Поддержка многоядерной архитектуры процессоров в PowerMILL 10
Тактовая частота как мерило производительности процессора
Многоядерность как средство увеличения производительности процессоров
Поддержка многоядерности в САПР-системах
Поддержка многоядерных процессоров в PowerMILL 10
Ограничения на многопроцессорные конфигурации в PowerMILL 10
Влияние на производительность технологий Intel Turbo Boost и Hyper-Threading
Зависимость производительности PowerMILL 10 и PowerMILL 9 от тактовой частоты процессора
Зависимость производительности PowerMILL 10 и PowerMILL 9 от количества ядер процессора
В нашей тестовой лаборатории появилась возможность протестировать новую версию программного продукта PowerMILL от компании Delcam plc и сравнить ее с предыдущей версией. В данной статье мы ознакомим читателей с результатами тестирования и постараемся дать рекомендации по конфигурации компьютера, которая обеспечит достижение максимальной производительности в PowerMILL 10.
Тактовая частота как мерило производительности процессора
Если вспомнить историю эволюции процессоров для ПК, то начиная с появления первого процессора i8080 в 1979-м и вплоть до 2005 года все усилия разработчиков были направлены в первую очередь на увеличение их тактовой частоты. Так, если первые процессоры работали на тактовой частоте 5 МГц, то в 2005 году был преодолен рубеж в 3 ГГц.
Столь стремительный рост частоты был вызван тем, что производительность работы процессора напрямую зависит от его тактовой частоты. Однако, чтобы мотивированно продемонстрировать, каким образом производительность процессора зависит от его тактовой частоты, необходимо определиться с терминологией и сформулировать, что именно подразумевается под производительностью процессора.
На уровне интуиции с понятием производительности процессора проблем не возникает. Чем быстрее процессор выполняет программу, тем выше его производительность, то есть производительность процессора должна определяться скоростью выполнения им программного кода. Собственно, именно таким образом и трактуется производительность процессора, под которой понимают скорость выполнения им инструкций программного кода (Instruction Per Second, IPS), или количество инструкций, выполняемых в единицу времени (за секунду). Если попытаться записать данное определение в виде математической формулы, то получится следующее:
![]()
Для того чтобы в явном виде связать производительность процессора с его тактовой частотой F, определяемой как количество тактов процессора в единицу времени, необходимо количество инструкций программного кода, выполняемых за единицу времени (IPS), выразить через количество инструкций, выполняемых за один такт процессора (Instruction Per Clock, IPC):
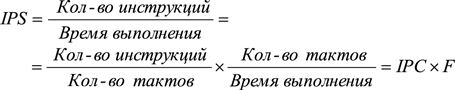
Из формулы видно, что IPC зависит и от микроархитектуры процессора, и от технологии производства, определяющей минимальные размеры используемых транзисторов и их быстродействие, и от оптимизации программного кода к архитектуре процессора.
Как видите, производительность процессора прямо пропорциональна как тактовой частоте, так и количеству инструкций, выполняемых за один такт. Из этой формулы также следует, что существует два принципиально разных подхода к увеличению производительности процессора. Первый из них заключается в увеличении тактовой частоты, а второй — в увеличении IPC.
На практике, как правило, реализуются оба подхода одновременно, то есть производительность процессора увеличивается за счет как масштабирования тактовой частоты, так и увеличения IPC. Вопрос лишь в том, какой из двух подходов является доминирующим.
Как мы уже отмечали, вплоть до 2005 года доминирующим средством увеличения производительности процессора являлось наращивание его тактовой частоты. Производительность процессоров буквально отождествлялась с их тактовой частотой, а микроархитектура создавалась именно с расчетом обеспечения ее максимально возможного масштабирования. Примером этого может служить микроархитектура Intel NetBurst, положенная в основу процессоров семейства Intel Pentium 4, особенностью которой являлся супердлинный конвейер, что позволяло наращивать тактовую частоту.
Казалось бы, если масштабирование тактовой частоты представляет собой довольно эффективное средство для увеличения производительности процессоров, что мешает и дальше двигаться в том же направлении? Почему считается, что наращивание тактовой частоты процессоров как доминирующий способ увеличения производительности — это тупик?
Дело в том, что увеличение тактовой частоты процессора приводит к росту его энергопотребления и, как следствие, к повышению тепловыделения. Зависимость потребляемой процессором мощности от его тактовой частоты выражается следующим образом:
Потребляемая мощность = С x U2 x F,
где C — динамическая емкость процессора, F — тактовая частота процессора, U — напряжение питания процессора.
Если учесть, что для повышения тактовой частоты процессора (в рамках одной микроархитектуры и техпроцесса) необходимо увеличивать напряжение питания ядра, получаем, что потребляемая мощность нелинейным образом зависит от частоты процессора. То есть незначительное увеличение тактовой частоты процессора приводит к значительному увеличению потребляемой им мощности.
В итоге проблема увеличения энергопотребления процессоров превращается в проблему их охлаждения. Дело в том, что современные воздушные кулеры не в состоянии отвести от процессора более 130-140 Вт тепла, а потому энергопотребление процессора не должно превышать критического значения в 130-140 Вт.
Собственно, именно возрастание энергопотребления процессора при увеличении его тактовой частоты и определило нецелесообразность дальнейшей разработки микроархитектуры процессоров, приспособленной к масштабированию тактовой частоты. Достигнув своего предела по энергопотреблению, тактовая частота перестала быть единственным мерилом производительности процессоров. Акцент был смещен в сторону разработки энергоэффективных процессоров, в которых увеличение производительности достигается не за счет масштабирования тактовой частоты, а за счет увеличения количества инструкций, выполняемых процессором за один такт (IPC).
Многоядерность как средство увеличения производительности процессоров
В итоге курс был взят на разработку многоядерных процессоров, и в 2005 году появились первые двухъядерные процессоры для настольных ПК. Дело в том, что многоядерные процессоры позволяют повышать производительность именно за счет увеличения IPC, то есть количества инструкций программного кода, обрабатываемых за каждый такт работы процессора. В идеале при переходе от одноядерной архитектуры процессора к двухъядерной можно сохранить тот же уровень производительности, снизив тактовую частоту каждого из ядер почти вдвое.
В реальности, конечно, всё несколько сложнее — результат будет зависеть от используемого приложения и его оптимизации к двухъядерному процессору. То есть, чтобы приложение могло одновременно задействовать несколько процессорных ядер, оно должно хорошо распараллеливаться. Если же программный код написан таким образом, что подразумевает только последовательное выполнение инструкций, от многоядерности проку не будет.
Для того чтобы продемонстрировать, как именно масштабируется производительность многоядерного процессора в зависимости от оптимизации программного кода к многоядерной архитектуре, рассмотрим следующий пример.
Пусть имеется многоядерный процессор с количеством ядер, равным n. Предположим, что на этом процессоре выполняется программа, включающая N инструкций программного кода, причем S инструкций этого кода может выполняться только последовательно, а P инструкций (P=N–S) являются программно независимыми друг от друга и могут выполняться одновременно на всех n ядрах процессора. Обозначим через s = S/N долю инструкций, выполняемых последовательно, а через p = P/N — долю инструкций, выполняемых параллельно. В случае применения одноядерного процессора время, затрачиваемое на выполнение всего программного кода, составит: t1 = N/(IPS).
В случае применения n-ядерного процессора время, затрачиваемое на выполнение всего программного кода, окажется меньше за счет параллельного выполнения P команд на n ядрах процессора и будет соответствовать формуле:
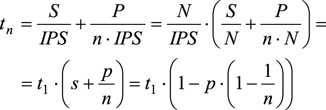
Поскольку приростом производительности в данном случае можно считать сокращение времени выполнения программы при использовании многоядерного процессора по сравнению со временем выполнения той же программы при применении одноядерного процессора (t1/tn), то получим, что прирост производительности составит: t1/tn = 1 – p · (1 – (1/n)).
Как видно из приведенной формулы, прирост производительности в случае многоядерной архитектуры процессора зависит от оптимизации приложения к многоядерной архитектуре, то есть от его способности распараллеливаться. К примеру, даже в случае, когда 90% программного кода распараллеливается на несколько исполнительных ядер, использование четырехъядерного процессора позволяет получить только трехкратный прирост производительности в сравнении с одноядерной архитектурой процессора.
Рассмотренный нами пример представляет собой идеальную ситуацию, но в реальности всё несколько сложнее. Тем не менее основная идея остается неизменной: применение многоядерных процессоров требует внесения кардинальных изменений в программное обеспечение.
Нужно отметить, что далеко не все приложения сегодня оптимизированы под многоядерную архитектуру процессоров. В то же время имеется ряд приложений, которые, наоборот, позволяют получить ощутимый прирост производительности от многоядерной архитектуры процессоров.
Поддержка многоядерности в САПР-системах
Если рассмотреть возможность распараллеливания программного кода применительно к САПР-программам, то ситуация здесь весьма неоднозначна.
Большинство методов конечных элементов позволяют разбить вычислительную задачу на более мелкие блоки, математическое взаимодействие между которыми происходит по условно заданным границам. В результате многие популярные CAE-системы успешно работают на вычислительных кластерах (группе компьютеров, объединенных в локальную сеть с высокой пропускной способностью). На первый взгляд время счета задачи должно быть обратно пропорционально количеству компьютеров в кластере, но на практике, из-за задержек при передаче данных и дополнительной обработки информации, зависимость времени выполнения расчета от количества компьютеров в кластере не является линейной.
Как правило, практическая реализация распараллеливания вычислений требует от разработчиков очень больших затрат. Естественно, что адаптация под многоядерные процессоры CAE-систем, уже имеющих свои кластерные версии, не составляет для разработчиков большого труда.
В противоположность CAE-системам сам принцип работы с твердотельными CAD-моделями, имеющими логическую структуру в виде дерева построения, не позволяет выполнять эффективное распараллеливание вычислений при их перестроении. Кроме того, взаимосвязи между элементами эскизов и сборок также образуют логические цепочки, поэтому CAD-системы требуют преимущественно последовательных вычислений. В результате специально разработанные для многопроцессорных компьютеров CAD-системы могут использовать преимущества нескольких ядер, но на типовых задачах ощутимого роста производительности от увеличения количества процессоров не происходит. Отчасти это связано еще и с необходимостью максимально быстрого доступа к разным блокам памяти, содержащим 3D-модель, поэтому CAD-системы на кластерах пока не прижились. Хотя следует отметить, что вычислительные кластеры с успехом применяются для визуализации (рендеринга) гигантских сборок, в том числе и на панелях высокого разрешения, набранных из нескольких мониторов.
Поддержка многоядерных процессоров в PowerMILL 10
Другое направление, допускающее возможность распараллеливания процесса вычислений, — генерация управляющих программ для станков с ЧПУ. Дело в том, что цена современных пятиосевых станков с ЧПУ исчисляется сотнями тысяч долларов, поэтому стоимость их амортизации очень высока, а простаивание в ожидании, пока CAM-система рассчитает управляющую программу, — непозволительная роскошь. При единичном производстве инструментальной оснастки CAM-система должна не только обладать такими качествами, как надежность, качество и эффективность сгенерированных управляющих программ, но и обеспечивать максимально возможную скорость счета. Это особенно актуально для производства крупногабаритной оснастки для изделий аэрокосмической, судостроительной и автомобильной отраслей.
С учетом того обстоятельства, что все современные процессоры для ПК и серверов являются многоядерными (двух- или четырехъядерными), понятно, что современная CAM-система должна уметь эффективно использовать многоядерный потенциал процессора.
В частности, в одной из наиболее распространенных CAM-систем PowerMILL 10-й версии от компании Delcam plc разработчики добавили возможность распараллеливания вычислений с целью поддержки многоядерных процессоров. В результате программный пакет PowerMILL 10 позволяет в полной мере реализовать преимущества многоядерных процессоров.
В PowerMILL 10 технологии параллельного вычисления были применены двумя различными способами. Во-первых, теперь можно подготавливать, вычислять и редактировать траекторию движения инструмента в активном режиме, выполняя при этом вычисление других траекторий в фоновом режиме, с минимальным уменьшением скорости обработки. В принципе, эта технология способна работать и на одноядерном процессоре, но в полной мере ощутить все ее преимущества можно лишь на многоядерном процессоре.
Во-вторых, 10-я версия PowerMILL может одновременно рассчитывать траекторию фрезерования разных участков обрабатываемого элемента детали. При этом используется одна и та же стратегия, но каждое ядро независимо рассчитывает УП для обработки отдельных участков. В результате время генерации траектории обработки снижается пропорционально количеству задействованных ядер процессора.
Уникальным преимуществом, предлагаемым PowerMILL 10, является то, что параллельная обработка данных применяется и в активном, и в фоновом режиме одновременно. Несомненно, это дает более весомый выигрыш в производительности в 10-й версии, чем в любом из предыдущих выпусков PowerMILL.
Вероятно, одним из наиболее важных, но внешне менее заметных улучшений в PowerMILL 10 является использование параллельной обработки данных при вычислении траекторий.
В PowerMILL 9 параллельно выполнялась только операция переразмещения точек траектории. В PowerMILL 10 под параллельную обработку оптимизирован и код расчета траектории движения инструмента. В результате расчета траектории обработки, например в случае применения стратегии Растр (Raster), вычисления почти полностью идут параллельно.
Возможности распараллеливания вычислений реализованы и в таких стратегиях обработки, как:
- постоянная Z (Constant Z);
- 3D-смещение (3D Offset);
- стратегии черновой обработки (Area clearance);
- межслойная Z (Interleaved constant Z);
- оптимизированная Z (Optimised constant Z);
- вычисления границы (Boundary calculations).
Вычисление 3D-модели состояния заготовки также оптимизировано под многоядерные процессоры. Отметим, что распределение задач между ядрами многоядерного процессора осуществляется полностью автоматически.
Благодаря оптимизации кода, PowerMILL 10 стала самой быстрой CAM-системой на рынке, обогнав по скорости генерации управляющих программ все без исключения предыдущие свои версии.
Кроме того, разработчики компании Delcam усовершенствовали математические алгоритмы расчета ресурсоемких чистовых стратегий обработки с целью снижения требуемого объема оперативной памяти. Это особенно актуально для очень больших CAD-моделей, при работе с которыми пользователи раньше иногда сталкивались с проблемой нехватки памяти компьютера.
В предыдущей, 9-й версии PowerMILL появилась функция перераспределения точек траектории (Point Distribution), благодаря которой на станке достигается более высокая физическая скорость подачи. В PowerMILL 10 эта функция также использует алгоритм распараллеливания вычислений.
Ограничения на многопроцессорные конфигурации в PowerMILL 10
Поскольку в PowerMILL 10 реализована эффективная поддержка параллельной обработки данных, то естественно было бы предположить, что для повышения производительности целесообразно применять многопроцессорные серверы.
Однако, как показывают результаты исследований, проведенных специалистами компании Delcam plc, всё не так просто. В частности, в ходе тестирования выяснилось, что сервер с двумя двухъядерными процессорами имеет более низкую производительность в PowerMILL 10, чем компьютер с одним четырехъядерным процессором, а сервер с двумя четырехъядерными процессорами уступает по производительности серверу с одним четырехъядерным процессором. То есть увеличение числа процессоров приводит к снижению производительность в PowerMILL 10.
Причина негативного влияния увеличения числа процессоров на производительность в PowerMILL 10 заключается в том, что узким местом в данном случае является не производительность процессора, а время, затрачиваемое на доступ к основной памяти. Производители процессоров пытаются справиться с этой проблемой, добавляя к процессору быструю кэш-память третьего уровня (L3). Часто используемые данные сохраняются в кэше L3, где к ним можно получить быстрый доступ. При наличии нескольких ядер в процессоре все они применяют один и тот же кэш L3.
Когда ядра процессора работают параллельно, при взаимодействии между ядрами для координации их задач используются все преимущества общего кэша при условии, что все ядра находятся в одном процессоре. Однако преимущества общего кэша теряются, когда некоторые из ядер находятся в другом процессоре, и для взаимодействия тогда применяется внешняя шина или основная память. Дальнейшие издержки возникают из-за того, что необходимо поддерживать когерентность кэша, то есть содержимое кэша должно синхронизироваться с содержимым основной памяти, и наоборот.
Итак, исходя из всего вышеизложенного, можно сделать вывод, что сегодня для PowerMILL 10 оптимальной является конфигурация ПК с одним четырехъядерным процессором (процессоров с большим количеством ядер пока не производится).
Тестирование PowerMILL 10
Для того чтобы на практике убедиться во всех преимуществах новой, 10-й версии PowerMILL, мы провели тестирование этого программного продукта, сравнив его с PowerMILL 9.
Для тестирования использовался стенд следующей конфигурации:
- процессор — Intel Core i7-965 Extreme Edition;
- системная плата — Gigabyte GA-EX58-UD4;
- чипсет системной платы — Intel X58 Express;
- Intel Chipset Device Software — 9.1.1.1019;
- память — DDR3-1333 (Kingston KVR1333D3D8R9SK3/6G);
- объем памяти — 6 Гбайт (три модуля по 2048 Мбайт);
- режим работы памяти — DDR3-1066, трехканальный режим;
- тайминги памяти — 7-7-7-20;
- видеокарта — GeForce GTX295;
- видеодрайвер — ForceWare 191.07;
- жесткий диск — Western Digital WD2500JS;
- операционная система — Microsoft Windows 7 Ultimate 64-bit.
Для тестирования мы использовали два теста (Test#1 и Test#2), в которых рассчитывается управляющая программа для обработки модели штампа размером 1850x1700x400 мм, содержащей 2300 поверхностей.
В первом тесте используется только одна стратегия обработки — растр с различными параметрами. Этот тест позволяет оценить, каким образом многопоточность влияет на отдельную стратегию обработки.
Во втором тесте производится полная обработка штампа с применением набора инструмента и различных стратегий черновой, получистовой и чистовой обработки. Данный тест позволяет оценить, каким образом многопоточность влияет на обработку детали в целом.
Напомним, что процессор Intel Core i7-965 Extreme Edition является четырехъядерным и поддерживает технологию Hyper-Threading, за счет чего он воспринимается операционной системой как восьмиядерный.
Первоначально мы попытались протестировать программный продукт PowerMILL 10 с помощью 32-битной версии операционной системы Microsoft Windows 7 Ultimate с 3 Гбайт памяти DDR3-1066 в трехканальном режиме. Однако в ходе тестирования выяснилось, что данного объема оперативной памяти недостаточно, поэтому было принято решение увеличить объем памяти.
Поскольку процессор Intel Core i7-965 Extreme Edition имеет встроенный трехканальный контроллер памяти, целесообразно использовать либо 3, либо 6, либо даже 12 Гбайт памяти. То есть мы исходили из того, что память должна работать в трехканальном режиме, для чего необходимо применять по одному или по два модуля на каждый канал памяти. С учетом того обстоятельства, что в настоящее время распространены модули памяти емкостью 1 или 2 Гбайт, можно было использовать 3, 6 или 12 Гбайт памяти. Поскольку емкости в 3 Гбайт памяти оказалось недостаточно, выбор был между 6 и 12 Гбайт памяти. Объем в 12 Гбайт — это явно избыточно, поскольку само приложение PowerMILL 10 является 32-битным и не может адресовать более 4 Гбайт памяти. Именно поэтому в нашем стенде мы применяли 6 Гбайт памяти DDR3, а следовательно, 64-битную версию операционной системы Microsoft Windows 7 Ultimate.
Также отметим, что, несмотря на тот факт, что мы использовали память DDR3-1333, она принудительно была настроена на режим работы DDR3-1066. Дело в том, что сам процессор Intel Core i7-965 Extreme Edition в штатном режиме поддерживает только память DDR3-1066 (и менее скоростную), а DDR3-1333 — нет. А потому, дабы избежать зависания программы из-за нештатного режима работы памяти, было принято решение применять память в режиме DDR3-1066.
Результатами тестов Test#1 и Test#2 является время выполнения отдельных операций, причем таких результатов оказалось достаточно много. Дабы не загромождать статью излишним количеством результатов и графиков, в качестве интегрального результата каждого теста мы решили использовать суммарное время выполнения всех отдельных операций или, попросту, время выполнения всего теста.
В ходе тестирования мы не просто сравнили время выполнения каждого теста при применении пакета PowerMILL 10 с временем выполнения этого же теста при использовании пакета PowerMILL 9, но и исследовали зависимость результата тестирования от тактовой частоты процессора и от количества ядер процессора.
Изменение тактовой частоты процессора производилось в настройках BIOS путем изменения коэффициента умножения системной шины. Шаг изменения тактовой частоты процессора соответствовал частоте системной шины, то есть составлял 133 МГц.
Изменение числа ядер процессора также производилось в настройках BIOS. Учитывая, что процессор Intel Core i7-965 Extreme Edition является четырехъядерным, были проведены тесты для четырех-, трех-, двух- и одноядерной конфигураций процессора.
Также с учетом того, что процессор Intel Core i7-965 Extreme Edition поддерживает технологии Intel Turbo Boost и Hyper-Threading, было исследовано влияние данных технологий на результаты тестирования для пакетов PowerMILL 10 и PowerMILL 9.
Влияние на производительность технологий Intel Turbo Boost и Hyper-Threading
Результаты тестирования, демонстрирующие влияние технологий Intel Turbo Boost и Hyper-Threading на скорость выполнения тестовых задач в пакетах PowerMILL 10 и PowerMILL 9, представлены на рис. 1 и 2. Заметим, что тестирование проводилось при четырех активных ядрах процессора.
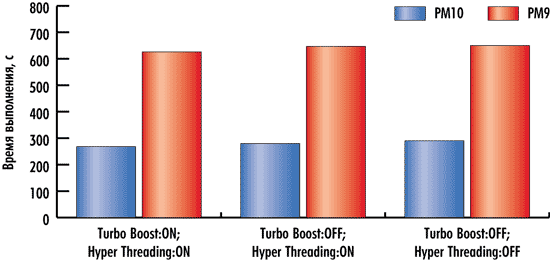
Рис. 1. Влияние технологий Intel Turbo Boost и Hyper-Threading
на скорость выполнения теста Test#1
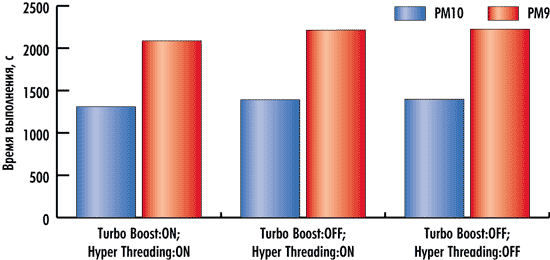
Рис. 2. Влияние технологий Intel Turbo Boost и Hyper-Threading
на скорость выполнения теста Test#2
Как видно по результатам тестирования, технология Intel Turbo Boost, то есть технология динамического разгона ядер процессора при выполнении определенных условий, практически не позволяет получить прироста производительности в тесте Test#1 и дает лишь незначительный прирост производительности в тесте Test#2 для пакета PowerMILL как 10-й, так и 9-й версии. В общем-то этот результат вполне закономерен, поскольку технология Intel Turbo Boost позволяет увеличить тактовую частоту ядер процессора всего на одну ступень по частоте системной шины (на 133 МГц), а, как мы увидим в дальнейшем, зависимость времени выполнения тестов от тактовой частоты процессора для пакета PowerMILL как 10-й, так и 9-й версии выражена довольно слабо.
Технология Intel Hyper-Threading также не позволяет получить заметного прироста производительности (скорости выполнения тестовых задач) для пакета PowerMILL 10-й и 9-й версий. Собственно, с пакетом PowerMILL 9 так и должно быть, поскольку он плохо оптимизирован под многоядерные процессоры и применение восьми логических ядер процессора вместо четырех не должно сказаться на изменении производительности.
Что же касается PowerMILL 10, то логично было бы предположить, что для данного программного продукта существует некоторое оптимальное количество ядер процессора и использование процессоров с большим числом ядер уже не позволит увеличить производительность.
Зависимость производительности PowerMILL 10 и PowerMILL 9 от тактовой частоты процессора
Результаты тестирования, демонстрирующие зависимость скорости выполнения тестовых задач в пакетах PowerMILL 10 и PowerMILL 9 от тактовой частоты процессора, представлены на рис. 3 и 4. Они лишь подтверждают теоретические выкладки о линейной зависимости производительности процессора от его тактовой частоты. Как видно по графикам, по мере увеличения тактовой частоты время выполнения тестов линейно уменьшается.
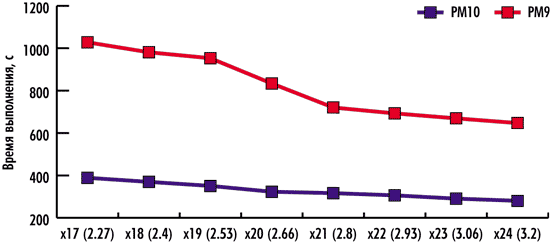
Рис. 3. Зависимость скорости выполнения теста Test#1
от тактовой частоты процессора
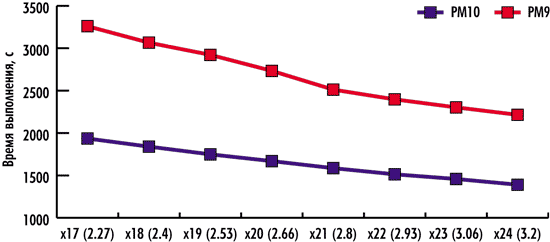
Рис. 4. Зависимость скорости выполнения теста Test#2
от тактовой частоты процессора
Для теста Test#1 увеличение тактовой частоты процессора на одну ступень по частоте системной шины, то есть на 133 МГц, приводит к уменьшению времени выполнения теста примерно на 5% при использовании PowerMILL 10 и примерно на 7% — в случае PowerMILL 9.
Для теста Test#2 увеличение тактовой частоты процессора на одну ступень по частоте системной шины приводит к уменьшению времени выполнения теста примерно на 5% при применении PowerMILL 10 и примерно на 5,5% — в случае PowerMILL 9.
Зависимость производительности PowerMILL 10 и PowerMILL 9 от количества ядер процессора
Результаты тестирования, демонстрирующие зависимость скорости выполнения тестовых задач в пакетах PowerMILL 10 и PowerMILL 9 от количества ядер процессора, представлены на рис. 5 и 6.
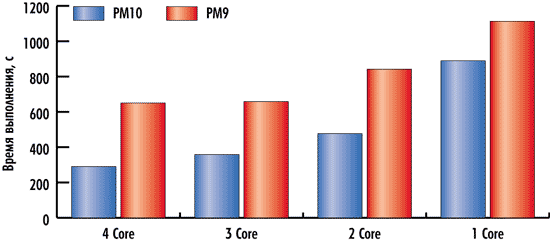
Рис. 5. Зависимость скорости выполнения теста Test#1
от количества ядер процессора
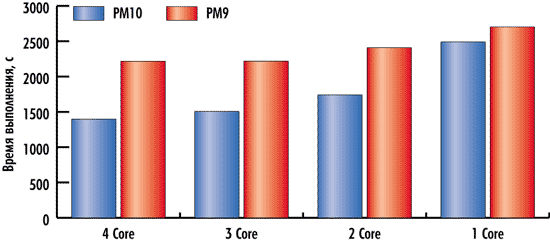
Рис. 6. Зависимость скорости выполнения теста Test#2
от количества ядер процессора
Обращает на себя внимание тот факт, что время выполнения тестов зависит от количества ядер процессора при использовании PowerMILL как 10-й, так и 9-й версии, однако характер этих зависимостей различен.
Для PowerMILL 9 и в тесте Test#1, и в тесте Test#2 результаты тестирования практически одинаковые как для трехъядерной, так и для четырехъядерной конфигурации процессора и только при переходе к двухъядерной и одноядерной конфигурациям процессора время выполнения тестов заметно увеличивается.
Для PowerMILL 10 и в тесте Test#1, и в тесте Test#2 результаты тестирования (время выполнения теста) улучшаются по мере увеличения числа ядер процессора.
Выводы
Обобщая результаты сравнительного тестирования программных продуктов PowerMILL 10 и PowerMILL 9, можно сделать следующие важные выводы.
Использование новой версии PowerMILL на компьютере с многоядерным процессором позволяет существенно сократить время создания управляющей программы для ЧПУ. В частности, при применении четырехъядерного процессора Intel Core i7-965 Extreme Edition время выполнения теста Test#1 при использовании PowerMILL 10-й версии вместо 9-й сокращается в 2,3 раза, а в тесте Test#2 — в 1,6 раза. При этом время выполнения отдельных операций уменьшается в 3-4 раза.
Для достижения максимальной производительности целесообразно применять пакет PowerMILL 10 именно в совокупности с четырехъядерным процессором семейства Intel Core i7. Четырехъядерные процессоры AMD семейства Phenom II не могут конкурировать по производительности с четырехъядерными процессорами семейства Intel Core i7, а потому в данном случае не представляют интереса.








