый контроллер памяти. В процессорах AMD K8 использовался один 128-битный контроллер памяти, который можно рассматривать как два спаренных 64-битных контроллера. В микроархитектуре AMD K10 применяются два независимых 64-битных контроллера памяти, что позволяет существенно ускорить доступ к памяти.
Чтобы понять, почему использование двух независимых 64-битных контроллеров памяти более эффективно, чем применение одного 128-битного контроллера, давайте вспомним, что современные модули памяти являются именно 64-битными. Для увеличения пропускной способности подсистемы памяти используется одновременный доступ к двум различным модулям памяти по двум 64-битным каналам (двухканальный режим работы). Это позволяет теоретически в два раза увеличить пропускную способность подсистемы памяти, поскольку за каждый такт работы контроллера памяти можно считывать две порции данных объемом по 64 бита, то есть всего 128 бит.
Однако применение двухканальной схемы работы контроллера памяти имеет и свои нюансы. Проблема заключается в том, что если процессору потребовались 64 бита данных (данные A), хранящиеся по адресу #1, то вместе с ними одновременно будут считаны и 64 бита данных (данные B), хранящихся по соседнему адресу #2 в другом модуле памяти. В операциях линейного чтения больших объемов данных такая ситуация лишь удваивает пропускную способность памяти. Однако может оказаться так, что процессору не нужны считанные данные B, а нужны только данные A. В этом случае двухканальный режим работы памяти не позволяет получить выигрыш в производительности, и соответственно 128-битный контроллер памяти будет функционировать с эффективностью одного 64-битного.
Применение двух независимых 64-битных контроллеров памяти, как в микроархитектуре AMD K10, позволяет одновременно загружать блоки данных с произвольными адресами из различных модулей памяти.
Предположим, к примеру, что процессору необходимо произвести операцию умножения двух чисел. Первое число — это Data A, которое имеет адрес #1, а второе число — Data D, имеющее адрес #4. Пусть Data A хранится в первом модуле памяти, а Data В — во втором. В случае использования 128-битного контроллера памяти придется сначала загрузить 64 бита данных по адресу #1 (Data A) из первого модуля памяти и одновременно с этим 64 бита данных по адресу #2 (Data B), которые процессору не нужны. Далее будут загружены 64 бита данных по адресу #3 (Data C), которые также не нужны процессору, и 64 бита данных по адресу #4 (Data D). Как видите, применение 128-битного контроллера памяти в данном случае малоэффективно. Если же используются два независимых 64-битных контроллера памяти, то за один такт загружается 64 бита данных по адресу #1 (Data A) и 64 бита данных по адресу #4 (Data D).
Новая технология доступа к памяти называется AMD Memory Optimizer Technology.
Кроме применения двух независимых 64-битных контроллеров памяти вместо одного 128-битного, имеются и другие улучшения контроллера памяти. Так, оптимизирован алгоритм переупорядочивания операций чтения/записи, что позволяет наиболее эффективно использовать шину памяти. Операции чтения имеют преимущество перед операциями записи, а данные, предназначенные для записи, откладываются в специальном буфере. Кроме того, контроллер памяти умеет анализировать последовательности запросов и делать соответствующую предвыборку.
Ядро процессора
Как известно, процесс обработки данных процессором включает несколько этапов. В простейшем случае можно выделить четыре этапа обработки команды:
- выборка из кэша;
- декодирование;
- выполнение;
- запись результатов.
Сначала инструкции и данные забираются из кэша L1, который разделен на кэш данных D-cache и кэш инструкций I-cache, — этот процесс называется выборкой. Затем выбранные из кэша инструкции декодируются в понятные для данного процессора примитивы (машинные команды) — такой процесс называется декодированием. Далее декодированные команды поступают на исполнительные блоки процессора, выполняются, а результат записывается в оперативную память.
Процесс выборки инструкций из кэша, их декодирование и продвижение к исполнительным блокам осуществляются в предпроцессоре (Front End), а процесс выполнения декодированных команд — в постпроцессоре, называемом также блоком исполнения команд (Execution Engine).
Стадии обработки команд принято называть конвейером обработки команд, а рассмотренный нами конвейер является четырехступенчатым. Заметьте, что каждую из этих ступеней команда проходит за один процессорный такт. Соответственно для примитивного четырехступенчатого конвейера на выполнение одной команды отводится четыре такта.
Конечно, рассмотренный нами процессор является гипотетическим. В реальных процессорах конвейер обработки команд сложнее и включает большее количество ступеней. Причина увеличения длины конвейера заключается в том, что многие команды являются довольно сложными и не могут быть выполнены за один такт процессора, особенно при высоких тактовых частотах. Поэтому каждая из четырех стадий обработки команд (выборка, декодирование, выполнение и запись) может состоять из нескольких ступеней конвейера. Собственно, длина конвейера — это одна из наиболее значимых характеристик любого процессора.
Итак, разобрав схему гипотетического классического процессора, давайте перейдем к рассмотрению нового ядра. Структурная блок-схема одного ядра процессора на базе микроархитектуры AMD K10 показана на рис. 3.
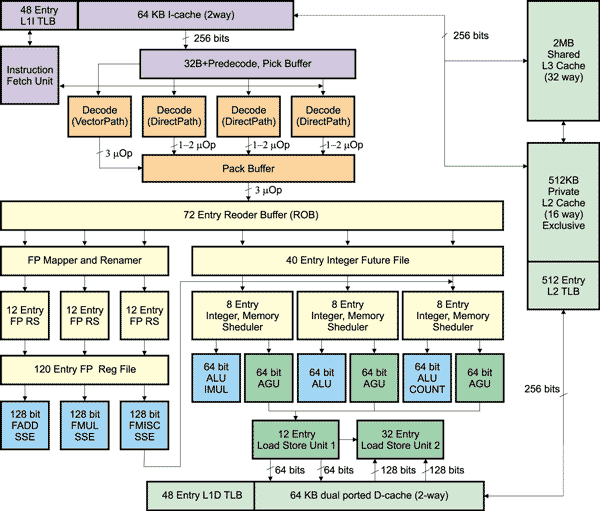
Рис. 3. Структурная блок-схема одного ядра процессора на базе микроархитектуры
AMD K10
Изучая структурную схему нового ядра и сравнивая ее со схемой легендарного K8, можно заметить, что общих черт у них больше, чем различий. Собственно, микроархитектура K10 наследует черты микроархитектуры K8, являясь ее логическим развитием. Используется все тот же 12-ступенчатый конвейер, как и в микроархитектуре K8.
Однако, несмотря на внешнее сходство, новое ядро процессора все же претерпело существенные изменения. Итак, расскажем обо всем по порядку.
Предвыборка данных и инструкций
Как уже отмечалось, в случае классического гипотетического процессора исполнение кода процессором начинается с процесса выборки инструкций и данных из кэша L1. Однако для того, чтобы инструкции и данные попали в этот кэш, их нужно предварительно туда загрузить из оперативной памяти. Такой процесс называется предвыборкой данных и инструкций из оперативной памяти. В процессорах с микроархитектурой K8 имеются два блока предвыборки (Fetch Unit): один для предвыборки данных, а другой для предвыборки инструкций. Блок предвыборки данных производит предвыборку в кэш L2.
В микроархитектуре AMD K10 предвыборка данных осуществляется непосредственно в кэш L1, что, по утверждению представителей компании AMD, способствует повышению производительности, несмотря на вероятность засорения кэша L1 ненужными данными.
Кроме того, в блоках предвыборки процессоров с микроархитектурой K10 реализован механизм адаптивной предвыборки данных, позволяющий динамически изменять глубину предвыборки, что позволяет избежать засорения кэша L1 ненужными данными.
Ну и последнее новшество, связанное с предвыборкой данных и инструкций, — это, как уже отмечалось, наличие нового блока предвыборки, расположенного в контроллере памяти. Такой блок анализирует запросы к памяти, предсказывает, какие данные понадобятся процессору, и извлекает их в собственный буфер, не занимая кэш процессора.
Выборка из кэша
Итак, в соответствии со схемой классического процессора процедура исполнения кода процессором начинается с выборки инструкций в формате X86 и данных из кэша L1. Инструкции X86 имеют переменную длину, причем информация о длине инструкций сохраняется в специальных полях в кэше инструкций L1. Загрузка инструкций переменной длины Х86 из кэша L1 происходит блоками определенной длины, из которых в дальнейшем выделяются инструкции, которые подвергаются декодированию. В процессорах на базе микроархитектуры K8 инструкции из кэша L1 загружаются блоками длиной 16 байт (128 бит), а в микроархитектуре K10 длина блока увеличена вдвое, то есть составляет 32 байта (256 бит). При выборке 16-байтного блока инструкции за такт процессоры на базе микроархитектуры K8 могут выбирать и соответственно отправлять на декодирование до четырех инструкций средней длиной 4 байта.
В принципе, нельзя утверждать, что использование увеличенного вдвое размера блока выборки инструкций в микроархитектуре AMD K10 позволяет выбирать за такт вдвое больше инструкций. Просто в архитектуре AMD K8 длина блока выборки инструкций была согласована с возможностями декодера. В архитектуре AMD K10 возможности декодера изменились, в результате чего потребовалось изменить и размер блока выборки, чтобы темп выборки инструкций был сбалансирован со скоростью работы декодера.
Предсказание переходов и ветвлений
Когда в потоке инструкций встречаются ветвления или переходы, выборка очередного блока инструкций производится с использованием механизма предсказания переходов. Предсказание переходов в процессорах на базе микроархитектуры K8 осуществляется по адаптивному алгоритму на основе анализа истории восьми предыдущих переходов.
Основным недостатком механизма предсказания переходов в микроархитектуре K8 было отсутствие предсказания косвенных переходов с динамически чередующимися адресами, то есть переходов, которые производятся по указателю, динамически вычисляемому при выполнении кода программы.
В микроархитектуре AMD K10 предсказание переходов существенно улучшено. Во-первых, появился механизм предсказания косвенных переходов. Во-вторых, оно выполняется на основе анализа 12 предыдущих переходов, что повышает точность предсказания. В-третьих, вдвое (с 12 до 24 элементов) увеличена глубина стека возврата.
Процесс декодирования
После этапа выборки инструкций X86 из кэша L1 в полном соответствии со схемой классического процессора наступает этап декодирования (трансляции) в машинные команды. Этап декодирования присущ любому современному х86-совместимому процессору, имеющему внутреннюю RISC-архитектуру. В этих процессорах внешние CISC-команды декодируются во внутренние RISC-инструкции, для чего используется декодер команд.
Процесс декодирования состоит из двух этапов. На первом этапе выбранные из кэша L1 блоки инструкций длиной 32 байта помещаются в специальный буфер предкодирования Predecode/Pick Buffer. В нем из 32-байтных блоков выделяются отдельные инструкции, которые затем сортируются и распределяются по различным каналам декодера. Декодер транслирует x86-инструкции в простейшие машинные команды (микрооперации), называемые micro-ops. Сами х86-команды могут быть переменной длины, а вот длина микроопераций уже фиксированная.
Инструкции x86 разделяются на простые (Small x86 Instruction) и сложные (Large x86 Instruction). Простые инструкции при декодировании представляются с помощью одной-двух микроопераций, а сложные команды — тремя и более микрооперациями.
Простые инструкции отсылаются в аппаратный декодер, построенный на логических схемах и называемый DirectPath, а сложные — в микропрограммный (Microcode Engine) декодер, называемый VectorPath. Этот декодер представляет собой своеобразный программный процессор. Он содержит программный код, хранящийся в MIS (Microcode Instruction Sequencer), на основе которого воспроизводится последовательность микроопераций.
Аппаратный декодер DirectPath является трехканальным и может декодировать за один такт три простые инструкции, если каждая из них транслируется в одну микрооперацию, либо одну простую инструкцию, транслируемую в две микрооперации, и одну простую инструкцию, транслируемую в одну микрооперацию, либо две простые инструкции за два такта, если каждая инструкция транслируется в две микрооперации (полторы инструкции за такт). Таким образом, за каждый такт аппаратный декодер DirectPath выдает три микрооперации.
Микропрограммный декодер VectorPath также способен выдавать по три микрооперации за такт при декодировании сложных инструкций. При этом сложные инструкции не могут декодироваться одновременно с простыми, то есть при работе трехканального аппаратного декодера микропрограммный декодер не используется, а при декодировании сложных инструкций, наоборот, бездействует аппаратный декодер.
Микрооперации, полученные в результате декодирования инструкций в декодерах DirectPath и VectorPath, поступают в буфер Pack Buffer, где они объединяются в группы по три микрооперации. В том случае, когда за один такт в буфер поступает не три, а одна или две микрооперации (в результате задержек с выбором инструкций), группы заполняются пустыми микрооперациями, но так, чтобы в каждой группе было ровно три микрооперации. Далее группы микроинструкций отправляются на исполнение.
Если посмотреть на схему декодера в микроархитектурах K8 и K10, то видимых различий, казалось бы, нет (рис. 4). Действительно, принципиальная схема работы декодера осталась без изменений. Разница в данном случае заключается в том, какие инструкции считаются сложными, а какие — простыми, а также в том, как декодируются различные инструкции. Так, в микроархитектуре K8 128-битные SSE-инструкции разбиваются на две микрооперации, а в микроархитектуре K10 большинство SSE-инструкций декодируется в аппаратном декодере как одна микрооперация. Кроме того, часть SSE-инструкций, которые в микроархитектуре K8 декодируются через микропрограммный VectorPath-декодер, в микроархитектуре K10 декодируются через аппаратный DirectPath-декодер.
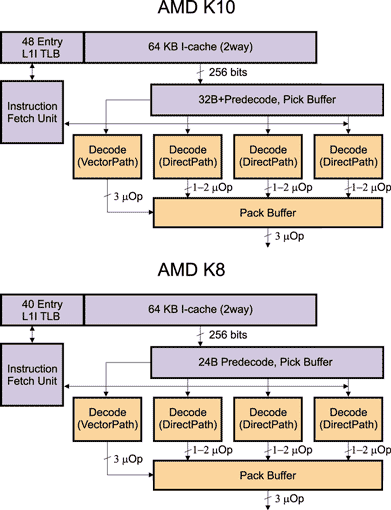
Рис. 4. Декодирование команд в микроархитектурах K8 и K10
Кроме того, в микроархитектуре K10 в декодер добавлен специальный блок, называемый Sideband Stack Optimizer. Не вникая в подробности, отметим, что он повышает эффективность декодирования инструкций работы со стеком и, таким образом, позволяет переупорядочить микрооперации, получаемые в результате декодирования, чтобы они могли выполняться параллельно.
Диспетчеризация и переупорядочивание микроопераций
После прохождения декодера микрооперации (по три за каждый такт) поступают в блок управления командами, называемый Instruction Control Unit (ICU). Главная задача ICU заключается в диспетчеризации трех микроопераций за такт по функциональным устройствам, то есть ICU распределяет инструкции в зависимости от их назначения. Для этого используется буфер переупорядочивания (ReOrder Buffer, ROB), который рассчитан на хранение 72 микроопераций (24 линии по три микрооперации), — рис. 5. Каждая группа из трех микроопераций записывается в свою линию. Из буфера переупорядочивания микрооперации поступают в очереди планировщиков целочисленных (Int Scheduler) и вещественных (FPU Scheduler) исполнительных устройств в том порядке, в котором они вышли из декодера. Планировщик для работы с вещественными числами (FPU Scheduler) рассчитан на 36 инструкций, и его основная задача заключается в том, чтобы распределять команды по исполнительным блокам по мере их готовности. Просматривая все 36 поступающих инструкций, FPU-планировщик переупорядочивает следование команд, строя спекулятивные предположения о дальнейшем ходе программы, чтобы создать несколько полностью независимых друг от друга очередей инструкций, которые можно выполнять параллельно. В микроархитектурах K10 и K8 имеется три исполнительных блока для работы с вещественными числами (FADD, FMUL, FMISC), поэтому FPU-планировщик должен формировать по три инструкции за такт, направляя их на исполнительные блоки.
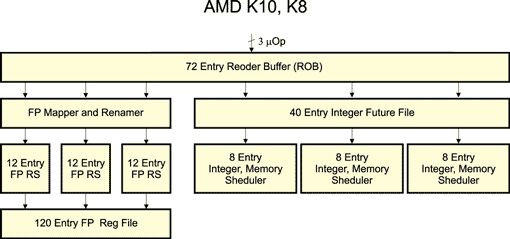
Рис. 5. Диспетчеризация и переупорядочивание микроопераций
Планировщик инструкций для работы с целыми числами (Int Scheduler) образован тремя станциями резервирования (RES), каждая из которых рассчитана на восемь инструкций. Все три станции, таким образом, образуют планировщик на 24 инструкции. Этот планировщик выполняет те же функции, что и FPU-планировщик. Различие между ними заключается в том, что в процессоре имеется семь функциональных исполнительных блоков для работы с целыми числами (три устройства ALU, три устройства AGU и одно устройство MULT).
Выполнение микроопераций
После того как все микрооперации прошли диспетчеризацию и переупорядочивание в соответствующих планировщиках, они могут быть выполнены в соответствующих исполнительных устройствах (рис. 6).
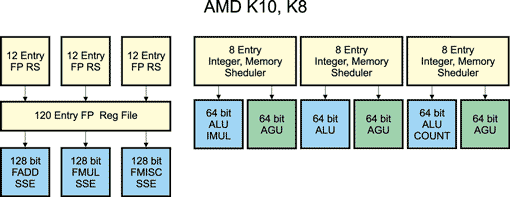
Рис. 6. Выполнение микроопераций
Блок операций с целыми числами состоит из трех распараллеленных частей. По мере готовности данных планировщик может запускать на исполнение из каждой очереди одну целочисленную операцию в устройство ALU и одну адресную операцию в устройство AGU. Количество одновременных обращений к памяти ограничено двумя. Таким образом, за каждый такт может запускаться на исполнение три целочисленных операции, обрабатываемые в устройствах ALU, и две операции с памятью, обрабатываемые в устройствах AGU.
Отметим, что в микроархитектуре K8 при выполнении операций с памятью имеется одно существенное ограничение. Дело в том, что операции обращения к памяти должны идти в том виде, в котором они записаны в коде программы, то есть более поздние в программе операции обращения к памяти не могут выполняться перед более ранними. Понятно, что такое ограничение может существенно отразится на эффективности выполнения программного кода, поскольку нередко блокирует выполнение программы на несколько тактов.
В микроархитектуре K10 такого ограничения не существует, то есть имеется возможность выполнения команды обращения к памяти вне очереди.
Как уже отмечалось, для работы с вещественными числами реализовано три функциональных устройства FPU: FADD — для вещественного сложения, FMUL — для вещественного умножения и FMISC (он же FSTORE) — для команд сохранения в памяти и вспомогательных операций преобразования.
В микроархитектурах K8 и K10 планировщик для работы с вещественными числами каждый такт может запускать на исполнение по одной операции в каждое функциональное устройство FPU. Подобная реализация блока FPU теоретически позволяет выполнять до трех вещественных операций за такт.
В микроархитектуре K8 устройства FPU являются 64-битными. Векторные 128-битные SSE-команды разбиваются на этапе декодирования на две микрооперации, которые производят операции над 64-битными половинами 128-битного операнда и запускаются на исполнение последовательно в разных тактах.
В микроархитектуре K10 устройства FPU являются 128-битными. Соответственно 128-битные SSE-команды обрабатываются с помощью одной микрооперации, что теоретически увеличивает темп выполнения векторных SSE-команд в два раза по сравнению с микроархитектурой K8.
Новые технологии энергосбережения
В микроархитектуре AMD K10, кроме существенных улучшений в процессе выполнения программного кода, предусмотрены и новые технологии энергосбережения, позволяющие существенно повысить оптимизированную производительность процессора, то есть производительность в расчет на ватт потребляемой энергии. В частности, в микроархитектуре AMD K10 реализованы такие технологии, как CoolCore, Independent Dynamic Core и Dual Dynamic Power Management (DDPM).
Технология CoolCore дает возможность автоматически выключать те части (цепи) процессора, которые в данный момент не используются. В результате достигается снижение энергопотребления и соответственно тепловыделения процессора.
Технология Independent Dynamic Core позволяет каждому ядру процессора работать на собственной тактовой частоте, то есть предусмотрено динамическое (в зависимости от текущей загрузки) и независимое изменение тактовой частоты каждого ядра процессора. В технологии Independent Dynamic Core предусмотрено пять энергетических уровней, что дает существенную экономию энергопотребления. Правда, технология Independent Dynamic Core позволяет динамически изменять только частоту ядра каждого процессора, но не напряжение питания. Напряжение питания всех ядер процессора одинаковое и определяется напряжением питания того ядра, которое функционирует на максимальной тактовой частоте.
Технология Dual Dynamic Power Management (DDPM) подразумевает применение двух различных линий для питания ядер процессора и контроллера памяти. Это позволяет не привязывать частоту работы контроллера памяти к частоте работы ядер процессора. Отметим, что технология Dual Dynamic Power Management реализуется только при использовании разъема Socket AM2+, поскольку в разъемах Socket AM2 предусмотрена единая линия для питания процессора и контроллера памяти.
Шина HyperTransport 3.0
В новых процессорах AMD для ПК (Phenom FX, Phenom X4, Phenom X3 и Phenom X2) предусмотрено применение новой шины HyperTransport 3.0. вместо HyperTransport 1.x. Правда, в серверных процессорах Opteron на базе микроархитектуры AMD K10 еще некоторое время будет использоваться шина HyperTransport 1.x, но в будущем в них также будет реализована поддержка шины HyperTransport 3.0.
Шина HyperTransport является двунаправленной и служит для обмена данными между процессором и компонентами системы. Первые версии шины HyperTransport работали на частоте 800 и 1000 МГц, что обеспечивало пропускную способность шины в 6,4 и 8 Гбайт/с соответственно.
Шина HyperTransport 3.0 имеет динамическую рабочую частоту, которая зависит от тактовой частоты процессора. Связь между тактовой частотой процессора и частотой шины HyperTransport определяется коэффициентом пропорциональности 3/4. К примеру, если тактовая частота процессора составляет 2,0 ГГц, то частота шины HyperTransport 3.0 — 1,5 ГГц.
Максимальная частота шины HyperTransport 3.0 равна 2,6 ГГц, что соответствует тактовой частоте процессора 3,5 ГГц (пока таких процессоров еще нет).
Кроме более высоких тактовых частот, новая шина HyperTransport 3.0 поддерживает режим динамической переконфигурации. К примеру, в процессе работы шина 1x16 HyperTransport может быть виртуально переконфигурирована в 2x8 HyperTransport. Это может пригодиться при использовании с многоядерными процессорами, когда каждому ядру будет отводиться своя шина HyperTransport.
Заключение
Итак, процессоры с новой микроархитектурой AMD K10 должны появиться на рынке еще до конца этого года. Несомненно, они составят достойную конкуренцию процессорам Intel с микроархитектурой Intel Core. Причем речь идет о конкуренции не только в сегменте бюджетных решений (собственно, в этом сегменте компания AMD всегда была лидером), но и в сегменте высокопроизводительных решений. Правда, нужно учитывать, что эти процессоры AMD появятся на рынке практически одновременно с новым семейством процессоров Intel, известным под кодовым наименованием Penryn, которые будут выполняться уже по 45-нм техпроцессу. Смогут ли процессоры AMD составить достойную конкуренцию новым процессорам Intel, пока не понятно. Но ждать осталось недолго — уже через один-два месяца можно будет расставить все точки над «и».








