Сравнение 64-битных архиваторов WinRAR 4.2, WinZip 17.0 и 7-Zip 9.30
Ограничение информационного алфавита
Еще 10-15 лет назад архиваторы использовались в основном для экономии места на жестких дисках и для того, чтобы уместить максимум данных на дискету. Однако времена изменились. Дискетами как средством переноса и хранения информации уже давно никто не пользуется, а стоимость накопителей стала настолько низкой, что никто даже не задумывается о сжатии данных с целью экономии места. Кроме того, объемы данных стали такими большими, что их архивация и разархивация с целью экономии места просто нецелесообразна, поскольку отнимает очень много времени. Ну действительно, сегодня объемы данных на накопителях пользователей измеряются терабайтами. А теперь представьте себе, сколько потребуется времени, чтобы заархивировать один терабайт данных. На это уйдет не один и даже не два часа, а как минимум часов 10-12, то есть компьютер придется оставить включенным на всю ночь.
Казалось бы, архиваторы сегодня должны постепенно утрачивать свою актуальность. Но ничего подобного не происходит. У подавляющего большинства пользователей среди прочих программ установлены архиваторы, либо они используют архиватор, встроенный в операционную систему Windows (другие ОС в данной публикации мы не рассматриваем).
Дело в том, что изменилось назначение архиваторов. Сегодня они используются преимущественно для выкладывания данных в Сеть. Большинство драйверов на сайтах производителей выкладываются именно в архивах, и большая часть программ на различных ресурсах также заархивированы. Кстати, и сам пользователь прежде чем выложить какиелибо данные в Сеть (например, на файлообменные ресурсы), запаковывает данные в архив.
Что касается российского рынка, то у нас наиболее распространенными являются три архиватора: WinRAR, WinZip и 7-Zip, представленные как в 32-, так и 64-битной версиях. Именно их мы и будем сравнивать в данной статье. Однако прежде кратко рассмотрим некоторые теоретические аспекты работы архиваторов.
Алгоритмы сжатия информации
Суть любого алгоритма сжатия информации заключается в том, чтобы путем некоторого преобразования исходного набора информационных бит получить на выходе некоторый набор меньшего размера. Причем все алгоритмы преобразования данных можно условно разделить на два класса: обратимые и необратимые.
Под необратимым алгоритмом сжатия информации подразумевается такое преобразование исходной последовательности бит, при котором выходная последовательность меньшего размера не позволяет в точности восстановить входную последовательность. Алгоритмы необратимого сжатия используются, например, в отношении графических, видео и аудиоданных, причем это всегда приводит к потере их качества. Естественно, в архиваторах алгоритмы необратимого сжатия данных не применяются, а потому в дальнейшем мы их рассматривать не будем.
Алгоритмы обратимого сжатия данных позволяют в точности восстановить исходную последовательность данных из сжатой последовательности. Именно такие алгоритмы и используются в архиваторах. Общими характеристиками всех алгоритмов сжатия являются степень сжатия (отношение объемов исходной и сжатой последовательности данных), скорость сжатия (время, затрачиваемое на архивирование некоторого объема данных) и качество сжатия (величина, показывающая, насколько сильно сжата последовательность данных, путем применения к нему повторного сжатия по этому же или иному алгоритму).
Теория сжатия информации, известная также как теория экономного кодирования дискретной информации, — это достаточно сложный раздел математической науки. Конечно же, изложение даже ее азов выходит далеко за рамки данной статьи, а потому мы лишь поверхностно рассмотрим различные алгоритмы сжатия информации, не вдаваясь в детали. Кроме того, сегодня разработано очень много алгоритмов сжатия данных, и их рассмотрение также входит в нашу задачу. Поэтому мы лишь на качественном уровне расскажем о нескольких алгоритмах, которые позволяют получить общее представление о методах сжатия информации.
Алгоритм RLE
Один из самых старых и самых простых методов сжатия информации — это алгоритм RLE (Run Length Encoding), то есть алгоритм кодирования серий последовательностей. Этот метод очень прост в реализации и представляет собой один из алгоритмов архивации, а суть его заключается в замене серии (группы) повторяющихся байтов на один кодирующий байт и счетчик числа их повторений. То есть группа одинаковых байтов заменятся на пару: <счетчик повторений, значение>, что сокращает избыточность данных.
В данном алгоритме признаком счетчика служат единицы в двух верхних битах считанного байта. К примеру, если первые два бита — это 11, то остальные 6 бит отводятся на счетчик, который может принимать значения от 1 до 64. Соответственно серию из 64 повторяющихся байтов можно определить всего двумя байтами, то есть сжать в 32 раза.
Есть и другой вариант реализации этого алгоритма, когда признаком счетчика является 1 в первом байте счетчика. В этом случае счетчик может принимать максимальное значение, равное 127, — а следовательно максимальная степень сжатия будет равна 64.
Понятно, что алгоритм RLE эффективен только тогда, когда имеется большое количество длинных групп одинаковых байтов. Если же байты не повторяются, то использование метода RLE приводит к увеличению объема файла.
Метод RLE, как правило, весьма эффективен для сжатия растровых графических изображений (BMP, PCX, TIF, GIF), поскольку они содержат очень много длинных серий повторяющихся последовательностей байтов.
Ограничение информационного алфавита
Еще один достаточно простой способ сжатия информации можно назвать ограничением информационного алфавита. Сразу же отметим, что на практике такой алгоритм не реализован, но изложение данного метода поможет лучше понять метод кодов переменной длины.
В дальнейшем под информационным алфавитом мы будем подразумевать набор символов, используемый для кодирования информационной последовательности. К примеру, пусть имеется некоторое текстовое сообщение. Для кодировки каждой буквы этого сообщения используется ASCII-таблица, состоящая из 256 символов. При этом под кодирование каждого символа отводится ровно 8 бит (1 байт). В данном случае информационный алфавит — это все 256 символов кодировочной ASCII-таблицы.
Понятно, что в исходном текстовом сообщении могут применяться не все 256 символов ASCII-таблицы. К примеру, если речь идет о текстовом сообщении на русском языке, в котором нет цифр, то достаточно 64 символов (33 строчные и 31 заглавная буквы). Если добавить к этому знаки препинания, знаки абзаца и перехода на новую строку, станет понятно, что число символов не превысит 100. В этом случае можно использовать не 8-, а 7-битное кодирование символов, что позволяет получить таблицу из 128 символов. То есть мы как бы ограничиваем информационный алфавит, за счет чего можно уменьшить разрядность каждого колируемого символа. Можно пойти дальше — точно определить количество применяемых символов в текстовом сообщении. Если, к примеру, выяснится, что в сообщении задействуются всего 30 символов (включая символы перехода на новую строку), то можно использовать 5-битную кодировочную таблицу, содержащую 32 символа, и тогда степень сжатия текстового сообщения станет еще большей. Действительно, если в исходном сообщении применяется 8-битное кодирование символов, а в сжатом — 5-битное, то коэффициент сжатия будет 8/5.
Несмотря на кажущуюся простоту метода ограничения алфавита, на практике он не используется. Дело в том, что описанный метод не позволяет корректно декодировать исходное сообщение без передачи дополнительной информации. Действительно, не зная кодировочных таблиц, применяемых для сжатия информации, декодировать ее невозможно. То есть вместе с закодированной информационной последовательностью необходимо передавать и кодировочные таблицы. Понятно, что в этом случае выигрыш от использования ограниченного алфавита сводится к нулю.
У метода ограниченного алфавита есть и другие недостатки. Если исходное информационное сообщение содержит большое количество разнообразных символов, то понизить разрядность представления символов алфавита не удастся и данный способ просто не сработает. Предположим, к примеру, что в исходном информационном сообщении содержится 129 символов из 256-символьного алфавита. Воспользоваться 7-битным кодированием символов в данном случае не удастся, поскольку 7 бит позволят закодировать только 128 символов. Поэтому для 129 символов придется обратиться к тому же 8-битному кодированию, как и в исходном 256-символьном алфавите.
Коды переменной длины
Одним из главных недостатков рассмотренного нами гипотетического метода ограничения алфавита является то, что в нем применяется равномерный код, когда все символы информационного алфавита имеют одинаковую длину (8, 7 бит или меньше). Было бы логичнее использовать такую систему кодирования, при которой длина кода символа зависит от частоты его появления в информационном сообщении. То есть, если в исходном информационном сообщении некоторые символы встречаются чаще других, то для них оптимально использовать короткие коды, а для редко встречающихся —более длинные.
В качестве гипотетического примера рассмотрим следующее информационное сообщение: «авиакатастрофа», которое содержит 14 символов. Предположим, что у нас имеется алфавит из 14 символов, который позволяет нам закодировать это сообщение. Если используется равномерный код, то на каждый символ алфавита потребуется 4 бита (длина кода в 4 бита позволит сформировать 16 символов). Однако нетрудно заметить, что в нашем информационном сообщении символ «а» встречается пять раз, символ «т» — два раза, а остальные символы — по одному разу. Если для символа «а» мы будем использовать код длиной 2 бит, для символа «т» — длиной 3 бита, а для остальных символов — длиной 4 бита, то мы наверняка сможем сэкономить. Нужно лишь понять, как именно строить коды переменной длины и как именно длина кода должна зависеть от частоты появления символа в информационном сообщении.
Если все символы входят в информационное сообщение с одинаковой частотой (равновероятны), то при информационном алфавите из N символов для кодирования каждого символа потребуется ровно log2 N бит. Фактически это случай равномерного кода.
Если же символы имеют разную вероятность появления в информационном сообщении, то, согласно теории К. Шеннона, символу, вероятность появления которого равна p, оптимально и, что особенно важно, теоретически допустимо ставить в соответствие код длиной –log2 p . Возвращаясь к нашему примеру с информационным сообщением «авиакатастрофа» и учитывая, что вероятность появления символа «а» (p(a)) составляет 5/14, вероятность появления символа «т» — 2/14, а вероятность появления всех остальных символов — 1/14, мы получим, что: для символа «a» оптимальная длина кода равна –log2(5/14) = 1,48 бит; для символа «т» — –log2(2/14) = 2,8 бит, а для всех остальных символов она составляет –log2(1/14) = 3,8. Поскольку в нашем случае длина кода может иметь только целочисленное значение, то, округляя, получим, что для символа «а» оптимально использовать код длиной 2 бита, для символа «т» — длиной 3 бита, а для остальных — длиной 4 бита.
Давайте посчитаем степень сжатия при использовании такого кодирования. Если бы применялся равномерный код на базе 14-символьного алфавита, то для кодирования слова «авиакатастрофа» потребовалось бы 56 бит. При использовании кодов переменной длины потребуется 5×2 бита + 2×3 бита + 7×4 бита = 44 бита, то есть коэффициент сжатия составит 1,27.
Теперь рассмотрим алгоритмы получения кодов переменной длины.
Префиксное кодирование
Наиболее простым методом получения кодов переменной длины является так называемое префиксное кодирование, которое позволяет получать целочисленные по длине коды. Главная особенность префиксных кодов заключается в том, что в пределах каждой их системы более короткие по длине коды не совпадают с началом (префиксом) более длинных кодов. Именно это свойство префиксных кодов позволяет очень просто производить декодирование информации.
Поясним это свойство префиксных кодов на конкретном примере. Пусть имеется система из трех префиксных кодов: {0, 10, 11}. Как видим, более короткий код 0 не совпадает с началом более длинных кодов 10 и 11. Пусть код 0 задает символ «а», код 10 — символ «м», а код 11 — символ «р». Тогда слово «рама» кодируется последовательностью 110100. Попробуем раскодировать эту последовательность. Поскольку первый бит — это 1, то первый символ может быть только «м» или «р» и определяется значением второго бита. Поскольку второй бит — это 1, то первый символ — это «р». Третий бит — это 0, и он однозначно соответствует символу «а». Четвертый бит — это 1, то есть нужно смотреть на значение следующего бита, который равен 0, тогда третий символ — это «м». Последний бит — это 0, что однозначно соответствует символу «а». Таким образом, свойство префиксных кодов, заключающееся в том, что более короткие по длине коды не могут совпадать с началом более длинных кодов, позволяет однозначно декодировать закодированное префиксными кодами переменной длины информационное сообщение.
Префиксные коды обычно получают построением кодовых (для двоичной системы) деревьев. Каждый внутренний узел такого бинарного дерева имеет два исходящих ребра, причем одному ребру соответствует двоичный символ «0», а другому — «1». Для определенности можно договориться, что левому ребру нужно ставить в соответствие символ «0», а правому — символ «1».
Поскольку в дереве не может быть циклов, от корневого узла к листовому всегда можно проложить один-единственный маршрут. Если ребра дерева пронумерованы, то каждому такому маршруту соответствует некоторая уникальная двоичная последовательность. Множество всех таких последовательностей будет образовывать систему префиксных кодов.
Для рассмотренного примера системы из трех префиксных кодов: {0, 10, 11}, которые задают символы «а», «м» и «р», кодовое дерево показано на рис. 1.

Рис. 1. Кодовое дерево для системы
из трех префиксных кодов: {0, 10, 11}
Удобство древовидного изображения префиксных кодов заключается в том, что именно древовидная структура позволяет сформировать коды переменной длины, отвечающие главному условию префиксных кодов, то есть условию, что более короткие по длине коды не совпадают с началом более длинных кодов.
До сих пор мы рассматривали лишь идею префиксных кодов переменной длины. Что касается алгоритмов получения префиксных кодов, то их можно разработать достаточно много, но наибольшую известность получили два метода: Шеннона—Фано и Хаффмана.
Алгоритм Шеннона—Фано
Данный алгоритм получения префиксных кодов независимо друг от друга предложили Р. Фано и К. Шеннон, заключается он в следующем. На первом шаге все символы исходной информационной последовательности сортируются по убыванию или возрастанию вероятностей их появления (частоты их появления), после чего упорядоченный ряд символов в некотором месте делится на две части так, чтобы в каждой из них сумма частот символов была примерно одинакова. В качестве демонстрации рассмотрим уже знакомое нам слово «авиакатастрофа».
Если символы, составляющие данное слово, отсортировать по убыванию частоты их появления, то получим следующую последовательность: {а(5), т(2), в(1), и(1), к(1), с(1), р(1), о(1), ф(1)} (в скобках указывается частота повторяемости символа в слове). Далее, нам нужно разделить эту последовательность на две части так, чтобы в каждой из них сумма частот символов была примерно одинаковой (насколько это возможно). Понятно, что раздел пройдет между символами «т» и «в», в результате чего образуется две последовательности: {а(5), т(2)} и {в(1), и(1), к(1), с(1), р(1), о(1), ф(1)}. Причем суммы частот повторяемости символов в первой и второй последовательностях будут одинаковы и равны 7.
На первом шаге деления последовательности символов мы получаем первую цифру кода каждого символа. Правило здесь простое: для тех символов, которые оказались в последовательности слева, код будет начинаться с «0», а для тех, что справа — с «1».
Далее повторяем описанную процедуру для каждой из полученных таким делением последовательностей символов, поскольку каждая из них также упорядочена по частоте повторяемости символов.
В частности, последовательность {а(5), т(2)} разделится на два отдельных символа: a(5) и т(2) (других вариантов деления нет). Тогда вторая цифра кода для символа «a» — это «0», а для символа «т» — «1». Поскольку в результате деления последовательности мы получили отдельные элементы, то они более не делятся и для символа «a» получаем код 00, а для символа «т» — код 01.
Последовательность {в(1), и(1), к(1), с(1), р(1), о(1), ф(1)} можно разделить либо на последовательности {в(1), и(1), к(1)} и {с(1), р(1), о(1), ф(1)}, либо на {в(1), и(1), к(1)}, {с(1)} и {р(1), о(1), ф(1)}.
В первом случае суммы частот повторяемости символов в первой и второй последовательностях будут 3 и 4 соответственно, а во втором случае — 4 и 3 соответственно. Для определенности воспользуемся первым вариантом.
Для символов полученной новой последовательности {в(1), и(1), к(1)} (это левая последовательность) первые две цифры кода будут 10, а для последовательности {с(1), р(1), о(1), ф(1)} — 11.
Далее продолжаем описанную процедуру для каждой из полученных последовательностей до тех пор, пока в результате деления последовательностей в них будет оставаться не более одного символа.
В нашем примере (рис. 2 и 3) получается следующая система префиксных кодов: «a» — 00, «т» — 01, «в» — 100, «и» — 1010, «к» — 1011, «с» — 1100, «р» — 1101, «о» — 1110, «ф» — 1111. Как нетрудно заметить, более короткие коды не являются началом более длинных кодов, то есть выполняется главное свойство префиксных кодов.

Рис. 2. Демонстрация алгоритма Шеннона—Фано
на примере слова «авиакатастрофа»

Рис. 3. Кодовое дерево для слова «авиакатастрофа»
в алгоритме Шеннона—Фано
Алгоритм Хаффмана
Алгоритм Хаффмана — это еще один алгоритм получения префиксных кодов переменной длины. В отличие от алгоритма Шеннона—Фано, который предусматривает построение кодового дерева сверху вниз, данный алгоритм подразумевает построение кодового дерева в обратном порядке, то есть снизу вверх (от листовых узлов к корневому узлу).
На первом этапе, как и в алгоритме Шеннона—Фано, исходная последовательность символов сортируется в порядке убывания частоты повторяемости символов (элементов последовательности). Для рассмотренного ранее примера со словом «авиакатастрофа» получим следующую отсортированную последовательность элементов: {а(5), т(2), в(1), и(1), к(1), с(1), р(1), о(1), ф(1)}.
Далее два последних элемента последовательности заменяются на новый элемент S1, которому приписывается повторяемость, равная сумме повторяемостей исходных элементов. Затем производится новая сортировка элементов последовательности в соответствии с их повторяемостью. В нашем случае два последних элемента o(1) и ф(1) заменяются на элемент S1(2), а вновь отсортированная последовательность примет вид: {а(5), т(2), S1(2), в(1), и(1), к(1), с(1), р(1)}.
Продолжая данную процедуру замещения двух последних элементов последовательности на новый элемент с суммарной повторяемостью и последующей пересортировкой последовательности в соответствии с повторяемостью элементов, мы придем к ситуации, когда в последовательности останется всего один элемент (рис. 4).

Рис. 4. Демонстрация алгоритма Хаффмана
на примере слова «авиакатастрофа»
Одновременно с замещением элементов и пересортировкой последовательности строится кодовое бинарное дерево. Алгоритм построения дерева очень прост: операция объединения (замещения) двух элементов последовательности порождает новый узловой элемент на кодовом дереве. То есть если смотреть на дерево снизу вверх, ребра кодового дерева всегда исходят из замещаемых элементов и сходятся в новом узловом элементе, соответствующем элементу последовательности, полученному путем замещения (рис. 5). При этом левому ребру кодового дерева можно присвоить значение «0», а правому — «1». Эти значения в дальнейшем будут служить элементами префиксного кода.

Рис. 5. Построение кодового дерева
в алгоритме Хаффмана
(замещение элементов «o» и «ф»
новым элементом S1)
Полное кодовое дерево, построенное по алгоритму Хаффмана для слова «авиакатастрофа», показано на рис. 6.

Рис. 6. Полное кодовое дерево для слова «авиакатастрофа»,
построенное по алгоритму Хаффмана
Пройдясь по ребрам кодового дерева сверху вниз, легко получить префиксные коды для всех символов нашего информационного алфавита:
a-{0}
т{111}
в{1101}
и{11000}
к{11001}
с{1010}
р{1011}
о{1000}
ф{1001}
Если теперь попытаться написать слово «авиакатастрофа» в кодировке Хаффмана, то получим 41-битную последовательность 0 1101 11000 0 11001 0 111 0 1010 111 1011 1000 1001 0. Интересно отметить, что при использовании префиксных кодов Шеннона—Фано мы также получим 41-битную последовательность для слова «авиакатастрофа». То есть в конкретном примере эффективность кодирования Хаффмана и Шеннона—Фано одинакова. Но если учесть, что реальный информационный алфавит — это 256 символов (а не 14, как в нашем примере), а реальные информационные последовательности — это любые по своему содержанию и длине файлы, то возникает вопрос об оптимальном префиксном коде, то есть коде, который позволяет получить минимальную по длине выходную последовательность.
Можно доказать, что система кодов, полученная с помощью алгоритма Хаффмана, —лучшая среди всех возможных систем префиксных кодов в том плане, что длина результирующей закодированной информационной последовательности получается минимальной. То есть алгоритм Хаффмана является оптимальным.
Основной недостаток алгоритма Хаффмана заключается в сложности процесса построения системы кодов. Тем не менее именно оптимальный алгоритм Хаффмана является самым распространенным алгоритмом генерации кода переменной длины и находит свое воплощение в большинстве утилит сжатия и архивации информации.
Арифметическое кодирование
Как мы уже отмечали, согласно критерию Шеннона, оптимальным является такой код, в котором под каждый символ отводится код длиной –log2 p бит. И если, к примеру, вероятность какого-то символа составляет 0,2, то оптимальная длина его кода будет равна –log2 0,2 = 2,3 бит. Понятно, что префиксные коды не могут обеспечить такую длину кода, а потому не являются оптимальными. Вообще длина кода, определяемая критерием Шеннона, — это лишь теоритический предел. Вопрос лишь в том, какой способ кодирования позволяет максимально приблизиться к этому теоретическому пределу. Префиксные коды переменной длины эффективны и достаточно просты в реализации, однако существуют и более эффективные способы кодирования, в частности алгоритм арифметического кодирования.
Идея арифметического кодирования заключается в том, что вместо кодирования отдельных символов код присваивается одновременно всей информационной последовательности. При этом очевидно, что длина кода, приходящаяся на один отдельный символ, может быть и не целым числом. Именно поэтому такой способ кодирования гораздо эффективнее префиксного кодирования и более соответствует критерию Шеннона.
Идея алгоритма арифметического кодирования заключается в следующем. Как и во всех рассмотренных ранее способах кодирования, каждый символ исходной информационной последовательности характеризуется его вероятностью. Исходной незакодированной последовательности ставится в соответствие полуинтервал [0, 1). Далее, если информационное сообщение содержит N символов, то этот интервал делится на N отдельных полуинтервалов, каждый из которых соответствует какому-то символу. Причем длина полуинтервала, соответствующего какому-либо символу, равна вероятности этого символа. Поясним это на примере. Рассмотрим информационную последовательность слова «макака». Выпишем все символы, входящие в эту последовательность, с указанием их вероятности: {м(1/6), а(3/6), к(2/6)} (сортировка символов может быть произвольной). Далее, выделим на рабочем полуинтервале [0, 1) полуинтервал [0, 1/6), соответствующий символу «м» (длина полуинтервала равна вероятности символа). Затем сделаем то же самое для символа «а», которому будет соответствовать полуинтервал [1/6, 4/6) длиной 3/6. Символу «к» будет соответствовать полуинтервал [4/6, 1) длиной 2/6 (рис. 7).

Рис. 7. Отображение символьного алфавита
на рабочем полуинтервале [0, 1)
для информационной последовательности слова «макака»
В результате мы получим, что любое вещественное число из полуинтервала [0, 1) однозначно соответствует какому-то символу исходной информационной последовательности. К примеру, число 0,4 входит в полуинтервал [1/6, 4/6) и, следовательно, соответствует символу «а».
Представление символов информационного алфавита в соответствии с их вероятностями на рабочем полуинтервале [0, 1) — это подготовительный этап кодирования. Сам процесс кодирования заключается в следующем. Берется первый символ исходной информационной последовательности, и для него определяется соответствующий полуинтервал на рабочем отрезке. Далее этот полуинтервал становится новым рабочим отрезком, который также необходимо разбить на полуинтервалы в соответствии с вероятностями символов. Если бы мы захотели закодировать только один первый символ нашей последовательности, то на этом операция кодирования закончилась бы. Любое вещественное число из нового рабочего полуинтервала соответствовало бы нашему символу. Однако нам нужно закодировать не один символ, а их последовательность. Поэтому берем второй символ и определяем для него соответствующий полуинтервал уже на новом рабочем отрезке. Далее этот полуинтервал становится новым рабочим отрезком, который также необходимо разбить на полуинтервалы в соответствии с вероятностями символов. Причем этот рабочий полуинтервал уже соответствует двум символам информационной последовательности, то есть любое вещественное число из этого нового рабочего полуинтервала соответствует двум первым символам информационной последовательности. Продолжая такие итерации, мы, в конечном счете, получим некоторый полуинтервал, который соответствует всей исходной информационной последовательности.
На каждом шаге итерации необходимо пересчитывать границы всех полуинтервалов на новом рабочем полуинтервале. Пусть, к примеру, первому символу последовательности на рабочем полуинтервале [0, 1) соответствует полуинтервал [a, b), а второму символу — полуинтервал [c, d).
Поскольку на первом шаге кодирования новым рабочим полуинтервалом станет полуинтервал [a, b), то в этом рабочем полуинтервале второму символу будет соответствовать полуинтервал [a+(b–a)×c, a+(b–a)×d). То есть полуинтервал [c, d) сожмется в (b–a) раз. Любое число из полуинтервала [a+(b–a)×c, a+(b–a)×d) однозначно определяет последовательность двух первых символов.
Ну а теперь рассмотрим процесс кодирования на конкретном примере информационной последовательности слова «макака» (рис. 8).
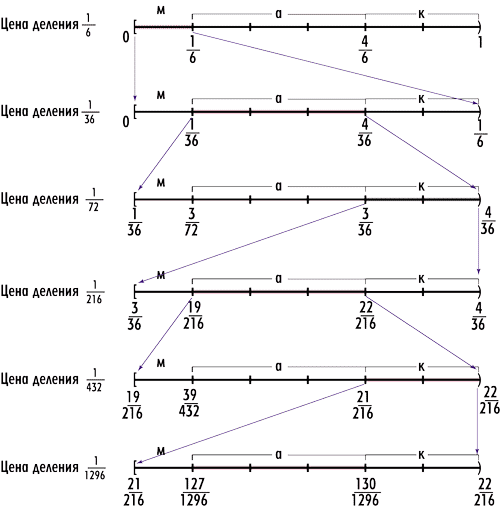
Рис. 8. Демонстрация арифметического кодирования
на примере информационной последовательности «макака»
Итак, первый символ — «м». На рабочем полуинтервале [0, 1) этому символу соответствует полуинтервал [0, 1/6), который становится новым рабочим полуинтервалом.
Далее, на новом рабочем полуинтервале [0, 1/6) откладываем полуинтервалы, соответствующие символам «м», «а» и «к». Символу «м» будет соответствовать уже полуинтервал [0, 1/36), символу «а» — полуинтервал [1/36, 4/36), а символу «к» — полуинтервал [4/36, 1/6). Отметим, что любое число из нового рабочего полуинтервала [0, 1/6) однозначно соответствует символу «м».
Следующий символ последовательности слова «макака» — это «а». На рабочем полуинтервале [0, 1/6) ему соответствует полуинтервал [1/36, 4/36), который и становится новым рабочим полуинтервалом. Далее, на новом рабочем полуинтервале [1/36, 4/36) откладываем полуинтервалы, соответствующие символам «м», «а» и «к». Символу «м» будет соответствовать уже полуинтервал [1/36, 3/72), символу «а» — полуинтервал [3/72, 3/36), а символу «к» — полуинтервал [3/36, 4/36). В данном случае важно, что уже любое вещественное число из рабочего полуинтервала [1/36, 4/36) представляет последовательность «ма».
Чтобы доказать это, рассмотрим число 1/36, входящее в этот полуинтервал. Поскольку это число входит в промежуток [0, 1/6), соответствующий символу «м» на исходном рабочем полуинтервале, то первый символ последовательности — это «м». Далее, необходимо отобразить (расширить) промежуток [0, 1/6) на исходный рабочий полуинтервал [0, 1). Для этого все точки полуинтервала [0, 1/6) делим на его длину (на 1/6). При этом число 1/36 перейдет в число 1/6. То есть мы как бы делаем обратное преобразование. Но число 1/6 на рабочем полуинтервале [0, 1) входит в промежуток [1/6, 4/6), соответствующий символу «а». Следовательно, второй символ последовательности — это «а».
Итак, мы выяснили, что число 1/36 из рабочего промежутка [1/36, 4/36) кодирует последовательность «ма». Пойдем дальше. Следующий символ последовательности «макака» — это «к». На рабочем полуинтервале [1/36, 4/36) ему соответствует промежуток [3/36, 4/36), который и становится новым рабочим полуинтервалом. Далее, на новом рабочем полуинтервале [3/36, 4/36) откладываем промежутки, соответствующие символам «м», «а» и «к». Символу «м» будет соответствовать уже полуинтервал [3/36, 19/216), символу «а» — полуинтервал [19/216, 22/216), а символу «к» — полуинтервал [22/216, 4/36). Любое вещественное число из рабочего полуинтервала [3/36, 4/36) представляет последовательность «мак». Теперь рассмотрим процесс раскодирования этой последовательности. Поскольку число 3/36 или 1/12 входит в полуинтервал [3/36, 4/36), покажем, что это число соответствует последовательности «мак».
Действительно, число 1/12 входит в промежуток [0, 1/6) на исходном рабочем полуинтервале, который соответствует символу «м». Следовательно первый символ — это «м». Далее, проецируем промежуток [0, 1/6) на промежуток [0, 1); при этом число 1/12 отобразится в число 1/2 на рабочем полуинтервале [0, 1). Поскольку число 1/2 входит в полуинтервал [1/6, 4/6), соответствующий символу «а», то второй символ последовательности — это «а». Затем необходимо спроецировать промежуток [1/6, 4/6) на рабочий полуинтервал [0, 1). При этом число 1/2 отобразится в число 2/3. Поскольку это число входит в промежуток [4/6, 1) на рабочем полуинтервале [0, 1), который соответствует символу «к», то третий символ последовательности — это «к».
Продолжая аналогичные действия по кодированию символов, мы придем к рабочему полуинтервалу [127/1296, 130/1296), который будет отвечать за все последовательности слова «макака» (рис. 8). Любое число из этого полуинтервала (например, 127/1296) однозначно определяет всю последовательность слова «макака» а обратное раскодирование осуществляется в шесть шагов.
Единственное, на чем имеет смысл остановиться при обратном раскодировании, это на процедуре проецирования полуинтервала [a, b) на полуинтервал [0, 1). При таком проецировании любая точка, принадлежащая промежутку [a, b), отобразится в точку x = (c – a)/(b – a), что легко доказать геометрически, используя обобщенную теорему Фалеса (рис. 9).

Рис. 9. Проецирование промежутка [a, b)
на промежуток [0, 1)
В качестве примера рассмотрим отображение промежутка [1/6, 2/3) на промежуток [0, 1). При таком проецировании число 1/2 из промежутка [1/6, 2/3) отобразится на число (1/2 – 1/6)/(2/3 – 1/6) = 2/3.
Итак, мы подробно рассмотрели процесс арифметического кодирования-декодирования. Отметим, что, в отличие от префиксного кодирования, в арифметическом кодировании символам не могут быть сопоставлены конкретные кодовые комбинации. Понятие «код» в данном случае несколько абстрактно и применимо только для информационной последовательности в целом. Здесь можно говорить только о вкладе, вносимом каждым символом, входящим в кодируемое информационное сообщение, в результирующую кодовую комбинацию. Этот вклад определяется длиной интервала, соответствующего символу, то есть вероятностью появления символа. Также отметим, что для возможности процесса декодирования декодер должен иметь информацию о том, какой именно промежуток соответствует каждому символу информационного алфавита на рабочем полуинтервале [0, 1). То есть данная информация является служебной и должна быть доступна декодеру.
До сих пор мы ничего не говорили о самом коде, который получится в результате арифметического кодирования. В рассмотренном нами примере со словом «макака» процесс арифметического кодирования завершился тем, что любое число из промежутка [127/1296, 130/1296) представляет последовательность «макака». Вопрос в том, какое именно число выбрать и как ему поставить в соответствие двоичный код. Можно использовать следующий способ: взять любое число из результирующего промежутка, перевести его в двоичную форму и отбросить целую часть двоичной дроби, равную нулю, — оставшаяся последовательность нулей и единиц и будет нашим кодом. Можно использовать и десятичное представление числа, но опять-таки использовать только дробную часть числа (отбросить ноль и десятичную запятую), представив ее в двоичном виде, который и задаст код последовательности.
Однако, не все так просто, как может показаться. Вообще, описанный нами алгоритм предполагает, что границы полуинтервалов представляются числами с неограниченной точностью. Кроме того, представляется проблемой выбор самого числа из конечного рабочего промежутка. Если, например, условиться использовать левую границу полуинтервала, то может оказаться, что она представляется в виде бесконечной десятичной дроби. Одним словом, при применении данного алгоритма возникает проблема манипуляций над числами, содержащими большое количество знаков после запятой.
Поэтому любая практическая реализация арифметического кодера должна основываться на операциях с целыми числами, которые не должны быть слишком длинными.
Идея заключается в том, чтобы числа, определяющие концы полуинтервалов, определялись бы целыми числами с разрядностью 16, 32 или 64 бита. Казалось бы, как это можно реализовать, если концы промежутков могут иметь неограниченное число знаков после запятой?
Прежде всего отметим, что все наши числа имеют вид 0,xxx… Поэтому 0 перед запятой можно отбросить и рассматривать лишь последовательности цифр после запятой. Далее, если концы всех промежутков выписать в десятичных дробях, можно заметить, что как только самые левые цифры чисел (рассматривается только дробная часть, то есть цифры после запятой), которые определяют концы рабочего полуинтервала на каждом шаге итерации, становятся одинаковыми, они уже не меняются в дальнейшем (на следующих итерациях). Отметим, что в нашем примере c последовательностью «макака» мало шагов итераций и даже на конечном шаге нет одинаковых левых цифр чисел, но при большем числе итераций они неизбежно появятся. Одинаковые цифры можно выдвинуть за скобки и работать с оставшейся дробной частью, которая ограничивается по длине. В ходе итераций уточняется последовательность цифр, выдвинутых за скобки, которая и представляет собой код.
Итак, метод арифметического кодирования — один из самых эффективных по степени сжатия алгоритмов, но скорость такого кодирования невысока.
Алгоритм LZW
Еще один распространенный алгоритм кодирования получил название LZW — по первым буквам фамилий его разработчиков: Lempel, Ziv и Welch (алгоритм Лемпеля—Зива—Велча).
Алгоритм был опубликован Велчем в 1984 году в качестве улучшенной реализации алгоритма LZ78, представленного Лемпелем и Зивом в 1978 году, и был запатентован фирмой Sperry.
Алгоритм LZW использует идею расширения информационного алфавита. Вместо традиционного 8-битного представления 256 символов ASCII-таблицы обычно используется 12-битное, что позволяет определить таблицу на 4096 записей.
Идея алгоритма LZW заключается в том, чтобы заменять строки символов некоторыми кодами, для чего и используется таблица на 4096 записей. Это делается без какого-либо анализа входной последовательности символов. При добавлении каждой новой строки символов просматривается таблица строк. Сжатие происходит, когда строка символов заменяется кодом. Первые 256 кодов (когда используются 8-битные символы) по умолчанию соответствуют стандартному набору символов, то есть значения кодов 0-255 соответствуют отдельным байтам. Остальные коды (256-4095) соответствуют строкам обрабатываемым алгоритмом.
По мере кодирования последовательно считываются символы входного потока и проверяется, есть ли в созданной таблице строк такая строка. Если она есть, то считывается следующий символ, а если нет, то в выходной поток заносится код для предыдущей найденной строки, в таблицу заносится новая строка и поиск начинается снова.
Рассмотрим в качестве примера входную последовательность ABCABCABCABCABCABC#. Маркер # будет символизировать конец исходного сообщения.
Для простоты будем считать, что используются только заглавные буквы английского алфавита (26 букв) и маркер # конца сообщения. Соответственно для перебора всех букв нашего алфавита достаточно 5 бит (25 = 32). Теперь предположим, что символы нашего алфавита кодируются по номеру буквы в алфавите от 1 до 26 следующим образом:
#=00000 (010)
A=00001 (110)
B=00010 (210)
C=00011 (310)
Последний символ Z будет иметь код 11010 (2610).
Отметим, что когда в нашей таблице кодов появится символ с кодом 32, то алгоритм должен перейти к 6-битным группам.
В нашем примере первый символ — это «A». Поскольку при инициализации в таблицу были занесены все односимвольные строки, то строка, соответствующая символу «A», в таблице есть (код символа 00001).
Далее считывается следующий символ «B» из входного потока и проверяется, есть ли строка «AB» в таблице. Такой строки в таблице пока нет. Поэтому данная строка заносится в таблицу с первым свободным кодом 100 000 (3210), а в выходной поток записывается код 00001, соответствующий предыдущему символу («A»).
Далее начинаем с символа, которым оканчивается последняя занесенная в таблицу строка, то есть с символа «B». Поскольку символ «B» есть в таблице, то считываем следующий символ «C». Строки «BC» в таблице нет, поэтому заносим эту строку в таблицу под кодом 100 001 (3310), а в выходной поток записывается код 00010, соответствующий предыдущему символу ( «В»).
Далее начинаем с символа, которым оканчивается последняя занесенная в таблицу строка, то есть с символа «С». Поскольку символ «С» есть в таблице, то считываем следующий символ «A». Строки «CA» нет в таблице, поэтому заносим эту строку в таблицу под кодом 100 010 (3410), а в выходной поток записывается код 00011, соответствующий предыдущему символу (символу «C»).
Затем начинаем с символа, которым оканчивается последняя занесенная в таблицу строка, то есть, с символа «A». Поскольку символ «A» есть в таблице, то считываем следующий символ «B». Строка «AB» уже есть в таблице, поэтому считываем следующий символ «C». Строки «ABC» нет в таблице, поэтому заносим эту строку в таблицу под кодом 100 011 (3510), а в выходной поток записывается код 100 000, соответствующий предыдущему символу в таблице (строке «AB»).
Далее начинаем с символа «C». Поскольку он уже есть в таблице, считываем следующий символ «A». Строка «CA» уже есть в таблице, поэтому считываем следующий символ «B». Строки «CAB» нет в таблице, поэтому заносим ее туда, а в выходной поток записываем код 100 010, соответствующий строке «CA».
Продолжая подобным образом, построим таблицу кодов для всего сообщения ABCABCABCABCABCABC# (табл. 1).
Особенность алгоритма LZW заключается в том, что для декодирования нет необходимости сохранять таблицу строк в файл для распаковки. Алгоритм построен таким образом, что можно восстановить таблицу строк, пользуясь только потоком кодов.
В заключение отметим, что алгоритм LZW находит применение в сжатии растровых изображений (форматы JPG, TIFF), а также в таком популярном формате, как PDF.
Другие методы кодирования
Мы рассмотрели лишь несколько наиболее известных алгоритмов сжатия данных, дабы дать читателям поверхностное представление о методах сжатия данных. Конечно же, самих алгоритмов сжатия разработано очень много, и их рассмотрение не входит в задачи данной публикации. Тем не менее при рассмотрении архиваторов WinRAR, WinZip и 7-Zip можно встретить упоминание о таких алгоритмах кодирования, как PPMd, LZMA и bzip2. А потому вкратце поясним, о чем идет речь.
Итак, начнем с метода PPM (PPMd — это одна из многочисленных вариаций метода PPM).
PPM (Prediction by Partial Matching) — это алгоритм сжатия данных без потерь, основанный на контекстном моделировании и предсказании (предсказание по частичному совпадению).
Метод PPM был предложен еще в 1984 году Клири (Cleary) и Уиттеном (Witten) и до настоящего времени широко используется, поскольку является одним из наиболее эффективных методов экономного кодирования.
В рассмотренных нами ранее методах для кодирования информационных сообщений требовалось знание вероятности появления символов. В случае если нет никакой дополнительной информации об источнике, определить эти вероятности можно только путем статистического анализа его информационной выборки. Данный принцип лежит в основе статистических методов экономного кодирования, к которым относится и метод PPM.
В модели PPM используется понятие так называемого контекста, под которым понимается множество символов в несжатом потоке, предшествующих данному. На основе статистики, собираемой в процессе обработки информации, статистический метод позволяет оценить вероятность появления в текущем контексте произвольного символа или последовательности символов.
Длина контекста, применяемого при предсказании, обычно очень ограниченна. Эта длина обозначается N и называется порядком контекста, или порядком модели PPM. Если предсказание символа по контексту из N символов не может быть произведено, то предпринимается попытка предсказать его с помощью контекста более низкого порядка. Рекурсивный переход к моделям с меньшим порядком реализуется, пока предсказание не произойдет в одной из моделей либо когда контекст приобретет нулевую длину (N = 0).
Сам алгоритм PPM лишь предсказывает значение символа, а непосредственное сжатие осуществляется такими алгоритмами, как алгоритм Хаффмана или арифметическое кодирование.
Отметим, что алгоритм PPM имеет множество вариаций и используется, в частности, в архиваторах WinRAR (алгоритмы PPMd и PPMII), 7-Zip (алгоритм PPMd) и WinZip (алгоритм PPMd).
Еще один часто применяемый алгоритм сжатия — это LZMA (Lempel-Ziv-Markov chain-Algorithm), который был разработан в 2001 году и является своеобразным вариантом алгоритма LZW. В этом алгоритме используется метод скользящего окна и интервального кодирования.
Алгоритм LZMA находит применение в архиваторах 7-Zip и WinZip.
Последний алгоритм, о котором мы упомянем, — это алгоритм bzip2, основанный на преобразовании Барроуза—Уилера (Burrows—Wheeler Transform, BWT). В алгоритме bzip2 преобразование BWT используется для превращения последовательностей многократно чередующихся символов в строки одинаковых символов, а затем применяется преобразование MTF, а в заключение — кодирование Хаффмана. Процесс BWT-преобразования очень прост — он выполняется в три этапа, которые мы рассмотрим на примере исходной информационной последовательности «BANAN».
На первом этапе составляется таблица всех циклических сдвигов входной строки. В нашем случае из строки «BANAN» мы получим путем циклического сдвига еще четыре строки: «ANANB», «NANBA», «ANBAN» и «NBANA».
На следующем этапе производится сортировка в алфавитном порядке всех полученных строк, включая исходную (табл. 2). На последнем этапе мы выписываем строку, полученную по последним символам (сверху вниз) всех отсортированных строк. То есть если все отсортированные строки представить в виде матрицы, то нужная нам строка образована последним столбцом этой матрицы. В нашем случае получим строку «BNNAA». Кроме того, для возможности восстановления исходной строки по преобразованной нам нужно запомнить еще и номер исходной строки в отсортированном списке строк. В нашем случае это третья строка, поэтому результат преобразования можно записать как BWT = («BNNAA», 3).
Важно, что в результате BWT-преобразования все повторяющиеся символы группируются вместе, что очень удобно для последующего кодирования.
Теперь посмотрим, как сделать обратное преобразование. Итак, мы имеем результат преобразования в виде «BNNAA», 3.
Сначала записываем в столбик нашу строку «BNNAA». Затем сортируем все символы этого столбца в алфавитном порядке. Далее, слева от полученного столбца записываем столбец «BNNAA» и производим сортировку в алфавитном порядке уже всех двухсимвольных строк. Далее дописываем к эти двум столбцам слева опять столбец «BNNAA» и производим сортировку в алфавитном порядке уже всех трехсимвольных строк. Процедуру продолжаем до тех пор, пока строки не будут содержать по пять символов. В отсортированной по пяти символам матрице находим третью строку (напомним, что номер три мы изначально запомнили), которая и будет представлять раскодированную последовательность символов (табл. 3).
Как видите, прямое и обратное BWT-преобразование реализуется очень просто.
Итак, мы рассмотрели наиболее важные алгоритмы сжатия информации, которые находят применение в современных архиваторах. При этом мы преследовали лишь одну цель — продемонстрировать, каким образом можно реализовать сжатие информации без потерь. Однако мы не стремились к детальному рассмотрению всех алгоритмов сжатия информации, тем более что количество их огромно.
Ну а теперь давайте познакомимся с тремя наиболее популярными архиваторами, реализующими сжатие данных без потерь с использованием различных алгоритмов.
Тестируемые архиваторы
WinRAR 4.2
Архиватор WinRAR — это Windows-версия архиватора RAR. Он предназначен для создания архивов в форматах RAR и ZIP. Кроме того, этот архиватор позволяет распаковывать архивы форматов 7Z, ACE, ARJ, BZIP2, CAB, GZ, ISO, JAR, LZH, TAR, UUE, Z.
Существует 32- и 64-разрядная версия WinRAR. В дальнейшем мы будем рассматривать только 64-битную версию.
WinRAR позволяет создавать крупный архив с дроблением его на части (тома) заданного размера. Это очень удобно, когда необходимо передать большой объем данных через файлообменные серверы в Интернете, большинство из которых обладают ограничением по размеру одного передаваемого файла. Кроме того, можно использовать архивацию без сжатия, когда множество файлов и папок объединяются в один общий файл (архив). Данный способ часто используется для повышения скорости копирования, поскольку один архивный файл будет копироваться гораздо быстрее, чем множество отдельных файлов.
Среди функций WinRAR также стоит выделить возможность создания самораспаковывающихся SFX-архивов, распаковать которые можно без всяких архиваторов. Кроме того, пользуясь WinRAR, можно надежно защитить содержимое архива от свободного просмотра и распаковки с помощью пароля.
WinRAR также имеет встроенную командную строку, что очень удобно при написании различных скриптов.
При архивации WinRAR позволяет выбрать один из пяти вариантов сжатия (Store, Fastest, Fast, Normal, Good, Best). Вариант Store подразумевает отсутствие сжатия, а вариант Best — максимальную степень сжатия, но и максимальное время архивации.
Архиватор WinRAR является платным.
WinZip 17
Архиватор формата ZIP (PKZIP) был первоначально создан для MS-DOS в 1989 году компанией PKWare и сегодня является одним из самых распространенных. Версия WinZip появилась в 1990-м как коммерческий графический интерфейс для PKZIP.
В мае 2006 года корпорация Corel объявила о приобретении WinZip Computing.
В конце 2012-го компания WinZip Computing (подразделение компании Corel) представила новую русифицированную версию приложения WinZip 17, которая оптимизирована для многоядерных процессоров и поддерживает возможность использования вычислительных мощностей графических процессоров, встроенных в процессоры Intel Core третьего поколения, процессоры AMD A-Series APU, а также дискретные графические карты AMD Radeon и NVIDIA GeForce.
Архиватор WinZip 17 является 64-битным и позволяет создавать архивы в форматах ZIP и ZIPX, а также распаковывать архивы форматов 7Z, RAR, BZIP2, LHA/LZH, CAB, ISO и других (каких именно, в документации не уточняется).
Вообще архиватор WinZip 17 обладает большим количеством дополнительных возможности и функций, но сейчас мы их касаться не будем, а рассмотрим лишь его возможности по созданию архивов.
Естественно, WinZip 17 позволяет создавать архив с дроблением его на тома заданного размера. Кроме того, можно использовать архивацию без сжатия, когда множество файлов и папок объединяются в один общий файл (архив).
Кроме того, поддерживается возможность шифрования архива (128- и 256-битное AES-шифрование).
При архивации WinZip позволяет задать уровень компрессии и алгоритм сжатия. Для формата ZIPX можно выбрать алгоритм PPMd, LZMA или bzip2, которые обеспечивают очень высокую степень сжатия. Кроме того, имеется вариант, называемый Best Method, предусматривающий максимальную степень сжатия. При выборе данного метода архиватор сам выбирает оптимальный алгоритм сжатия, обеспечивающий максимальную степень компрессии, в зависимости от типа файла.
Также отметим, что WinZip не имеет встроенной командной строки, однако в случае ее необходимости можно скачать дополнение WinZip Command Line Support Add-On Version 3.2, которое обеспечивает работу с командной строкой.
Архиватор WinZip является платным.
7-Zip 9.30
В отличие от архиваторов WinRAR и WinZip, архиватор 7-Zip абсолютно бесплатный. 7-Zip — это программное обеспечение с открытым кодом, при этом большая часть исходного кода находится под лицензией GNU LGPL.
Существует как 32-, так и 64-битная версии этого архиватора. Текущей версией, появившейся в конце 2012 года, является версия 9.30.
Архиватор 7-Zip имеет удобный графический интерфейс, но при этом поддерживает работу с командной строкой.
Основным форматом для архиватора 7-Zip является собственный формат 7Z с компрессией LZMA. Кроме того, 7-Zip позволяет производить архивирование/разархивирование в форматах ZIP, GZIP, BZIP2 и TAR. Также поддерживается разархивирование форматов ARJ, CAB, CHM, CPIO, DEB, DMG, HFS, ISO, LZH, LZMA, MSI, NSIS, RAR, RPM, UDF, WIM, XAR и Z.
Как утверждает производитель, архиватор 7-Zip обеспечивает степень сжатия выше, чем RAR, за исключением мультимедийных данных. Более того, считается, что по степени сжатия 7-Zip уступает только архиваторам PAQ и его GUI-модификации KGB, которые, однако, имеют на порядок большее время сжатия.
Для форматов ZIP и GZIP архиватор 7-Zip предлагает сжатие, которое на 2-10% лучше, чем предоставляемое архиваторами PKZip и WinZip
Программа поддерживает работу на 64-битных операционных системах. Интерфейс программы переведен на множество языков, включая русский.
Отметим, что архиватор позволяет создавать самораспаковывающиеся архивы для формата 7z. Кроме того, поддерживается шифрование AES 256-бит.
Естественно, архиватор 7-Zip (как WinZip и WinRAR) интегрируется в проводник Windows и доступен через контекстное меню.
Еще одна особенность заключается в том, что в архиваторе 7-Zip предусмотрен плагин для FAR Manager.
Для своего родного формата 7z архиватор позволяет выбрать уровень сжатия (без сжатия, «Скоростной», «Быстрый», «Нормальный», «Максимальный», «Ультра»), а также задать алгоритм сжатия (LZMA2, LZMA, PPMd, BZip2).
Кроме того, дополнительно можно задать размер словаря, размер слова, размер блока и число потоков.
Также поддерживается создание архивов, разбитых на тома заданного размера.
Методика тестирования
Для тестирования архиваторов мы использовали стенд следующей конфигурации:
- процессор — Intel Core i7-3770K;
- материнская плата — Gigabyte GA-Z77X-UD5H;
- память — DDR3-1600 (2×4 Гбайт);
- накопитель — Intel SSD 520 Series 240 Гбайт;
- видеокарта — NVIDIA GeForce GTX 660Ti (видеодрайвер 314.07).
На стенде устанавливалась операционная система Windows 8 Ultimate (64-бит).
Для архивации были подготовлены следующие типы данных:
пятьдесят аудиофайлов в формате MP3 общим размером 841 Мбайт;
десять видеоклипов в формате MOV, снятых фотокамерой Canon EOS Mark II 5D с разрешением 1920×1080 (25 FPS, Bitrate 46 362 Кбит/с). Общий размер всех клипов — 1,48 Гбайт;
24 фотографии в формате TIFF, снятых фотокамерой Canon EOS Mark II 5D. Размер каждой фотографии — 60,1 Мбайт; размер всех фотографий — 1,41 Гбайт;
три текстовых файла (формат dic) общим размером 722 Мбайт.
Каждый из архиваторов запускался со всеми предусмотренными уровнями компрессии с алгоритмом компрессии по умолчанию. Все остальные установки архиватора (размер словаря, размер слова, размер блока) также использовались по умолчанию. Для каждого архиватора мы применялся только родной формат архива, то есть RAR для WinRAR, ZIP и ZIPX для WinZip и 7Z для 7-Zip.
Запуск архиватора осуществлялся с помощью стандартной процедуры с использованием контекстного меню Проводника Windows.
Поскольку архиватор WinZip 17.0 поддерживает возможность применения графического процессора через Open CL для ускорения процесса архивации, мы протестировали этот архиватор как с поддержкой использования графического процессора, так и без оного. Соответствующая опция реализуется в настройках архиватора.
Для каждого типа данных измерялось время архивации, время разархивации и коэффициент сжатия, который рассчитывался как отношение размера несжатых данных к размеру заархивированных данных.
Кроме того, рассчитывался и интегральный показатель архивации как отношение коэффициента сжатия к суммарному времени архивации и разархивации, а полученное число для удобства представления умножалось на 100. Чем выше коэффициент сжатия и чем меньше суммарное время архивации и разархивации, тем лучше.
Результаты тестирования
WinRAR 4.2
Архиватор WinRAR 4.2 был протестирован с четырьмя уровнями компрессии: Fastest, Fast, Normal, Good и Best. Отметим, что по умолчанию используется уровень компрессии Normal. Размер словаря при архивации по умолчанию составлял 4096 Кбайт.
Итак, обратимся к результатам тестирования. Прежде всего отметим, что время архивирования действительно меняется в зависимости от уровня компрессии. Тем не менее если говорить о таких данных, как аудиофайлы, то для режимов Fast, Normal, Good и Best время архивации практически не меняется. Аналогично и для видеофайлов время архивации примерно одинаково в режимах Fast, Normal, Good и Best (рис. 10).

Рис. 10. Время архивации в различных режимах работы архиватора WinRAR 4.2
Степень сжатия вообще слабо зависит от установленного уровня компрессии. Так, для всех режимов работы (Fast, Normal, Good и Best) степень сжатия одинакова для видео и аудиофайлов (эти данные практически не сжимаются). Кроме того, по степени сжатия для всех типов данных оказываются практически одинаковыми режимы Normal, Good и Best (рис. 11).

Рис. 11. Степень сжатия в различных режимах работы архиватора WinRAR 4.2
Время разархивации данных получается одинаковым практически для всех режимов (рис. 12).

Рис. 12. Время разархивации данных, сжатых с различными уровнями компрессии,
архиватором WinRAR 4.2
Вообще, анализируя полученные данные, можно сказать, что режимы Normal, Good и Best мало чем отличаются друг от друга. Степень сжатия в этих режимах получается практически одинаковой, время разархивации данных, сжатых в этих режимах, тоже почти одинаково и лишь немного различается время архивации для указанных режимов работы.
Если же говорить об оптимальном режиме сжатия для архиватора WinRAR, то это режим Fastest, который позволяет очень быстро создавать архивы при степени сжатия, которая лишь немного уступает степени сжатия в режимах Normal, Good и Best (рис. 13).
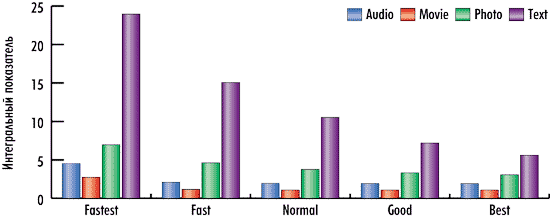
Рис. 13. Интегральная оценка архивации для различных режимов работы WinRAR 4.2
WinZip 17.0
Архиватор WinZip 17.0 был протестирован с различными уровнями компрессии и алгоритмами сжатия:
- super fast;
- Legacy compression;
- enhanced deflate;
- bzip2;
- LZMA;
- PPMd;
- best method.
Алгоритмам сжатия PPMd, LZMA, bzip2 и best method соответствуют архивы в форматах ZIPX, а остальным — в форматах ZIP.
Как уже отмечалось, архиватор WinZip 17.0 может использовать вычислительную мощность графического ядра через язык Open CL. Поэтому один раз этот архиватор был протестирован с использованием графического процессора, а второй раз — без.
Сразу же отметим, что режим работы архиватора WinZip 17.0 c графическим адаптером — это, мягко говоря, фикция. Во всяком случае использование видеокарты NVIDIA GeForce GTX 660Ti вкупе с видеодрайвером 314.07 не дает никакого эффекта. Результаты тестирования с ним и без него Open CL вообще не различаются. А потому в дальнейшем мы не будем делать различий этих двух режимов работы архиватора WinZip 17.0
По результатам тестирования нужно отметить, что время архивирования очень зависит от установленного уровня компрессии и алгоритма сжатия, а также от типа данных. Так, режим максимального сжатия с применением алгоритма PPMd требует очень много времени, особенно для аудио и видеофайлов. Режим максимального сжатия при использовании алгоритма LZMA требует много времени для фотографий. Самыми скоростными оказываются режимы super fast, Legacy compression и enhanced deflate (рис. 14).

Рис. 14. Время архивации в различных режимах работы архиватора WinZip 17
Если говорить о степени сжатия, то ситуация следующая. Архиватор WinZip 17 практически не может сжимать аудио и видеофайлы, а вот текстовые файлы и фотографии сжимаются очень неплохо. Наибольшая степень сжатия достигается при максимальном сжатии с алгоритмом LZMA и в режиме best method, когда архиватор сам определяет оптимальный алгоритм сжатия в зависимости от типа данных (рис. 15).

Рис. 15. Степень сжатия в различных режимах работы архиватора WinZip 17
Время разархивации данных получается практически одинаковым для режимов сжатия enhanced deflate, Legacy compression и super fast (рис. 16). А вот для режима сжатия PPMd время разархивации гораздо больше.

Рис. 16. Время разархивации данных, сжатых с различными уровнями компрессии,
архиватором WinZip 17
Что касается оптимального режима сжатия для архиватора WinZip, то для всех типов данных это режим super fast, который позволяет очень быстро создавать архивы при степени сжатия, лишь немного уступающей степени сжатия в других режимах (рис. 17).

Рис. 17. Интегральная оценка архивации для различных режимов работы WinZip 17
7-Zip 9.30
Архиватор 7-Zip 9.30 был протестирован с четырьмя уровнями сжатия: «Скоростной», «Быстрый», «Нормальный», «Максимальный» и «Ультра» (по умолчанию используется уровень компрессии «Нормальный»).
Такие настройки, как метод сжатия, размер словаря, размер слова, размер блока и число потоков в настройках архиватора не изменялись, то есть использовались по умолчанию. Отметим, что по умолчанию применяется алгоритм сжатия LZMA2, а размер словаря, размер слова и размер блока зависит от уровня сжатия.
Итак, обратимся к результатам тестирования. Прежде всего отметим, что для всех типов данных время архивирования зависит от используемого уровня сжатия, что вполне логично (рис. 18).

Рис. 18. Время архивации в различных режимах работы архиватора 7-Zip 9.30
А вот степень сжатия слабо зависит от выбранного уровня сжатия. Для уровней сжатия «Скоростной» и «Быстрый» для всех типов данных получаются практически одинаковые степени сжатия, так же как и для уровней сжатия «Нормальный», «Максимальный» и «Ультра». Кроме того, нужно отметить, что 7-Zip 9.30 (как и остальные архиваторы) практически не сжимает аудио и видеофайлы (рис. 19).

Рис. 19. Степень сжатия в различных режимах работы архиватора 7-Zip 9.30
Время разархивации данных получается одинаковым для всех режимов сжатия. Исключение составляет лишь видеофайлы, для которых время разархивации зависит от того, с каким уровнем сжатия данные были архивированы (рис. 20).

Рис. 20. Время разархивации данных, сжатых с различными уровнями компрессии,
архиватором 7-Zip 9.30
Что касается оптимального режима сжатия для архиватора 7-Zip 9.30, то это режим «Скоростной» — он позволяет очень быстро создавать архивы при степени сжатия, которая лишь немного уступает степеням сжатия во всех остальных режимах (рис. 21).

Рис. 21. Интегральная оценка архивации для различных режимов работы 7-Zip 9.30
Сравнение архиваторов
В заключение попытаемся сравнить три протестированных нами архиватора друг с другом.
Понятно, что у архиваторов различные режимы работы, и в этом смысле их достаточно сложно сравнивать друг с другом. Поэтому мы сравним архиваторы в двух режимах работы: в режиме, обеспечивающем сжатие с максимальной скоростью, и в режиме, обеспечивающем максимальное сжатие.
Режим, обеспечивающий максимальную скорость архивации, — это «Скоростной» для архиватора 7-Zip 9.30; super fast для архиватора WinZip 17.0 и Fastest для архиватора WinRAR 4.2.
Режим, обеспечивающий максимальное сжатие, — это «Ультра» для архиватора 7-Zip 9.30; best method для архиватора WinZip 17.0 и Best для архиватора WinRAR 4.2.
Итак, в режиме, обеспечивающем сжатие с максимальной скоростью, лидером по времени сжатия является архиватор WinZip 17.0 — он обеспечивает минимальное время сжатия для всех типов данных (рис. 22).

Рис. 22. Время архивации в режиме сжатия с максимальной скоростью
По коэффициенту сжатия в режиме архивации с максимальной скоростью лидером опять-таки является архиватор 7-Zip 9.30 — он обеспечивает наилучшее сжатие для фотографий и текста (для аудио и видеофайлов все архиваторы обеспечивают одинаковое сжатие) — рис. 23.

Рис. 23. Степень сжатия в режиме сжатия с максимальной скоростью
Тем не менее по интегральной оценке лидером все равно является архиватор WinZip 17.0 — именно обеспечивает наилучшее сжатие с учетом времени архивации для всех типов данных (рис. 24).

Рис. 24. Интегральная оценка в режиме сжатия с максимальной скоростью
В режиме, обеспечивающем максимальное сжатие, лидером по времени сжатия является архиватор WinRAR 4.2, обеспечивающий минимальное время сжатия для всех типов данных (рис. 25).

Рис. 25. Время архивации в режиме максимального сжатия
По коэффициенту сжатия в режиме максимального сжатия архиваторы 7-Zip 9.30 и WinZip 17 практически одинаковы и немного обгоняют архиватор WinRAR 4.2 по сжатию текста, но уступают ему по сжатию фотографий (рис. 26).
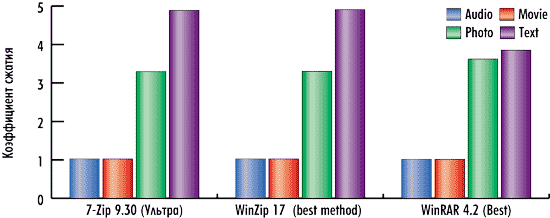
Рис. 26. Время архивации в режиме максимального сжатия
Однако по интегральной оценке, учитывающей степень сжатия и время архивации, лидером все равно является архиватор WinRAR 4.2 (рис. 27).

Рис. 27. Интегральная оценка в режиме максимального сжатия
Итак, по результатам нашего тестирования лучшими являются архиватор WinRAR 4.2 в режиме максимальной степени сжатия и архиватор WinZip 17.0 в режиме максимальной скорости сжатия.








