Вавилонское столпотворение в Интернете
Как работают поисковые системы
AllTheWeb/Fast Search (www.alltheweb.com)
Яндекс (www.yandex.ru или www.ya.ru)
По библейской легенде в незапамятные времена жители города Вавилона задумали построить башню до небес, чтобы стать выше Бога. Но Господь, разгневавшись на такую дерзость, смешал языки и заставил людей заговорить на разных наречиях. Наступил хаос, поскольку люди перестали понимать друг друга.
Интернет, в свою очередь, задумывался с целью расширения интеллектуальных и образовательных возможностей человека, но по мере его роста и проникновения в широкие массы его развитие превратилось в своего рода вавилонское столпотворение. Сегодня каждый пользователь на себе может ощутить один из главных парадоксов Интернета — полезной информации становится все больше, но найти что-либо необходимое — все сложнее. (Попробуйте, например, набрать в поисковой системе ставший уже анекдотическим запрос: «детские рассказы о животных». Только проследите за тем, чтобы дети не увидели результатов этого поиска…)
Таким образом, замусоривание информации — головная боль человека XXI века. И чем больше информации в Интернете, тем эта проблема острее, поэтому любая работа, направленная на снижение остроты данной проблемы, имеет сегодня все шансы на успех.
Как работают поисковые системы
![]() тобы
успевать за лавинообразным ростом объема информации в Интернете, поисковые алгоритмы
постоянно меняются, создаются дополнительные сервисы, дорабатывается дизайн
и т.д. Словом, нет предела совершенствованию поисковых машин — чтобы выжить,
они должны соответствовать быстро расширяющемуся Интернету. При этом разработчики,
занятые постоянной оптимизацией и приспособлением существующих поисковых машин
к растущим объемам информации, пытаются также реализовать что-то новое, что,
с их точки зрения, действительно важно и необходимо для повышения эффективности
поиска.
тобы
успевать за лавинообразным ростом объема информации в Интернете, поисковые алгоритмы
постоянно меняются, создаются дополнительные сервисы, дорабатывается дизайн
и т.д. Словом, нет предела совершенствованию поисковых машин — чтобы выжить,
они должны соответствовать быстро расширяющемуся Интернету. При этом разработчики,
занятые постоянной оптимизацией и приспособлением существующих поисковых машин
к растущим объемам информации, пытаются также реализовать что-то новое, что,
с их точки зрения, действительно важно и необходимо для повышения эффективности
поиска.
Однако, как мы покажем ниже, многие современные методы поиска информации в Сети крайне архаичны и даже порочны в своей основе, а новые алгоритмы оптимизации только усугубляют проблему информационного засорения той небольшой части Интернета, которую видят сегодня поисковики и которая является всего лишь верхушкой информационного айсберга. Все это может привести в недалеком будущем к тому, что пользователям поисковых систем придется копаться в одном только мусоре, попсе и рекламе, а все более или менее серьезное будет надежно погребено под грудами этой ерунды и станет доступным только по прямым ссылкам, узнать которые будет весьма непросто.
Современные поисковые системы имеют многоуровневую организацию, и в основе своей все они состоят из пяти программных компонентов:
- Spider (паук) — эта браузероподобная программа планомерно путешествует по Сети и скачивает все попавшиеся ей на пути Web-узлы (страницы по глобальным URL-ссылкам). По сути, Spider работает точно так же, как и любой Web-браузер, только ничего не визуализирует, а лишь считывает HTML-код;
- Crawler (сборщик, или путешествующий паук) — это порождаемый Spider’ом процесс, который углубляет поиск, перемещаясь по всем локальным ссылкам, найденным на странице. Как и Spider, сборщик тоже скачивает страницы, но уже способен их анализировать в поисках перекрестных ссылок. Собственно, его основные задачи — сканирование Интернет-ресурсов в поисках изменений на страницах и определение того, куда он должен идти дальше, основываясь на найденных ссылках или исходя из заранее заданного списка адресов;
- Indexer (индексатор) — ключевая программа поисковой системы, которая анализирует Web-страницы, скачанные пауками, определяет их тематическую принадлежность, актуальность, популярность у пользователей и т.д. Индексатор разбирает страницу на части и анализирует такие ее элементы, как заголовки страниц, ссылки, тексты, структурные элементы, стилевые элементы и т.д. По окончании анализа он индексирует ресурсы, то есть строит базы данных по ключевым словам и сохраняет эти базы данных в удобном для поиска виде;
- Database (база данных) — хранилище скачанных и обработанных индексатором страниц. Такая база данных требует огромных ресурсов для хранения информации и нуждается в эффективных алгоритмах доступа;
- Gateway (шлюз) или Search engine/Results engine (собственно поисковая машина) — принимает запросы от пользователей, анализирует их и извлекает результаты поиска из базы данных. Именно эта система решает, какие страницы удовлетворяют запросу пользователя, и предоставляет ему интерфейс для просмотра и уточнения этих результатов.
Таково краткое описание функционирования поисковой системы, которое, возможно, не совсем точно соответствует действительности, но позволяет нам получить представление о том, чего можно ожидать от поиска информации в Сети и какие факторы могут затруднить нахождение требуемого.
Степень против экспоненты
 ачнем
с самого начала — с роботов-пауков и индексатора. Хотя программы-поисковики
производят отбор результатов на основании собственных, постоянно меняющихся
критериев и алгоритмов, но, судя по социологическим исследованиям, наибольшую
популярность из них имеют те, которые всего-навсего смогли проиндексировать
наибольшее количество документов.
ачнем
с самого начала — с роботов-пауков и индексатора. Хотя программы-поисковики
производят отбор результатов на основании собственных, постоянно меняющихся
критериев и алгоритмов, но, судя по социологическим исследованиям, наибольшую
популярность из них имеют те, которые всего-навсего смогли проиндексировать
наибольшее количество документов.
Так, например, однажды, к удивлению многих ветеранов поисковых работ, в безусловные лидеры вырвался никому ранее не известный Google (http://www.google.com), который и сегодня продолжает бить рекорды популярности. В последнее время в любом исследовании он непременно получает первые места в категориях «Самый информативный», «Самый релевантный», «Самый удобный в использовании» и т.д. При внимательном рассмотрении поисковой системы Google, созданной студентами Стэнфордского университета, оказывается, что одним из принципиальных ее отличий от других поисковиков является то, что она проиндексировала уже более 8 млрд. страниц — в несколько раз больше, чем ее ближайшие конкуренты. Поскольку не все проиндексированные страницы хранятся в базе (как и не все показываемые ссылки — проиндексированы), то критерием мощности индексация на самом деле не является, но суть, тем не менее, отражает — Google превзошел конкурентов по широте охвата.
Второй по популярности глобальной поисковой системой сегодня обладает, если объединить все ее дочерние подразделения, компания Yahoo! (http://www.yahoo.com). Как известно, в 2003 году Yahoo!, оператор одного из крупнейших Web-порталов, приобрела другую компанию — Overture Services, работающую в рекламном и поисковом бизнесе в Интернете (ранее между Yahoo! и Overture действовали только соглашения о партнерстве). В свою очередь, Overture является и разработчиком систем для поиска, и владельцем популярнейших в прежние годы поисковых сайтов AltaVista (http://www.altavista.com) и AlltheWeb/Fast Search (http://www.alltheweb.com). Поисковые технологии норвежской компании Fast Search & Transfer (FAST) считались наиболее близкими по своим возможностям к Google, и потому Overture приобрела их для ликвидации своего отставания в этой области. Позиции AllTheWeb были сильны и потому, что в этой поисковой системе проиндексировано очень много документов (3-4 млрд.), что, конечно, вдвое меньше, чем сейчас у Google, но все равно в несколько раз больше, чем у других конкурентов. Однако в дальнейшем менее популярная на рынке поисковых систем AllTheWeb, по заявлениям компании Overture, будет использоваться для первичной обкатки и отладки новых технологий, которые будут потом окончательно доводиться до ума на более раскрученной, хотя и менее мощной AltaVista. При этом Overture намерена, насколько это возможно, сохранять аудиторию данных сайтов, но основное внимание все же будет уделять лицензированию своей технологий поиска и оказанию услуг таким крупным порталам, как MSN, AOL и Yahoo!. Немного устаревшие, однако все равно интересные публикации о том, как устроены индексы самых больших в мире поисковых систем — Google и Fast, можно прочитать на сайте searchenginewatch.com в интервью с создателями этих поисковых систем (Google: http://searchenginewatch.com/searchday/article.php/2161091; AllTheWeb (Fast): http://searchenginewatch.com/searchday/article.php/2161101).
Что мы ищем в Интернете?В 2004 году поисковая система Google, пока остающаяся, несмотря на сильную конкуренцию, самой востребованной среди пользователей Сети, получила больше всего запросов о Бритни Спирс, Кристине Агилере и других знаменитостях женского пола, которые сумели оттеснить с первых строчек популярности не только известных мужчин, но и новости о войне в Ираке и даже MP3-файлы. В первую десятку, составленную из запросов со всего мира и опубликованную на сайте Google Zeitgeist, помимо актрис и певиц, попали игры, чаты, Орландо Блум (Orlando Bloom), сыгравший Леголаса во «Властелине колец», Гарри Поттер и MP3. Среди публичных фигур лидерство держит президент США Джордж Буш, за которым идут Джанет Джексон (ее брат Майкл на седьмом месте), Джон Керри, Бритни Спирс и Саддам Хусейн. Страной, за информацией о которой чаще всего обращались к помощи Google, оказалась Франция. Она же стала единственным европейским государством в первой десятке. Далее расположились Китай, Индия, Ирак, Иран, Южная Корея, Гаити, Куба и Пакистан. На Google Zeitgeist были расставлены по популярности различные товары и бренды, которые в 2004 году искали в Интернете: iPod стоит на первом месте в разделе электроники, Tablet PC — в разделе компьютерных товаров, а бикини, как выяснилось, — самая востребованная одежда. Французская компания Louis Vuitton лидирует со своим брендом. Отдельные списки были составлены и по странам (отметим, что Россия туда попала впервые). Предпочтения российских пользователей в минувшем году расположились по рейтингу следующим образом: обои для рабочего стола Windows, фильм «Ночной дозор», теннисистка Мария Шарапова, расписания поездов, сотовые телефоны, футбол, г.Беслан, «Фабрика звезд», пластиковые окна, открытки. |
||
Кстати, такие некогда популярные поисковые системы, как AltaVista или Northern Light, утратили привлекательность исключительно из-за снижения мощности своих баз (то есть из-за уменьшения сферы поиска), так как первая долгое время не уделяла достаточного внимания индексированию новых документов, а вторая сосредоточила свои усилия на возрождении услуг специализированного платного целевого поиска, сузив возможности автоматического индексирования. AltaVista, находясь во владении компании CMGI (а до того — у компании Compaq), неоднократно публиковала даже пресс-релизы, сообщающие об утере значительной части базы данных своих поисковиков в результате физического переноса серверов, и потому быстро потеряла доверие пользователей. А ведь когда-то AltaVista считалась лучшим из всех существовавших поисковиков. Кроме того, у AltaVista насчитываются 58 патентов, охватывающих самые разные аспекты поиска информации в Сети (в России технологии AltaVista продвигает компания РБК). Однако вместо того, чтобы развивать свои технологии поиска, эта компания, в попытках расширить сферу деятельности, отстала от конкурентов и растеряла все свои преимущества. Владельцы компании Northern Light тоже, так сказать, перемудрили — решив выжать из поиска в Сети все возможные материальные блага, занялись составлением собственной коллекции периодических изданий, статьи в которых заинтересованным лицам предоставлялись за определенную плату, а ведь понятно, что никакая коллекция не может сравниться по объему с результатом работы автоматических пауков и мощного индексатора системы Google. В результате Northern Light теперь серьезно уступает конкурентам и совершенно незаметна на рынке поисковых систем. Тяжелый финансовый кризис настиг Excite, а другие некогда популярные поисковые системы, такие как WebCrawler, Lycos и Infoseek, или вообще позакрывались, или превратились в фасады других поисковиков.
Таким образом, стало очевидным, что чем быстрее растет Сеть, тем труднее угнаться за ней многочисленным классификаторам, каталогам и поисковым машинам, которые не пошли по экстенсивному пути развития и недостаточно активно расширяют свои базы.
Однако огромный сегмент Сети просто не подпадает под определение индексируемого контента и остается за пределами внимания поисковиков. Именно эти сайты и составляют основу той «невидимой» Сети, разговор о которой пойдет ниже.
Еще в 2000 году, когда были проведены наиболее крупные исследования о наполнении Интернета, выяснилось, что поисковыми системами индексируется лишь незначительная часть документов, находящаяся как бы на поверхности Интернета. Американская компания BrightPlanet оценила, что недоступная часть Сети может быть приблизительно в 500 раз больше того, к чему поисковые серверы могут обеспечить доступ. В то время каждая из лидирующих поисковых систем, судя по числу проиндексированных документов, знала не более 1 млрд. Web-страниц. Если это составляет менее 10% от общедоступного контента, то большая часть документов (соответственно до 500 млрд.) оставалась недоступной поисковикам, а это значит, что где-то в глубине Сети (обозначается терминами Deep Web или Invisible Web), несмотря на декларации о доступности информации для любого посетителя, хранятся страницы, на поиск которых у пользователя ушла бы целая жизнь.
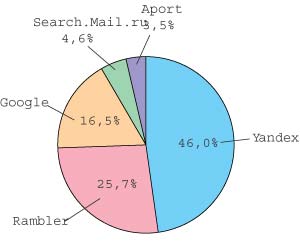
Популярность поисковых систем у российских пользователей
Между тем со временем ситуация только ухудшается, и даже если предположить, что четыре года назад исследователи ошиблись в своих оценках раз в десять, то на каждый найденный нами документ приходятся десятки скрытых (кстати, одним из самых популярных вопросов новичков форумов на http://searchenginewatch.com или на http://searchengines.ru является следующий: «Почему поисковик не индексирует мой сайт, несмотря на все мои усилия?»).
Ухудшение ситуации вполне закономерно по одной простой причине: база данных поисковых систем растет со временем как логарифмическая функция (приближаясь к своему физическому пределу), в то время как количество Web-страниц теоретически возрастает как степенная функция (и непременно опередит первую). Недавно, например, в Интернете появилась еще одна напасть — блоги (сайты личных дневников). Издатели американского словаря Merriam-Webster даже назвали слово blog — главным словом прошлого года. Так, по некоторым оценкам, количество блогов в Интернете уже сегодня приближается к 5 млн. и каждые 5-6 секунд создается новый блог.
Google (www.google.com)Поисковая система Google, запущенная в 1998 году, является ныне единоличным лидером среди глобальных поисковых систем по всем значимым параметрам. Но главное достоинство Google — это объем индексного файла, который составляет сегодня более 8 млрд. Web-страниц и статей из групп новостей по интересам. За сутки программы-роботы системы индексируют более 5 млн. новых и обновленных страниц, причем актуализация базы производится каждые 28 дней. Несомненным преимуществом поисковика Google является его способность индексировать документы не только в виде HTML-файлов, но и в форматах PDF, RTF, PS, DOC, XLS, PPT, WP5 и ряде других. При этом Google позволяет моментально конвертировать страницы в указанных форматах в обычный HTML-файл, так что пользователю не нужно специальное программное обеспечение для доступа к файлу. Google отличается высокой степенью комфорта для пользователя. Хотя Google — это глобальная поисковая система, пользователи из неанглоязычных стран автоматически переадресовываются на интерфейс на их родном языке. Длительность процесса поиска в большинстве случаев не превышает одной секунды, несмотря на огромный объем индексного файла системы. А у интерфейса первой страницы Google сегодня вообще нет достойных конкурентов в Сети.
Методика поиска с помощью Google предельно проста. В поисковую строку вводится запрос на естественном языке — на русском, английском или любом другом. К сожалению, язык запросов не допускает усечения терминов знаком «*», поэтому необходимо вводить все возможные словоформы самостоятельно. Набор логических операторов предельно лаконичен — «+», OR и «-», а также реализована возможность поиска по фразам в кавычках. Все термины запроса по умолчанию объединяются условием AND (логическое «И»), так что ставить перед ними знак «+» не обязательно — в список результатов попадают лишь страницы, содержащие все введенные ключевые слова. Поисковый механизм игнорирует стоп-слова (предлоги, союзы, артикли), однако если какое-либо из таких слов существенно, то перед ним необходимо поставить «+», давая системе понять, что в данном случае термин даже из одной буквы является значимым. Google имеет в своем арсенале множество опций для максимальной конкретизации запроса, доступных через меню Advanced Search «Расширенный поиск». Помимо уже описанных возможностей, добавляются фильтры, ограничивающие язык документа, его формат (к примеру, «только документы в PDF»), время опубликования («за 1 год»), место термина в самом документе («в заголовке страницы») или расположение страницы в определенном домене или даже на сайте. Кроме возможностей поиска текстовых материалов, Google обладает лучшими на данный момент возможностями поиска иллюстраций с помощью режима поиска изображений («Картинки»). Предусмотрена также возможность уточнения поиска среди уже найденных результатов («Поиск среди результатов»). В качестве собственного справочника Интернет-ресурсов Google использует усовершенствованный массив Open Directory Project, что порой позволяет сочетать достоинства обоих этих поисковых инструментов. Кстати, дополнительным платным сервисом Google является поиск трудно доступной информации не роботом, а человеком. Стоимость этого вида обслуживания — 2,50 долл. за ответ. |
||
Сухие цифры статистики также показывают опережающую динамику расширения Интернета, несмотря на то что производители поисковых систем утверждают обратное. В 1999 году наилучший результат по охвату Web-контента принадлежал поисковой системе Northern Light, проиндексировавшей 16% доступной информации, Snap и AltaVista шли на втором месте с показателем 15,5%; система HotBot замыкала список лидеров с долей в 11,3%. При этом утверждалось, что интегральный показатель всех проиндексированных документов составил к 2000 году около 30%. Но уже в 2000 году исследование NUA Internet Surveys (http://www.nua.ie/surveys) показало, что все поисковики вместе взятые проиндексировали и внесли в свои базы данных менее одной шестой части доступного информационного наполнения Сети, то есть около 17%. Годом позже в исследованиях компаний National Equipment и Inktomi прогнозировался рост Интернета до 1 млрд. страницу, что позволило компании Inktomi утверждать, что в ее распоряжении находится 50% проиндексированных Web-страниц. Хотя у Inktomi не было даже собственного поисковика, она предоставляла свои услуги таким популярным сайтам, как HotBot, ICQIt, MSN, Canada.com, Goto.com и Yahoo! (в последнем поиск по базе данных Inktomi осуществляется при отсутствии искомых элементов в собственной базе Yahoo!). На втором месте с долей в размере 34% оказалась разработка норвежских программистов Fast Search (AllTheWeb.com), которые заявили, что именно этому поисковику, созданному при поддержке Dell Computer, предстоит обогнать всех конкурентов, стать абсолютным лидером и удовлетворить запросы пользователей на 100%. Однако жизнь быстро внесла свои коррективы — победила система Google, официальный размер базы данных которой составлял тогда лишь около 20% от всего Интернет-наполнения. Уже к 2003 году и такие оценки стали казаться сильно завышенными, а результаты работы поисковиков до сих пор оставляют желать лучшего. При этом мощности поисковиков уже сейчас находятся на пределе — ведь до последнего времени вся информация, вплоть до копий исходных документов, хранилась в самой базе. Когда-то это было обусловлено ненадежностью каналов связи, Web-серверов и другого компьютерного оборудования и давало возможность пользователю ознакомиться с документом, фактически независимо от его доступности, в момент обращения к поисковой системе. Но поисковики просто не в состоянии наращивать свою память и вычислительную мощность пропорционально росту количества документов в Сети. Например, на Google сегодня работают уже сотни высокопроизводительных серверов и десятки тысяч компьютеров послабее, которые разбросаны по всему миру и находятся в различных data-центрах, что порождает уже чисто аппаратные проблемы. Кстати, судя по последним тенденциям полнотекстовые документы в своей базе Google уже не хранит.
К слову, в конце минувшего года, в первый же день после официального объявления о запуске новой поисковой системы Microsoft MSN (http://search.msn.com), она продемонстрировала крайне нестабильную работу и до сих пор никак не выйдет из бета-версии. Сайт MSN Search периодически отказывается обслуживать некоторых посетителей, выдавая сообщения о временной недоступности сервиса. Компания Microsoft по этому поводу заявила, что поисковая система до сих пор находится в стадии тестирования и в процессе ее отладки могут возникнуть перебои в работе. Составит ли она конкуренцию нынешнему лидеру на рынке Интернет-поиска — компании Google, покажет время, а вот то, что для этого потребуется немало сил и средств, — очевидно уже сейчас. Одним из достоинств MSN Search ее создатели называли именно большое число проиндексированных документов — более 5 млрд., в то время как у Google на момент запуска MSN Search этот показатель составлял 4,5 млрд., то есть Microsoft хотела превзойти Google по объему базы, но ее неудача наглядно продемонстрировала, что мощности поисковых систем нельзя наращивать до бесконечности.
Кроме того, с ростом числа документов в Интернете затрудняется работа пауков, которые самостоятельно сканируют Сеть в поисках новых документов. Если прежде, когда количество документов измерялось сотнями тысяч, такой способ позволял быстро наполнить базу и, следовательно, представить там максимальное количество документов, то теперь, когда документов сотни миллионов, подобный подход себя исчерпал. Мало того что просканированными оказываются не более 10-15% документов в Сети, но и все изменения и перемещения уже известных документов попадают в базу со значительным опозданием (до 3-4 недель), то есть найти актуальную информацию в Интернете, если туда не заглядывает специально «назначенный» паук, становится совершенно невозможно.
«Невидимый» Интернет
 русском сегменте Сети все не так плохо, однако здесь ситуация складывается по
принципу «не было бы счастья, да несчастье помогло»: темпы развития Рунета и
Интернета по-прежнему совершенно несопоставимы, зато темпы роста баз данных
отечественных поисковых систем значительно опережают показатели их американских
коллег. Так, разработчики проекта Yandex.Ru (которые идут в нашей стране по
стопам Google, постепенно вытесняя конкурентов) утверждают, что поисковая система
Яндекс на данный момент проиндексировала более 90% Рунета, но сюда, естественно,
не входят те сайты, индексация которых не предусмотрена правилами регистрации,
а также сайты, установившие запрет на индексацию собственных ресурсов.
русском сегменте Сети все не так плохо, однако здесь ситуация складывается по
принципу «не было бы счастья, да несчастье помогло»: темпы развития Рунета и
Интернета по-прежнему совершенно несопоставимы, зато темпы роста баз данных
отечественных поисковых систем значительно опережают показатели их американских
коллег. Так, разработчики проекта Yandex.Ru (которые идут в нашей стране по
стопам Google, постепенно вытесняя конкурентов) утверждают, что поисковая система
Яндекс на данный момент проиндексировала более 90% Рунета, но сюда, естественно,
не входят те сайты, индексация которых не предусмотрена правилами регистрации,
а также сайты, установившие запрет на индексацию собственных ресурсов.
К тому же индексации не подлежат многочисленные сайты, которые динамически предоставляют пользователям подготовленную в соответствии с их запросами информацию. Разработчиков таких сайтов трудно винить в нежелании подогнать свое детище под требования поисковых машин — базы данных в некоторых случаях являются единственной альтернативой для оформления содержимого Web-сайта.
Впрочем, сначала вся информация в Интернете была представлена в HTML, причем без таблиц, картинок и рисунков и т.п., которые появились в Сети позже. Естественно, что алгоритмы поиска были ориентированы прежде всего на текст, а сейчас объем мультимедийного наполнения (таблицы, базы данных, рисунки, музыка, видео) уже значительно превышает объем текстов, вследствие чего сегодня крайне сложно найти информационную сводку, картинку или нужный музыкальный фрагмент, не зная его дополнительных параметров, хотя средства для этого уже появляются. Возможны также варианты, когда доступ к той или иной странице требует ввода пароля, даже несмотря на отсутствие там конфиденциальной информации. А на многих страницах чаще всего присутствует стандартная информация, не представляющая интереса для поисковиков, а уникальное содержимое ресурса глубоко скрыто под локальными ссылками и переходами.
И конечно же, полагаясь на русское «авось», авторы большинства российских сайтов не регистрируются в поисковых механизмах и не заботятся хотя бы о небольшой раскрутке своих ресурсов. Создатели сайтов, видимо, предполагают, что рано или поздно желающие их все равно найдут. Однако чем дальше, тем такая перспектива представляется все менее реальной — если еще лет пять назад роботы-пауки добирались даже до потайных уголков Сети, то сегодня ожидать их внезапного визита на свою страницу уже не приходится. И даже опытные Web-мастера сейчас с нетерпением ждут каждого ежемесячного обновления баз данных поисковых систем, надеясь только на высшие силы, которые привлекут внимание роботов-пауков к их сайтам. Рядовым же пользователям такие ресурсы, затерянные на просторах «невидимой» Сети, можно найти, лишь руководствуясь известной истиной «места знать надо». Вот только таких мест становится все больше и больше, а доступ к ним — все труднее. Между тем «невидимый» Интернет так же доступен для рядового пользователя, как и «видимый», но стандартные способы поиска туда уже не приведут.
Реклама против «ботаников»
 сли
количество информации в Интернете растет очень быстро, то этого отнюдь нельзя
сказать о ее качестве. А поскольку владельцам поисковиков тоже приходится искать
средства к существованию, то услуги по платному размещению рекламы в результатах
поиска — один из основных источников доходов и для Google, и для других поисковых
систем. Однако обычная баннерная реклама, которую видят все посетители Интернет-сайтов,
приносит в последнее время все меньше доходов (практика показывает, что пользователи
ее вообще игнорируют), поэтому многие поисковые системы перешли на так называемую
контекстную рекламу, которая демонстрируется пользователям в зависимости от
содержания их запроса. Например, если пользователь ищет в Интернете «кондиционер
для дома», то он увидит и рекламу фирмы, торгующей кондиционерами в розницу.
Некоторые поисковики уже беззастенчиво продают желающим лучшее пространство,
так что первые выведенные результаты поиска могут принадлежать сайтам-спонсорам,
а вовсе не тем, которые система определила как наиболее подходящие. Кстати,
лидеры — и Google, и Яндекс — тоже продают спонсорские ссылки, которые сортируются
и показываются в зависимости от темы поиска пользователя. Однако эти ссылки
явно обозначаются как реклама и демонстрируются отдельно от результатов поиска.
Другие системы формально позволяют пользователю исключить спонсорские ссылки
из результатов поиска, но обычно эта опция делается не слишком заметной. Кроме
того, в качестве дополнительной услуги такие компании, как Overture, предлагают
платное включение сайтов заказчика в базу данных своих поисковиков. Информация
о таких сайтах в базе данных будет обновляться чаще, чем информация об обычных
неоплаченных ресурсах, и, следовательно, продвигаться выше по списку найденных
документов и иметь большую актуальность. При этом рекламный и алгоритмический
поиск, по утверждениям компании, будут дополнять друг друга, хотя вряд ли в
таком случае сделка с Overture принесет AllTheWeb/Fast Search и AltaVista пользу
— куда вероятнее другой исход: продавшись рекламщикам, указанные поисковики
окончательно лишатся доверия пользователей.
сли
количество информации в Интернете растет очень быстро, то этого отнюдь нельзя
сказать о ее качестве. А поскольку владельцам поисковиков тоже приходится искать
средства к существованию, то услуги по платному размещению рекламы в результатах
поиска — один из основных источников доходов и для Google, и для других поисковых
систем. Однако обычная баннерная реклама, которую видят все посетители Интернет-сайтов,
приносит в последнее время все меньше доходов (практика показывает, что пользователи
ее вообще игнорируют), поэтому многие поисковые системы перешли на так называемую
контекстную рекламу, которая демонстрируется пользователям в зависимости от
содержания их запроса. Например, если пользователь ищет в Интернете «кондиционер
для дома», то он увидит и рекламу фирмы, торгующей кондиционерами в розницу.
Некоторые поисковики уже беззастенчиво продают желающим лучшее пространство,
так что первые выведенные результаты поиска могут принадлежать сайтам-спонсорам,
а вовсе не тем, которые система определила как наиболее подходящие. Кстати,
лидеры — и Google, и Яндекс — тоже продают спонсорские ссылки, которые сортируются
и показываются в зависимости от темы поиска пользователя. Однако эти ссылки
явно обозначаются как реклама и демонстрируются отдельно от результатов поиска.
Другие системы формально позволяют пользователю исключить спонсорские ссылки
из результатов поиска, но обычно эта опция делается не слишком заметной. Кроме
того, в качестве дополнительной услуги такие компании, как Overture, предлагают
платное включение сайтов заказчика в базу данных своих поисковиков. Информация
о таких сайтах в базе данных будет обновляться чаще, чем информация об обычных
неоплаченных ресурсах, и, следовательно, продвигаться выше по списку найденных
документов и иметь большую актуальность. При этом рекламный и алгоритмический
поиск, по утверждениям компании, будут дополнять друг друга, хотя вряд ли в
таком случае сделка с Overture принесет AllTheWeb/Fast Search и AltaVista пользу
— куда вероятнее другой исход: продавшись рекламщикам, указанные поисковики
окончательно лишатся доверия пользователей.
AllTheWeb/Fast Search (www.alltheweb.com)Поисковая система, существовавшая под данным именем с 1997 года, была разработана в Норвегии и первоначально ориентировалась преимущественно на европейские сайты. В 2003 году поисковик Fast Search стал собственностью Yahoo!, но продолжал существовать и в качестве оригинального поискового сервиса, регулярно наращивая собственный индексный файл и повышая степень релевантности поиска. На протяжении последних лет Fast Search справедливо рассматривался в качестве главного конкурента Google, но с 25 марта прошлого года под брендом Fast Search была размещена и запущена в действие поисковая система Yahoo!, разработанная на основе поискового механизма Inktomi, ранняя версия которого использовалась, в частности, в поисковой системе HotBot. В настоящее время Fast Search фактически представляет собой «зеркало» (запасной сервер) поисковой системы Yahoo!, с той лишь разницей, что в его модуле выдачи результатов гораздо лучше решены проблемы вывода документов на разных языках, использующих кодировки, отличные от расширенной латиницы. В числе 36 языков, с которыми вполне корректно работает система, есть и русский.
Индексный файл Fast Search, по уверениям владельцев, в настоящее время содержит около 3 млрд. документов. Помимо текстовых документов, нынешний вариант системы поддерживает поиск в группах новостей по интересам, поиск иллюстраций, видеофрагментов и аудиофайлов, в том числе и с русскоязычных серверов. Система способна собирать сведения и индексировать размещенные в Интернете файлы в форматах PDF, DOC, XLS, PPT. Fast Search оперирует традиционным языком запросов, включающим знаки «+», «-» и кавычки для поиска цитат. Для формирования сложных запросов рекомендуется обращаться к расширенному поиску (Advanced Search). Система многоступенчатых меню позволяет применять фильтры, в числе которых — ограничения по местоположению термина в документе, по определенному домену, по географическому местоположению, по времени опубликования документа и по формату файла. В числе сервисных функций Fast Search — возможности установки персональных режимов для поиска и их сохранения в системе (на конкретном компьютере) для работы в дальнейшем. |
||
Еще одной причиной появления «невидимой» части Сети является такая особенность поисковиков, как приоритет актуальности или проверки обновления информации. Для того чтобы ссылки, предоставленные поисковым механизмом, были более актуальными и свежими, время от времени пауки проводят реиндексацию сайтов, сравнивая вновь загруженные страницы с теми, которые уже содержатся в базе данных. Если различий не обнаружено, робот решает, что ничего с тех пор не изменилось и что, собственно говоря, индексировать здесь нечего; причем если главная страница не претерпела никаких изменений, то некоторые поисковики обычно полагают, что и все остальное тоже сохранилось в первозданном виде. Более всего при таком подходе страдают сайты учебных заведений, так как там главная страница, как правило, остается неизменной в течение многих лет, в то время как на персональных страницах профессоров и студентов появляются диссертации, научные работы или какие-нибудь коллекции тематических ссылок «о вечном».
Еще более серьезную проблему при поиске необходимой информации в Интернете представляют так называемые профессиональные оптимизаторы. Ведь что означает понятие «поисковая оптимизация» для Web-мастеров и владельцев Интернет-сайтов? По существу, это обман поисковых технологий с целью вывести свой сайт в первые страницы результатов поиска, используя знания об алгоритмах работы поисковых систем для раскрутки сайтов, а в конечном счете — для получения прибыли от рекламы либо от продаваемых через такой сайт товаров или услуг. Оптимизация сайта под поисковые системы — это один из самых малозатратных, но весьма эффективных способов продвижения ресурса в Сети, поэтому каждый коммерческий ресурс непременно этим пользуется. В результате в Сети появилось немыслимое количество так называемых дорвеев, ПО и методов, предназначенных для того, чтобы «заспамить» ту или иную поисковую систему или поймать ее паука в нужное время. Так, если раньше процесс оптимизации ресурсов ограничивался лишь адаптацией под поисковые системы страниц с контентом, то теперь он с них только начинается. Дорвей (Doorway Page) — вспомогательная Web-страница, которая специально оптимизируется под конкретные поисковые запросы, но сама никакой полезной информации не несет (содержит, например, повторяющиеся ключевые слова и HTML-тэги, наиболее полно удовлетворяющие поисковым алгоритмам), а предназначается исключительно для того, чтобы обманным путем привлечь посетителя на Web-страницу, для которой создавался дорвей. Поисковые алгоритмы, в свою очередь, постоянно совершенствуют средства для борьбы с таким спамом и при обнаружении дорвея жестко наказывают породивший его ресурс, удаляя все ссылки из базы, но и спамеры искусно маскируются, так что эта война будет продолжаться бесконечно.
Иногда оптимизаторам удавалось даже обходить индексаторы поисковых систем, вследствие чего коммерческие Web-страницы безоговорочно включались в базу с высоким рангом, так как поисковик считал такую страницу поступившей из надежного источника и использовал представленную ею же самой информацию для ее описания и ранжирования. А поскольку большинство пользователей не заходят дальше второй-третьей страницы результатов, проталкивание сайта на первые позиции или в первую десятку по близким ключевым запросам — вожделенная цель любого коммерческого ресурса, к которой он стремится любой ценой.
AltaVista (www.altavista.com)AltaVista — одна из старейших поисковых систем, которая была введена в эксплуатацию в 1995 году и в течение нескольких лет являлась признанным лидером сетевого поиска по объему индексного файла, по эффективности ранжирования результатов и по сервисным функциям. Именно здесь впервые был опробован ставший ныне традиционным язык запросов: знаки «+» и «-», усечение с помощью знака «*» и кавычки для поиска по точной фразе. В форме углубленного запроса были впервые эффективно использованы булевые операторы и оператор расстояния — NEAR.
В 2002 году AltaVista подверглась значительной модернизации: был кардинально обновлен программный модуль, что позволило расширить объем базы данных до более чем 1 млрд. страниц. В это же время в AltaVista был добавлен интеллектуальный модуль Prisma, помогающий пользователям точнее сформулировать запрос. Однако приобретение данной поисковой системы корпорацией Yahoo! положило конец существованию оригинального поискового механизма AltaVista и ее индексного файла. В настоящее время, как и в случае с Fast Search, при вводе запроса происходит транслирование результатов поиска из базы поискового модуля Yahoo!. Сегодня Fast Search и AltaVista — это полные аналоги поисковой системы Yahoo! (ее фактические дублеры). |
||
Поэтому говорить сегодня о каких-то объективных принципах поиска становится все труднее, ибо в качестве профессиональных оптимизаторов выступают не только отдельные лица, но и целые организации, которые оказывают широкий спектр услуг — от простой оптимизации на этапе изготовления сайта до полного сопровождения, консалтинга и аудита. Теперь это превратилось в профессиональную деятельность; у оптимизаторов наработан немалый опыт; для этого создается специализированное программное обеспечение, обучаются кадры и т.п.
Конечно, поисковые системы непрерывно корректируют свои алгоритмы, стараясь держать их в секрете, однако это усложняет попадание в верхние строчки результатов поиска как раз для мелких частных сайтов и рядовых Web-дизайнеров, но никак не для крупных фирм и рекламных компаний, которые привлекают профессиональных оптимизаторов, способных без промедления разобраться с любым изменением правил.
В результате мы имеем следующую картину:
- старые домены и сайты постепенно вытесняются из поисковых баз, так как они редко обновляются и не придерживаются новых правил (а базы, как мы уже говорили, — не резиновые). Кстати, первый в мире домен (Интернет-сайт, зарегистрированный аж 15 марта 1984 года), который находится по адресу http://www.symbolics.com, вы никогда не найдете, поскольку его содержимое представлено только графикой (отсканированной документацией) и, следовательно, ни одна поисковая система его не проиндексирует;
- слишком новые и прогрессивные Web-сайты, которые динамически выдают свое содержимое в зависимости от требований пользователя, индексируются поисковиками с большим трудом, так как подобные ресурсы рассчитаны на тематические запросы живых людей, а не на пауков-роботов. Разумеется, поисковики в этом случае могут поработать и с базами данных таких систем или разработчики сайтов могут что-нибудь специально оптимизировать для поиска, но в общем случае поисковые алгоритмы консервативнее, чем современные им Web-технологии (например, файлы форматов Adobe Acrobat PDF или MS Word DOC только недавно начали полноценно индексироваться);
- в результате всего этого, по мере роста и расширения Интернета, в базах данных поисковых систем останутся лишь коммерческие сайты, специально подготовленные оптимизаторами.
Вы, конечно, можете оспорить последнее утверждение, но приведем в качестве аргумента всего два факта. Компания Inktomi уже неоднократно объявляла о том, что ее поисковая система индексирует несколько миллиардов различных Web-страниц, но это не значит, что при поиске пользователям будет доступна вся проиндексированная база. Почему? Да потому, что из индекса, по которому производятся поиск и выдача ответа пользователю, Inktomi вынуждена была исключать большую часть страниц, обращение к которым происходит редко (или вообще не происходит), а значит, их можно считать заведомо нерелевантными. При этом компания уверяет, что, ограничив рабочий индекс, она значительно ускоряет поиск и помогает пользователям экономить время. Кроме того, если поисковая база невелика, ее проще обновлять и индексировать. Главное же — не количество проиндексированных страниц, утверждает Inktomi, а качество содержащейся в них информации, которое будет удовлетворять 99% пользователей! Чтобы определить, включать ли страницу в результаты поиска в дальнейшем, система анализирует ее содержание, ссылки на нее и реакции пользователей, получивших эту страницу при предыдущем поиске. Очевидно, что крупнейшие поисковые серверы, пользующиеся индексом Inktomi, то есть Yahoo!, AOL, ExciteAtHome, Hotbot и Microsoft Network, против такой практики не возражают.
Впрочем, и пользователям, ищущим информацию на популярные темы, никаких неудобств это не доставит, ибо они быстро и легко найдут домашнюю страничку или Web-сайт поклонников Бритни Спирс, Кристины Агилеры и прочих знаменитостей. Однако тем, кто разыскивает информацию по специализированной тематике, не интересующей основную массу посетителей Интернета, при таком подходе о поиске придется забыть. Такая вот завуалированная форма цензуры в Интернете…
И наконец, самый парадоксальный факт, который недавно обнародовали американские ученые из университетов Питтсбурга и штата Пенсильвания (США) в своей работе «Web Search: Public Searching of the Web», — оказывается, популярность электронной коммерции в Интернете сегодня опережает даже порнографию! Так, согласно проведенному исследованию, если в 1997 году более 20% поисковых запросов в Сети было связано с сексом, то в настоящее время процент таких запросов от европейских пользователей снизился более чем вдвое, а от американских — в четыре раза! Люди стали активнее интересоваться Интернет-коммерцией и бизнесом, больше стало запросов, связанных с покупками через Сеть, а реклама в Интернете переживает бурный расцвет. Прошли те времена, когда предприятия и фирмы просто считали хорошим тоном иметь свое представительство в Интернете — сегодня бизнес принял возможности Сети как серьезного инструмента по получению дополнительной прибыли, не требующей больших вложений. Даже доходы России от Интернета в 2004 году, по словам министра информационных технологий и связи Леонида Реймана, составили 255 млрд. руб. А там, где побеждает коммерческий подход, говорить о каких-то специфических потребностях группы узких специалистов или просто энтузиастов-дилетантов вряд ли уместно.
Кстати, когда на сайте SearchEngineWatch.com появился новый обзор недавно зарегистрированных патентов, а также заявок на патенты, которые связаны с поисковыми технологиями, то особое внимание привлек патент Overture, который описывает способ управления результатами поиска со стороны рекламодателя.
Потомки Эллочки-Людоедки
Словарь Вильяма Шекспира, по подсчету исследователей, составляет 12 000 слов.
Словарь негра из людоедского племени Мумбо-Юмбо составляет 300 слов.
Эллочка Щукина легко и свободно обходилась тридцатью. <...>
Оставшиеся в крайне незначительном количестве слова служили передаточным звеном между Эллочкой и приказчиками универсальных магазинов.
И.Ильф, Е.Петров. 12 стульев
 режде
чем возмущаться недостатками поисковиков, которые не могут обеспечить качественный
поиск информации, и ругать слабую аппаратную базу их серверов, которые затыкаются
от наплыва сетевого мусора, давайте спросим себя, правильно ли мы ищем?
режде
чем возмущаться недостатками поисковиков, которые не могут обеспечить качественный
поиск информации, и ругать слабую аппаратную базу их серверов, которые затыкаются
от наплыва сетевого мусора, давайте спросим себя, правильно ли мы ищем?
Казалось бы, с развитием технологических возможностей современные поисковые системы должны обеспечить гарантированное нахождение информации (по крайней мере в «видимой» ими части Интернета), однако пользователи по-прежнему недовольны качеством их работы, хотя основная их масса не желает прикладывать никаких интеллектуальных усилий для формирования критериев поиска. Около 80% запросов состоят из одного или двух слов, на которые поисковик выдает тысячи результатов, а пользователи просматривают лишь первую страницу и, не найдя там ничего интересного, вообще покидают поисковую систему.
А ведь необходимо обучаться обращению с поисковыми машинами. Удивительно низким является процент использования запросов с применением логических или контекстных операторов. А если операторы и используются, то это в основном булевы AND и OR. Доля использования операторов контекстной близости и логического отрицания (NOT) не превышает 1-2%. В то же время именно реализация отработки сложных запросов (которых пока не более 10%) всегда определяла эффективность поиска. Глядя на такую пассивность пользователей, поисковики переходят к другим методам формирования запросов. Так, у популярного сегодня Google имеется самый лаконичный набор логических операторов — «+», OR и «-» (и реализована возможность поиска по фразам в кавычках), а своих успехов он добивается отнюдь не усложнением запросов. Кроме того, всего 200 различных слов присутствуют в 80% всех запросов, а если словарный запас расширить до 500 слов, то он охватит более 90% всех запросов. Короче говоря, Интернет-язык представляет собой нечто среднее между языками Эллочки-Людоедки и дикаря Мумбо-Юмбо. Тогда, наверное, и в школу можно вообще не ходить, а выучить 500 слов, купить компьютер и выйти в Интернет…
Яндекс (www.yandex.ru или www.ya.ru)Запущенный в сентябре 1997 года, этот поисковик в настоящее время является бесспорным лидером российского поискового сервиса, демонстрирует высокие показатели как по объему проиндексированных документов, так и по релевантности поиска. Яндекс проиндексировал около 1,5 млн. российских и зарубежных русскоязычных серверов, а также серверов на территории СНГ (всего учтено около 200 млн. оригинальных документов). Актуализация базы осуществляется еженедельно. Кроме того, Яндекс — пока единственная российская поисковая система, индексирующая документы в форматах PDF, RTF и DOC. Интерфейс поисковика максимально прост — он состоит из единственной строки ввода. За счет встроенной системы морфологической обработки терминов Яндекс приспособлен для формирования запросов на естественном русском языке. Мощнейшие лингвистические методы позволяют учесть самые разные оттенки употребления ключевых слов и охватить всевозможные сочетания терминов. В процессе обработки запроса поисковый механизм самостоятельно производит расширения, исключает стоп-слова, анализирует расстояние терминов друг от друга и пр. Типичный запрос в этом случае задается путем ввода в поисковую строку отдельных терминов или целой фразы. Яндекс показывает найденные термины в окружающем словарном контексте, что позволяет сразу же установить степень соответствия найденного документа информационной потребности пользователя.
Для формирования более точного запроса целесообразно обратиться к «Расширенному поиску» (пункт в нижней части титульной страницы). С помощью структурированного меню можно задать ограничения по различным сочетаниям ключевых слов, по местоположению термина в документе, по времени и языку публикации, по месту на сайте. Максимально детализированный запрос можно создать и в простой форме — с использованием языка запросов Яндекс, который включает множество специальных символов, употребление которых подробно описано в файле «Синтаксис языка запросов» (http://www.yandex.ru/info/syntax.html). Снабженные этими символами ключевые слова вводятся в ту же поисковую строку, что и в первом случае. Среди сервисных функций Яндекса — поиск в новостях, в собственном каталоге Интернет-ресурсов и в перечне товаров из Интернет-магазинов, включая книжные. |
||
Понятно, что невозможно построить разумную выборку из миллиарда документов по таким скудным запросам. Естественным выходом здесь могло бы быть сохранение контекста запросов пользователя, его истории и предпочтений, то есть создание некой индивидуальной «теневой» базы. Но на стороне поискового сервера подобное сделать сегодня практически невозможно — он и так перегружен, поэтому приходится применять какие-то странные критерии, которые на практике имеют очень отдаленное отношение к реальной жизни. В последнее время в технологии поиска все чаще стали внедряться элементы качественного и количественного контент-анализа, которые когда-то применялись в психологии и социологии. Если качественный контент-анализ базируется на глубоком лингвистическом и семантическом анализе отдельных предложений и всего текста, то основой количественного анализа являются статистические подходы. Например, такие отечественные поисковые системы, как Яндекс, активно пользуются морфологической обработкой терминов и поиском по словоформам. Подобная система, с одной стороны, лучше приспособлена для формирования запросов на естественном русском языке, а с другой — поиск по словоформам может далеко увести нас от заданной тематики, ибо один и тот же корень встречается в далеких по смыслу словах.
Человек достаточно легко справляется с различением указанных слов за счет понимания контекста, в котором они находятся, но для компьютерных систем различить близкие наборы символов — почти неразрешимая задача. Следовательно, для надежного определения отбора результатов поиска нужно не только проводить морфологический анализ, но вдобавок и понимать, о чем идет речь. И если человек однозначно воспринимает контекст, то существующие сегодня алгоритмы этот контекст просто не учитывают.
Во многие современные сетевые поисковые системы внедрены такие компоненты, как:
- автоматическая группировка документов по заранее определенному классификатору;
- попытка определения новых классов на основе неструктурированных или слабо структурированных документов;
- ранжирование документов по смысловой принадлежности;
- выявление семантически подобных документов (поиск по эталону или смысловой близости);
- автоматический анализ и смысловое преобразование запросов пользователей.
В результате, несмотря на то, что синтаксис запросов к популярным поисковым системам со временем значительно упростился, количество откликов постоянно увеличивается. Сегодня можно констатировать, что с привлечением в Интернет все большего количества пользователей традиционные подходы к поиску, основанные на использовании логических операторов, теряют свое значение, а на первый план выходят новые семантические алгоритмы. Нужно признать, что пионером в этом деле стала как раз компания Google, поставившая на ранжирование выдачи и алгоритмы отбора документов, основанные на цитируемости их в Сети. Системы, базирующиеся исключительно на базах данных, как мы сказали выше, уже не выдерживают потока Интернет-информации, поэтому ставка сегодня делается на семантические алгоритмы. При этом речь идет не только об объемах, но и о политематичности и динамике, то есть о возможности постоянного обновления информации, которая к тому же не имеет очевидной тематической направленности и регулярности. Но вся беда в том, что при таком подходе поисковикам очень легко навязать пользователю свое собственное понимание его запросов, а рекламщики, не теряясь, будут ловить рыбку в мутной воде. Понятно, что формальные оценки соответствия полученного требуемому ввести очень сложно.
Rambler (www.rambler.ru)Этот поисковик был запущен в октябре 1996 года и сначала предназначался для выявления материалов на серверах в пределах бывшего СССР. К началу нового тысячелетия Rambler на время утратил лидирующие позиции, устарев практически по всем параметрам. Однако проведенная в декабре 2002 года коренная модернизация всей программно-аппаратной части позволила этой поисковой системе вновь обрести былой авторитет. По результатам тестов Rambler занимает второе место после Яндекса по величине базы данных — около 120 млн. страниц. Производительность поискового робота декларируется в объеме 6,9 млн. страниц в сутки. В Рамблере также усовершенствован поиск по новостям: робот посылается на ведущие новостные сайты России каждые два часа.
Система обладает обычной и расширенной формами ввода запроса («Расширенный поиск»). По умолчанию результаты поиска группируются по сайтам, что весьма логично, поскольку на одном сайте термин используется, как правило, в едином контексте. Всегда четко указываются дата создания документа и дата его последнего индексирования поисковым роботом. Каждая найденная ссылка снабжена функциями «Восстановить текст», «Все документы с сайта» и «Найти похожие», причем последняя работает лучше, чем у многих конкурентов, и помогает, в частности, выявлять аспекты применения искомого термина в контексте, который было крайне трудно предположить при начальном поиске. Кроме наличия и местоположения ключевых слов, механизм выдачи результатов Rambler учитывает также популярность ресурса, которая определяется его посещаемостью (если на странице установлен счетчик Rambler Top100) и количеством внешних ссылок на данную страницу. Достоинствами модуля выдачи результатов Rambler являются отсев нерелевантных документов и защита от сайтов-двойников. |
||
Посмотрите, например, что произошло с расхожим термином «релевантность» (от англ. relevancy), который вводился в свое время специально для того, чтобы оценить степень соответствия документа запросу. Собственно, вначале появились два ясных и очевидных термина, характеризующих поиск в сетях (причем задолго до появления Интернета) — полнота (ничего не потеряно) и точность (не найдено ничего лишнего). Алгоритмизация поиска потребовала формализации этих терминов. О полноте охвата ресурсов Сети, как об одном из основных аспектов характеристики полноты сетевой информационно-поисковой системы, мы уже говорили. Второй аспект этого вопроса связан с полнотой информации, предъявляемой пользователю по его запросу. Если предположить, что по запросу пользователя Q в базе данных найдено Р документов, соответствующих этому запросу, а предъявлено для просмотра всего N документов, то полнота системы П определяется по формуле: П = (N:P)Ѕ100%. В том случае, если П оказывается больше 100%, то пользователю выдано минимум (N–P) документов, не соответствующих его запросу (то есть нерелевантных).
Соответственно под релевантностью понимается формальное соответствие информации, выдаваемой системой, сделанному запросу. Если по запросу пользователя получено N документов, из которых N1 соответствует запросу, а N2 не соответствует (N = N1+N2), то релевантность Р определяется по формуле: Р = (N1:N)Ѕ100%, а «информационный шум» — по формуле: «Ш» = (N2:N)Ѕ100% = 100%–Р.
Однако когда между поисковыми машинами началась жесткая конкуренция и компании-производители бросились оптимизировать поисковые алгоритмы таким образом, чтобы выдавать наиболее релевантные ответы, то были придуманы различные алгоритмы и методы определения релевантности, которые впоследствии, как показала практика, далеко увели этот термин от его первоначального значения, то есть соответствия между желаемой и получаемой информацией.
В простейшем случае релевантность текста определяли процентом вхождения ключевых слов запроса к общему объему текста; при этом считалось, что высокорелевантным текстом следует признать такой, где вхождение запроса в текст равно примерно 4-7% (меньшего может не хватить, а большее чревато тем, что система сочтет текст за поисковый спам и наложит на эту страницу фильтр). И если в каталогах релевантность сайта оценивали сами люди (модераторы), которые распределяли ресурсы по тематическим разделам, а также пресекали использование запрещенных методов оптимизации, то поисковая машина при запросе пользователя могла рассчитать релевантность настолько абсурдно, что пользователь не находил ничего полезного в выданном ему результате, ведь по своему существу формальный запрос к системе является предметом алгоритмической обработки информационной потребности и не всегда точно отражает последнюю.
В конце концов эта степень близости между реально полученными документами и тем, что следовало бы получить из системы, настолько формализовалась, что для оценки адекватности поиска потребовалось введение нового, неформального понятия — пертинентности, которое теперь и используется на практике. Хотя пертинентность (от англ. pertinent — подходящий, имеющий отношение) в принципе является синонимом изначального значения слова «релевантность» и указывает на соответствие содержания документов информационной потребности пользователя, но теперь этот термин теперь стараются не формализовывать, а, напротив, в каком-то смысле противопоставляют синтетическому критерию релевантности (соответствие конкретным запросам). Поскольку информационная потребность, как правило, не может быть точно выражена словами и определяется только после оценки просматриваемых документов (подходят они или не подходят), то релевантный документ может оказаться непертинентным, и наоборот.
Апорт (aport.ru)В настоящее время Апорт является единственным профессионально поддерживаемым отечественным справочником Интернет-ресурсов. Данный каталог как составная часть входит в одноименный портал, включающий также поисковую систему. Справочник имеет многоуровневую иерархическую структуру, характеризующуюся достаточной логичностью и продуманностью. Каждая ссылка справочника снабжена аннотацией, дающей предварительное представление о содержимом сервера. Сообщается его географическое местонахождение, указываются индекс цитирования, рассчитываемый на основании числа ссылок на данную страницу с других сайтов, и параметр «лига», преимущественно определяющий качество дизайна. Апорт наиболее эффективен при поиске серверов российских учреждений, а также для выявления перечней сайтов однородных объектов, имеющих разные названия (например, сайтов известных футболистов, сборников кулинарных рецептов, расписания авиарейсов, списков кадровых агентств, коллекций географических карт и т.п.).
Эта поисковая система, запущенная в феврале 1996 года, сегодня замыкает группу лидеров отечественных поисковых сервисов. Объем ее индексного файла составляет примерно 70 млн. документов. Особенностью Апорта является то, что он не ограничивает своих роботов пределами доменов России и СНГ — в перечне результатов можно встретить ссылки на многие зарубежные серверы. Кроме того, Апорт снабжен массой различных возможностей, позволяющих считать его одним из самых удобных для пользователей. Именно здесь был применен сложный язык запросов (http://aport.ru/help.htm) для максимальной детализации поискового предписания и для избавления пользователя от информационного шума, возникающего при случайном сочетании ключевых слов. Апорт на достаточно высоком уровне осуществляет поиск MP3-файлов и в настоящее время является фактически единственной системой, при помощи которой можно искать в российском Интернете аудиофайлы. Список результатов содержит сведения об адресе, дате опубликования и последней проверке документа. Документы с одного сайта сгруппированы вместе. |
||
Использование любых синтетических критериев открывает широкие возможности для манипулирования результатами поисков, хотя с этим борются все поисковые системы. Такая ситуация ведет к снижению качества поиска, ибо потенциально более пертинентные документы неминуемо оттесняются своими «оптимизированными» конкурентами в конец списка. Наверное, многие сталкивались с тем, что действительно полезные ресурсы сегодня находятся на второй-третьей странице выдачи поискового запроса. В простейшем случае пертинетность означает для пользователя соотношение объема полезной для него информации к общему объему полученной информации и имеет решающее значение. Практика показывает, что когда количество непертинентных документов лежит в интервале от 10 до 30%, то ищущий чувствует себя комфортно, не теряясь в море информационного мусора, и считает, что количество найденных документов его вполне удовлетворяет. Сегодня именно достижение высокой пертинентности является основной ареной конкурентной борьбы современных поисковых систем. Для максимального удовлетворения потребностей пользователей информационно-поисковые системы максимально интеллектуализируются — в частности получили широкое практическое применение теории и методы семантических сетей и анализа текстов.
Если раньше у многих пользователей формировалось мнение об Интернете как об огромной информационной свалке только из-за их собственного неумения правильно формулировать запросы и получать приемлемые объемы отклика, то сегодня всем нам грозит опасность действительно очутиться на такой информационной свалке, маскируемой под райский сад. Оно и понятно: большинство пользователей в состоянии оценить пертинентность того или иного документа только в сравнении с другими, а если весь доступный контент будет схож по содержанию, то пользователи будут считать его пертинентным и никогда не узнают, какие еще россыпи знаний скрывает от них Интернет под грудой предоставленного им однородного информационного мусора.
Таким образом, даже новейшие интеллектуальные методы поиска не могут бороться с вытеснением реально полезных ресурсов под груды мусора, а вследствие опережающего роста общего количества сайтов в Интернете по сравнению с объемом документов, доступных поисковым системам, такая ситуация будет только усугубляться.
PageRank и связность1 Сети
оисковые
машины способны выдавать списки документов с миллионами ссылок. Даже просто
просмотреть такие списки невозможно, да и не нужно. Удобно было бы иметь возможность
задать формальные критерии хотя бы относительной важности (с точки зрения пертинентности)
документов, с тем чтобы наиболее важные ресурсы попадали в начало списка выдаваемых
результатов. А так как с индексированием Интернета сегодня возникают определенные
проблемы, то все поисковики уделяют основное внимание именно алгоритму ранжирования
полученных ссылок.
Наиболее часто используемыми критериями при ранжировании являются:
- наличие слов из запроса в документе, их количество, близость к началу документа, близость друг к другу;
- наличие слов из запроса в заголовках и подзаголовках документов (заголовки должны быть специально отформатированы);
- количество ссылок на данный документ с других документов;
- «респектабельность» ссылающихся документов.
В последнее время поисковики все больше внимания уделяют таким внешним факторам, как наличие ссылок на рассматриваемые страницы с других ресурсов по данной тематике. Таким образом, для улучшения качества поиска часть работы по определению качества документов косвенно возложили на самих Web-дизайнеров. Размещая ссылку на внешний ресурс, создатель как бы рекомендует его посетителям своего сайта — именно эту особенность Интернета решили использовать для повышения качества поиска. Получается, что Интернет как бы каталогизирует сам себя, а повышенная значимость документа определяется с учетом ссылок извне на сайт, который содержит этот документ.
Ссылочные критерии ранжирования помогли несколько исправить и положение дел с рекламной оптимизацией. Такой критерий довольно трудно подделать, ибо на размещение ссылки на других сайтах требуется добрая воля их владельцев, которые, в свою очередь, заботятся о качестве своих ресурсов и не будут продвигать недостойные сайты, способные повредить их собственной репутации. Словом, ставка была сделана на саморегуляцию Интернета.
1 Связность, связный — термины теории графов.
Как же учесть цитируемость ресурса? Ссылки ведь тоже бывают разные. Количество внешних ссылок на сайт не годится для получения представления о цитируемости, поскольку с появлением бесплатных хостингов количество ссылок очень легко увеличить или попросту договориться с какими-нибудь ресурсами о взаимном цитировании. Но важность таких ссылок ничтожна по сравнению со ссылками с известных и авторитетных ресурсов. PageRank и есть такой параметр важности, так как он выражает не только цитируемость страницы, но и значимость этой цитируемости. Само название PageRank определяет алгоритм расчета цитируемости, разработанный и используемый разработчиками поисковой системы Google (Sergey Brin & Larry Page). Русский аналог — это взвешенный индекс цитирования (ВИЦ) на Яндексе. Есть такие аналоги и у Апорта, и у Рамблера.
Основная идея такого ранжирования состоит в том, чтобы определить вероятность нахождения пользователя на данной Web-странице; при этом, конечно, сумма вероятностей по всем Web-страницам сети должна быть равной единице, так как пользователь Интернета обязательно должен где-то находиться.
Но у этой модели много недостатков, так как PageRank в принципе должен был бы нормироваться по всем документам Сети, а большая их часть недоступна поисковикам. Правда, сами величины, в общем-то, относительны, поэтому при расчетах они часто нормируются не на единицу по сумме всех страниц, а на единичный усредненный (то есть на суммарный по N страницам), то есть PageRank выражен не в единицах вероятности, а в неких относительных единицах. Кроме того, вводится так называемое затухание, чтобы длинные цепочки ссылок на сайте были малополезны (это реализация «правила трех кликов», утверждающего, что пользователь не захочет искать нужную ему страницу более чем тремя кликами).
Главным же недостатком алгоритма поиска с применением PageRank является то, что он при поиске продвигает наверх те документы, которые и без поисковика наиболее популярны, поэтому введение такого алгоритма существенно ужесточает конкуренцию, что и продемонстрировала в свое время поисковая система Google. Однако когда новые правила игры были всеми осознаны и поняты, то поисковики опять начали проигрывать «оптимизаторам», а новичков такой порядок вообще не устраивал — их никто не пускал в «клуб известных сайтов», которые поднимали PageRank.
Но самым опасным заблуждением, на котором базируется алгоритм ранжирования по цитируемости, является предположение о связности Интернета, которое основано на уверенности в том, что с любого сайта можно попасть на любой другой за конечное число переходов по ссылкам. Однако для разработки такого рода алгоритмов необходимо учитывать архитектуру всего Web-пространства, а этой информацией пока никто в достаточной мере не владеет. И даже отдаленно близкой к реальности математической модели не существовало вплоть до начала 2000 года. А когда специалисты компаний AltaVista, IBM и Compaq совершили прорыв, математически описав «карту» Интернет-ресурсов и гиперсвязей, то оказалось, что расхожее мнение о том, будто Интернет является единым переплетенным пространством, попросту неверно. Проследив с помощью поискового механизма AltaVista свыше 600 млн. Web-страниц и миллиарды ссылок, размещенных на этих страницах, ученые пришли к следующим выводам о структуре Web-пространства, которая напоминает, по их мнению, «галстук-бабочку» (Bow Tie):
- центральное ядро, или узел галстука, составляют примерно 30% Web-страниц, взаимосвязанных настолько тесно, что, следуя гиперссылкам, из любой из них в конечном счете можно попасть на любую другую (сильно связное множество);
- 24% Web-страниц — это отправные Web-страницы, которые содержат гиперссылки, в конечном счете ведущие к ядру, но из ядра к ним попасть нельзя (односторонняя связность);
- столько же — 24% — оконечных Web-страниц, к которым можно прийти по ссылкам из ядра, но нельзя вернуться назад;
- и наконец, 22% Web-страниц полностью изолированы от центрального ядра — это либо «мысы», связанные гиперссылками со страницами любой другой категории; либо «перешейки», соединяющие две Web-страницы, которые не входят в ядро; либо «острова», вообще не пересекающиеся с остальными ресурсами Интернета. Единственный способ обнаружить ресурсы этой группы — знать их точный адрес. Никакие поисковые машины не смогут найти эти «необитаемые острова», если они в прошлом каким-то образом не соединялись с другими частями Интернета.
Теперь уже ясно, что пропорции указанных четырех категорий остаются неизменными, несмотря на значительное увеличение общего объема Web-ресурсов. Если путь от сайта к сайту все-таки существует, то среднее количество кликов по результатам исследований составляет 16; если этот путь двусторонний, то среднее число промежуточных кликов сокращается до 7; однако с большой вероятностью случайно выбранные Web-страницы вообще никак не будут связаны.
Таким образом, при активном применении PageRank примерно четверть Интернет-сайтов обречена на существование в рамках «невидимого» Интернета, и даже если какие-то из них случайно попадут в поле зрения поисковиков, то со временем они все равно будут выброшены из баз, как обладающие низким рангом и малопопулярные. И пользователь может провести всю жизнь в поисках нужной информации с такого «необитаемого острова», если только совершенно случайно не наткнется на искомый материал.
Заключение
сли
в самое ближайшее время не будет предпринято каких-то действительно радикальных
мер, то Интернет как информационная система убьет сам себя. И даже поисковые
системы современного типа этой задачи не решают. Нужны какие-то средства поиска
информации по нечетким запросам, нужны, в конце концов, не только роботы-пауки,
но и роботы-чистильщики информации, а также роботы-полицейские.
Нужны и персональные средства актуализации данных. Интернет будет полезен только тогда, когда в нем будет относительно чисто и все будет разложено по полочкам.
Синтаксис запросов к популярным поисковым системам в последнее время настолько упростился, что можно рассматривать в качестве одного из удивительных феноменов тот факт, что качество откликов по-прежнему сохраняется на приемлемом уровне при лавинообразном росте ресурсов Сети. Сейчас дошло даже до того, что в качестве перспективных рассматриваются системы поиска вообще практически без запросов пользователя. Такой поисковик будет искать популярные ресурсы исходя из общего поискового контекста, причем параллельно будет сообщаться еще немало сопутствующей информации. Например, результаты поиска по цифровым камерам будут сопровождаться таблицей популярных моделей, которые искали другие пользователи. Остается только разбить искавших по полу и возрасту, и можно будет узнать, «чего же я хочу на самом деле».
В любом случае сегодня можно констатировать, что привычные подходы к поиску, основанные на использовании логических операторов, потерпели крах и что на первое место в поисковых методах вышли не инструменты индексирования баз данных и организации логического поиска, а новые семантические алгоритмы. Следует отметить, что пионером здесь стала компания Google, поставившая на ранжирование выдачи и алгоритмы, основанные на цитируемости.
Традиционные средства учета информационных ресурсов Сети — каталоги и информационно-поисковые системы — сегодня уже не справляются с задачей поиска и не выдерживают усиления потока Интернет-информации. Все основные технологические проблемы Интернет-технологий, которые мы сейчас наблюдаем и зачастую ощущаем на себе, появились по причине того, что в те времена, когда данные технологии еще только разрабатывались, никто не предвидел превращения Интернета в глобальную информационную среду. Все сказанное полностью относится и к поисковым системам.
Существующая архитектура, которая обеспечивала работоспособность поисковой системы в условиях низкой скорости и ненадежности каналов связи, низкой вычислительной мощности клиентского оборудования и не очень больших объемов документов (сотни тысяч, миллионы), что было актуально в 90-х годах, сейчас окончательно устарела. Высокоскоростные и надежные каналы связи стали обычным явлением, в несколько десятков раз выросла вычислительная мощность клиентских компьютеров, а число документов в Сети увеличилось в сотни раз, приближаясь к сотне миллиардов. Следовательно, необходима иная архитектура, реализующая новые требования, однако современные подходы к решению этих проблем кажутся не более чем латанием старых дыр. И хотя уже возник новый класс систем, который позволяет как-то справляться с проблемой размерности Сети, его можно рассматривать лишь как временный феномен. Да, такие поисковики, как Google «у них» или Яндекс «у нас», еще способны выдавать относительно содержательные, семантически наполненные результаты, причем без непосредственного привлечения методов искусственного интеллекта, объемных баз знаний и даже экспертов как таковых, а лишь за счет использования частотно-лингвистических и эвристических методов, но долго ли будет сохраняться текущее положение? Этот вопрос остается открытым.
По-прежнему незаменимыми остаются сегодня узкотематические (или региональные) каталоги и поисковики. Одним из основных источников тематической информации являются каталоги ссылок, пополняемые добровольцами. Но такие ресурсы содержат адреса не более чем 1% всех страниц в Сети, и хотя в большинстве случаев можно рассчитывать на высокий уровень пертинентности полученных там ссылок, никак нельзя ожидать от них не только сколь-нибудь существенного расширения в будущем, но даже приемлемого обновления в настоящем. Рекомендуем обратить внимание на такие глобальные справочники, как Open Directory Project (http://dmoz.org), а также российские — Апорт (http://aport.ru), List.ru (list.mail.ru), Weblist (Weblist.ru или www.yahoo.ru), Улитка (www.ulitka.ru), Иван Сусанин (www.susanin.net). К основным недостаткам российских справочников относятся отсутствие четких подходов в отборе материалов, серьезные ошибки в систематизации данных, запаздывание в отражении источников и низкий уровень аннотаций. Создание и поддержание в актуальном состоянии качественных справочников по Интернет-ресурсам требует серьезных инвестиций, которых в России пока еще нет, так что далеко не всегда информация, содержащаяся в каталоге, будет соответствовать потребностям пользователя.
Другой вариант — тематические ресурсы или ворталы (вертикальные порталы), посвященные специализированной тематике. Именно на подобных сайтах можно получить необходимую информацию, так как в большинстве случаев коллекционированием ссылок там занимается человек, который в той или иной мере разбирается в данном вопросе и для которого этот проект является либо хобби, либо способом дополнительного заработка. Для поиска в «невидимой» Сети, а именно в том ее сегменте, который составляют базы данных, к счастью, тоже существуют специализированные ресурсы. Direct Search, созданный Гари Прайсом (Gary Price), на данный момент находится на сервере George Washington University. На этом сайте собраны коллекции ссылок на различные базы данных, полные тексты книг на языке оригинала, экономические прогнозы на ближайшие несколько лет и т.д.
Программный пакет BullsEye 2 компании IntelliSeek осуществляет поиск более чем в 800 сетевых ресурсах. Кроме основных механизмов, BullsEye предоставляет доступ к базам данных, не проиндексированным по указанным выше причинам. Этой же компании принадлежит и другая уникальная разработка в области сетевого поиска — сайт Invisible Web, который включает каталог баз данных самого различного направления, объединенных одной особенностью — в большинстве своем все они не были проиндексированы поисковыми машинами. При введении ключевого слова этот ресурс не выдаст привычного набора из десяти ссылок, а определит ресурсы, с помощью которых поиск необходимой информации станет оптимальным. Сайт WebData.com — это еще один пример поисковой машины, основной задачей которой является сотрудничество с базами данных.
Кстати, совсем недавно Google сообщил о специальной индексации сайтов крупнейших учебных заведений, что должно несколько улучшить поиск различной информации академического характера. Новый вид поиска под названием Google Scholar (http://scholar.google.com) облегчит жизнь учащимся и научным работникам, так как он специально предназначен для поиска специализированной научной литературы, включая рефераты диссертаций, статьи, книги, различные научные публикации и ссылки на них. При этом в базу данных научного поисковика от Google войдут как документы, находящиеся в открытом доступе, так и материалы, доступные исключительно по подписке (статьи, которые только цитируются в проиндексированных материалах, выводятся в результатах с пометкой citation), причем последние включаются в базу данных по согласованию с издателями, полные версии статей будут доступны только подписчикам, а все остальные пользователи смогут ознакомиться только с рефератами таких материалов. Впрочем, необходимо отметить, что сейчас Google Scholar работает далеко не со всеми научными издательствами, да и сам сервис только тестируется, поэтому еще неясно, к чему все это в конце концов приведет. Например, пока на Google Scholar не будут размещаться рекламные ссылки, но в будущем они, конечно, появятся. Стоит отметить, что Google Scholar отнюдь не единственная поисковая система по научным материалам, а среди наиболее универсальных систем такого рода можно назвать Scirus (http://www.scirus.com), принадлежащую одному из крупнейших в мире научных издательств Elseiver.
Некоторые разработчики надеются, что им удастся радикально улучшить и расширить применение механизмов метапоиска, которые будут отбирать результаты поиска других поисковых машин и более точно распределять их по тематическим категориям. К наиболее известным метапоисковым машинам сегодня относятся, в частности, MetaCrawler (http://www.metacrawler.com), KartOO (http://www.kartoo.com), Vivisimo (http://vivisimo.com), Ez2www.com (http://ez2www.com) и др. В российском сегменте Интернета также представлены подобные системы, рассылающие запросы как в российские, так и в глобальные поисковые системы, — это сервисы Punto (http://Punto.ru) и MetaBot (http://www.metabot.ru), которые являются малоизвестными и не обладают выдающимися достоинствами. Развернутый список метапоисковых систем можно получить в Русской справочной библиотеке (http://www.openweb.ru/stepanov/library/gsengine.htm).
Однако, несмотря на приведенные примеры, говорить о победах на пространстве «невидимой» Сети нельзя, тем более что этот сегмент Интернета, возможно, будет расти быстрее прочих. И как бы там ни было и чего бы ни добивались ученые, но если общая тенденция развития доступной части Интернета лежит в области коммерциализации и популяризации Интернет-ресурсов, то все стремления к систематизации Интернета будут напоминать попытки наведения порядка на свалке и развитие индустрии по переработке мусора.
Между тем количество пользователей Интернета постоянно растет, их средний социальный статус неуклонно понижается, а среднестатистическое время, которое эти пользователи проводят в Сети, увеличивается. Проведенный среди американцев опрос показал, что если в 2000 году среднестатистический житель страны тратил на Сеть менее 10 часов в неделю, то к 2005 году средняя продолжительность пребывания в Интернете увеличится вдвое. При этом уже более 50% интернетчиков, по данным статистических опросов, не верят в достоверность информации в Сети, причем с каждым годом доверие к достоверности размещенной там информации все больше падает — в 2000 году количество пользователей, доверяющих Интернету, составляло около 60%.
А тем временем акции поисковых систем (в том числе и самой популярной — Google) продолжают дешеветь…








